【论文阅读】自动作文评分系统:一份系统的文献综述
摘要
- 许多研究者在过去的几十年间都在致力于自动作文评分和简答题打分,但是通过像与提示之间的内容的相关性、思想的发展性、文章内聚力、文章连贯性等来评估一篇文章,到目前为止都是一项挑战。
- 很少的研究者聚焦于基于内容的评分,他们中的大多数都强调基于风格的评分。
- 我们观察到在内容和连贯性(coherence)方面对于文章评分的研究还没有完善。
研究方法
我们用PICOC准则来构建此研究问题的框架。
- P(Population)学生文章与问答题评估系统;
- I(Intervention)评估技术,数据集,特征抽取方法;
- C(Comparison)不同方法和结果的对比;
- O(Outcomes)评估AES系统的准确度;
- C(Context) NA。
研究问题
为了从现有的在自动作文评分的研究中收集和提供研究证据,我们构建了下面的研究问题(RQ):
- RQ1:在自动作文评分上,有哪些可获得的数据集?
这个问题的答案能够罗列一些可用的数据集,他们的领域,以及获得这些数据集的方法。它也能够提供大量的文章和对应的提示。 - RQ2:有什么提取出来用于文章评估的特征?
这个问题的答案能够提供对于目前已经抽取的大量特征的见解,并且许多用于提取这些特征的库。 - RQ3:有哪些可用的可以衡量算法的准确度的评价指标?
这个答案会提供每个机器学习方法的不同的评价指标,以及一些普遍使用到的衡量技术。 - RQ4:有哪些用于自动作文评分的机器学习技术,并且他们是怎么实现的?
它提供了对于不同的机器学习技术,像回归模型、分类模型、以及用于模拟作文自动评分系统的神经网络的见解。这个问题的回答能够给我们用于自动作文评分的不同的评分方式。 - RQ5:有哪些现有研究的挑战和局限性?
这个问题的答案提供了现有研究方法的缺陷,像内聚力(cohesion)、连贯性(coherence)、完整性(completeness),以及反馈(feedback)。
结果
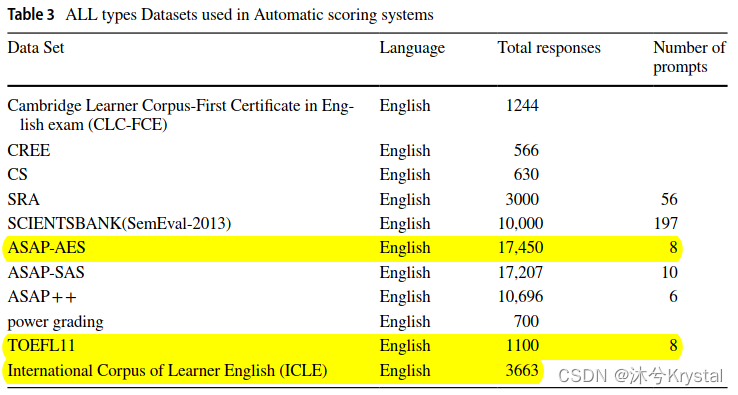
1.在自动作文评分上,有哪些可获得的数据集?
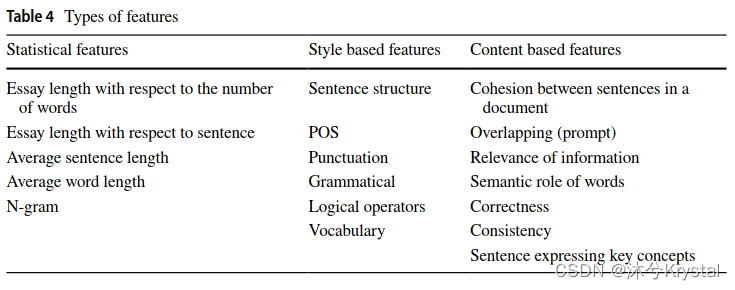
2.有什么提取出来用于文章评估的特征?
