flink常见问题(持续更新)
本文记录我在使用flink过程中遇到的部分问题,后续遇到别的问题也在这里更新,文章长期更新。
1.内存问题导致被yarn/k8s杀掉
这种问题基本都是因为物理内存或者虚拟内存超过被yarn杀掉,可以看到如下日志:

虚拟内存超标
如果是虚拟内存超过了需要改yarn配置即可,比如设置yarn.nodemanager.vmem-check-enabled为false关闭虚拟内存检测或者增加yarn.nodemanager.vmem-pmem-ratio的值,默认为2.1,比如我上图中12*2.1=25.2G。
物理内存超标
物理内存超标首先需要检查自己代码是否会有内存泄漏。此处我是用的flink-sql,并未自己写代码,所以排除上述情况。
我产生上述情况的taskmanager内存参数如下:
-Djobmanager.memory.process.size=2g \
-Dtaskmanager.numberOfTaskSlots=2 \
-Dtaskmanager.memory.process.size=12g \
-Dtaskmanager.memory.managed.fraction=0.5 \
-Dtaskmanager.memory.jvm-overhead.fraction=0.4 \
-Dstate.backend="rocksdb" \
-Dstate.backend.incremental="true" \我用了rocksdb做状态后端,rocksdb做状态后端会直接用物理内存,且内存不是完全按照flink分配的managed.memory大小来使用,所以需要增加overhead的内存,我这里给了0.4的比例,但是真实起作用的overhead只有1gb,具体原因参见我的另一篇博文:flink-taskmanager内存计算 。
查看内存分配详情,通过flink-ui界面找到container的dataport端口

