Hadoop原理,HDFS架构,MapReduce原理
Hadoop原理,HDFS架构,MapReduce原理
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开
测开的话,你就得学数据库,sql,oracle,尤其sql要学,当然,像很多金融企业、安全机构啥的,他们必须要用oracle数据库
这oracle比sql安全,强大多了,所以你需要学习,最重要的,你要是考网络警察公务员,这玩意你不会就别去报名了,耽误时间!
文章目录
- Hadoop原理,HDFS架构,MapReduce原理
- @[TOC](文章目录)
- Hadoop是什么?
- Hadoop概述
- Hadoop优势
- Hadoop的生态系统
- Hadoop集群的部署模式
- Hadoop的历史版本
- HDFS的演进
- HDFS基本概念
- HDFS的优缺点
- HDFS主从架构
- HDFS写原理
- HDFS读数据的原理
- HDFS的shell操作
- MapReduce分布式计算框架
- map和reduce内部如何合作
- maptask
- reducetask
- shuffle工作原理
- MapReduce的运行模式
- MapReduce的性能优化
- 总结
文章目录
- Hadoop原理,HDFS架构,MapReduce原理
- @[TOC](文章目录)
- Hadoop是什么?
- Hadoop概述
- Hadoop优势
- Hadoop的生态系统
- Hadoop集群的部署模式
- Hadoop的历史版本
- HDFS的演进
- HDFS基本概念
- HDFS的优缺点
- HDFS主从架构
- HDFS写原理
- HDFS读数据的原理
- HDFS的shell操作
- MapReduce分布式计算框架
- map和reduce内部如何合作
- maptask
- reducetask
- shuffle工作原理
- MapReduce的运行模式
- MapReduce的性能优化
- 总结
Hadoop是什么?
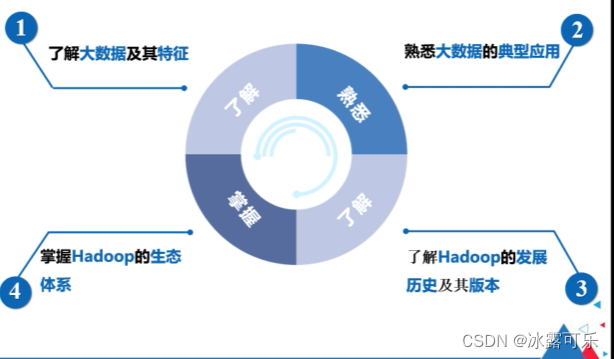


Hadoop概述

Hadoop优势
计算能力
存储能力
廉价计算机组成
高效率,吞吐量高
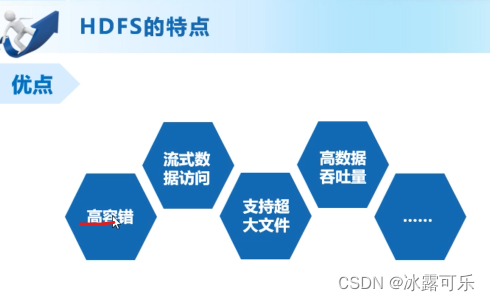
可靠,容错
数据副本机制基本不会丢
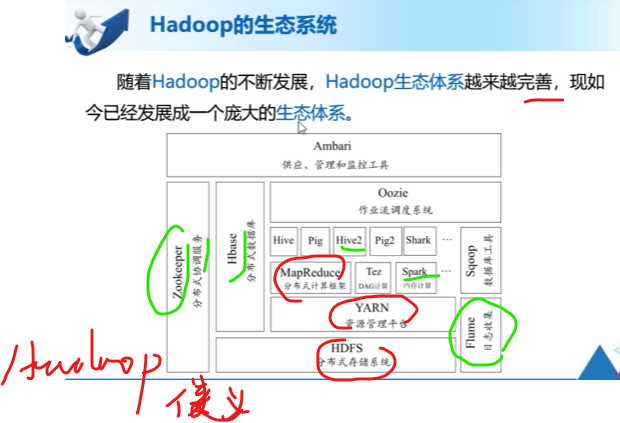
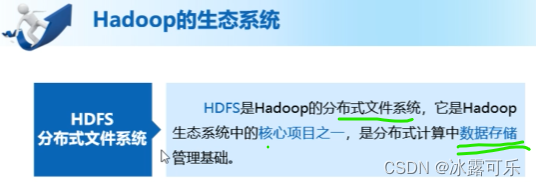
Hadoop的生态系统








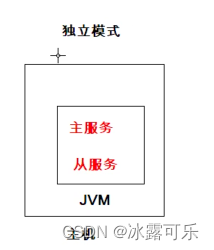
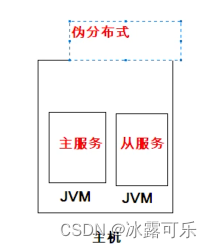
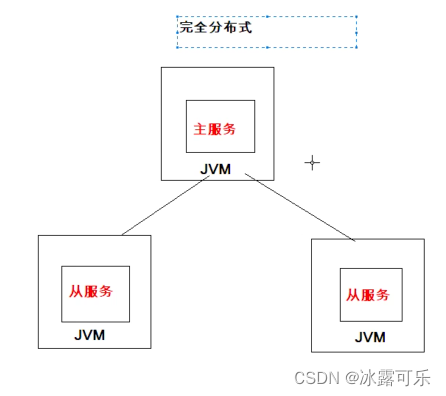
Hadoop集群的部署模式

