112-JavaSE基础进阶:XML的创建、文档约束、文件的解析技术-Dom4J、解析案例、文件的数据检索技术-XPath
XML
一、关于XML需要学会什么?
1、XML
- 在有些业务场景下,存储数据或者传输数据给别人的时候,数据需要满足一定的规范进行组织。
2、XML解析技术
- XML文件中存储的数据是需要提取出来的。
3、XPath
- 如何方便的在XML文件中进行数据的检索(查询)?
4、设计模式
- 开发中还有一些比较常见的设计模式是需要掌握的,理解设计模式有利于理解某些程序。
二、XML
1、概述
-
XML是可扩展标记语言(eXtensible Markup Language)的缩写,它是一种
数据表示格式,可以描述非常复杂的数据结构,常用于传输和存储数据。
(1)XML的特点和使用场景
-
特点:
- 纯文本,默认使用UTF-8编码;
- 如果把XML内容存为文件,那么它就是一个XML文件。
-
XML的使用场景:
-
XML内容经常被当成消息进行网络传输,或者作为配置文件用于存储系统的信息。
-
举个例子:
- 假如你在淘宝买了一个东西,然后快递是由顺丰负责,这时顺丰系统就需要将客户的物流信息传输给淘宝系统;
- 如果直接传输一大串文字,淘宝系统当然会懵逼掉;
- 因此他们就约定好,使用XML格式来发,这样淘宝系统就能识别到顺丰系统传输过来的数据了。

-
总结
- XML是什么?
- XML的全称为:EXtensible Markup Language,是一种可扩展的标记语言。
- 它是一种数据表示格式,可以用于自定义数据格式。
- XML的作用是什么?
- 用于进行存储数据和传输数据。
- 作为软件的配置文件。
2、XML的创建、语法规则
- 就是创建一个
XML类型的文件,要求文件的后缀必须使用xml,如hello_world.xml。
(1)IDEA创建XML文件的操作步骤
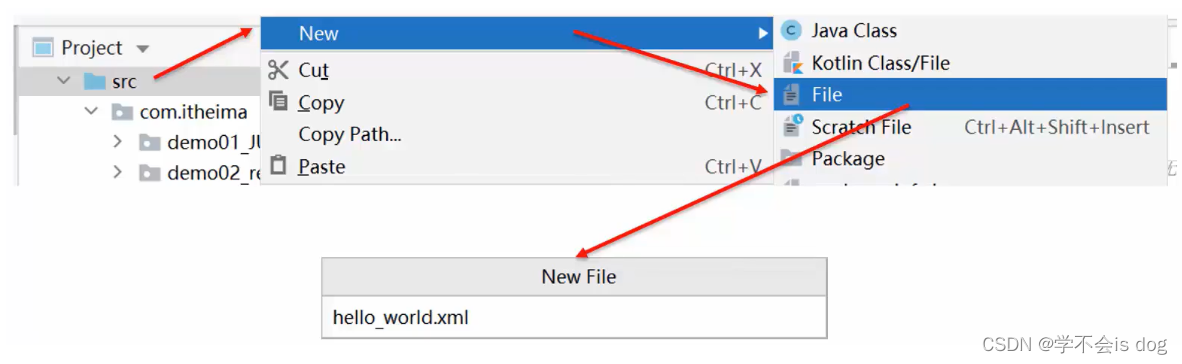
(2)XML的语法规则
-
XML文件的后缀名为:
xml -
文档声明必须是:
第一行
A. XML的标签(元素)规则
-
标签由一对尖括号和合法标识符组成:
<name></name>,必须存在一个根标签,有且只能有一个。 -
标签必须成对出现,有开始,有结束:
<name></name> -
特殊的标签可以不成对,但是必须有结束标记,如:
<br/> -
标签中可以定义属性,属性和标签名用空格隔开,属性值必须用引号引起来:
<student id="1"></student> -
标签需要正确嵌套:


B. 范例一
<?xml version="1.0" encoding="UTF-8" ?>
<student>
<name>女儿国王</name>
<sex>女</sex>
<hobby>唐僧,追唐僧</hobby>
<info>
<age>27</age>
<address>女儿国</address>
</info>
</student>
C. XML的其他组成
-
XML文件中可以定义注释信息:
<!-- 注释内容 --> -
XML文件中可以存在以下特殊字符
< < 小于 > > 大于 & & 和号 ' ' 单引号 " " 引号 -
XML文件中可以存在CDATA区:
<![CDATA[内容...]]>
D. 范例二
<?xml version="1.0" encoding="UTF-8" ?>
<!-- version: XML默认的版本号码; encoding: 本XML文件的编码 -->
<!-- 根标签有且仅能有一个 -->
<student>
<!-- 标签必须成对出现,有开始、结束 -->
<name>女儿国王</name>
<sex>女</sex>
<hobby>唐僧,追唐僧</hobby>
<info>
<age>27</age>
<address>女儿国</address>
</info>
<!-- 特殊的标签可以不成对,但必须有结束标记 -->
<br/>
<!-- sql数据库语句:
JavaWeb会学的,目前不需要理解语句的意思,只需要理解以下特殊字符即可:
< ——>代表 <: 小于
> ——>代表 >: 大于
& ——>代表 &: 和号
' ——>代表 ': 单引号
" ——>代表 ": 引号
-->
<sql>
<!-- 这一句sql语句的小于符号会报错!需要用 < 来代替 -->
select * from user where age < 18;
<!-- 这一句sql语句的小于符号、和符号会报错!需要用 < & 来代替 -->
select * from user where age < 18 && > 10;
</sql>
<!-- 如果觉得用那些特殊字符来代替某些符号太麻烦的话,可以使用CDATA区: <![CDATA[内容...]]> -->
<![CDATA[
select * from user where age < 18;
select * from user where age < 18 && > 10;
]]>
</student>
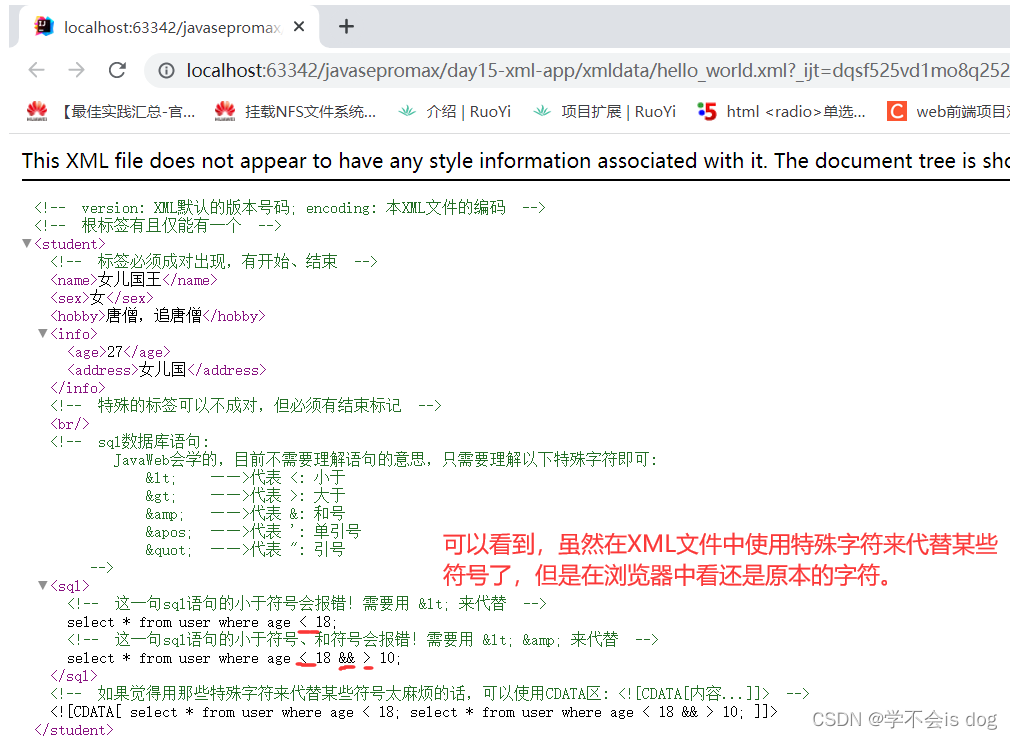
总结
- XML的组成格式要求是啥?
