flink在企业IT架构中如何定位-在选型流批一体技术与大数据架构时的避坑指南
前言
先放出本文的结论:讨论流批一体不该分系统去讨论谁该去负责和拥用这个流批一体,而是应该考虑业务系统要有流批一体架构同时大数据也必须要有流批一体架构。两者都不应该说:这是我独有的法宝。而当遇有特殊场景时又需要共用“一条流”来做流批一体。
落笔这篇文章比较难,写什么呢?写架构设计?这倒不是最重要的,因为一家企业的技术架构只是次要的,而企业架构才是最重要的。企业架构才能决定技术架构。企业架构如果走偏根本也就不用谈什么技术架构了。
对于一家企业来说企业级架构是CIO的责任,CIO是以业务结果为导向的。因此当面临流批一体技术出现时CIO往往会面临:
- 和原有大数据如何定位流批一体技术?
- 是否需要单独搞一套架构?
- 和原有大数据架构是否冲突了、人际关系怎么搞、发生了边界冲突甚至“互抢活”怎么办?
- 以上几点如果成立那么岂不是影响了原有组织架构及人员的稳定性了?出活受到影响怎么办?团队也不稳定了?
作为CIO本身就为业务结果导向而服务和赋能业务的,当然CIO也是企业几大O之一,因此他还需要考虑管理的问题即:著名的“不要把鸡蛋放在一个篮子里,以免一下全打碎”的管理上的问题。说白了就是:万一有人技术太好,他管的东西太多,万一这个人不可控那CIO自己最后不是要“吃土 ”?
因此每当新的技术引入时,如果这个技术沾上了一点本企业内原本己有组织架构的“同名词”时,CIO总会作上述的思考。
反过来,我们的“纯”技术人员也经常因为合理、客观的提议却没想到会触犯到了上述这些点而总是得到一些“模棱两可”或者是“不置可否”、甚至是“天书”一样的指令。苦涩难懂、搞得我们可爱的技术人员身体累倒也不算,还经常“心累”。仔细想想,是不是都是因为你没有想到这些考虑而你的老板却想到了这些考虑?(捂嘴笑)是不是这样的呢?
因此本文将使用TOGAF规范(企业架构设计-而非仅仅只是技术架构)去帮助CIO这类角色彻底了解流批一体到底和大数据是什么关系?也帮助我们的技术人员在本企业己有大数据组织架构时如何合理的提议引入和建立流批一体技术并且不受到抵触。你可以认为它是一个避坑宝典也可以认为它是企业级架构设计思想。
先从什么是企业架构说起
万事开头难!为什么我们先要提一下企业级架构?它和我们技术上的架构到底有什么不一样的地方?
如果你已经读过了TOGAF并且有着超过8-10年实操经验者那么你可以直接跳过这一节。而如果你是一个做的非常棒的“技术架构”但经常会在日常工作中碰到技术架构遇见了非技术可以解决的问题时心累那么我强烈建议你好好阅读一下本节。
我们先来看一下TOGAF企业架构的四大核心目标说明:
- 业务架构,定义了商业策略,管理,组织和关键业务流程。
- 应用架构,这种结构为待配置的个人应用系统提供一个蓝图,从他们的交互,他们的关系到该组织核心的业务流程。
- 数据架构,这个描述一个组织逻辑的和物理的数据资产和数据管理资源的结构。
- 技术架构,它描述了支持核心部署和关键任务应用的软件基础设施。这种软件有时也叫做中间件。
企业级架构师需要考虑的是这么4个点。
看!技术架构只是其中的一小部分。而企业级架构才是我们嘴里一直说的“架构师”的那个真正的“架构师”的函义,架构师真心不是这么简单的。
其实CIO的思考模式就是照着这4个点的。我们把这四个点用非常接地气的“白话”来描述一下,大家就明白为什么CIO的思考模式其实就是TOGAF企业架构四大核心目标了。
业务架构-最核心的点(我们很多技术人员都没有领会)
书面的话:定义了商业策略,管理,组织和关键业务流程。
白话:一个好的IT系统要能对本企业的业务赋能,开发速度要快,不受任何供应商的绑架,可以像模块一样“坏了、烂了”随时替换。要容易内化和容易上手否则维护这套系统的人个个都必须是博士后、高精尖那么企业不要混了。也不能因为某个、某些人的离职或者持骄自傲变得这个技术团队不好管理。我们还要考虑部门间不要“越界”,不要“互相抢活 ”。同时这个系统不能是一个纯技术系统当然它的运行要基于本企业业务逻辑去执行的,是为了本企业的业务所服务的。
应用架构
应用架构不仅仅是指数据流、input/output间的交互,而是假设有10个系统,你把10个系统设想成10个部门。系统间的交互就是部门间的交互。原来那些对接点可能都是“人肉”,现在要变成接口,那么如何考虑这个接口设计?设计时是否有可优化的地方?那么同时你在设计系统时也考虑到把企业原有的“运营流程”给优化了、给提效了呢?这就是IT的斌能。
数据架构
大家有没有听说过,比起一些技术框架或者团队的人员来说企业DB里的数据才是企业IT最金贵的资产?怎么利用好数据、保护好数据?于是才有了什么:灾备、异地备、两地三中心啊等等等。
技术架构
这个就不展开了,太简单了。看。。。技术架构真的很简单,它的简单是一个打双引号的简单,这边我用“简单”是指它不需要去思考第一点和第二点即业务架构和应用架构。
而恰恰这也带出了今天的重点。假设现在你是一个技术架构,你在本企业已经有大数据团队了,你去建议你的CTO或者是你的CIO用流批一体技术。此时你的老板这么回答你:
CIO:这是一个好东西,但是我们的大数据团队作什么呢?另外想一下我们的大数据团队为什么不能做呢?
