Greenplum数据库数据分片策略Hash分布——执行器行为
Greenplum数据库Hash分布执行器部分主要涉及Motion、Result和SplictUpdate节点。以使用CdbHash *makeCdbHash(int numsegs, int natts, Oid *hashfuncs)创建一个 CdbHash 结构体、cdbhashinit()执行初始化操作,仅仅是初始化hash初始值、cdbhash()函数会调用hashDatum()针对不同类型做不同的预处理,最后将处理后的列值添加到哈希计算中、cdbhashreduce() 映射哈希值到某个 segment为脉络学习以下执行器对Hash分布的处理。
Motion
只有当Motion类型为MOTIONTYPE_HASH且执行发送任务(MOTIONSTATE_SEND)的后端才可能涉及Hash分布处理(motionstate->mstype == MOTIONSTATE_SEND && node->motionType == MOTIONTYPE_HASH)。也就是说后端进程需要将处理的数据直接发送给其他后端进程,且这个接收后端可以通过分布键数据进行计算哈希值、映射segment后定位到。其执行堆栈为ExecInitNode --> ExecInitMotion --> makeCdbHash。
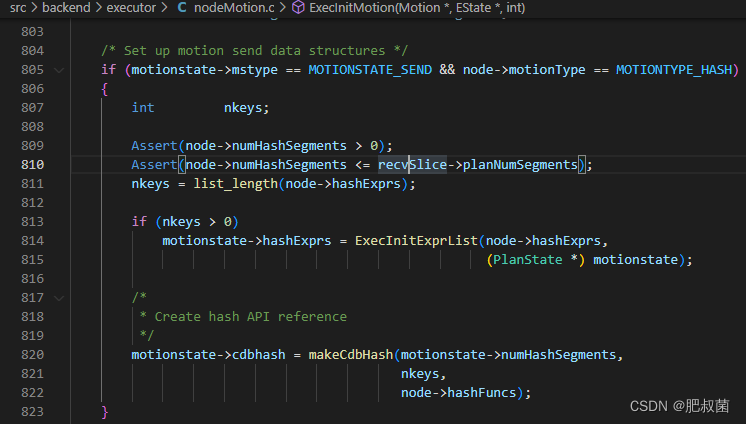
涉及hash的motion执行流程堆栈如下ExecMotion --> execMotionSender --> doSendTuple --> evalHashkey(nodeMotion.c) --> cdbhashinit和cdbhash。调用doSendTuple发送tuple的情况下,当motion类型为MOTIONTYPE_HASH,就需要计算出该segment的index,然后设置到targetRoute变量中。计算的函数就是evalHashkey。
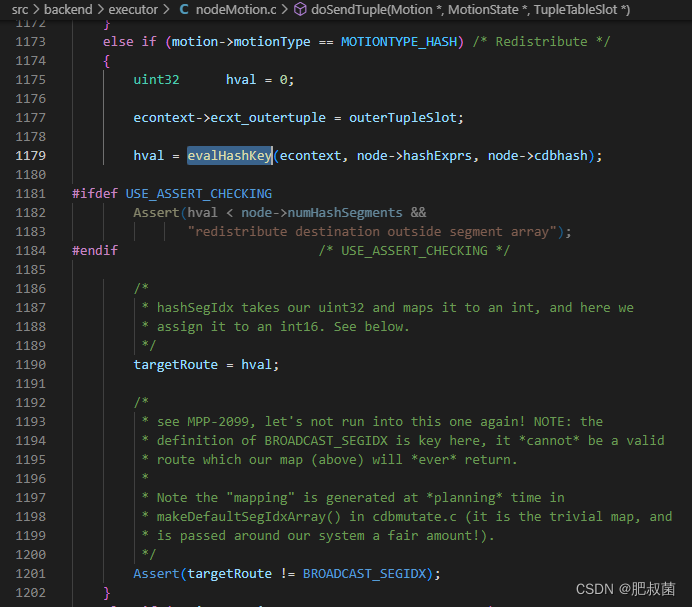
如果向evalHashKey函数传入分布键列表hashkeys则使用CdbHash计算哈希值、映射segment,如果没有传入分布键,直接随机选取segment。CdbHash计算哈希值、映射segment的流程在Greenplum数据库Hash分布——计算哈希值和映射segment描述过,这里就不做叙述了。
uint32 evalHashKey(ExprContext *econtext, List *hashkeys, CdbHash * h) {
ListCell *hk; unsigned int target_seg;
ResetExprContext(econtext);
MemoryContext oldContext = MemoryContextSwitchTo(econtext->ecxt_per_tuple_memory); // 切换到ecxt_per_tuple_memory
if (list_length(hashkeys) > 0){ /* If we have 1 or more distribution keys for this relation, hash them. However, If this happens to be a relation with an empty policy (partitioning policy with a NULL distribution key list) then we have no hash key value to feed in, so use cdbhashrandomseg() to pick a segment at random. */
int i = 0;
cdbhashinit(h);
foreach(hk, hashkeys){
ExprState *keyexpr = (ExprState *) lfirst(hk);
Datum keyval; bool isNull;
keyval = ExecEvalExpr(keyexpr, econtext, &isNull); /* Get the attribute value of the tuple */
cdbhash(h, i + 1, keyval, isNull); /* Compute the hash function */
i++;
}
target_seg = cdbhashreduce(h);
}else {
target_seg = cdbhashrandomseg(h->numsegs);
}
MemoryContextSwitchTo(oldContext);