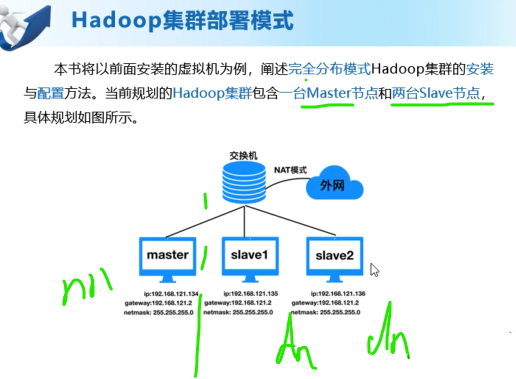
Hadoop的历史版本



收费的牛逼
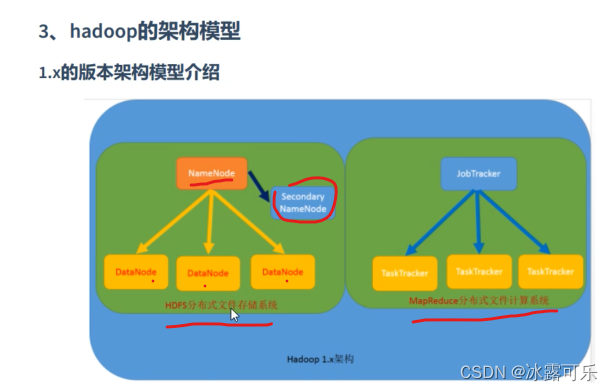
主从架构

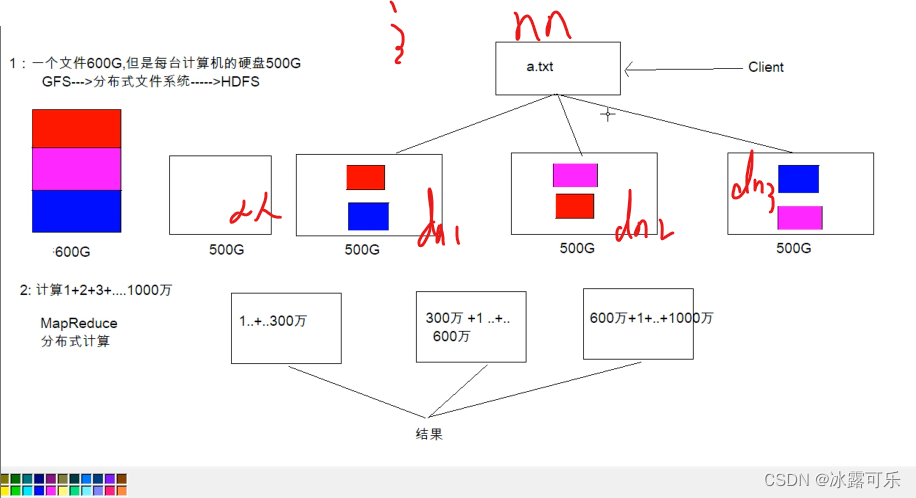
计算类似的
MapReduce
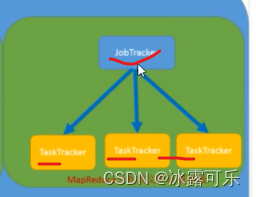
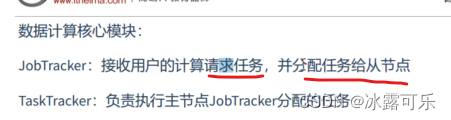
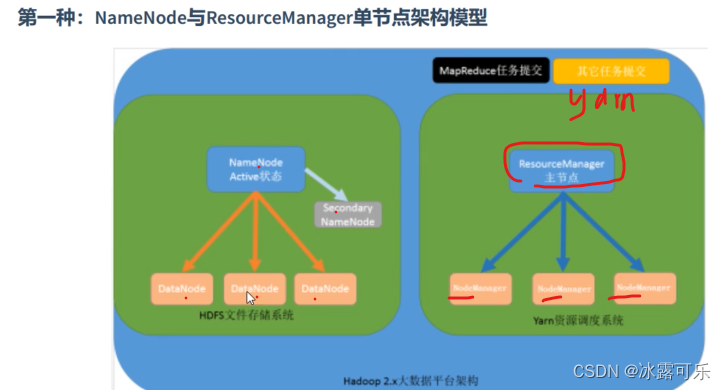
yarn来管理分配资源和调度资源
resourcemanager
管理nodemanager
APPmaster,进程去计算
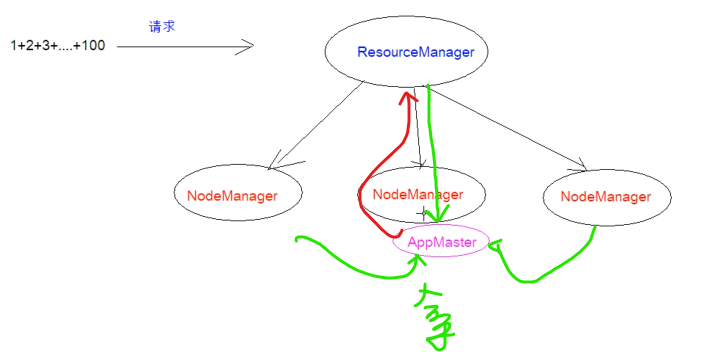
app计算完,上报给老大
单点故障依然gg

还是备份思想
gg
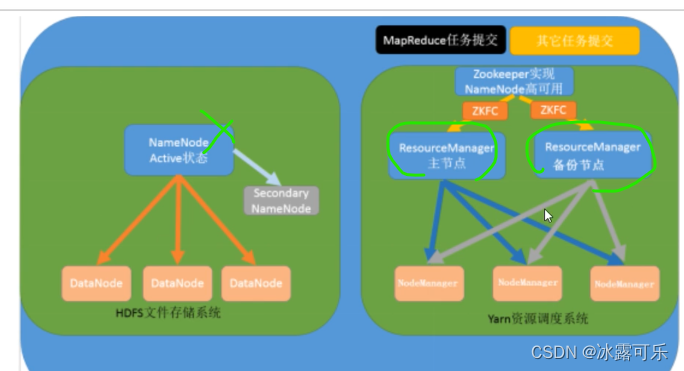
zookeeper来搞这种管理,美滋滋
这门课牛逼,终于说清楚了这些事情


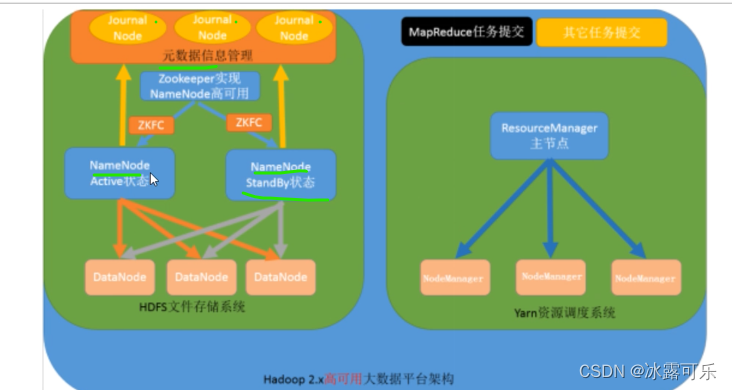
不是resource 了

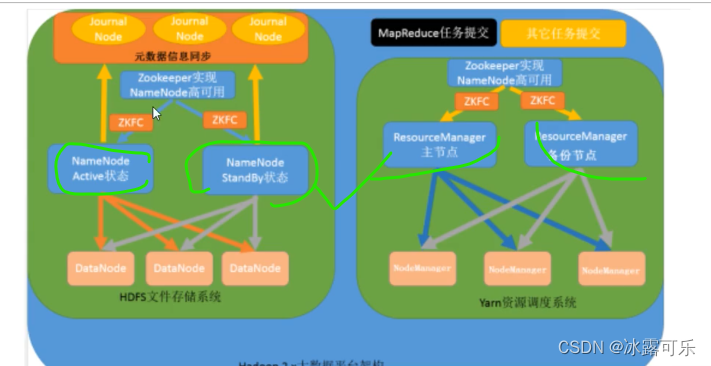
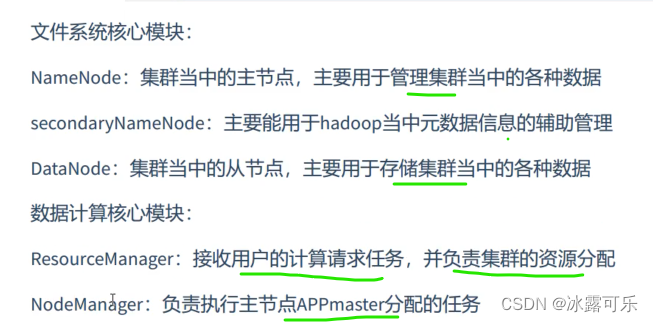
HDFS的演进

