【调研】详解Transformer结构——Attention Is All You Need
转载请注明出处:小锋学长生活大爆炸【xfxuezhang.blog.csdn.net】
以下内容均调研自网上,若有错误欢迎指正~~
目录:
- Background Introduction
- Model Structure
- Structure dismantling——Input
- Structure dismantling——Encoder
- Structure dismantling——Decoder
- Structure dismantling——Output
- Effectiveness and significance
- Pros and Cons
- How to implement Parallelism
- Improvements and Variants
- Vision-Transformer
- Open Source
- References


Transformer是一个完全依赖自注意力的面向sequence to sequence任务的NLP模型,由谷歌大脑在17年的论文《Attention is all you need》中首次提出。它抛弃了传统的CNN和RNN神经网络,整个网络结构完全由Attention机制以及前馈神经网络组成,它解决了RNN长期依赖和无法并行化以及CNN缺失全局特征等问题。(尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM依旧无能为力。)
Transformer可以被应用于许多领域,如文本、语音、医药、生物等等。在过去两年中发布的关于人工智能的arXiv论文中,有70%提到了transformer。并且斯坦福大学的研究人员在2021年8月的一篇论文中称transformer为“基础模型”,因为他们看到它推动了人工智能的范式转变。
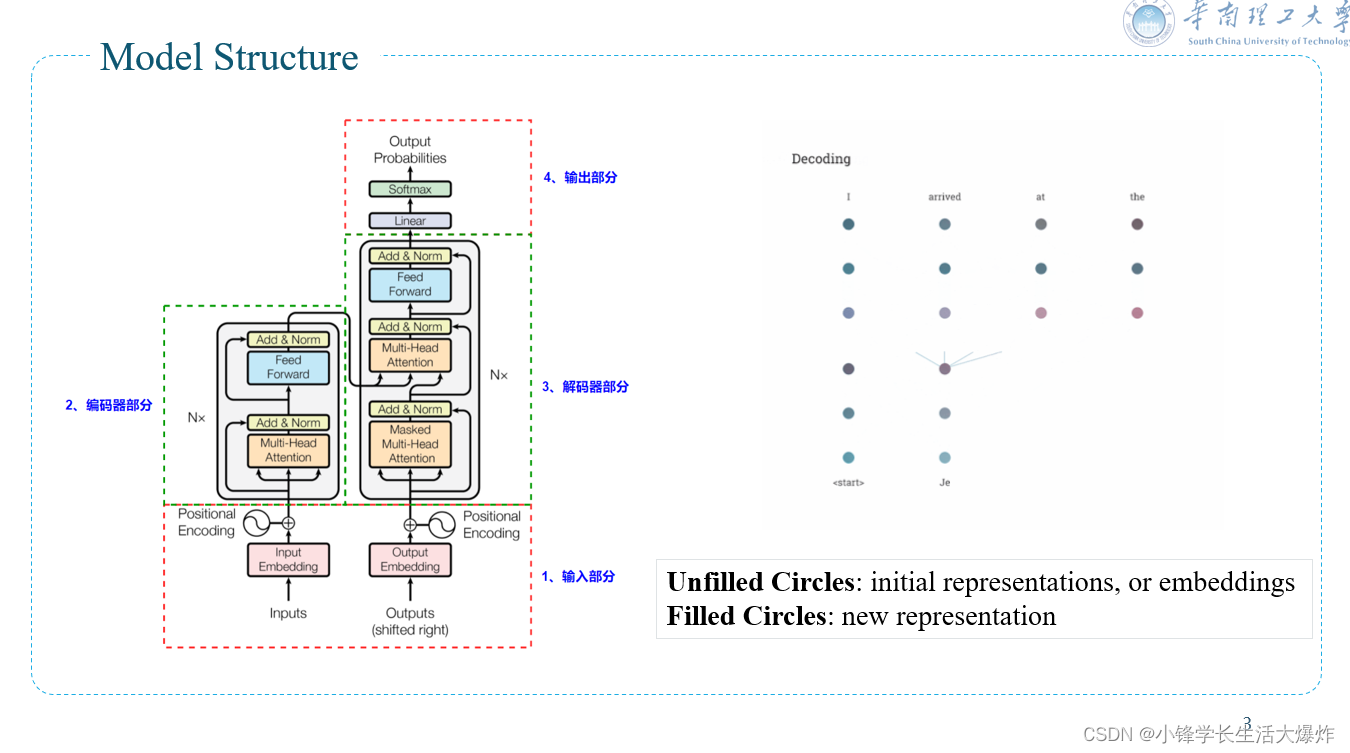
Transformer由四个部分组成,分别是输入部分、编码器部分、解码器部分以及输出部分。
输入字符首先通过嵌入转为向量,并加入位置编码来添加位置信息;
然后经过使用了多头自注意力和前馈神经网络的编码器和解码器来提取特征,最后全连接输出结果。
我们通过右边的动画,简单说明一下如何将transformer应用于机器翻译的。
机器翻译的神经网络通常包含一个编码器,它读取输入的句子并生成一个表示。
空心圆代表transformer为每个词生成的初始表示。
然后,解码器逐字生成输出句子,同时参考编码器生成的表示。
然后,利用自注意力,从所有其他的词中聚合信息,在整个上下文中为每个词生成一个新的表征,由实心圆来表示。
然后,这个步骤对所有的词平行地重复多次,连续地产生新的表示。
解码器的操作与此类似,但每次生成一个词,从左到右。它不仅关注其他先前生成的词,而且还关注编码器生成的最终表征。
下面将分别讲解一下这四个结构。

