Hbase性能调优(一)

目录
1、HBase关键参数配置
1.1 写参数调整
1.1.1客户端调优
1.1.2 使用PutList方式提交请求
1.2 Memstore相关
1.2.1 根据 memstore 大小flush hfile
1.2.3 Flush前进行Compaction
1.3 内存相关
1.3.1 GC参数
1.4 HFile相关
1.4.1文件同步sync
1.5 Compaction相关
1.5.1Compact文件大小阈值
1.5.2 Compact文件个数阈值
1.5.3 Compact文件数目
1.5.4 Compact文件大小选择
1.5.5 Major Compaction执行周期
1.6 HLog相关
1.6.1 文件同步sync
1.6.2 Hlog Flush条件
1.7 表设计相关
1.7.1压缩算法
1.7.2 Block大小
1.7.3 缓存内存
2、提升读效率
2.1 客户端调优
2.2 内存相关
2.2.1 GC参数
2.3 缓存相关
3、关键参数配置指导--案例
3.1 活跃Region对集群的影响
4、定位调优
4.1日志收集
4.2 调优定位
4.3定位调优思路
4.3.1通过客户端程序,记录写入、读取速度
4.3.2查看HBase监控信息
4.3.3查看相关日志
1、HBase关键参数配置
如果同时存在读和写的操作,这两种操作的性能会相互影响。如果写入导致的flush和Compaction操作频繁发生,会占用大量的磁盘IO操作,从而影响读取的性能。如果写入导致阻塞较多的Compaction操作,就会出现Region中存在多个HFile的情况,从而影响读取的性能。所以如果读取的性能不理想的时候,也要考虑写入的配置是否合理。
1.1 写参数调整
1.1.1客户端调优
参数值:setAutoFlush
解析:
autoflush = false的原理是当客户端提交delete或put请求时,将该请求在客户端缓存,直到数据超过2M(hbase.client.write.buffer决定)或用户执行了hbase.flushcommits()时才向regionserver提交请求。因此即使htable.put()执行返回成功,也并非说明请求真的成功了。假如还没有达到该缓存而client崩溃,该部分数据将由于未发送到regionserver而丢失。这对于零容忍的在线服务是不可接受的。
autoflush = true虽然会让写入速度下降2-3倍,但是对于很多在线应用来说这都是必须打开的,也正是hbase为什么让它默认为true的原因,每次请求都会发往regionserver,而regionserver接收到请求后第一件事情就是写HLOG。因此对IO要求是非常高的,为了提高hbase的写入速度应该尽可能地提高IO吞吐量,比如增加磁盘、使用raid卡、减少replication因子数等。
如何调优?
默认:true
经验设定:根据集群情况 可以设置为 false,手动 flush。
1.1.2 使用PutList方式提交请求
可以极大地提升写性能
val putList: util.ArrayList[Put] = new util.ArrayList[Put]()1.2 Memstore相关
当regionserver(以下简称为RS)收到一个写请求,会将这个请求定位到某个特定的region。每一个region存储了一系列的Row,每一个 Row 对应的数据分散在一个或多个ColumnFamily(以下简称为CF)。特定CF的数据都存储在对应的store里面,而每个store都是由一个memstore和很多个storefile组成。memstore存储在RS的内存中,而storefile则存储在HDFS上。当一个写请求到达RS的时候,该请求对应的数据首先会被 menstore 存储,直到达到一定的临界条件,memstore里面的数据才会flush到 storefile。
使用 memstore 的主要原因是为了使存储在 HDFS 上的数据是有序的(按Row)。HDFS设计为顺序读写的,已有的文件不能被修改。这就意味着,因为hbase收到的写请求是无序的,所以如果直接将这些数据写到HDFS上,以后再对文件里面的内容做排序就会是一件极其困难的事情;无序的数据存储方式,又会大大影响后续的读请求性能。为了解决这种问题,hbase会将最近的某些写请求放到内存中(也就是memstore),并将这些数据在flush到storefile之前做好排序。
除了解决排序的问题,memstore还有其他好处,比如:
它能充当memcache的角色,缓存最近写入的数据。鉴于新数据的访问频率和几率都比旧数据高很多,这就大大的提高客户端的读效率。
注意:每个 memstore 每次刷新时,都会给 CF 生产一个 storefile。
剩下读取就非常容易了,hbase 会检查数据是否在 memstore 里面,否则就去storefile读取,然后返回给客户端。
1.2.1 根据 memstore 大小flush hfile
参数值:hbase.hregion.memstore.flush.size
参数解析:
在regionserver中,当写操作内存中存在超过 memstore.flush.size 大小的memstore,则MemstoreFlusher就启动flush操作将该memstore以hfile的形式写入对应的store中。
如何调优?
默认:128M
A、如果 Regionserver 的内存充足,而且活跃Region数量也不是很多的时候,可以适当增大该值,可以减少 compaction 的次数,有助于提升系统性能。
B、这种 flush 产生的时候,并不是紧急的flush,flush操作可能会有一定延迟,在延迟期间,写操作还可以进行,Memstore还会继续增大,最大值 = “memstore.flush.size” * "hbase.hregion.memstore.block.multiplier"。
hbase.hregion.memstore.block.multiplier 默认 4 , 4 * 128 = 512 M
C、当超过最大值时,将会阻塞写操作。适当增大“hbase.hregion.memstore.block.multiplier”可以减少阻塞,减少性能波动。
参数值:hbase.regionserver.global.memstore.size 默认:0.4参数解析:
RegionServer 中,负责 flush 操作的是 MemStoreFlusher 线程。该线程定期检查写操作内存,当写操作占用内存总量达到阈值,MemStoreFlusher 将启动 flush 操作,按照从大到小的顺序,flush若干相对较大的 memstore,直到所占用内存小于阈值。
阈值 = “hbase.regionserver.global.memstore.size” * "hbase.regionserver.global.memstore.size.lower.limit" * "Hbase_HEAPSIZE"
upperLimit说明:hbase.hregion.memstore.flush.size这个参数的作用是单个Region内所有memstore大小总和,超过该指定值时,会flush该region的所有memstore。RegionServerd的flush是通过将请求添加一个队列,模拟生产消费模式来异步处理的。那这里就有一个问题,当队列来不及消费,产生大量积压请求时,可能会导致内存陡增,最坏的情况是触发OOM(程序申请内存过大,虚拟机无法满足我们,然后自杀)。
这个参数的作用是防止内存占用过大,当ReionServer内所有region的memstore所占用内存总和达到heap的40%时,Hbase会强制block所有的更新并flush这些region以释放所有memstore占用的内存。
lowerLimit说明:lowelimit在所有Region的memstore所占用内存达到Heap的40%时,不flush所有的memstore。它会找一个memstore内存占用最大的region,做个别flush,此时写更新还是会被block。lowerLimit算是一个在所有region强制flush导致性能降低前的补救措施。在日志中,表现为“** Flush thread woke up with memory above low water.”
如何调优?
比如 Hbase_HEAPSIZE=8, 阈值= 0.4 * 0.95 * 8 = 3.04G
[[hbase.regionserver.global.memstore.size.lower.limit]]
*`hbase.regionserver.global.memstore.size.lower.limit`*::
+
.Description
Maximum size of all memstores in a region server before flushes are forced.
Defaults to 95% of hbase.regionserver.global.memstore.size.
A 100% value for this property causes the minimum possible flushing to occur when updates are
blocked due to memstore limiting.
+
.Default
`0.95`
[[hbase.hregion.memstore.block.multiplier]]
*`hbase.hregion.memstore.block.multiplier`*::
+
.Description
Block updates if memstore has hbase.hregion.memstore.block.multiplier
times hbase.hregion.memstore.flush.size bytes. Useful preventing
runaway memstore during spikes in update traffic. Without an
upper-bound, memstore fills such that when it flushes the
resultant flush files take a long time to compact or split, or
worse, we OOME.
+
.Default
`4`该配置与“hfile.block.cache.size”的和不能超过0.8,也就是写和读操作的内存不能超过HeapSize的80%,这样可以保证除读和写以外其他操作的正常运行, 40% 是否需要调整需要看HBase的读和写那个多 然后做相应的调整,我们集群是写相对少,读取很多。
1.2.3 Flush前进行Compaction
参数值:hbase.hstore.blockingStoreFiles
参数解析:
在region flush前首先判断 StoreFile文件个数,是否大于hbase.hstore.blockingStoreFiles。如果大于需要先Compaction并且让flush延时90s(这个参数可以通过hbase.hstore.blockingWaitTime进行配置),在延时过程中,将会继续写从而使得Memstore还会继续增大超过阈值(“memstore.flush.size” * "hbase.hregion.memstore.block.multiplier" 128*4),导致写操作阻塞。当完成Compaction后,可能就会产生大量写入。这样就导致性能激烈震荡。
hbase.hstore.blockingWaitTime 默认值:90000
如何调优?