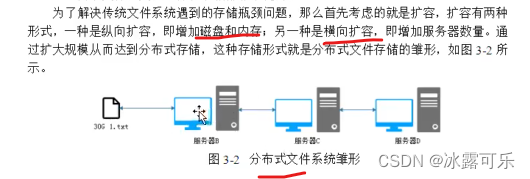
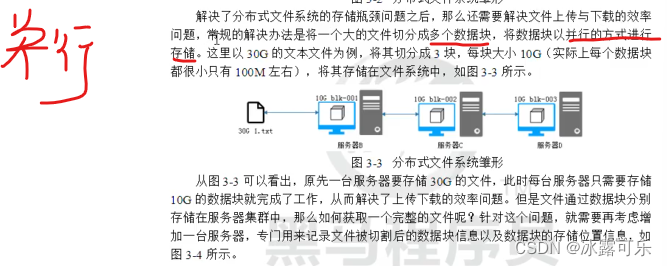
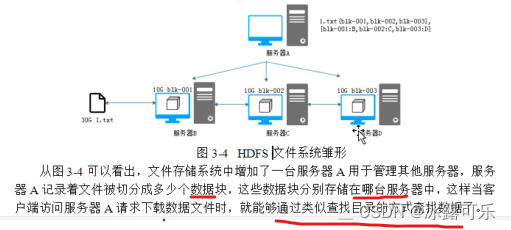
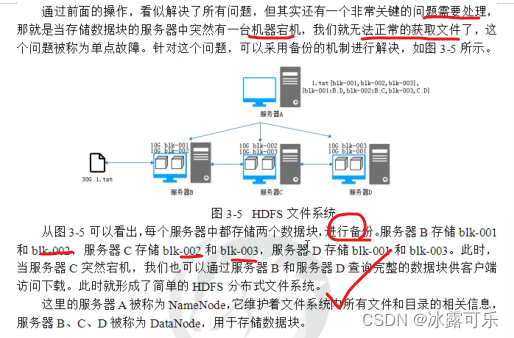
老牛逼了
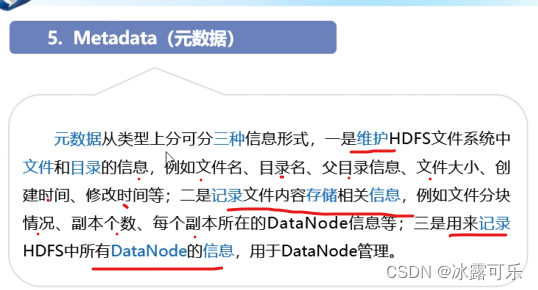
HDFS基本概念
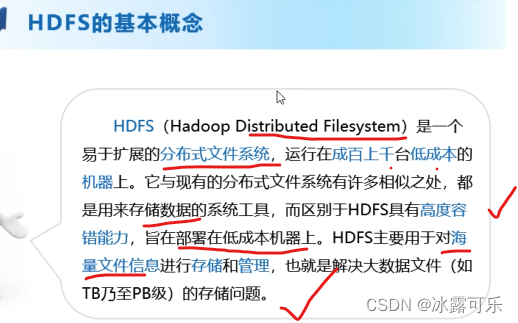
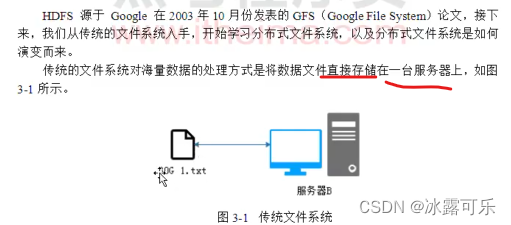
不妨设a.txt要存储,它很大很大,一个机子存不了
咱需要拆分成多个block
这样分开存在不同的机子上
支离破碎的文件,需要统一管理,namenode来管理
当客户端访问是,先要问nn,你给我真实的地址,我一个个去读取然后组装就好。
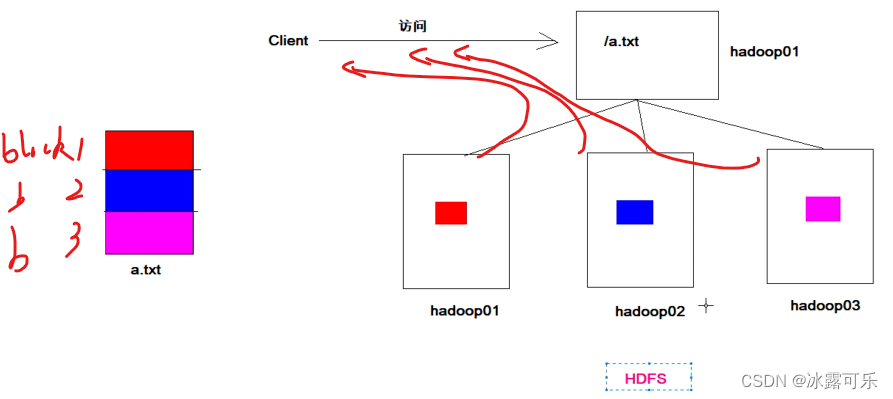

