【机器学习】DBSCAN聚类算法的理论/实现与调参
1. 初识DBSCAN
-
DBSCAN: Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法,是一种基于密度的空间聚类算法
-
DBSCAN将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据库中发现任意形状的聚类
-
DBSCAN是一种著名的密度聚类算法,它基于一组"邻域"参数来刻画样本分布的紧密程度。DBSCAN先发现密度较高的点,然后把相近的高密度点逐步连成一片,进而生成各种簇
-
DBSCAN算法的可视化演示:DBSCAN聚类可视化

2. 基本概念解释
-
核心对象
- 邻域内至少包含MinPts个最少样本/最少点的对象
- 邻域和MinPts个数均可指定
- MinPts个最少样本包含核心对象本身
-
邻域
- 邻域是一个空间,点的邻域是与点距离小于 ε ε ε的集合
-
核心点/边界点/噪声点
- 核心点,Core Point. 若样本 x x x的 ε ε ε邻域内至少包含MinPts个样本,则称样本 x x x为核心点
- 边界点,Border Point. 若样本 x x x的 ε ε ε邻域内包含的样本数量小于MinPts,但是它在其他核心点的邻域内,则称样本点 x x x为边界点
- 噪声点,或离群点/异常样本,Noise Point. 既不是核心点也不是边界点的点

-
密度直达/密度可达/密度相连
- 密度直达:两个样本位于统一邻域内,且其中一个样本是核心对象,称样本由核心对象密度直达。密度直达不满足对称性
- 密度可达:一个样本能由另一个核心对象通过密度直达串起来,称样本由核心对象密度可达。密度可达不满足对称性
- 密度相连:若两个样本均由另一个样本密度可达,称这两个样本密度相连。密度相连满足对称性
-
簇
- 由密度可达关系导出的最大的密度相连的样本集合。
- 在基于密度的聚类算法中,通过在数据集中寻找被低密度区域分离的高密度区域,将分离出的高密度区域作为一个独立的类别

3. DBSCAN算法流程

-
算法描述:以每个数据点为圆心,以邻域为半径画圈,然后数有多少个点,在这个圈内,这个数就是点密度值,然后选取一个点密度阈值MinPts,圈内点数小于MinPts为低密度点,大于或等于MinPoints的为高密度点,称之为核心点或核心对象;如果有一个高密度的点在另一个高密度点的圈内,我们就把这两个点连接起来,这样就可以把好多点不断串联起来;如果有低密度的点也在高密度点的圈内,把它也连到最近的高密度点上,称之为边界点
-
簇的形成:DBSCAN使用的方法很简单,它任意选择一个没有类别的核心对象作为种子,然后找到所有这个核心对象能够密度可达的样本集合,即为一个聚类簇。接着继续选择另一个没有类别的核心对象去寻找密度可达的样本集合,这样就得到另一个聚类簇。一直运行到所有核心对象都有类别为止
-
簇的形成图示:

-
对算法步骤的理解:
- MinPts最少点包含核心对象本身
- 离群点/边界点的区别:边界点属于某个簇,离群点不属于任何簇
- DBSCAN不是完全稳定的算法,某些样本可能到两个核心对象的距离都小于 ϵ ϵ ϵ,但是这两个核心对象由于不是密度直达,又不属于同一个聚类簇,那么如果界定这个样本的类别呢?一般来说,此时DBSCAN采用先来后到,先进行聚类的类别簇会标记这个样本为它的类别
- 整个搜索过程类似广度优先搜索与深度优先搜索的结合。每一个核心对象邻域内的点加入队列,然后FIFO访问同时将新的核心对象的邻域内点继续加入队列访问,这样一级一级一圈一圈往外访问最后形成簇
- 算法会重新访问数据点
-
算法的时间和空间复杂度
- 时间复杂度:DBSCAN的基本时间复杂度是 O(N * 找出Eps领域中的点所需要的时间),N是点的个数。最坏情况下时间复杂度是O(N^2)
- 时间复杂度:在低维空间数据中,有一些数据结构如KD树,使得可以有效的检索特定点给定距离内的所有点,时间复杂度可以降低到O(NlogN)
- 空间复杂度:低维和高维数据中,其空间都是O(N),对于每个点它只需要维持少量数据,即簇标号和每个点的标识(核心点或边界点或噪音点)
4. 算法参数选择与调参过程
-
参数选择:
- 两个必须参数:邻域半径 ε ε ε + 最少点 M i n P t s MinPts MinPts
- ε ε ε设置的非常小,则意味着没有点是核心对象,所有点都被标记为噪声
- ε ε ε设置的非常大,可能会导致所有点形成单个簇
- DBSCAN虽然不显示设置簇的个数,但设置邻域半径可以隐式地控制找到的簇的个数
- 以下为不同邻域半径和不同最少点参数下的聚类结果对比说明
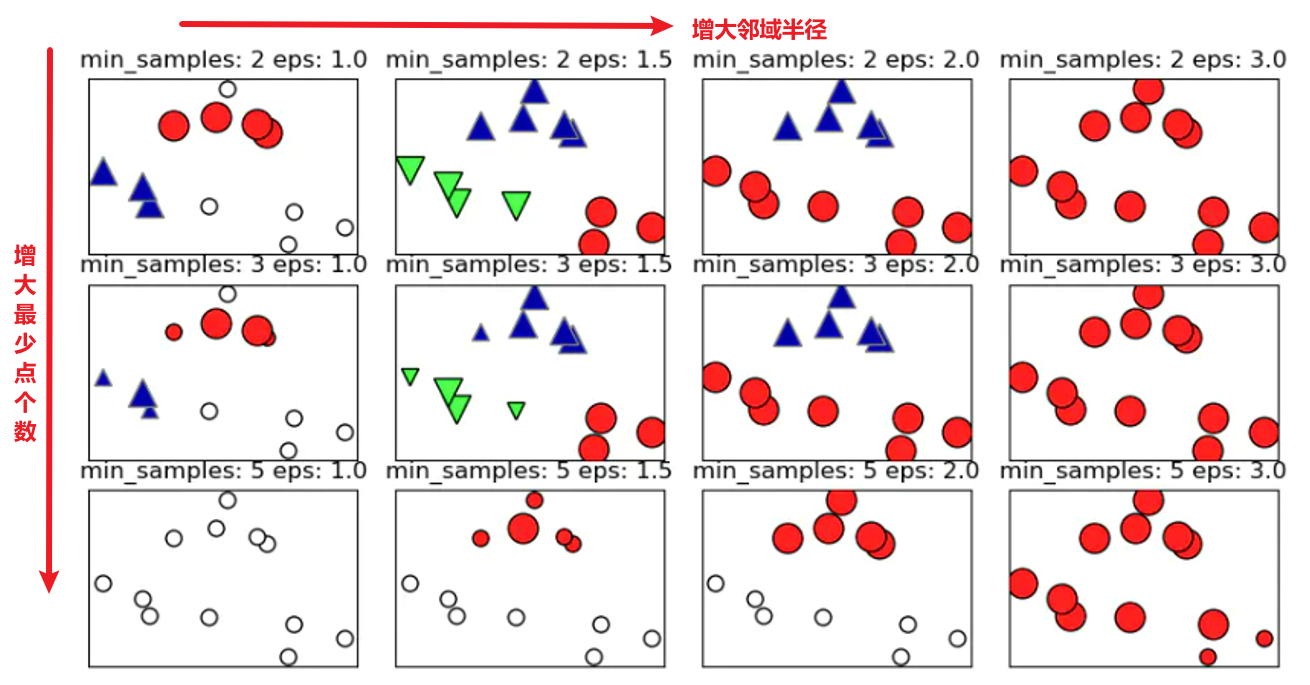
-
调参:邻域半径和最少点参数的选取
-
邻域半径 ε ε ε:通过绘制k距离曲线(k distance graph)得到,在k距离曲线明显拐点位置为对应较好的参数。若邻域半径设置过小,大部分数据不能聚类;若参数设置过大,多个簇和大部分对象会归并到同一个簇中
-
最少点MinPts:
- 指导性原则(a rule of thumb):MinPts ≥ dim+1,其中dim表示待聚类数据的维度
- MinPts = 1是不合理的,设置为1表示每个独立点都是一个簇
- MinPts ≤ 2与层次聚类最近邻域结果相同
- MinPts必须选择大于等于3的值
-
k距离曲线:利用了KNN算法,给定参数k,对于每个数据点,计算对应的第k个最近邻距离,并将数据集中所有点对应的最近邻距离按照降序排序,这幅图为排序的k距离图,选取图中拐点位置对应的k距离值设置为 ε ε ε,一般将k值设置为4,大于4无明显差异。也有文章推荐:k = 2 * dim - 1,dim表示特征维度
-
理想的k距离曲线如图

