基于时序行为的协同过滤推荐算法(Python)
目录
1相关工作 1
1.1 传统的协同过滤算法 1
1.2 基于时序信息的推荐算法 2
1.3 基于关系挖掘的协同过滤算法 2
2 问题定义和概率矩阵分解 3
3 SequentialMF 推荐算法描述 4
3.1 基于时序行为建模的最近邻选择 4
3.2 矩阵分解模型 5
3.3 SequentialMF时间复杂度分析 8
3.4 算法讨论 8
4 推荐框架 9
5 实验结果及分析 9
5.1 实验数据集 9
5.2 评价标准 10
5.3 比较算法及参数设定 10
5.4 实验结果与分析 12
6总结 15
4 推荐框架
第 3.1 节和第 3.2 节分别介绍了最近邻构建方式和求解优化方法,在本节中将给出本文提出的基于时序行 为的推荐算法具体的推荐框架.该推荐算法一共分 4 个步骤:
(1) 读入数据,其中数据的信息应包括用户的评分信息和评分的时间信息;
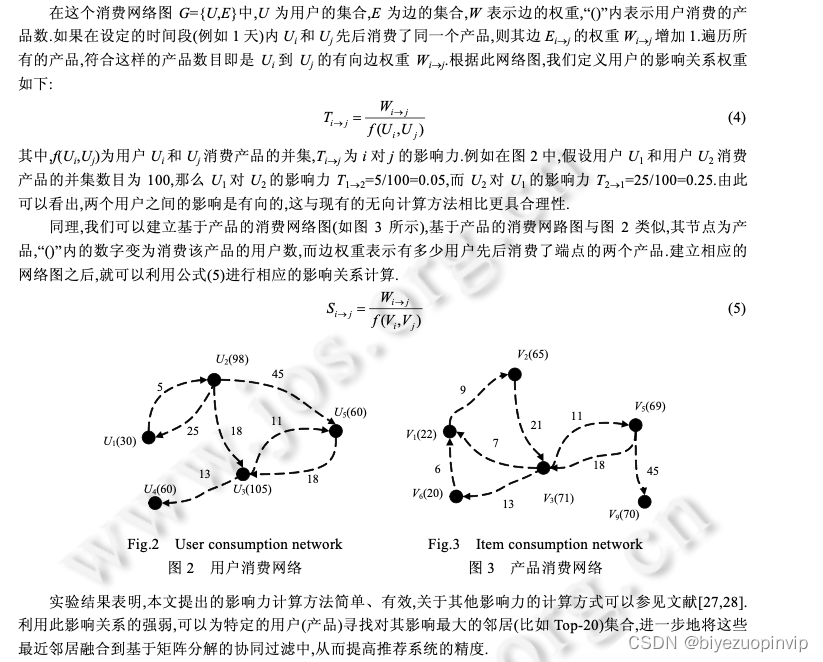
(2) 系统将根据读入的信息构建用户的消费网络图和产品的消费网络图,并根据此图计算影响力最大的 近邻集(第 3.1 节);
(3) 算法将该近邻集合运用到概率矩阵分解模型当中,利用概率矩阵分解模型学习出用户的特征向量和 项目的特征向量(第 3.2 节);
(4) 根据该特征向量预测重构评分矩阵,利用该评分矩阵对用户形成相应的推荐.
图 4 介绍了该算法的具体过程,图中对每个步骤都进行了相应的介绍.从图中可以看出,该算法中主要的计 算复杂度在步骤(2)和步骤(3)中,第 3.3 节已经对这两个步骤的时间复杂度进行了具体的分析.值得注意的是,在 实际的推荐系统中,往往将计算复杂度较高的步骤(1)~步骤(3)放在线下处理,通过已有的数据,在线下学习到用 户和产品的特征向量,而在线上则通过学习到的特征向量进行推荐,以提高系统的推荐速度;在线上推荐结束后,系统将用户在线上的行为数据再传输给存储系统,然后将根据新的数据更新相应的推荐模型. 从图 4 中可以更直观地看出,SequentialMF 推荐框架利用更易获取的时序信息获取关系信息,并且算法采 用有向的影响力来衡量关系程度,从而进一步提高推荐精度.最后算法将计算的关系信息融入到概率矩阵分解模型当中,为如何扩展矩阵分解提供了一条思路.
5 实验结果及分析
本节首先介绍实验所用数据集,然后说明评价标准及对比算法,最后给出 SequentialMF 模型与其他方法的 对比实验结果,并对实验结果进行了相应的分析.
