大数据复习(day03)
HDFS特点总结
HDFS特点
1、分布式存储架构,支持海量数据存储。(GB、TB、PB级别数据)
2、高容错性,数据块拥有多个副本(副本冗余机制)。副本丢失后,自动恢复。
3、低成本部署,Hadoop可构建在廉价的服务器上。
4、能够检测和快速应对硬件故障,通过RPC心跳机制来实现。
5、简化的一致性模型,这里指的是用户在使用HDFS时,所有关于文件相关的操作,比如文件切块、块的复制、块的存储等细节并不需要去关注,所有的工作都已被框架封装完毕。用户所需要的做的仅仅是将数据上传到HDFS。这大大简化了分布式文件存储操作的难度和管理的复杂度。
6、HDFS不能做到低延迟的数据访问(毫秒级内给出响应)。但是Hadoop的优势在于它的高吞吐率(吞吐率指的是∶单位时间内产生的数据流)。可以说HDFS的设计是牺牲了低延迟的数据访问,而获取的是数据的高吞吐率。如果要想获取低延迟的数据访问,可以通过Hbase框架来实现。
如果已经存储了大量的小文件,可以通过HDFS Har归档机制(将多个文件合并成-个或少数文件)
MapReduce介绍
概述
MapReduce是一个分布式的计算框架(编程模型),最初由由谷歌的工程师开发,基于GFS的分布式计算框架。后来Cutting根据《Google Mapreduce》,设计了基于HDFS的Mapreduce分布式计算框架。
MR框架对于程序员的最大意义在于,不需要掌握分布式计算编程,不需要考虑分布式编程里可能存在的种种难题,比如任务调度和分配、文件逻辑切块、位置追溯、工作。这样,程序员能够把大部分精力放在核心业务层面上,大大简化了分布式程序的开发和调试周期。
MapReduce框架的节点组成结构
JobTracker / ResourceManager: 任务调度者,管理多个TaskTracker。ResourceManager是hadoop2.0版本之后引入了yarn,有yarn来管理hadoop之后,jobtracker就被替换成了ResourceManager
MapReduce重要组件:
①Mapper组件
②Reducer组件
③Partitioner组件(Hadoop默认用的是HashPartitioner,会Mapper输出key的Hash分区,从而确保相同的Mapper输出key落到同一个分区里),分区指的是ReduceTask.

④Combiner组件(现在Map端合并后在发给ReduceTask)
作用:
1.减少reduceTask的合并负载
2.减少网络数据传输,节省带宽
⑤InputFormat组件更改Mapper的输入key,输入value
⑥OutputFormat组件更改输出到结果文件的格式
2.MapTask和ReduceTask 的任务数量
①MapTask数量=Job的文件切片数(文件切片不是文件切块)
文件切片=InputSplit,属于逻辑切块,通过对象来描述,包含: pathstart length
所以文件切片中没有文件数据
文件切块=当把文件上传到HDFS时,会被物理切块,存到Datanode上。

②ReduceTask数量(分区数),和切片没有关系,默认就1个。通过代码进行设定
job.setNumReduceTasks (3) ;
序列化机制+FlowCount案例
