【机器学习】 朴素贝叶斯算法:原理、实例应用(文档分类预测)
1. 算法原理
1.1 朴素贝叶斯方法
朴素贝叶斯方法涉及一些概率论知识,我们先来复习一下。
联合概率:包含多个条件,并且所有的条件同时成立的概率,公式为:
条件概率:事件A在另一个事件B已经发生的前提下发生的概率,记作P(A|B),如果有多个条件,
那记作:
朴素贝叶斯一般公式:
我举个小例子帮助大家理解:
某学校有N名学生,男生占60%,女生占40%。男生都留短发,女生一半留短发,一半留长发。
问题1:随机一个学生,知道性别的情况下,他(她)留短发的概率是多少?
答:男:P(短发|男生)=1;女:P(短发|女生)=0.5
问题2:随机一个学生,只知道他留短发,他是男生的概率是多少?
答:设 B=短发;A=男生
要求的是
P(B|A)=1, P(A)=0.6, P(B)=0.6*1+0.4*0.5=0.8
P(A|B)=1*0.6/0.8=0.75
1.2 文档分类方法
文档分类是在已经分类好了的文档中提取关键字,在以后遇到新的文档时,从这些关键字中预测这篇新文章是哪个类别。
在文档分类中,朴素贝叶斯公式为:
P(C|W) :某个关键字属于某个分类的概率
P(W|C) :某个分类下,某个关键字出现的概率
P(C) : 某个类别的概率(某个类别的文档数/总文档数)
P(W) : 这个关键字在需要预测的文档中出现的概率
1.3 拉普拉斯平滑系数
假如现在有一新的篇文章,它的主题包括‘影院’‘云计算’等关键字,我计算它属于娱乐类文章的概率。公式如下:
P(娱乐类|影院,云计算) = P(影院,云计算|娱乐类)*P(娱乐类)/P(影院,云计算),
其中P(影院,云计算|科技类)=P(影院|科技类)* P(云计算|科技类)
然而对于预测之前建立的分类模型,如果在已经分类好的文章中娱乐类文章种没有出现过云计算这个关键字,那么P(云计算|娱乐类)=0,导致P(影院,云计算|娱乐类)=0,结果就是一篇包括‘影院’‘云计算’等关键字的文章属于娱乐类的概率为0,这肯定不对。只要它里面包含了任何一个和娱乐类相关的词,都有可能是娱乐类。
因此引入拉普拉斯平滑系数来避免出现0概率的情况。方法如下:
将 P(W|C) 更改为
Ni:该W词在C类别所有文档中出现的次数,即云计算在娱乐类文章中出现了多少次。
N: C类别的文档所有词出现的次数和,即娱乐类一共有多少词。
a: 指定系数,一般为1。
m:训练文档中统计出现的特征词个数,即整个文档有多少词。
1.4 特征向量化方法
将一篇文章中出现的所有词进行特征向量化,将单词提取出来,计算它们一共出现了多少次。首先要从sklearn库中导入该方法 from sklearn.feature_extraction.text import CountVectorizer。
特征向量化方法:vect.fit_transform()
上式可理解为:fit表示提取特征,transform表示变成sparss矩阵
下面我用两个字符串例子来演示一下这个方法:
# 导入特征向量化方法
from sklearn.feature_extraction.text import CountVectorizer
# 定义两个字符串
word1 = 'i love python, python makes me happy'
word2 = 'hello world, i love the world'
# 变量vect接收特征向量化方法
vect = CountVectorizer()
# 将2个变量传入特征向量化方法,用于提取每个单词出现的次数
words = vect.fit_transform([word1,word2])
words变量接收的是sprase类型的矩阵,sparse矩阵只会标记word1和word2中不为0的地方,为0的地方不显示,即空格符就不计数直接跳过。如'i','love'等词,sparse矩阵会对这些词进行标记,标记方式为该词出现的次数。下面用代码帮助大家理解。
使用 vect.get_feature_names() 命令来获取word1和word2中出现的所有单词。
# 查看提取了哪些单词
names = vect.get_feature_names() #提取word1和word2中出现过的所有单词