return target_seg;
}
Result
关于Result节点的详细内容可以参考PostgreSQL数据库查询执行——控制节点Result。greenplum在Result节点引入numHashFilterCols、hashFilterColIdx和hashFilterFuncs成员,为每行数据的hashFilterColIdx数组指定列计算cdbhash值,如果映射的segment不是当前执行该ResultNode的segment,该行数据将被抛弃,也就是引入了filter过滤数据功能。
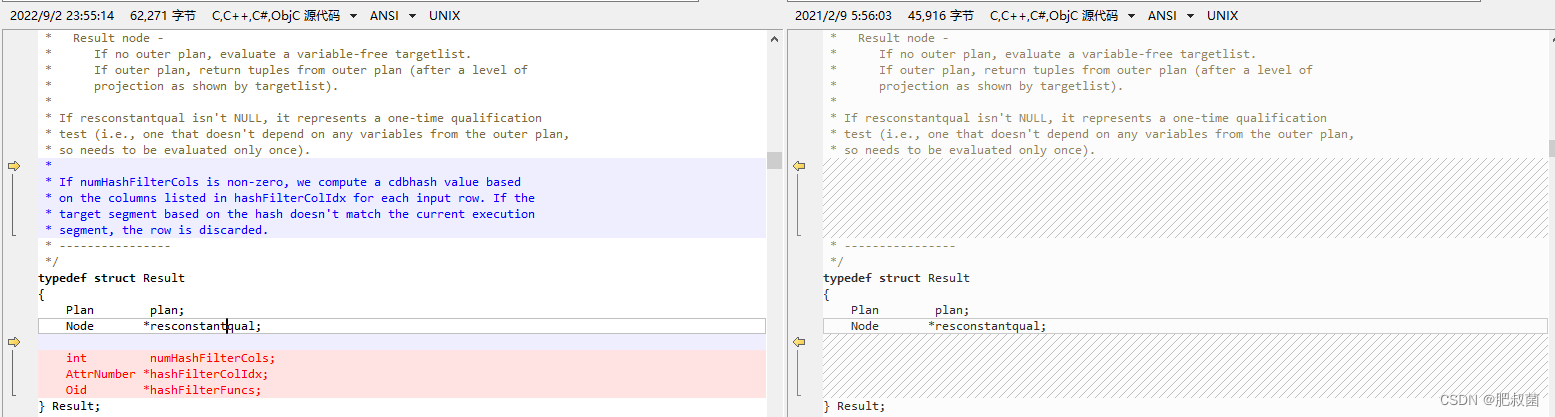
其执行堆栈为ExecInitNode --> ExecInitResult --> makeCdbHash。如果numHashFilterCols大于零时,使用numHashFilterCols、hashFilterFuncs和planNumSegments创建CdbHash结构体。
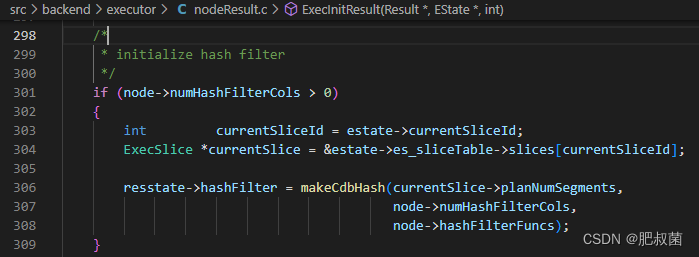
Result节点执行堆栈为ExecResult --> TupleMatchesHashFilter(nodeResult.c) --> cdbhashinit\cdbhash。TupleMatchesHashFilter函数用于处理ExecInitNode greenplum在Result节点引入了filter过滤数据功能。TupleMatchesHashFilter如果数据tuple匹配hash filter时返回true。
/* Returns true if tuple matches hash filter. */
static bool TupleMatchesHashFilter(ResultState *node, TupleTableSlot *resultSlot){
Result *resultNode = (Result *)node->ps.plan;
bool res = true;
if (node->hashFilter) { // CdbHash结构体
cdbhashinit(node->hashFilter);
for (int i = 0; i < resultNode->numHashFilterCols; i++){ // 处理参与过滤的每个列
int attnum = resultNode->hashFilterColIdx[i]; // 取出列号
Datum hAttr; bool isnull;
hAttr = slot_getattr(resultSlot, attnum, &isnull);
cdbhash(node->hashFilter, i + 1, hAttr, isnull); // 将列数据加入hash计算
}
int targetSeg = cdbhashreduce(node->hashFilter);
res = (targetSeg == GpIdentity.segindex); // 判定是否是本segment index
}
return res;
}
SplitUpdate
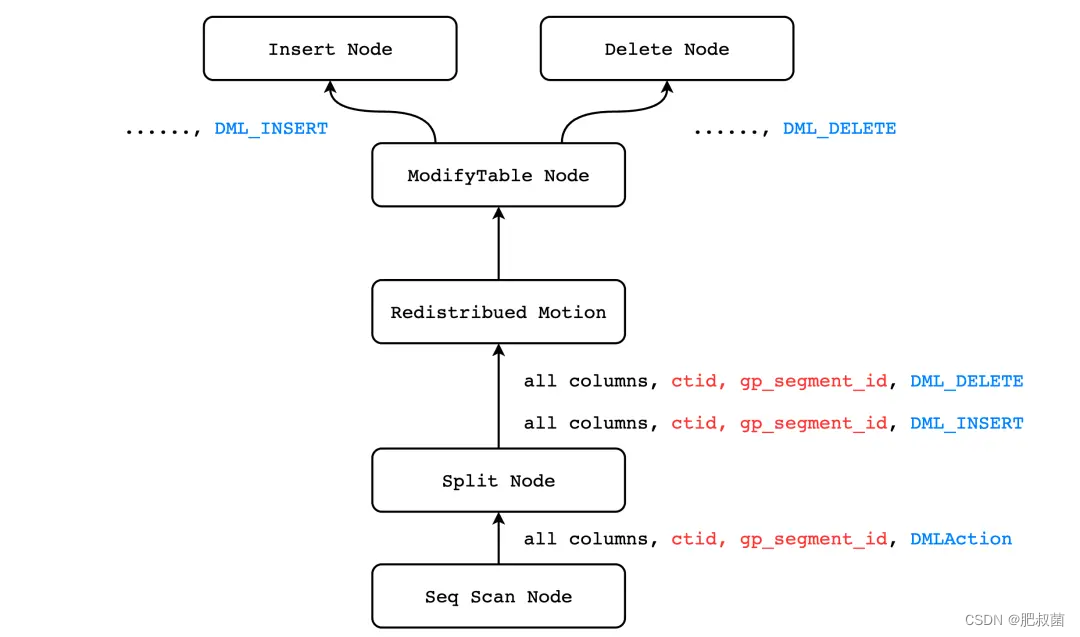
在Greenplum数据库中,允许用户更新元组的分片键,使得数据从当前节点转移到另一个节点。Greenplum数据库非常巧妙的利用了 Motion Node 可以在节点之间进行数据传输的特性,以及 PostgreSQL 的火山模型,实现了更新分片键的特性。PostgreSQL中并没有任何的一个执行器节点能够完成分布式数据的更新,Greenplum 引入了一个新的执行器节点 SplitUpdate。SplitUpdate 的原理其实非常简单,其过程和 PostgreSQL 中更新数据类似,只不过两者的出发点不同而已。当我们执行 update 语句时,并不会原地更新数据,而是先插入一条更新后的数据,再删除旧数据。Greenplum 所实现的 Split Update 并不会执行 ExecUpdate() 函数,而是主动地将更新操作分裂成 INSERT 和 DELETE(其实就是在更新后数据存储segment执行INSERT,在原数据存储segment执行DELETE)。
postgres=# create table t (a int, b int); // 分布键为a,分布策略为random
postgres=# insert into t values (1), (2), (3);
postgres=# select gp_segment_id, * from t; -- ①
gp_segment_id | a | b