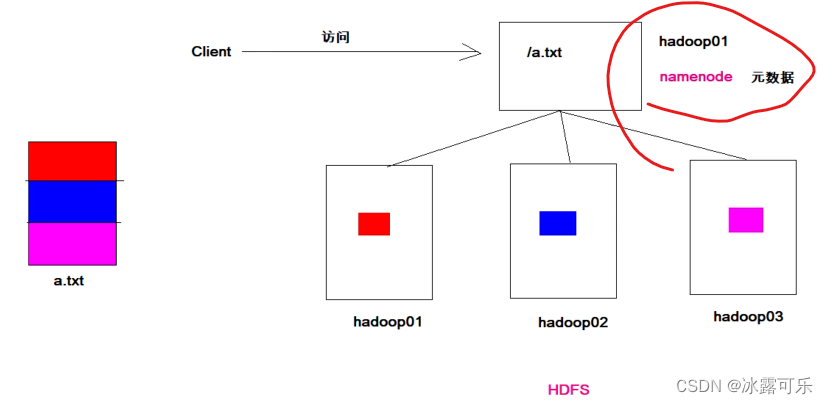
nn就是老大
datanode

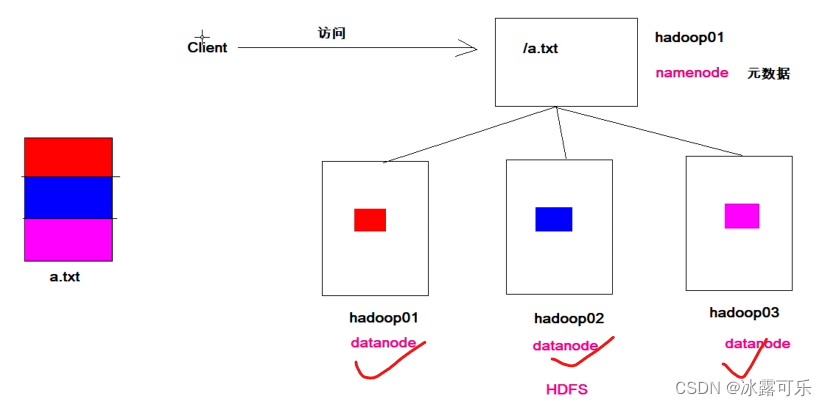
block

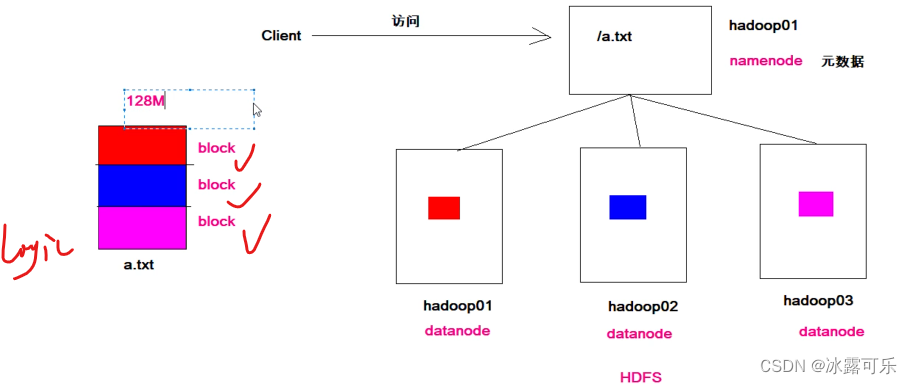
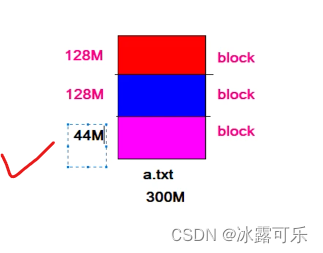
300m那平均分开
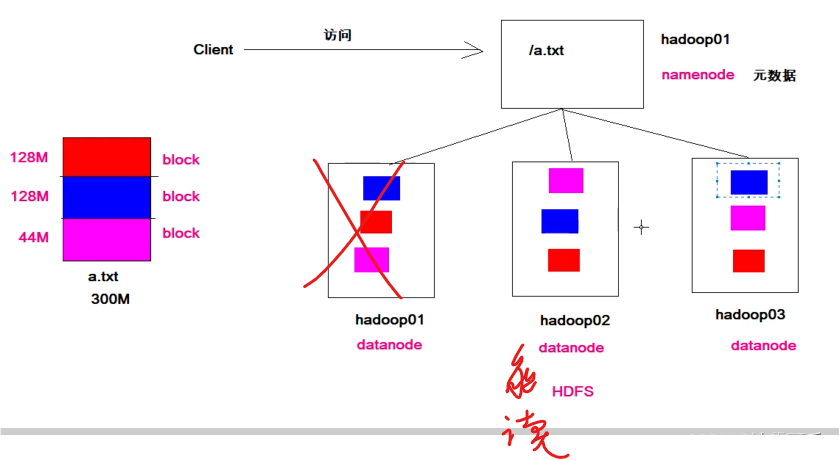
3份一样的数据,分开存储,增加容错性
HDFS的优缺点
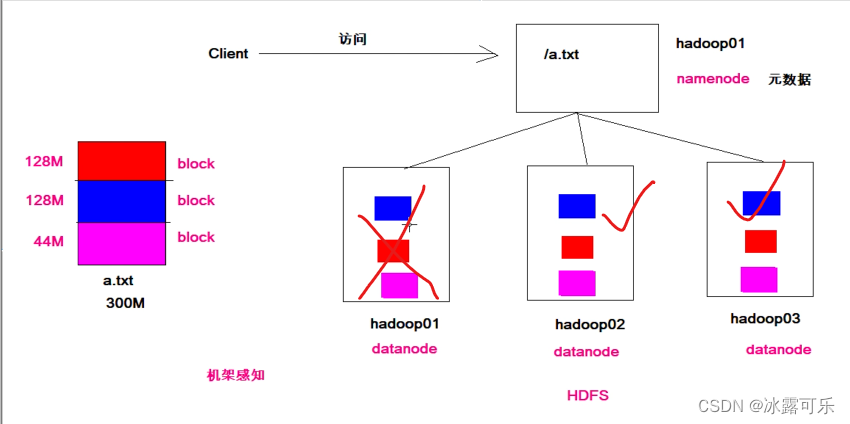
蓝色dn1丢失
但是dn2和dn3保持数据的完整性
美滋滋
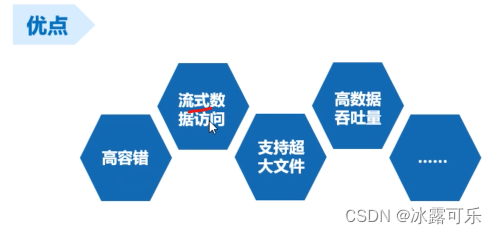
字节流,好像访问本地文件,效率高
支持超大文件的存储,切片分开存储,都能玩
高数据的吞吐量,不支持修改,支持存储
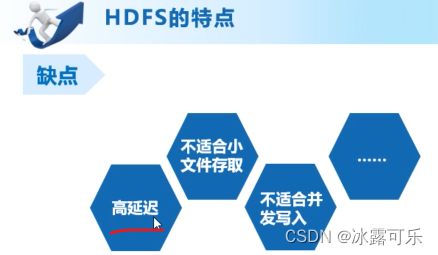
由于数据多,分开存,这样的话,速度慢
适合线下处理
尤其是小文件多,元数据量大,很烦人
并发写入不合适,他要备份
一次写入,多次读取
HDFS主从架构
namenode管理datanode
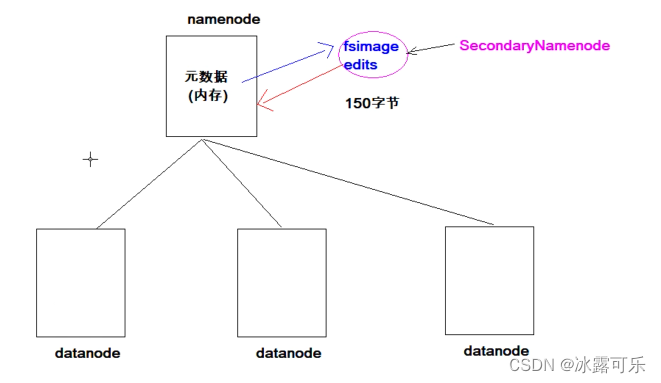
namenode的元数据是缓存在自己身上的,secondarynamenode辅助管理
datanode经常需要汇报给老大namenode
一个大文件,一般有3个副本
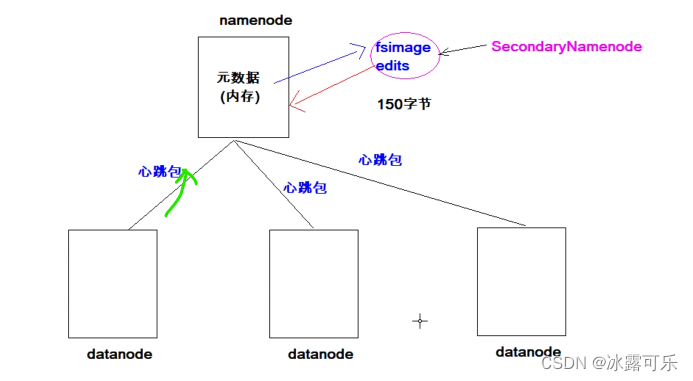
HDFS写原理
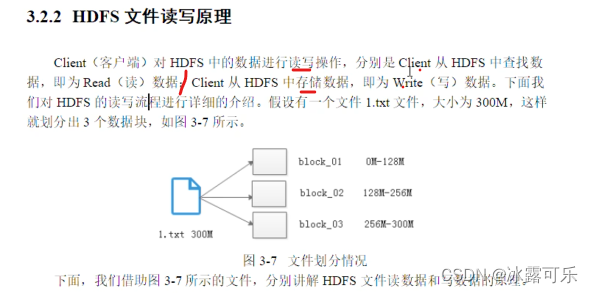
client客户端的操作
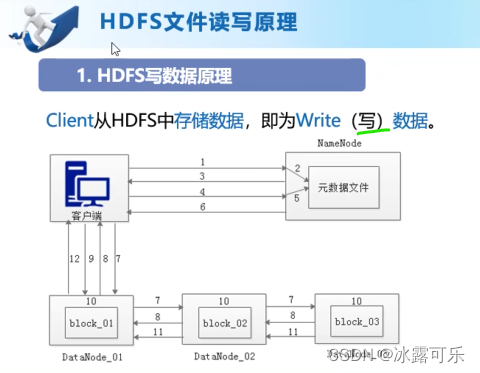
分步骤玩
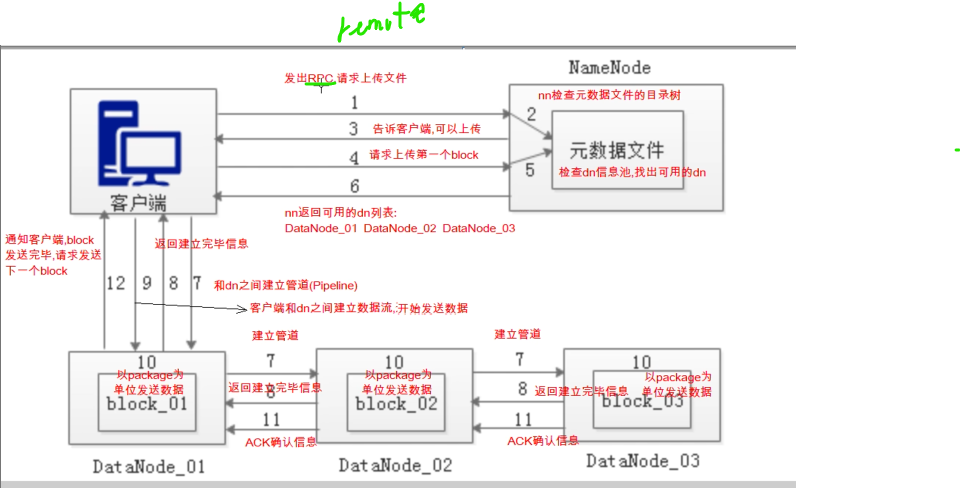
1:客户端发出RPC,请求上传文件
2:nn检查元数据文件的目录树
3:告诉客户端,可以上传
4:上传请求第一个block,一共3个
5:每个block是要3个副本的,nn需要检查dn的信息池,查他的存储量和可用性,找到可用的list,即可用的副本
6:返回可用的datanode可用的列表,dn123
7:客户端收到了列表之后,他就知道存到哪里了,他需要和服务器之间建立pipeline管道,且dn1和dn2之间也要建立管道,dn2和dn3都要建立,这样的话,数据流通道搞出来了,当客户端一旦发送,就能同时发送哦
8:当管道建立好后,返回管道建立完毕的信息,相当于ack,tcp协议连接类似
9:就可以发送了,建立传输数据流,发送数据
10:以package包为单位,慢慢发,64k大小,dn1发送诶dn2,dn2发送给dn3
11:发送完毕,告诉前面确认好了,ack确认信息
12:通知客户端,block发送完毕,请求发送下一个block,以此循环发
懂了吧
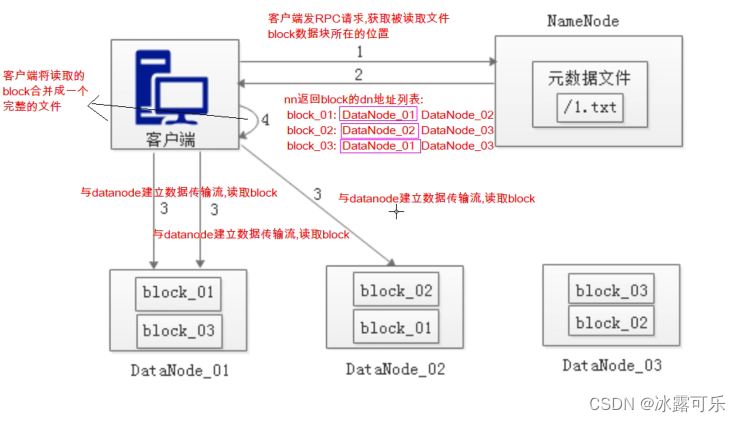
HDFS读数据的原理
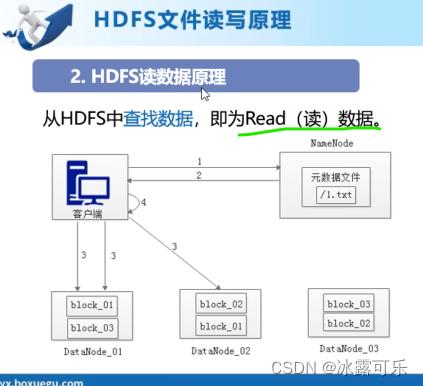
1:客户端发RPC请求,获取读取文件block数据所在的位置,往往1文件,是分成了多个block,而且分散存储在不同的服务器上的
2:nn返回block返回datanode的地址列表,比如dn1,dn2,dn3上都有副本
3:当客户端知道了地址,他直接挑选排序靠前的地址列表,距离自己比较近的那个节点,它还能挑选健康的服务器,比如挑选,然后建立通信管道,分别读取,并发读取哦。每次读完,那客户端都要完成校验,发现不完整,还需要从新问nn;
4:读取完成,合成一个完整的文件
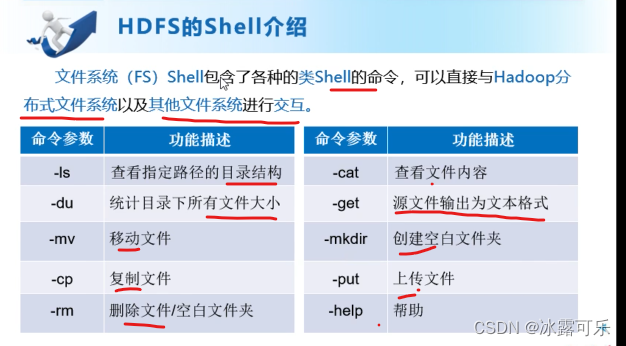
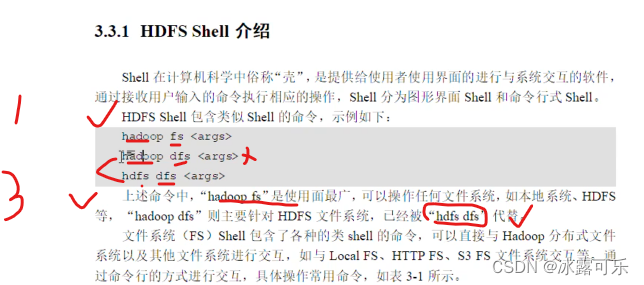
HDFS的shell操作