你:。。。。。。
然后你回去后无言以答,但又总觉得有什么地方感觉不对?这不是抢不抢活的概念而是实际你们企业已经产生了实时计算需求,而这些需求在你之前设计和落地时总是充满了这样、那样的困难。
结合企业架构来看大都企业都会碰到的IT整体架构时的“坑 ”
如我前文所述,分析这个问题你需要放下你的心态、跳脱技术的思维去用TOGAF企业架构来思考你一直来已经碰到的问题。
要知道,对于一个业务型企业来说,所谓高科技这三个字它势必会有这么两个业务结果:
- 由于用了新技术,因此长久来说省钱了- cost saving;
- 由于用了新技术,因此可以给业务带来额外的利润,这边的利润是指的包括:经营收入增长、降本增效、至少30%以上的提效,即-business benefits;
要么有cost saving,要么有business benefits,要知道在商业企业或者是零售企业,no one buy for flexible or advanced。
如果你说要show技术、要炫技术,你可以在家自己搭建各种集群玩儿。在企业内架构就必须是建立在:以业务结果为导向的基础上的架构设计。
于是我们打开传统零售(先进零售模式都是那些大厂,那些我们用手指头都可以数得过来不算在我说的传统零售企业内)的IT系统架构来看,目前市面上的99%的零售厂商,无论巨、大、中、小(除去大厂那些外)都是这么一种通用企业级架构。

没错吧?如果你身在我说的这样的企业内,你看了这个企业架构图会很有感受。特别是“蓝”色的那一大块,一个个“烟囱”一样的孤岛。。。这不是我们本章讨论重点。关键是这个企业架构。
比较明显的是两块绿色区域。不少大型点的零售商超好在近3年内来意识到了数字化转型的重要,好歹已经建立起了一体化的业务交易系统以及一体化大数据系统了。而且不少企业在这方面做的还不错、挺超前的。
我们建立的业务交易系统一般都是目前零售界经常提的“全渠道中台”系统的模式为模板而设计的,然后我们再一步步把原有的数据都抽到大数据中去,利用大数据来完成离线计算、报表等任务用。
大数据这东西出现的特别好玩!说白了就是:世界上在4-5年前除了oracle可以做到集群(10台服务器的计算能力真的可以做到乘以10倍的计算量)没有一个数据库可以做到真正意义上的集群,都只是停留在“打散数据存储读写IO频次”或者是“读写分离,多从库结构”,而不具备“集群运算”能力。