默认:10
增加hbase.hstore.blockingStoreFiles,可以降低Block几率。
1.3 内存相关
Hbase利用内存完成读写操作。提高Hbase内存可以有效提高Hbase性能。
1.3.1 GC参数
参数值:GC_OPTS
参数解析:
GC_OPTS主要需要调整HeapSize的大小和NewSize的大小。
HMaster:
- -Xms512M -Xmx1G -XX:NewSize=64M -XX:MaxNewSize=128M
RegionServer:
- -Xms4G -Xmx6G -XX:NewSize=64M -XX:MaxNewSize=128M如何调优?
A、调整HeapSize大小的时候,建议将Xms和Xmx设置成相同的值,这样可以避免JVM动态调整HeapSize大小的时候影响性能。
B、调整NewSize大小的时候,建议把其设置为HeapSize大小的1/9。
C、HMaster:当HBase集群规模越大、Region数量越多时,可以适当调大HMaster的GC_OPTS参数。
D、RegionServer:RegionServer需要的内存一般比HMaster要大。在内存充足的情况下,HeapSize可以相对设置大一些。
经验设定:
HDP默认RegionServer 为服务器内存的 1/3,主Hmaster的HeapSize为4G的时候,Hbase集群可以支持100000Region数的规模。根据经验值,单个RegionServer的HeapSize不建议超过20G。
1.4 HFile相关
1.4.1文件同步sync
参数值:hbase.regionserver.hfile.durable.sync
参数解析:
控制HFfile文件在写入到HDFS时的同步程度。每一条wal是否持久化到硬盘 ,如果为true,HDFS在把数据写入到硬盘后才返回:如果为false,HDFS在把数据写入OS的缓存后就返回。
如何调优?
默认:true
把该值设置为false比设为true时在写入性能上会更优。
1.5 Compaction相关
1.5.1Compact文件大小阈值
参数值:hbase.regionserver.thread.compaction.throttle 默认:2.5G参数值:hbase.regionserver.thread.compaction.throttle 默认:2.5G (2684354560)
参数解析:
控制一次Minor Compaction时,进行compaction的文件总大小的阈值。
如何调优?
默认:2.5G
Compaction时的文件总大小会影响这一次compaction的执行时间,如果太大,可能会阻塞其他的compaction或flush操作。
1.5.2 Compact文件个数阈值
参数值:hbase.hstore.compaction.min
参数解析:
当一个Store中文件超过该值时,会进行compact。
如何调优?
默认:3
适当增大该值,可以减少文件被重复执行compaction,但是如果过大,会导致Store中文件数过多而影响读取的性能,且一次的flush操作会占用更多的内存空间,具体可以根据内存调大该参数,我们小集群单机32G , RegionServer8G , 该参数没有调整。
1.5.3 Compact文件数目
参数值:hbase.hstore.compaction.max
参数解析:
控制一次compaction操作时的文件数量的最大值。
如何调优?
默认:10
与“hbase.hstore.compaction.max.size”的作用基本相同,主要是控制一次compaction操作的时间不要太长。
1.5.4 Compact文件大小选择
参数值:hbase.hstore.compaction.max.size 默认值(9223372036854775807)
参数解析:
如果一个HFle文件的大小大于该值,那么Minor Compaction操作中不会选择这个文件进行compaction操作,除非进行Major Compaction操作。
如何调优?
默认:2.5G
这个值可以防止较大的HFile参与Compaction操作。在禁止Major Compaction后,一个Store中可能存在几个HFile,而不会合并成一个HFile,这样不会对数据读取造太大的性能影响。
1.5.5 Major Compaction执行周期
参数值:hbase.hregion.majorcompaction
参数解析:由于执行 Major Compaction 会占用较多的系统资源,如果正在处于系统繁忙时期,会影响系统的性能 。
如何调优?
默认: 7天(HDP)
A. 如果业务没有较多的更新、删除、回收过期数据空间时, 建议设置为 0,以禁止Major Compaction,线上手动触发合并,以表为单位 触发 MajorCompaction 。
B. 如果必须要执行 Major Compaction,以回收更多的空间,可以适当增加该值,同时配置参数“hbase.offpeak.end.hour”和“hbase.offpeak.start.hour”以控制 Major Compaction 发生在业务空闲的时期。
一般选择A方式,HDP关闭Major Compaction ,凌晨按照表触发major 合并,频率一周一次。

代码示例如下:
/**
* major compaction
*
* @param tableList 合并表列表
* @param config
* @param sleepTime 休眠时间
* @throws IOException
*/
public static void tableMajorCompaction(String[] tableList, Configuration config, Long sleepTime) throws IOException {
for (String table : tableList) {
// 判断表是否存在
TableName tableName = TableName.valueOf(table.trim());
Connection connection = ConnectionFactory.createConnection(config);
// 如果admin作为方法传过来会 if 判断会存在连接超时
Admin admin = connection.getAdmin();
logger.info("+++++++++++++++++++++ table name " + tableName.getNameAsString() + " +++++++++++++++++++++");
if (admin.tableExists(tableName)) {
// 触发 majorCompaction
try {
logger.info("+++++++++++++++++++++ start major compaction table name : " + tableName.getNameAsString() + " +++++++++++++++++++++");
admin.majorCompact(tableName);
logger.info("+++++++++++++++++++++ end major compaction table name : " + tableName.getNameAsString() + " +++++++++++++++++++++");
logger.info("+++++++++++++++++++++ table " + tableName.getNameAsString() + " is table enabled " + admin.isTableEnabled(tableName) + " +++++++++++++++++++++");
} catch (IOException e) {
logger.info("+++++++++++++ table " + tableName.getNameAsString() + " is table enabled " + admin.isTableEnabled(tableName) + " majorCompaction failure ++++++");
e.printStackTrace();
}
}
admin.close();
connection.close();
try {
// 设置表major compaction 间隔时间
logger.info("+++++++++++++++++++++ major compaction sleep time " + sleepTime + " minutes " + " +++++++++++++++++++++");
TimeUnit.MINUTES.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}1.6 HLog相关
RS 上有一个 Write-ahead Log (以下简称 WAL),数据会持续的默认写到这个文件中。它包含了所有已经提交到 RS 的,已经保留在 memstore 中但是尚未 flush 到 storefile 的数据编辑历史。
这些在 memstore 中的,尚未持久化的数据,在 RS 发生错误时我们需要借助它进行恢复,它能重现这些尚未持久化的数据的编辑轨迹。
当 WAL(Hlog)变得非常大时,重现它的记录会花费非常多的时间。因此,我们需要限制WAL 的大小,当达到这个大小时,会触发 memstore 的 flush。
当数据 flush 到磁盘后,WAL 的大小就会变小,因为我们不需要再保存这些已经完成持久化的数据编辑记录。

1.6.1 文件同步sync
参数值:hbase.regionserver.wal.durable.sync
参数解析:
控制 HLog 文件在写入到 HDFS 时的同步程度。每一条wal是否持久化到硬盘,如果为 true, HDFS 在把数据写入到硬盘后才返回;如果为 false, HDFS 在把数据写入 OS 的缓存后就返回。
如何调优?
把该值设置为 false 比 true 在写入性能上会更优。
1.6.2 Hlog Flush条件
参数值:
hbase.regionserver.maxlogs
hbase.regionserver.hlog.blocksize参数解析:
A、表示一个RegionServer上未进行Flush的Hlog的文件数量的阈值,如果大于该值,RegionServer会强制进行flush操作。
B、表示每个Hlog文件的最大大小。如果Hlog文件大小大于该值,就会滚动出一个新的Hlog,旧的将被禁用并归档。
如何调优?
这两个参数共同决定了RegionServer中可以存在的未进行Flush的hlog数量。
WAL的最大容量 = hbase.regionserver.maxlogs * hbase.regionserver.hlog.blocksize。
当达到这个容量的时候,memstore flush就会被触发。因此,你在调整memstore的设置的时候,你同样需要调整这些值来适应那些编号。否则,WAL容量达到限制可能导致memstore flush的罪魁祸首,你专门配置memstore参数所增加的资源可能永远无法被物尽其用。这个时候可以适当调整这两个参数的大小。以避免出现这种强制flush的情况。
经验设定:
hbase.regionserver.maxlogs:默认32,建议调整为100
hbase.regionserver.hlog.blocksize:默认 128M
32 * 128M = 4096 M
1.7 表设计相关
1.7.1压缩算法
参数值:COMPRESSION
参数解析:配置数据的压缩算法,这里的压缩是HFile中block级别的压缩。对于可以压缩的数据,配置压缩算法可以有效减少磁盘的IO,从而达到提高性能的目的。
如何优化?
默认:None
并非所有数据都可以进行有效的压缩。例如一张图片的数据,因为图片一般已经是压缩后的数据,所以压缩效果有限。推荐使用SNAPPY,因为它有较好的Encoding / Decoding 速度和可以接受的压缩率。
实例:create 'test_table',{NAME => 'cf1', COMPRESSION => 'SNAPPY'}1.7.2 Block大小
参数值:BLOCKSIZE
参数解析:
配置HFile中block块的大小,不同的block块大小,可以影响HBase读写数据的效率。越大的block块,配合压缩算法,压缩的效率就越好;但是由于HBase的读取数据是以block块为单位的,所以越大的block块,对应随机读的情况,性能可能会比较差。
如何调优?
