GAN Step By Step -- Step1 GAN介绍
GAN Step By Step

心血来潮
GSBS,顾名思义,我希望我自己能够一步一步的学习GAN。GAN 又名 生成对抗网络,是最近几年很热门的一种无监督算法,他能生成出非常逼真的照片,图像甚至视频。GAN是一个图像的全新的领域,从2014的GAN的发展现在,在计算机视觉中扮演这越来越重要的角色,并且到每年都能产出各色各样的东西,GAN的理论和发展都蛮多的。我感觉最近有很多人都在学习GAN,但是国内可能缺少比较多的GAN的理论及其实现,所以我也想着和大家一起学习,并且提供主流框架下 pytorch,tensorflow,keras 的一些实现教学。
在一个2016年的研讨会,杨立昆描述生成式对抗网络是“机器学习这二十年来最酷的想法”。
Step1 GAN介绍
GAN
Generative Adversarial Network
Authors
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio
Abstract
We propose a new framework for estimating generative models via an adversarial process, in which we simultaneously train two models: a generative model G that captures the data distribution, and a discriminative model D that estimates the probability that a sample came from the training data rather than G. The training procedure for G is to maximize the probability of D making a mistake. This framework corresponds to a minimax two-player game. In the space of arbitrary functions G and D, a unique solution exists, with G recovering the training data distribution and