那么oracle集群特别的贵,贵到它按照cpu的核数、每增加一核来和企业算钱,如果经历过的同学真的知道我在说什么意思。如果你家的企业真的都要用oracle集群。。。那么你企业真的有10位数的投资每年投在db上那么这个事也就变得简单多了,我们也就不需要再提什么大数据了。
正是因为哪有企业这么烧钱的,因此才有了后来的大数据。
所以,大数据在刚开始应用时对于传统企业解决的就是原来需要oracle超大集群才能做到的那些BI、报表和分析,它是离线计算或者T+1...T+n计算的。
各位记得:传统企业很少有一次性把大数据一整 套技能栈全部投资、待养成熟、到位后再开始做业务的。都是“切碎”成了几年的零碎,然后以小步快步、不断叠代来进行的。
因此我们按照上面的这个企业级架构,才有了大数据团队和业务系统团队的业务架构如下所示。
大数据在传统企业内的定位
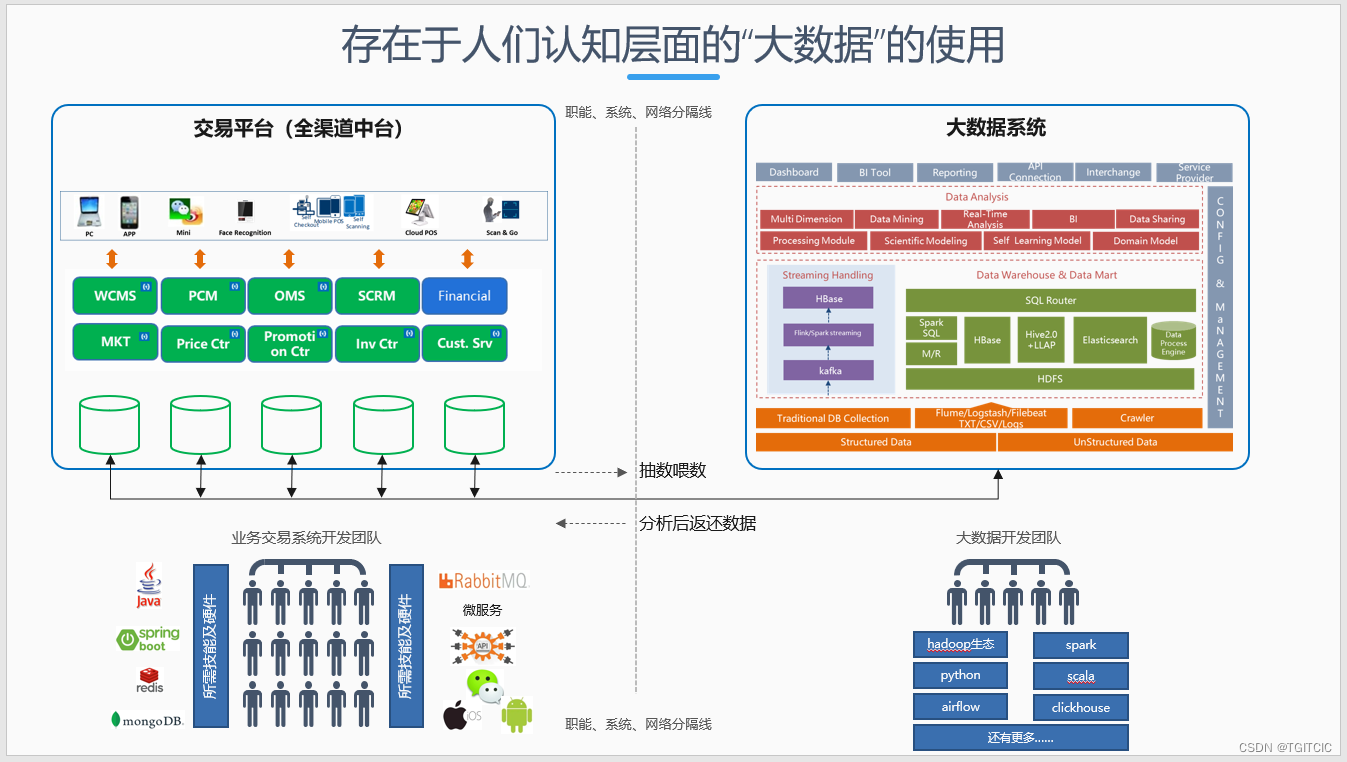
根据上文所述:传统企业很少有一次性把大数据一整 套技能栈全部投资、待养成熟、到位后再开始做业务的。都是“切碎”成了几年的零碎,然后以小步快步、不断叠代来进行的。
因此我们可以看到,对于传统零售企业直接真金白银带来流量的一定先是“线上业务系统”,对于大数据团队一开始是解决“我不要用恶贵的oracle集群,而用开源的大数据先解决我的bi报表、离线分析”问题。
企业架构的最核心目标是:业务架构,而业务架构才决定了:以业务结果为导向的“组织结构”。
看!
对不对,你的企业也是这样的,没说错吧?
哦。。。于是我们开始看业务开发团队的要求:
- 嗯。。。这个也要会那个也要会,技术栈一堆,但其实也不算太难,只是需要多点“猿”,然后看似技术栈用了不少但面对千、万级并发交易场景时又一个不能少。
- 呣。。。大数据呢我们先按照离线计算需求,那么大数据招来的人就先按照大数据离线报表、分析能力去招好了,一步步来。
但是。。。。。。
一切平稳了一段时间,可能短的话你所在的企业在一年后。。。快的话在两年内,你就会收到了这样的需求了。
实时计算类需求被提出后给现有企业架构带来的冲击
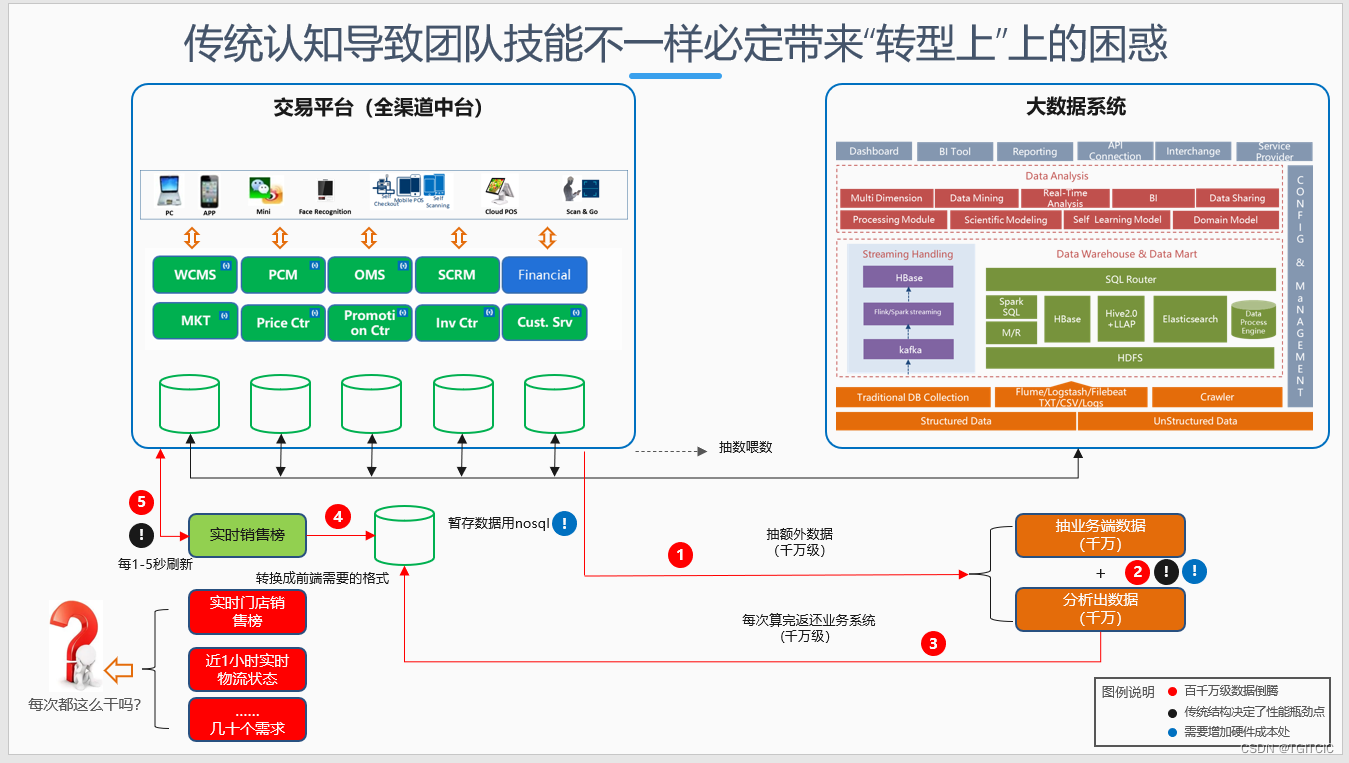
