Linux多路I/O复用入门必读 -- epoll实现原理以及使用方法
提到Linux多路I/O复用,肯定会绕不开epoll。下面就epoll的实现原理以及使用方法做一个讲解。
1.epoll相关基本概念
1.1 阻塞
阻塞是进程调度中重要一环,指进程在执行某个操作时,由于需要等待另外某件事发生而处于等待时的状态。例如,线程在调用read操作是,由于当前没有数据可读,需要等写事件发生之后才能完成read操作,那么写操作发生之前,read操作一直处于等待状态,即阻塞。读写操作一般都是阻塞的,阻塞时该线程不占用CPU的,即这段时间CPU可以去干别的线程的活。
1.2多路I/O复用
多路I/O复用就是指,多个网络I/O操作复用一个单线程,比如在一个线程中监听多个socket。由于单线程中所有的操作都是顺序执行的,如果监听多个socket,那么就只能按照顺序去读/写每个socket,但是读写可能是阻塞的,结果导致效率很低。epoll就是Linux内核为了处理大批量文件描述符而编写的多路I/O复用接口。
1.3 等待队列
进(线)程如果执行某个操作被阻塞了,就会将该进程加入到对应文件的等待队列中。例如,进程A在从socket1读取数据时被阻塞了,进程A就会被加入到socket1的等待队列中,然后socket1有新数据到达可读时,就会唤醒等待队列中的进程A,并将进程A从等待队列中移除。由于Linux中万物皆是文件,可以这么讲,如果文件f1去操作文件f2时被阻塞,文件f1就会被加入到f2的等待队列,以便f2就绪时唤醒f1继续操作。
2.epoll基本数据结构
2.1 epoll的基本使用方法
下面这段代码可以说明,是怎么利用epoll进行多个I/O操作的。
对epoll的使用基本上可以分为3个部分:
1、通过epoll_create创建一个epoll对象
2、通过epoll_ctl加入(修改删除等)需要监听的socket等文件对象
3、通过epoll_wait返回就绪的socket,然后对就绪的socket进行操作
int s = socket(AF_INET, SOCK_STREAM, 0);
bind(s, ...)
listen(s, ...)
int epfd = epoll_create(...); // 1.创建一个epoll对象,可以通过该对象管理多个socket等文件
// epfd相当于是新创建的epoll的id(文件描述符),可以通过epfd来操作这个epoll对象,例如添加、删除socket等。
epoll_ctl(epfd, ...); //2.将所有需要监听的socket添加到epfd中
while(1){
int n = epoll_wait(...) // 2.这里会返回所有就绪的socket
for(接收到数据的socket){
//处理
}
}
2.2 epoll涉及到的主要数据结构
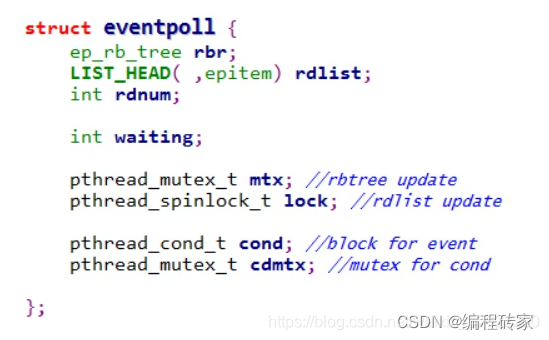
Epoll主要由两个结构体:eventpoll与epitem。Epitem是每一个IO所对应的的事件。比如 epoll_ctl EPOLL_CTL_ADD操作的时候,就需要创建一个epitem。Eventpoll是每一个epoll所对应的的。比如epoll_create 就是创建一个eventpoll。
epitem结构体定义:

eventpoll定义:
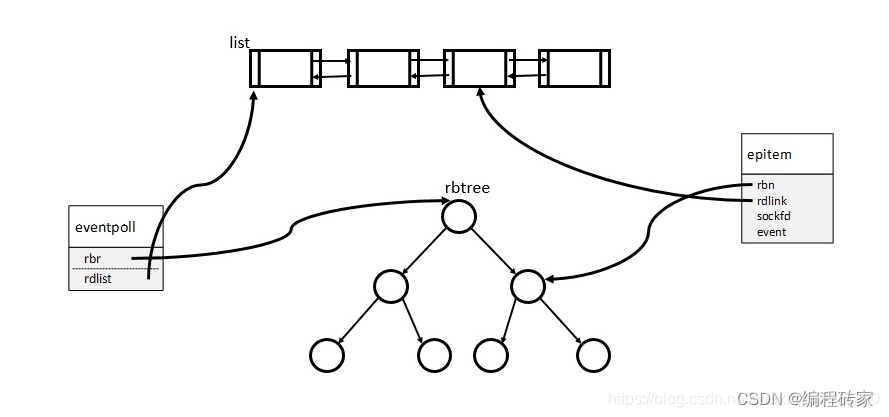
数据结构如下图所示:
用epoll来管理多个I/O事件时涉及到几个基本问题:
(1)I/O事件的储存
eventpoll就是用来管理各种I/O事件的对象,需要将监听的I/O对象加入到eventpoll,为了查找、删除方便,采用红黑树来储存,红黑树根节点为rbr,每个新增一个I/O时间,rbr插入一个epitem类型的节点。
(2)如何将就绪事件返回
这里就需要维护一个就绪列表 – rdlist,rdlist中包含了rbr中处于就绪状态的节点,然后返回rdlist,进程就可以快速访问所有的就绪事件,而不必遍历所有的事件。
(3)当某个事件就绪时,如何加入就绪列表
可以看到事件节点epitem结构体中包含一个rdlink指针,指向就绪列表。我个人认为主要有两个作用:一是事件就绪时,就通过就绪列表的头节点插入到就绪列表中,二是如果红黑树删除某个节点时,自然也是要删除就绪列表中的节点,因为rdlink指向就绪列表,直接将指向的节点删除就OK了
3.epoll为何高效
3.1 slect的原理以及不高效的原因
先看一下select的基本使用方法:
int s = socket(AF_INET, SOCK_STREAM, 0);
bind(s, ...)