默认:64Kb
如果要提升写入性能,一般扩大到128kb或者256kb,可以提升写数据的效率,也不会影响太大的随机读性能。
实例:create 'test_table',{NAME => 'cf1', BLOCKSIZE => '32768'}
1.7.3 缓存内存
参数值:IN_MEMORY
参数解析:
配置这个表的数据有限缓存在内存中,这样可以有效提升读取的性能。
如何调优?
默认:false
对于一些小表,而且需要频繁进行读取操作的,可以设置此配置项
实例:create 'test_table',{NAME => 'cf1', IN_MEMORY => 'true'}
2、提升读效率
2.1 客户端调优
A、Scan数据时需要设置caching(一次从服务端读取的记录条数),若使用默认值读性能会降到极低。
B、当不需要读一条数据所有列时,需要指定读取的列,以减少网络IO
C、只读取Rowkey时,可以为Scan添加一个只读取Rowkey的filter(FirstKeyOnlyFilter或者KeyOnlyFilter)。
D、在客户端代码中,可以设置caching和batch用来提升查询效率。
scan中的setCaching与setBatch方法的区别是什么呢?
setCaching设置的值为每次rpc的请求记录数,默认是1;cache大可以优化性能,但是太大了会花费很长的时间进行一次传输。
- setBatch设置每次取的column size;有些row特别大,所以需要分开传给client,就是一次传一个row的几个column。
- batch和caching和hbase table column size共同决意了rpc的次数。
例如:
Scan.setCaching(caching);
scan.setBatch(batch); 当 caching 和 batch 都为 1 的时候,我们要返回 10 行具有 20 列的记录,就要进行 201 次 RPC, 因为每一列都作为一个单独的 Result 来返回,这样是我们不可以接受的(还有一次 RPC 是用来确认 scan 已经完成) 。
a) RPC 次数公式: RPCs = (Rows * Cols per Row) / Min(Cols per Row, Batch Size)/Scanner Caching
RPC次数=总批次数(Results数量)/每次返回的批次数(caching大小)+1
[[hbase.client.scanner.caching]]
*`hbase.client.scanner.caching`*::
+
.Description
Number of rows that will be fetched when calling next
on a scanner if it is not served from (local, client) memory. Higher
caching values will enable faster scanners but will eat up more memory
and some calls of next may take longer and longer times when the cache is empty.
Do not set this value such that the time between invocations is greater
than the scanner timeout; i.e. hbase.client.scanner.timeout.period
+
.Default
`100`2.2 内存相关
Hbase利用内存完成读写操作。提高HBase内存可以有效提高HBase性能。
2.2.1 GC参数
参数值:GC_OPTS
参数解析:
GC_OPTS主要需要调整HeapSize的大小和NewSize的大小。
HMaster:
- -Xms512M -Xmx1G -XX:NewSize=64M -XX:MaxNewSize=128M
RegionServer:
- -Xms4G -Xmx6G -XX:NewSize=64M -XX:MaxNewSize=128M如何调优?
A. 调整 HeapSize 大小的时候,建议将 Xms 和 Xmx 设置成相同的值,这样可以避免 JVM动态调整 HeapSize 大小的时候影响性能。
B. 调整 NewSize 大小的时候,建议把其设置为 HeapSize 大小的 1/9。
C. HMaster:当 HBase 集群规模越大、 Region 数量越多时,可以适当调大 HMaster 的GC_OPTS 参数。
D. RegionServer: RegionServer 需要的内存一般比 HMaster 要大。在内存充足的情况下,HeapSize 可以相对设置大一些。
经验设定:
主 HMaster 的 HeapSize 为 4G 的时候, HBase 集群可以支持 100000Region 数的规模。根据经验值,单个 RegionServer 的 HeapSize 不建议超过 20GB
2.3 缓存相关
参数值:hfile.block.cache.size
参数解析:
HBase缓存区大小,主要影响查询性能。根据查询模式以及查询记录分布情况来解决缓存区的大小。
如何调优?
默认:0.4
如果采用随机查询使得缓存区的命中率较低,可以适当降低缓存区大小,可以根据生产中的数据读写比重做调整。
3、关键参数配置指导--案例
3.1 活跃Region对集群的影响
HBase在设计上,遵循了LSM-TREE的原理:写数据阶段,尽最大努力先将每一个Region的数据保留在内存(MemStore)中,等达到一定的阈值(默认为128M)之后,再 将这些数据固化(Flush)到文件(HFile)中,在这过程中,为了保证数据的安全性,通过将数据写入到一个人日志文件(Hlog)中:
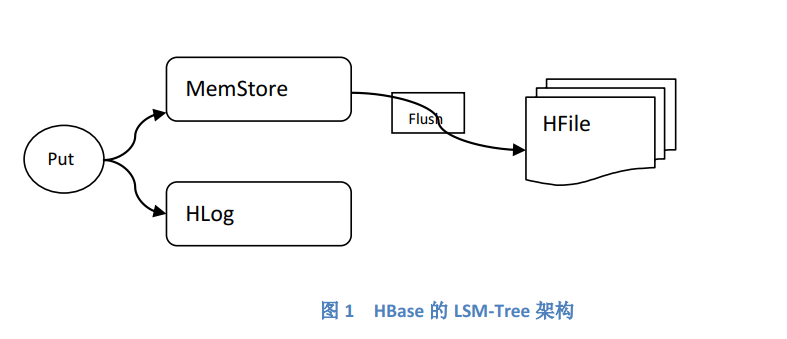
在当前时间段可能被写入用户数据的Region,称作“活跃 Region”。
举例:
如果一个用户表的Region是按天划分的,那么,第一天的用户数据,只会被写入到第一天的Region中,则这些Region就是活跃的Region。此时,对于其它天的Region,都处于一种“空闲”的状态。
集群中每一个物理节点的内存资源都是有限的,每一个Region的数据都是暂时先保留在内存中然后再固化到HFile文件中的,因此,我们需要控制一个时间段的活跃的Region数目。如果Region过多的话,会导致内存资源紧张,每一个Region在内存中的数据可能还没有达到预先设置阈值的大小就被提前触发Flush操作,这会导致Flush频率升高,产生大量的小HFile(小文件过多会导致读取性能的直线下降,也会加大Compaction的频率和压力)。相反活跃Region过少的话,也会导致并发度提升不上去,读写性能偏低。
如果有热点的数据导致RegeionServer GC 我们可能需要 拆分Region去提高并发 ,并且让热点数据分到 不同的Region 上,或者达到阈值大小Region会自动Split。
如何设置最合理的活跃Region数目?
需要根据MemStore Flush的阈值大小,以及RegionServer堆内存的大小、预留MemStore空间的大小进行合理的计算。
如下列子可以说明这种计算方法:
举例:
假设分配给 RegionServer堆内存的大小为8G,MemStore所占空间比例为40%,MemStore Flush的阈值大小为128M,则合理的活跃Region数目约为8*1024*0.4/128=26(个/节点)。

4、定位调优
4.1日志收集
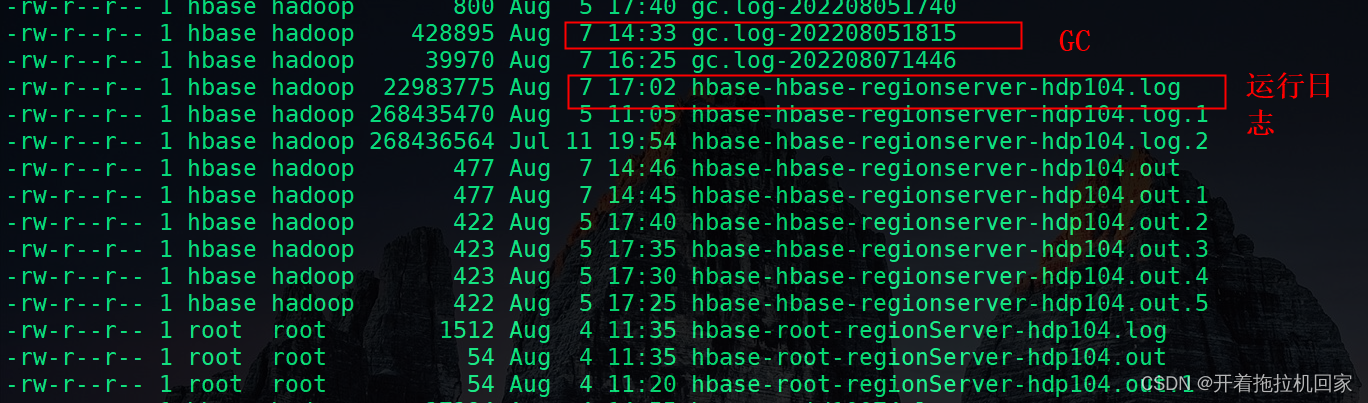
日志分类介绍:
当前HBase的日志保存在/var/log/Bigdata/HBase和/var/log/Bigdata/audit/hbase目录下,具体如下:

4.2 调优定位
对于读写性能定位和调优,主要查看Regionserver的hbase-XXX-regionserver-XXX.log 运
行日志。
日志中是否出现过以下信息?