一般传统企业的市场部、电商部是业务部门,这几个部门由于负责着公司经营流水、现金流KPI,因此他们说出的需求会比较有“力道”。当你的会员超过了百万、订单日超过万时这种需求一定会到来,如:
- EC部门说:我想要在手机上做一个门店排名,实时变化,每秒钟刷一下,数值变化在5秒内;
- EC部门说:我想要在手机上把原来的这个“推荐商品”根据近10分钟内的下单变化在首页实时展示爆品情况;
- EC部门说:我要根据客户在直播室的弹幕,收集这些弹幕把说“好吃”的那些品统计出来,在内部做一个“大屏”,让运营部门可以看到这些实时变化;
- EC部门说:我要看当前所有订单配送情况,每5秒刷新一下这些业务维度:用户下单、骑手接单、骑手配送中、配送超时这些个业务状态。把这样的东西做成柱状图、饼图显示在公司内部每个办公室天花板上悬挂的46寸电视屏上;
于是我们大都企业、技术或者是BA、产品经理本能的想到了“大数据”部门去实现。然后就去找大数据部门提需求了。
经过数天的需求讨论、分析,方案做出来了然后大数据部门也能给业务系统算得出这样东西来,于是大数据和业务交易系统间的交互就是如下所述:
- 反正大数据每天从业务部门抽千万(没错,会员过百万日订单过万,每天历史说千万级别那是算少的)级别数据过来;
- 然后业务系统那的微信、APP只要做成每5秒自己刷新然后发过来一个请求到大数据;
- 大数据这根据请求不同,在后台用20台、30台hadoop生态技术去。。。算;
- 算完后发觉:哎呀。。。这个每5秒在千万级数据里算一下结果,现有大数据就算有30台机器也吃不消啊?能不能60分钟一刷新呢?
- EC部门一看一想:哎,大数据部门也只有一个,大数据手上也只有现有这点硬件。我这个需求虽然说可以带来转化率但这个事是需要需求落地后才看得到的,如果单纯的追求5秒内一刷新,我把大数据那的成本搞了涨个30%,50%的我也说不过去啊?这么一想,忍忍吧,60分钟就60分钟;
- 然后大数据那拿到了更新版需求,好啊,这60分钟,但是回去一盘手里的资源,每60分钟前端现在每秒在7,000并发,我的天啊,这也受不了啊。要不这样吧我找到交易系统负责人:这样吧,我们可以算,但是我们是在千万级数据里抽取、转换来算的。而在小程序、APP上显示这个显示格式和我们的计算格式间还存在:去重、聚合。要不我们把算完的结果给你们再传过去,你们拿到这计算完的结果再转成你们在小程序、APP上显示时需要的格式吧?