由于计算机无法直接处理非结构化的文本信息,因此需要将文本转换为向量。文本表示的方法有:one-hot 、整数编码、word embedding。Transformer选择第三种,在嵌入空间中,将每个单词都映射并分配一个特定的值。
如果模型没有捕捉顺序序列的能力,会导致无论句子的结构怎么打乱,都会得到类似的结果。由于 self-attention 没有循环结构,Transformer 需要一种方式来表示序列中元素的相对或绝对位置关系。为了解决这个问题,论文中在编码词向量时引入了位置编码的特征,这样Transformer就能区分不同位置的单词了。
对于加入位置信息,常见的模式有:根据数据学习和自己设计编码规则。试验后发现两种选择的结果是相似的,所以采用了第2种方法,优点是不需要训练参数,而且即使在训练集中没有出现过的句子长度上也能用。这里作者使用sin和cos函数来实现编码规则,其中, pos 表示单词的位置, i 表示单词的维度。作者这么设计的原因是考虑到在NLP任务中,除了单词的绝对位置,单词的相对位置也非常重要。根据公式 sin(α+β)=sinαcosβ+cosαsinβ 以及cos(α+β)=cosαcosβ−sinαsinβ ,这表明位置 k+p 的位置向量可以表示为位置 k 的特征向量的线性变化,这为模型捕捉单词之间的相对位置关系提供了非常大的便利。并且由于三角公式不受序列长度的限制,因此可以允许模型推断比训练期间遇到的更长的序列。(偶数位置用正弦,奇数位置用余弦)
经过输入部分后,文本已变成了向量,可以送入编码器了。

