为什么你的程序跑不满CPU?——简单聊聊多核多线程
最近同事测试自己的程序,感觉处理耗时太长,一看CPU使用率,才25%。想要提高CPU使用率降低处理时长,于是向我询问。以此为契机写了这篇,聊聊多核多线程。水平有限,仅供参考。
1.单核单线程
一切开始的前提是,你需要知道,CPU执行的所有代码其实就是一条条指令。
首先来聊聊单核单线程下你的程序是怎么运行的。假如你的程序就两行代码:
b=a+1;
c=b+1;
而你的CPU每运行一行代码需要1秒,那么很明显,对于单核CPU来说,运行你的代码需要2秒。但实际上这往往需要2秒多,因为你的CPU还需要处理很多可能的中断,比如当你的CPU刚执行完b=a+1时, 这个时候插入了一台USB设备,它触发了一个中断,中断你可以简单理解为一个函数,这里的USB中断你可以理解为,插入了USB就要执行一个“USB函数”,这个过程不受控制(实际过程复杂的多)。一般来说中断优先级是高于你的用户代码的,所以CPU只能转头去执行USB函数中的代码,这个时候你的代码才执行到了一半,当执行完USB函数后,CPU才会转头回来继续执行你的代码。最终你的代码可能运行了3秒甚至更久。
2.单核多线程
你可能觉得2秒甚至更久的时间对你的程序来说太长了,那是否可以使用多线程优化程序的执行?
其实仔细想一下就知道,无论使用多少个线程,假如CPU每执行一行代码就是1秒,那这两行代码怎么也得要2秒。所以单核情况下,多线程并不会提高代码执行效率。单核多线程的意义在于,当你的代码中有需要等待的地方,CPU可以在等待时去做其他事,这里你需要知道,CPU调度的最小单位是线程。比如上文中的例子假如是这样:
b=a+1;
sleep(1);
d=c+1;
正常你用单个线程去跑这段代码假如需要3秒,最后我们需要的结果是b和d,但很明显d=c+1在这里需要等待sleep休眠1秒后才能计算,而实际上这行代码和前文并没有数据上的关联和依赖。如果此时我们用两个线程,线程1跑【b=a+1;sleep(1)】,线程2跑【d=c+1】,虽然我们的CPU是单核的,意味着同一时间只能跑一行代码,但是在线程1运行完b=a+1后,sleep时,CPU可以转去执行d=c+1,这样最终我们只用了2秒就可以得到b和d的结果,此时多线程的运用相当于填补了CPU执行sleep等类似的等待过程。
单核多线程的另外一个意义是可以做到多个线程“同时”进行,注意这里的同时是加引号的。这种情况下每个线程如果优先级相同,则它们可能消耗相同的时间片,你可以把时间片简单理解为每个线程每次能够运行的最大时间。这适用于对时间不敏感,但是强调了同时的程序。比如你的代码是这样的:
b=a+1;
d=c+1;
f=e+1;
h=g+1;
很明显这段代码运行需要最少4秒,上文我说过,使用多线程并不能缩短这个时间,但是你希望【b=a+1;d=c+1】和【f=e+1;h=g+1】这两段代码“同时”执行,这种情况下使用多线程也是可以的,假如时间片=1秒,如果把这两段代码分别放在两个线程,且它们优先级相同,则CPU的执行顺序可能是这样的:
第一秒:先执行线程1的b=a+1;
第二秒:线程1的时间片消耗完了,CPU转去执行线程2的f=e+1;
第三秒:线程2的时间片消耗完了,CPU转去执行线程1的d=c+1;
第四秒:线程1的时间片又消耗完了,CPU又转去执行线程2的h=g+1;
最终CPU还是消耗了4秒执行上述代码,但是却是两个线程交替执行。这在某些场景,比如播放电影(我们需要播放画面的同时,播放音频)时,是很有用的。
单核情况下的多线程叫做并发。也就是所谓的单核多线程其实只是在同一个CPU上交替执行多个线程,但实际是,在任意时间点,只能有一个线程执行,只不过CPU切换的速度很快,给你造成一种多个线程同时运行的假象。只有多核才能做到真正意义上的同时运行。更多细节可以搜索并发与并行的区别。
3.多核单线程
假如你有一个四核CPU,每个核还是1秒执行1行代码,而你的代码是:
b=a+1;
c=b+1;
e=d+1;
f=e+1;
如果把这四行代码放在一个mian函数里执行,你会发现CPU在程序执行的时候,只有25%。这是否是因为有3个核压根就没有工作?
其实不然,这种情况下,无论是只使用1个核还是四个核都使用,CPU使用率最多都是25%。为什么?