- 于是双方一拍即合、于是就开干了。干完后发觉业务系统和大数据间传数据和拿结果为:千万级数据经过了两次跨网段的交互。业务系统再要基于最后一次千万级数据的返还基础上再来一次有千万级数据参与计算:去重、合并,再考虑把第三次千万级数据转换成了小程序、APP上最终要显示的结果塞到Redis里以应对每秒千~万级的并发访问流量;
好家伙,我们可以看到:
- 图上那些红点处,都是千万级别数据交互的数据流;
- 黑点处,其实都存在着系统性能瓶劲,就算大数据这通过历史算出来的结果输出给中台可是实际是业务系统这为了显示走的是:前端+Redis缓存里取结果,因此业务系统这才要又再要做一次数据结果的转换;
- 正是由于这些黑点的存在,那么又不能影响业务部门要求的“实时性”,怎么办?那么就变成了“业务系统也需要增加硬件”+“大数据处也需要增加硬件”,这就是蓝点处标记出来的原因;
最终这个事落地了、硬件也加了。然后更大的坑发生了。
每天这个数据是积累的、每次不仅仅只是显示这个数据。像什么:计算流水、对帐这些“history data”,运营部门还要经常看看。
这好家伙,本来增加了一堆硬件和实施成本可以应对“当天”场景,过2周发觉中台这用来暂存数据的一个中间件内存爆了、磁盘爆了、大数据又要增加硬件了。EC部门也开始有抱怨过来了:又卡了。。。又慢了。。。数据晚到30分钟!
于是,CIO此时就会开始烦了,于是CIO把大数据和业务系统的人找过来,开始了解系统间的交互以及问题产生的原因。
一起给自己挖了一个更大的坑-大血坑
为应对实时计算的业务需求上的实时性同时又不影响到现有交易系统,我们给自己挖了一个更大的大血坑,并且我们把自己给埋了进去。这个坑是这样的:
CIO把大数据的人,把交易系统的人全部召集起来,开了一个会。
CIO:啊。。。这个。。。是怎么回事。
- 大数据团队负责人发言了:主要还是并发的问题,算数据我们没任何问题,主要还是并发量的问题这个并发不要说7,000一秒就算2,000一秒过来,那么这个本来就属于交易系统的能力,因为你要支持高并发,就会需要有NG->Varnish->缓存->nosql一整条链路,以及用于开发这些链路所需技能的人员和相关的硬件。
- 交易系统负责人也发言了:这条链路交易系统目前己有,开发这条链路的所需技能是交易系统开发人员的本职工作。大数据说的对,如果要把算完的数据直接放入交易系统的Redis内,那么大数据这不仅仅要算而还要在算完后需要按照现在小程序、APP所需要的数据结构塞进Redis,而塞进Redis前大数据计算的结果上再需要按照交易端系统的业务逻辑再次进行第三次转换成可用于现有前端应用展示用的json data;