如前面seq2seq部分的同学介绍,encoder-decoder结构基本是seq2seq的标配。Encoder部分将输入向量提取特征并转为语义编码。
在transformer中,使用N个相同结构的block串联作为encoder(原论文中N=6),每个block分为2个子层。
为了对应,这里顺序倒了一下。我们设定模型的子层编号为从下往上排。
先看下面的第1个子层,其中使用到了多头自注意力。自注意力机制减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。而多头自注意力其实就是使用了多个自注意力,将embedding之后的向量按维度d_model=512 切割成h=8 个,分别做self-attention之后再合并在一起。(self-attention的特点在于无视词(token)之间的距离直接计算依赖关系,从而能够学习到序列的内部结构,实现也较为简单并且可以并行计算。)
最基础的 attention 有两种形式, 一种是 矩阵加法,一种是 矩阵点积。(虽然矩阵加法的计算更简单,但是Add 形式套着tanh和v,相当于一个完整的隐层)。在整体计算复杂度上两者接近,但是矩阵乘法已经有了非常成熟的加速实现。在dk较小的时候,两者的效果接近。但是随着d增大,Add开始显著超越Mul。作者分析 Mul 性能不佳的原因,认为是极大的点积值将整个 softmax 推向梯度平缓区,使得收敛困难,所以有了scaled。
这个scaled dot-product attention结构通过 Q 和 K 的相似性程度来确定 V 的权重分布。其中,在计算公式中,“根号dk分之一”是缩放因子,dk 表示 K 的维度,默认用 64。引入此比例因子是为了抵消点积在大值下大幅增长的影响。(因为对于 dk 很大的时候,点积得到的结果维度很大,使得结果处于softmax函数梯度很小的区域。这时候除以一个缩放因子,可以一定程度上减缓这种情况。)
不过论文中并没有对Multi-head Attention有很强的理论说明,因此后续有不少论文对Multi-head Attention机制都有一定的讨论。
上面的子层Feed Forward是一个两层的full-connect层,论文中前馈神经网络模块输入和输出的维度均为512,其内层的维度为2048。(这里使用FFN层的原因是:为了使用非线性函数来拟合数据。如果说只是为了非线性拟合的话,其实只用到第一层就可以了,但是这里为什么要用两层全连接呢,是因为第一层的全连接层计算后,其维度是(batch_size, seq_len, 2048) ,而使用第二层全连接层是为了进行维度变换,将2048转换为初始的512维。)
可以看到,每层之后都用到了归一化和残差链接。
归一化Norm在深度神经网络中非常重要,在transformer中用的是LayerNorm。它可以防止层中的值范围变化太大,这意味着模型训练得更快,并且具有更好的泛化能力。LN是对单个数据的指定维度进行Norm处理与batch无关。(使用ln而不是bn的原因是,因为输入序列的长度问题,每一个序列的长度不同,虽然会经过padding处理,但是padding的0值其实是无用信息,实际上有用的信息还是序列信息,而不同序列的长度不同,所以这里不能使用bn一概而论。)
每个子层的残差连接Add可以有效减小因层数加深而导致的梯度消失现象。

解码器可以看做是编码器的逆操作,作用是重新将语义信息转为向量输出。与encoder对应,decoder也使用N个相同结构的block串联而成(原论文中N=6)。
对于第一个大模块,即N个中的第一个,训练的时候每次的输入为上次的输入加上输入序列向后移一位的ground truth,也就是新的单词。实际中是一次性把目标序列的embedding输入第一个大模块中,然后在多头注意力模块对序列进行mask。
下面第一个子层的的Mask-Multi-Head-Attention就是在多头注意力上引入了mask掩码。
Transformer 模型里面涉及两种 mask,分别是在所有的 scaled dot-product attention 里面都需要用到的Padding Mask ,和在此处用到的Sequence Mask。Padding Mask是在较短的输入序列后面填充 0。而Sequence Mask的作用是将未来的信息遮掩,防止未来信息被提前利用,这里mask是一个下三角矩阵,即对角线以及对角线左下都是1,其余都是0。
上面两个子层与编码器部分相同,可以直接复用。唯一不同的是第二个子层的Q,K,V矩阵的来源,其Q矩阵来源于下面子模块的输出(对应到图中即为masked多头自注意力模块经过Add & Norm后的输出),而K,V矩阵则来源于整个Encoder端的输出,这里的交互模块就跟seq2seq with attention中的机制一样,目的就在于让Decoder端的单词(token)给予Encoder端对应的单词(token)“更多的关注(attention weight)”。
(解码阶段的每个时间步都输出一个元素。接下来会重复这个过程,直到输出一个结束符,表示 Transformer 解码器已完成其输出。每一步的输出都会在下一个时间步输入到下面的第一个解码器,解码器像编码器一样将解码结果显示出来。)

分类的深度神经网络的最后一层往往是全连接层+Softmax。
线性层又称全连接层,其每个神经元与上一层所有神经元相连,实现对前一层的线性组合/线性变换,主要用来转换维度。
Softmax即归一化指数函数,多用于多分类问题中。该层使最后一维的向量中的数字缩放到0-1的概率值域内, 并满足他们的和为1。计算公式如图,其中Vi表示原数据V中的第i个元素。
通过以上步骤后,就可以得出概率最大的类。