- 这些特征被划分成了3组:
1.基于统计的特征
2.基于风格的特征
3.基于内容的特征 - 如果是基于统计的特征,大多数的研究者会使用回归模型;对于神经网络模型,研究者会使用基于风格和基于内容的特征。
- 下表展示了所有在文章评分中的特征集合。
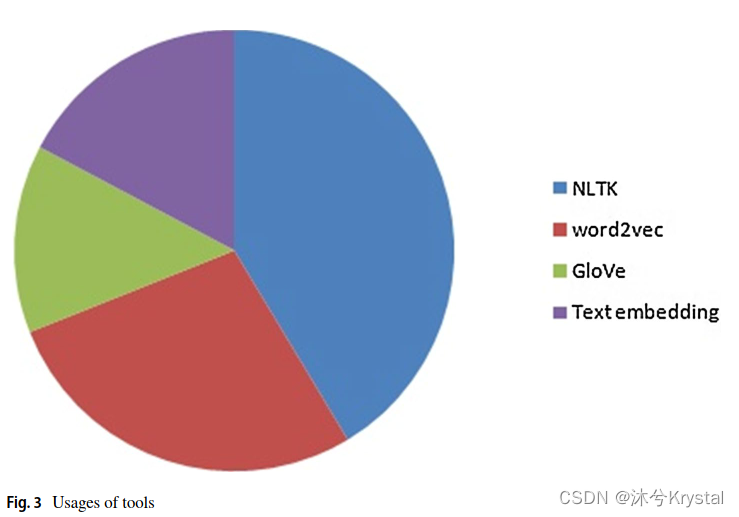
- 下图展示了所有的特征提取的NLP库:
3.有哪些可用的可以衡量算法的准确度的评价指标?
- 二次加权Kappa值,quadrated weighted kappa (QWK)
- 平均绝对误差,Mean Absolute Error (MAE)
- 皮尔逊相关系数,Pearson Correlation Coefficient (PCC)
- QWK会找到人类的评估分数 与系统的评估分数 的一致性,结果取值在0到1;MAE是人类打分与系统生成的分数之间的实际差距。MSE(mean square error)衡量了误差平方的平均值,MSE的值都是正数;PCC寻求两个变量之间的相关系数。
4.有哪些用于自动作文评分的机器学习技术,并且他们是怎么实现的?
- 回归技术
- 分类模型
- 神经网络
- 基于实体的方法(ontology-based approach)
- 所有过去10年中开发的现存的AES系统 都采用的是有监督的学习技术。 回归任务的目标是预测文章的分数,分类任务是分类文字从属于与问题话题(低、中、高)相关; 近3年来,大多数AES系统使用神经网络的概念。
基于回归的模型
- 2009年,Mohler等人提出 文章到文章的语义相似度 来为学生的文章分配分数。有两个文本相似度的度量:基于知识的度量、基于语料库的度量。Leacock等人使用节点计数发现了基于最短路径长度的相似度。Lesk相似度发现对应的定义之间的重叠度。Wu等人的算法,基于两个给定概念在词网分类学中的深度,发现了它们的相似度。在基于语料的相似中,LSA BNC,LSA Wikipedia,和ESA Wikipedia,浅层语义分析被在Wikipedia上进行训练,并且具备了不错的领域知识。在所有的相似度分数中,相关分数LSA Wikipedia 的准确度得分更高。但是这些相似度度量算法没有使用到NLP的概念,这些模型都是2010年之前的,并且基础的概念模型是和 在神经网络上更新的算法和基于内容的特征一起 来延续自动作文评分的研究的。
- 2014年,Adamson等人提出了一个自动作文评分系统,它是一个基于统计的方法,在其中他们检索了特征像POS,字符数,词数,句子数,错误拼写的单词数,词的n-gram表示来准备文章向量。他们用这些向量建立了一个矩阵,并在这个上面应用LSA来得到每篇文章的分数。它是一个基于统计的方法,并没有考虑到文章的语义,它的准确率是0.532.