**Flush thread woke up with memory above low water.
日志中出现这个 信息说明有部分写过程出现过阻塞等待的现象,造成这个现象的原因是各个Region的Memstore使用的大小加起来超过了总的阈值,于是阻塞,并开始找一个Region进行Flush,,这个过程会需要消耗掉一段时间,通常来说造成这个的原因是单台Region server上的Region数太多了,因此单台Region server上最好不要放置过多的Region,一种调节方法是调大split的fileSize,这样可以适当的减少Region数,但需要关注调整后读性能的变化。
**delaying flush up to
当日志中出现这个信息时,可能会造成出现下面的现象,从而产生影响,这个通常是StoreFile太多造成的,通常可以调大点StoreFile个数的阈值。
**Blocking updates for
当日志中出现这个信息时,表示写动作已被阻塞,造成这个现象的原因是memStore中使用的大小已超过其阈值的2倍,通常是由于上面的delaving flush up to 造成的,或者是region数太多造成的,或者是太多的Hlog造成的,这种情况下会造成很大的影响,如内存够用的话,可以调大阈值,如果是其他原因,就对症下药。
** MemstoreFlusherChore requesting flush of trafficDevInOutData,f,1638033732634.11fee23bc197ca372d64bdf2a7c7ad0c. because d has an old edit so flush to free WALs after random delay 119964ms
memstore频繁flush,同时多次compact小文件hfile
2021-09-28 08:20:15,571 INFO [regionserver/datanode-3:16020.Chore.1] regionserver.HRegionServer: MemstoreFlusherChore requesting flush of camerastatus,36,1629354980778.a0e5d07244cc72496418cede17a00805. because cs has an old edit so flush to free WALs after random delay 197350ms
2021-09-28 08:20:15,571 INFO [regionserver/datanode-3:16020.Chore.1] regionserver.HRegionServer: MemstoreFlusherChore requesting flush of camerastatus,71,1629354980778.74c804edb5424098dd60d3c2873afb1e. because cs has an old edit so flush to free WALs after random delay 225855ms
2021-09-28 08:20:15,571 INFO [regionserver/datanode-3:16020.Chore.1] regionserver.HRegionServer: MemstoreFlusherChore requesting flush of camerastatus,78,1629354980778.1644f3003decc6c30729fa6644b50dcc. because cs has an old edit so flush to free WALs after random delay 43644ms
2021-09-28 08:20:15,571 INFO [regionserver/datanode-3:16020.Chore.1] regionserver.HRegionServer: MemstoreFlusherChore requesting flush of devicestatus,23,1629354985569.1b410d1f1cbaa62c78cffdb1df821347. because ds has an old edit so flush to free WALs after random delay 240635ms
2021-09-28 08:20:15,571 INFO [regionserver/datanode-3:16020.Chore.1] regionserver.HRegionServer: MemstoreFlusherChore requesting flush of devicestatus,05,1629354985569.bd95a2d85b067b159e7295cb765cbcf5. because ds has an old edit so flush to free WALs after random delay 207731ms解决:
- 调大hbase.hregion.memstore.flush.size :128M–> 256M
- 判断Region个数是否合理,过多的Region会频繁的flush
***2021-11-30 14:01:50,761 INFO [JvmPauseMonitor] util.JvmPauseMonitor: Detected pause in JVM or host machine (eg GC): pause of approximately 2893ms
GC pool 'G1 Young Generation' had collection(s): count=4 time=76ms
GC pool 'G1 Old Generation' had collection(s): count=1 time=3148ms
读取HBase,报GC ,这种尤其会导致 RegionServer服务挂掉
解决:
- 可以调整 ReigionSever 内存
- 查看是否是热点数据导致,排查查询是否合理,设置Scan 的大小
4.3定位调优思路
针对HBase读写变慢的场景,可以按照如下思路进行定位、调优:
开始-->对比性能差距-->查看监控信息-->查看相关日志-->确定具体场景-->进行参数调优-->后续观察
4.3.1通过客户端程序,记录写入、读取速度
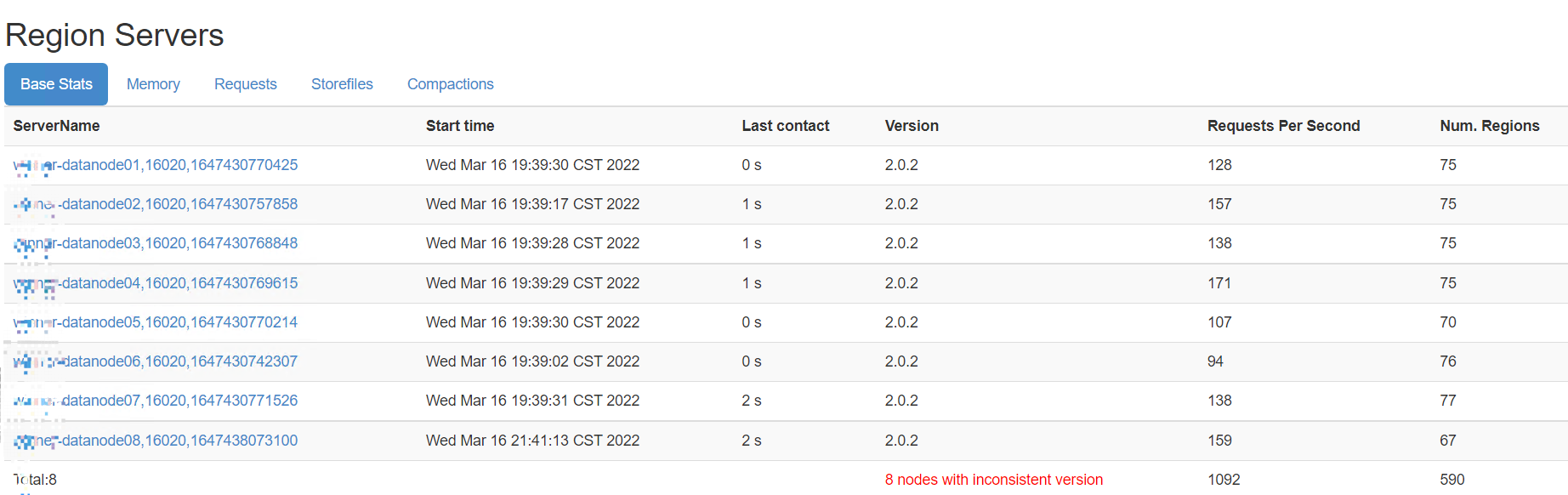
在客户端程序中,可以记录HBase写入/读取速度,关注性能差距。或者,通过HMaster的页面来查看各个RegionServer的RPC请求。
4.3.2查看HBase监控信息
Region的分裂、compaction、flush次数过多、flush耗时高、硬件资源抢占等众多元素都会影响性能,因此,需要从Manager监控页面中,查看各个RegionServer的各类监控指标,需要重点关注:RegionServer GC时间、RegionServer GC次数、节点CPU/内存利用率、Compaction的次数,Flush文件次数、Flush操作的平均耗时、Split次数等信息。