- 文件后缀名是
xml - 文档声明必须是
第一行 - 必须存在一个根标签,
有且只能有一个 - XML文件中可以定义注释信息:
<!-- 注释内容 --> - 标签必须成对出现,有开始、结束标签:
<student></student> 必须能够正确的嵌套标签
- 文件后缀名是
3、什么是文档约束?
- 文档约束:
- 是用来限定xml文件中的标签以及属性应该如何定义。
- 以此强制约束程序员必须按照文档约束的规定来编写xml文件。
- 是用来限定xml文件中的标签以及属性应该如何定义。
问题:
-
由于XML文件可以自定义标签,导致XML文件可以随意定义,程序在解析的时候可能出现问题。

4、文档约束的分类
- DTD
- schema
5、XML文档约束方式一:DTD约束[了解]
(1)DTD使用
-
需求:
- 利用DTD文档约束,约束一个XML文件的编写。
-
分析:
-
1、编写DTD约束文档,后缀必须是:
.dtd
-
2、在需要编写的XML文件中导入该DTD约束文档
-
3、按照约束的规定编写XML文件的内容
-
-
实现:
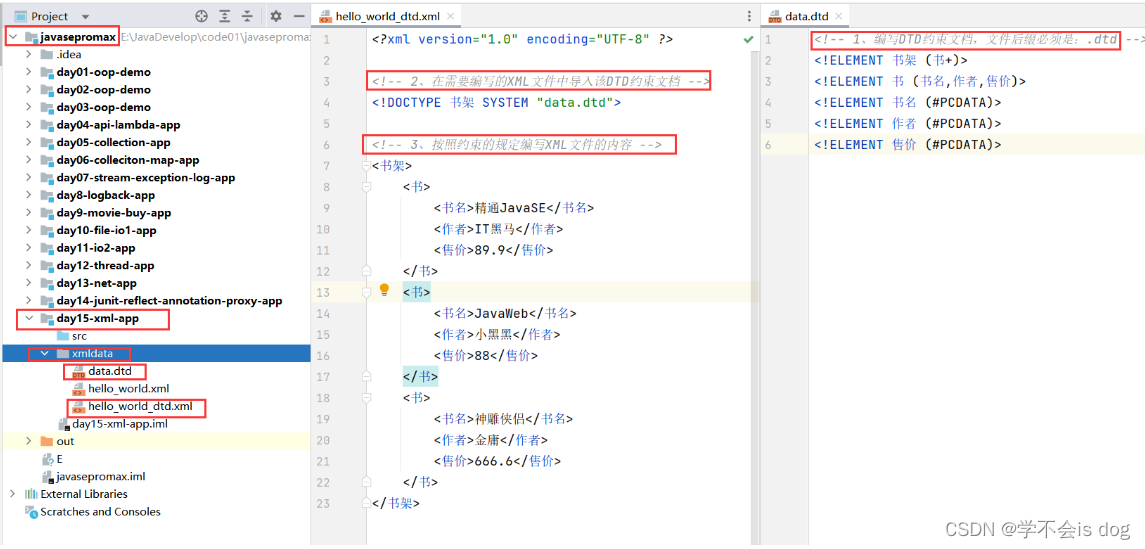
<!-- 1、编写DTD约束文档,文件后缀必须是:.dtd --> <!ELEMENT 书架 (书+)> <!ELEMENT 书 (书名,作者,售价)> <!ELEMENT 书名 (#PCDATA)> <!ELEMENT 作者 (#PCDATA)> <!ELEMENT 售价 (#PCDATA)><?xml version="1.0" encoding="UTF-8" ?> <!-- 2、在需要编写的XML文件中导入该DTD约束文档 --> <!DOCTYPE 书架 SYSTEM "data.dtd"> <!-- 3、按照约束的规定编写XML文件的内容 --> <书架> <书> <书名>精通JavaSE</书名> <作者>IT黑马</作者> <售价>89.9</售价> </书> <书> <书名>JavaWeb</书名> <作者>小黑黑</作者> <售价>88</售价> </书> <书> <书名>神雕侠侣</书名> <作者>金庸</作者> <售价>666.6</售价> </书> </书架>
总结
-
XML的文档约束:DTD的作用和问题?