CIO听完,点了点头道:其实就是数据倒来倒去在这样倒腾时产生了额外的、不必要的开销。这样吧。。。我说大数据负责人啊,你也别和我烦了!反正算也在你这算,你就别把算完的数据再返还给交易系统了。你直接在你的大数据这把业务系统所需的那条链路所涉及到的硬件都筹备起来吧,以后前端展示这块把API长到你这边所属的NG上就成了。。。啊。。。我说我的秘书啊,你记一下会议纪要。给大数据这筹备一整套和交易系统一样的那些部件,什么NG,要6个?Redis,6个?Mongo也要,好吧给3个内存要乘3相应的CPU也要乘3,MQ也要5个,ELK要5个。。。哎。。。好多钱。。。唉。。。算了,忍忍吧,全给吧。。。。。。
话还没说完,大数据负责人就说了:您等一下,这些开发技能也需要人。。。
CIO:这没问题,你把相应的人也筹备一套吧。
于是整个企业架构会变成下面这么一个样子,这个样子的架构就是根据着上面这样的经常在各企业内出现、经常让技术人员心累、经常发生的争论而得来的。
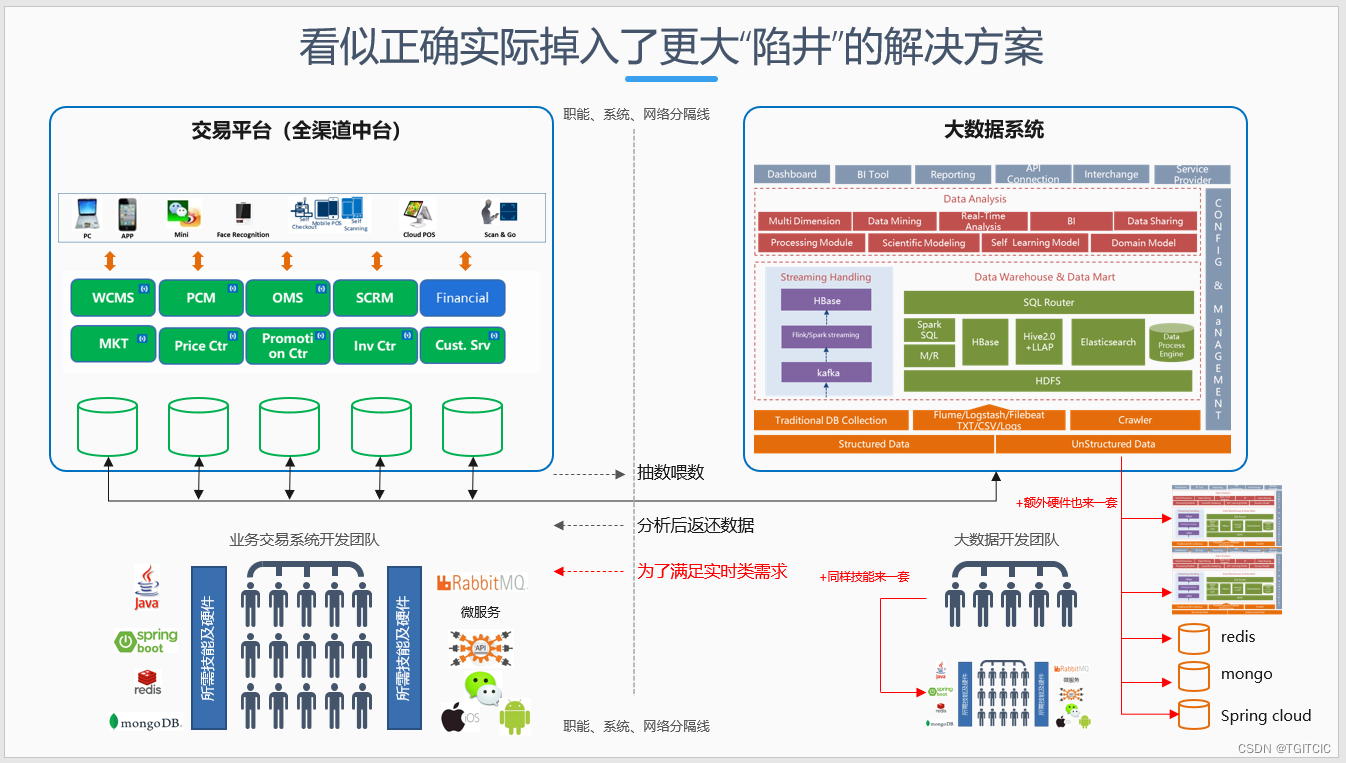
对不对,是不是?
这种企业架构就这样来的呀,一点不奇怪。
业务为导向的需求决定了企业架构、企业架构才能决定技术架构。
当然,以上红色的字都是“事后諸葛亮”才得知的,这都是无数个惨痛案例的总结。也正是我上文中提到的,相应的技术Leader或者领导在还没有发生以上这个“果”前已经感受到了一种“总觉得哪里不对劲”的地方。
但是这个“果”一旦发生我们再要板正,那时的情况已经属于“高危”了。因为企业架构已经错了。一旦当企业架构错了,它势必会影响到应用架构、技术架构,最终它会反噬业务架构。
我们来看这样错误的企业架构光从成本上会带来什么样的影响:
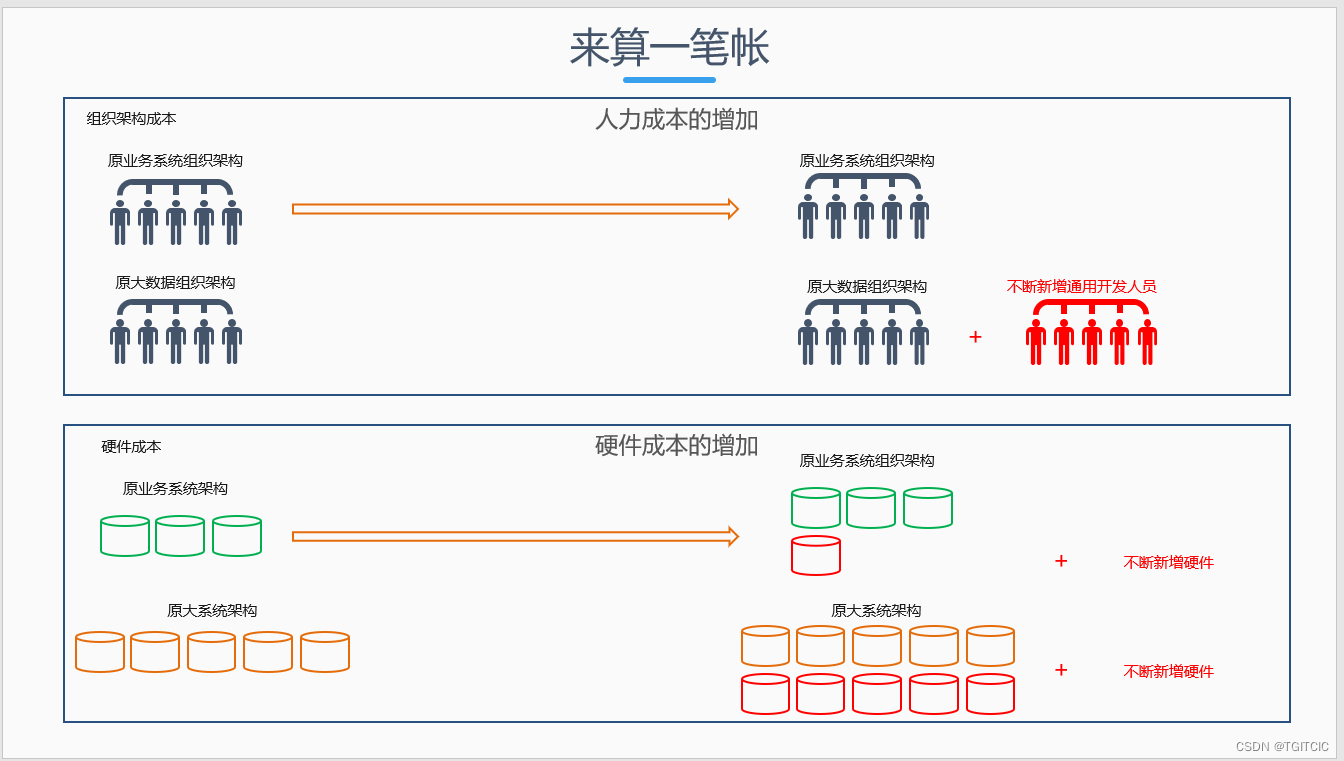
如果在这个企业架构内,光是成本出了这么大的问题倒也算了。团队还会陷入混乱中,当出现了两套一模一样的业务交易系统架构时,业务需求怎么提?技术架构如何去定位?但是这也不是最严重的。
我们知道:术有专精,那么当一个不相干的团队要完全掌握起另一个团队早熟练的技能它必须先要有一个“学习成本”。
把学习成本加上去,受影响的就是企业业务。
时下里市场瞬息万变,掌握先机早、哪怕早1天都可以取得至关重要的胜利。