listen(s, ...)
int fds[] = 存放需要监听的socket,后面作为参数传给select去遍历
while(1){
int n = select(..., fds, ...) // 遍历所有需要监听的socket
for(int i=0; i < fds.count; i++){
// FD_ISSET判断是否为置位,如果某个socket有数据,对应的bit会置位
if(FD_ISSET(fds[i], ...)){
//fds[i]的数据处理
}
}
}
我个人理解,虽然select可以去监听多个socket,但是本质上还是去遍历所有需要监听的socket,只是用select函数封装了一层。
下面这部分内容直接引用一下Epoll原理解析中的内容:
假如进程A中调用了select函数,去监听sock1、sock2、sock3,首先将进程A从工作队列移除,然后这三个socket的等待队列都会加入进程A,进程A处于阻塞状态。注意这一步,需要监听多少socket,就需要将进程A加入多少个等待队列,由于需要去遍历所有的socket,因此时间话费较大。
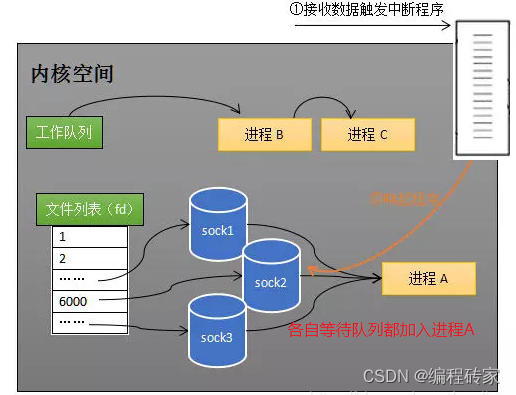
一旦任何一个socket有了数据,就需要将进程A从所有的socket的等待队列移除,并加入到工作队列,进程A得以继续执行。这里也是需要去遍历所有的socket,因此开销也较大。
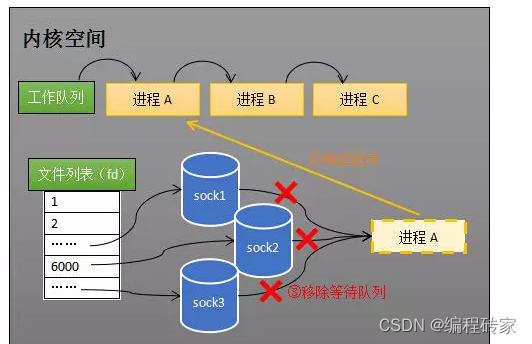
由于其中一个socket有数据到达,进程A被唤醒,重新加入到工作队列。需要注意的是,进程A被唤醒后,只知道有数据到达,但是并不知道哪些socket有数据到达,因此调用select函数之后,为了处理有数据的socket还得再遍历一遍所有的socket。
通过上面的过程分析,select效率较低最要是需要反复遍历所有的socket:
(1)调用select函数,进程阻塞,需要将进程加入到所有socket的等待队列,需要遍历所有的socket;
(2)当有数据到达时,进程被唤醒,需要将进程从所有的socket的等待队列移除,需要遍历所有的socket;
(3)为了处理有数据到达的socket,又得遍历所有的socket。
正是因为遍历开销大,才规定select的最大的监视数量,默认为1024
3.2 epoll的原理
(1)将eventpoll添加到所有需要监听的socket的等待队列
epoll和select有一个本质的不同,那就是epoll扮演了一个中介的角色,进程和socket直接不再是直接交互,而是通过epoll对象进行交互,而select本质上还是遍历各个socket,socket与进程直接交互。