- 作者使用行人数据统计的k距离曲线如下图

k = 4的k距离图:彩色圆点是k距离值,蓝色+是曲线拟合的结果 
k = 3的k距离图:彩色圆点是k距离值,蓝色+是曲线拟合的结果 -
可以看到k = 4时,拐点处对应的纵轴取值为3.19;k = 3时,拐点处对应的纵轴取值为2.4;即可以用这两个统计得到的行人聚类邻域半径测试
-
不同参数的测试结果

k = 4得到的参数:[ε, MinPts] = [3.2, 5] 的聚类结果 
k = 3得到的参数:[ε, MinPts] = [2.5, 3] 的聚类结果 
k = 3得到的参数:[ε, MinPts] = [2.5, 4] 的聚类结果 - 对本次测试来说,[ε, MinPts] = [2.5, 3]比较合理
-
5. DBSCAN算法的优缺点
-
优点
- 不需要像k-means均值聚类那样预先确定簇的数量
- 对异常值/离群点不敏感,对离群点有较好的鲁棒性,甚至可以检测离群点
- 能将高密度数据分离成小集群
- 可以聚类非线性关系,即可以在任意大小和形状的集群中工作,可以划分复杂形状的簇
-
缺点
- 输入参数敏感。确定参数[ε, MinPts]困难,若选取不当,将造成聚类质量下降
- 算法聚类效果依赖于距离公式的选取,实际应用中常用欧氏距离,对于高维数,存在维数灾难,即难以聚类高维数据
- 当数据量增大时,要求较大的内存支持,I/O消耗也很大
6. DBSCAN算法的python实现
-
方法1:使用sklearn的自带算法
-
导入sklearn.cluster中自带的DBSCAN算法实现
-
代码如下(参考网上)
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets from sklearn.cluster import DBSCAN # matplotlib inline X1, y1 = datasets.make_circles(n_samples=5000, factor=.6, noise=.05) X2, y2 = datasets.make_blobs(n_samples=1000, n_features=2, centers=[[1.2,1.2]], cluster_std=[[.1]], random_state=9) X = np.concatenate((X1, X2)) # 展示样本数据分布 plt.scatter(X[:, 0], X[:, 1], marker='o') plt.show() # eps和min_samples 需要进行调参 y_pred = DBSCAN(eps = 0.1, min_samples = 10).fit_predict(X) # 分类结果 plt.scatter(X[:, 0], X[:, 1], c=y_pred) plt.show() -
聚类效果

-
-
方法2:按照算法流程实现DBSCAN算法
-
算法流程参考了3.中算法步骤实现
-
代码结构如下(数据载入 + 算法调用 + 可视化 + k距离图调参)

-
聚类算法实现
import numpy as np import random #计算两个向量之间的欧式距离 def calDist(X1 , X2 ): sum = 0 for x1 , x2 in zip(X1 , X2): sum += (x1 - x2) ** 2 return sum ** 0.5 #获取一个点的ε-邻域(记录的是索引) def getNeibor(data , dataSet , e): res = [] for i in range(np.shape(dataSet)[0]): if calDist(data , dataSet[i])<e: res.append(i) return res #密度聚类算法 def DBSCAN(dataSet , e , minPts): coreObjs = {}#初始化核心对象集合 C = {} n = np.shape(dataSet)[0] #找出所有核心对象,key是核心对象的index,value是ε-邻域中对象的index for i in range(n): neibor = getNeibor(dataSet[i] , dataSet , e) if len(neibor)>=minPts: coreObjs[i] = neibor oldCoreObjs = coreObjs.copy() k = 0#初始化聚类簇数 notAccess = list(range(n))#初始化未访问样本集合(索引) while len(coreObjs)>0: OldNotAccess = [] OldNotAccess.extend(notAccess) cores = coreObjs.keys() #随机选取一个核心对象 randNum = random.randint(0,len(cores) - 1) # as index, max = size - 1 cores=list(cores) # print('\n randNum = ', randNum) # print('\n coresObjs.size = ', len(cores)) core = cores[randNum] queue = [] queue.append(core) notAccess.remove(core) while len(queue)>0: q = queue[0] del queue[0] if q in oldCoreObjs.keys() : delte = [val for val in oldCoreObjs[q] if val in notAccess]#Δ = N(q)∩Γ queue.extend(delte)#将Δ中的样本加入队列Q notAccess = [val for val in notAccess if val not in delte]#Γ = Γ\Δ k += 1 C[k] = [val for val in OldNotAccess if val not in notAccess] for x in C[k]: if x in coreObjs.keys(): del coreObjs[x] return C -
运行结果