5.1 实验数据集
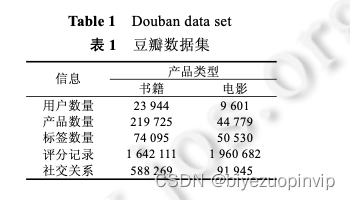
为了可以比较不同信息(关系)对推荐结果的影响,实验数据集应当含有评分信息、标签信息以及用户社会 关系.为此,本文使用从豆瓣网站抓取的数据作为实验数据集.豆瓣网站是一个针对电影、书籍及音乐的评价讨 论网站,网站为用户提供了评分、讨论以及推荐服务.它拥有目前中国最大的中文类书籍、音乐以及电影数据 库,并且是中国最大的网上社区之一.在该网站中,每个用户可以为书籍、音乐或电影做出[1,5]范围内的评分.另 外,豆瓣中也提供了类似于 Facebook 的社交关系服务,它允许用户通过 E-mail 发现自己的朋友.本文转载自http://www.biyezuopin.vip/onews.asp?id=16999综上所述,豆瓣 数据集比较适合本文中的实验研究.
本文从豆瓣网站中抓取了两组数据集:一组数据为用户对书籍的评分信息、用户社交关系以及标签信息, 另一组数据为用户对电影的评分信息及对应的其他信息.数据情况见表 1.
# -*- coding: utf-8 -*-
# --------------------------------------------------------
# Name: UserBasedCF.py
# Purpose: 基于已知的训练集,"测试集"中的user的item进行评分预测.
# Data: MovieLens
# Language: Python 2.7
# Author: Hailin
# E-mail: hailinfufu@outlook.com
# Created: 1-11-2016
# --------------------------------------------------------
import math, random, sys, datetime
from math import sqrt
from loadMovieLens import loadMovieLensTrain
from loadMovieLens import loadMovieLensTest
class UserBasedCF:
def __init__(self, train=None, test=None):
self.trainfile = train
self.testfile = test
self.readData()
def readData(self, train=None, test=None):
self.trainfile = train or self.trainfile
self.testfile = test or self.testfile
self.traindata = loadMovieLensTrain(train) # 加载训练集
self.testdata = loadMovieLensTest(test) # 加载测试集
def generate_dataset(self, filename, pivot=0.7):
''' load rating data and split it to training set and test set '''
trainset_len = 0
testset_len = 0
for line in self.loadfile(filename):
user, movie, rating, _ = line.split('::')
# split the data by pivot
if (random.random() < pivot):
self.trainset.setdefault(user, {})
self.trainset[user][movie] = int(rating)
trainset_len += 1
else:
self.testset.setdefault(user, {})
self.testset[user][movie] = int(rating)
testset_len += 1
print >> sys.stderr, 'split training set and test set succ'
print >> sys.stderr, 'train set = %s' % trainset_len
print (self.trainset)
print >> sys.stderr, 'test set = %s' % testset_len
print (self.testset)
### 计算pearson相关度
def sim_pearson(prefer, person1, person2):
sim = {}
# 查找双方都评价过的项
for item in prefer[person1]:
if item in prefer[person2]:
sim[item] = 1 # 将相同项添加到字典sim中
# 元素个数
n = len(sim)
if len(sim) == 0:
return -1
# 所有偏好之和
sum1 = sum([prefer[person1][item] for item in sim])
sum2 = sum([prefer[person2][item] for item in sim])
# 求平方和
sum1Sq = sum([pow(prefer[person1][item], 2) for item in sim])
sum2Sq = sum([pow(prefer[person2][item], 2) for item in sim])
# 求乘积之和 ∑XiYi
sumMulti = sum([prefer[person1][item] * prefer[person2][item] for item in sim])
num1 = sumMulti - (sum1 * sum2 / n)
num2 = sqrt((sum1Sq - pow(sum1, 2) / n) * (sum2Sq - pow(sum2, 2) / n))
if num2 == 0: ### 如果分母为0,本处将返回0.