D equal to 1/2 everywhere. In the case where G and D are defined by multilayer perceptrons, the entire system can be trained with backpropagation. There is no need for any Markov chains or unrolled approximate inference networks during either training or generation of samples. Experiments demonstrate the potential of the framework through qualitative and quantitative evaluation of the generated samples.
[Paper]

我们先来看一段wikipedia上对GAN的定义:
生成对抗网络(英语:Generative Adversarial Network,简称GAN)是非监督式学习的一种方法,通过让两个神经网络相互博弈的方式进行学习。该方法由伊恩·古德费洛等人于2014年提出。[1]
生成对抗网络由一个生成网络与一个判别网络组成。生成网络从潜在空间(latent space)中随机采样作为输入,其输出结果需要尽量模仿训练集中的真实样本。判别网络的输入则为真实样本或生成网络的输出,其目的是将生成网络的输出从真实样本中尽可能分辨出来。而生成网络则要尽可能地欺骗判别网络。两个网络相互对抗、不断调整参数,最终目的是使判别网络无法判断生成网络的输出结果是否真实。[2][1][3]
生成对抗网络常用于生成以假乱真的图片。[4]此外,该方法还被用于生成视频[5]、三维物体模型[6]等。
其实我们简单的来说,GAN就是将一个随机变量的分布映射到我们数据集的分布中了,我们也可以更加直观的看下图
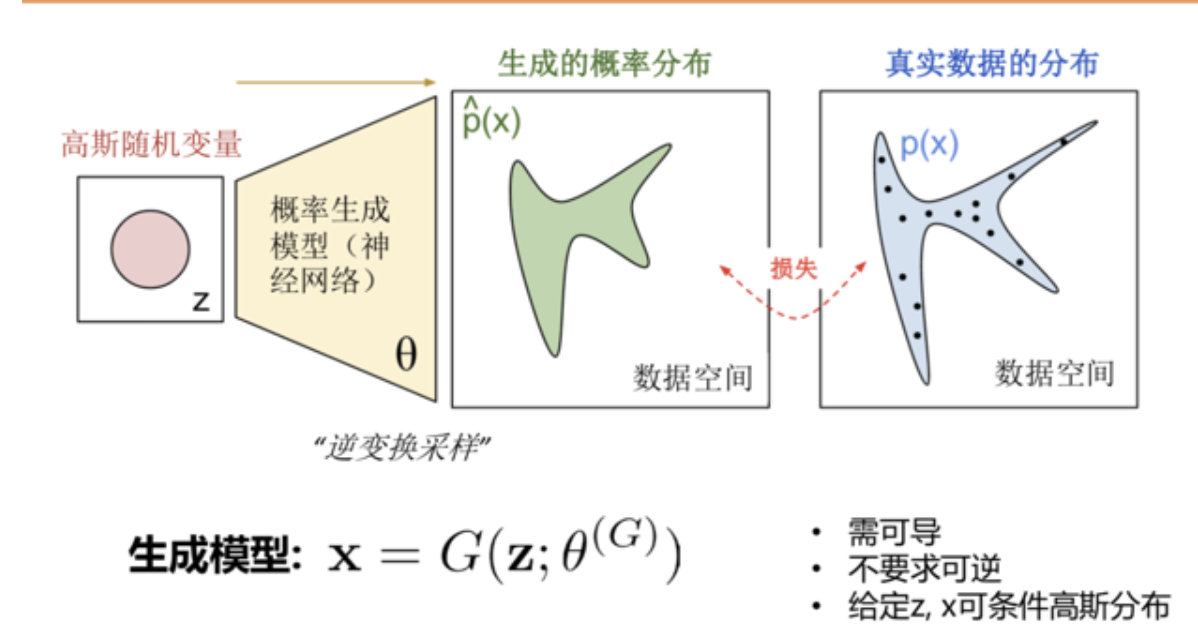
简单的来说,就给定一个噪声z的输入,通过生成器的变换把噪声的概率分布空间尽可能的去拟合真实数据的分布空间.
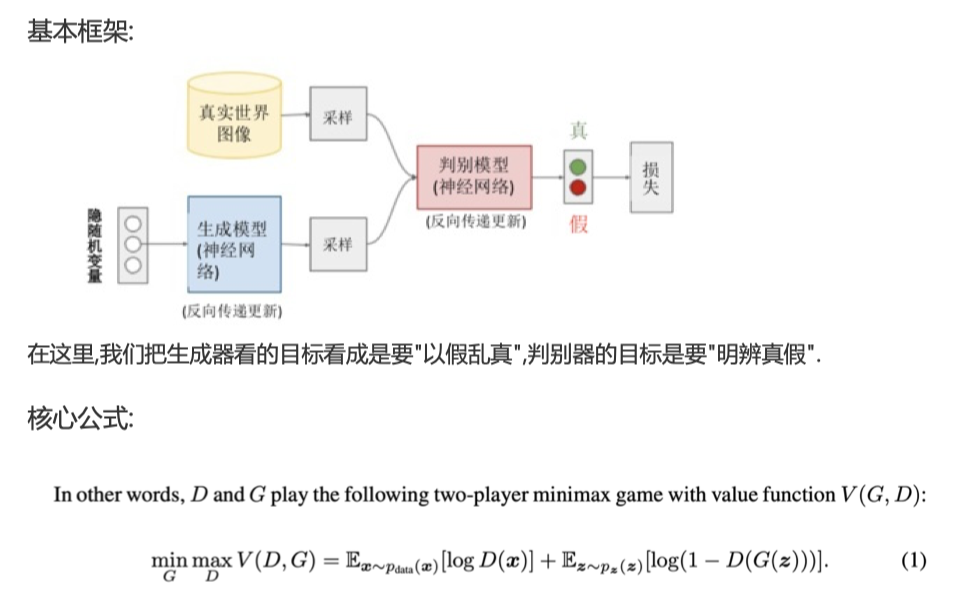
基本框架
我们也可以给一个基本框架,在这里,我们把生成器看的目标看成是要"以假乱真",判别器的目标是要"明辨真假".