---------------+---+---
1 | 1 |
0 | 2 |
0 | 3 |
(3 rows)
如上例所示,从 ① 中我们可以看到数据目前是分布在 segment-0 和 segment-1 上的,当我们更新分布键 a 以后,数据将全部分布在了 segment-0 上。
postgres=# explain (verbose, costs off) update t set a = a + 1;
QUERY PLAN
--------------------------------------------------------------------
Update on public.t -- ⑤
-> Explicit Redistribute Motion 3:3 (slice1; segments: 3) -- ④
Output: ((a + 1)), b, ctid, gp_segment_id, (DMLAction)
-> Split
Output: ((a + 1)), b, ctid, gp_segment_id, DMLAction -- ③
-> Seq Scan on public.t
Output: (a + 1), b, ctid, gp_segment_id -- ②
Optimizer: Postgres query optimizer
(8 rows)
在 ② 中我们可以看到,除了返回表 t 所有的定义列以及 ctid 以外,还额外返回了当前 tuple 的所处的 segment 的 segment_id,这是因为 Greenplum 是分布式数据库,必须由 (gp_segment_id, ctid) 两者才能唯一确定一个 tuple。而在 Split 节点中,输出列又多了一个 DMLAction,这一列将会保存 Split 节点向上输出的两个 tuple 中,哪一个执行插入,哪一个执行删除。Motion 节点则将数据发送至正确的 segment 上进行执行,并根据 DMLAction 的值决定执行插入还是删除。
postgres=# update t set a = a + 1;
UPDATE 3
postgres=# select gp_segment_id, * from t;
gp_segment_id | a | b
---------------+---+---
0 | 3 |
0 | 4 |
0 | 2 |
(3 rows)
通常来说,当我们想要给 PostgreSQL 添加一个新语法或者新功能时,通常会按照添加新语法->添加新路径->添加新查询计划->添加新的执行器节点等步骤来完成,但是 UPDATE 本身就是 PostgreSQL 原生的功能,因此不需要在 gram.y 中添加新的语法。但是,从 Split Update 的执行计划我们可以看到,除了原有的 SeqScan 节点和 Update 节点以外,还会有 Split 节点和 Motion 节点。其中 Split 节点用于将一个 tuple 分裂成两个,Motion 节点则将 Split 节点返回的 tuple 根据分片键发送至正确的 segment 上执行插入或者删除。在 PostgreSQL 中,一个执行节点对应着一个 Plan Node,而一个 Plan Node 则是由最优的 Path 所构成的。因此,我们需要实现 Split Path 和 Split Plan,Motion Path 和 Motoin 已经被实现了,我们可以直接拿过来复用。Split Path 其实非常简单,我们只需要在其返回的列中添加一个名叫 DMLAction 的标志位即可,它既 表示在执行 Modify Table 时执行的是 Split Update,同时也可以保存对于当前 tuple 是执行插入还是删除。接下来我们就来看下在 PostgreSQL 中新增一个 Path 有多么的简单。
首先,我们要决定 Split Update Path 中到底需要什么,或者说有哪些信息是需要该节点保存的。首先,Split Update Path 只会有一个 SubPath,不存在左右子树的情况,如 WindowAggPath。其次,我们最好是在 Split Update Path 中保存我们到底更新的是哪一张表,这样一来方便 Motion Path 打开这张表并获取 Distributed Policy,从而决定到底需不需要添加 Motion 节点。如果被更新表是随机分布或者是复制表的话,那么就不需要 Motion 节点了。因此,我们就得到了如下 Path 结构:
typedef struct SplitUpdatePath {
Path path;
Path *subpath; /* 子 Path,通常都是 ProjectionPath */