-
如果需要完整工程可留言或私信博主
-
7. DBSCAN算法的c++实现
-
此处的DBSCAN算法的C++实现是按照3.中算法步骤完成的
-
代码结构

-
聚类算法的主要函数
#include "math/math.h" #include <vector> #include <unordered_map> extern const bool g_pedestrian_cluster_switch; /** * @namespace cluster * @brief cluster */ namespace cluster { using math::Point2d; class DataPoint { private: int target_id_; // pedestrian id Point2d target_position_; // pedestrian position int cluster_id_; // valid >= 0; -1 for noise point bool is_core_point_; // core point bool is_visited_; // visited after cluster std::vector<int> arrival_points_; // pedestians within epsilon_radius public: DataPoint() = default; ~DataPoint() { arrival_points_.clear(); } /** * @brief get pedestrian id * @return int */ int GetDpId() const; /** * @brief set pedestrian id * @return void */ void SetDpId(int target_id); /** * @brief get pedestrian position * @return Point2d& */ const Point2d& GetPosition() const; /** * @brief set pedestrian position * @param target_position */ void SetPosition(const Point2d& target_position); /** * @brief is core object * @return true if core object, otherwise false */ bool IsCorePoint() const; /** * @brief Set as core point * @param is_core_point * @return void */ void SetCorePoint(bool is_core_point); /** * @brief is visited when clustering * @return true if visited, otherwise false */ bool IsVisited() const; /** * @brief Set as Visited * @param is_visited */ void SetVisited(bool is_visited); /** * @brief Get the Cluster Id * @return int */ int GetClusterId() const; /** * @brief Set Cluster Id * @param cluster_id */ void SetClusterId(int cluster_id); /** * @brief Get the Arrival Points * @return vector<int>& */ std::vector<int>& GetArrivalPoints(); }; class ClusterAnalysis { private: // std::unordered_map<int, DataPoint> data_set_; std::unordered_map<int, DataPoint> data_set_; double epsilon_radius_; int min_points_; int data_num_; /** * @brief calculate distance of two pedestrians * @param point1 * @param point2 * @return double */ double GetDistance(DataPoint& point1, DataPoint& point2); /** * @brief record pedestrians within epsilon_radius * @param data_point pedestrian reference * @return void */ void SetArrivalPoints(DataPoint& data_point); /** * @brief pedestrians clustering within core point epsilon_radius * @param data_point pedestrian * @param cluster_id * @return void */ void KeyPointCluster(DataPoint& data_point, int cluster_id); public: ClusterAnalysis() = default; ~ClusterAnalysis() { data_set_.clear(); } /** * @brief initialization according to pedestrian data {id, position} * @param pedestrian_data pedestrian extracted info * @param radius search radius * @param min_points min points for core point * @return void */ void Init(const std::vector<std::pair<int, Point2d>>& pedestrian_data, double radius = 2.5, int min_points = 3); /** * @brief execute dbscan algorithm recursively * @return void */ void ExecDBSCANRecursive(); /** * @brief record clustered result for post-process * @param pedestrian_cluested_ids {cluster_id, vector<pedestrian_id>} * @return void */ void SetClusteredResults(std::unordered_map<int, std::vector<int>>& pedestrian_cluested_ids); }; } // cluster -
运行结果显示

-
如果需要完整工程可留言或私信博主
8. DBSCAN算法性能优化
【参考文章】
DBSCAN算法的原理介绍
DBSCAN算法的python实例
DBSCAN算法步骤
各类聚类算法的比较
算法调参1
算法调参2
算法调参3
不同参数的影响可视化
参数选取原则
算法参数取值
绘制k距离图
k距离图曲线拟合
DBSCAN算法的优缺点
DBSCAN算法的优缺点
常见聚类算法的优缺点比较1
常见聚类算法的优缺点比较2
算法的python实现参考
算法的python实现参考
算法的c++实现参考
created by shuaixio, 2022.10.22