由于集群工作过程中,需要用到RPC操作,所以MR处理的对象必须可以进行序列化/反序列操作。Hadoop利用的是avro实现的序列化和反序列,并且在其基础上提供了便捷的API要序列化的对象必要实现相关的接口:
Writable接口–WritableComparable
3.MapReduce的排序
MR会对Mapper的输出key排序,具体如何排序,取决于Mapper输出key类型里compare方法
=======================================
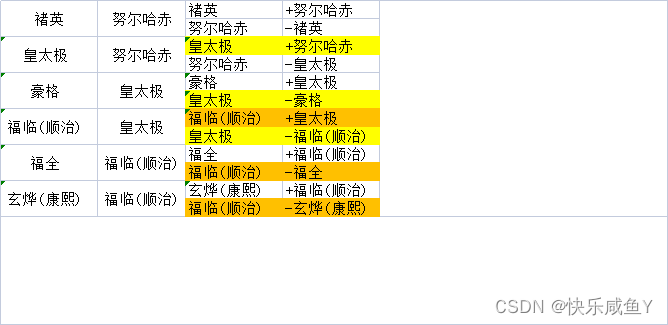
案例:找爷孙关系
案例文件
褚英 努尔哈赤
皇太极 努尔哈赤
多尔衮 努尔哈赤
多铎 努尔哈赤
豪格 皇太极
福临(顺治) 皇太极
福全 福临(顺治)
玄烨(康熙) 福临(顺治)
第一列是孩子辈,第二列是父母辈。现在要得到爷孙辈的关系
比如最后的输出结果︰
爷爷辈:[努尔哈赤]-->孙子辈:[福临(顺治),豪格]
爷爷辈:[皇太极]-->孙子辈:[玄烨(康熙),福全]
思路
代码部分



=================================
4.MRjob执行流程
在领取MapTask时,满足数据本地化策略。避免通过网络传输数据,节省带宽
Shuffle-Map阶段
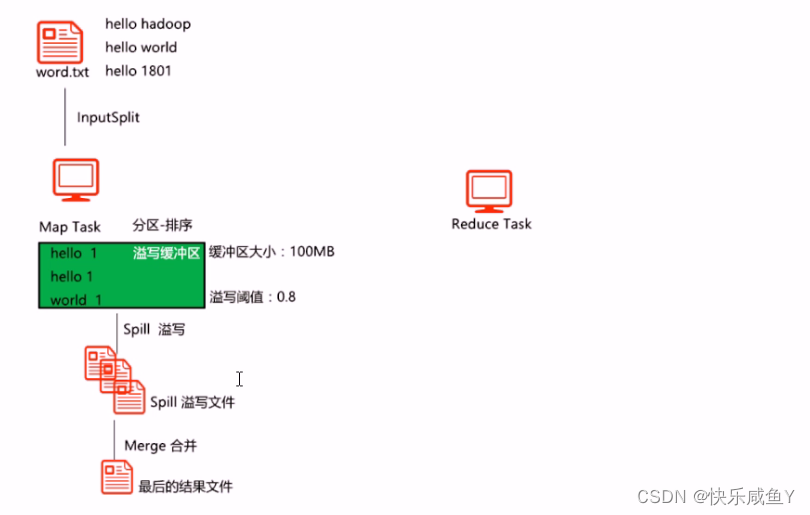
知识点
1.Map Task的输出k v,一开始会进入溢写缓冲区中,对数据做处理,比如分区、排序等操作。2有几个Map Task,就有几个对应的溢写缓冲区
3.溢写缓冲区默认是10oMB,溢写阈值:0.8。(都可通过配置文件调节)
4.当缓冲区中的数据达到溢写阈值时,会发生Spill溢写过程。把内存中数据溢写到磁盘的文件上。
5.第4步生成的文件,称为Spill溢写文件
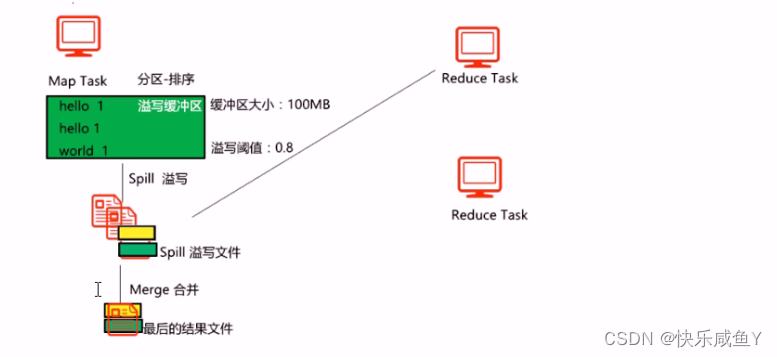
6.每一个Spill文件里的数据都是已分好区,且排好序的
7.当Spill过程结束之后,会发生Merge过程。目的是将多个Spill合成最后的结果文件( Finaloutput ) 。
8.结果文件是一个已分好区,且已排序的文件。
9.Spill和Merge过程不—定会发生。
10.如果发生了Spill过程,最后存留在溢写缓冲区里数据,会Flush到文件中。目的是确保数据都落到文件中。
11.如果发生了Spill过程,但不一定会发生Merge。即如果只有一个Spill文件,则此文件就是最后的结果文件。
12.从性能调优的角度,可以加入Combiner中间过程,会减少数据在溢写缓冲区的存储,间接减少了
Spill次数,即减少了磁盘的I/O次数。
13.如果加入了Combiner中间过程,在溢写缓冲区的处理阶段是一定会发生的。但是在Merge过程中,可能会发生。
14.Merge的Combiner不发生的条件:Spill文件的数量<3
15.从性能调优的角度,可以适当增大溢写缓冲区的大小,可以减少Spill的溢写次数。要根据服务的硬
件情况来调节。一般服务器内存:32GB或64GB。结合集群的:slave节点数量+Job数量+每个Job的MapTask数量
16.溢写缓冲区也叫环写缓冲区(环形缓冲区),注意:溢写阈值的参数可调,但是不要调成100%。目的是为了避免产生写阻塞时间。此外,环形缓冲区的好处是每个MapTask重复利用同一块内存地址空间,可以减少内存碎片的产生,提高内存使用率,而且从GC角度来看,可以减少full gc发生的次数。