RNN、CNN和Transformer是目前在NLP中最常用的三个特征抽取器
1、语义特征提取能力
比较三者在‘考察语义类能力的任务’上的表现,比如翻译。Transformer >> 原生CNN == 原生RNN
2、长距离特征捕获能力
比较三者在“主语-谓语一致性检测”任务上的能力。Transformer == RNN >> CNN。对于Transformer来说,Multi-head attention的head数量严重影响NLP任务中长距离特征捕获能力:结论是head越多越有利于捕获长距离特征。
3、任务综合特征抽取能力
Transformer > 原生CNN == 原生RNN
4、并行计算能力及运算效率
transformer实际的计算复杂度是self-attention+全连接。(从复杂度上来说,单个Transformer Block计算量大于单层RNN和CNN。
但是结合可并行,就不一样了):
如果句子平均长度n大于embedding size,那么意味着Self attention的计算量要大于RNN和CNN;
如果反过来,就是说如果embedding size大于句子平均长度,那么明显RNN和CNN的计算量要大于self attention操作。
实际情况:一般正常的句子长度,平均起来也就几十个单词,embedding size从128到512都常见。
RNN比前两者慢了3倍到几十倍之间
(d是embedding size,n是句子长度)
1、单从任务综合效果方面来说,Transformer明显优于CNN和RNN,CNN略微优于RNN;
2、速度方面Transformer和CNN明显占优,RNN在这方面劣势非常明显。

Ø算法的并行性非常好,符合目前的硬件(主要指GPU)环境;(在Encoder端Transformer可以并行处理整个序列,并得到整个输入序列经过Encoder端的输出。Decoder的并行化仅在训练阶段,在测试阶段,因为我们没有正确的目标语句,t时刻的输入必然依赖t-1时刻的输出,这时跟之前的seq2seq就没什么区别了。Decoder的并行化可以通过teacher force和masked self attention来实现)
ØTransformer不仅仅可以应用在NLP的机器翻译领域,甚至可以不局限于NLP领域,是非常有科研潜力的一个方向。
--------------------------------------------------------------------------------------------------------------------
Ø丧失了捕捉局部特征的能力,RNN + CNN + Transformer的结合可能会带来更好的效果。
ØTransformer失去的位置信息其实在NLP中非常重要,而论文中在特征向量中加入Position Embedding也只是一个权宜之计,并没有改变Transformer结构上的固有缺陷。
Ø计算复杂度较高,达到了O(N方)
Ø很难在小规模的数据上进行训练(以vision transformer为例,对于原始的ViT在ImageNet中等及以下数据集(大概100多万)上,效果比相当的Resnet效果差;在ImageNet-21K(14M)上效果更好。这里的大数据集怎么界定,网上有说数据集在14M-300M算大,100多万算少,基本就是围绕ImageNet和JFT300M来说。为了解决小数据集问题,很多人对此进行了魔改,有些通过调整参数,也有的将CNN重新引入,或者在大数据集上进行预训练。)

在Encoder端Transformer可以并行处理整个序列,并得到整个输入序列经过Encoder端的输出。transformer中attention结构不一样,它是将每个时刻的输入信息之间的距离视为1,任意两个时刻的输入信息是可以直接交互运算的,没有了时序上的限制,attention结构就可以进行并行化计算了。attention中信息之间的交互计算是通过矩阵运算实现的,而矩阵运算是可以很好的进行并行计算的(scaled dot点积)。而RNN中t时刻信息与t-2时刻信息的交互必须要先经过t-1时刻。
Decoder的并行化仅在训练阶段,在测试阶段,因为我们没有正确的目标语句,t时刻的输入必然依赖t-1时刻的输出,这时跟之前的seq2seq就没什么区别了。
teacher force指在每一轮预测时,不使用上一轮预测的输出,而强制使用正确的单词。通过这样的方法可以有效的避免因中间预测错误而对后续序列的预测,从而加快训练速度。而Transformer采用这个方法,为并行化训练提供了可能,因为每个时刻的输入不再依赖上一时刻的输出,而是依赖正确的样本,而正确的样本在训练集中已经全量提供了。