-
作用:
-
可以约束XML文件的编写。

-
-
问题:
-
不能约束具体的数据类型。
-
-
6、XML文档约束方式二:schema约束[了解]
-
schema可以约束具体的数据类型,约束能力上更强大。
-
schema本身也是一个xml文件,本身也受到其他约束文件的要求,所以编写的更加严谨。
(1)schema使用
-
需求:
- 利用schema文档约束,约束一个XML文件的编写。
-
分析:
- 1、编写schema约束文档,后缀必须是:
.xsd。 - 2、在需要编写的XML文件中导入该schema约束文档。
- 3、按照约束内容编写XML文件的标签。
- 1、编写schema约束文档,后缀必须是:
-
实现:
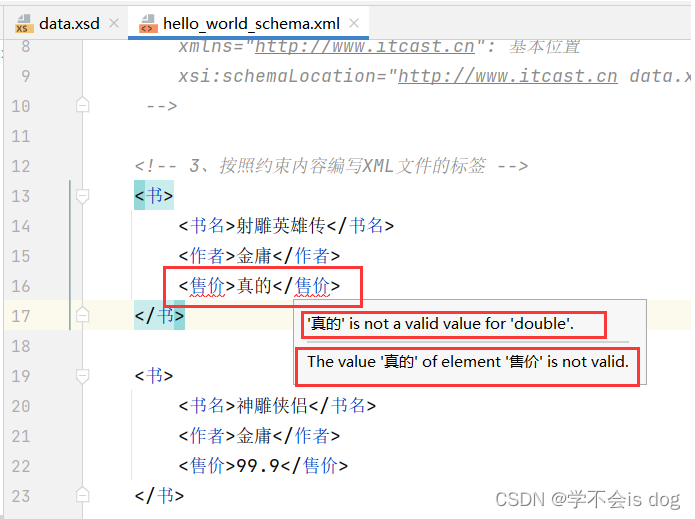
<?xml version="1.0" encoding="UTF-8" ?> <!-- 1、编写schema约束文档,后缀必须是:.xsd --> <!-- targetNamespace: 申明约束文档的地址(命名空间:相当于包名) --> <schema xmlns="http://www.w3.org/2001/XMLSchema" targetNamespace="http://www.itcast.cn" elementFormDefault="qualified"> <element name="书架"> <!-- 写子元素 --> <complexType> <!-- maxOccurs='unbounded': 书架下的子元素可以有任意多个!(无边界) --> <sequence maxOccurs="unbounded"> <element name="书"> <!-- 写子元素 --> <complexType> <!-- 不指定边界,说明书下的子元素只能有一个 --> <sequence> <!-- type="string": 约束编写的数据类型 --> <element name="书名" type="string"/> <element name="作者" type="string"/> <element name="售价" type="double"/> </sequence> </complexType> </element> </sequence> </complexType> </element> </schema><?xml version="1.0" encoding="UTF-8" ?> <!-- 2、在需要编写的XML文件中导入该schema约束文档 --> <书架 xmlns="http://www.itcast.cn" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.itcast.cn data.xsd"> <!-- xmlns="http://www.itcast.cn": 基本位置 xsi:schemaLocation="http://www.itcast.cn data.xsd": 具体的位置 --> <!-- 3、按照约束内容编写XML文件的标签 --> <书> <书名>射雕英雄传</书名> <作者>金庸</作者> <售价>566</售价> </书> <书> <书名>神雕侠侣</书名> <作者>金庸</作者> <售价>99.9</售价> </书> <书> <书名>三国演义</书名> <作者>罗贯中</作者> <售价>67.5</售价> </书> </书架>
总结
-
XML的文档约束:schema的优点?
-
可以约束XML文件的标签内容格式,以及具体的数据类型。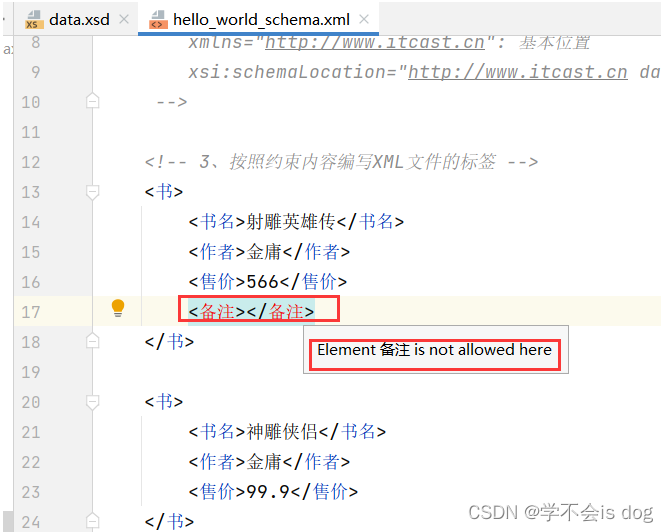
-
三、XML解析技术
1、概述
- XML的数据的作用是什么?最终需要怎么处理?
- 存储数据、做配置信息、进行数据传输。
- 最终需要被程序进行读取,解析里面的信息。
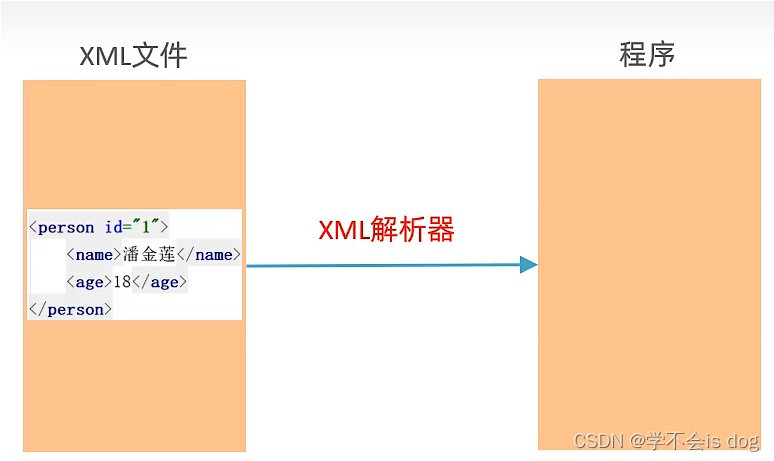
(1)什么是XML解析?