创建一个epoll对象之后,向其中添加需要监听的socket:
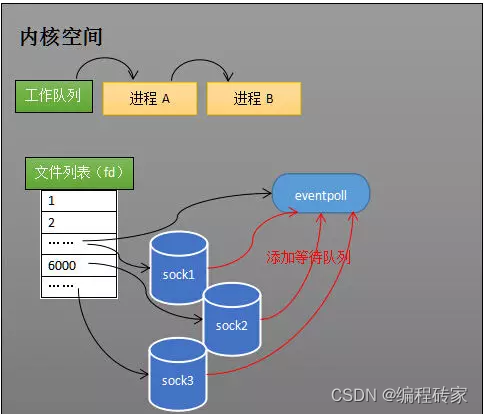
由于epoll扮演了一个中介的角色,进程不再是直接与socket交互,因此socket的等待队列中,添加的是epoll对象eventpoll,而select中是直接将进程添加到socket的等待队列中。这里貌似也要遍历所有的socket才能将eventpoll添加到等待队列中,但是这里只需要添加一遍,需要epoll对象中新加入需要监听的socket时,才需要将eventpoll添加到等待队列,有数据到达时,不会将eventpoll从socket的等待队列移除,而是去维护就绪列表rdlist(不知道这里理解对不对,如有不对,还请指正)。对比一下select,有数据到达是需要遍历所有的socket,将进程移除等待队列,然后阻塞时候又需要将进程添加到等待队列,这里就需要反复的遍历添加或删除。
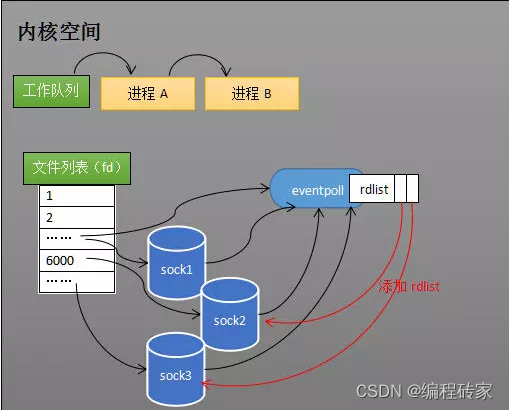
(2)数据到达时维护就绪列表rdlist
当某个socket收到数据之后,中断程序就会将某个socket添加到eventpoll的就绪列表rdlist中。rdlist维护的就是所有有数据到达的socket的列表,因此,如果处理有数据的socket时,也不需要遍历所有的socket了。
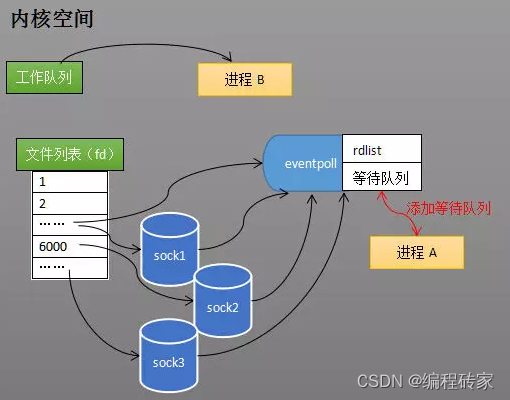
(3)阻塞或唤醒进程
假如进程A运行了到了epoll_wait()函数,eventpoll会将进程A加入到eventpoll的等待队列(不是socket的等待队列),并阻塞进程。
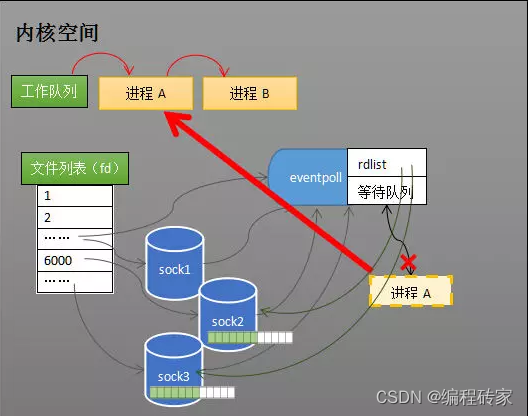
当有socket收到数据时,中断程序一方面修改rdlist,另一方面eventpoll就可以唤醒等待队列的进程A。
3.3 epoll高效的原因
(1)从设计思路上来讲,epoll作为socket与进程之间交互的一个中介,避免了反复将进程从socket的等待队列中删除或添加进去。因此添加或删除需要遍历所有的socket,显得低效。
(2)从返回结果看,select只能告诉进程是否有数据到达,具体哪些socket有数据到达,还需要去遍历。但是eventpoll维护了一个就绪列表rdlist,可以将有数据达到的socket直接返回给进程,避免了去遍历。
(3)从数据结构看,epoll维护监听的文件时,使用了红黑树,查找、删除具有log(N)时间复杂度,效率较高。
【参考文章】
1、Epoll的实现原理
2、Epoll原理解析
3、Linux 底层原理 —— epoll 与多路复用