CNN(卷积网络)如何处理Size(Shape)大小可变的输入图像数据
C N N (卷积网络)如何处理 S i z e ( S h a p e ) 大小可变的输入图像数据 CNN(卷积网络)如何处理Size(Shape)大小可变的输入图像数据 CNN(卷积网络)如何处理Size(Shape)大小可变的输入图像数据
为什么要输入图像数据大小可变?
因为纯ReSize之后图像变形可能非常严重,导致训练效果不佳。保证输入图像size可变,可以尽可能保持原图数据分布等特征。
为什么一般输入图像需要固定大小?
全连接层的输入是固定大小的,如果前一层输出的输入向量的维数不固定,根本连不上全连接层,无法训练模型。
方法1:去掉Dense层,使用kernel的数量来对应类别的数量(代表网络FCNN,全卷积神经网络),之后使用全局池化——GAP(Global Average Pooling),将每个kernel对应的feature map都转化成一个值,接softmax激活就能完成需求
卷积层讲解
in_channels, # 输入通道数
out_channels, # 输出通道数,即卷积核个数
kernel_size, # 卷积核尺寸
nn.Conv2d(512, num_classes, 1),所以卷积后的一张特征图就对应了一个类别,kernel_size = 1,表示输入图像宽高在卷积后不变
import numpy as np
import torch
from torchvision import models
from torch import nn
def bilinear_kernel(in_channels, out_channels, kernel_size):
"""Define a bilinear kernel according to in channels and out channels.
Returns:
return a bilinear filter tensor
"""
factor = (kernel_size + 1) // 2
if kernel_size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
og = np.ogrid[:kernel_size, :kernel_size]
bilinear_filter = (1 - abs(og[0] - center) / factor) * (1 - abs(og[1] - center) / factor)
weight = np.zeros((in_channels, out_channels, kernel_size, kernel_size), dtype=np.float32)
weight[range(in_channels), range(out_channels), :, :] = bilinear_filter
return torch.from_numpy(weight)
pretrained_net = models.vgg16_bn(pretrained=False)
class FCN(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.stage1 = pretrained_net.features[:7]
self.stage2 = pretrained_net.features[7:14]
self.stage3 = pretrained_net.features[14:24]
self.stage4 = pretrained_net.features[24:34]
self.stage5 = pretrained_net.features[34:]
self.scores1 = nn.Conv2d(512, num_classes, 1)
self.scores2 = nn.Conv2d(512, num_classes, 1)
self.scores3 = nn.Conv2d(128, num_classes, 1)