如下 compaction:
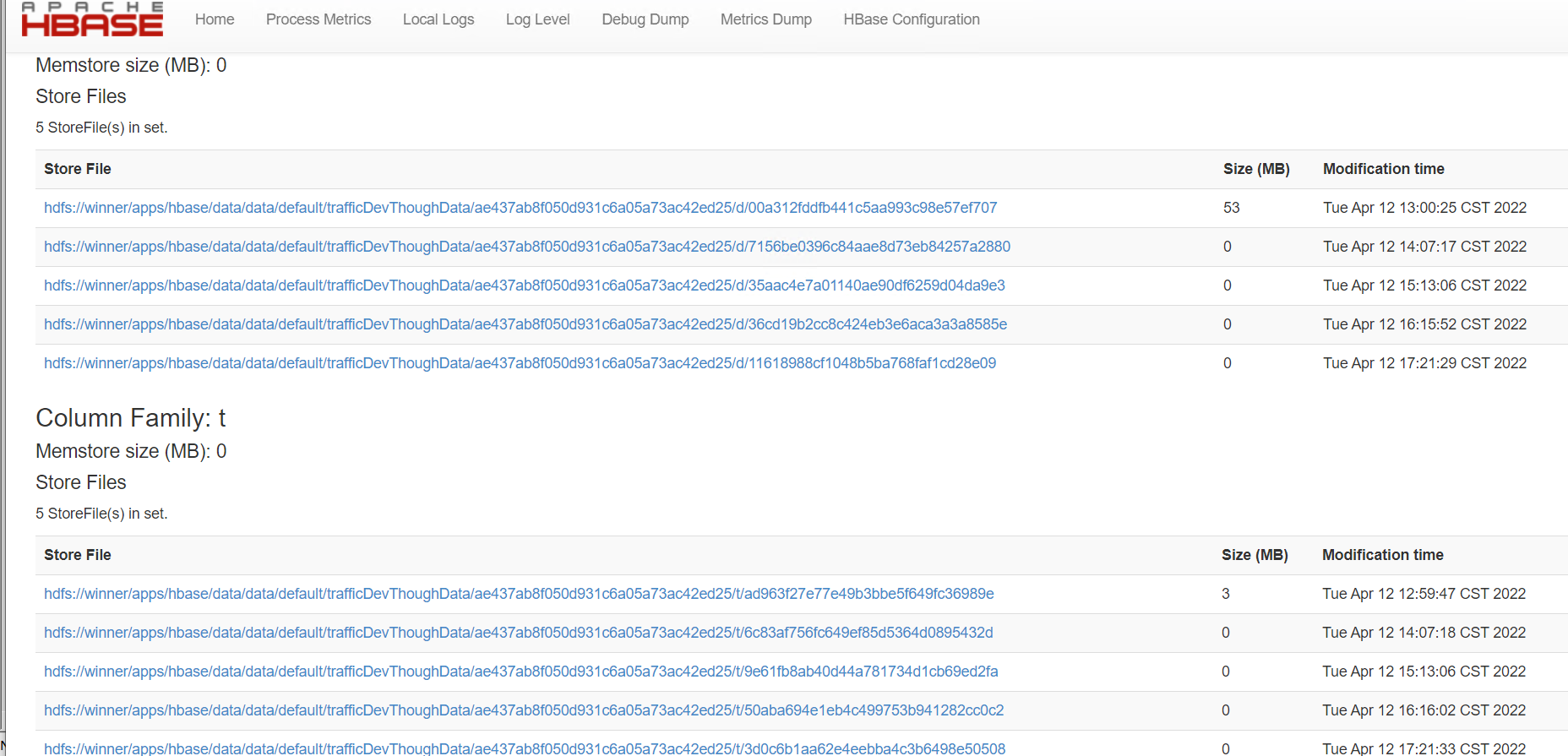

待合并的 StoreFile
合并完成:
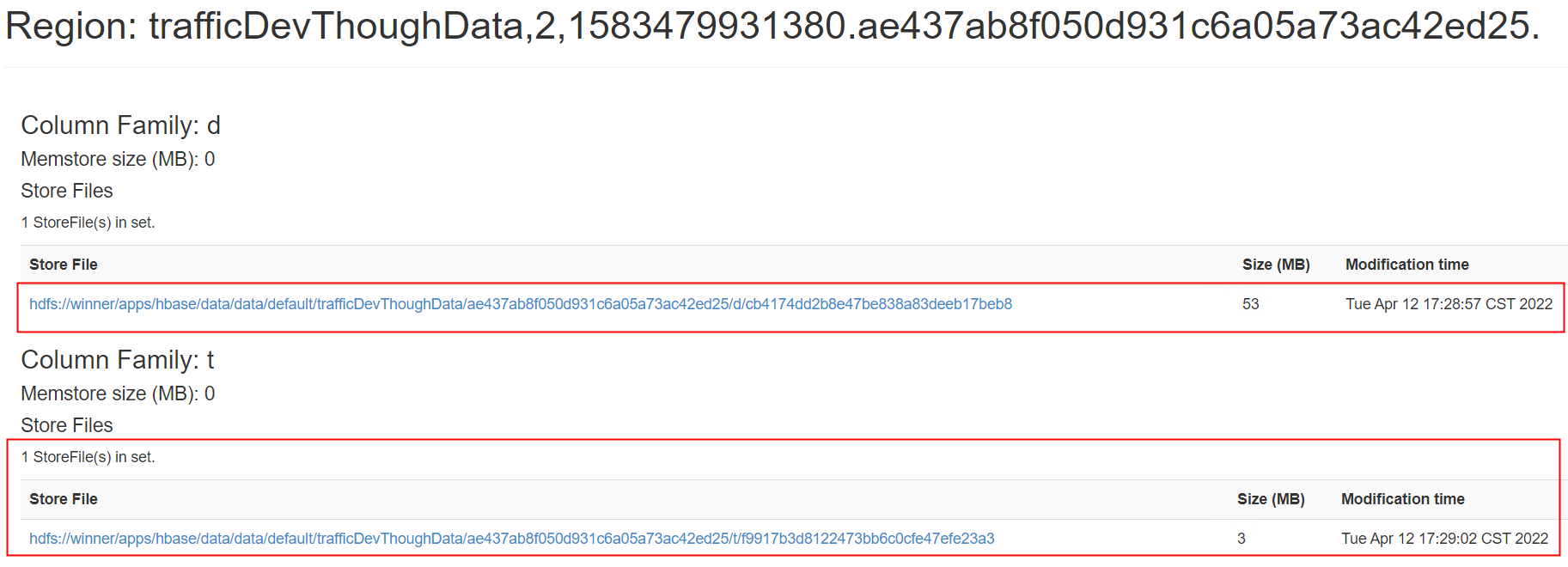
可以查看Grafra指标监控,下图是 BolockCache 缓存命中率
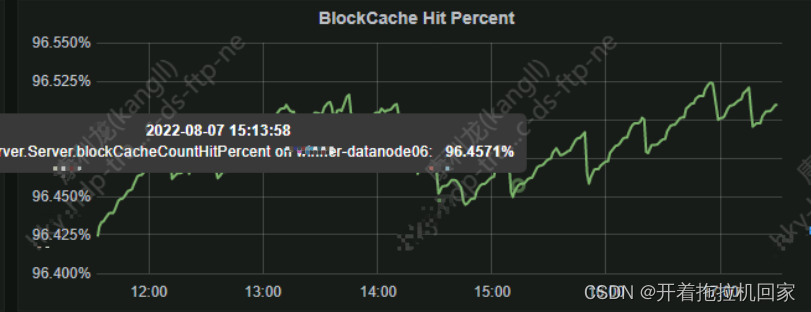
4.3.3查看相关日志
结合HBase的监控信息,查看RegionServer的运行日志。
2022-03-04 08:31:12,721 INFO [AsyncFSWAL-0] wal.AbstractFSWAL: Slow sync cost: 176 ms, current pipeline: [DatanodeInfoWithStorage[172.16.77.3:1019,DS-31df0572-b7e9-4943-9919-bb4e10a7729e,DISK], DatanodeInfoWithStorage[172.16.77.2:1019,DS-2d1bbb1e-9b8d-4f41-a769-c7fb5db5c691,DISK], DatanodeInfoWithStorage[172.16.77.11:1019,DS-ff711f83-e374-49e4-9c00-da26f69e243d,DISK]]
2022-03-04 08:31:12,721 INFO [AsyncFSWAL-0] wal.AbstractFSWAL: Slow sync cost: 175 ms, current pipeline: [DatanodeInfoWithStorage[172.16.77.3:1019,DS-31df0572-b7e9-4943-9919-bb4e10a7729e,DISK], DatanodeInfoWithStorage[172.16.77.2:1019,DS-2d1bbb1e-9b8d-4f41-a769-c7fb5db5c691,DISK], DatanodeInfoWithStorage[172.16.77.11:1019,DS-ff711f83-e374-49e4-9c00-da26f69e243d,DISK]]
2022-03-04 08:31:12,721 INFO [AsyncFSWAL-0] wal.AbstractFSWAL: Slow sync cost: 173 ms, current pipeline: [DatanodeInfoWithStorage[172.16.77.3:1019,DS-31df0572-b7e9-4943-9919-bb4e10a7729e,DISK], DatanodeInfoWithStorage[172.16.77.2:1019,DS-2d1bbb1e-9b8d-4f41-a769-c7fb5db5c691,DISK], DatanodeInfoWithStorage[172.16.77.11:1019,DS-ff711f83-e374-49e4-9c00-da26f69e243d,DISK]]
2022-03-04 08:31:12,736 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush HDFS audit logs completed.....
2022-03-04 08:31:14,736 INFO [AsyncFSWAL-0] wal.AbstractFSWAL: Slow sync cost: 109 ms, current pipeline: [DatanodeInfoWithStorage[172.16.77.3:1019,DS-31df0572-b7e9-4943-9919-bb4e10a7729e,DISK], DatanodeInfoWithStorage[172.16.77.2:1019,DS-2d1bbb1e-9b8d-4f41-a769-c7fb5db5c691,DISK], DatanodeInfoWithStorage[172.16.77.11:1019,DS-ff711f83-e374-49e4-9c00-da26f69e243d,DISK]]
2022-03-04 08:31:14,736 INFO [AsyncFSWAL-0] wal.AbstractFSWAL: Slow sync cost: 107 ms, current pipeline: [DatanodeInfoWithStorage[172.16.77.3:1019,DS-31df0572-b7e9-4943-9919-bb4e10a7729e,DISK], DatanodeInfoWithStorage[172.16.77.2:1019,DS-2d1bbb1e-9b8d-4f41-a769-c7fb5db5c691,DISK], DatanodeInfoWithStorage[172.16.77.11:1019,DS-ff711f83-e374-49e4-9c00-da26f69e243d,DISK]]
2022-03-04 08:31:21,383 INFO [AsyncFSWAL-0] wal.AbstractFSWAL: Slow sync cost: 5886 ms, current pipeline: [DatanodeInfoWithStorage[172.16.77.3:1019,DS-31df0572-b7e9-4943-9919-bb4e10a7729e,DISK], DatanodeInfoWithStorage[172.16.77.2:1019,DS-2d1bbb1e-9b8d-4f41-a769-c7fb5db5c691,DISK], DatanodeInfoWithStorage[172.16.77.11:1019,DS-ff711f83-e374-49e4-9c00-da26f69e243d,DISK]]
2022-03-04 08:31:21,423 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flushing HDFS audit. Event Size:659
2022-03-04 08:31:21,423 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush called. name=hbaseRegional.async.summary.multi_dest.batch.hdfs
2022-03-04 08:31:21,429 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush HDFS audit logs completed.....