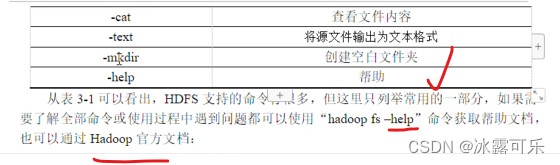
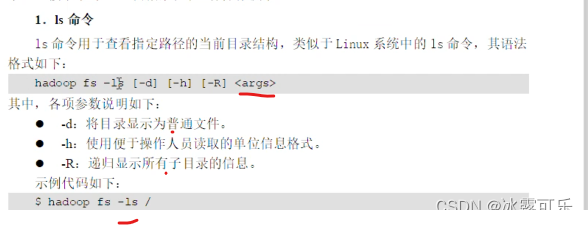
/根目录
Hadoop fs -ls /目录
这种特定的命令
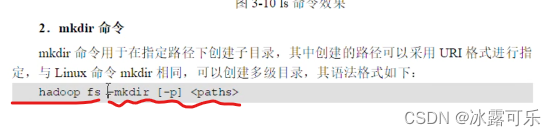
这种就是普通Linux之前加一个Hadoop fs
或者dfs fs

本地路径,目标路径
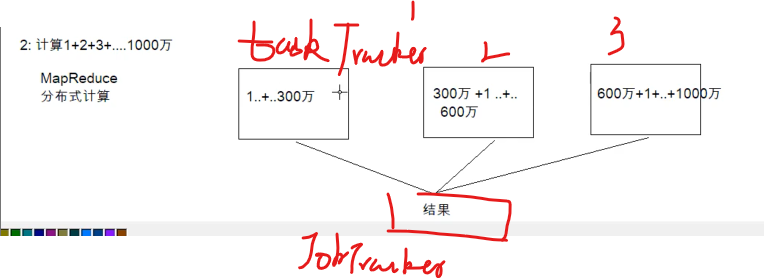
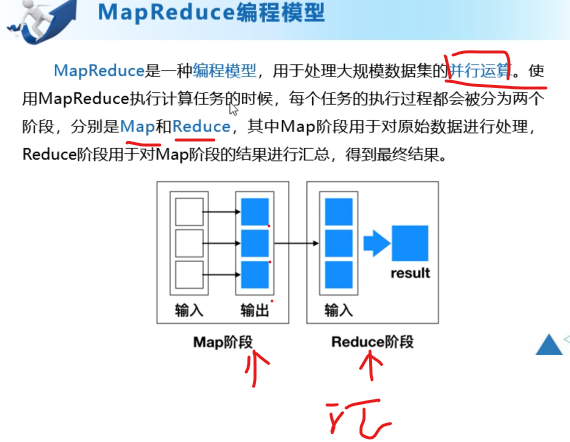
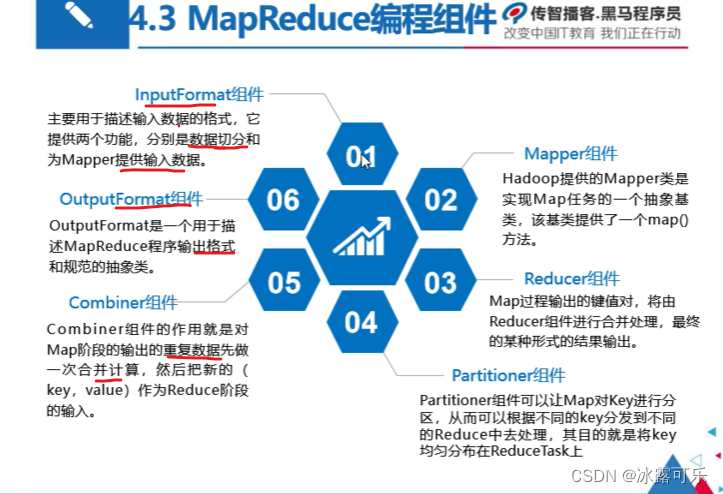
MapReduce分布式计算框架

