深度学习数据集最常见的6大问题
文章目录
- 简介
- Q1 数据量不够
- Q2 低质量的分类
- Q3 低质量的数据
- Q4 不平衡的分类
- Q5 数据不平衡
- Q6 没有验证集和测试集
- 结论
简介
如果您还没有听过,请告诉您一个事实,作为一名数据科学家,您应该始终站在一个角落跟你说:“你的结果与你的数据一样好。”
尝试通过提高模型能力来弥补糟糕的数据是许多人会犯的错误。这相当于你因为原来的汽车使用了劣质汽油导致汽车表现不佳,而更换了一辆超级跑车。这种情况下应该做的是提炼汽油,而不是升级的车。在这篇文章中。我将向您解释如何通过提高数据集质量的方法来轻松获取更好的结果。
注意:我将以图像分类的任务为例,但这些技巧可以应用于各种数据集。
Q1 数据量不够
如果你的数据集过小,你的模型将没有足够多的样本,概括找到其中的特征,在此基础上拟合的数据,会导致虽然训练结果没太出错但是测试错误会很高。
解决方案1:收集更多数据。
您可以尝试找到更多的相同源做为您的原始数据集,或者从另一个相似度很高的源,再或者如果你绝对要来概括。
注意事项:这通常不是一件容易的事,需要投入时间和金钱。此外,你可能想要做一个分析,以确定你需要有多少额外的数据。将结果与不同的数据集大小进行比较,并尝试进行推断。
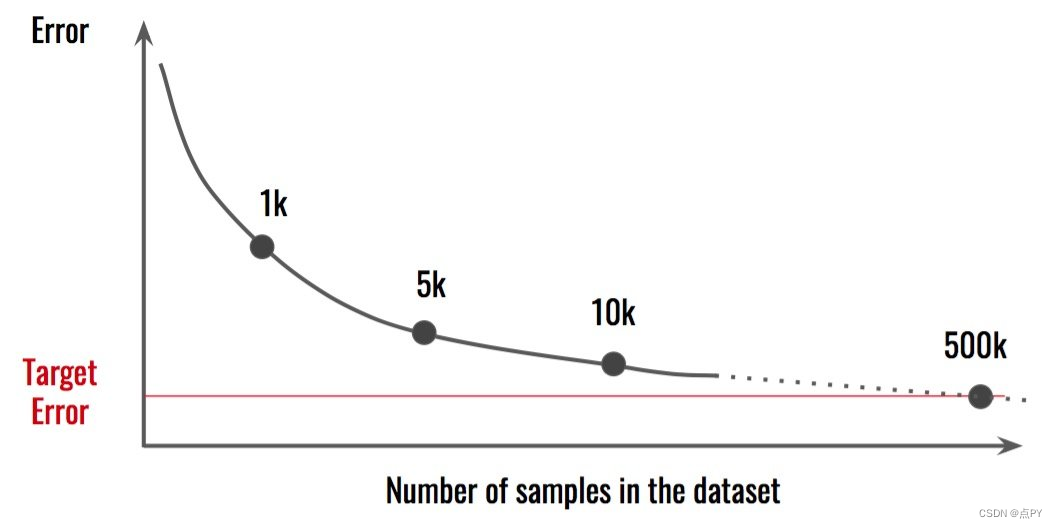
在这种情况下,似乎我们需要500k样本才能达到目标 误差。这意味着我们现在收集的数据量是目前的50倍。处理数据的其他方面或 模型可能更有效。
解决方案2:通过创建具有轻微变化的同一图像的多个副本来增强数据。
这种技术可以创造奇迹,并以极低的成本生成大量额外的图像。您可以尝试裁剪,旋转,平移或缩放图像。您可以添加 噪点,模糊,改变颜色或阻挡部分噪音。在所有情况下,您需要确保数据仍然代表同一个类。