为了更好地适应五花八门的下游任务,transformers已经被无限魔改了,成为了X-formers家族。
到2021年6月为止就已经有右图这么多的变体版本。
其中,提升点主要包括一下三个部分:
像比较熟悉的有CV的ViT、SOTR和DERT、NLP的BERT、Audio的Speech Transformer等等。

Transformer在NLP领域的成功应用, 使得相关学者开始探讨和尝试其在计算机视觉领域的应用一直以来, 卷积神经网络都被认为是计算机视觉的基础模型. 而Transformer的出现, 为视觉特征学习提供了一种新的可能. 基于Transformer的视觉模型在图像分类、目标检测、图像分割、视频理解、图像生成以及点云分析等领域取得媲美甚至领先卷积神经网络的效果.
ViT的总体想法是基于纯Transformer结构来做图像分类任务,论文中相关实验证明在大规模数据集上做完预训练后的ViT模型,在迁移到中小规模数据集的分类任务上以后,能够取得比CNN更好的性能。( 由于 Transformer 缺乏 CNN 固有的一些归纳偏置——例如平移等效性和局部性——它们在数据量不足的情况下不能很好地泛化。然而,作者发现在大型数据集(1400 万到 3 亿张图像)上训练模型超过了归纳偏置。当以足够的规模进行预训练时,Transformer 在具有较少数据点的任务上取得了出色的结果。
模型由三个模块组成:
这里有个小变动。ViT只用到了 Transformer 中的 Encoder,而并没有用到 Decoder,因而在最开头,还增加了一个可学习的嵌入向量Class Token,用于寻找其他几个输入向量对应的类别,进行分类预测。
流程:
1、将[224, 224, 3]的图⽚切分为14个[16, 16, 3]的patch,也即token。这样一张图就变成了sequence;
2、将每个patch转为[768]维的embedding,然后展平为[196, 768]。ViT中的位置编码没有采用原版 Transformer 中的 sin、cos编码,而是直接设置为可学习的参数。(对训练好的 Positional Encoding 进行可视化,如 图9 所示。我们可以看到,位置越接近,往往具有更相似的位置编码。此外,出现了行列结构,同一行/列中的 patch 具有相似的位置编码。),直接叠加在tokens上;
3、将Position embedding和tokens embedding相加,得到[197, 768];
4、输入encoder提取特征;其中,原本encoder中的Feed forward改成了MLP Block,并把Norm提前了。MLP Block就是全连接+GELU激活函数+Dropout组成,需要注意的是第一个全连接层会把输入节点个数翻4倍[197, 768] -> [197, 3072],第二个全连接层会还原回原节点个数[197, 3072] -> [197, 768]。
5、得到输出后,ViT中使用了 MLP Head对输出进行分类处理;(MLP Head原论文中说在训练ImageNet21K时是由Linear+tanh激活函数+Linear组成。但是迁移到ImageNet1K上或者你自己的数据上时,只用一个Linear即可。)
(在整合图⽚信息的时候,两种⽅式,⼀种是使⽤class token,另⼀种就是对所有tokens的输出做⼀个平均;实验结果证明,两者可以达到的同样的效果,只不过要控制好学习率。)
在论文中有给出三个模型(Base/ Large/ Huge)的参数。其中的Layers就是重复堆叠Encoder Block的次数,Hidden Size就是对应通过Embedding层后每个token的向量长度),MLP size是MLP Block第一个全连接的节点个数(是Hidden Size的四倍),Heads代表Multi-Head Attention的heads数。
(为什么Patch embedding和位置编码可以相加?=>很多解释,⼤家都在以果推因; 就是看到这个模型是这样做的,然后去推断这么做的原因; 记住就好;)


感谢看到这里~
确实内容还有待改进,比如“自注意力机制”应该重点讲,不过时间仓促没有添加,之后有时间可以补上!
小推荐,腾讯云的这款云GPU用于模型训练还不错,1元/天,详情可见:云产品特惠专区