Index resultRelation; /* 被更新表在 RTE 链表中的下标(从 1 开始) */
} SplitUpdatePath;
紧接着,我们需要一个函数,来创建我们的 SplitUpdatePath 结构,这个函数的作用也非常简单,只需要把 SplitUpdatePath 添加到下层路径之上,并将标志位添加至 PathTarget 中即可:
typedef struct DMLActionExpr {
Expr xpr;
} DMLActionExpr;
static SplitUpdatePath *make_splitupdate_path(PlannerInfo *root, Path *subpath, Index rti) {
RangeTblEntry *rte;
PathTarget *splitUpdatePathTarget;
SplitUpdatePath *splitupdatepath;
DMLActionExpr *actionExpr;
rte = planner_rt_fetch(rti, root); /* Suppose we already hold locks before caller */
actionExpr = makeNode(DMLActionExpr); /* 创建 DMLAction 列 */
splitUpdatePathTarget = copy_pathtarget(subpath->pathtarget);
add_column_to_pathtarget(splitUpdatePathTarget, (Expr *) actionExpr, 0); /* 将 DMLAction 插入到 target list 的尾部,在执行阶段取出 */
/* populate information generated above into splitupdate node */
splitupdatepath = makeNode(SplitUpdatePath);
splitupdatepath->path.pathtype = T_SplitUpdate; /* Split Path 的节点类型为 T_SplitUpdate */
splitupdatepath->path.parent = subpath->parent; /* 它们具有相同的 RelOptInfo */
splitupdatepath->path.pathtarget = splitUpdatePathTarget; /* 替换 pathtarget,即返回列必须多出 DMLAction 列 */
splitupdatepath->path.rows = 2 * subpath->rows; /* 预估的 tuple 数量,由于 split update = delete + insert,所以会有 2 条数据 */
splitupdatepath->path.param_info = NULL; /* 其余参数照抄即可 */
splitupdatepath->path.parallel_aware = false;
splitupdatepath->path.parallel_safe = subpath->parallel_safe;
splitupdatepath->path.parallel_workers = subpath->parallel_workers;
splitupdatepath->path.startup_cost = subpath->startup_cost;
splitupdatepath->path.total_cost = subpath->total_cost;
splitupdatepath->path.pathkeys = subpath->pathkeys;
splitupdatepath->path.locus = subpath->locus;
/* 包裹 ProjectionPath,使其成为子节点 */
splitupdatepath->subpath = subpath;
splitupdatepath->resultRelation = rti;
/* 这里也只是在原有的 path 下面加了一个一个属性而已 */
return splitupdatepath;
}
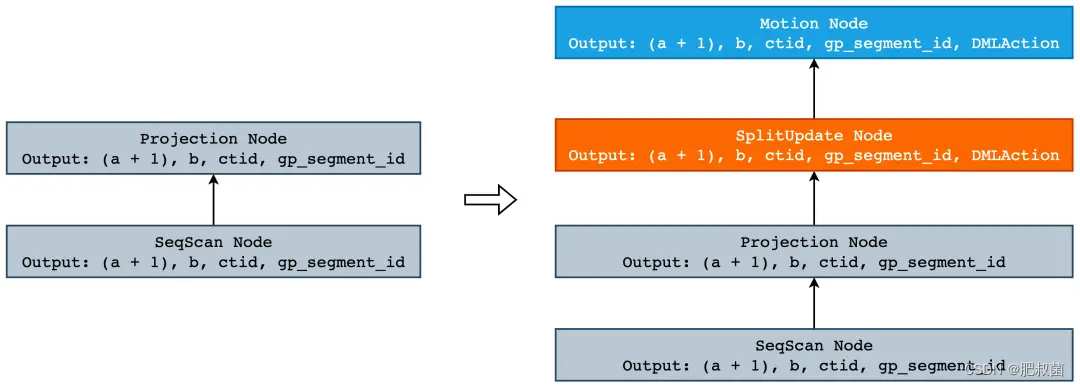
当有了 SplitUpdatePath 以后,剩下的就是将 Path 转换成 Plan,由于我们并没有其它可供竞争的 Path,因此直接构建即可:
/* SplitUpdate Plan Node */ // 定义在src/include/nodes/plannodes.h中