所有这些图像仍然代表“猫”类别
这可能非常强大,因为堆叠这些效果会为您的数据集提供指数级的样本。请注意,这通常不如收集更多 原始 数据。

注意事项:所有增强技术可能无法用于您的问题。例如,如果要归类柠檬和酸橙,不与色相玩,因为这将是有意义颜色是对分类重要。

Q2 低质量的分类
这很简单,但如果可能的话,花些时间浏览一下您的数据集,并验证每个样本的标签。这可能需要一段时间,但在数据集中使用反例会对 学习过程产生不利影响。
此外,为您的类选择正确的粒度级别。根据问题,您可能需要更多或更少的类。例如,您可以使用全局分类器对小猫的图像进行分类,以确定它是动物,然后通过动物分类器运行它以确定它是小猫。一个巨大的模型可以做到这两点,但它会更难。
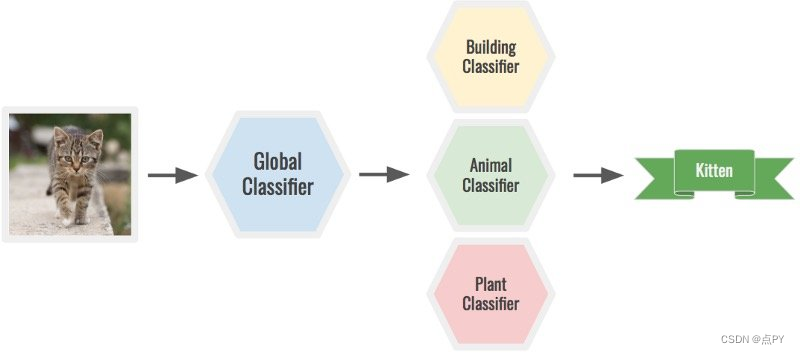
具有专门分类器的两阶段预测。
Q3 低质量的数据
如引言中所述,低质量数据只会导致低质量的结果。
数据集中的数据集中的样本可能与您要使用的数据集相差太远。这些可能会更混乱的模式不是很有帮助。
解决方案:删除最糟糕的图像。
这是一个漫长的过程,但会改善您的结果。

当然,这三个图像代表猫,但模型可能无法使用它。
另一个常见问题是当您的数据集由与真实世界应用程序不 匹配的数据组成时。例如,如果图像来自完全不同的来源。
解决方案:考虑技术的长期应用,以及将用于获取生产数据的方法。
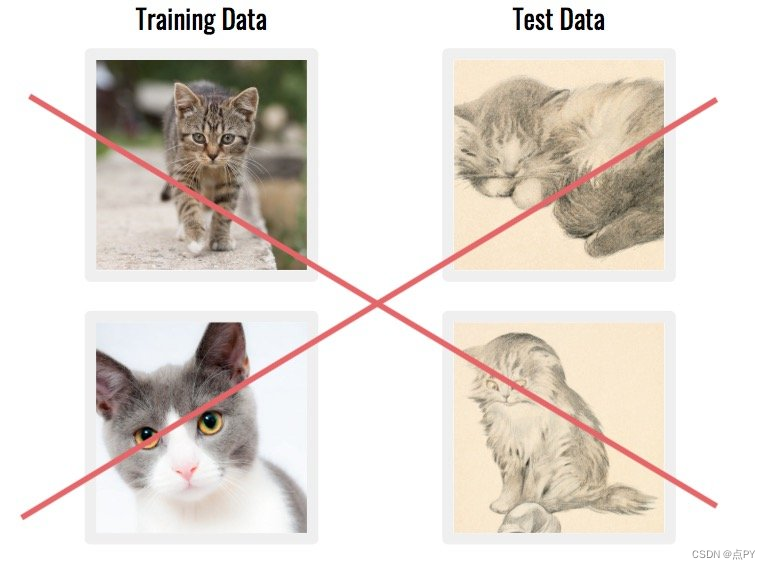
使用不代表您的真实世界应用程序的数据通常是一个坏主意。您的模型可能会提取在现实世界中无法使用的功能。
Q4 不平衡的分类
如果数每类样本的不是大致的相同的所有类,模型可能有利于统治阶级的倾向,因为它会导致一个较低的 错误。我们说该模型存在偏差,因为类分布是偏态的。这是一个严重的问题,也是您需要查看精度,召回或混淆矩阵的原因。
解决方案1:收集代表性不足的分类的更多样本。
然而,这在时间和金钱上通常 是昂贵的,或者根本不可行。
解决方案2:对数据进行过度/不足的采样。
这意味着您从过度表示的类中删除一些样本,或从代表不足的类中复制样本。比重复更好,使用数据增加,如前所述。
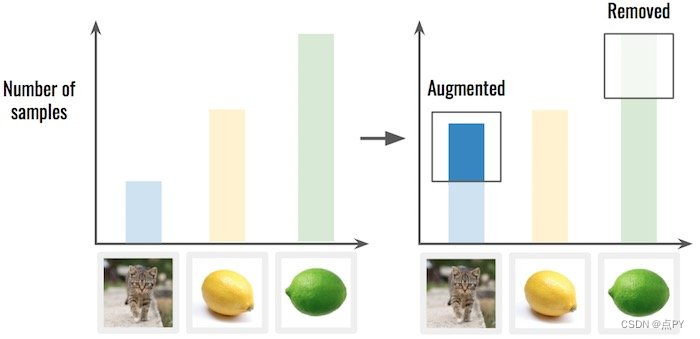
补充猫类图片,减少青柠的图片可以让数据集不同的分类更平衡
Q5 数据不平衡
如果您的数据没有特定 格式,或者值不在特定 范围内,则您的模型可能无法处理它。你将有形象,有更好的结果横宽比和像素值。
解决方案1:裁剪或拉伸数据,使其具有与其他样本相同的方面或格式。