建议∶看GC回收算法以及GC收集器,《深度理解Java虚拟机:JVM高级特性与最佳实践》(第2版)看第二章
17.可以开启Map Task的压缩机制,将最后的结果文件做压缩。好处可以减少网络数据的传输。
18.当Merge过程结束后,所有的Spill文件被删除
19.有几个Map Task ,就有几个最后结果文件。
20.最后的结果文件存到服务节点的本地磁盘上。
21.虽然一个Map Task处理的切片数据是128MB(满的情况),但是不能凭输入的数据大小来判断map的输出大小,要根据实际的业务代码来判断。
22.Map Task的输出结果有两类收器:
①DirectMapoutputCollector在没有reducer组件的情况下使用
②MapoutputBuffer 在有reducer组件的情况收集,在这个类中,包含了Spill 、溢写缓冲区相关的对象
Shuffle-Reduce阶段
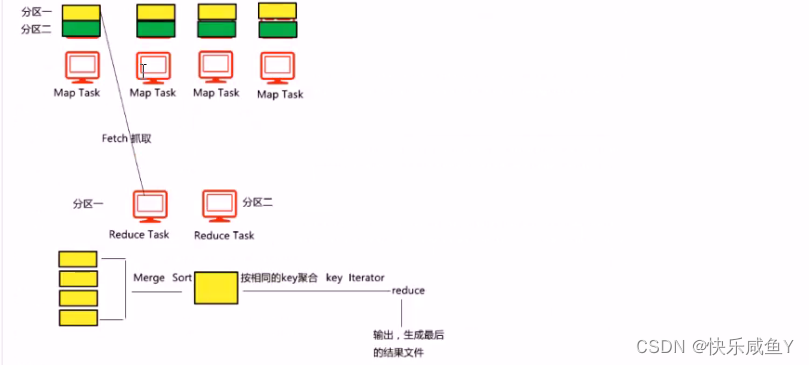
知识点
1.当Map阶段接收,reduce会Fetch自己分区的数据
2.reduce 的Fetch结束后,会进行Merge和Sort
3.Merge和Sort结束后,会发生reduce,按相同key聚合,形成key iterator传给开发者
4.Fetch线程数默认是5个,此参数可以调节。一般的做法是让此线程数接近或等于map task 数量。达到并行抓取的目的。
订单表数据
1001 20170710 4 2
1002 20170710 3 100
1003 20170710 2 40
1004 20170711 2 23
1005 20170823 4 55
1006 20170824 3 20
1007 20170825 2 3
1008 20170826 4 23
1009 20170912 210
1010 20170913 2 2
1011 20170914 3 14
1012 20170915 2 18
商品表数据
1 chuizi 3999
2 Huawei 3999
3 Xiaomi 2999
4 Apple 5999
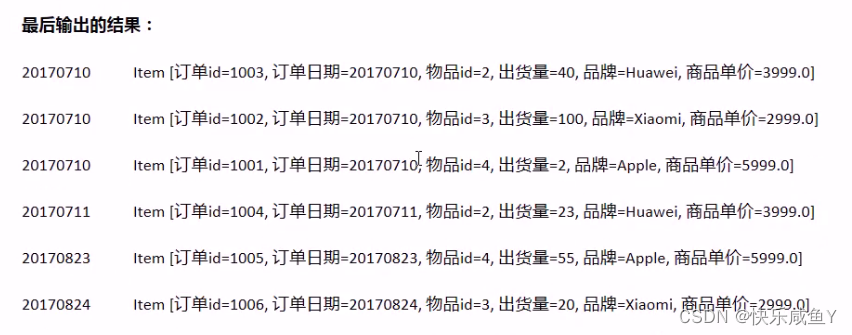
最后结果
20170710 ltem [订单dm1003,订单日期-20170710,物品id=2,出货量=40,品牌=Huawei,商品单价=3999.0]
20170710 ltem [订单dm1002,订单日期=20170710,物品ld=3,出货量=100,品牌=xiaomi,商品单价=2999.0]
20170710 ltem [订单idm1001,订单日期-20170716l 物品id=4,出货量=2,品牌=Apple, 商品单价=999.0]
20170711 ltem [订单idm1004,订单日期=20170711,物品id=2,出货量=23,品牌=Huawei,商品单价=3999.0]
20170823 ltem [订单d-1005,订单日期-20170823,物品d=4。出货量=55,品牌=Apple,商品单价=5999.0]
6.MapReduce的Join,可能会引起数据倾斜问题,如何解决?