self.conv_trans1 = nn.Conv2d(512, 256, 1)
self.conv_trans2 = nn.Conv2d(256, num_classes, 1)
self.upsample_8x = nn.ConvTranspose2d(num_classes, num_classes, 16, 8, 4, bias=False)
self.upsample_8x.weight.data = bilinear_kernel(num_classes, num_classes, 16)
self.upsample_2x_1 = nn.ConvTranspose2d(512, 512, 4, 2, 1, bias=False)
self.upsample_2x_1.weight.data = bilinear_kernel(512, 512, 4)
self.upsample_2x_2 = nn.ConvTranspose2d(256, 256, 4, 2, 1, bias=False)
self.upsample_2x_2.weight.data = bilinear_kernel(256, 256, 4)
def forward(self, x):
# print('image:', x.size())
s1 = self.stage1(x)
# print('pool1:', s1.size())
s2 = self.stage2(s1)
# print('pool2:', s2.size())
s3 = self.stage3(s2)
# print('pool3:', s3.size())
s4 = self.stage4(s3)
# print('pool4:', s4.size())
s5 = self.stage5(s4)
# print('pool5:', s5.size())
scores1 = self.scores1(s5) # self.scores1 = nn.Conv2d(512, num_classes, 1); 这里进行了一次通道数的变化
# print('scores1:', scores1.size())
s5 = self.upsample_2x_1(s5) # nn.ConvTranspose2d(512, 512, 4, 2, 1, bias=False); 转置卷积进行第一次上采样
# print('s5:', s5.size())
##############融合##################
add1 = s5 + s4 # 第一次上采样 与 s4进行融合
# print('add1:', add1.size())
scores2 = self.scores2(add1) # self.scores2 = nn.Conv2d(512, num_classes, 1) 将融合后的add1进行一次通道数变化为num_classes
# print('scores2:', scores2.size())
add1 = self.conv_trans1(add1) # self.conv_trans1 = nn.Conv2d(512, 256, 1) 将融合后的add1进行一次通道数变化为256
# print('add1:', add1.size())
add1 = self.upsample_2x_2(
add1) # self.upsample_2x_2 = nn.ConvTranspose2d(256, 256, 4, 2, 1, bias=False) 将通道256的add1 ,上采样为add1
# print('add1:', add1.size())
add2 = add1 + s3 # 将add1 和 s3 进行融合
# print('add2:', add2.size())
output = self.conv_trans2(add2) # self.conv_trans2 = nn.Conv2d(256, num_classes, 1) 改变add2的通道数