# 将sparse矩阵转换成正常的数组形式
arr = words.toarray()
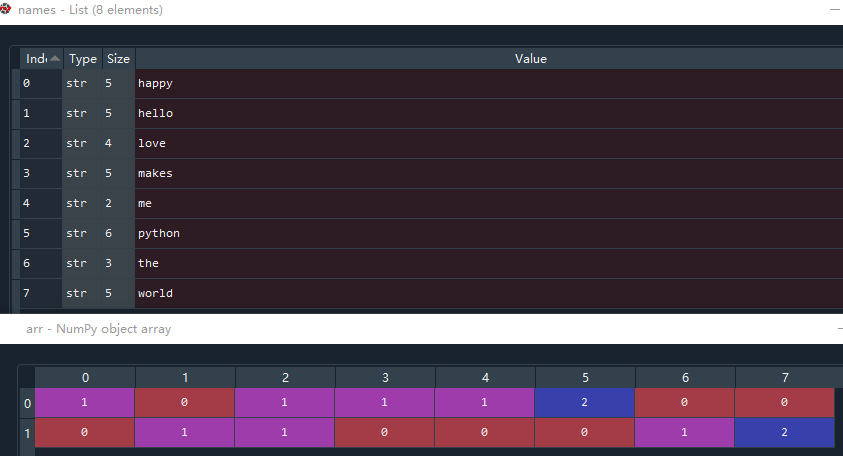
解释:arr变量中第0行表示word1某单词出现次数,第1行表示word2,某出现次数与names列表中的对应。即name列表中的'happy'在word1中出现了1次,在word2中出现了0次,‘world’这个词在word1中出现了0次,在word2中出现了2次。
2. 文档分类实战
2.1 数据获取
使用sklearn内部数据集获取新闻分组数据,下载到指定文件夹。有关系统内部数据集的获取方法可以参考我的前一篇文章机器学习-K近邻算法,或者该网页sklearn数据集,本篇文章就不进行详述。如果找不到数据集的,文末有数据集,有需要的自取。
# 使用sklearn内部数据集,获取新闻分组数据
from sklearn.datasets import fetch_20newsgroups
# 指定文件下载位置,把新闻数据下载到里面
filepath = 'C:\\Users\\admin\\.spyder-py3\\test\\文件处理\\newsgroup'
newsgroups = fetch_20newsgroups(data_home = filepath) #返回值是一个.Bunch类型数据

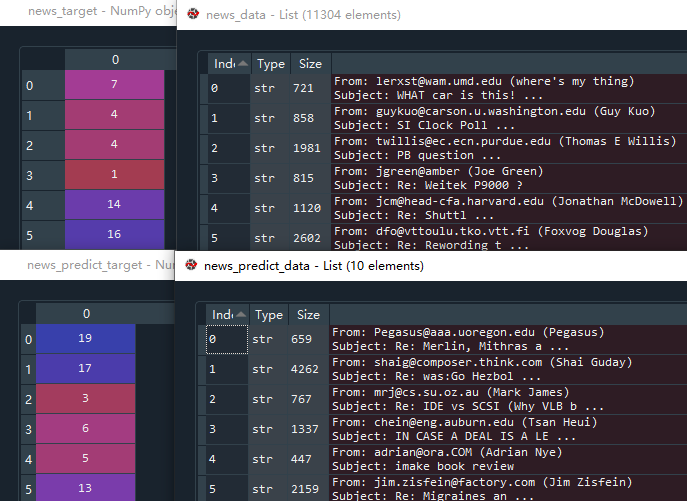
我们得到的newsgroups是一个.Bunch类型的数据;data中存放的是11314篇新闻文章;DESCR是对这个数据集的描述;filename是文件路径,可以忽视;target存放的是这11314篇文章的分类,一共有20个类别记作0到19;target_names记录的是20种分类的名称。
2.2 数据处理
首先从.Bunch数据中提取我们需要的,news_data相当于预测所需的特征值x,news_target相当于预测目标y。
# news_data中存放具体的文章,相当于x
news_data = newsgroups.data
# news_target中存放数据的目标值,即分类的结果,相当于y
news_target = newsgroups.target
从数据中提取最后10行用于结果验证,news_predict_data 存放最后十个的文章数据,用作最后预测函数的输入值,news_predict_target 存放最后十个主题分类,用于和最终预测结果比较,验证是否正确。然后将建模所用的数据剔除最后10行,即将 news_data 和 news_target 都删除最后10行数据。
# 取最后10行特征值作为验证集。用于预测的x
news_predict_data = news_data[-10:]
# 最后10行目标作为验证预测结果的准确性。用于验证的y
news_predict_target = news_target[-10:]
# 用于建模的特征值删除最后10行,x
news_data = news_data[:-10]
# 用于建模的目标值删除最后10行,y
news_target = news_target[:-10]
到此我们已经划分出验证所用数据和建模所用数据。
2.3 划分训练集和测试集
一般采用75%的数据用于训练,25%用于测试,因此把数据进行训练之前,先要对数据划分。
使用 sklearn.model_selection.train_test_split 进行分割
划分方式:
x_train,x_test,y_train,y_test = train_test_split(x数据,y数据,test_size=数据占比)
train_test_split() 参数
x:数据集特征值(news_data)
y:数据集目标值(news_target)
test_size: 测试数据占比,用小数表示
train_test_split() 返回值
x_train:训练部分特征值
x_test: 测试部分特征值
y_train:训练部分目标值
y_test: 测试部分目标值