执行如下命令:
netstat -anop | grep xxxx
top -p xxxx例如:
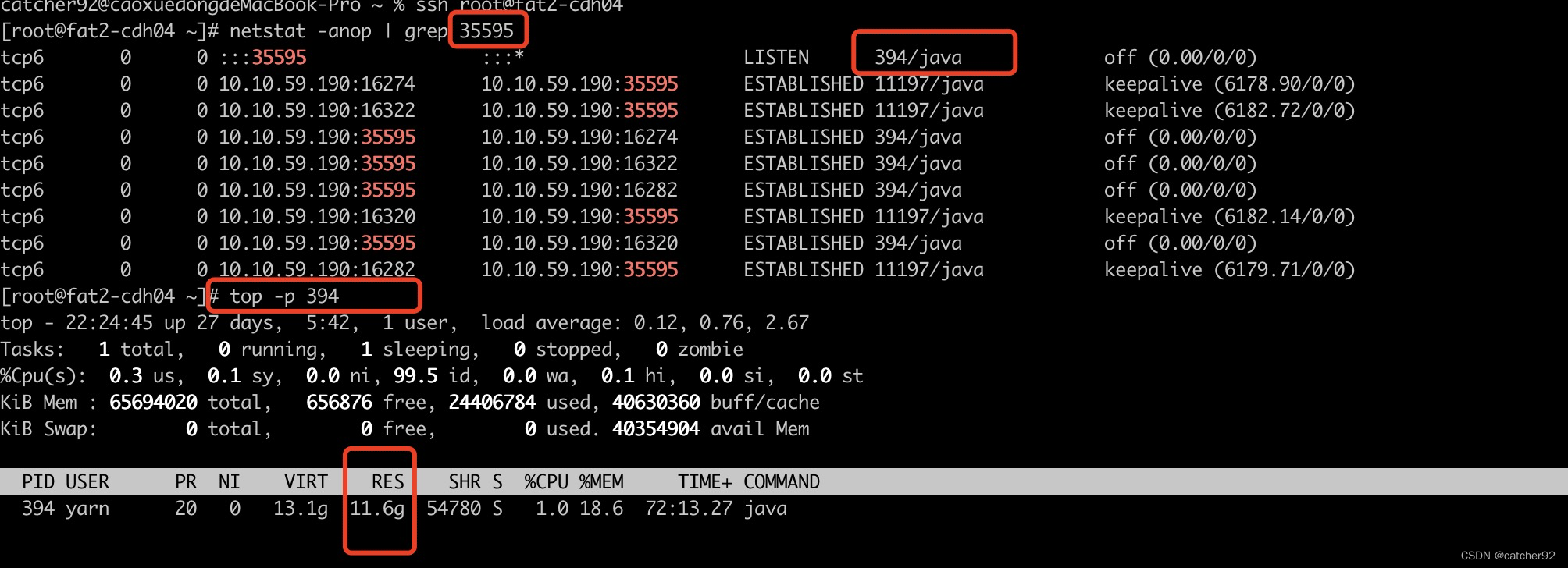
可以看到设置12g,已经使用了11.6g,使用的内存还是挺高的。
通过pmap -x 394 | sort -r -n -k3 > /data/tmp/394-pmap-sorted.txt 查看内存分配信息,结果如下图:
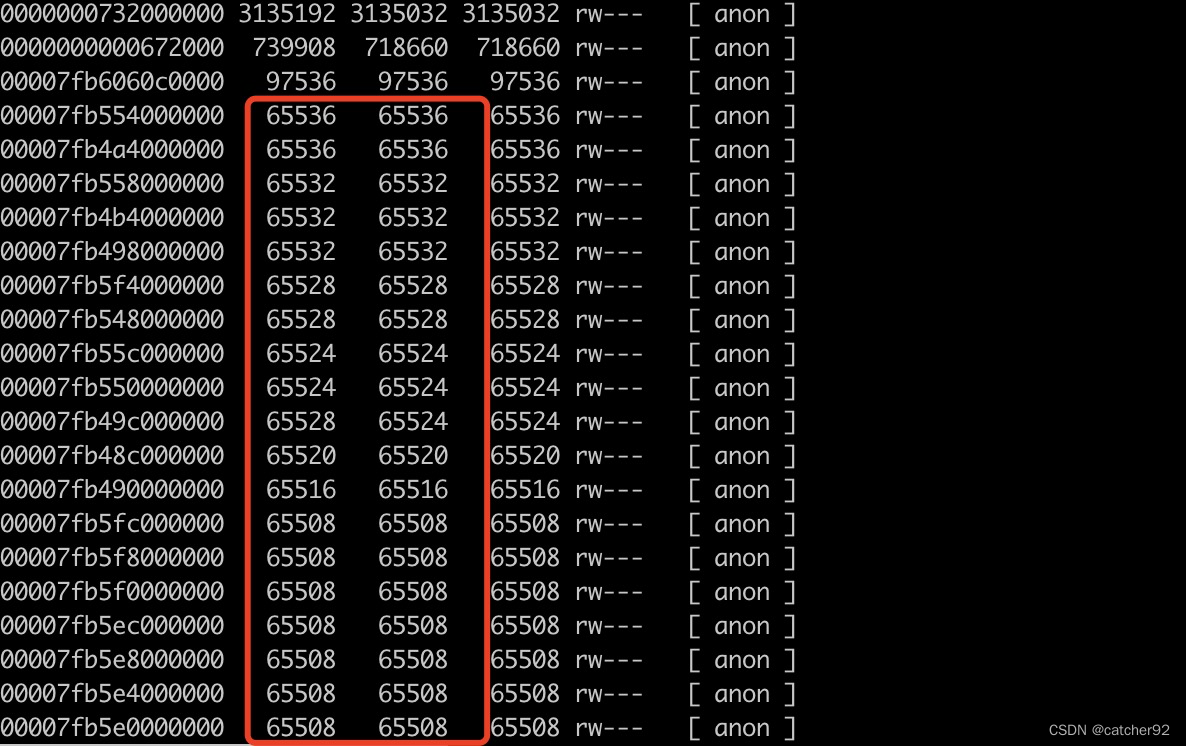
可以看到我这里有很多接近64M的内存,由于我这里是flink读hudi数据再写hudi,hudi数据存储在hdfs上,所以就想到了linux中Glibc Thread Arena问题,这个问题会导致申请很多大约64M的内存,解决这个问题需要同时修改yarn配置和flink程序配置。
- yarn配置修改yarn.nodemanager.env-whitelist配置项目,在里边新增MALLOC_ARENA_MAX。
- flink程序配置添加如下配置:-Dcontainerized.taskmanager.env.MALLOC_ARENA_MAX="1"
修改以后重新提交程序运行,继续看pmap结果:

已经没有大片的64M左右的内存了,所以上述改动生效。
除了上述解决办法还有个简单的解决办法,就是再次增大overhead。比如我增加如下参数 -Dtaskmanager.memory.jvm-overhead.max="4gb" 再结合-Dtaskmanager.memory.jvm-overhead.fraction=0.4设置该参数将原来1g的overhead设置为4g,此时尝试再运行程序,也没有再被kill了,程序内存高峰值8.8g,离进程的最大12g还有比较大的buffer空间,至此问题解决。