2022-03-04 08:31:21,699 INFO [regionserver/bigdata-datanode01:16020.Chore.2] regionserver.HRegionServer: MemstoreFlusherChore requesting flush of trafficDevThoughData,b,1583479931380.06fbdb6077c1d85a1650274be21a3d62. because d has an old edit so flush to free WALs after random delay 3755ms
2022-03-04 08:31:21,699 INFO [regionserver/bigdata-datanode01:16020.Chore.2] regionserver.HRegionServer: MemstoreFlusherChore requesting flush of trafficCountData,8,1583479895746.d2c6921ebfb0ba8b027fc8f5e12747ee. because t has an old edit so flush to free WALs after random delay 88197ms
2022-03-04 08:31:23,469 INFO [AsyncFSWAL-0] wal.AbstractFSWAL: Slow sync cost: 150 ms, current pipeline: [DatanodeInfoWithStorage[172.16.77.3:1019,DS-31df0572-b7e9-4943-9919-bb4e10a7729e,DISK], DatanodeInfoWithStorage[172.16.77.2:1019,DS-2d1bbb1e-9b8d-4f41-a769-c7fb5db5c691,DISK], DatanodeInfoWithStorage[172.16.77.11:1019,DS-ff711f83-e374-49e4-9c00-da26f69e243d,DISK]]
2022-03-04 08:31:24,043 WARN [RpcServer.default.FPBQ.Fifo.handler=99,queue=9,port=16020] ipc.RpcServer: (responseTooSlow): {"call":"Scan(org.apache.hadoop.hbase.shaded.protobuf.generated.ClientProtos$ScanRequest)","starttimems":1646353871641,"responsesize":21925,"method":"Scan","param":"region { type: REGION_NAME value: \"win_pos_detail,15555555,1583480015067.da12819b3f1c928a867f8befb3969708.\" } scan { column { family: \"sale\" } start_r <TRUNCATED>","processingtimems":12400,"client":"172.16.76.252:52356","queuetimems":1,"class":"HRegionServer"}
2022-03-04 08:31:24,302 INFO [AsyncFSWAL-0] wal.AbstractFSWAL: Slow sync cost: 107 ms, current pipeline: [DatanodeInfoWithStorage[172.16.77.3:1019,DS-31df0572-b7e9-4943-9919-bb4e10a7729e,DISK], DatanodeInfoWithStorage[172.16.77.2:1019,DS-2d1bbb1e-9b8d-4f41-a769-c7fb5db5c691,DISK], DatanodeInfoWithStorage[172.16.77.11:1019,DS-ff711f83-e374-49e4-9c00-da26f69e243d,DISK]]
2022-03-04 08:31:24,302 INFO [AsyncFSWAL-0] wal.AbstractFSWAL: Slow sync cost: 105 ms, current pipeline: [DatanodeInfoWithStorage[172.16.77.3:1019,DS-31df0572-b7e9-4943-9919-bb4e10a7729e,DISK], DatanodeInfoWithStorage[172.16.77.2:1019,DS-2d1bbb1e-9b8d-4f41-a769-c7fb5db5c691,DISK], DatanodeInfoWithStorage[172.16.77.11:1019,DS-ff711f83-e374-49e4-9c00-da26f69e243d,DISK]]
2022-03-04 08:31:24,397 INFO [org.apache.ranger.audit.queue.AuditBatchQueue1] provider.BaseAuditHandler: Audit Status Log: name=hbaseRegional.async.summary.multi_dest.batch, finalDestination=hbaseRegional.async.summary.multi_dest.batch.solr, interval=01:02.652 minutes, events=7000, stashedCount=7000, totalEvents=536305000, totalStashedCount=536305000
2022-03-04 08:31:27,038 INFO [regionserver/bigdata-datanode01:16020-longCompactions-1638251199523] throttle.PressureAwareThroughputController: 517d112fcca731c5c3d8e06d3914d788#d#compaction#237505 average throughput is 26.91 MB/second, slept 0 time(s) and total slept time is 0 ms. 0 active operations remaining, total limit is 50.52 MB/second
2022-03-04 08:31:27,307 INFO [regionserver/bigdata-datanode01:16020-longCompactions-1638251199523] regionserver.HStore: Completed major compaction of 3 (all) file(s) in d of 517d112fcca731c5c3d8e06d3914d788 into 9245edab8bad4aab9da720dd3f47f85e(size=134.3 M), total size for store is 134.3 M. This selection was in queue for 0sec, and took 53sec to execute.
2022-03-04 08:31:27,307 INFO [regionserver/bigdata-datanode01:16020-longCompactions-1638251199523] regionserver.CompactSplit: Completed compaction region=trafficCountData,d,1583479895746.517d112fcca731c5c3d8e06d3914d788., storeName=d, priority=97, startTime=1646353833551; duration=53sec
2022-03-04 08:31:27,429 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flushing HDFS audit. Event Size:649
2022-03-04 08:31:27,429 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush called. name=hbaseRegional.async.summary.multi_dest.batch.hdfs
2022-03-04 08:31:27,435 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush HDFS audit logs completed.....
2022-03-04 08:31:27,435 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] provider.BaseAuditHandler: Audit Status Log: name=hbaseRegional.async.summary.multi_dest.batch, finalDestination=hbaseRegional.async.summary.multi_dest.batch.hdfs, interval=01:00.869 minutes, events=109209, succcessCount=7011, totalEvents=24443791697, totalSuccessCount=537144228
2022-03-04 08:31:29,475 INFO [hbaseRegional.async.summary.multi_dest.batch_hbaseRegional.async.summary.multi_dest.batch.solr_destWriter] provider.BaseAuditHandler: Audit Status Log: name=hbaseRegional.async.summary.multi_dest.batch.solr, interval=01:00.023 minutes, events=1, failedCount=1, totalEvents=134784, totalFailedCount=134784
2022-03-04 08:31:29,497 INFO [hbaseRegional.async.summary.multi_dest.batch_hbaseRegional.async.summary.multi_dest.batch.solr_destWriter] queue.AuditFileSpool: Destination is down. sleeping for 30000 milli seconds. indexQueue=706, queueName=hbaseRegional.async.summary.multi_dest.batch, consumer=hbaseRegional.async.summary.multi_dest.batch.solr
2022-03-04 08:31:31,673 INFO [regionserver/bigdata-datanode01:16020.Chore.2] regionserver.HRegionServer: MemstoreFlusherChore requesting flush of trafficDevThoughData,b,1583479931380.06fbdb6077c1d85a1650274be21a3d62. because d has an old edit so flush to free WALs after random delay 87680ms
2022-03-04 08:31:31,673 INFO [regionserver/bigdata-datanode01:16020.Chore.2] regionserver.HRegionServer: MemstoreFlusherChore requesting flush of trafficCountData,8,1583479895746.d2c6921ebfb0ba8b027fc8f5e12747ee. because t has an old edit so flush to free WALs after random delay 106840ms
2022-03-04 08:31:33,436 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flushing HDFS audit. Event Size:634
2022-03-04 08:31:33,436 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush called. name=hbaseRegional.async.summary.multi_dest.batch.hdfs
2022-03-04 08:31:33,456 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush HDFS audit logs completed.....
2022-03-04 08:31:34,491 INFO [LruBlockCacheStatsExecutor] hfile.LruBlockCache: totalSize=2.56 GB, freeSize=651.27 MB, max=3.20 GB, blockCount=137855, accesses=12965953920, hits=12671625625, hitRatio=97.73%, , cachingAccesses=12684291931, cachingHits=12639510478, cachingHitsRatio=99.65%, evictions=809035, evicted=9715267, evictedPerRun=12.008463169084155
2022-03-04 08:31:36,424 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flushing HDFS audit. Event Size:22
2022-03-04 08:31:36,424 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush called. name=hbaseRegional.async.summary.multi_dest.batch.hdfs
2022-03-04 08:31:36,426 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush HDFS audit logs completed.....