return 0
result = num1 / num2
return result
### 获取对item评分的K个最相似用户(K默认20)
def topKMatches(prefer, person, itemId, k=20, sim=sim_pearson):
userSet = []
scores = []
users = []
# 找出所有prefer中评价过Item的用户,存入userSet
for user in prefer:
if itemId in prefer[user]:
userSet.append(user)
# 计算相似性
scores = [(sim(prefer, person, other), other) for other in userSet if other != person]
# 按相似度排序
scores.sort()
scores.reverse()
if len(scores) <= k: # 如果小于k,只选择这些做推荐。
for item in scores:
users.append(item[1]) # 提取每项的userId
return users
else: # 如果>k,截取k个用户
kscore = scores[0:k]
for item in kscore:
users.append(item[1]) # 提取每项的userId
return users # 返回K个最相似用户的ID
### 计算用户的平均评分
def getAverage(prefer, userId):
count = 0
sum = 0
for item in prefer[userId]:
sum = sum + prefer[userId][item]
count = count + 1
return sum / count
### 平均加权策略,预测userId对itemId的评分
def getRating(prefer1, userId, itemId, knumber=20, similarity=sim_pearson):
sim = 0.0
averageOther = 0.0
jiaquanAverage = 0.0
simSums = 0.0
# 获取K近邻用户(评过分的用户集)
users = topKMatches(prefer1, userId, itemId, k=knumber, sim=sim_pearson)
# 获取userId 的平均值
averageOfUser = getAverage(prefer1, userId)
# 计算每个用户的加权,预测
for other in users:
sim = similarity(prefer1, userId, other) # 计算比较其他用户的相似度
averageOther = getAverage(prefer1, other) # 该用户的平均分
# 累加
simSums += abs(sim) # 取绝对值
jiaquanAverage += (prefer1[other][itemId] - averageOther) * sim # 累加,一些值为负
# simSums为0,即该项目尚未被其他用户评分,这里的处理方法:返回用户平均分
if simSums == 0:
return averageOfUser
else:
return (averageOfUser + jiaquanAverage / simSums)
##==================================================================
### 计算RMSE评分预测
def getRMSE(records):
return math.sqrt(sum([(rui-pui)*(rui-pui) for u,i,rui,pui in records]))/float(len(records))
### 计算MAE评分预测
def getMAE(records):
return sum([abs(rui-pui) for u,i,rui,pui in records])/float(len(records))
## getAllUserRating(): 获取所有用户的预测评分,存放到fileResult中
##
## 参数:fileTrain,fileTest 是训练文件和对应的测试文件,fileResult为结果文件
## similarity是相似度度量方法,默认是皮尔森。
##==================================================================
def loadfile(filename):
''' load a file, return a generator. '''
fp = open(filename, 'r')
for i, line in enumerate(fp):
yield line.strip('\r\n')
# if i % 100000 == 0:
# print >> sys.stderr, 'loading %s(%s)' % (filename, i)
fp.close()
#print >> sys.stderr, 'load %s succ' % filename
def getAllUserRating(n=1,k=20, similarity=sim_pearson):
if(n==1):
traindata = loadMovieLensTrain('ml-100k/u1.base') # 加载训练集
testdata = loadMovieLensTest('ml-100k/u1.test') # 加载测试集
else:
pivot = 0.7
traindata={}
testdata={}
for line in loadfile('ml-1m/ratings.dat'):
user, movie, rating, _ = line.split('::')
# split the data by pivot
if (random.random() < pivot):
traindata.setdefault(user, {})
traindata[user][movie] = int(rating)
else:
testdata.setdefault(user, {})
testdata[user][movie] = int(rating)
inAllnum = 0
records=[]
for userid in testdata: # test集中每个用户
for item in testdata[userid]: # 对于test集合中每一个项目用base数据集,CF预测评分
rating = getRating(traindata, userid, item, k) # 基于训练集预测用户评分(用户数目<=K)
records.append([userid,item,testdata[userid][item],rating])
inAllnum = inAllnum + 1
#np.savetxt("records.txt",records,fmt='%1.4e')
#print("-------------Completed!!-----------", inAllnum)
SaveRecords(records)
return records
def SaveRecords(records):
file = open('records.txt', 'a')
file.write("%s\n" % ("------------------------------------------------------"))
for u, i, rui, pui in records:
file.write('%s\t%s\t%s\n' % (u, i, rui,pui))
file.close()
############ 主程序 ##############
if __name__ == "__main__":
trainfile = 'ml-100k/u1.base'
testfile = 'ml-100k/u1.test'
ratingfile = 'ml-1m/ratings.dat'
#usercf=UserBasedCF()
#usercf.generate_dataset()
print("\n--------------基于MovieLens的推荐系统 运行中... -----------\n")
print ("请选择你要使用的数据集\n1:ml-100k\n2:ml-1m")
n=input("Your choose:")
if(n==1):
print ("即将进行的试验数据为ml-100k")
else:
print ("即将进行的试验数据为ml-1m")
starttime = datetime.datetime.now()
print("%3s%20s%20s%20s" % ('K', "RMSE","MAE","耗时"))
for k in [ 25, 50, 75, 100, 125, 150]:
r=getAllUserRating(n, k)
rmse=getRMSE(r)
mae=getMAE(r)
print("%3d%19.3f%%%19.3f%%%17ss" % (k, rmse * 100, mae * 100, (datetime.datetime.now() - starttime).seconds))