更不用提当发生进度每每延误、成本还上升时,再上层的老板,那种CEO、CFO、CMO,更不懂技术和更不要听你bla了,直接就是一个结论:花了大笔钱开发效率和质量反而更低了。
况且我们搞技术的都知道,就算过了6个月,大数据团队把这一整套业务交易系统该有的硬件环境、技术栈、人员全部具备了也能自己分析、然后马上自己写API、甚至可以写Android或IOS了,这个架构还是有致命伤的。
这个致命伤就在于:永远要去业务系统的DB获取这些History的数据。就这一点注定了这个实时性永远达不到并陷入到一个永远的不断堆加成本、开发效率又低、性能更差的无限循环陷井中去。
用流比一体思想改造或者防止出现错误的企业架构
因此我们后面才出现了“流批一体”的概念,流批一体流批一体。很多人会觉得这4个字理解起来很晦涩!
这什么个意思呢?读起来么觉得高大上,真正要落地时怎么去定位这个架构呢?
我的博客很喜欢既提“高大上”的新名字、又提接地气的业务(其实就是指不需要懂技术的业务人员也可以完全理解)上的真正含义。
流批一体的定位
- 我们先来解释“流批”这两个字:传统的数据处理叫跑批,在上千万的结果集里找出那些我要的数据然后去重、聚合、行变列、列变行的转换成我要最终输出的结果。而流批指的却是:实时或者说有一个比较“小”的“短”的固定的时间窗口(通常<=60分钟)内的那些“瞬时”数据;
- 再来解释一体这两个字:接着以上的话,把数据取出来后我们要做去重、聚合、行变列列变行等基于业务规则的转换。那么我们在基于这个很小的固定时间窗口取数据时就顺便一起把这些转换行为给转了,而不要每每都是:数据传过来落一个盘,跑一批全/批扫描,扫描和批时再去做这个转换,这是3个动作。这3个动作每次处理如果都要全来一遍这种就是传统的跑批;
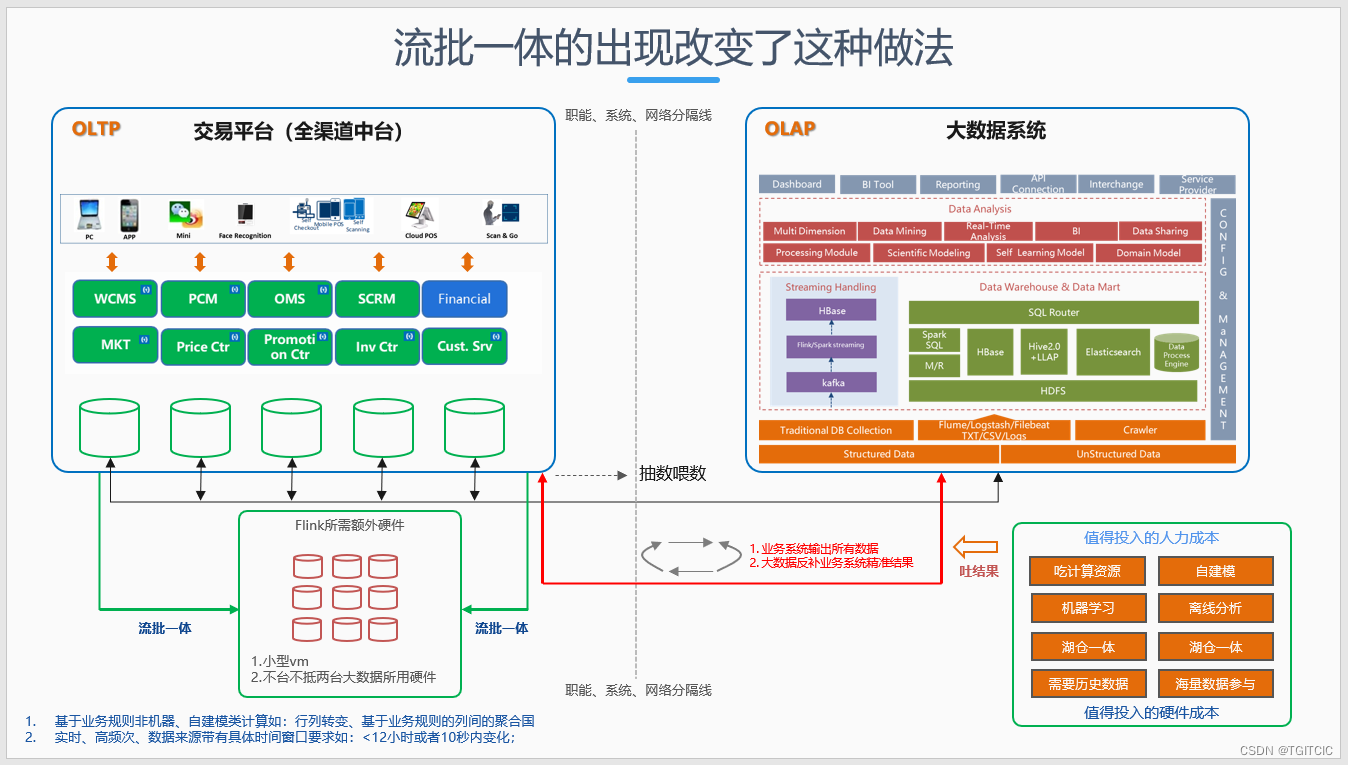
所以流批一体流批一体,它的理想状态是我们就拿业务系统来说它的流批就必须放在业务系统架构内。
我们注意上图中那条绿色的线。它是完全落在业务系统的局域网段内的。业务系统和其它系统间是有ip segregation即:网段隔离的,有ip segregation就会有一堵防火墙,有防火墙就会有网络IO、有网络压力就会有网络延迟。你可以认为流批一体组件长在业务系统内它在对业务数据的处理等于:本地化数据处理能力。而不是跨越了两个系统,更精准的我们说:流体一体必须不能跨越两个不同业务域的数据库去做互相落盘再扫描逐行去处理的过程,它不是用来来来回回在几个数据库间“倒腾”这批数据的,这就是“一体化架构的所谓流批一体”。