# print('output:', output.size())
output = self.upsample_8x(
output) # self.upsample_8x = nn.ConvTranspose2d(num_classes, num_classes, 16, 8, 4, bias=False)
# 使用转置卷积进行上采样
# print('output:', output.size())
return output
if __name__ == "__main__":
# 随机生成输入数据
rgb = torch.randn(1, 3, 480, 480)
# 定义网络
net = FCN(12)
# 前向传播
out = net(rgb)
# 打印输出大小
print('-----' * 5)
print(out.shape)
print('-----' * 5)
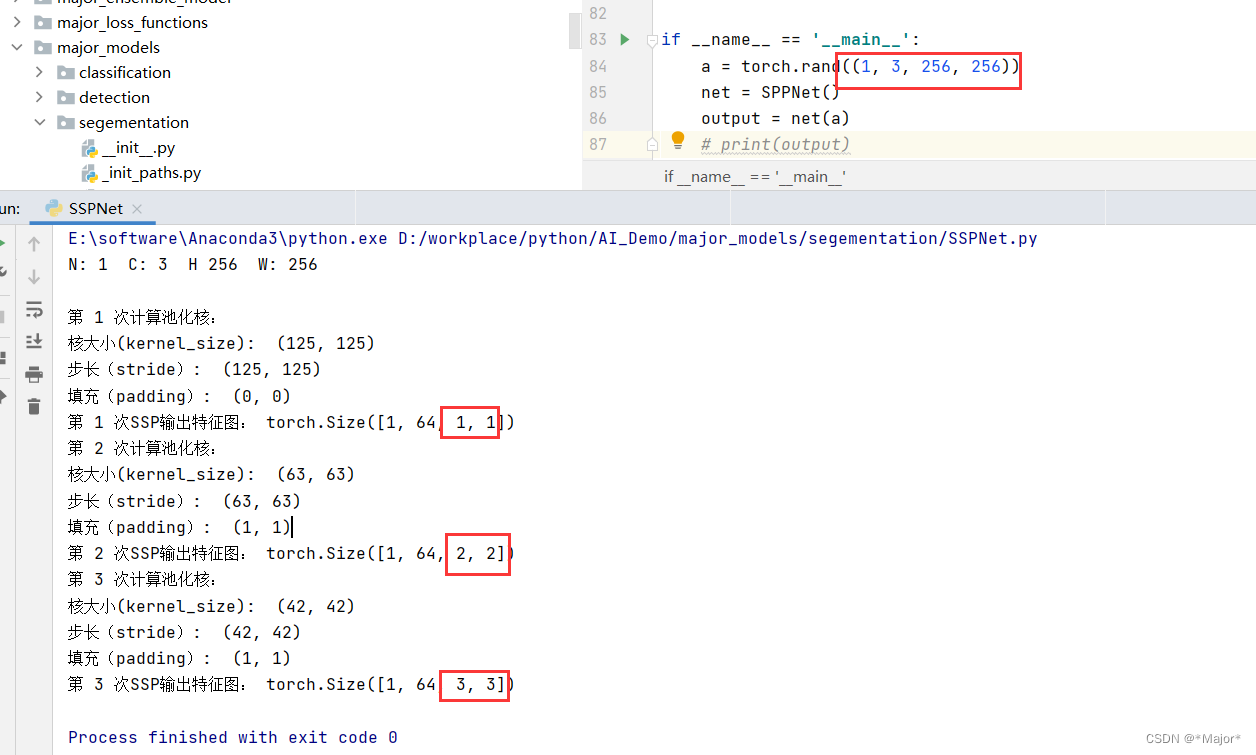
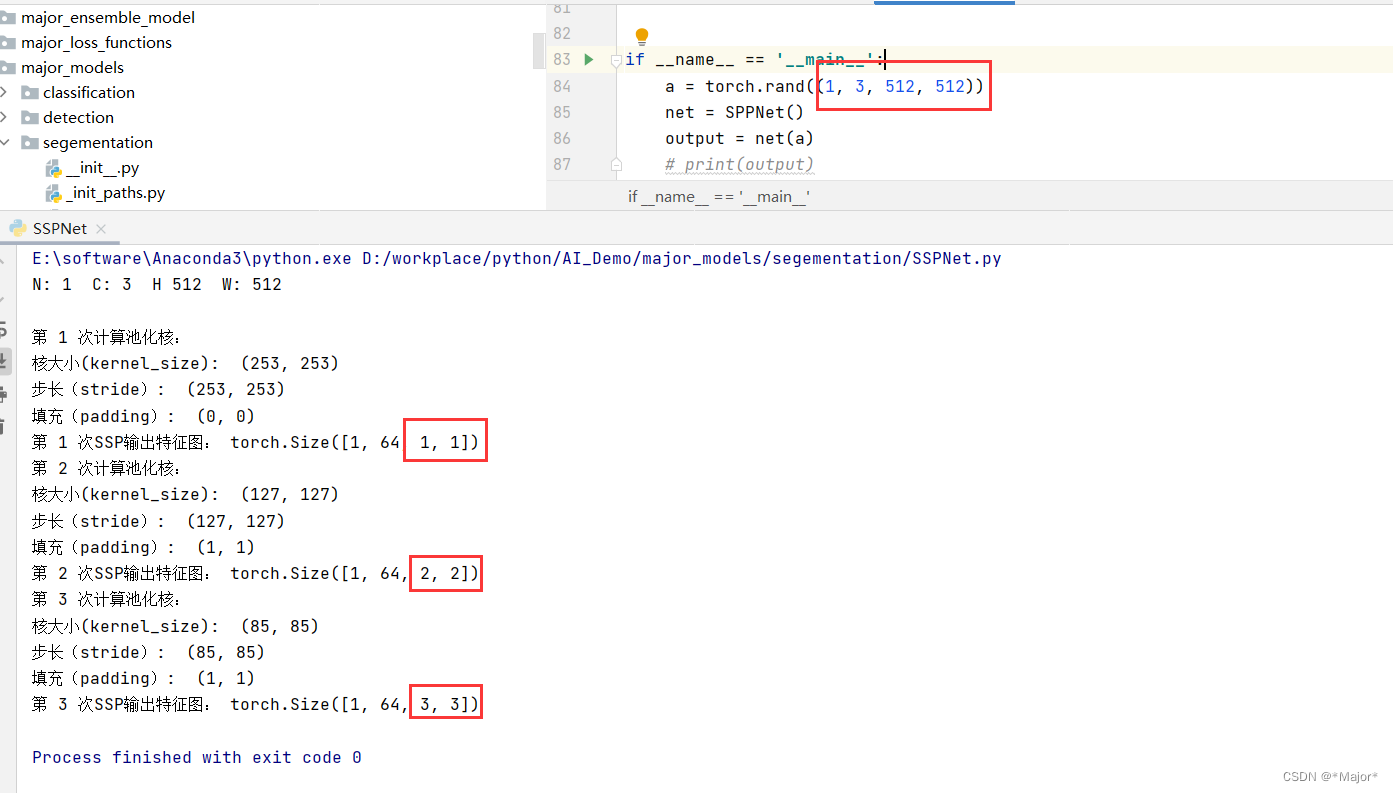
方法2:使用空间金字塔池化-SSP,一个固定输出大小的pooling(池化)操作,拥有了处理可变大小输入的能力,从而不固定输入大小,而是有固定输出大小
关键问题:SSP如何做到输出大小能够固定,其实是通过特定计算核大小(kernel_size)、步长(stride)、填充(padding)从而使输出为固定的大小的特征图
特定计算公式

代码实现
num_level = 3 # 3层池化卷积
N, C, H, W = input_img.size()
for i in range(num_level):
level = i + 1
print('第',level,'次计算池化核:')
kernel_size = (ceil(H / level), ceil(W / level))
print('核大小(kernel_size): ',kernel_size)
stride = (ceil(H / level), ceil(W / level))
print('步长(stride): ',stride)
padding = (floor((kernel_size[0] * level - H + 1) / 2), floor((kernel_size[1] * level - W + 1) / 2))
print('填充(padding): ',padding)
# 池化
res= F.max_pool2d(input_img, kernel_size=kernel_size, stride=stride, padding=padding)
示例如下:输入数据:torch.rand((1, 3, 256, 256))
示例如下:输入数据:torch.rand((1, 3, 512, 512))
from math import floor, ceil
import torch
import torch.nn as nn
import torch.nn.functional as F
class SSP2d(nn.Module):
def __init__(self, num_level, pool_type='max_pool'):
super(SSP2d, self).__init__()
self.num_level = num_level
self.pool_type = pool_type
def forward(self, x):
N, C, H, W = x.size()
# print('多尺度获取信息,并进行特征融合...')
print()
for i in range(self.num_level):
level = i + 1
print('第',level,'次计算池化核:')
kernel_size = (ceil(H / level), ceil(W / level))
print('核大小(kernel_size): ',kernel_size)
stride = (ceil(H / level), ceil(W / level))