HDFS是存储
MapReduce是计算
懂?
yarn是管理
分而治之——MapReduce

map
reduce






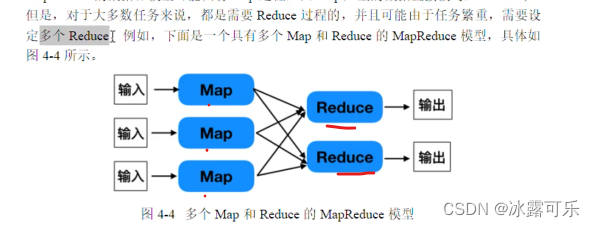

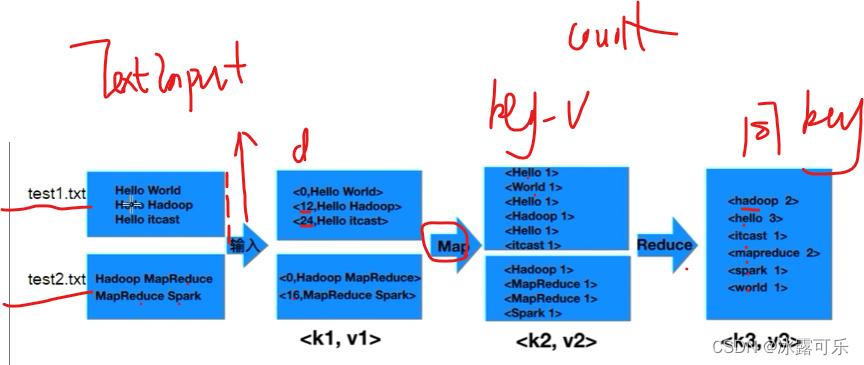
map和reduce内部如何合作

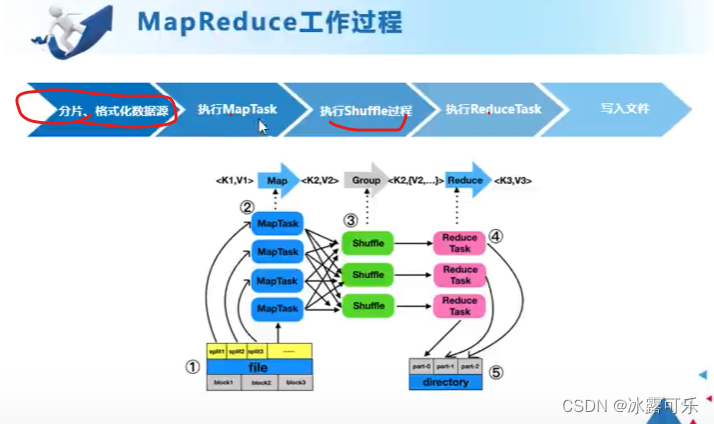

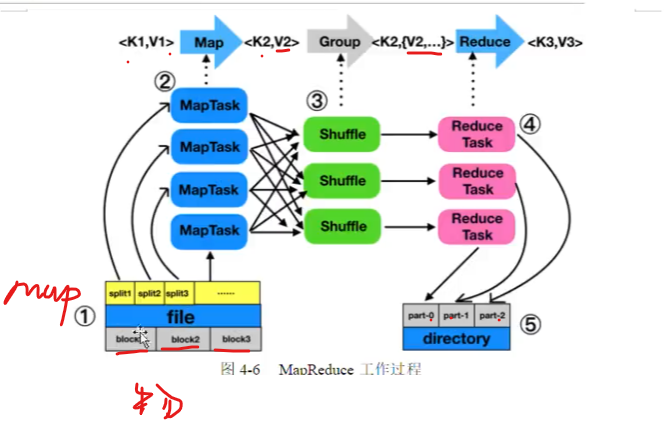
格式化,结构化




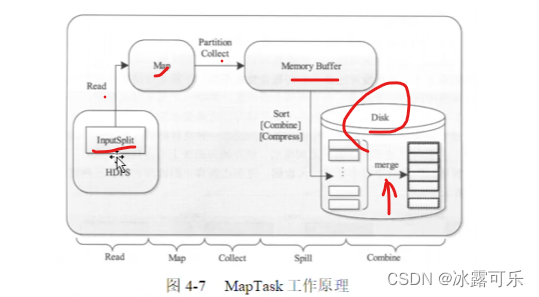
maptask
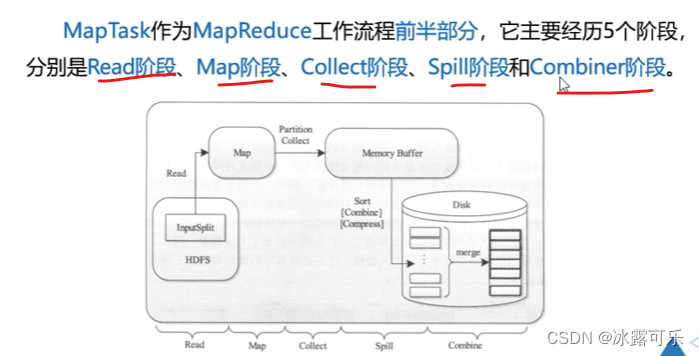



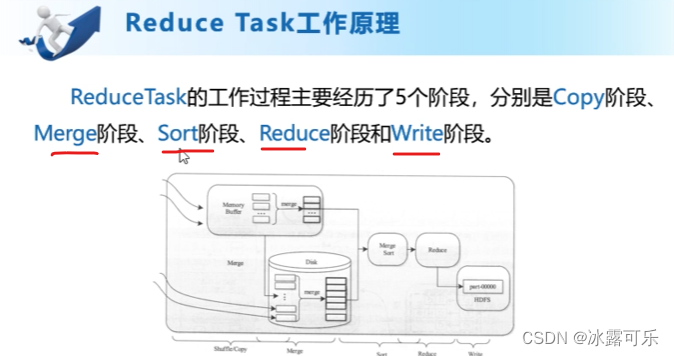
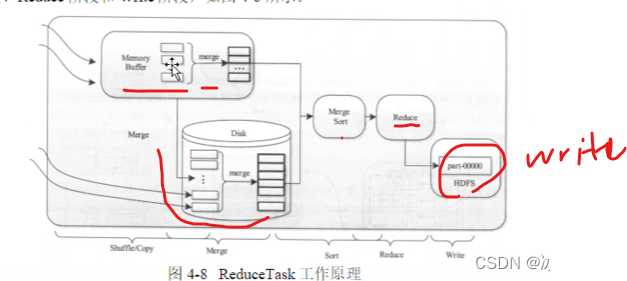
reducetask