-
使用程序读取XML中的数据
(2)两种解析方式
- SAX解析
- 一行一行解析,适合解析大文件。
- DOM解析
- 直接将XML文件加载到内存中,当成一棵树来解析。
- 适合解析小文件
(3)Dom常见的解析工具
| 名称 | 说明 |
|---|---|
| JAXP | SUN公司提供的一套XML的解析的API |
| JDOM | JDOM是一个开源项目,它基于树型结构,利用纯Java的技术对XML文档实现解析、生成、序列化以及多种操作。 |
dom4j | 是JDOM的升级品,用来读写XML文件的。 具有性能优异、功能强大和极其易使用的特点,它的性能通过sun公司官方的dom技术,同时它也是一个开放源代码的软件,Hibernate也用它来读写配置文件。 |
| jsoup | 功能强大DOM方式的XML解析开发包,尤其对HTML解析更加方便。 |
(4)DOM解析文档对象模型
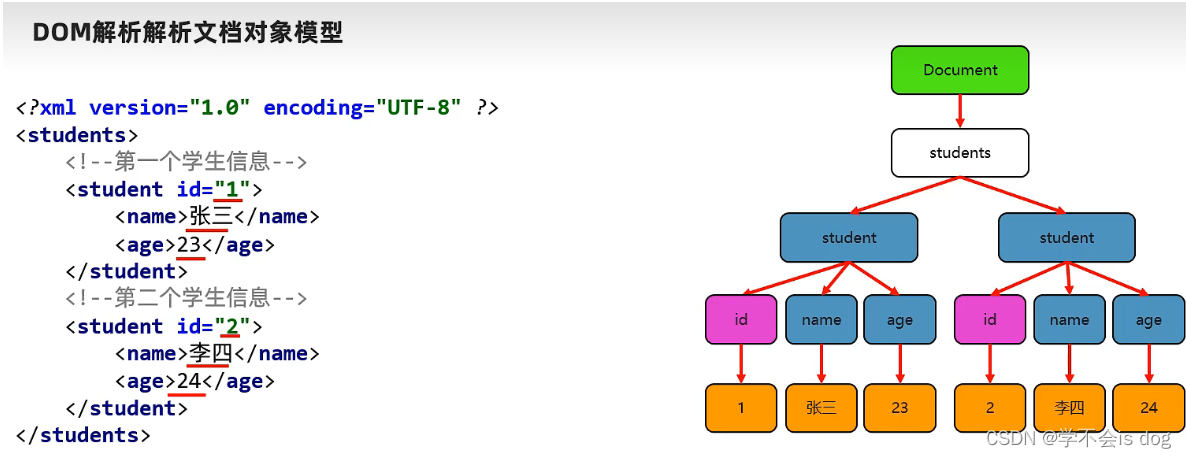
- Document对象:整个xml文档
- Node对象:
- Element对象:标签
- Attribute对象:属性
- Text对象:文本内容
总结
- Dom解析的文档对象模式是啥样的?
- Document对象:整个xml文档
- Node对象:
- Element对象:标签
- Attribute对象:属性
- Text对象:文本内容
- Dom解析常用技术框架?
- Dom4J
2、Dom4J解析XML文件
(1)Dom4J解析XML:得到Document对象的API
-
SAXReader类
构造器/方法 说明 public SAXReader() 创建Dom4J的解析器对象 Document read(String url) 加载XML文件成为Document对象
-
Document类
方法名称 说明 Element getRootElement() 获取根元素对象
(2)Dom4J使用
-
需求:
- 使用Dom4J把一个XML文件的数据进行解析
-
分析:
-
1、下载Dom4J框架,官网下载(属于第三方)。
- 可以全部下载下来,单击就可以
-
2、在项目中创建一个文件夹:lib。

-
3、将dom4j-2.1.1.jar文件复制到 lib 文件夹。
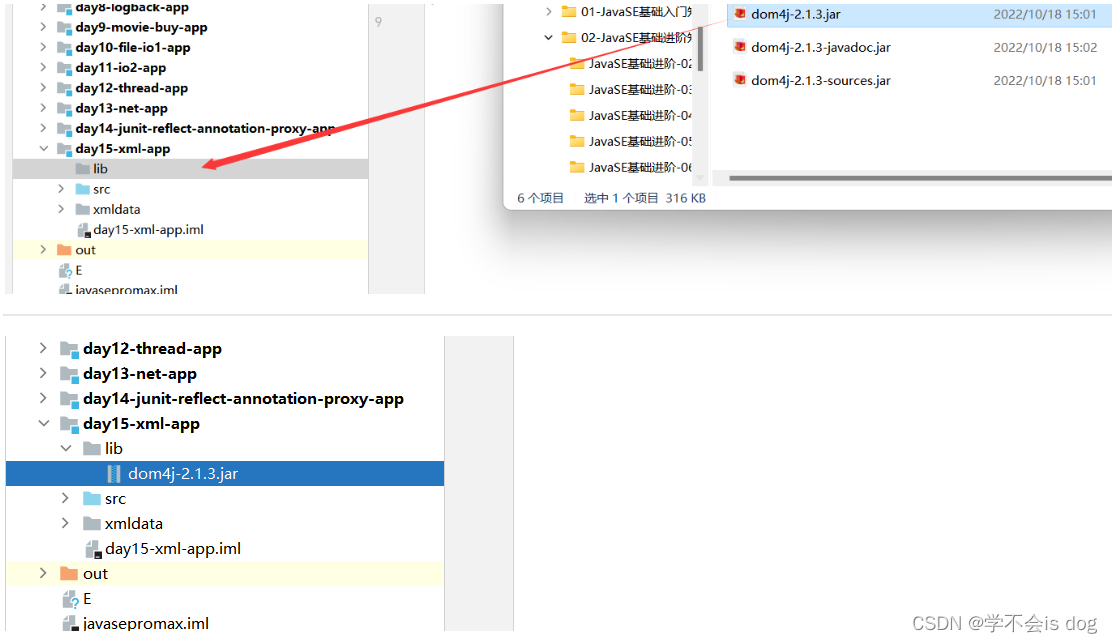
-
4、在jar文件上点右键,选择 Add as Library ——> 点击OK(把jar包加载到依赖库)。
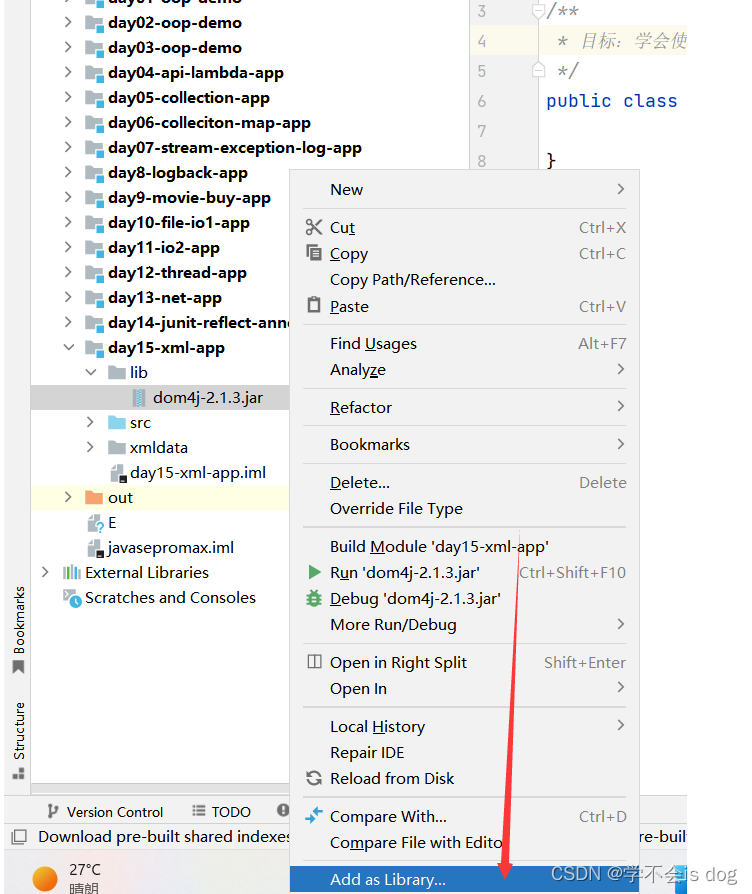
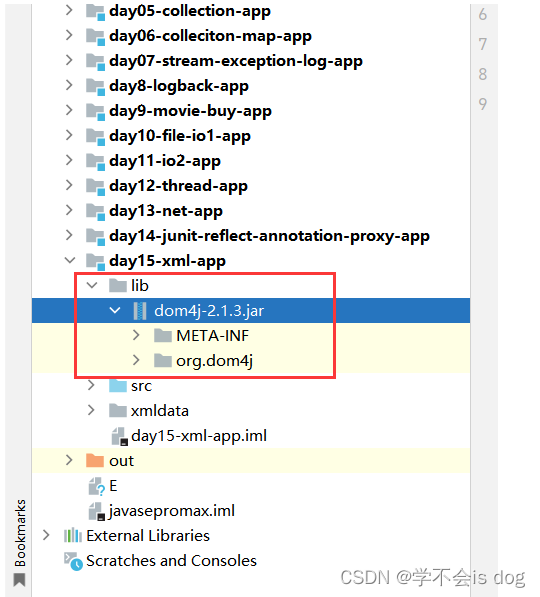
-
5、在类中导包使用。
-
先创建一个xml文件,作为被解析的xml文件
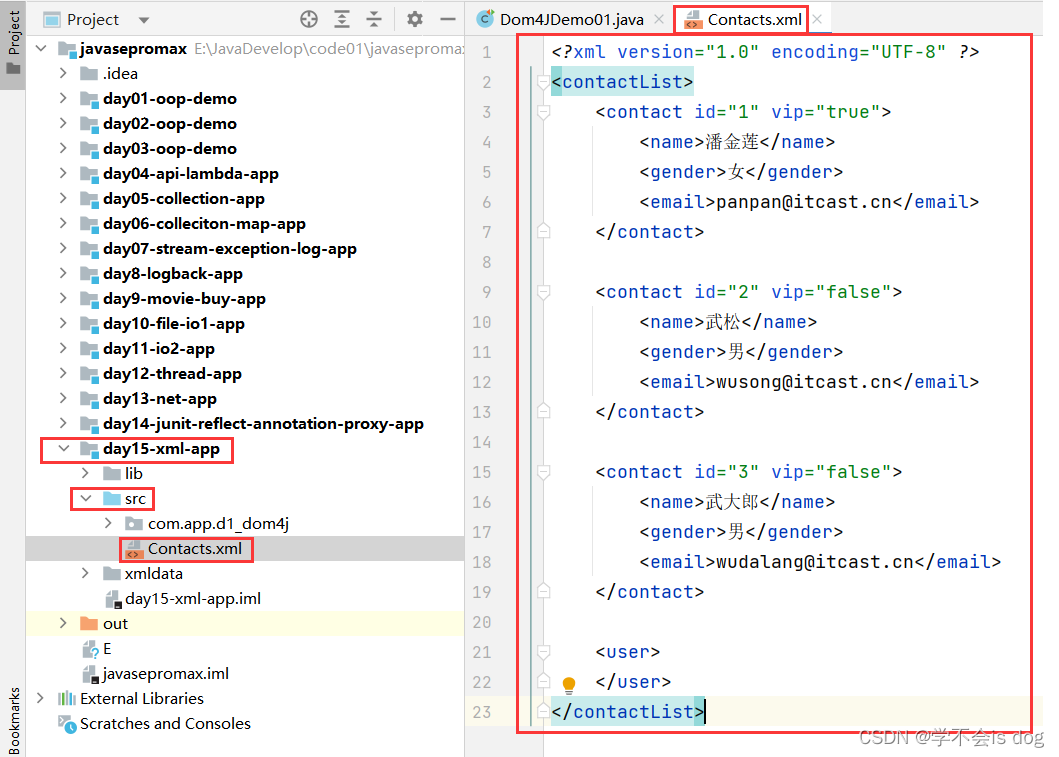
-
然后创建一个类,再创建一个测试方法:
package com.app.d1_dom4j; import org.dom4j.Document; import org.dom4j.Element; import org.dom4j.io.SAXReader; import org.junit.Test; import java.io.File; import java.io.InputStream; /** * 目标:学会使用Dom4J解析XML文件中的数据。 */ public class Dom4JDemo01 { @Test public void parseXMLData() throws Exception { // 1、创建一个Dom4J的解析器对象,代表了整个dom4j框架 SAXReader saxReader = new SAXReader(); // 2、把XMl文件加载到内存中成为一个Document文档对象 // 不推荐:因为一旦改了模块名,就会找不到该xml文件 // Document document = saxReader.read(new File("day15-xml-app/src/Contacts.xml")); // 推荐——>注意:getResourceAsStream()方法中的 "/" 是直接到 src 下寻找文件的。 InputStream is = Dom4JDemo01.class.getResourceAsStream("/Contacts.xml"); Document document = saxReader.read(is); // 3、获取根元素 Element rootElement = document.getRootElement(); System.out.println("根元素名:" + rootElement.getName()); } } -
运行:
-
-
3、Dom4J解析XML文件中的各种节点
(1)Dom4J解析XML的元素、属性、文本的API
| 方法名称 | 说明 |
|---|---|
| List< Element > elements() | 获取当前元素下的所有子元素,返回集合 |
| List< Element > elements(String name) | 获取当前元素下指定名字的子元素,返回集合 |
| Element element(String name) | 获取当前元素下指定名字的子元素,如果有很多名字相同的返回第一个 |
| String getName() | 得到元素名字 |
| String attributeValue(String name) | 通过属性名直接获取属性值 |
| String elementText(子元素名) | 获取指定名称的子元素的文本 |
| String getText() | 获取文本 |
(2)范例
package com.app.d1_dom4j;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.junit.Test;
import java.io.InputStream;
import java.util.List;
/**
* 目标:学会使用Dom4J解析XML文件中的各种节点:元素、属性、文本
*/
public class Dom4JDemo02 {
/**
* 定义一个方法,解析指定的XML文件中的各种节点:
* 元素、属性、文本
*/
@Test
public void parseXMLData() throws Exception {
// 1、创建一个Dom4J的解析器对象,代表整个Dom4J框架
SAXReader saxReader = new SAXReader();
// 2、将指定的XML文件加载到内存中,成为一个Document文档对象
InputStream is = Dom4JDemo02.class.getResourceAsStream("/Contacts.xml"); // 通过类对象找到src下的文件
Document document = saxReader.read(is);
// 3、获取根元素
Element rootElement = document.getRootElement();