大白话版本
知乎上有一个很不错的解释,大家应该都能理解:
假设一个城市治安混乱,很快,这个城市里就会出现无数的小偷。在这些小偷中,有的可能是盗窃高手,有的可能毫无技术可言。假如这个城市开始整饬其治安,突然开展一场打击犯罪的「运动」,警察们开始恢复城市中的巡逻,很快,一批「学艺不精」的小偷就被捉住了。之所以捉住的是那些没有技术含量的小偷,是因为警察们的技术也不行了,在捉住一批低端小偷后,城市的治安水平变得怎样倒还不好说,但很明显,城市里小偷们的平均水平已经大大提高了。

警察们开始继续训练自己的破案技术,开始抓住那些越来越狡猾的小偷。随着这些职业惯犯们的落网,警察们也练就了特别的本事,他们能很快能从一群人中发现可疑人员,于是上前盘查,并最终逮捕嫌犯;小偷们的日子也不好过了,因为警察们的水平大大提高,如果还想以前那样表现得鬼鬼祟祟,那么很快就会被警察捉住。
为了避免被捕,小偷们努力表现得不那么「可疑」,而魔高一尺、道高一丈,警察也在不断提高自己的水平,争取将小偷和无辜的普通群众区分开。随着警察和小偷之间的这种「交流」与「切磋」,小偷们都变得非常谨慎,他们有着极高的偷窃技巧,表现得跟普通群众一模一样,而警察们都练就了「火眼金睛」,一旦发现可疑人员,就能马上发现并及时控制——最终,我们同时得到了最强的小偷和最强的警察。

非大白话版本
生成对抗网络(GAN)由2个重要的部分构成:
- 生成器(Generator):通过机器生成数据(大部分情况下是图像),目的是“骗过”判别器
- 判别器(Discriminator):判断这张图像是真实的还是机器生成的,目的是找出生成器做的“假数据”

下面详细介绍一下过程:
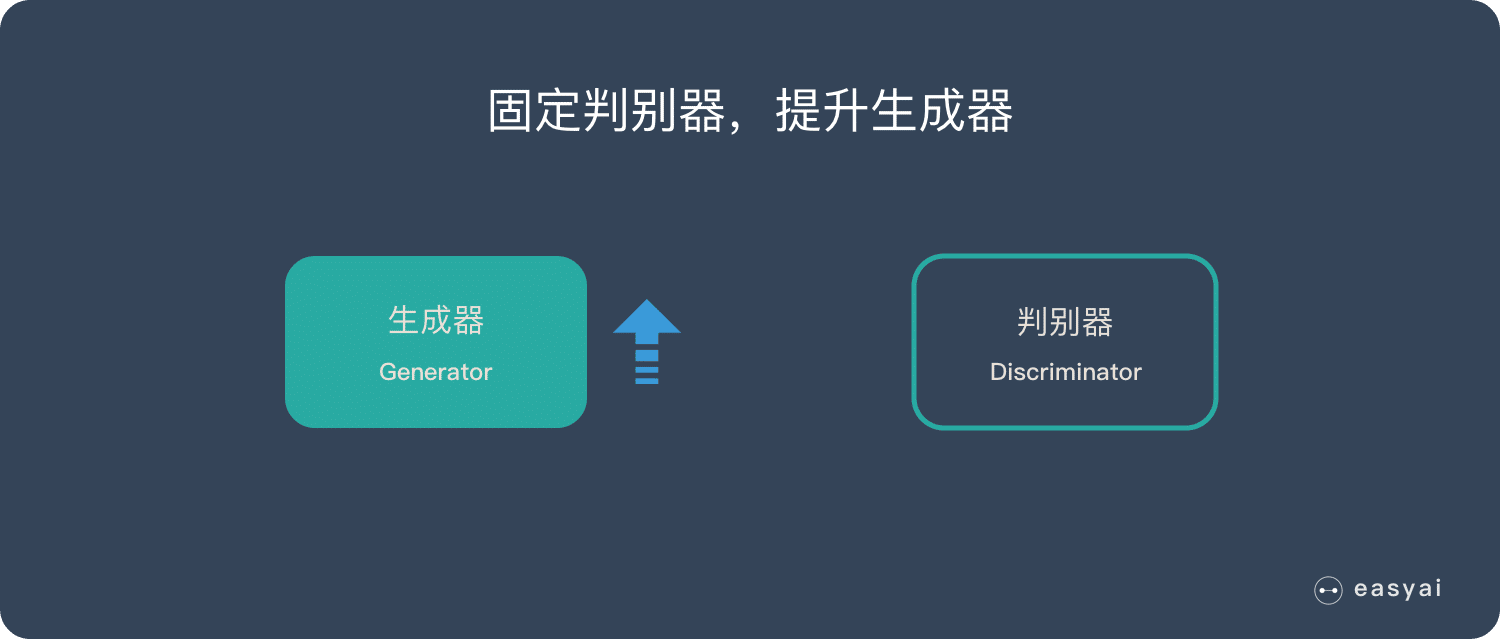
第一阶段:固定「判别器D」,训练「生成器G」
我们使用一个还 OK 判别器,让一个「生成器G」不断生成“假数据”,然后给这个「判别器D」去判断。
一开始,「生成器G」还很弱,所以很容易被揪出来。
但是随着不断的训练,「生成器G」技能不断提升,最终骗过了「判别器D」。
到了这个时候,「判别器D」基本属于瞎猜的状态,判断是否为假数据的概率为50%。
第二阶段:固定「生成器G」,训练「判别器D」
当通过了第一阶段,继续训练「生成器G」就没有意义了。这个时候我们固定「生成器G」,然后开始训练「判别器D」。
「判别器D」通过不断训练,提高了自己的鉴别能力,最终他可以准确的判断出所有的假图片。
到了这个时候,「生成器G」已经无法骗过「判别器D」。

循环阶段一和阶段二
通过不断的循环,「生成器G」和「判别器D」的能力都越来越强。
最终我们得到了一个效果非常好的「生成器G」,我们就可以用它来生成我们想要的图片了。
下面的实际应用部分会展示很多“惊艳”的案例。
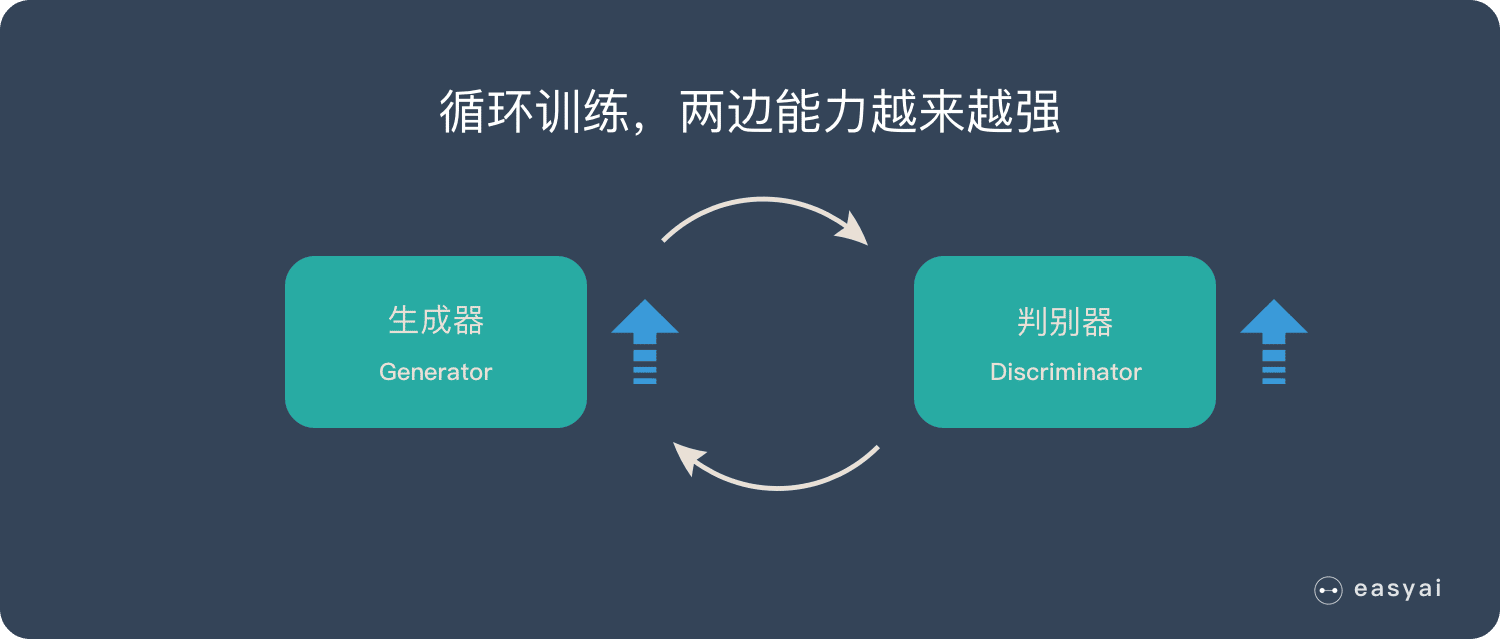