2022-03-04 08:31:37,708 INFO [MemStoreFlusher.1] hbase.RangerAuthorizationCoprocessor: Unable to get remote Address
2022-03-04 08:31:37,708 INFO [MemStoreFlusher.1] regionserver.HRegion: Flushing 2/2 column families, dataSize=5.37 MB heapSize=12.89 MB
2022-03-04 08:31:37,929 INFO [MemStoreFlusher.1] regionserver.DefaultStoreFlusher: Flushed memstore data size=5.22 MB at sequenceid=5402371 (bloomFilter=true), to=hdfs://bigdata/apps/hbase/data/data/default/trafficDevThoughData/06fbdb6077c1d85a1650274be21a3d62/.tmp/d/41c2a84ce32b4bed8b6cf91ad92f1454
2022-03-04 08:31:38,043 INFO [MemStoreFlusher.1] regionserver.DefaultStoreFlusher: Flushed memstore data size=161.89 KB at sequenceid=5402371 (bloomFilter=true), to=hdfs://bigdata/apps/hbase/data/data/default/trafficDevThoughData/06fbdb6077c1d85a1650274be21a3d62/.tmp/t/0dbac591f2e04be2a3de52d451227cbb
2022-03-04 08:31:38,063 INFO [MemStoreFlusher.1] regionserver.HStore: Added hdfs://bigdata/apps/hbase/data/data/default/trafficDevThoughData/06fbdb6077c1d85a1650274be21a3d62/d/41c2a84ce32b4bed8b6cf91ad92f1454, entries=10434, sequenceid=5402371, filesize=34.7 K
2022-03-04 08:31:38,073 INFO [MemStoreFlusher.1] regionserver.HStore: Added hdfs://bigdata/apps/hbase/data/data/default/trafficDevThoughData/06fbdb6077c1d85a1650274be21a3d62/t/0dbac591f2e04be2a3de52d451227cbb, entries=264, sequenceid=5402371, filesize=11.3 K
2022-03-04 08:31:38,074 INFO [MemStoreFlusher.1] regionserver.HRegion: Finished flush of dataSize ~5.37 MB/5635690, heapSize ~12.89 MB/13520248, currentSize=0 B/0 for 06fbdb6077c1d85a1650274be21a3d62 in 366ms, sequenceid=5402371, compaction requested=true
2022-03-04 08:31:38,074 INFO [regionserver/bigdata-datanode01:16020-shortCompactions-1638251207060] hbase.RangerAuthorizationCoprocessor: Unable to get remote Address
2022-03-04 08:31:38,074 INFO [regionserver/bigdata-datanode01:16020-longCompactions-1638251199523] hbase.RangerAuthorizationCoprocessor: Unable to get remote Address
2022-03-04 08:31:38,076 INFO [regionserver/bigdata-datanode01:16020-shortCompactions-1638251207060] regionserver.HRegion: Starting compaction of d in trafficDevThoughData,b,1583479931380.06fbdb6077c1d85a1650274be21a3d62.
2022-03-04 08:31:38,076 INFO [regionserver/bigdata-datanode01:16020-shortCompactions-1638251207060] regionserver.HStore: Starting compaction of [hdfs://bigdata/apps/hbase/data/data/default/trafficDevThoughData/06fbdb6077c1d85a1650274be21a3d62/d/5f553eeb7a57466191a7330baf0b5b13, hdfs://bigdata/apps/hbase/data/data/default/trafficDevThoughData/06fbdb6077c1d85a1650274be21a3d62/d/d004d88417db4d7dac46bede365de960, hdfs://bigdata/apps/hbase/data/data/default/trafficDevThoughData/06fbdb6077c1d85a1650274be21a3d62/d/41c2a84ce32b4bed8b6cf91ad92f1454] into tmpdir=hdfs://bigdata/apps/hbase/data/data/default/trafficDevThoughData/06fbdb6077c1d85a1650274be21a3d62/.tmp, totalSize=40.7 M
2022-03-04 08:31:38,227 INFO [regionserver/bigdata-datanode01:16020-shortCompactions-1638251207060] hbase.RangerAuthorizationCoprocessor: Unable to get remote Address
2022-03-04 08:31:41,880 INFO [regionserver/bigdata-datanode01:16020.Chore.3] regionserver.HRegionServer: MemstoreFlusherChore requesting flush of trafficCountData,8,1583479895746.d2c6921ebfb0ba8b027fc8f5e12747ee. because t has an old edit so flush to free WALs after random delay 147178ms
2022-03-04 08:31:42,430 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] provider.BaseAuditHandler: Audit Status Log: name=hbaseRegional.async.summary.multi_dest.batch.hdfs, interval=01:05.812 minutes, events=5512, succcessCount=5512, totalEvents=537144884, totalSuccessCount=537144884
2022-03-04 08:31:42,430 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flushing HDFS audit. Event Size:326
2022-03-04 08:31:42,431 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush called. name=hbaseRegional.async.summary.multi_dest.batch.hdfs
2022-03-04 08:31:42,433 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush HDFS audit logs completed.....
2022-03-04 08:31:47,536 INFO [regionserver/bigdata-datanode01:16020.logRoller] wal.AbstractFSWAL: Rolled WAL /apps/hbase/data/WALs/bigdata-datanode01,16020,1638251192251/bigdata-datanode01%2C16020%2C1638251192251.1646353783734 with entries=12910, filesize=128.44 MB; new WAL /apps/hbase/data/WALs/bigdata-datanode01,16020,1638251192251/bigdata-datanode01%2C16020%2C1638251192251.1646353907380
2022-03-04 08:31:48,483 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flushing HDFS audit. Event Size:13
2022-03-04 08:31:48,483 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush called. name=hbaseRegional.async.summary.multi_dest.batch.hdfs
2022-03-04 08:31:48,484 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush HDFS audit logs completed.....
2022-03-04 08:31:51,678 INFO [regionserver/bigdata-datanode01:16020.Chore.2] regionserver.HRegionServer: MemstoreFlusherChore requesting flush of trafficCountData,8,1583479895746.d2c6921ebfb0ba8b027fc8f5e12747ee. because t has an old edit so flush to free WALs after random delay 1288ms
2022-03-04 08:31:54,506 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flushing HDFS audit. Event Size:627
2022-03-04 08:31:54,506 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush called. name=hbaseRegional.async.summary.multi_dest.batch.hdfs
2022-03-04 08:31:54,512 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush HDFS audit logs completed.....
2022-03-04 08:31:57,493 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flushing HDFS audit. Event Size:23
2022-03-04 08:31:57,493 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush called. name=hbaseRegional.async.summary.multi_dest.batch.hdfs
2022-03-04 08:31:57,496 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush HDFS audit logs completed.....
2022-03-04 08:32:01,256 INFO [regionserver/bigdata-datanode01:16020-shortCompactions-1638251207060] throttle.PressureAwareThroughputController: 06fbdb6077c1d85a1650274be21a3d62#d#compaction#237508 average throughput is 28.68 MB/second, slept 0 time(s) and total slept time is 0 ms. 0 active operations remaining, total limit is 50.52 MB/second
2022-03-04 08:32:01,467 INFO [regionserver/bigdata-datanode01:16020-shortCompactions-1638251207060] regionserver.HStore: Completed compaction of 3 (all) file(s) in d of 06fbdb6077c1d85a1650274be21a3d62 into 120630ea735a4c338a61c433c36da550(size=40.7 M), total size for store is 40.7 M. This selection was in queue for 0sec, and took 23sec to execute.
2022-03-04 08:32:01,468 INFO [regionserver/bigdata-datanode01:16020-shortCompactions-1638251207060] regionserver.CompactSplit: Completed compaction region=trafficDevThoughData,b,1583479931380.06fbdb6077c1d85a1650274be21a3d62., storeName=d, priority=97, startTime=1646353898074; duration=23sec
2022-03-04 08:32:01,677 INFO [regionserver/bigdata-datanode01:16020.Chore.2] regionserver.HRegionServer: MemstoreFlusherChore requesting flush of trafficCountData,8,1583479895746.d2c6921ebfb0ba8b027fc8f5e12747ee. because t has an old edit so flush to free WALs after random delay 143429ms
2022-03-04 08:32:02,581 INFO [MemStoreFlusher.0] hbase.RangerAuthorizationCoprocessor: Unable to get remote Address
2022-03-04 08:32:02,582 INFO [MemStoreFlusher.0] regionserver.HRegion: Flushing 2/2 column families, dataSize=41.69 MB heapSize=84.76 MB
2022-03-04 08:32:02,786 INFO [AsyncFSWAL-0] wal.AbstractFSWAL: Slow sync cost: 188 ms, current pipeline: [DatanodeInfoWithStorage[172.16.77.3:1019,DS-31df0572-b7e9-4943-9919-bb4e10a7729e,DISK], DatanodeInfoWithStorage[172.16.77.12:1019,DS-f2f88eaa-2be4-48b3-b9a5-395fa2477eed,DISK], DatanodeInfoWithStorage[172.16.77.4:1019,DS-606115d1-f90a-405b-91a9-22ab4588e60a,DISK]]
2022-03-04 08:32:03,210 INFO [MemStoreFlusher.0] regionserver.DefaultStoreFlusher: Flushed memstore data size=30.91 MB at sequenceid=3013339 (bloomFilter=true), to=hdfs://bigdata/apps/hbase/data/data/default/trafficCountData/d2c6921ebfb0ba8b027fc8f5e12747ee/.tmp/d/a9352d04a1e04a2b80240300a933d35e
2022-03-04 08:32:03,386 INFO [MemStoreFlusher.0] regionserver.DefaultStoreFlusher: Flushed memstore data size=10.79 MB at sequenceid=3013339 (bloomFilter=true), to=hdfs://bigdata/apps/hbase/data/data/default/trafficCountData/d2c6921ebfb0ba8b027fc8f5e12747ee/.tmp/t/0d128f73a0c3419eb18f8ac00022cef3
2022-03-04 08:32:03,412 INFO [MemStoreFlusher.0] regionserver.HStore: Added hdfs://bigdata/apps/hbase/data/data/default/trafficCountData/d2c6921ebfb0ba8b027fc8f5e12747ee/d/a9352d04a1e04a2b80240300a933d35e, entries=12806, sequenceid=3013339, filesize=101.4 K
2022-03-04 08:32:03,427 INFO [MemStoreFlusher.0] regionserver.HStore: Added hdfs://bigdata/apps/hbase/data/data/default/trafficCountData/d2c6921ebfb0ba8b027fc8f5e12747ee/t/0d128f73a0c3419eb18f8ac00022cef3, entries=136, sequenceid=3013339, filesize=9.3 K
2022-03-04 08:32:03,429 INFO [MemStoreFlusher.0] regionserver.HRegion: Finished flush of dataSize ~41.69 MB/43719694, heapSize ~84.76 MB/88877272, currentSize=0 B/0 for d2c6921ebfb0ba8b027fc8f5e12747ee in 847ms, sequenceid=3013339, compaction requested=true
2022-03-04 08:32:03,430 INFO [regionserver/bigdata-datanode01:16020-shortCompactions-1638251207378] hbase.RangerAuthorizationCoprocessor: Unable to get remote Address
2022-03-04 08:32:03,430 INFO [regionserver/bigdata-datanode01:16020-shortCompactions-1638251207537] hbase.RangerAuthorizationCoprocessor: Unable to get remote Address
2022-03-04 08:32:03,501 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flushing HDFS audit. Event Size:333
2022-03-04 08:32:03,501 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush called. name=hbaseRegional.async.summary.multi_dest.batch.hdfs
2022-03-04 08:32:03,505 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush HDFS audit logs completed.....