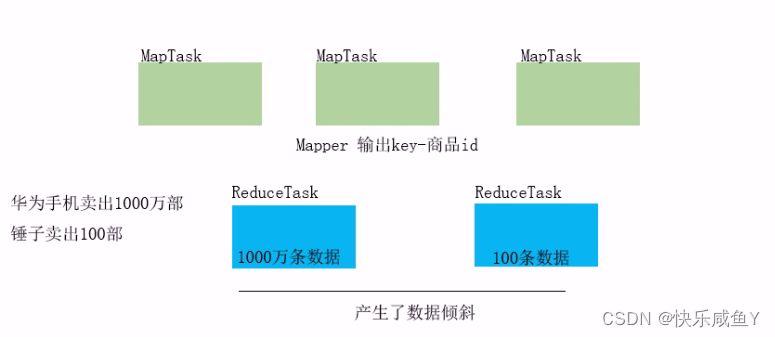
上图演示的是reduce-side-join 。这种join方式可能引起数据倾斜。
所以,可以采用map-side-join来实现

上图演示的是map-side-join的思想,将小表数据加载到每个MapTask的缓荐中,然后再MapTask完成Join。可以避免产生数据倾斜
Yarn概述
概述
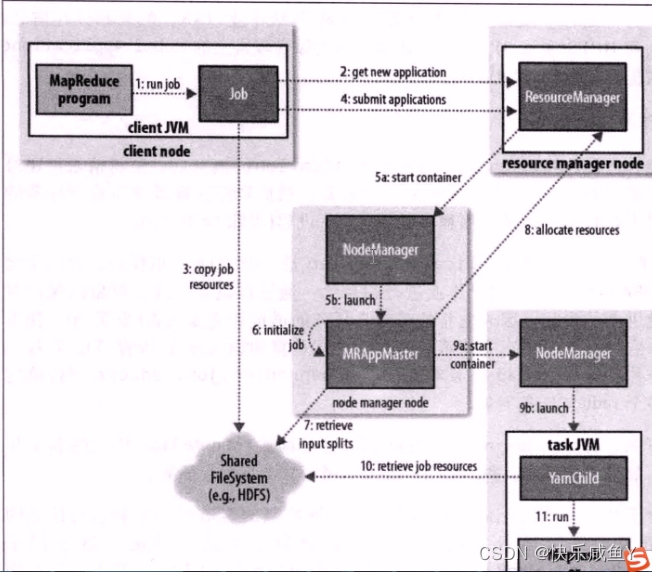
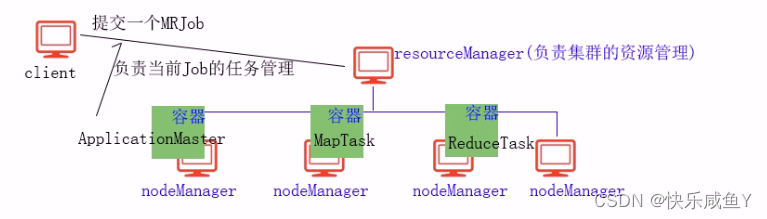
Apache Hadoop YARV ( Yet Another Resource Negotiator,另一种资源协调者)是一种新的Hadoop资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在资源利用率、资源统一管理和数据共享等方面带来了巨大好处。
YARN的基本思想是将JobTracker的两个主要功能(资源管理和作业调度/监控)分离,主要方法是创建一个全局的ResourceManager (RM )和若千个针对应用程序的ApplicationMaster ( AM )。这里的应用程序是指传统的
MapReduce作业。
YARN分层结构的本质是ResourceManager。这个实体控制整个集群并管理应用程序向基础计算资源的分配。ResourceManager将各个资源部分(计算、内存、带宽等)精心安排给基础NodeManager ( YARN 的每节点代理)。
ResourceManager还与ApplicationMaster一起分配资源,与NodeManager一起启动和监视它们的基础应用程序。在此上下文中,ApplicationMaster承担了以前的TaskTracker 的一些角色,ResourceManager承担了JobTracker的角色。
ApplicationMaster管理一个在VARN内运行的应用程序的每个实例。ApplicationMaster负责协调来自ResourceManager的资源,并通过NodeManager监视容器的执行和资源使用(CPU、内存等的资源分配)。
复习Yarn的三种资源调度器
①FIFO调度器(先来先服务调度器)
②Fair调度器(公平调度器)
③Capacity调度器(容器调度器,默认的)