typedef struct SplitUpdate {
Plan plan;
AttrNumber actionColIdx; /* DMLAction 在 targetlist 中的位置,便于快速访问 */
AttrNumber tupleoidColIdx; /* ctid 在 targetlist 中的位置,便于快速访问 */
List *insertColIdx; /* 执行 Insert 时需要使用到的 target list */
List *deleteColIdx; /* 执行 Delete 时需要使用到的 target list */
/* 下面的字段就是 Distributed Policy,在更新以哈希分布的表时会使用,主要用来计算
* Insert 的 tuple 到哪个 segment,Delete 的话直接用本 segment 的 gp_segment_id
* 即可。*/
int numHashAttrs;
AttrNumber *hashAttnos;
Oid *hashFuncs; /* corresponding hash functions */
int numHashSegments; /* # of segs to use in hash computation */
} SplitUpdate;
接下来就是在 create_splitupdate_plan() 函数中填充 SplitUpdate 计划节点中的字段,主要就是一些索引 List 和 Distributed Policy,这些内容流程比较简单,但是又没有现成的通用函数来完成,因此会有些繁琐:
static Plan * create_splitupdate_plan(PlannerInfo *root, SplitUpdatePath *path) {
Path *subpath = path->subpath;
Plan *subplan;
SplitUpdate *splitupdate;
Relation resultRel;
TupleDesc resultDesc;
GpPolicy *cdbpolicy;
int attrIdx;
ListCell *lc;
int lastresno;
Oid *hashFuncs;
int i;
/* 获取更新表的 Distributed Policy */
resultRel = relation_open(planner_rt_fetch(path->resultRelation, root)->relid, NoLock);
resultDesc = RelationGetDescr(resultRel);
cdbpolicy = resultRel->rd_cdbpolicy;
/* 递归构建 subpath 的 Plan */
subplan = create_plan_recurse(root, subpath, CP_EXACT_TLIST);
/* Transfer resname/resjunk labeling, too, to keep executor happy */
apply_tlist_labeling(subplan->targetlist, root->processed_tlist);
splitupdate = makeNode(SplitUpdate);
splitupdate->plan.targetlist = NIL; /* filled in below */
splitupdate->plan.qual = NIL;
splitupdate->plan.lefttree = subplan;
splitupdate->plan.righttree = NULL;
copy_generic_path_info(&splitupdate->plan, (Path *) path);
lc = list_head(subplan->targetlist);
/* 遍历目标更新表的所有属性 */
for (attrIdx = 1; attrIdx <= resultDesc->natts; ++attrIdx) {
TargetEntry *tle;
Form_pg_attribute attr;
tle = (TargetEntry *) lfirst(lc);
lc = lnext(lc);
attr = &resultDesc->attrs[attrIdx - 1];
/* 构建 Insert 和 Delete 列表,其中 deleteColIdx 仅仅只是为了满足格式要求,无实际作用 */