System.out.println("根元素名:" + rootElement.getName());
System.out.println("-----------------------------");
// 4、获取当前根元素下的所有子元素,并遍历输出返回的集合
List<Element> elements = rootElement.elements();
System.out.println("当前根元素下的所有子元素:");
forEachElements(elements);
System.out.println("-----------------------------");
// 5、获取当前根元素下的所有名字为contact的子元素,并遍历输出返回的集合
List<Element> contacts = rootElement.elements("contact");
System.out.println("当前根元素下的所有名字为contact的子元素:");
forEachElements(contacts);
System.out.println("-----------------------------");
// 6、获取当前元素下指定名字的子元素(如果有多个,则返回第一个子元素)
Element contact = rootElement.element("contact");
// 7、得到元素名字
System.out.println("元素名:" + contact.getName());
System.out.println("-----------------------------");
// 8、获取contact元素下的所有子元素,并遍历输出返回的集合
List<Element> contactEles = contact.elements();
System.out.println("contact元素下的所有子元素:");
forEachElements(contactEles);
System.out.println("-----------------------------");
// 9、根据元素获取属性值
Attribute id = contact.attribute("id");
System.out.println("属性名:" + id.getName() + ",属性值:" + id.getValue());
Attribute vip = contact.attribute("vip");
System.out.println("属性名:" + vip.getName() + ",属性值:" + vip.getValue());
System.out.println("-----------------------------");
// 10、获取指定名称的子元素文本
String name = contact.elementText("name");
String name1 = contact.elementTextTrim("name"); // 去掉前后空格
String gender = contact.elementText("gender");
String email = contact.elementText("email");
System.out.println("name:" + name);
System.out.println("name1:" + name1);
System.out.println("gender:" + gender);
System.out.println("email:" + email);
System.out.println("-----------------------------");
// 11、通过属性名直接获取属性值
String id1 = contact.attributeValue("id");
System.out.println(id1);
String vip1 = contact.attributeValue("vip");
System.out.println(vip1);
System.out.println("-----------------------------");
// 12、获取文本
Element email1 = contact.element("email");
String text = email1.getText();
System.out.println(text);
}
/**
* 定义一个遍历所有子元素集合的方法
* @param elements 所有子元素的集合
*/
public void forEachElements(List<Element> elements){
for (Element element : elements) {
System.out.println(element.getName());
}
}
}
根元素名:contactList
-----------------------------
当前根元素下的所有子元素:
contact
contact
contact
user
-----------------------------
当前根元素下的所有名字为contact的子元素:
contact
contact
contact
-----------------------------
元素名:contact
-----------------------------
contact元素下的所有子元素:
name
gender
email
-----------------------------
属性名:id,属性值:1
属性名:vip,属性值:true
-----------------------------
name: 潘金莲
name1:潘金莲
gender:女
email:panpan@itcast.cn
-----------------------------
1
true
-----------------------------
panpan@itcast.cn
Process finished with exit code 0
总结
- Dom4J的解析思想?
- 得到文档对象Document,从中获取元素对象和内容。
4、Dom4J解析XML文件:案例实战
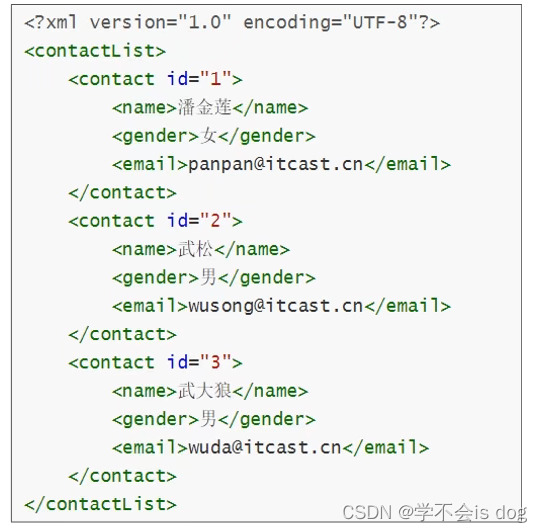
-
Contact.xml文件
-
需求:
-
利用Dom4J的知识,将Contact.xml文件中的联系人数据封装成List集合,其中每个元素是实体类Contact。
-
打印输出 List中的每个元素:

-
-
实现:
<?xml version="1.0" encoding="UTF-8" ?> <contactList> <contact id="1" vip="true"> <name>潘金莲</name> <gender>女</gender> <email>panpan@itcast.cn</email> </contact> <contact id="2" vip="false"> <name>武松</name> <gender>男</gender> <email>wusong@itcast.cn</email> </contact> <contact id="3" vip="false"> <name>武大郎</name> <gender>男</gender> <email>wudalang@itcast.cn</email> </contact> <user> </user> </contactList>package com.app.d2_dom4j_test; /** * 1、创建Contact联系人对象,用于封装解析XML文件后得到的联系人数据 */ public class Contact { /** * 联系人属性必须对应着XML文件中的联系人数据来写 */ private int id; // 编号 private boolean vip; // vip private String name; // 姓名 private char gender; // 性别 private String email; // 邮箱 public Contact() { } public Contact(int id, boolean vip, String name, char gender, String email) { this.id = id; this.vip = vip; this.name = name; this.gender = gender; this.email = email; } public int getId() { return id; } public void setId(int id) { this.id = id; } public boolean isVip() { return vip; } public void setVip(boolean vip) { this.vip = vip; } public String getName() { return name; } public void setName(String name) { this.name = name; } public char getGender() { return gender; } public void setGender(char gender) { this.gender = gender; } public String getEmail() { return email; } public void setEmail(String email) { this.email = email; } @Override public String toString() { return "Contact{" + "id=" + id + ", vip=" + vip + ", name='" + name + '\'' + ", gender=" + gender + ", email='" + email + '\'' + '}'; } }package com.app.d2_dom4j_test; import org.dom4j.Document; import org.dom4j.Element; import org.dom4j.io.SAXReader; import org.junit.Test; import java.util.ArrayList; import java.util.List; /** * 目标:Dom4J解析XML文件的案例实战 * 需求: * 利用Dom4J的知识,将Contact.xml文件中的联系人数据封装成List集合,其中每个元素是实体类Contact; * 打印输出List中的每个元素(联系人数据) */ public class Dom4JTest01 { /** * 定义一个测试方法:解析XML文件数据到List集合中 */ @Test public void parseXMLDataToList() throws Exception { // 1、创建一个Dom4J的解析器对象 SAXReader saxReader = new SAXReader(); // 2、将指定的XML文件加载到内存中,成为一个文档Document对象 Document document = saxReader.read(Dom4JTest01.class.getResourceAsStream("/Contacts.xml")); // 3、获取根元素 Element rootElement = document.getRootElement(); // 4、获取当前根元素下的名字为contact的所有子元素 List<Element> contactElements = rootElement.elements("contact"); // 6、创建一个ArrayList集合,用于存储封装好的联系人对象 List<Contact> contactList = new ArrayList<>(); // 7、遍历所有名字为contact的子元素 for (Element contactElement : contactElements) { // 8、开始解析XML文件中的联系人数据,封装成一个Contact对象 Contact contact = new Contact(); // 开始封装数据 contact.setId(Integer.valueOf(contactElement.attributeValue("id"))); // 字符串转换成int类型 contact.setVip(Boolean.valueOf(contactElement.attributeValue("vip"))); // 字符串转换成boolean类型 contact.setName(contactElement.elementTextTrim("name")); contact.setGender(contactElement.elementTextTrim("gender").charAt(0)); // 取索引位置为0的字符 contact.setEmail(contactElement.elementTextTrim("email")); // 9、将封装好的联系人对象添加到contactList集合 contactList.add(contact); } // 10、遍历联系人集合,输出展示 System.out.println("联系人如下:"); for (Contact contact : contactList) { System.out.println("id: " + contact.getId() + ", " + "vip: " + contact.isVip() + ", " + "姓名: " + contact.getName() + ", " + "性别: " + contact.getGender() + ", " + "邮箱: " + contact.getEmail()); } } }
四、XML检索技术:Xpath
1、问题?