两种可能性来改善格两种可能性来改善格式错误的图像式错误的图像。
解决方案2:规范化数据,使每个样本的数据都在相同的值范围内。

将值范围标准化为在整个数据集中保持一致。
Q6 没有验证集和测试集
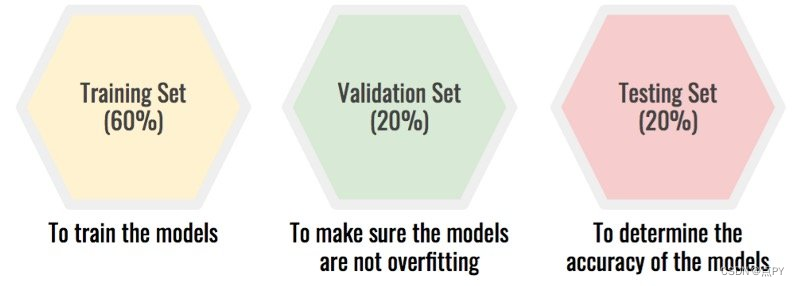
清理,扩充和正确标记数据集后,需要将其拆分。许多人通过以下方式将其拆分:80%用于训练,20%用于测试,这 使您可以轻松发现过度装配。但是,如果您在同一测试集上尝试多个模型,则会发生其他情况。通过选择具有最佳测试精度的模型,您实际上过度拟合了测试集。发生这种情况是因为您手动选择的模型不是其内在模型 值,但其性能上的特定数据集。
解决方案:将数据集拆分为三个:训练集、验证集、测试集。
该屏蔽你的测试被设置过度拟合由模型的选择。选择过程变为:
- 在训练集上训练你的模型。
- 在验证集上测试它们以确保没有过拟合。
- 选择最有希望的模型。在测试集上测试它,这将为您提供模型的真实准确性。
注意:一旦您选择了生产模型,请不要忘记在整个 数据集上进行训练!数据越多越好!
结论
我希望到现在你确信在考虑你的模型之前你必须注意你的数据集。您现在知道处理数据的最大错误,如何避免陷阱,以及如何构建杀手数据集的提示和技巧!如有疑问,请记住:“获胜者是不是一个最好的模式,这是一个最好的数据。”。