splitupdate->insertColIdx = lappend_int(splitupdate->insertColIdx, attrIdx);
splitupdate->deleteColIdx = lappend_int(splitupdate->deleteColIdx, -1);
splitupdate->plan.targetlist = lappend(splitupdate->plan.targetlist, tle);
}
lastresno = list_length(splitupdate->plan.targetlist);
/* ....... */
splitupdate->plan.targetlist = lappend(splitupdate->plan.targetlist,
makeTargetEntry((Expr *) makeNode(DMLActionExpr),
++lastresno, "DMLAction", true));
/* 构建 Distributed Policy 相关,例如哈希函数、分片键等等 */
hashFuncs = palloc(cdbpolicy->nattrs * sizeof(Oid));
for (i = 0; i < cdbpolicy->nattrs; i++) {
AttrNumber attnum = cdbpolicy->attrs[i];
Oid typeoid = resultDesc->attrs[attnum - 1].atttypid;
Oid opfamily;
opfamily = get_opclass_family(cdbpolicy->opclasses[i]);
hashFuncs[i] = cdb_hashproc_in_opfamily(opfamily, typeoid);
}
splitupdate->numHashAttrs = cdbpolicy->nattrs;
splitupdate->hashAttnos = palloc(cdbpolicy->nattrs * sizeof(AttrNumber));
memcpy(splitupdate->hashAttnos, cdbpolicy->attrs, cdbpolicy->nattrs * sizeof(AttrNumber));
splitupdate->hashFuncs = hashFuncs;
splitupdate->numHashSegments = cdbpolicy->numsegments;
relation_close(resultRel, NoLock);
root->numMotions++;
return (Plan *) splitupdate;
}
当我们有了 Path 和 Plan 之后,剩下的就是执行器了。下面是对SplitUpdate进行初始化。
/* ExecNode for Split.
* This operator contains a Plannode in PlanState. The Plannode contains indexes to the ctid, insert, delete, resjunk columns needed for adding the action (Insert/Delete). A MemoryContext and TupleTableSlot are maintained to keep the INSERT tuple until requested.
*/
typedef struct SplitUpdateState {
PlanState ps;
bool processInsert; /* flag that specifies the operator's next action. */
TupleTableSlot *insertTuple; /* tuple to Insert */
TupleTableSlot *deleteTuple; /* tuple to Delete */
AttrNumber input_segid_attno; /* attribute number of "gp_segment_id" in subplan's target list */
AttrNumber output_segid_attno; /* attribute number of "gp_segment_id" in output target list */
struct CdbHash *cdbhash; /* hash api object */
} SplitUpdateState;