- 2016年,Cummins等人提出了定时聚合百分比向量模型来对所有的文章排序,并且之后他们将排序算法转换为预测文章的分数。该模型的训练采用的特征有 词的unigrams和bigrams,POS,文章长度,语法关系,最大词长,句长。它是一个多任务学习,给文章排序以及预测文章的分数。QWK是0.69。
- 2016年,Sultan等人提出了一个岭回归(Ridge回归)来用问题降级(Question Demoting)寻求短回答打分。问题降级(Question Demoting)是一个全新的概念,它被包括在文章的最终评估中,来消除文章中的冗余的词。提取的特征是文本相似度,也就是学生回答和参考答案之间的相似度。问题降级是一个学生回答中重复的数量。他们通过逆文档频率,来分配术语的权重。句长比是学生回答的词的数量,是另外一个特征。采用以上这些特征,并应用岭回归模型,他们取得了0.887的准确率。
- 2018年,Contreras等人提出的基于文本挖掘的实体在这个模型上在各个阶段得到文章的得分。在阶段1,他们用ontoGen来产生实体和SVM来寻求文章中的概念和相似度。在阶段2,他们检索了特征,像文章长度,词数,正确度,词汇量,以及用到的词的种类,领域知识。在检索了统计数据后,他们使用线性回归模型来找到文章的分数,评价准确度是0.5。
- 2019年,Darwish等人提出用LSA对模糊实体融合。他们检索了两种特征,像句法特征和语义特征。在句法特征中,他们发现用tokens的词汇分析,并且构建了解析树。如果这个解析树被打断或者坏掉,这篇文章就是不协调的。关于句法特征,一个分隔的等级会被分配给文章。语义特征比如有相似度分析,空间数据分析。相似度分析的目的是发现冗余的句子,空间数据分析是为了发现中心和部分之间的欧几里得距离(Euclid distance)。之后,他们将句法特征和形态学特征分数结合得到最终的得分。采用多线性回归模型,他们取得准确率为0.77,大多数是在统计特征上。
- 2020年,Suzen等人提出了一个用于短回答打分的文本挖掘方法。首先,他们将模型的答案与学生的回答做对比,通过计算两个句子之间的距离。通过对比模型的答案和学生的回答,他们发现文章的完整度并且提供反馈。在这个方法中,模型的词汇量在打分中起着非常重要的作用,并且有这个模型的词汇,分数会被分配给学生的回答,并且提供反馈。学生的回答和模型答案的相关度为0.81。
基于分类的模型
- 2013年,Persing等人使用支持向量机来给文章打分。提取的特征有OS,N-gram和语义文本来训练模型,并且从文章中识别关键词,来给出最终的得分。
- 2015年,Sakaguchi等人提出了两个方法:基于回答的 和 基于参考的。在基于回答 的打分中,提取的特征有回答的长度、n-gram模型、和句法元素,来训练支持向量回归模型。在基于参考 的打分中,特征比如像 使用word2vec句子相似度 被用来发现句子的余弦相似度,也就是回答的最终分数。 首先,分数是被各自发现的,之后结合两个特征来得到最终的分数。通过结合两个分数,这个系统有一显著的性能提升。
- 2018年,Mathias等人提出自动作文打分数据集,该数据集有文章的属性得分。第一个概念特征的选择取决于文章的种类,所以共同的属性有 内容、组织、词的选用、句子的流畅度、惯例。在这个系统中,每个属性都被各自单独打分,运用每个识别的属性的优势。该模型中他们使用的是随机森林分类器来对每个属性打分。他们在ASAS数据集的提示1上取得的QWK为0.74.
- 2019年,Ke等人使用支持向量机来发现回答的分数。在这个方法中,特征比如说有 同意度,特殊度,清晰度,与提示的相关度,简洁度,雄辩,自信,发展方向,观点的公正性,重要性。
- 2019年,Salim等人提出一个XGBoost机器学习分类器来评价文章。这个算法被训练在特征上,比如词数,POS,解析树深度和 用句子相关性百分比的文章连贯性。内聚力和连贯性在训练中被考虑进去。并且他们实现了K折交叉验证,平均准确度是68.12。
神经网络模型
- 2016年,Shehab等人提出了一个神经网络方法,该方法使用学习向量量子化(vector quantization)来训练人类评分了的文章。在训练之后,网络能够对未打分的文章进行打分。首先,我们应该处理文章来移除拼写检查,之后执行预处理的步骤,像文档标注、去除停用词、取词干,并且把它提交给神经网络。最后,模型能够对文章给出反馈,判断它是否与该话题相关。并且人类打分与系统分数之间的相关系数为0.7665.