其实在这里,可能有个小问题,到底是先训练生成器,还是先训练判别器,其实我仔细查看了一下论文,论文给的范式是先训练判别器,再对生成器进行训练。这两者具体的不同,我感觉也是有点奇怪,我在实际训练的时候,这两种都能得到结果,可能先训练生成器的时候,损失波动会比先训练判别器大,在我当前的实验结果看来,可能是先训练判别器是更稳定的。不过对于GAN来说,稳定是什么,他不知道
不过我也不知道,为什么一些代码中给的是先训练生成器哈哈,如果大家明白,也可以给我一个回答。
简单的代码实现
第一部分是生成,第二部分是对抗。简单来说,就是有一个生成网络和一个判别网络,通过训练让两个网络相互竞争,生成网络来生成假的数据,对抗网络通过判别器去判别真伪,最后希望生成器生成的数据能够以假乱真。
可以用这个图来简单的看一看这两个过程

通过前面我们知道生成对抗网络有两个部分构成,一个是生成网络,一个是对抗网络,我们首先写一个简单版本的网络结构,生成网络和对抗网络都是简单的多层神经网络
让我们用MNIST手写数字数据集探索一个具体的例子:

我们将让Generator创建新的图像,如MNIST数据集中的图像,它取自现实世界。当从真实的MNIST数据集中显示实例时,Discriminator的目标是将它们识别为真实的。
同时,Generator正在创建传递给Discriminator的新图像。它是这样做的,希望它们也将被认为是真实的,即使它们是假的。Generator的目标是生成可通过的手写数字,以便在不被捕获的情况下进行说谎。Discriminator的目标是将来自Generator的图像分类为假的。
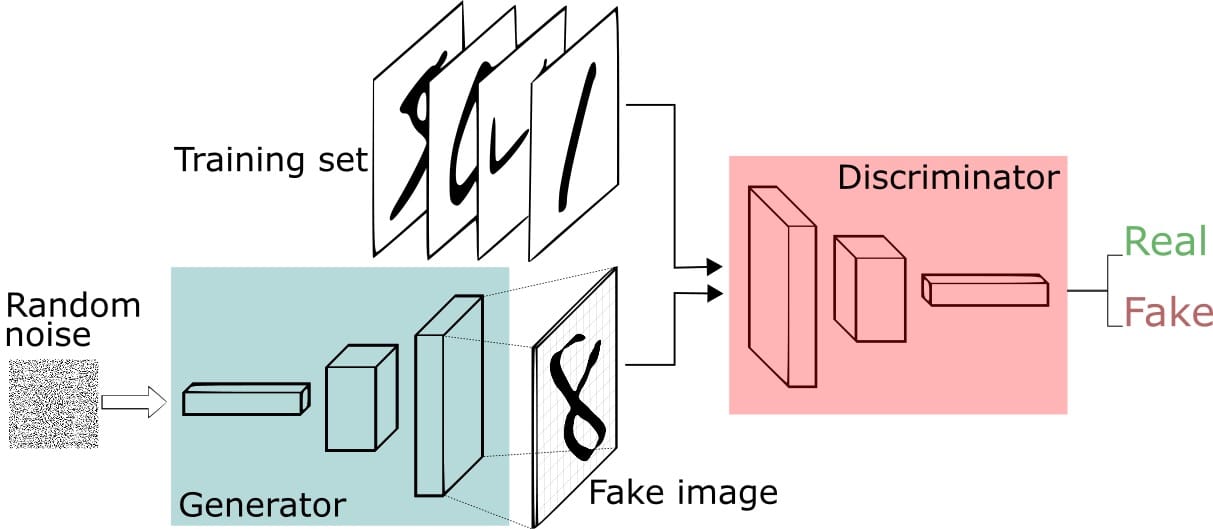
所以,如果我们需要完成一个生成对抗网络,我们需要一个生成器和判别器
判别器 Discriminator
判别网络的结构非常简单,就是一个二分类器,结构如下:
- 全连接(784 -> 1024)
- leakyrelu, α \alpha α 是 0.2
- 全连接(1024 -> 512)
- leakyrelu, α \alpha α 是 0.2
- 全连接(512 -> 256)
- leakyrelu, α \alpha α 是 0.2
- 全连接(256 -> 1)
- Sigmoid
其中 leakyrelu 是指 f(x) = max( α \alpha α x, x)
我们判别网络实际上就是一个二分类器,我们需要判断我们的图片是真还是假
class discriminator(nn.Module):
def __init__(self,input_size):
super(discriminator,self).__init__()
self.dis = nn.Sequential(
nn.Linear(input_size, 1024),
nn.LeakyReLU(0.2),
nn.Dropout(0.3),
nn.Linear(1024, 512),