反过来我们说大数据要不要流批一体。
大数据当然也需要流批一体技术!即:业务系统有了流批一体大数据内同样也需要有流批一体。为什么这样说呢?哪道不能。。。复用?
组件间的复用是指业务功能在同一业务领域内的复用,大数据处要使用的流批一体的场景和业务交易系统不一样。大数据处的流批一体靠的是这样的场景来驱动的:
- 数据模型的变化是实时不是每次需要开发一个CR、编译、测试、上线而是动态实时变化的;
- 从湖仓一体过来的数据要变成驱动另一个数据模型的“进参”时的实时变化需求;
- raw data数据的ETL过程中要做实时转变、聚合、去重等操作。如:从APP前端埋点抽数、从整个公司的Nginx抽访问日志进数仓时还伴随着格式上的转换、还有AI场景;
这些大数据应用场景其实都也和业务系统一样,同样是需要流批一体化技术的。
总结
本篇着重阐述了这么两个层面的观点:
- 如何正确区分大数据和流批一体技术的混淆。并不是只有业务系统也不是只有大数据需要流批一体,而是都需要。只是各自需要的业务驱动场景不一样;
- 如何区分一个业务需求到底是放在业务系统的流批一体去做还是大数据数仓上去做,本质区别在于:实时计算用的这个数据源是业务瞬时(一般来说<60分钟)、访问高频次(<=5秒一刷新)、高并发(千位数并发)+并且不要落History(落库)还是:计算用的数据源是History Data(巨型、海量数据)的分析后算出结果。如果是前者即:瞬时数据那么go业务系统的流批一体。如果是后者即:巨型海量数据:go大数据系统;
这边需要补充一个很重要的概念:业务规则引擎/触发引擎的结合使用。
如果我们在这些架构里混入了一个“触发引擎”,这个事情也会变得很复杂,但其实又不那么复杂!判断条件也很简单,那就是:几方结合起来一起应用。
就是:
如果参与的计算的数据是海量数据且数据间的“加减乘除”不是固定的而是可配置的、被条件触发的,那么这一整块统统应该放在大数据平台去做。而对于在这个场景下大数据吐出的输出物同时又要满足到:高频次、高并发“sink(沉淀)”到交易系统内的nosql中去时,那么在大数据的输出物和业务系统的nosql间架设一条流批一体通道。
其核心原因就是:业务系统是OLTP系统它并不具备巨型海量数据计算但是它可以满足高频次、高并发、业务幂等这些动作因此它需要的数据说白了就是对外展示的“二维数据”必须且一定是一张“小表”,而不能是一张“无限增涨每次百万、千万级行增长”的大宽表。