Hadoop集群配置运行
文章目录
- 前期准备
- 配置JDK环境
- Hadoop安装配置
- hadoop-env.sh
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
- yarn-site.xml
- workers
- Hadoop集群启动
- hdfs格式化
- 启动集群
- 参考
前期准备
下面以三台Ubuntu虚拟机搭建集群。
需要互相ssh能够免密通讯
如果不行,可以参考:Unbuntu使用手机热点创建两台电脑的集群(实现ssh免密通信)
下面需要的软件安装包都放在百度网盘,有需要的自取。
链接:https://pan.baidu.com/s/1rcG1xckk3zmp9BLmf74hsg?pwd=1111
提取码:1111
配置JDK环境
下载jdk8,解压缩:
tar -xxvf jdk1.8.tar.xz
验证文件可用性,java执行: java -version查看结果:进入java所在目录,执行 ./java -version
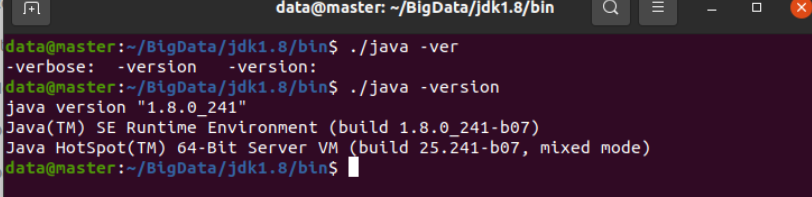
说明验证成功。
然后需要添加到环境变量里:
首先进入用户名的目录

然后编辑 .bashrc 文件
vim .bashrc
按i进行编辑

然后
按ESC
:wq
保存退出
然后运行
. .bashrc
然后命令行输入
java -version

说明配置成功。
Hadoop安装配置
同样先解压文件
tar -zxvf hadoop-3.3.2.tar.gz
然后编辑.bashrc配置环境变量
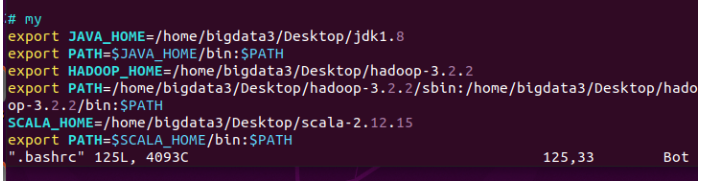
然后同样需要
. .bashrc
然后输入
hadoop

说明配置成功。
然后还有许多文件需要配置:

进入此目录,开始配置文件
hadoop-env.sh
vim hadoop-env.sh
需要在最后加上
export JAVA_HOME=/home/bigdata3/software/jdk1.8
export HADOOP_PID_DIR=/home/bigdata3/software/hadoopData/pids
第一个配置jdk路径
第二个配置日志文件路径
core-site.xml
<configuration>
<!-- 设置dfs副本数,不设置默认是3个 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<!-- 设置secondnamenode的端口 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<!-- 设置dfs副本数,不设置默认是3个 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>master:50070</value>
</property>
<!-- 设置secondnamenode的端口 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
</configuration>
不过dfs.namenode.secondary设置为master:50090是非常不合理的。
但是为了方便就这样了。
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>HADOOP_HOME</name>
<value>/home/bigdata3/software/hadoop-3.2.2</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
最重要的就是第一个配置
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
workers
指定datanode节点,将所有datanode节点域名写入文件,一般是一行一个,所有集群中的节点此文件内容相同。
slave0
slave1
master
Hadoop集群启动
hdfs格式化
要在namenode上执行命令:
hadoop namenode -format
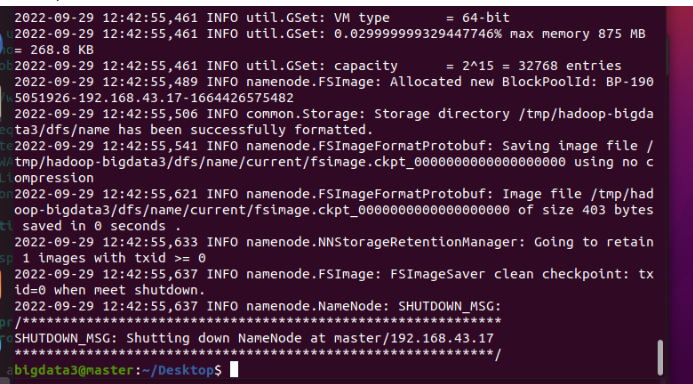
这样说明初始化成功
启动集群
start-all.sh
启动成功可以进行jps验证和web页面验证。
不过队友还没搞完,后面还没搞好。下次来补
参考
大数据上课的笔记。