[DM复习]关联规则挖掘(下)
关联规则挖掘|其他相关概念
第二部分主要介绍在关联规则挖掘中一些其他的概念以及评价指标,Apriori算法及其实现详见上一篇博文[DM复习]Apriori算法-国会投票记录关联规则挖掘(上)
一.频繁项集的紧凑表示
说明:之所以提出频繁项集的紧凑表示,是因为事务数据集中找到的频繁项集的数量十分巨大,我们需要从中找到最具有代表性的项集,其可以推导出其他额频繁项集。
1.极大频繁项集
定义:极大频繁项集是那些直接超集都不频繁的频繁项集
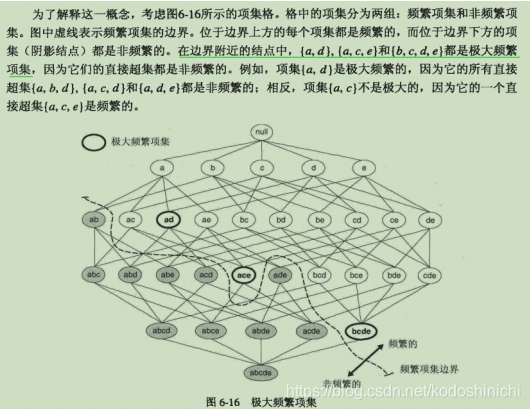
评价与意义
①优点:找到了极大频繁项集就不要枚举出所有频繁项集了
②缺点:极大频繁项集并不包含其子集对应的支持度信息,需要再扫描一遍数据集来确定非极大的频繁项集的支持度。
2.闭频繁项集
定义:
闭项集——某一项集的直接超集都不具有和它本身相同的支持度计数的项集
闭频繁项集——闭项集+频繁项集
性质:
①所有极大频繁项集都是闭项集
理解:极大频繁项集的超集都不是频繁项集,则一个支持度计数≥支持度阈值,另一个支持度计数<支持度阈值。
②非闭项集的支持度都等于它直接超集的最大支持度
理解:根据支持度计数的反单调性和闭项集的不等式夹逼可以得到等式关系。
意义:提出闭频繁项集就是为了弥补前面所说的极大频繁项集不包含其子频繁项集的支持度信息的问题
利用闭频繁项集来计算其子集的支持度

二.产生频繁项集的其他方法
说明:Apriori算法虽然已经根据先验原理在产生频繁项集的时候对搜索空间进行了剪枝。但是依然会有不可低估的I/O开销。
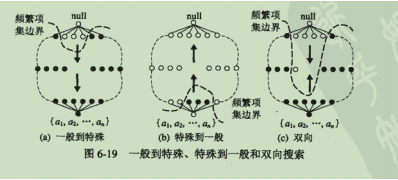
- 项集格遍历的方式
一般到特殊(Apriori)
特殊到一般
双向遍历
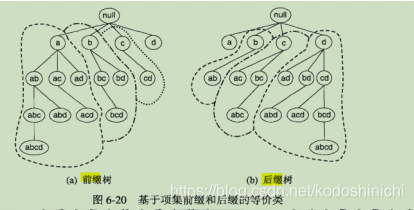
- 等价类划分的方式
基于项集前缀的前缀树
基于项集后缀的后缀树
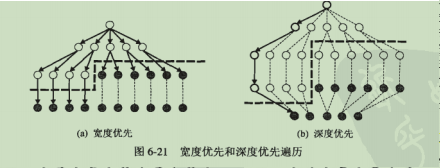
- 搜索方式
宽度优先(Apriori)
发现所有1-频繁项集,之后再去搜寻所有2-频繁项集,直到没有in的频繁项集产生为止
深度优先
从图中某一个节点开始,计算支持度计数并判断是否频繁,如果是则一直往下进行拓展,直到到达一个非频繁节点,再回溯到下一个分支继续搜索。
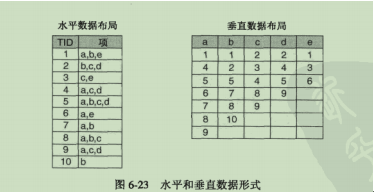
- 事务数据集的表示
水平数据布局(Apriori)
每一行表示一个事务
垂直数据布局
每一列为一个数据项,针对每一个项有一个事务列表,垂直模式方便查找某一个事务的支持度
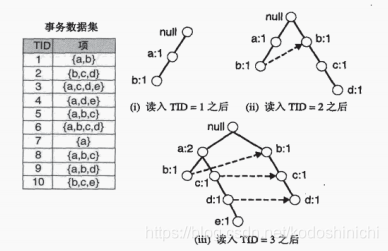
三.FP增长算法
FP增长算法和Apriori算法的“产生-测试”范型不同,它是使用一种称作FP树的紧凑数据结构组织数据,并直接从该结构中提取频繁项集。
FP增长算法的压缩效果比较好的原因是:其通过逐个读入事务,并把每个事务映射到FP树中的一条路径来构造,因为事务之间可能会存在重叠的项,这样就可以节省一些空间。
1.FP树表示法