2022-03-04 08:32:09,496 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flushing HDFS audit. Event Size:25
2022-03-04 08:32:09,496 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush called. name=hbaseRegional.async.summary.multi_dest.batch.hdfs
2022-03-04 08:32:09,497 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush HDFS audit logs completed.....
2022-03-04 08:32:12,499 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flushing HDFS audit. Event Size:25
2022-03-04 08:32:12,499 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush called. name=hbaseRegional.async.summary.multi_dest.batch.hdfs
2022-03-04 08:32:12,506 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush HDFS audit logs completed.....
2022-03-04 08:32:18,501 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flushing HDFS audit. Event Size:34
2022-03-04 08:32:18,501 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush called. name=hbaseRegional.async.summary.multi_dest.batch.hdfs
2022-03-04 08:32:18,502 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush HDFS audit logs completed.....
2022-03-04 08:32:20,396 INFO [AsyncFSWAL-0] wal.AbstractFSWAL: Slow sync cost: 193 ms, current pipeline: [DatanodeInfoWithStorage[172.16.77.3:1019,DS-31df0572-b7e9-4943-9919-bb4e10a7729e,DISK], DatanodeInfoWithStorage[172.16.77.12:1019,DS-f2f88eaa-2be4-48b3-b9a5-395fa2477eed,DISK], DatanodeInfoWithStorage[172.16.77.4:1019,DS-606115d1-f90a-405b-91a9-22ab4588e60a,DISK]]
2022-03-04 08:32:20,396 INFO [AsyncFSWAL-0] wal.AbstractFSWAL: Slow sync cost: 176 ms, current pipeline: [DatanodeInfoWithStorage[172.16.77.3:1019,DS-31df0572-b7e9-4943-9919-bb4e10a7729e,DISK], DatanodeInfoWithStorage[172.16.77.12:1019,DS-f2f88eaa-2be4-48b3-b9a5-395fa2477eed,DISK], DatanodeInfoWithStorage[172.16.77.4:1019,DS-606115d1-f90a-405b-91a9-22ab4588e60a,DISK]]
2022-03-04 08:32:20,396 INFO [AsyncFSWAL-0] wal.AbstractFSWAL: Slow sync cost: 159 ms, current pipeline: [DatanodeInfoWithStorage[172.16.77.3:1019,DS-31df0572-b7e9-4943-9919-bb4e10a7729e,DISK], DatanodeInfoWithStorage[172.16.77.12:1019,DS-f2f88eaa-2be4-48b3-b9a5-395fa2477eed,DISK], DatanodeInfoWithStorage[172.16.77.4:1019,DS-606115d1-f90a-405b-91a9-22ab4588e60a,DISK]]
2022-03-04 08:32:20,396 INFO [AsyncFSWAL-0] wal.AbstractFSWAL: Slow sync cost: 121 ms, current pipeline: [DatanodeInfoWithStorage[172.16.77.3:1019,DS-31df0572-b7e9-4943-9919-bb4e10a7729e,DISK], DatanodeInfoWithStorage[172.16.77.12:1019,DS-f2f88eaa-2be4-48b3-b9a5-395fa2477eed,DISK], DatanodeInfoWithStorage[172.16.77.4:1019,DS-606115d1-f90a-405b-91a9-22ab4588e60a,DISK]]
2022-03-04 08:32:21,721 INFO [AsyncFSWAL-0] wal.AbstractFSWAL: Slow sync cost: 151 ms, current pipeline: [DatanodeInfoWithStorage[172.16.77.3:1019,DS-31df0572-b7e9-4943-9919-bb4e10a7729e,DISK], DatanodeInfoWithStorage[172.16.77.12:1019,DS-f2f88eaa-2be4-48b3-b9a5-395fa2477eed,DISK], DatanodeInfoWithStorage[172.16.77.4:1019,DS-606115d1-f90a-405b-91a9-22ab4588e60a,DISK]]
2022-03-04 08:32:23,079 INFO [AsyncFSWAL-0] wal.AbstractFSWAL: Slow sync cost: 314 ms, current pipeline: [DatanodeInfoWithStorage[172.16.77.3:1019,DS-31df0572-b7e9-4943-9919-bb4e10a7729e,DISK], DatanodeInfoWithStorage[172.16.77.12:1019,DS-f2f88eaa-2be4-48b3-b9a5-395fa2477eed,DISK], DatanodeInfoWithStorage[172.16.77.4:1019,DS-606115d1-f90a-405b-91a9-22ab4588e60a,DISK]]
2022-03-04 08:32:24,559 INFO [org.apache.ranger.audit.queue.AuditBatchQueue1] provider.BaseAuditHandler: Audit Status Log: name=hbaseRegional.async.summary.multi_dest.batch, finalDestination=hbaseRegional.async.summary.multi_dest.batch.solr, interval=01:00.163 minutes, events=3000, stashedCount=3000, totalEvents=536308000, totalStashedCount=536308000
2022-03-04 08:32:24,560 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flushing HDFS audit. Event Size:36
2022-03-04 08:32:24,560 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush called. name=hbaseRegional.async.summary.multi_dest.batch.hdfs
2022-03-04 08:32:24,571 INFO [AsyncFSWAL-0] wal.AbstractFSWAL: Slow sync cost: 135 ms, current pipeline: [DatanodeInfoWithStorage[172.16.77.3:1019,DS-31df0572-b7e9-4943-9919-bb4e10a7729e,DISK], DatanodeInfoWithStorage[172.16.77.12:1019,DS-f2f88eaa-2be4-48b3-b9a5-395fa2477eed,DISK], DatanodeInfoWithStorage[172.16.77.4:1019,DS-606115d1-f90a-405b-91a9-22ab4588e60a,DISK]]
2022-03-04 08:32:24,591 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush HDFS audit logs completed.....
2022-03-04 08:32:25,887 INFO [AsyncFSWAL-0] wal.AbstractFSWAL: Slow sync cost: 150 ms, current pipeline: [DatanodeInfoWithStorage[172.16.77.3:1019,DS-31df0572-b7e9-4943-9919-bb4e10a7729e,DISK], DatanodeInfoWithStorage[172.16.77.12:1019,DS-f2f88eaa-2be4-48b3-b9a5-395fa2477eed,DISK], DatanodeInfoWithStorage[172.16.77.4:1019,DS-606115d1-f90a-405b-91a9-22ab4588e60a,DISK]]
2022-03-04 08:32:26,857 INFO [AsyncFSWAL-0] wal.AbstractFSWAL: Slow sync cost: 132 ms, current pipeline: [DatanodeInfoWithStorage[172.16.77.3:1019,DS-31df0572-b7e9-4943-9919-bb4e10a7729e,DISK], DatanodeInfoWithStorage[172.16.77.12:1019,DS-f2f88eaa-2be4-48b3-b9a5-395fa2477eed,DISK], DatanodeInfoWithStorage[172.16.77.4:1019,DS-606115d1-f90a-405b-91a9-22ab4588e60a,DISK]]
2022-03-04 08:32:27,560 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flushing HDFS audit. Event Size:32
2022-03-04 08:32:27,560 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush called. name=hbaseRegional.async.summary.multi_dest.batch.hdfs
2022-03-04 08:32:27,585 INFO [org.apache.ranger.audit.queue.AuditBatchQueue0] destination.HDFSAuditDestination: Flush HDFS audit logs completed.....