SplitUpdate节点的初始化堆栈如下ExecInitNode --> ExecInitSplitUpdate --> makeCdbHash和ExecInitNode --> ExecInitSplitUpdate —> 设置ExecProcNode为ExecSplitUpdate(该函数会调用cdbhashinit\cdbhash)。
/* Init SplitUpdate Node. A memory context is created to hold Split Tuples. */
SplitUpdateState* ExecInitSplitUpdate(SplitUpdate *node, EState *estate, int eflags){
SplitUpdateState *splitupdatestate = makeNode(SplitUpdateState);
splitupdatestate->ps.plan = (Plan *)node;
splitupdatestate->ps.state = estate;
splitupdatestate->ps.ExecProcNode = ExecSplitUpdate; // 设置ExecProcNode为ExecSplitUpdate(该函数会调用cdbhashinit\cdbhash)
splitupdatestate->processInsert = true;
Plan *outerPlan = outerPlan(node); /* then initialize outer plan */
outerPlanState(splitupdatestate) = ExecInitNode(outerPlan, estate, eflags);
ExecAssignExprContext(estate, &splitupdatestate->ps);
/* New TupleDescriptor for output TupleTableSlots (old_values + new_values, ctid, gp_segment, action). */
TupleDesc tupDesc = ExecTypeFromTL(node->plan.targetlist);
splitupdatestate->insertTuple = ExecInitExtraTupleSlot(estate, tupDesc, &TTSOpsVirtual);
splitupdatestate->deleteTuple = ExecInitExtraTupleSlot(estate, tupDesc, &TTSOpsVirtual);
/* Look up the positions of the gp_segment_id in the subplan's target list, and in the result. */
splitupdatestate->input_segid_attno = ExecFindJunkAttributeInTlist(outerPlan->targetlist, "gp_segment_id");
splitupdatestate->output_segid_attno = ExecFindJunkAttributeInTlist(node->plan.targetlist, "gp_segment_id");
/* DML nodes do not project. */
ExecInitResultTupleSlotTL(&splitupdatestate->ps, &TTSOpsVirtual);
splitupdatestate->ps.ps_ProjInfo = NULL;
/* Initialize for computing hash key */
if (node->numHashAttrs > 0)
splitupdatestate->cdbhash = makeCdbHash(node->numHashSegments,node->numHashAttrs,node->hashFuncs); // 创建cdbhash
if (estate->es_instrument && (estate->es_instrument & INSTRUMENT_CDB))
splitupdatestate->ps.cdbexplainbuf = makeStringInfo();
return splitupdatestate;
}
对于 Split 执行节点而言,要做的事情就是将下层执行器节点返回的 tuple 一分为二并保存起来,一个表示删除,一个表示插入,然后继续向上返回给上层节点。执行堆栈如下所示ExecSplitUpdate --> SplitTupleTableSlot --> evalHashkey(nodeSplictUpdate.c) --> cdbhashinit\cdbhash。
