mysql索引下推与回表
1.简介:
介绍:索引下推是mysql5.6版本的新特性
方法:就是把服务层查询工作下推到引擎层去处理
作用:它能减少回表查询次数,提高查询效率,减少io的开销
回表:使用非聚簇索引进行查找数据时,需要根据主键值去聚簇索引中再查找一遍完整的用户记录,这个过程叫做回表.
聚簇索引和非聚簇索引的区别:聚簇索引可以直接找到数据,非聚簇索引先找到聚簇索引,在通过聚簇索引找数据
2.MySQL架构图
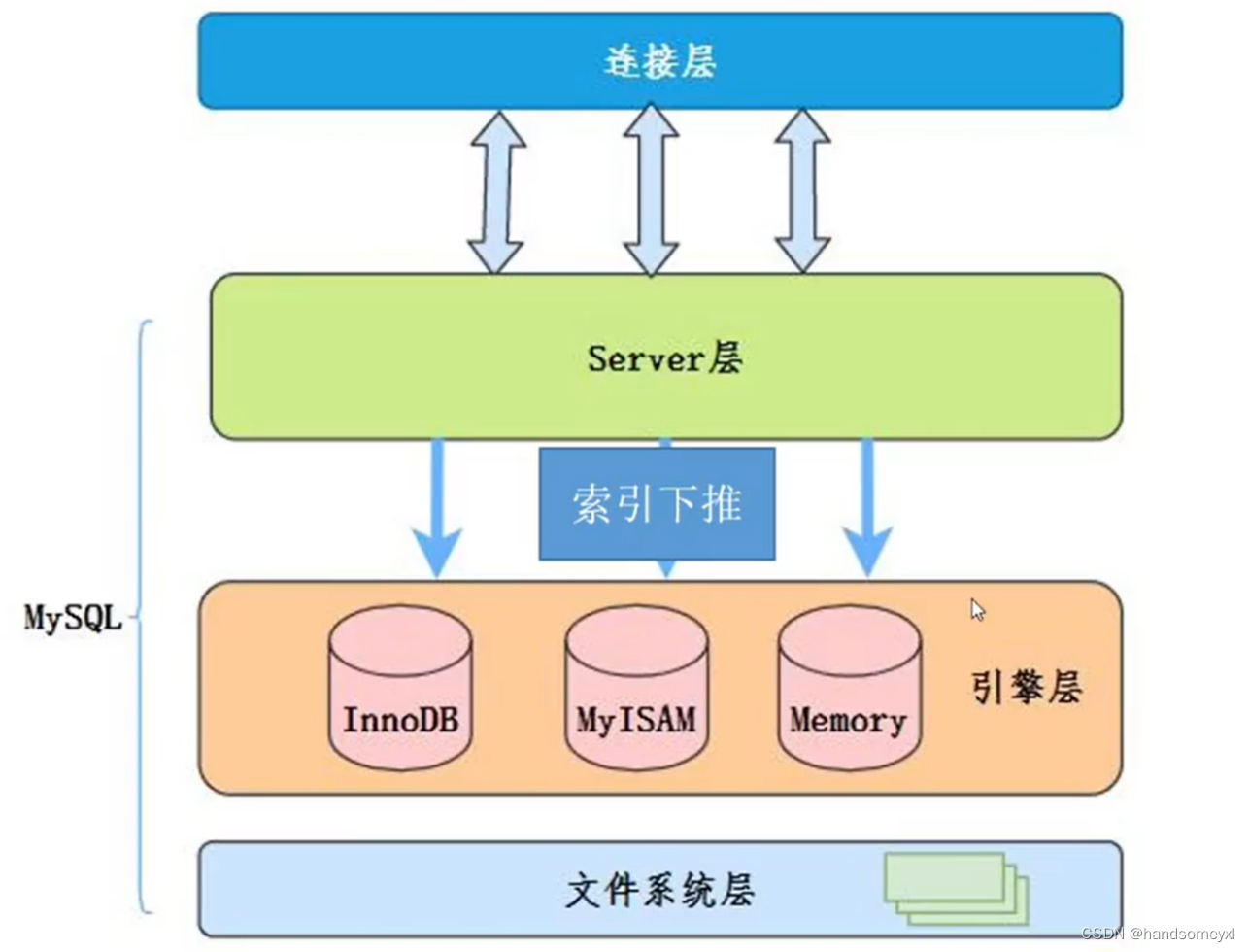
以前是在Service层的工作交给了引擎层
3.举例

sql语句:
创建索引:create index idx_name_age on user(name,age);
查询语句:select * from user where name like ‘张’ and age=10;
1)没有使用索引下推

解释:存储引擎读取索引记录 ,根据索引中的主键值,并读取完整的行记录。存储引擎把记录交给Service层去检测该记录是否满足where条件
这样我们就会发现我们的第二次回表查询张飞的这条记录是多余的
问:没有使用索引下推为什么age会在server层 ,不是建立了(name,age)索引了吗?
答:最左匹配原则,name是like并且百分号在右边,因此当前的联合索引实际上只有name会生效,如果想要对age进行过滤就需要回表将行数据从聚集索引中查出来,放到service层再对其进行过滤
2)使用索引下推

解释:判断条件部分能否用索引的列来检查,条件不满足就处理下一行记录。把原来在Service层的工作放到了引擎层中去,这样就减少了回表的次数,提高了效率
大家可以执行一下以下sql语句:
EXPLAIN SELECT * FROM USER WHERE NAME LIKE '张' AND age=10

希望文章对你有帮助,有问题私信一起交流!