- 2016年,Kopparapu等人使用结构和语义特征的自动文章排序。这个方法使用所有的回答构建了一个超级文本;然后,基于这个超级文本来对学生的作文排序。生成的结构和语义特征用作获取分数。在一个段落中,15个结构特征,像平均句子个数,平均句长,词数,名词数,动词数,形容词数等,这些被用来得到一个句法分数。一个相似度分数被用作语义特征来计算整体的分数。
- 2016年,Dong等人提出了一个层级CNN模型。该模型构建了两层,第一层用词嵌入来表示单词,第二层是一个用来最大池化的词卷积层来寻求词的向量表示。下一层是一个句子级别的卷积层,采用最大池化,来寻求句子的内容和同义词。然后用一个全连接的稠密层来产生输出一篇文章的分数。采取层级CNN模型,达到了平均QWK为0.754的准确率。
- 2016年,Taghipour等人第一次提出一个作文评分的神经网络方法,它的构建基于卷积和循环神经网络的概念有助于对一篇文章进行打分。这个神经网络使用了一个对词向量的独热表示的查询表。他们的采用LSTM的网络模型最终的性能是平均QWK为0.708。
- 2017年,Dong等人提出采用CNN+LSTM的基于注意力的打分系统。对于CNN,输入的参数是字符级和词级的嵌入,并且它有一个注意力池化层,并且使用NLTK来得到句子和字符级别的嵌入。输出给出了一个句子向量,它提供了句子的权重。在CNN之后,会有一个有一个注意力池化的LSTM层,最后这层会给出结果的最终分数。平均QWK是0.764。
- 2017年,Riordan等人提出了一个采用CNN和LSTM层的神经网络。词嵌入作为神经网络的输入。一个LSTM网络层能够检索窗口特征,并且把它们传递给聚合层。聚合层是一个浅层的层,它馈入正确的词窗,并且给出连续的层来预测答案分数。他们达到QWK为0.90。
- 2017年,Zhao等人提出一个叫做记忆增强的神经网络的新的概念,这个神经网络有4层:输入表示层、记忆强调层、记忆读取层和输出层。输入层基于文章的长度把文章表示为向量。在转换词向量后,记忆强调层馈入文章样例,并且给所有的术语(terms)加权。记忆读取层把记忆强调的分段作为输入,并且发现内容以最终化得分。最后,输出层会输出最终的分数。文章分数的准确度是0.78,比LSTM神经网络好很多。
- 2018年,Mathias等人提出了采用LSTM(CNN层和GloVe预训练词嵌入)的深度学习网络。
- 2018年,Dasgupta等人提出了一种作文自动评分的技术,该技术采用增强的文本定性特征。它提取了三种特征,语言学特征、认知特征和心理学特征。
- 2020年,Zhu等人提出一个 多方式机器学习方法(multimodal)。
所有方法的比较
- 在Bow中,向量包含了词在文章中的出现频率,向量没能包含相邻词之间的关系。在word2vec中,向量从多个维度表示了词与词或者提示句子之间的关系,但是word2vec向量是单向的,当一个词有多个意思的时候,它不能很好的进行语义的表示。
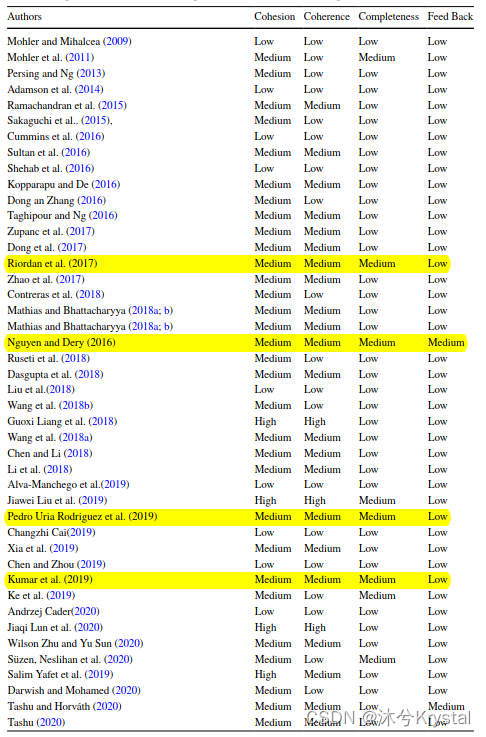
- 下表展示了关于文章的内聚力、连贯性、完整度以及反馈的模型的比较:
在目前的研究中有哪些挑战和局限性?
- 评估一篇文章,需要考虑到以下的因素:内容与提示之间的相关性、思想的发展性、内聚力、连贯性、领域知识。
- 很少有模型研究 内容的相关性,比如学生的回答是否与给定的提示相关联,以及相关程度多少合适。并且很少有内聚力和文章连贯性/条理性的讨论。
- 另一个局限是 没有采用机器学习模型的基于领域知识的评估。当一个词在不同领域有不同意思时,这些模型无法捕捉到想要的特征。
综合
- 没有模型能够都同时考虑到 统计特征、基于风格的特征和基于内容的特征。
- 连贯性:句子之间的逻辑连接(局部连贯性)和段落之间的逻辑连接(全局连贯性)。如果没有连贯性,文章中的所有句子都是独立和没有意义的。