JMeter的使用——傻瓜式学习【中】
目录
前言
1、JMeter参数化
1.1、什么是参数化
1.2、用户定义的变量
1.2.1、什么时候使用用户定义的变量
1.2.2、使用“用户定义的变量”进行参数化的步骤:
1.2.3、案例
1.3、用户参数
1.3.1、什么时候使用用户参数?
1.3.2、使用“用户参数”进行参数化的步骤:
1.3.3、案例
1.4、CSV数据文件设置
1.4.1、什么时候使用CSV数据文件设置
1.4.2、使用“CSV数据文件设置”进行参数化的步骤?
1.4.3、案例
1.5、函数——随机数据
1.5.1、使用场景
1.5.2、使用“counter函数”进程参数化的步骤:
1.5.3、案例
1.6、4种参数化方式对比
2、JMeter断言
2.1、响应断言
2.2.1、参数认识:
2.1.2、案例:
2.2、JSON断言
2.2.1、参数认识:
2.2.2、案例:
2.3、持续时间断言
2.3.1、参数说明
2.3.2、案例:
3、JMeter关联
3.1、正则表达式提取器
3.1.1、介绍正则表达式
案例使用一:
案例二:
3.1.2、正则表达式提取器
案例:
3.2、Xpath提取器
案例:
3.3、JSON提取器
案例:
前言
小白同学,可以先看这篇哦:http://t.csdnimg.cn/geQnl
1、JMeter参数化
1.1、什么是参数化
定义:使用不同的测试数据,调用相同的测试方法进行测试
本质:实现测试数据与测试方法的分离
实现方式举例:
- 用户定义的变量——全局变量【JMeter有】
- 用户参数——为每个用户分配不同的参数值【Jmeter有】
- CSV数据文件设置——文件方式参数化【Jmeter有】
- 函数——随机数据【JMeter有】
- 数据库
下面我们来看看JMeter中的几种参数化:
1.2、用户定义的变量
1.2.1、什么时候使用用户定义的变量
定义全局变量
1.2.2、使用“用户定义的变量”进行参数化的步骤:
- 添加线程组
- 添加用户定义的变量。格式为变量名 - 变量值
- 添加http请求,引用定义的变量名。格式:${变量名}
- 添加察看结果树
1.2.3、案例
步骤一:添加线程组

步骤二:添加用户定义的变量
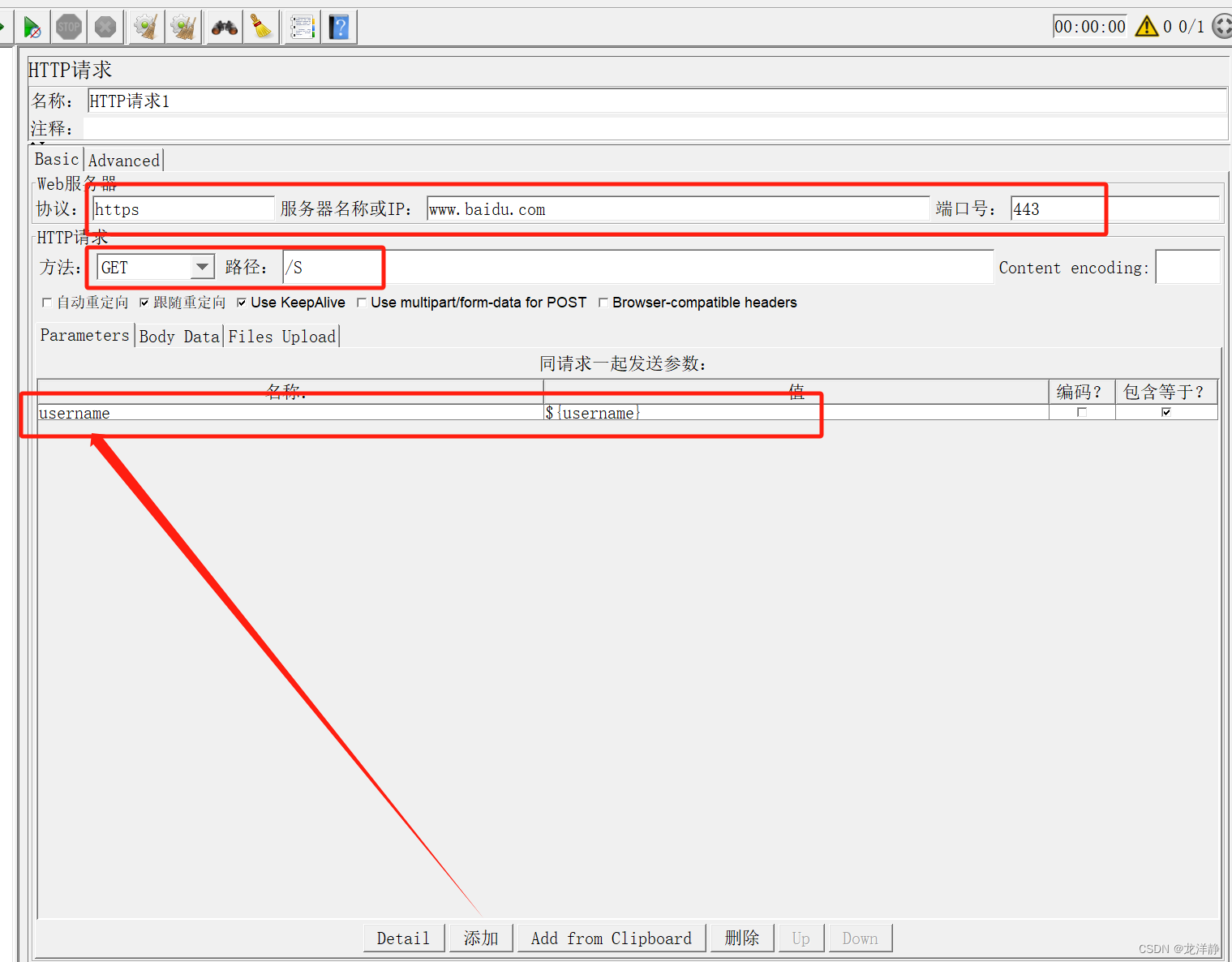
步骤三:添加http请求
http中可以这样填:

也可以这样填:
步骤四:添加察看结果树
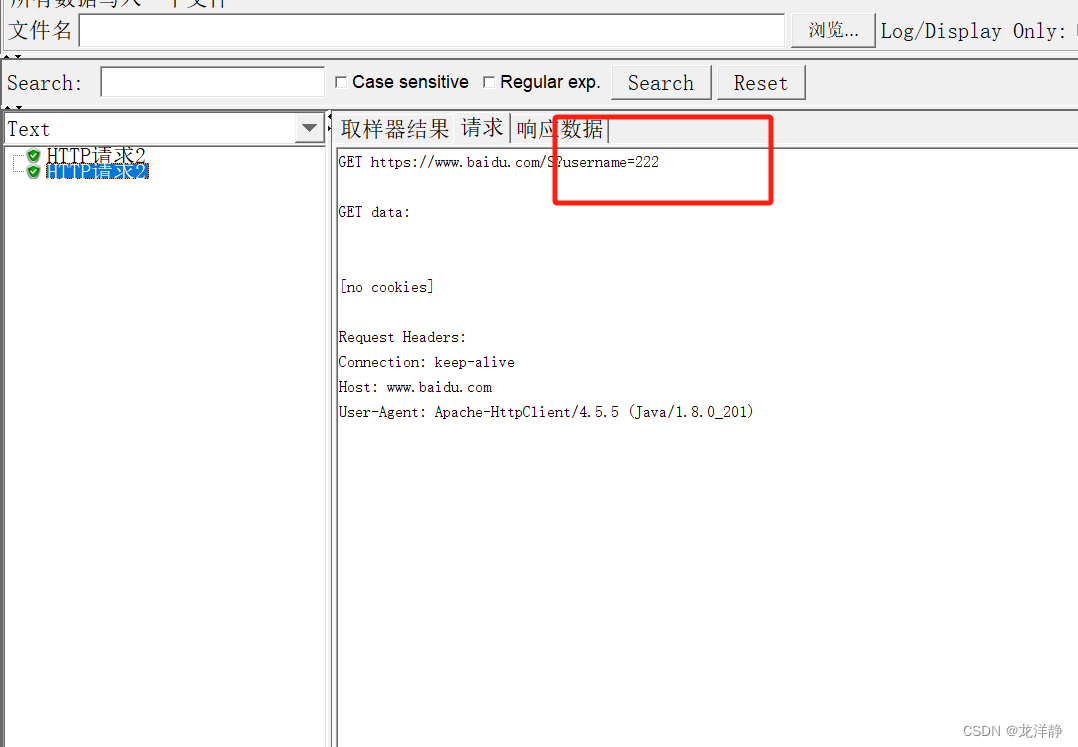
查看运行结果:

1.3、用户参数
1.3.1、什么时候使用用户参数?
针对同一组参数,当不同的用户来访问时,可以获取到不同的值
1.3.2、使用“用户参数”进行参数化的步骤:
- 添加线程组,设置线程数为n(模拟的用户数)
- 添加用户参数:第一列添加多个变量名;后续每一列为一组用户数据【看案例】
- 添加http请求,引用定义的变量名。格式:${变量名}
- 添加查看结果树
1.3.3、案例
步骤一:添加线程组
和上面一样,记得设置线程数,例:2
步骤二:添加用户参数


步骤三:添加http请求
同第一个案例
步骤四:添加察看结果树
同第一个案例
查看运行结果:

1.4、CSV数据文件设置
1.4.1、什么时候使用CSV数据文件设置
当不同的用户,或者同一个用户多次循环时,都可以获取到不同的值
1.4.2、使用“CSV数据文件设置”进行参数化的步骤?
- 定义CSV数据文件
- 添加线程组
- 添加CSV数据文件设置
- 添加http请求,引用定义的变量名。格式${变量名}
- 添加查看结果树
1.4.3、案例
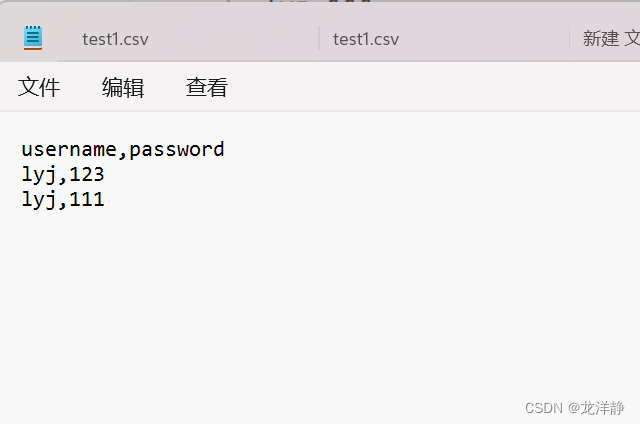
步骤一:定义CSV数据文件
步骤二:添加线程组
同案例1,设置循环次数,例:2
步骤三:添加CSV数据文件设置