/* Splits every TupleTableSlot into two TupleTableSlots: DELETE and INSERT. */
static TupleTableSlot *ExecSplitUpdate(PlanState *pstate){
SplitUpdateState *node = castNode(SplitUpdateState, pstate);
PlanState *outerNode = outerPlanState(node);
SplitUpdate *plannode = (SplitUpdate *) node->ps.plan;
TupleTableSlot *slot = NULL;
TupleTableSlot *result = NULL;
/* Returns INSERT TupleTableSlot. */
if (!node->processInsert)
{
result = node->insertTuple;
node->processInsert = true;
}
else
{
/* Creates both TupleTableSlots. Returns DELETE TupleTableSlots.*/
slot = ExecProcNode(outerNode);
if (TupIsNull(slot))
{
return NULL;
}
/* `Split' update into delete and insert */
slot_getallattrs(slot);
Datum *values = slot->tts_values;
bool *nulls = slot->tts_isnull;
ExecStoreAllNullTuple(node->deleteTuple);
ExecStoreAllNullTuple(node->insertTuple);
SplitTupleTableSlot(slot, plannode->plan.targetlist, plannode, node, values, nulls);
result = node->deleteTuple;
node->processInsert = false;
}
return result;
}
SplitUpdate节点后续再研究,这里先记下
参考:https://my.oschina.net/GreenplumCommunity/blog/5569079
ExecInitNode --> ExecPartitionDistribute --> distributeTupleTableSlot --> ExecFindTargetPartitionContentId --> findTargetContentid --> makeCdbHashForRelation --> makeCdbHash
Greenplum数据库Hash分布——DDL
cdb_get_opclass_for_column_def函数在ALTER TABLE SET DISTRIBUTED BY语句为表设置distribution policy的函数ATExecSetDistributedBy、CREATE TABLE AS语句基于DISTRIBUTED BY设置Query->intoPolicy的函数setQryDistributionPolic
CopyFrom --> InitDistributionData --> makeCdbHashForRelation --> makeCdbHash
Greenplum数据库Hash分布——优化器
get_partitioned_policy_from_path
getPolicyForDistributedBy
create_plan_recurse --> create_modifytable_plan --> cdbpathro_plan_create_sri_plan --> DirectDispatchUpdateContentIdsForInsert --> makeCdbHash
create_scan_plan/create_motion_plan/create_bitmap_subplan --> DirectDispatchUpdateContentIdsFromPlan --> GetContentIdsFromPlanForSingleRelation --> makeCdbHashForRelation --> makeCdbHash