shuffle工作原理
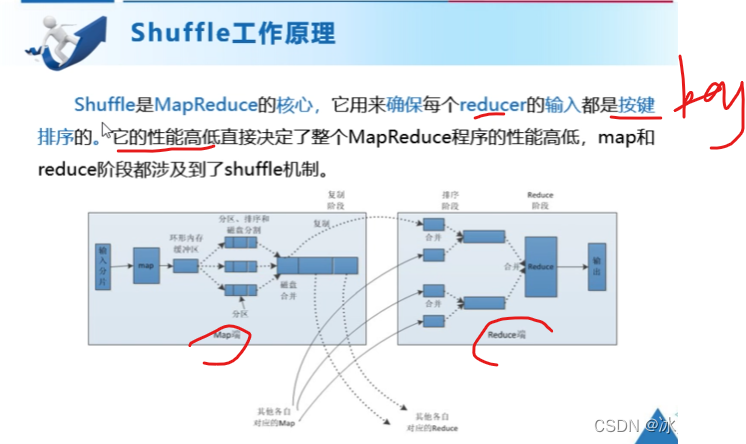

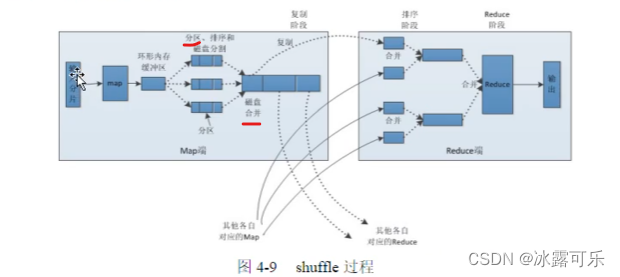

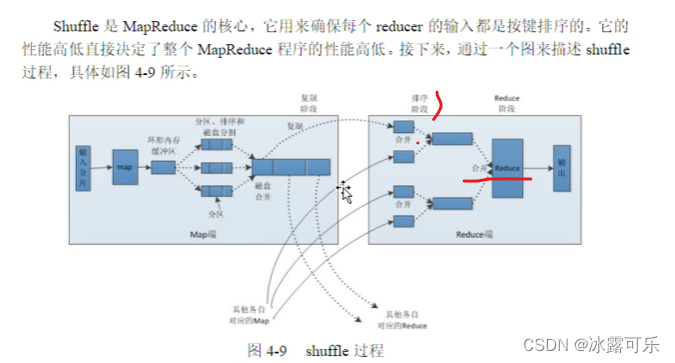


blocksize最重要




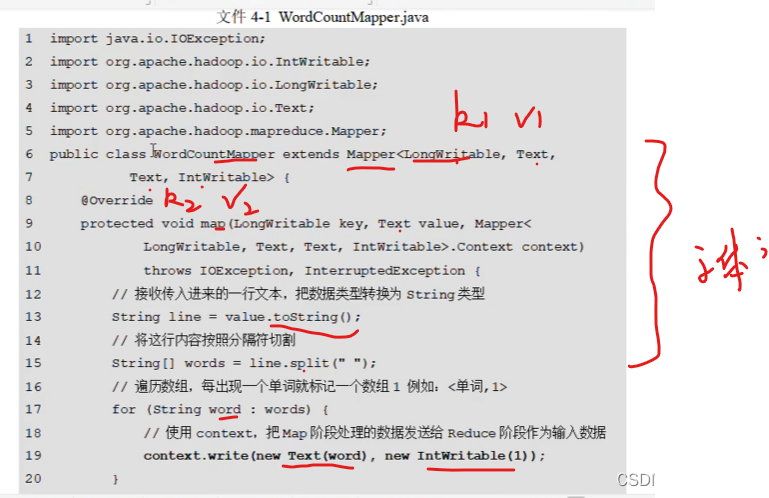
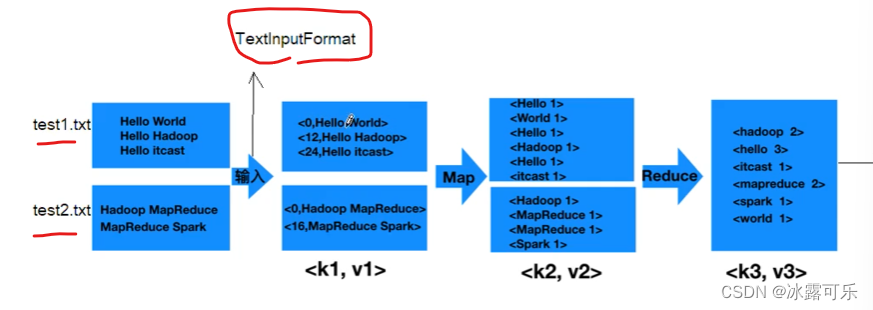
new一个text和int就是kv
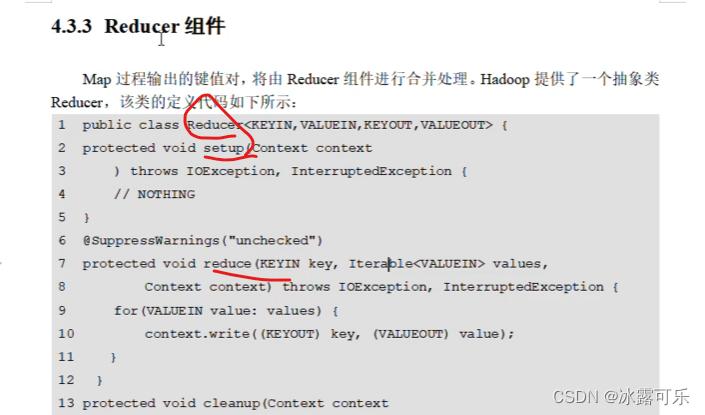

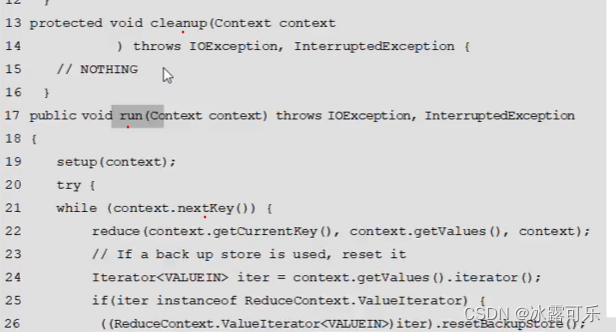
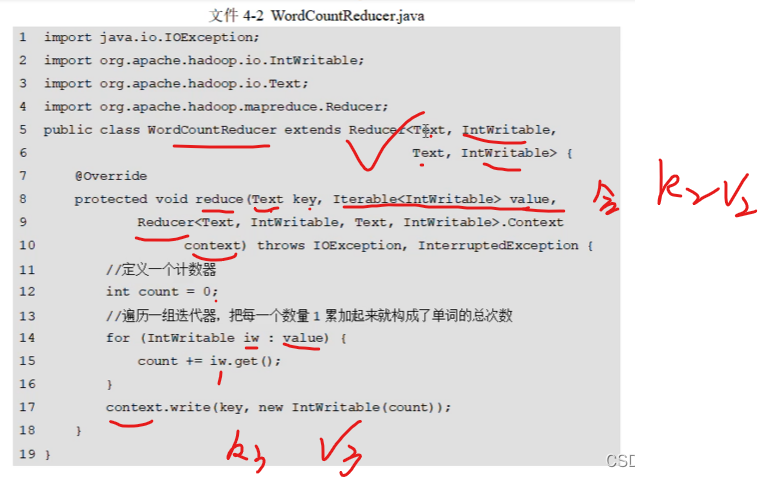