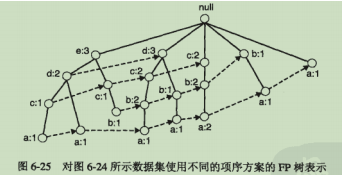
2.FP增长算法的频繁项集产生
核心宗旨:将频繁项集产生的问题分解成多个子问题,其中每个子问题分别涉及发现以e,d,c,b和a结尾的频繁项集,接下来以发现所有以e结尾的频繁项集的任务,设支持度阈值为2.
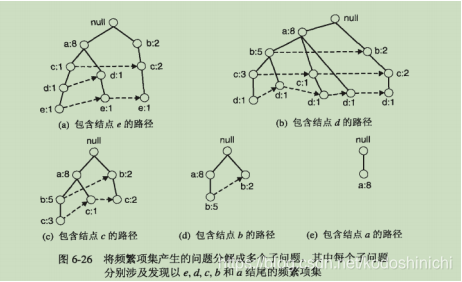
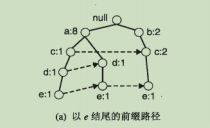
- 收集FP树中包含节点e的所有路径,这些初始的路径称为前缀路径。
- 根据节点标识的数字以及节点e之间的关联将所有数字累加计算e的支持度计数。若最小支持度,≥支持度阈值则认为是频繁项集。
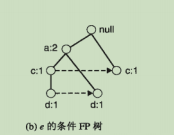
- 因为{e}是频繁的,所以可以在此基础上继续发现以de,ce,be,ae结尾的频繁项集的子问题。首先需要将e的前缀路径转化为条件FP树
①更新前缀路径上的支持度计数,有些计数并不是包含e的项的计数
②调整完计数之后,删除节点e(因为后续进行支持度统计不需要再用到e),且根据支持度阈值再删除那些不频繁的项。
- 使用条件FP树进行子问题发现,下面以发现de结尾的频繁项集为例。在FP树中收集d的所有前缀路径,计算所有与d关联的数值之和,得到de的支持度计数,当大于或等于支持阈值的时候,可以再构造de的FP条件树,然后进行ade,cde,bde的频繁项集的发现。

四.模式评估
1.相依表
①相依表的构建与计算
理解:使用相依表进行置信度的计算,本质上就是在计算条件概率

②置信度的误导问题
在这个规则下计算置信度,那么实质是计算一个条件概率,就是联合概率除以单概率;仅仅看数值置信度应该已经大过了阈值,可能会被认为是较好的规则

2.统计独立
在讲述贝叶斯公式的时候,两件事情如果不是独立的,就不能使用乘法公式,而应该使用条件概率公式

3.其他兴趣度量方式
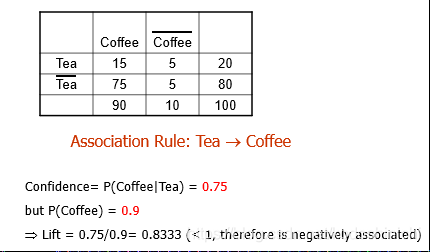
3.1 提升度(Lift)
提升度的计算方式实质上就是在条件概率的基础上考虑了条件事件本身发生的概率。
提升度计算时存在的问题
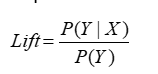
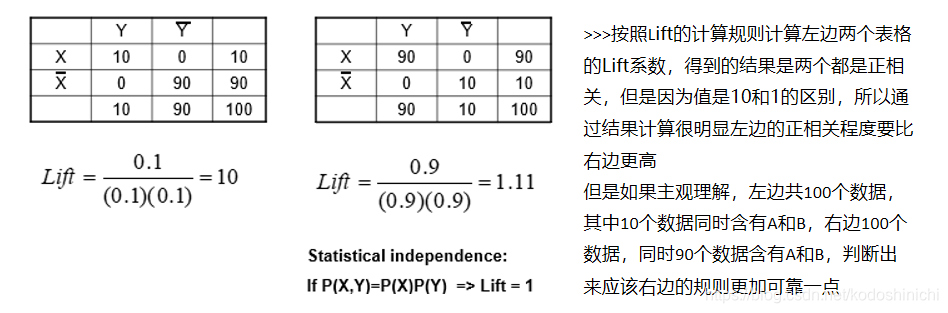
3.2 兴趣度(Interest) 
结合前面的统计独立的相关概念,可以知道当Interest值等于1说明事件相互独立,小于1说明两个变量负相关,大于1则正相关。
3.3. PS和coeffecient
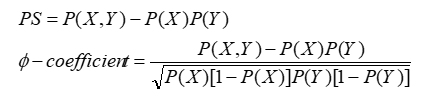
3.4 好的评价指标的原则
3.5 计算指标的一些特性