假如你的程序只放在第一个核上运行,这很好理解:
| 时间 | CPU0使用率 | CPU1使用率 | CPU2使用率 | CPU3使用率 |
| 第1秒 | 100% | 0% | 0% | 0% |
| 第2秒 | 100% | 0% | 0% | 0% |
| 第3秒 | 100% | 0% | 0% | 0% |
| 第4秒 | 100% | 0% | 0% | 0% |
4秒内,CPU实际可以执行16行代码,而实际只有CPU0执行了4行,所以CPU在4秒内总的使用率为4/16=25%。
假如你的程序在4个核上运行,则可能是:
| 时间 | CPU0使用率 | CPU1使用率 | CPU2使用率 | CPU3使用率 |
| 第1秒 | 100% | 0% | 0% | 0% |
| 第2秒 | 0% | 100% | 0% | 0% |
| 第3秒 | 0% | 0% | 100% | 0% |
| 第4秒 | 0% | 0% | 0% | 100% |
同样的也是25%。你可以能会好奇为何CPU不是按下面的方式运行的:
| 时间 | CPU0使用率 | CPU1使用率 | CPU2使用率 | CPU3使用率 |
| 第1秒 | 100% | 100% | 100% | 100% |
| 第2秒 | 0% | 0% | 0% | 0% |
| 第3秒 | 0% | 0% | 0% | 0% |
| 第4秒 | 0% | 0% | 0% | 0% |
在这种情况下,我们统计CPU占用率的周期很重要,如果以4秒为一个周期,那CPU使用率还是25%,如果以1秒为周期则第一秒使用率是100%,后面3秒使用率都是0%。但我们最关心的还是这种情况下可以把程序执行需要4秒给缩短到1秒。但这种情况是不可能发生的,当你使用单线程写了一个程序时,就注定了你的每行代码都要依次执行(这里不考虑CPU乱序执行,且就算乱序也不影响),你的第二行代码就必须等第一行代码执行完毕才能执行,无论第一行代码或是第二行代码在哪个CPU上执行!所以,无论以哪种情况来说,你的CPU从你的代码开始到结束,占用率最多25%,且必须耗时4秒甚至更久才能执行完。
4.多核多线程
按照上面的说法,我们是否可以把4行代码分别放在四个线程中,这样岂不是可以实现表3?
实际是可以实现的,但可惜的是,计算结果是错误的。因为我们可以看到,4行代码里面,数据是有依赖关系的,计算c之前需要保证先计算b,计算b之前,需要保证a是正确的。这就是所谓的线程间同步。所以即使是使用4个线程,为了使计算结果正确,我们也没有办法做到耗时1秒。
在这个例子中,假如我们把四行代码分别放在四个线程中,然后四个线程分别在4个核上运行,比如第一个核上运行线程1,执行的是第一行代码,以此类推。
那我们的代码在实际考虑数据依赖关系后,很可能是:
第一秒,线程1执行,其他线程都等待,也就是虽然其他线程放在其他核上,但是其他核使用率仍然为0%。
第二秒,线程1执行完毕,告诉了线程2,然后线程2开始执行,此时CPU0、2、3核都没在使用。
第三秒,线程2执行完毕,告诉了线程3,然后线程3开始执行,此时CPU0、1、3核都没在使用。
第四秒,线程3执行完毕,告诉了线程4,然后线程4开始执行,此时CPU0、1、2核都没在使用。
其中一个线程如何告诉另一个线程可以搜索线程(进程)间同步方式相关资料。
我们看下来,发现好像使用多线程也并没有缩小耗时,也就是说,如果你的程序执行有数据依赖关系的,多线程并不能优化执行效率,因为你后面的代码即使可以执行,也无法执行,因为它要等待前面的代码计算完成,用前面的计算结果继续计算。
细心的你可能发现,上面例子中第三行代码并不需要等待第二行代码执行完毕,因为c=b+1和e=d+1并没有关系,也就是第二行代码必须等第一行计算完毕,第四行代码必须等第三行计算完毕,但是前两行和后两行并没有一点关系,那我们完全可以把第1、2行代码放在线程1中,运行在其中一个核上,把第3、4行代码放在线程2中,运行在另一个核上,最终CPU使用率是:
| 时间 | CPU0使用率 | CPU1使用率 | CPU2使用率 | CPU3使用率 |
| 第1秒 | 100% | 100% | 0% | 0% |
| 第2秒 | 100% | 100% | 0% | 0% |
| 第3秒 | 0% | 0% | 0% | 0% |
| 第4秒 | 0% | 0% | 0% | 0% |
之前的多核单线程中,程序需要运行4秒,总体CPU使用率25%,现在程序只需要运行2秒,总体CPU使用率50%。此时才把多核多线程优势完全发挥出来。
这是否就是多线程优化极限了?