nn.LeakyReLU(0.2),
nn.Dropout(0.3),
nn.Linear(512, 256),
nn.LeakyReLU(0.2),
nn.Dropout(0.3),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self,x):
out = self.dis(x)
return out
生成器 Generator
接下来我们看看生成网络,生成网络的结构也很简单,就是根据一个随机噪声生成一个和数据维度一样的张量,结构如下:
- 全连接(噪音维度 -> 256)
- leakyrelu, α \alpha α 是 0.2
- 全连接(256 -> 512)
- leakyrelu, α \alpha α 是 0.2
- 全连接(512 -> 1024)
- leakyrelu, α \alpha α 是 0.2
- 全连接(1024 -> 784)
- tanh 将数据裁剪到 -1 ~ 1 之间
class generator(nn.Module):
def __init__(self, noise_dim):
super(generator,self).__init__()
self.gen = nn.Sequential(
nn.Linear(noise_dim, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 512),
nn.LeakyReLU(0.2),
nn.Linear(512, 1024),
nn.LeakyReLU(0.2),
nn.Linear(1024, 784),
nn.Tanh()
)
def forward(self, x):
out = self.gen(x)
return out
超参数设置
对于对抗网络,相当于二分类问题,将真的判别为真的,假的判别为假的,作为辅助,可以参考一下论文中公式
ℓ
D
=
E
x
∼
p
data
[
log
D
(
x
)
]
+
E
z
∼
p
(
z
)
[
log
(
1
−
D
(
G
(
z
)
)
)
]
\ell_D = \mathbb{E}_{x \sim p_\text{data}}\left[\log D(x)\right] + \mathbb{E}_{z \sim p(z)}\left[\log \left(1-D(G(z))\right)\right]
ℓD=Ex∼pdata[logD(x)]+Ez∼p(z)[log(1−D(G(z)))]
而对于生成网络,需要去骗过对抗网络,也就是将假的也判断为真的,作为辅助,可以参考一下论文中公式
ℓ
G
=
E
z
∼
p
(
z
)
[
log
D
(
G
(
z
)
)
]
\ell_G = \mathbb{E}_{z \sim p(z)}\left[\log D(G(z))\right]
ℓG=Ez∼p(z)[logD(G(z))]