# 划分测试集和训练集
from sklearn.model_selection import train_test_split
# 数据的75%用于训练,25%用于测试
x_train,x_test,y_train,y_test = train_test_split(news_data,news_target,test_size=0.25)
2.4 特征提取
为了统计每一篇文章中各个单词出现的次数,哪些分类中哪些单词出现的比较多,从而建立分类模型,同1.4所述。因此导入特征向量化方法CountVectorizer()
然后,对用于训练的新闻数据 x_train 进行 .fit_transform() 操作,先进行fit提取特征值,再transform 将数据sparse矩阵化,统计各个单词出现次数,特征向量化方法见1.4。
那么为什么对于测试用的新闻数据 x_test 只需要进行 transform 操作,而不需要 fit 提取特征值呢?可以简单理解为,x_train 是用来建立模型的,我需要知道它有哪些特征,这些特征值如何与目标值 y_train 相对应。模型建立完成之后,测试数据 x_test 是用来检测这个模型的准确率,相当于我给这个模型传一个 sparse 矩阵,这么模型自己就会进行一个特征的提取,内部会对我对输入值进行一系列处理得到预测结果。同理,我们也需要对验证所用的x数据 news_predict_data 进行sparse矩阵化。
# 导入特征向量化方法
from sklearn.feature_extraction.text import CountVectorizer
# news_vect 接收特征向量化方法
news_vect = CountVectorizer()
# 将x_train传入特征向量化方法
x_train = news_vect.fit_transform(x_train) #用于训练
# 测试数据矩阵化
x_test = news_vect.transform(x_test) #用于测试
# 把验证数据变成sparss矩阵,输入sparss矩阵,输出预测结果
news_predict_data = news_vect.transform(news_predict_data)
2.5 朴素贝叶斯方法预测
首先导入朴素贝叶斯方法库 from sklearn.naive_bayes import MultinomialNB
朴素贝叶斯函数: MultinomialNB()
MultinomialNB() 接收的参数 (alpha=1,fit_prior=True,class_prior=None)
alpha:拉普拉斯平滑系数,默认为1
朴素贝叶斯训练方法: .fit(self, x_train, y_train, sample_weight=None)
传入的x可以是数组、列表、sparss矩阵
# 导入朴素贝叶斯方法
from sklearn.naive_bayes import MultinomialNB
# nb接收朴素贝叶斯方法
nb = MultinomialNB()
# 训练,传入训练的特征sparss矩阵,训练的目标值
nb.fit(x_train,y_train)
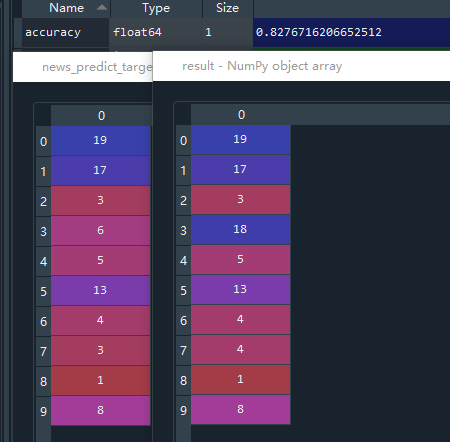
# 评分法看模型准确率,传入测试值特征sparss矩阵,和测试目标值
accuracy = nb.score(x_test,y_test)
# 预测,输入预测所需的特征值x
result = nb.predict(news_predict_data)
评分法计算模型准确率: .score(x_test, y_test)
根据x_test预测结果,把预测结果和真实的y_test比较,计算准确率
朴素贝叶斯预测方法: .predict(预测所需的x数据)
此处的x数据需要输入sparse矩阵
accuracy 存放模型准确率,result 存放分类结果,最终准确率为83%,result和实际结果news_predict_target有微小偏差。
完整代码如下:
# 文档分类实战#(1)数据获取
# 使用sklearn内部数据集,获取新闻分组数据
from sklearn.datasets import fetch_20newsgroups