步骤四:添加http请求
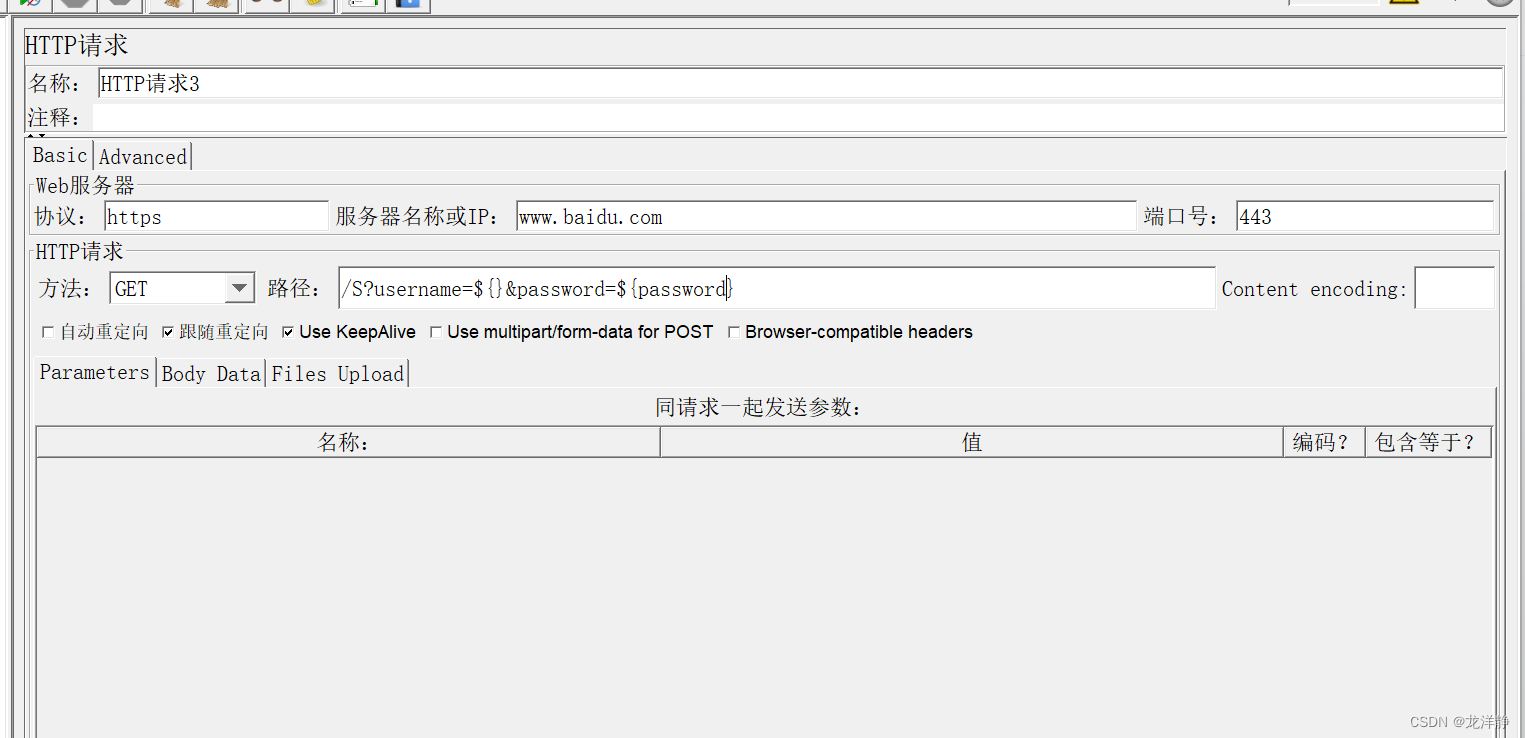
步骤五:添加察看结果树
同案例1
查看运行结果:
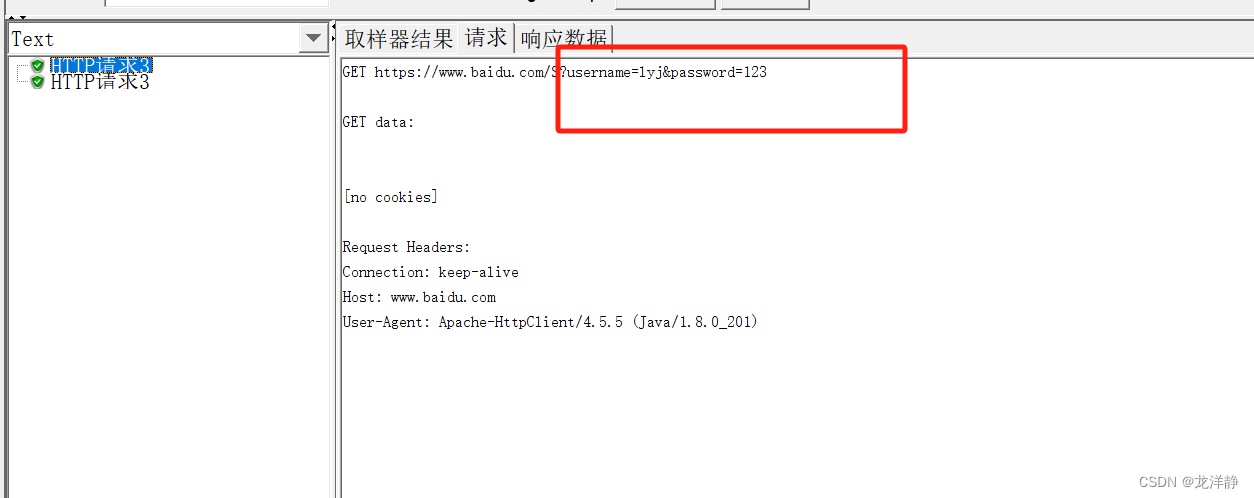
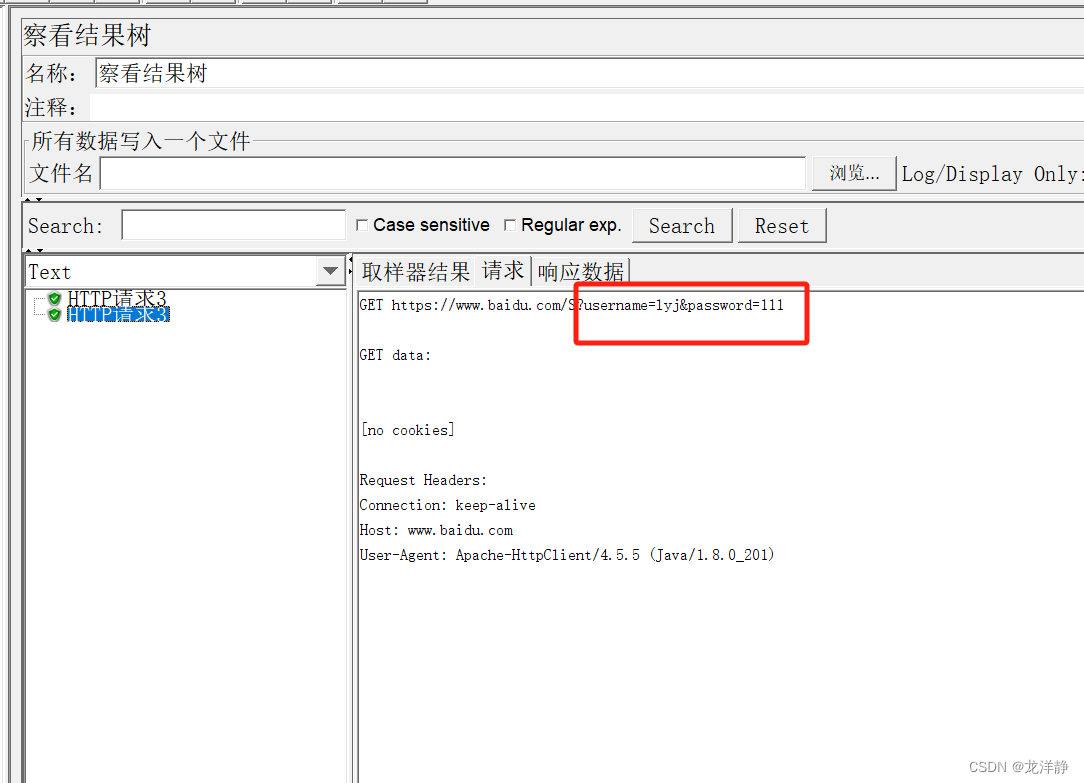
1.5、函数——随机数据
1.5.1、使用场景
自动生成不重复的数据,让每个用户循环都能取到不同的数据,且不需要提前定义
1.5.2、使用“counter函数”进程参数化的步骤:
- 添加线程组,设置虚拟用户数和循环次数
- 生成_counter函数
- 添加http请求,使用_counter函数。格式:${_counter(FALSE,)}
- 添加察看结果树
1.5.3、案例
步骤一:添加线程组
同上,设置线程数2,循环次数2
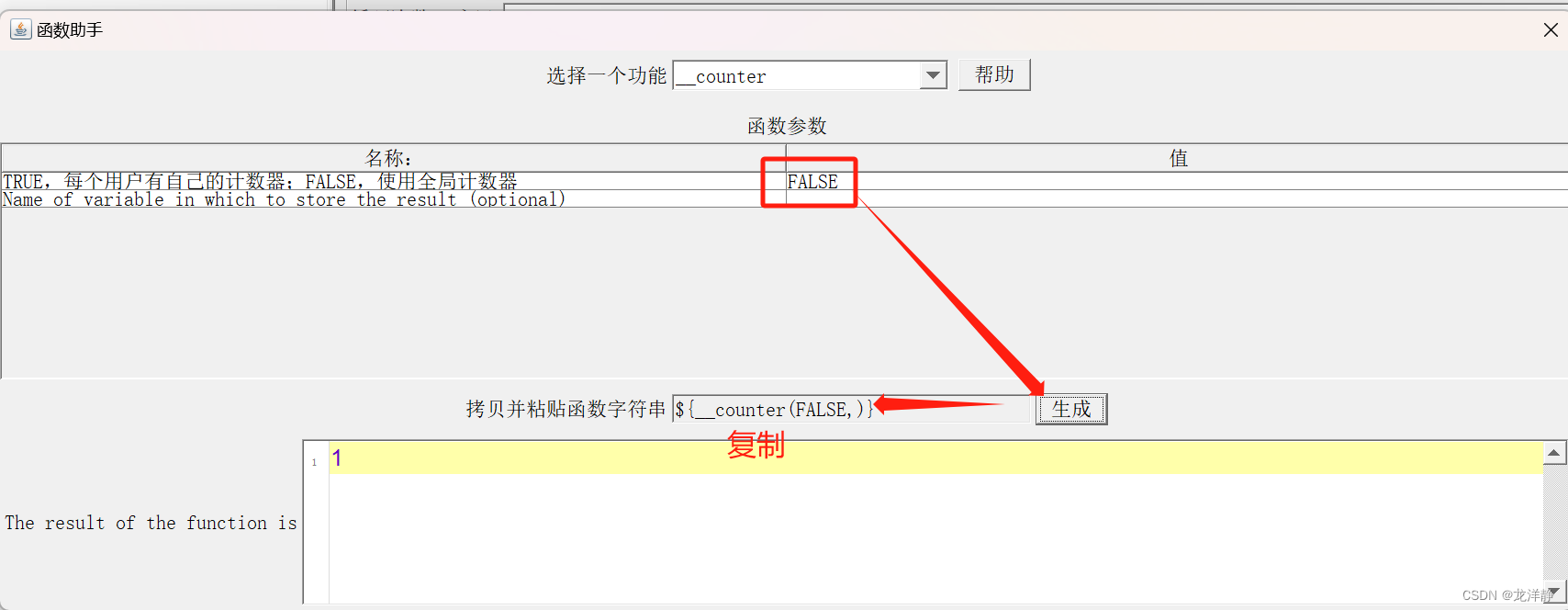
步骤二:生成_counter函数

参数:
-
第一个参数
- True,每个用户(线程)的计数器保持独立,每个用户(线程)计数从1开始计数。
- False,全局计数器,所以用户(线程)统一从1开始计数。
-
第二个参数
- 将计数器函数生成的值赋值给新变量。比如,新变量名称为number,后续可以通过参数化方式${number}引用计数器的值。
步骤三:添加http请求

步骤四:添加察看结果树
同上
查看运行结果:


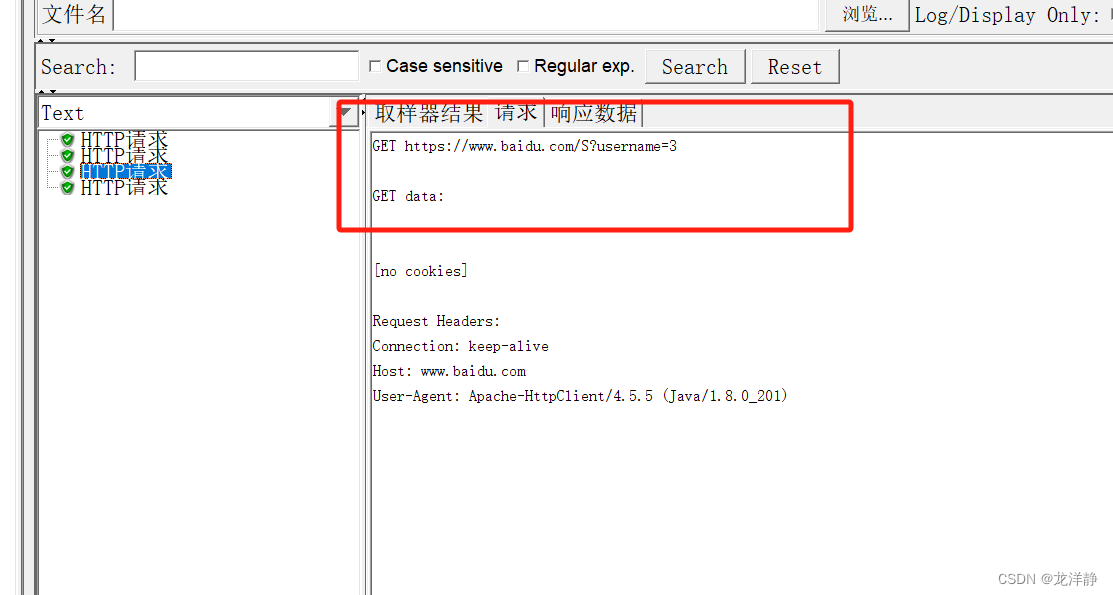
1.6、4种参数化方式对比
- 用户定义的变量:作用:定义全局变量;局限性:每次取值(无论是否相同的用户)都是固定值
- 用户参数:作用:保证不同的用户针对同一组参数,可以取到不同的值;局限性:同一个用户在多次循环中,取到相同的值
- CSV数据文件设置:作用:保证不同的用户及同一用户多次循环时,都可以取到不同的值;局限性:需要手动进行设置测试数据
- 函数:作用:保证不同的用户多次循环时,都可以取到不同的值,不需要提前设置;局限性:输入数据有特定的业务要求时无法使用
2、JMeter断言
断言就是让程序判断预期结果与实际结果是否一致
JMeter中常用的断言:
- 响应断言
- JSON断言
- 持续时间断言
2.1、响应断言
2.2.1、参数认识:

各个参数说明:
1:
- 响应文本:来自服务器的响应文本,即主体
- 响应代码:响应的状态码,例如200
- 响应信息: 响应的信息,例如OK
- response headers:相应头部
- request Headers:请求头部
- request Data:请求数据
- URL样本:请求的URL
- Document(text):响应的整个文档
- Ignore Status:忽略返回的响应状态码
2:
- 包括:文本包含指定的正则表达式(正则表达式后面会简单介绍一下,现在就理解为包含一个字符串就可以了)
- 匹配:整个文本匹配指定的正则表达式
- Equals:整个返回结果的文本等于指定的字符串(区分大小写)
- Substring:返回结果的文本包含指定字符串(区分大小写)
- 否:取反。就是指符合刚才的断言即为错,不符合为对
- 或者:多个测试模式,有一个满足即为通过。默认是且,所有通过才为通过
2.1.2、案例:
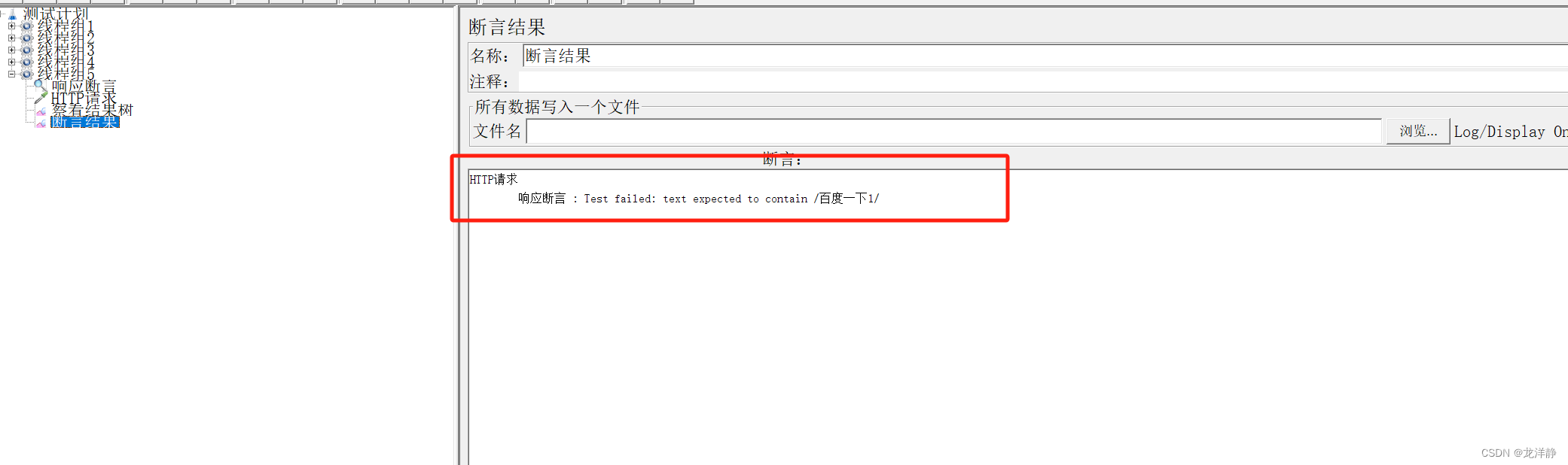
断言:

添加一个断言结果:
http请求:
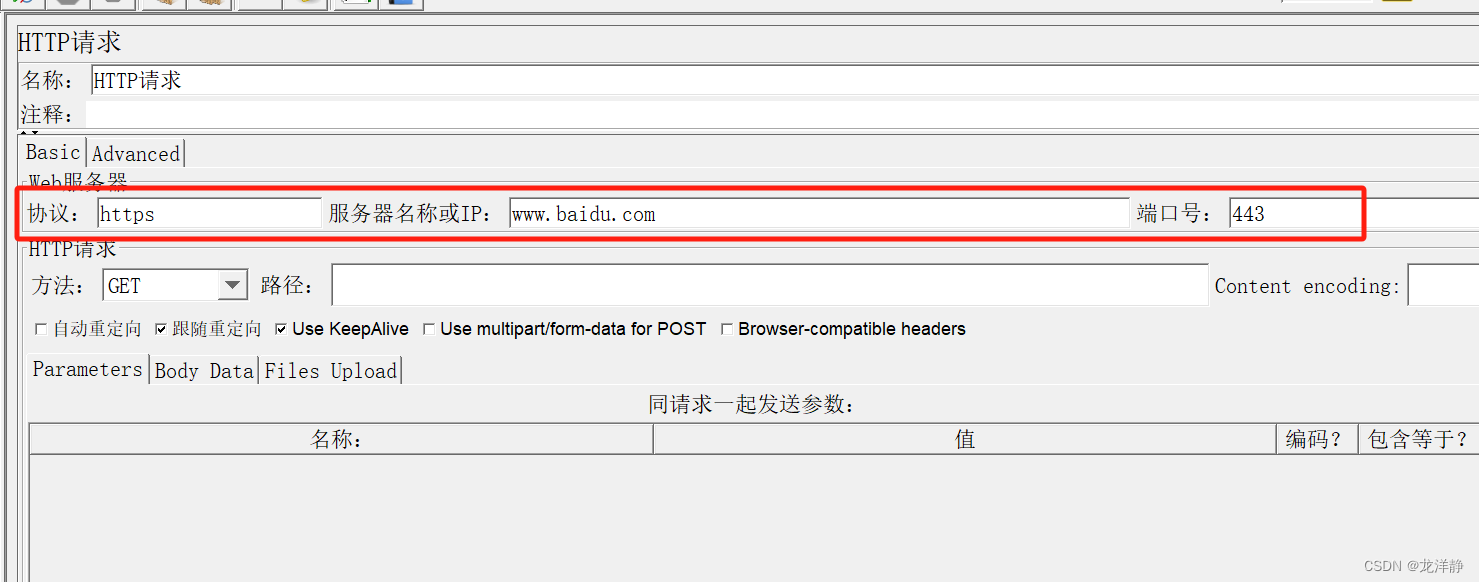
运行后,查看结果:
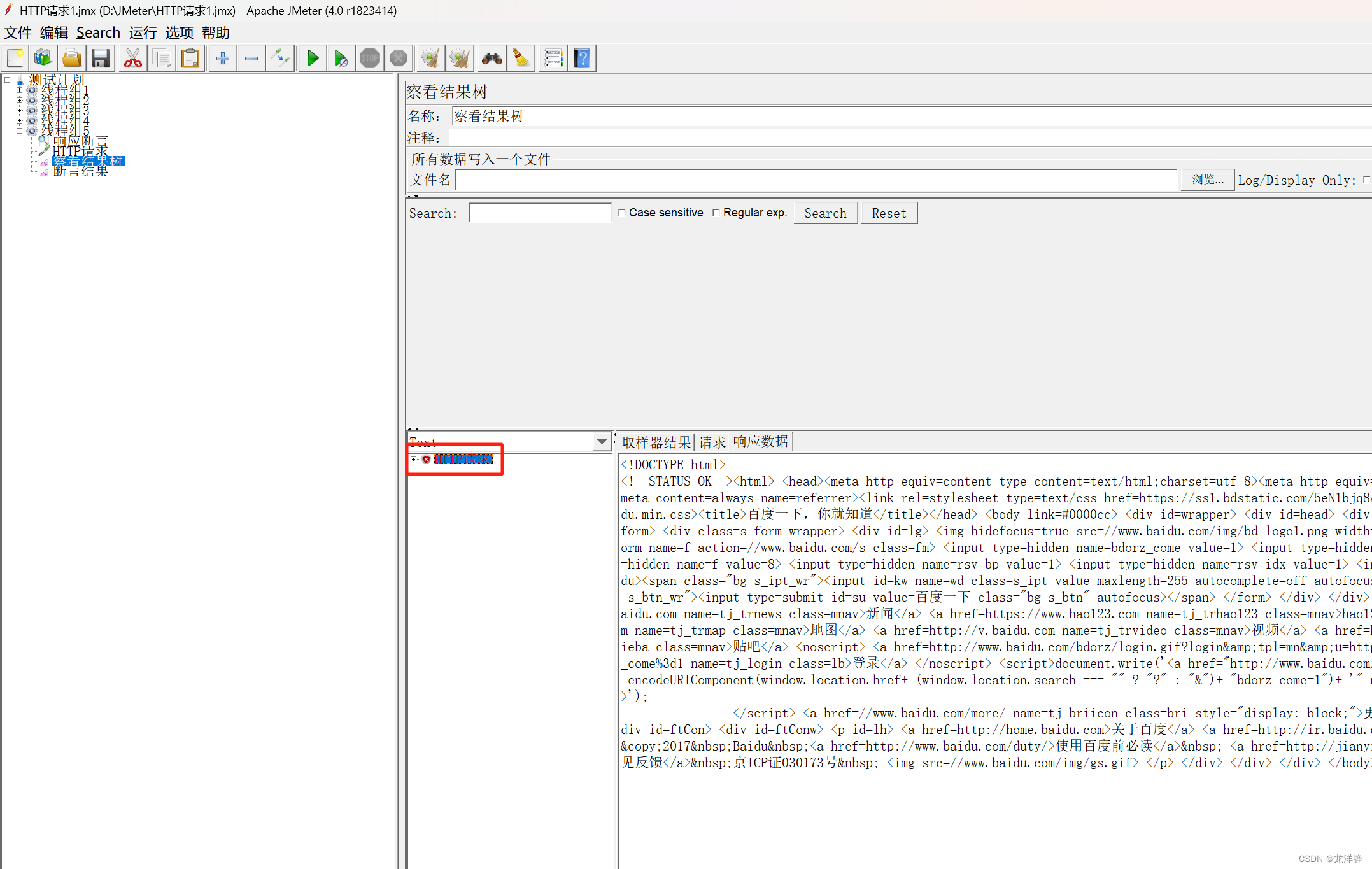
2.2、JSON断言
2.2.1、参数认识:
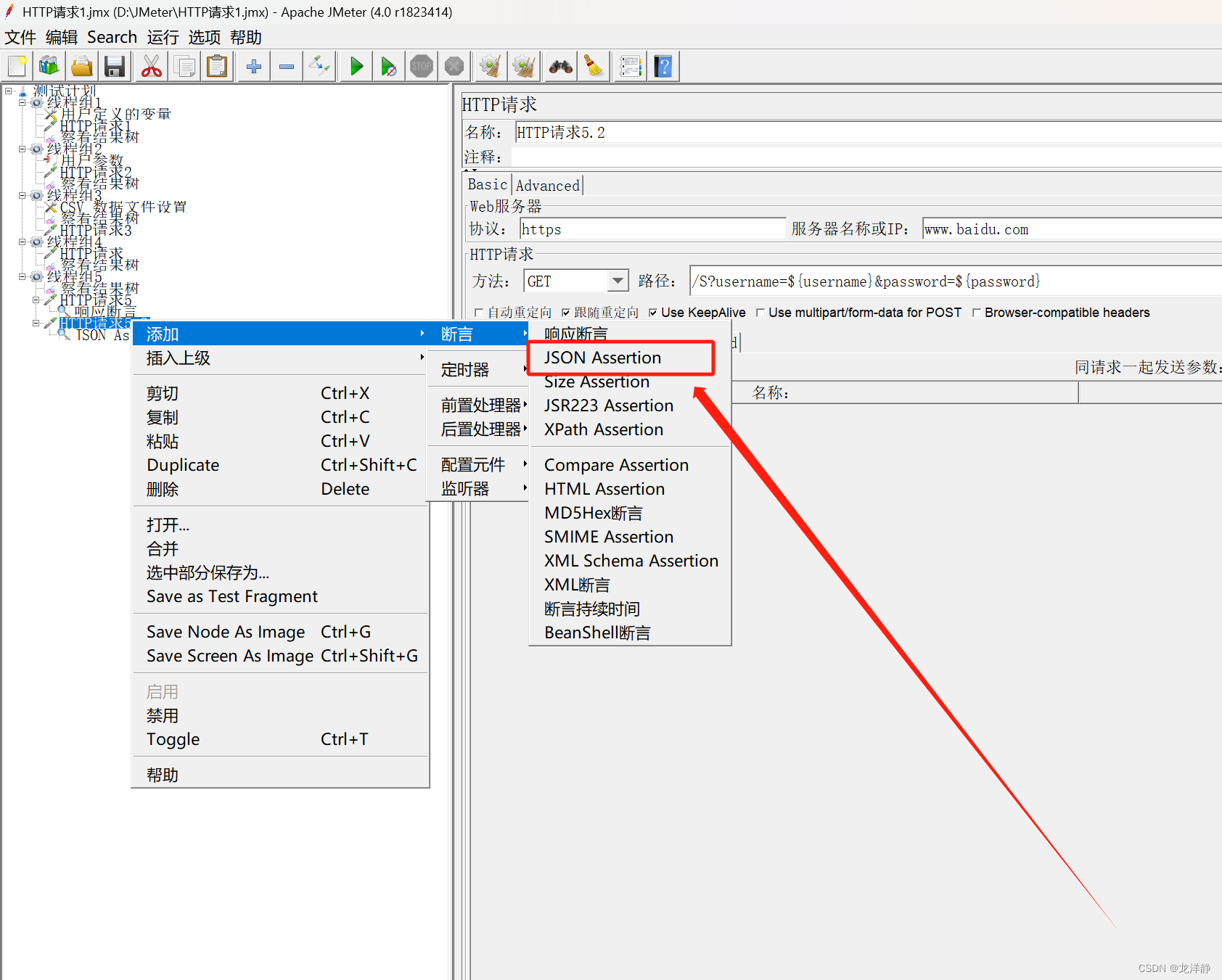
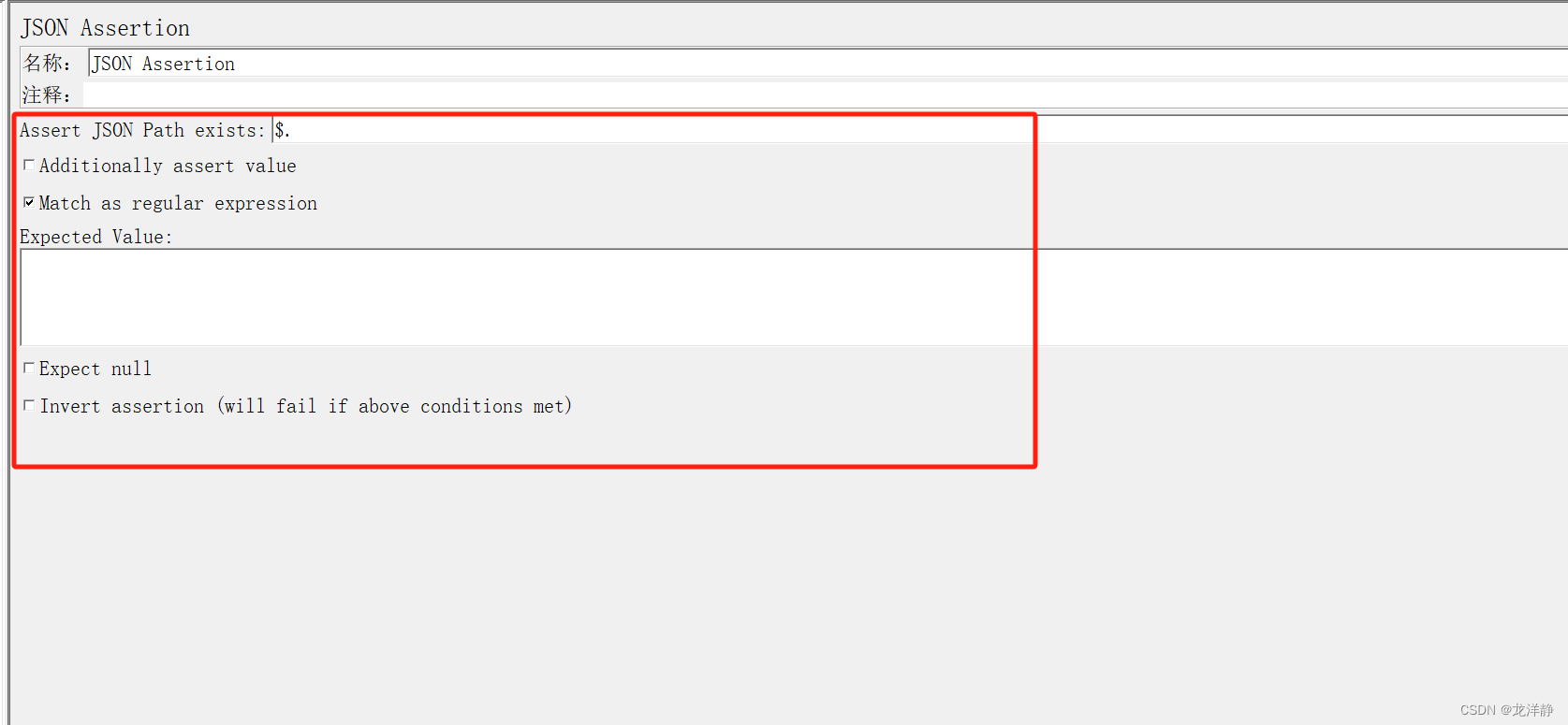
参数说明:
- Assert JSON Path exists:用于断言的JSON元素的路径(实际结果)
- Additionally assert value:如果您想要用某个值生成断言,请选择复选框
- Match as regular expression:使用正则表达式断言
- Expected Value:期望值
- Expect null:希望为空,则勾选复选框
- Invert assertion(will fail if above conditions met):反转断言(如果满足上述条件则失败)
2.2.2、案例:
http请求:
JSON断言:

上述的JSON的路径,就是这个值在json格式下对应的位置,$.data.gender对应如下:

运行后,看断言:

2.3、持续时间断言
就是用来检查http请求的响应时间是否超出要求范围
2.3.1、参数说明
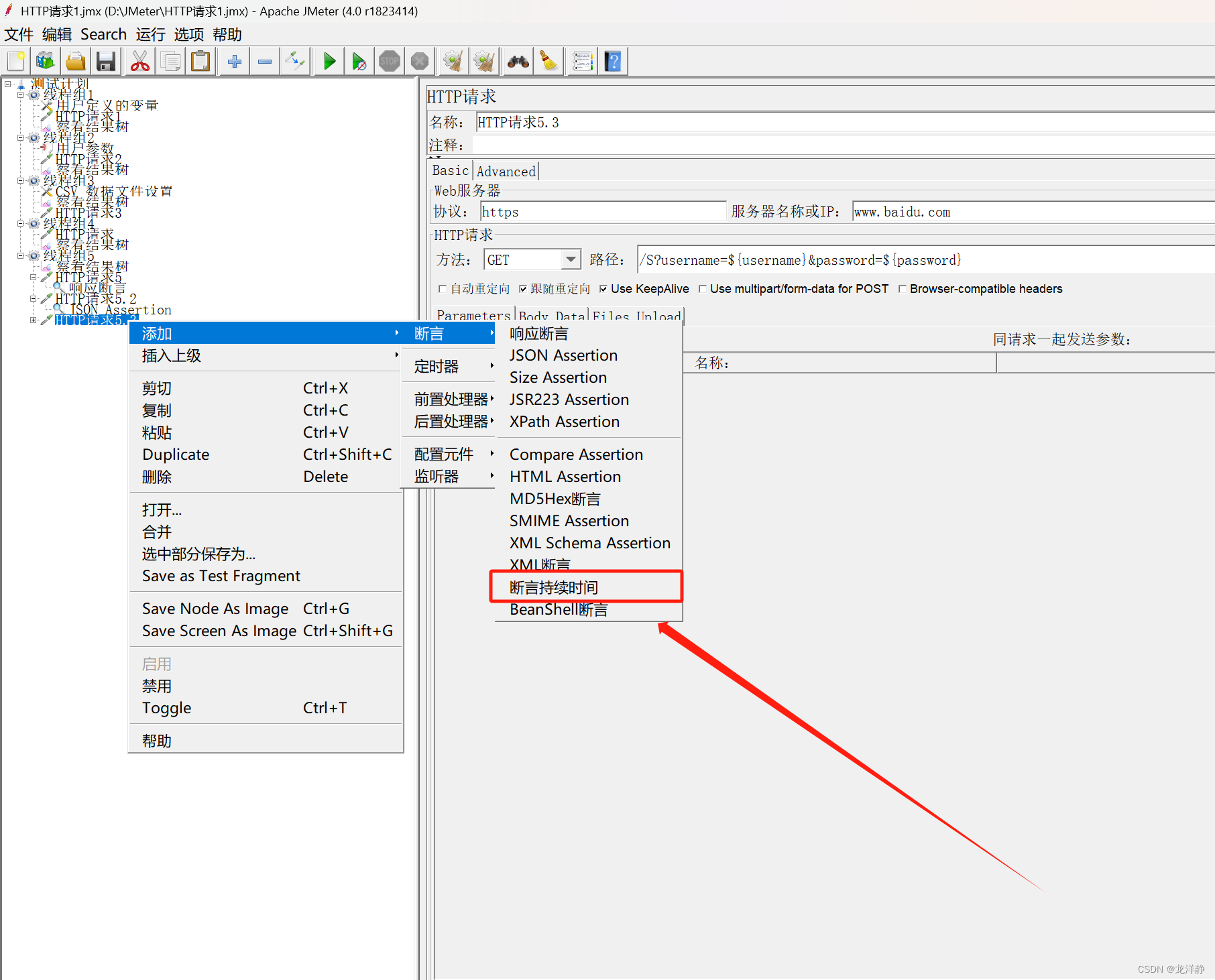