如果你还记得前面的二分类 loss,那么你就会发现上面这两个公式就是二分类 loss
b
c
e
(
s
,
y
)
=
y
∗
log
(
s
)
+
(
1
−
y
)
∗
log
(
1
−
s
)
bce(s, y) = y * \log(s) + (1 - y) * \log(1 - s)
bce(s,y)=y∗log(s)+(1−y)∗log(1−s)
如果我们把 D(x) 看成真实数据的分类得分,那么 D(G(z)) 就是假数据的分类得分,所以上面判别器的 loss 就是将真实数据的得分判断为 1,假的数据的得分判断为 0,而生成器的 loss 就是将假的数据判断为 1
criterion = nn.BCELoss()
d_optimizer = torch.optim.Adam(D.parameters(), lr=3e-4, betas=(0.5, 0.999))
g_optimizer = torch.optim.Adam(G.parameters(), lr=3e-4, betas=(0.5, 0.999))
训练网络生成图片
d_losses = []
g_losses = []
iter_count = 0
for i in range(nepochs):
for img,_ in train_loader:
num_img = img.shape[0] # 图片的数量
real_img = img.view(num_img,-1)
real_img = real_img.to(device) # 真实图片
real_label = Variable(torch.ones(num_img,1)).to(device) # 随机得到单位张量作为真实标签 1
fake_label = Variable(torch.zeros(num_img,1)).to(device) # 随机得到零张量作为假标签 0
real_out = D(real_img) # 判别真实图片
# print(real_out.shape)
d_loss_real = criterion(real_out,real_label) # 真实图片的损失
real_scores = real_out
z = torch.randn(num_img, NOISE).to(device) # 随机生成z NOISE造成的数据
fake_img = G(z) # 生成假图片
fake_out = D(fake_img) # 得到D(G(z))
d_loss_fake = criterion(fake_out,fake_label) # log(1-D(G(z)))
fake_scores = fake_out
d_loss = d_loss_real + d_loss_fake # 总的损失 x-logD(x) + z-log(1-D(G(z)))