- 如果需要从XML文件中检索需要的某个信息(如name),怎么解决?
- Dom4J需要进行文件的全部解析,然后再寻找要找的数据。
- Xpath技术更加适合做信息检索。
2、XPath介绍
- XPath在解析XML文档方面提供了一个独树一帜的路径思想,更加优雅、高效。
- XPath使用
路径表达式来定位XML文档中的元素节点或属性节点。
示例:
- /元素/子元素/孙元素
3、使用XPath检索XML文件
(1)Document中与XPath相关的API
| 方法名称 | 说明 |
|---|---|
| Node selectSingleNode(“表达式”) | 获取符合表达式的唯一元素 |
| List< Node > selectNodes(“表达式”) | 获取符合表达式的元素集合 |
(2)XPath的四大检索方案
-
绝对路径:
-
采用绝对路径获取从根节点开始逐层的查找:
/contactList/contact/name节点列表并打印信息方法名称 说明 /根元素/子元素/孙元素 从根元素开始,一级一级向下查找,不能跨级。
-
-
相对路径:
-
先得到根节点contactList
-
再采用相对路径获取下一级contact节点的name子节点并打印信息
方法名称 说明 ./子元素/孙元素 从当前元素开始,一级一级向下查找,不能跨级
-
-
全文检索:
-
直接全文检索所有的name元素并打印
方法名称 说明 //元素 在全文查找这个元素,无论元素在哪里 //元素1/元素2 在全文找元素1下面一级的元素2,无论在哪一级,但元素2一定是元素1的子节点 //元素1//元素2 在全文找元素1下面的全部元素2,元素1无论在哪一种,元素2只要是元素1的子孙元素都可以找到
-
-
属性查找:
-
在全文中搜索属性,或者带属性的元素
方法名称 说明 //@属性名 查找属性对象,无论是哪个元素,只要有这个属性即可。 //元素[@属性名] 查找元素对象,全文检索指定元素名和属性名。 //元素[@属性名=值] 查找元素对象,全文检索指定元素名和属性名,并且属性值相等。
-
(2)范例
-
需求:
- 使用Dom4J把一个XML文件的数据进行解析。
-
分析:
-
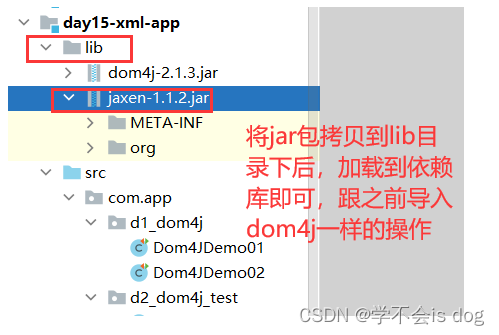
1、导入jar包(dom4j和jaxen-1.1.2.jar),XPath技术依赖Dom4J技术。
- 2、通过dom4j的SAXReader获取Document对象。
- 3、利用XPath提供的API,结合XPath的语法完成选取XML文档元素节点进行解析操作。
-
-
实现:
<?xml version="1.0" encoding="UTF-8" ?> <contactList> <contact id="1" vip="true"> <name> 蔡文姬 </name> <gender>女</gender> <email>caiwenji@123.com</email> </contact> <contact id="2" vip="false"> <name>关羽</name> <gender>男</gender> <email>guanyu@123.com</email> </contact> <contact id="3" vip="true"> <name id="666">刘备</name> <gender>男</gender> <email>liubei@123.com</email> </contact> <user> <contact> <info> <name id="888">武大郎</name> </info> </contact> </user> </contactList>package com.app.d3_xpath; import org.dom4j.Attribute; import org.dom4j.Document; import org.dom4j.Element; import org.dom4j.Node; import org.dom4j.io.SAXReader; import org.junit.Test; import java.util.List; /** * 目标:使用XPath检索XML文件 * 需求:使用Dom4J把一个XML文件的数据进行解析 */ public class XPathDemo { /** * 1、绝对路径: /根元素/子元素/子元素 */ @Test public void parse01() throws Exception { System.out.println("-----------------1、绝对路径-------------------"); // a、创建解析器对象 SAXReader saxReader = new SAXReader(); // b、把XML文件加载成Document文档对象 Document document = saxReader.read(XPathDemo.class.getResourceAsStream("/Contacts2.xml")); // g、检索contact元素下所有的name元素节点 List<Node> nameNodes = document.selectNodes("/contactList/contact/name"); System.out.println("contact元素下所有的name元素:"); forEachElementsAndAttribute(nameNodes); System.out.println(); // h、检索contact元素下所有的gender元素节点 List<Node> genderNodes = document.selectNodes("/contactList/contact/gender"); System.out.println("contact元素下所有的gender元素:"); forEachElementsAndAttribute(genderNodes); System.out.println(); // i、检索contact元素下所有的email元素节点 List<Node> emailNodes = document.selectNodes("/contactList/contact/email"); System.out.println("contact元素下所有的email元素:"); forEachElementsAndAttribute(emailNodes); } /** * c、定义一个遍历所有联系人的元素、属性节点的方法: * 因为此方法里面是重复代码,因此独立成一个方法,提高代码复用性。 * @param nodes 所有联系人的元素、属性节点的List集合 */ public void forEachElementsAndAttribute(List<Node> nodes) { if (nodes == null){ // 传入的参数为空,结束方法 System.out.println("您传入的参数为空!"); return; } // d、遍历所有联系人的元素、属性节点的集合,得到所有联系人的元素、属性信息。 for (Node node : nodes) { // e、判断该节点是否为元素节点 if (node instanceof Element) { // true,说明该节点为元素节点 // f、每遍历到一个联系人的元素节点,就将Node类型强转成Element类型 // (因为是继承关系:Element继承Node,所以可以强转) Element element = (Element) node; // g、获取此联系人的元素信息,去掉前后空格后,打印输出到控制台 System.out.println(element.getTextTrim()); }else { // false,说明该节点不是元素节点 // h、每遍历到一个联系人的属性节点,就将Node类型强转成Attribute类型 // (因为是继承关系:Attribute继承Node,所以可以强转) Attribute attribute = (Attribute) node; // i、获取此联系人的属性信息,打印输出到控制台 System.out.println(attribute.getName() + "--->" + attribute.getValue()); } } } /** * 2、相对路径: ./子元素/子元素 ('.' 