参数:
- 持续时间(毫秒):请求允许的最大响应时间,超过则认为失败~
2.3.2、案例:
断言:
http请求同上一个案例相同~
运行,查看断言结果:

3、JMeter关联
关联:当请求之间有依赖关系,比如一个请求的入参是另一个请求的返回数据。这时就需要用到关联处理
JMeter中常用的关联方法:
- 正则表达式提取器
- Xpath提取器
- JSON提取器
3.1、正则表达式提取器
3.1.1、介绍正则表达式
- 公式格式:左边界(匹配符号)右边界:可以提取出想要获取的数据内容
- .:是通配符,可以代表任意字符(除换行回车)
- *: 代表前面的字符出现0次或者多次
- .*匹配规则:找到左边界值后,往右查找有边界,找到最后面的右边界,中间的所有数据都被记录下来
- ?: 代表非贪婪匹配,找到左边界后,往右查找匹配右边界,只要有匹配的右边界就停止继续查找;再次查找
- 左边界和右边界
最终使用:
公式格式:左边界(.*?)右边界
案例使用一:
我们结合现在网站,来验证一下: 正则表达式在线测试 | 菜鸟工具
内容:<title>百度一下,你就知道</title><title>百度一下,你就知道</title>
提取目标:<title>百度一下,你就知道</title>
正则表达式:套公式:左边界<title>,右边界:</title>
结果:
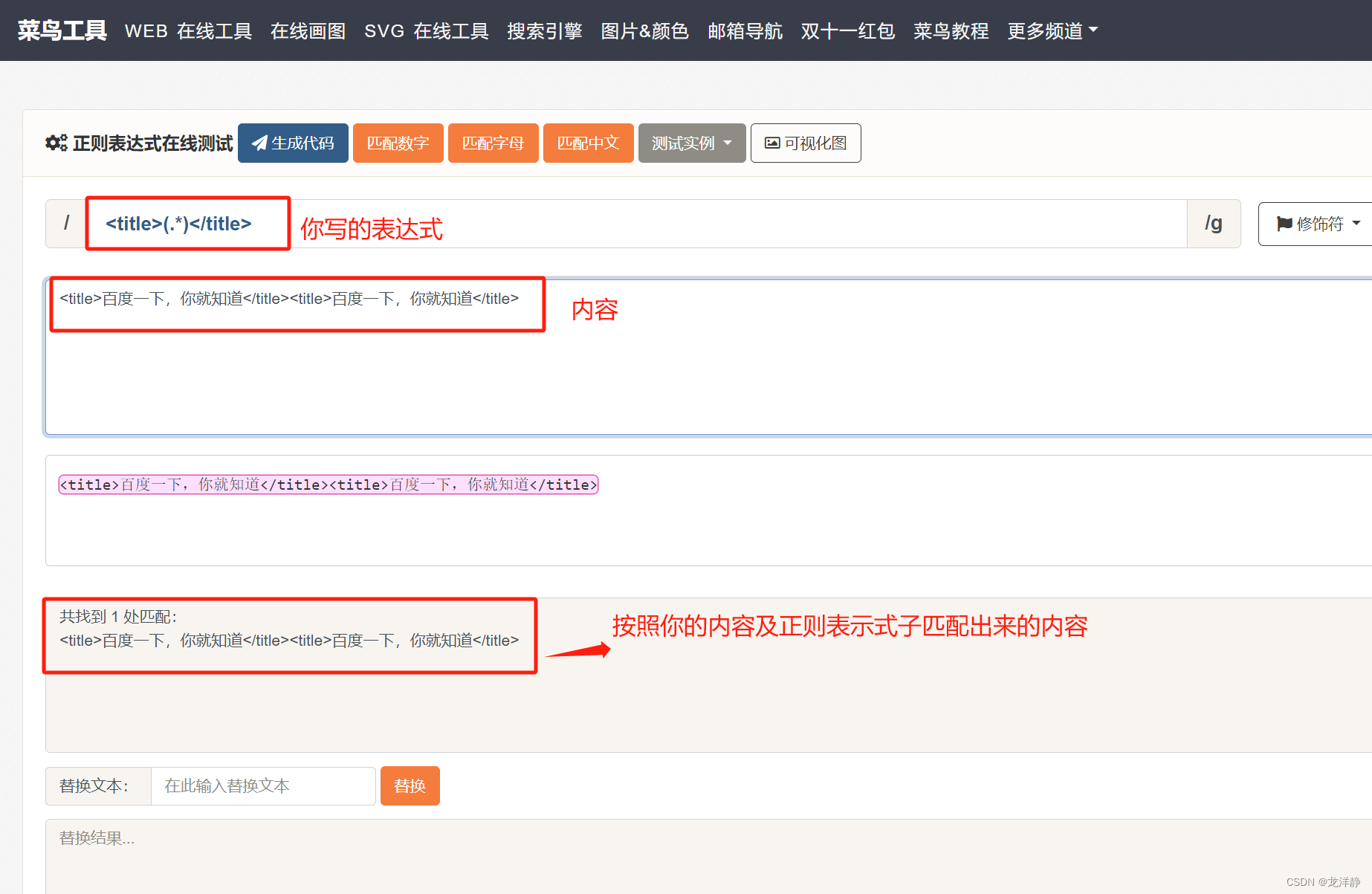
和我们预想的不太一样,预想的是:<title>百度一下,你就知道</title>
所以我们要加一个问号,表示非贪婪匹配:
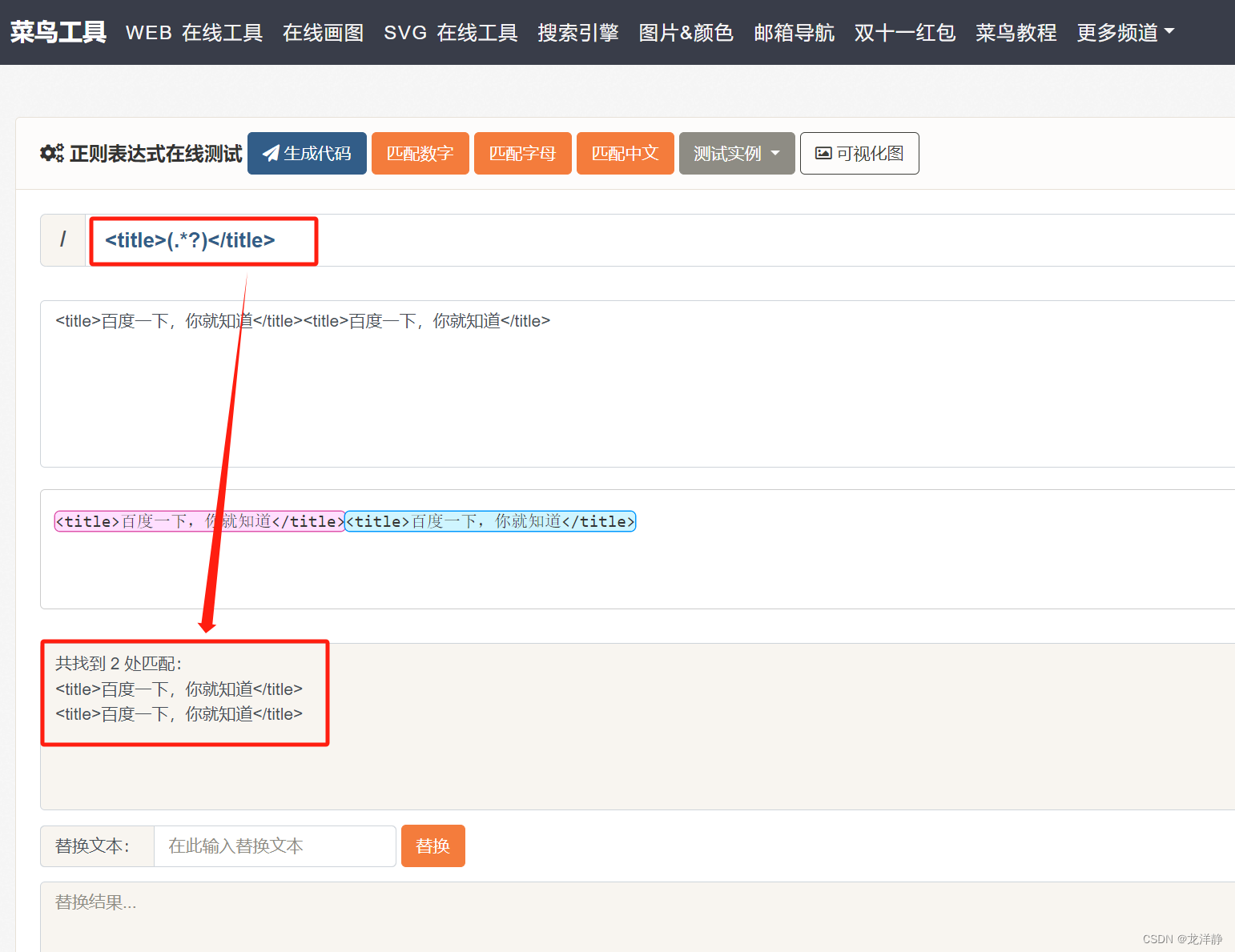
这里是找到了两处,我们可以自己决定要哪一个~
案例二:
内容:
预计匹配:所有的号码
表达式错误示范:

正确匹配:
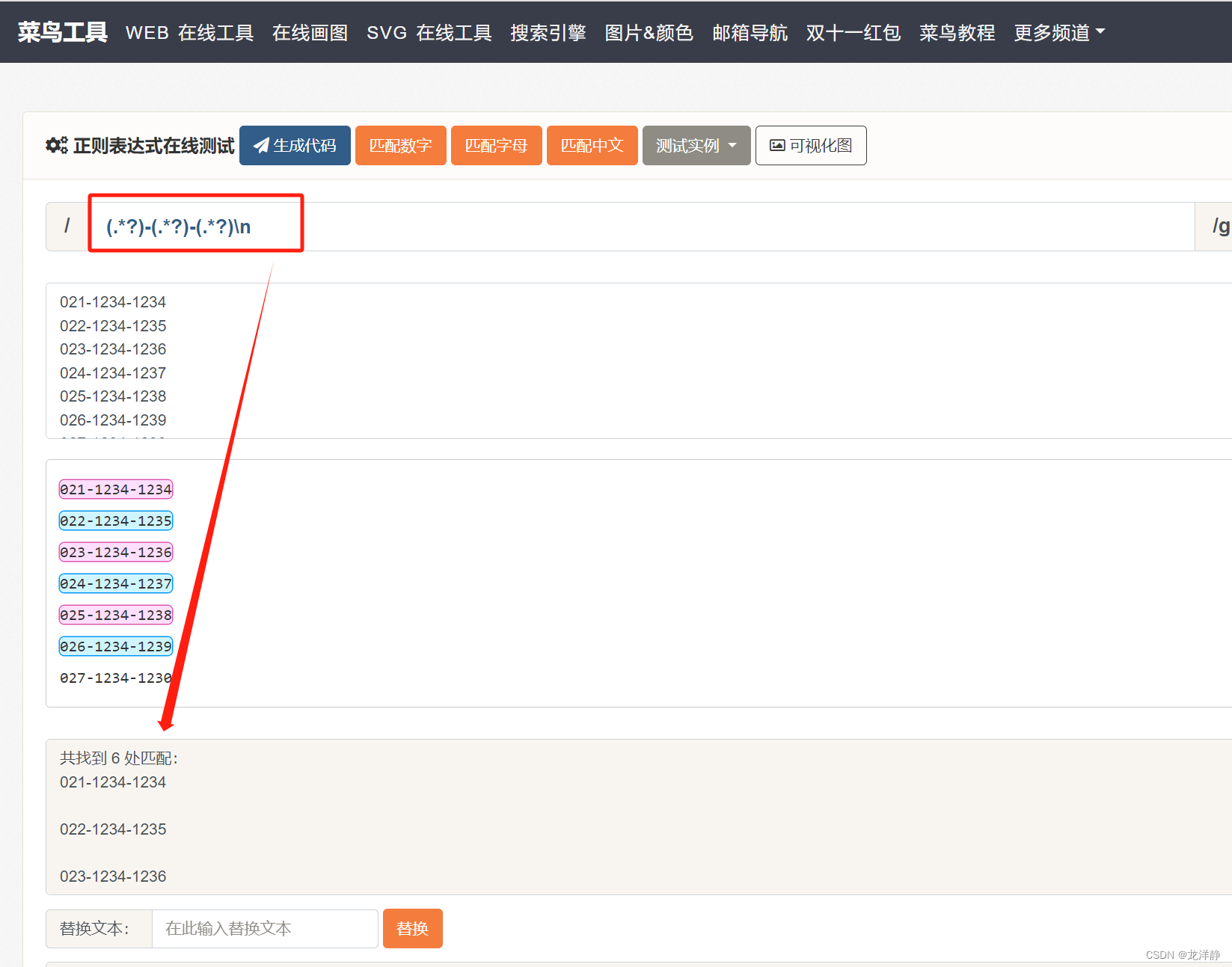
注:
- 通过一个正则表达式可以提取出多组数据,每组数据设置对应的左边界和右边界即可
- 每一组数据都可以有一个或者多个值
3.1.2、正则表达式提取器
- 作用:任意格式的响应数据,都可以使用正则表达式提取器进行提取
- 添加:
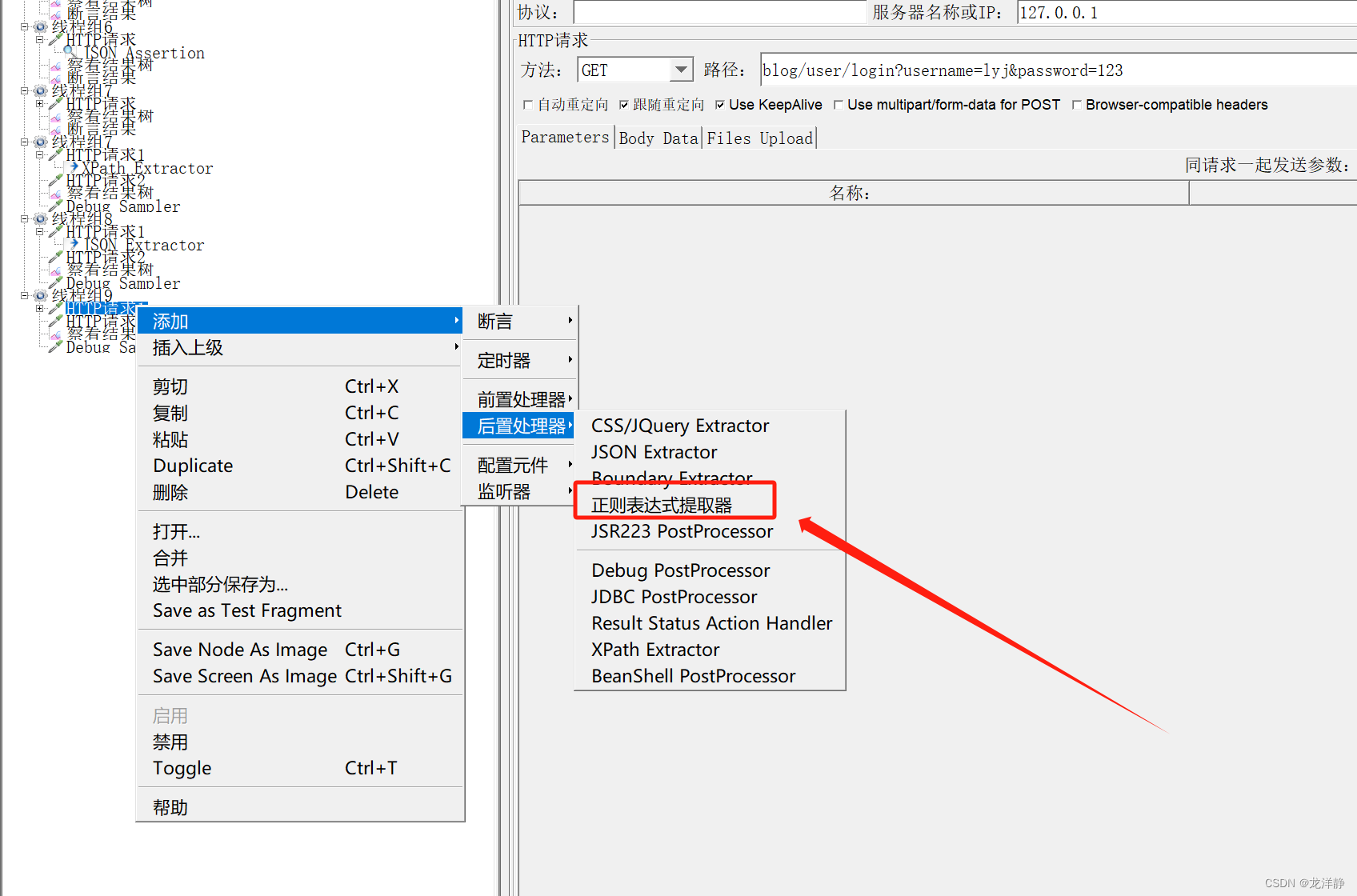
- 参数说明:

- 引用名称:存放提取出的值的参数名称,如填写title
- 正则表达式:左边界(*?)右边界
- 模板:用SS引用起来,表示解析出第几个()的值
- 匹配数字: 1表示第1个值,-1表示所有取值,0表示随机
- 缺省值:默认值。通常用于后续的逻辑判断,建议使用一些特殊含义的,比如0,NULL,ERROR等。
案例:
请求1:

正则表达式提取器:

请求2:
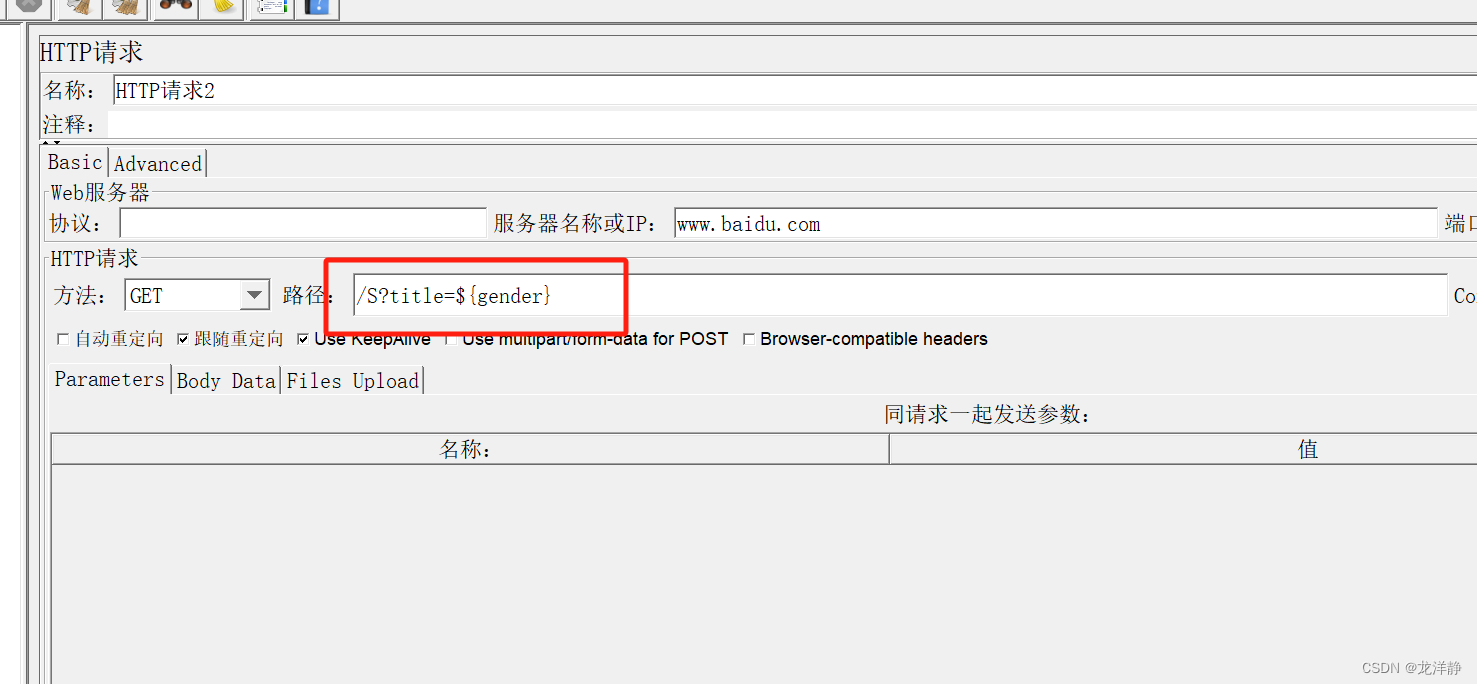
运行,查看结果树:
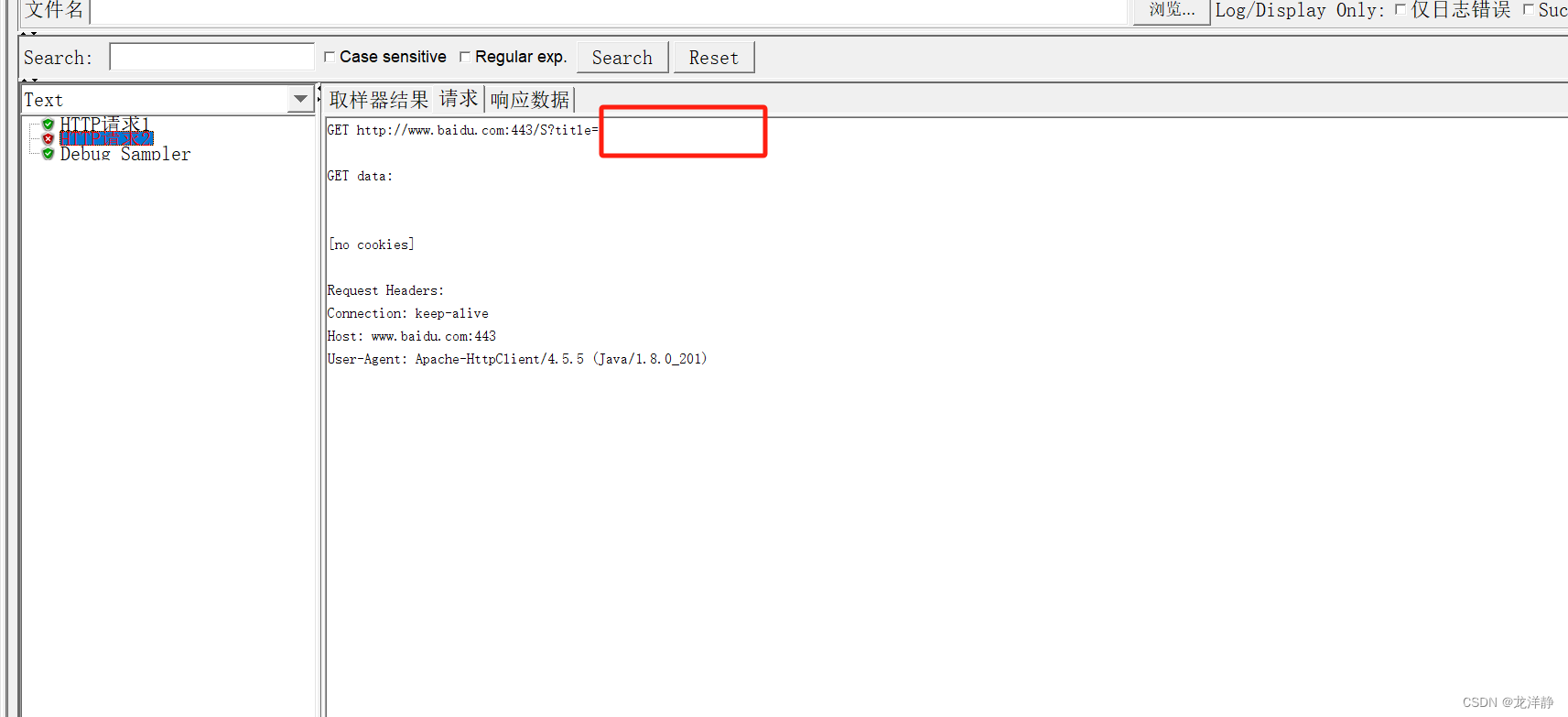
这里的值为空,怎么办?
我们可以添加一个
调试取样器,不用对里面的值更改,添加了就行:

添加一个查看结果树,运行,看结果:

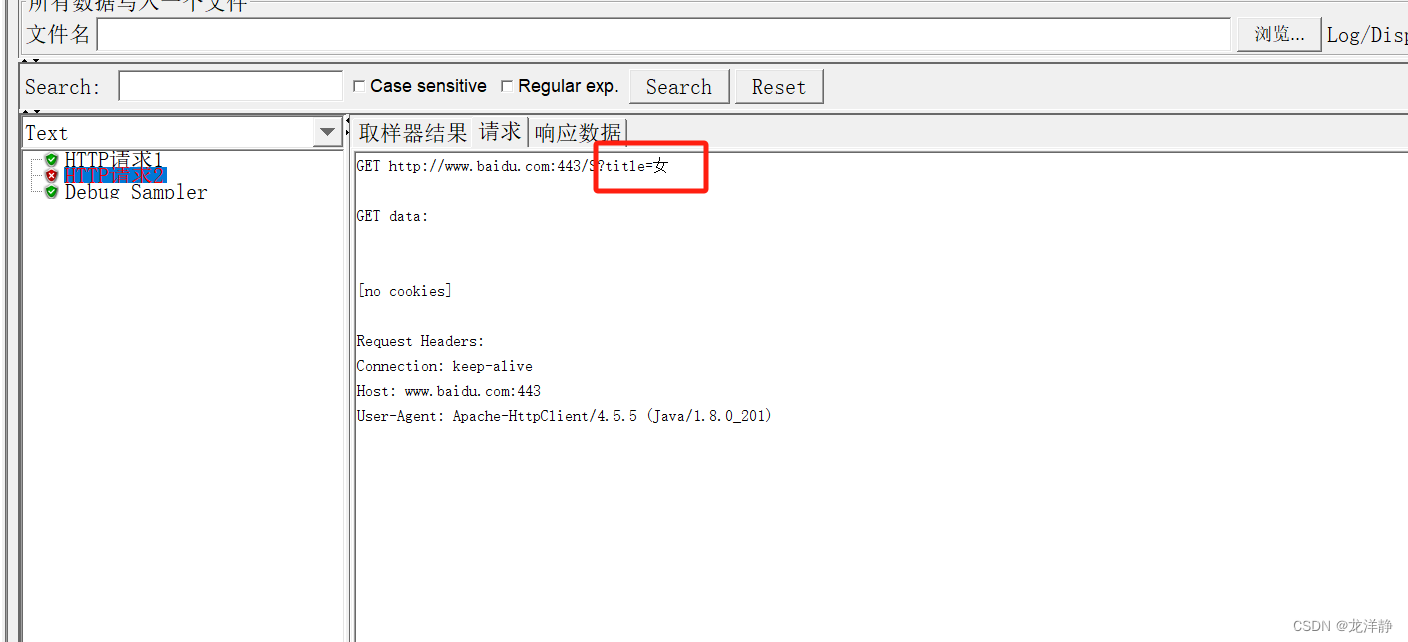
我们可以看到gender变量确实为空,但下面的变量有值呀,所以我们修改请求2:

重新运行,查看:
3.2、Xpath提取器
- 作用:针对html格式的响应结果数据进行提取
- 添加位置:
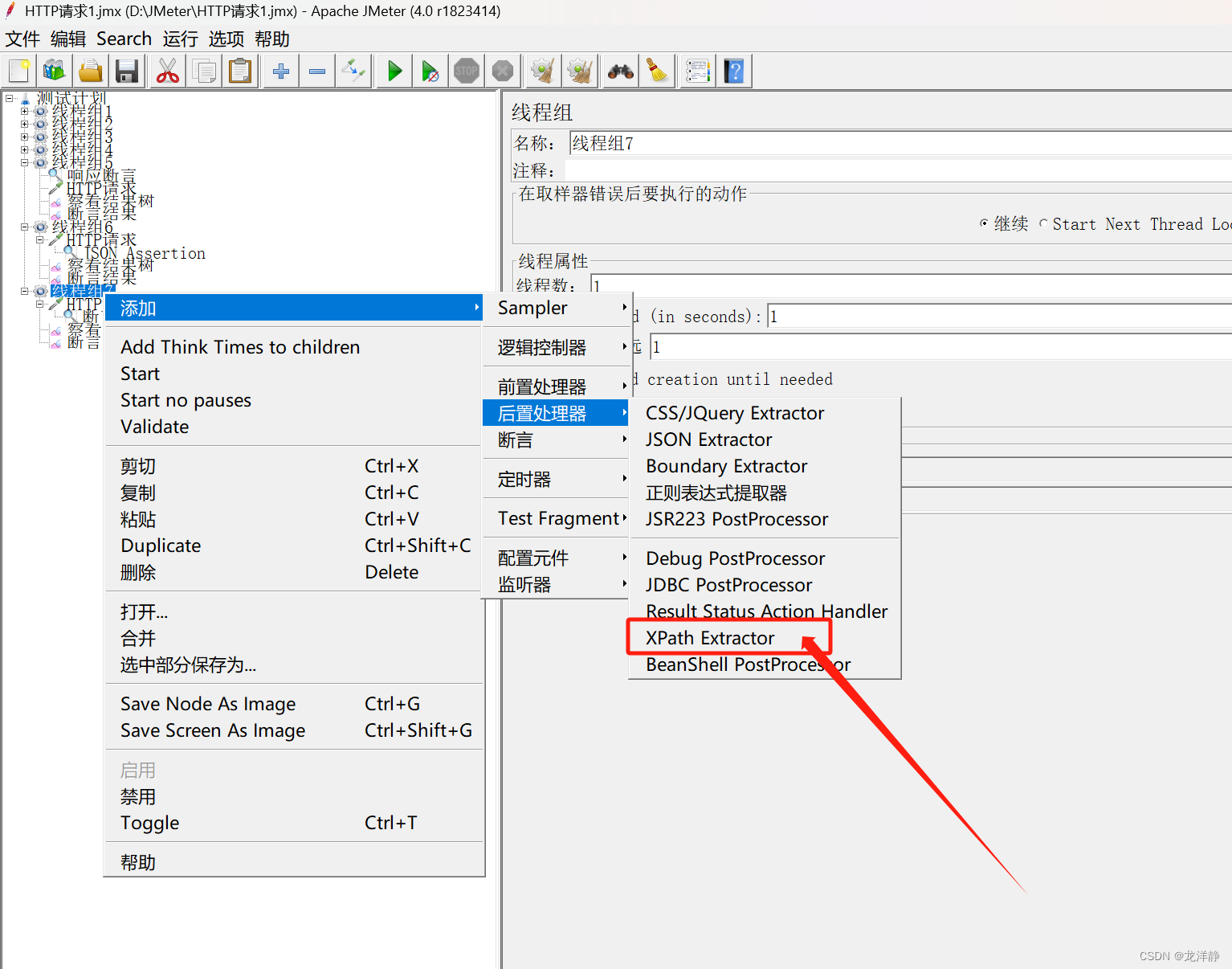
- 参数说明:

- Use Tidy(tolerant parser):当需要处理的页面是html格式时,需要勾选该选项;当需要处理的页面是XML或XHTML格式时,取消选中该选项
- Quiet表示只显示需要的HTML页面
- Report errors表示显示响应报错
- Show warnings表示显示警告
- Use Namespaces:如果启用该选项,后续的XML解析器将使用命名空间来分辨;
Validate XML:根据页面元素模式进行检查解析 - Ignore Whitespace:忽略空白内容
- Fetch external DTDs:如果选中该项,外部将使用DTD规则来获取页面内容(一些XML元素具有属性,属性包含应用程序使用的信息,属性仅在程序对元素进行读、写操作时,提供元素的额外信息,这时候需要在DTDs中声明)
- Return entire XPath fragment of text content:返回文本内容的整个XPath片段;
- 引用名称:存放提取出的值的参数名称
- Xpath Query:用户提取值的xpath表达式【和UI自动化定位元素一样】
- 匹配数字:如果xpath路径可以查询出许多的结果,则可以选择提取哪个。0表示随机;-1表示所有;1表示第一个值
- 缺省值:参数的默认值。可以不填写。通常用于后续的逻辑判断,建议使用一些特殊含义的,比如0,NULL,ERROR等。
案例:
请求1:
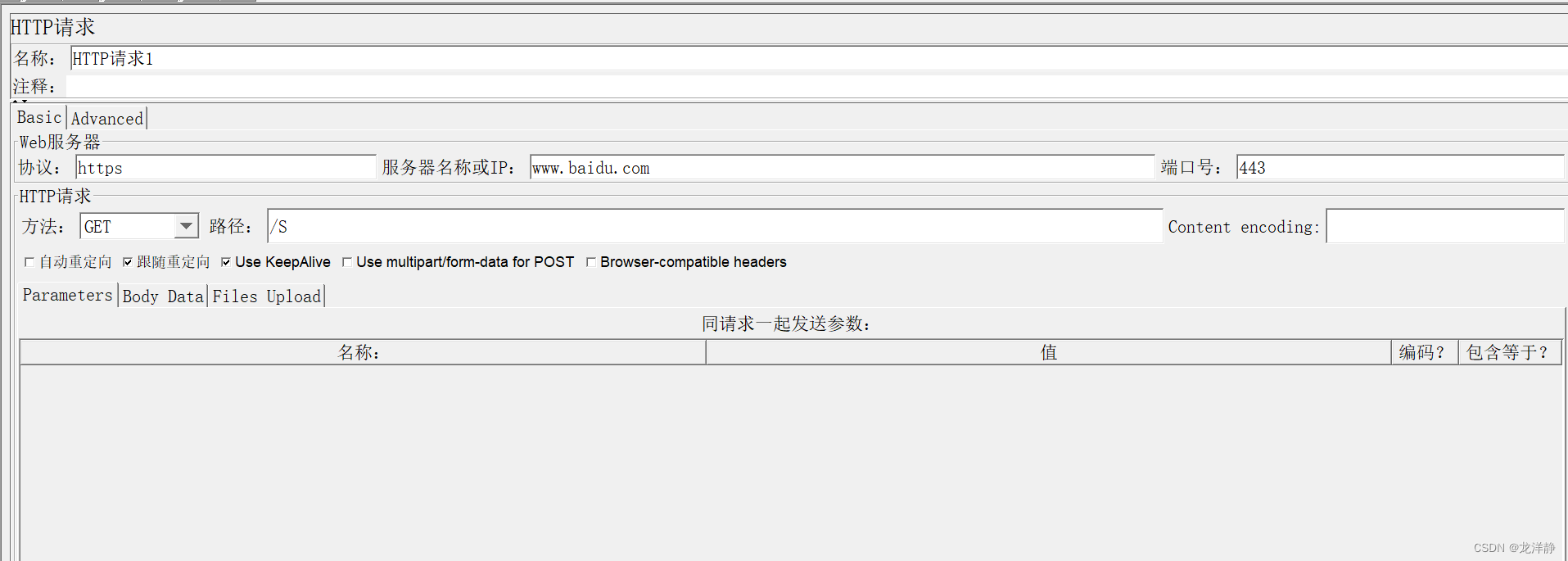
Xpath提取器:

http请求2:
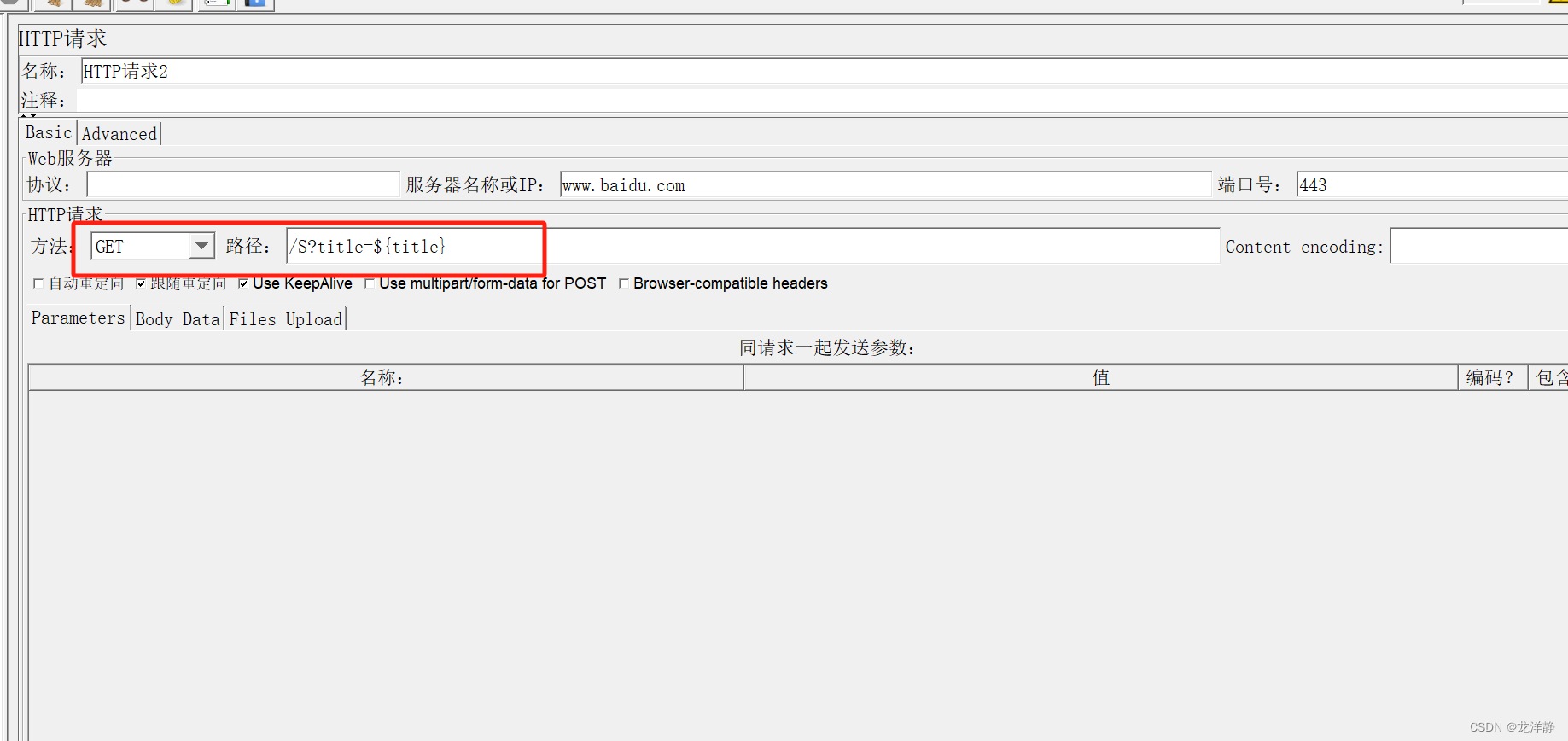
添加一个调试取样器,不用对里面的值更改,添加了就行:
添加一个查看结果树,运行,看结果:

3.3、JSON提取器
作用:针对JSON格式的响应结果数据进行提取
添加位置:
参数介绍:
- Names of create variables:存放提取出的值的参数名称
- JSON Path Expression:JSON路径表达式
- Match No:如果JSON路径匹配出许多结果,则可以选择提取哪个:0表示随机;-1表示所有;1表示第一个值
- Default Value:参数的默认值
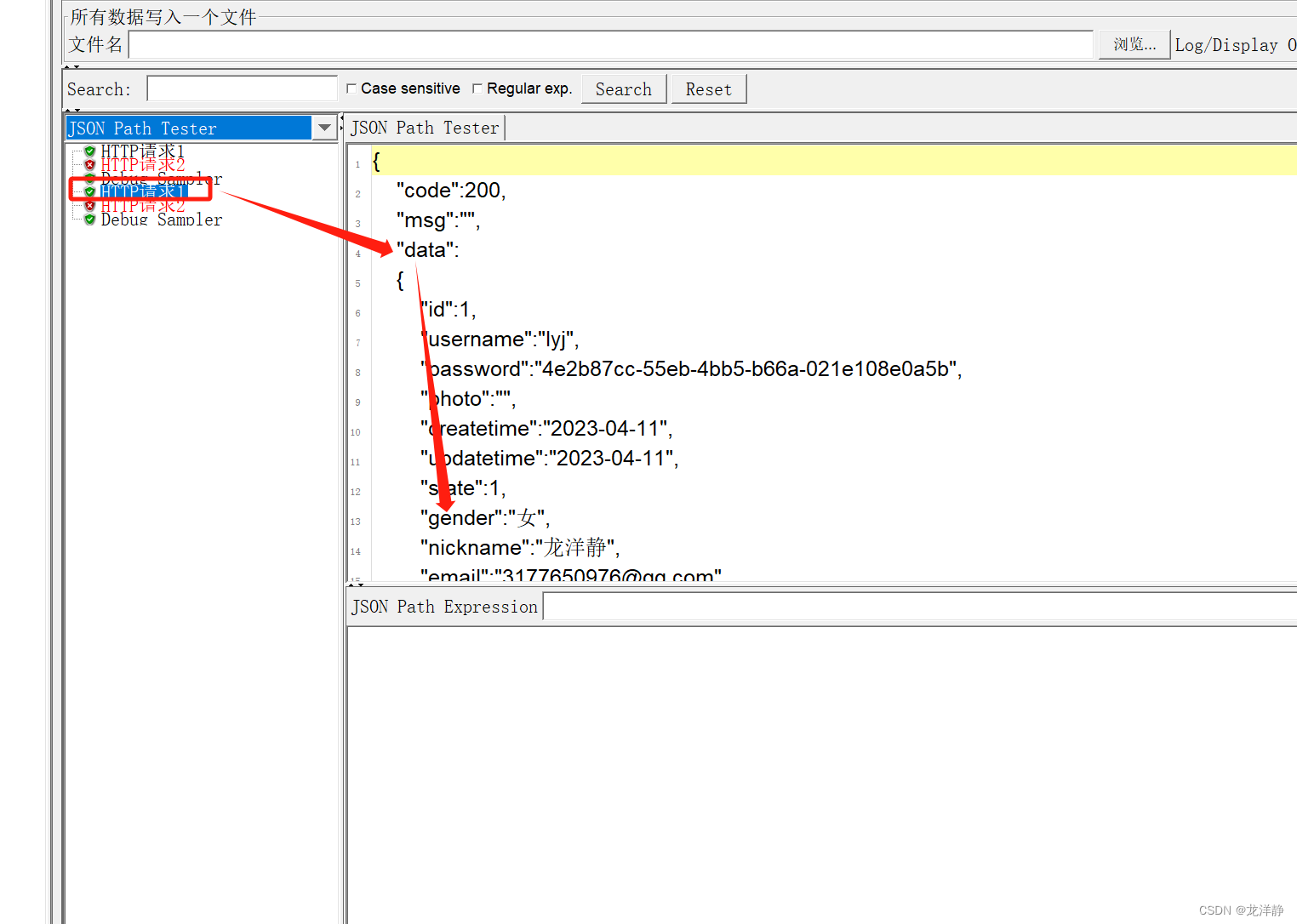
案例:
请求1:

JSON提取器:

请求2:

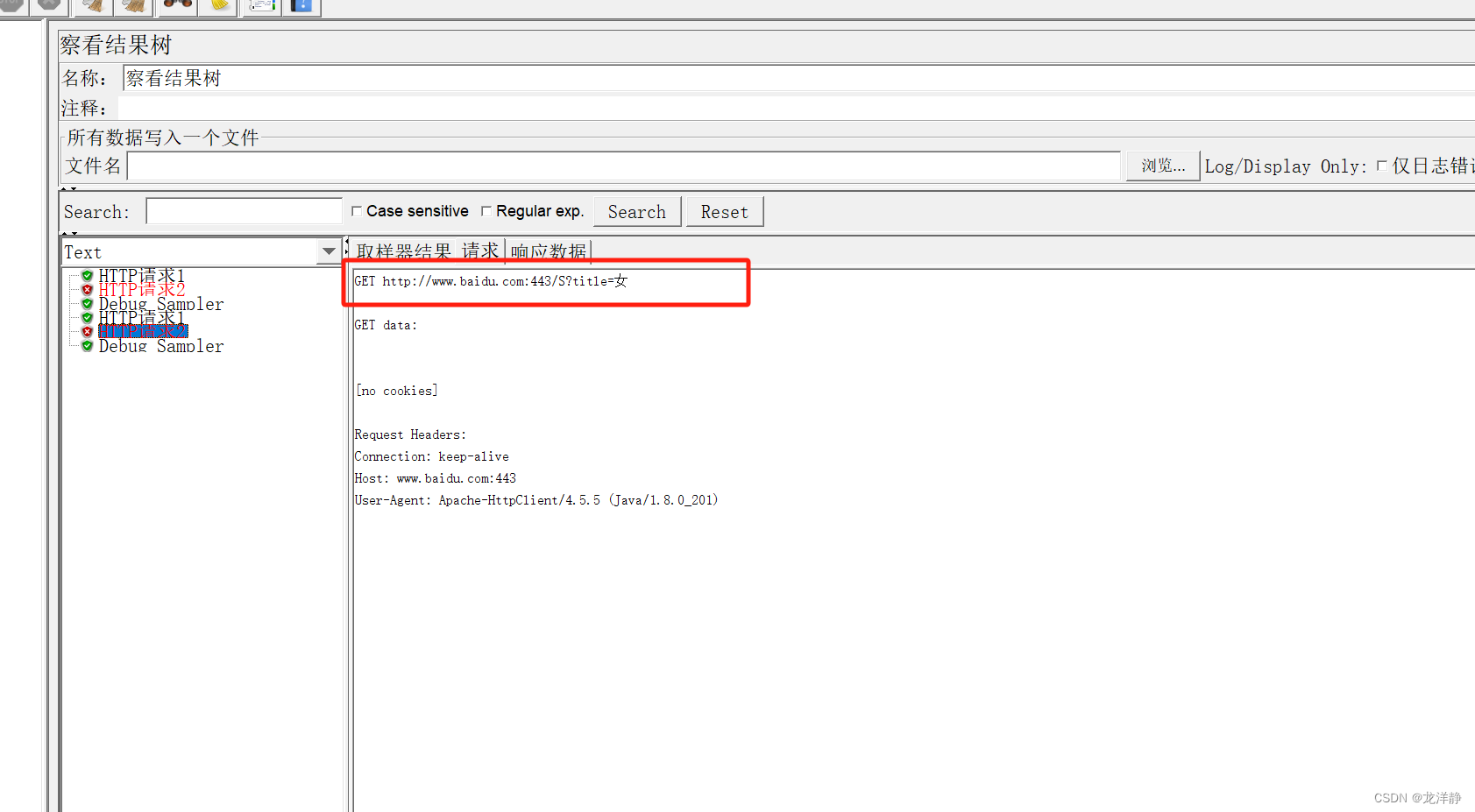
运行结果:
好啦,先到这里咯~~~