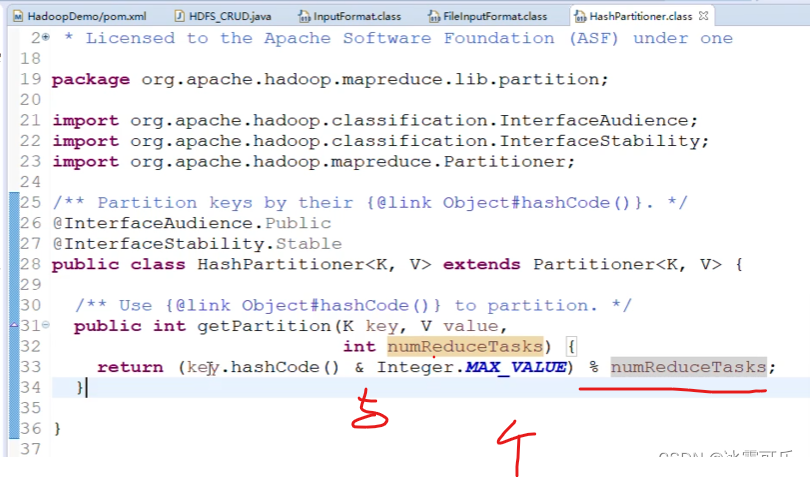
k想通,哈希值就相同
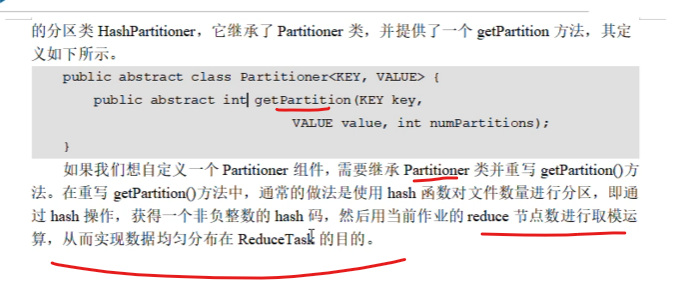
就是分区的编号,根key个数相同



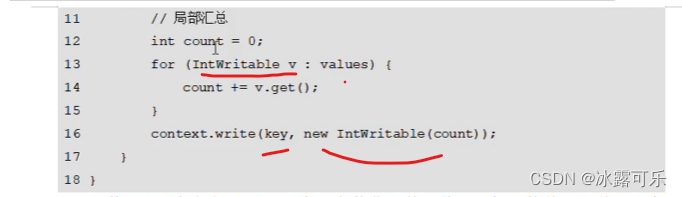



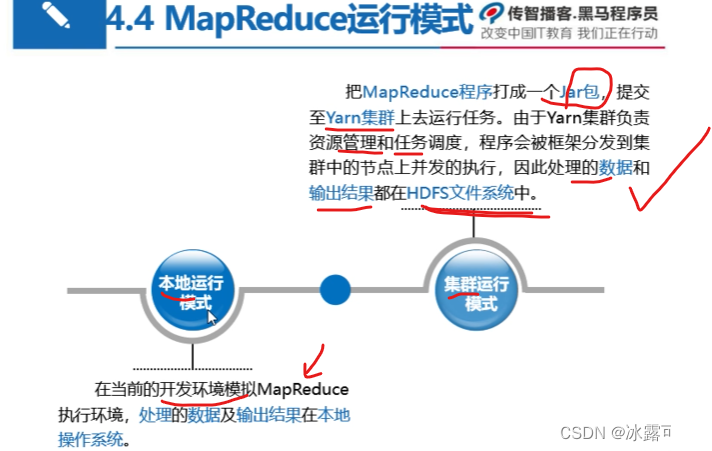
MapReduce的运行模式
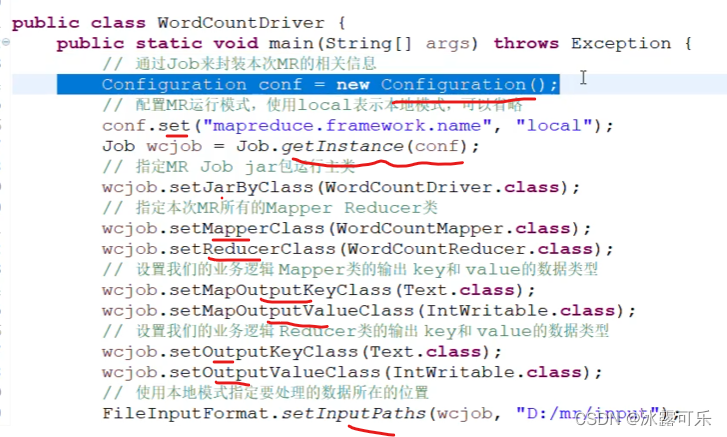
输入输出
key123各种格式
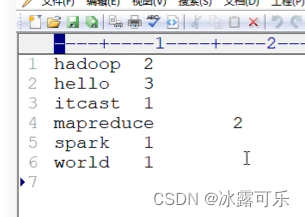
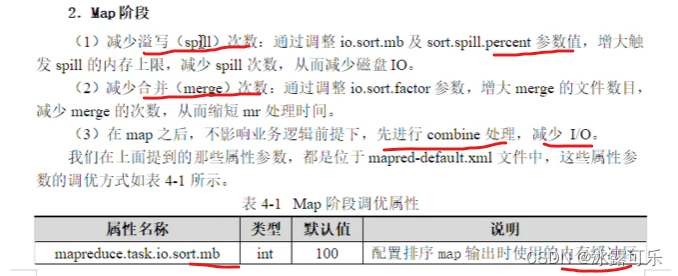
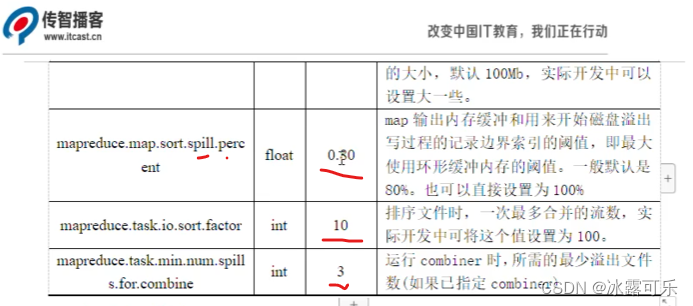
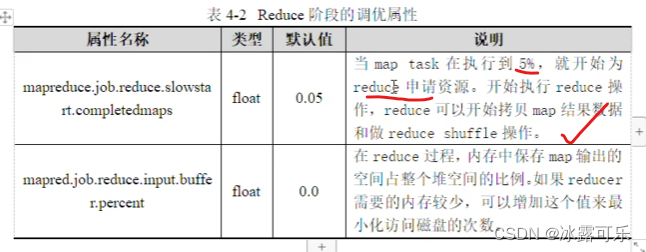
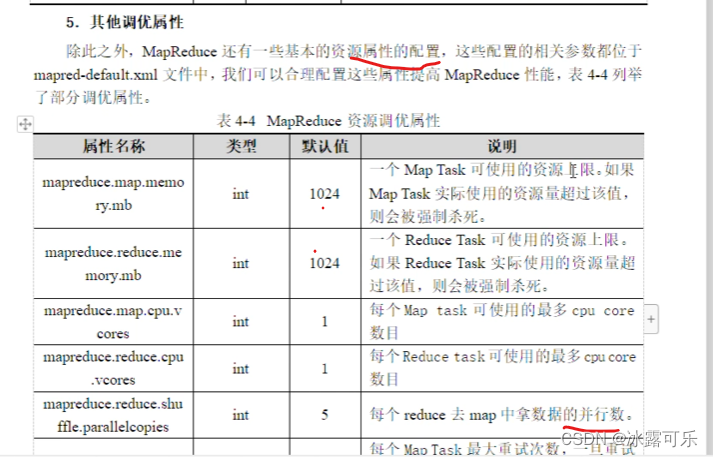
MapReduce的性能优化



总结
提示:重要经验:
1)
2)学好oracle,即使经济寒冬,整个测开offer绝对不是问题!同时也是你考公网络警察的必经之路。
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。