print('步长(stride): ',stride)
padding = (floor((kernel_size[0] * level - H + 1) / 2), floor((kernel_size[1] * level - W + 1) / 2))
print('填充(padding): ',padding)
# print('进行最大池化并将提取特征展开:')
# print()
ttt = F.max_pool2d(x, kernel_size=kernel_size, stride=stride, padding=padding)
print('第',level,'次SSP输出特征图:', ttt.size())
if self.pool_type == 'max_pool':
# 拉成一维
tensor = (F.max_pool2d(x, kernel_size=kernel_size, stride=stride, padding=padding)).view(N, -1)
else:
tensor = (F.avg_pool2d(x, kernel_size=kernel_size, stride=stride, padding=padding)).view(N, -1)
if i == 0:
res = tensor
# print('展开大小为: ',res.size())
else:
res = torch.cat((res, tensor), 1)
# print('合并为: ',res.size())
return res
class SPPNet(nn.Module):
def __init__(self, num_level=3, pool_type='max_pool'):
super(SPPNet, self).__init__()
self.num_level = num_level
self.pool_type = pool_type
self.feature = nn.Sequential(nn.Conv2d(3, 64, 3),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(64, 64, 3),
nn.ReLU())
# num_grid = 1 + 4 + 9 = 14
self.num_grid = self._cal_num_grids(num_level)
self.spp_layer = SSP2d(num_level)
self.linear = nn.Sequential(nn.Linear(self.num_grid * 64, 512),
nn.Linear(512, 10))
def _cal_num_grids(self, level):
count = 0
for i in range(level):
count += (i + 1) * (i + 1)
return count
def forward(self, x):
#print('x初始大小为:')
N, C, H, W = x.size()
print('N:', N, ' C:', C, ' H', H, ' W:', W)
x = self.feature(x)
#print('x经过卷积、激活、最大池化、卷积、激活变成:')
N, C, H, W = x.size()
# print('64(conv)->62(maxpool)->31(conv)->29')
# print('N:', N, ' C:', C, ' H', H, ' W:', W)
# print('x进行空间金字塔池化:')
x = self.spp_layer(x)
# print('空间金字塔池化后,x进入全连接层:')
x = self.linear(x)
return x
if __name__ == '__main__':
a = torch.rand((1, 3, 512, 512))
net = SPPNet()
output = net(a)
# print(output)