d_optimizer.zero_grad() # 梯度归0
d_loss.backward() # 反向传播
d_optimizer.step() # 更新生成网络的参数
z = torch.randn(num_img, NOISE).to(device) # 随机生成z NOISE造成的数据
fake_img = G(z) # 生成图片
output = D(fake_img) # 经过判别器得到结果
g_loss = criterion(output, real_label) # 得到假的图片和真实图片的label的loss log(D(G(z)))
g_optimizer.zero_grad() # 归0梯度
g_loss.backward() # 反向传播
g_optimizer.step() # 更新生成网络的参数
if (iter_count % 250 == 0):
# display.clear_output(True)
print('Iter: {}, D: {:.4}, G:{:.4}'.format(iter_count, d_loss.data, g_loss.data))
d_losses.append(d_loss),g_losses.append(g_loss)
imgs_numpy = deprocess_img(fake_img.data.cpu().numpy())
show_images(imgs_numpy[0:16])
plt.savefig("images/%d.png" % iter_count) # 每250次保存一次图片
plt.show()
print()
iter_count += 1
训练的时候,我们先训练dloss,dloss由真实世界图片和生成图片以及其标签进行训练。
在训练判别器的时候,真实世界图片对应真实的标签real,生成的图片对应fake标签,也就是让判别器"明辨真假"的过程。
在训练生成器的时候,我们输入高斯噪声和ground truths,等于是告诉生成对抗网络,我给你一个"假的"图片,但是是"真的"标签,也就是我们让生成器以假乱真的过程。
然后不断的在"明辨真假"和"以假乱真"的两个过程不断迭代训练,最终,生成器可以很好的"以假乱真",判别器可以很好的"明辨真假"。当我们把生成器的图片给"人"看的时候,人就会被"以假乱真"了。
训练结果
Iter: 0, D: 1.364, G:0.6648
Iter: 250, D: 1.362, G:0.8941
…
Iter: 93500, D: 1.331, G:0.8405
Iter: 93750, D: 1.303, G:0.7253




我们可以看到,到后面,我们基本可以看到了一个比较好的数字样本图片了,而这些图片都是假的图片,是靠我们的GAN生成出来的,从一开始全是噪声,慢慢的生成这样,还是很不错的,不用迭代了比较长的时间,已经接近以假乱真了。
参考