代表了当前元素) */ @Test public void parse02() throws Exception { System.out.println("-----------------2、相对路径-------------------"); // a、创建解析器对象 SAXReader saxReader = new SAXReader(); // b、把XML文件加载成Document文档对象 Document document = saxReader.read(XPathDemo.class.getResourceAsStream("/Contacts2.xml")); // c、获取根元素 Element rootElement = document.getRootElement(); // d、检索contact元素下所有的name元素节点 List<Node> nameNodes = rootElement.selectNodes("./contact/name"); System.out.println("contact元素下所有的name元素:"); forEachElementsAndAttribute(nameNodes); } /** * 3、全文检索: * //元素 ——>在全文找这个元素 * //元素1/元素2 ——>在全文找元素1下面的一级元素2 * //元素1//元素2 ——>在全文找元素1下面的全部元素2 */ @Test public void parse03() throws Exception { System.out.println("-----------------3、全文检索-------------------"); // a、创建解析器对象 SAXReader saxReader = new SAXReader(); // b、把XML文件加载成Document文档对象 Document document = saxReader.read(XPathDemo.class.getResourceAsStream("/Contacts2.xml")); // c、检索数据 // 只要是name属性的,都找出来 List<Node> nameNodes1 = document.selectNodes("//name"); System.out.println("(1)全文中所有name:"); forEachElementsAndAttribute(nameNodes1); System.out.println(); // 找元素contact下面的一级元素name List<Node> nameNodes2 = document.selectNodes("//contact/name"); System.out.println("(2)全文中所有contact下一级的name:"); forEachElementsAndAttribute(nameNodes2); System.out.println(); // 找元素contact下面的所有元素名为name的 List<Node> nameNodes3 = document.selectNodes("//contact//name"); System.out.println("(3)全文中所有contact下的所有name:"); forEachElementsAndAttribute(nameNodes3); System.out.println(); // 只要是元素名为gender的,都找出来 List<Node> genderNodes = document.selectNodes("//gender"); System.out.println("(4)全文中所有gender:"); forEachElementsAndAttribute(genderNodes); System.out.println(); // 只要是元素为email的,都找出来 List<Node> emailNodes = document.selectNodes("//email"); System.out.println("(5)全文中所有email:"); forEachElementsAndAttribute(emailNodes); } /** * 4、属性查找: * //@属性名称 ——>在全文检索属性对象 * //元素[@属性名称] ——>在全文检索包含该属性的元素对象 * //元素[@属性名称=值] ——>在全文检索包含该属性的元素且属性值为该值的元素对象 */ @Test public void parse04() throws Exception { System.out.println("-----------------4、属性查找-------------------"); // a、创建解析器对象 SAXReader saxReader = new SAXReader(); // b、把XML文件加载成Document文档对象 Document document = saxReader.read(XPathDemo.class.getResourceAsStream("/Contacts2.xml")); // c、检索全文中属性名为id的节点信息 List<Node> idNodes = document.selectNodes("//@id"); System.out.println("(1)全文中所有id:"); forEachElementsAndAttribute(idNodes); System.out.println(); // d、检索全文中属性名为vip的节点信息 List<Node> vipNodes = document.selectNodes("//@vip"); System.out.println("(2)全文中所有vip:"); forEachElementsAndAttribute(vipNodes); System.out.println(); // e、检索全文中包含id属性的name元素 List<Node> nameNodes = document.selectNodes("//name[@id]"); System.out.println("(3)全文中包含id属性的name元素:"); forEachElementsAndAttribute(nameNodes); System.out.println(); // f、检索全文中包含id属性,并且id属性值为666的name元素 Node nameNode = document.selectSingleNode("//name[@id=666]"); // g、将检索到的Node类型的name元素节点 强转成 Element类型的name元素 Element nameElement = (Element) nameNode; // h、获取该name元素的文本信息,去掉前后空格后,打印输出 System.out.println("(4)全文中包含id属性并且属性值为666的name元素:\n" + nameElement.getTextTrim()); } }-----------------1、绝对路径------------------- contact元素下所有的name元素: 蔡文姬 关羽 刘备 contact元素下所有的gender元素: 女 男 男 contact元素下所有的email元素: caiwenji@123.com guanyu@123.com liubei@123.com -----------------2、相对路径------------------- contact元素下所有的name元素: 蔡文姬 关羽 刘备 -----------------3、全文检索------------------- (1)全文中所有name: 蔡文姬 关羽 刘备 武大郎 (2)全文中所有contact下一级的name: 蔡文姬 关羽 刘备 (3)全文中所有contact下的所有name: 蔡文姬 关羽 刘备 武大郎 (4)全文中所有gender: 女 男 男 (5)全文中所有email: caiwenji@123.com guanyu@123.com liubei@123.com -----------------4、属性查找------------------- (1)全文中所有id: id--->1 id--->2 id--->3 id--->666 id--->888 (2)全文中所有vip: vip--->true vip--->false vip--->true (3)全文中包含id属性的name元素: 刘备 武大郎 (4)全文中包含id属性并且属性值为666的name元素: 刘备 Process finished with exit code 0
总结
- XPath作用是啥?检索方案有哪四大类?
- 检索XML文件中的信息。
- 绝对路径、相对路径、全文检索、属性查找