其实在特殊情况下,还可以再次优化。
多级流水线
很多情况下,我们的程序需要处理的数据是流式的,比如音视频,也就是数据会每隔一定时间来一帧,而我们的程序需要每来一帧处理一次,这个时候如果数据来的时间大于数据处理的时间,我们可以仿照CPU的多级流水线的设计思路优化我们的处理。
按照我们上文的例子,假如我们的处理流程是这样的:
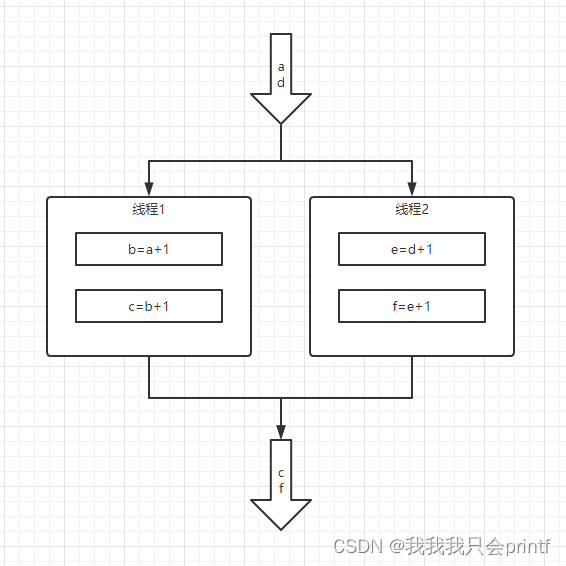
在这里,a和d每隔2秒来一次的话是可以正常输出c和f的值的,如果a和d每隔1秒来一次的话,等到下一次数据来,我们上次数据还没有计算完成,肯定会卡顿,导致数据丢失,而且这种情况无法通过缓存输入数据解决,因为这会越堆积越多。但是如果我们按照下面的思路修改:
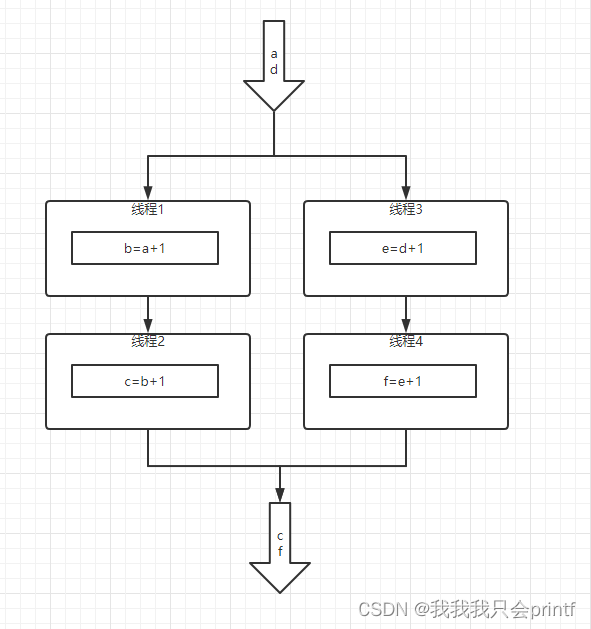
程序运行流程是这样的:
第一秒:第一帧数据到来,线程1和线程3执行,因为没有线程1和3的结果,线程2和线程4运行跳过,最终没有输出c、f,CPU使用率50%
第二秒:第二帧数据到来,线程1和线程3计算第二次来的数据,线程2和线程4计算上一轮中线程1和线程3输出的数据,最终输出第一帧数据对应的c、f,CPU使用率100%
第三秒:第三帧数据到来,线程1和线程3计算第三次来的数据,线程2和线程4计算上一轮中线程1和线程3输出的数据,最终输出第二帧数据对应的c、f,CPU使用率100%
余下同理。
由上可以看出,通过错位一帧,我们可以把CPU使用率从原来的50%提高到100%,虽然输出落后输入一帧,但是却可以满足1秒输出一次的要求。使用此种方法需要考虑三个问题,一是整个过程耗时、被分割为每一级的耗时、与输入间隔之间是否满足要求,理论上分割级数越多,整体耗时越短。二是分割级数越多,输入与输出之间的迟滞越长。三是因为每一级都要保存上次计算的结果(有时候我们可能并不是像这个例子一样那么简单,可能每级之间都使用队列通信,此时缓存的数据不止一帧),所以分级越多,内存消耗越大。