# 指定文件下载位置,把新闻数据下载到里面
filepath = 'C:\\Users\\admin\\.spyder-py3\\test\\文件处理\\newsgroup'
newsgroups = fetch_20newsgroups(data_home = filepath) #返回值是一个.Bunch类型数据#(2)数据预处理
# news_names存放分类,一共20类
news_names = newsgroups.target_names
# news_data中存放具体的文章,相当于x
news_data = newsgroups.data
# news_target中存放数据的目标值,即分类的结果,相当于y
news_target = newsgroups.target# 取最后10行特征值作为验证集。用于预测的x
news_predict_data = news_data[-10:]
# 最后10行目标作为验证预测结果的准确性。用于验证的y
news_predict_target = news_target[-10:]
# 用于建模的特征值删除最后10行,x
news_data = news_data[:-10]
# 用于建模的目标值删除最后10行,y
news_target = news_target[:-10]#(3)划分测试集和训练集
from sklearn.model_selection import train_test_split
# 数据的75%用于训练,25%用于测试
x_train,x_test,y_train,y_test = train_test_split(news_data,news_target,test_size=0.25)#(4)特征抽取
# 导入特征向量化方法
from sklearn.feature_extraction.text import CountVectorizer
news_vect = CountVectorizer() # news_vect 接收特征向量化方法
# 将x_train传入特征向量化方法,用于统计x_train中每篇文章的单词出现了多少次,返回sparss矩阵
# fit先提取x_train的特征,transform将x_train中的数据进行sparss矩阵化
x_train = news_vect.fit_transform(x_train) #用于训练
# 上面已经进行过提取特征的操作,这一步不需要fit,直接进行transform矩阵化即可
x_test = news_vect.transform(x_test) #用于测试,我给模型一个sparss矩阵,模型给我一个预测结果
# 同理,我也需要把验证数据变成sparss矩阵,输入sparss矩阵,输出预测结果
news_predict_data = news_vect.transform(news_predict_data) #(5)朴素贝叶斯方法预测
from sklearn.naive_bayes import MultinomialNB # 导入朴素贝叶斯方法
# MultinomialNB接收的参数(alpha=1,fit_prior=True,class_prior=None)
# alpha:拉普拉斯平滑系数,默认为1
# 用于训练时的fit()方法,fit(self,x,y,sample_weight=None)
# 传入的x可以是数组、列表、sparss矩阵nb = MultinomialNB() # nb接收朴素贝叶斯方法
# 训练,传入训练的特征sparss矩阵,训练的目标值
# 朴素贝叶斯训练时,只需要提取特征值fit,不需要transform对特征进行一系列操作
nb.fit(x_train,y_train)
# 评分法看模型准确率,传入测试值特征sparss矩阵,和测试目标值
accuracy = nb.score(x_test,y_test) # 根据x_test预测结果,把预测结果和真实的y_test比较,计算准确率
# 预测,输入预测所需的特征值x(非sparss矩阵)
result = nb.predict(news_predict_data)