Codeforces Round #624 (Div. 3) F - Moving Points(树状数组+去重离散化)
题目链接
题目大意
在 O X OX OX坐标轴上有 n n n个点,每个点都有一个速度(可以为负数),每时每刻所有点都以自己的速度不断运动,定义 d ( i , j ) d(i,j) d(i,j)为第 i i i和第 j j j个点在坐标轴上的的最短距离(可以是任意时刻)如果可以相遇则 d ( i , j ) = 0 d(i,j)=0 d(i,j)=0,求任意两个节点的 d d d之和。显然两个节点要么相遇要么不相遇,相遇的话 d d d为 0 0 0,不相遇的话 d d d为初始两点的距离(因为随着时间流逝不相遇的话距离会越来越大)
解题思路
首先需要明白的是如果当前 x i < x j x_i<x_j xi<xj且 v i ≤ v j v_i \leq v_j vi≤vj,那么两点不会相遇,只需要加上两者差值的绝对值,否则就不统计二者的距离。如果使用树状数组的话,我们需要知道要统计的是每个节点前面有多少个速度小于等于它的节点。如第二组样例输入1 2 4后,三者速度相同,那么其贡献是 2 ∗ 4 − ( 1 + 2 ) 2*4-(1+2) 2∗4−(1+2),也就是该节点前面有 n u m num num个小于等于它的节点,就拿 n u m ∗ x − s u m ( x − 1 ) num*x-sum(x-1) num∗x−sum(x−1),后者是节点之前的前缀和。而且要保证后面节点坐标大于当前节点坐标,而且速度也要满足后者大于等于前者。故我们要对速度和坐标分别从小到大进行排序。
对上面分析完之后,接下来就是如何去建立树。对去重后的速度数组建立树状数组,而且要用另外一个二元组保存坐标和速度的对应关系并对坐标从小到大排序,这样保证了两个序列都是从小到大的排列。每次先取当前坐标的速度,使用 l o w e r b o u n d lower_bound lowerbound查找在去重的速度排第几位(注意从 1 1 1开始),我们再通过建立的两个树状数组 s u m sum sum和 c n t cnt cnt(分别记录前缀和以及每个速度对应的前面速度有几个点),求出对 a n s ans ans的贡献后再更新这个速度(这里是相对的第几大)以后的树状数组,这样就可以计算出结果
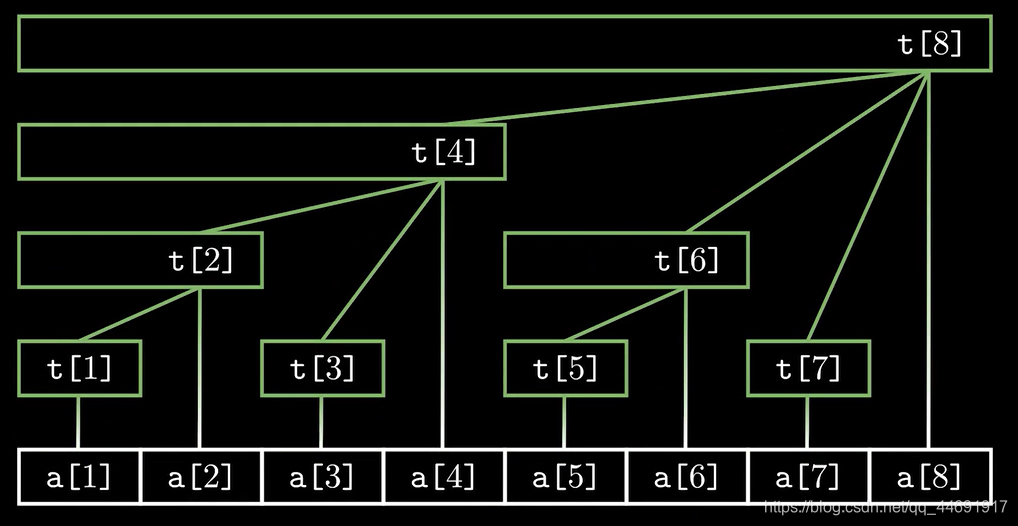
我参考了这个博客,感谢博主。每次我都会去列一下是否建立的树状数组符合题目,然后在纸上构造出这个图:如图的
a
a
a对应去重后的速度数组
v
v
v,而
t
t
t就是
s
u
m
sum
sum和
c
n
t
cnt
cnt数组。
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
typedef long long ll;
#define lowbit(x) (x&(-x))
const int maxn=2e5+10;
pair<ll,ll> a[maxn];
ll sum[maxn],cnt[maxn];
int v[maxn],n;
void update(int i,int k){
while(i<=n){
cnt[i]++; //当前以及之后对应节点数增加一
sum[i]+=k; //当前以及之后前缀和增加k
i+=lowbit(i);
}
}
ll getSum(int i){
ll ans=0;
for(;i;i-=lowbit(i))
ans+=sum[i];
return ans;
}
ll getCnt(int i){
ll ans=0;
for(;i;i-=lowbit(i))
ans+=cnt[i];
return ans;
}
int main(){
scanf("%d",&n);
for(int i=1;i<=n;i++){
scanf("%lld",&a[i].first);
}
for(int i=1;i<=n;i++){
scanf("%lld",&v[i]);
a[i].second=v[i];
}
sort(a+1,a+1+n);
sort(v+1,v+1+n);
int tot=unique(v+1,v+n+1)-v-1; //得到一共多少个去重后的速度
ll ans=0;
for(int i=1;i<=n;i++){
int num=lower_bound(v+1,v+1+tot,a[i].second)-v; //减去v得到的才是当前速度是第几大
ans+=1LL*getCnt(num)*a[i].first-getSum(num);
update(num,a[i].first);
}
printf("%lld",ans);
}
做法二
这是我去逛CF官网提交记录的时候发现的,而且很多大佬也都这样写%%%,我想了一会没想出来为什么这样写,但是大佬的代码总是简单精炼效率高。
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N=2e5+10;
int n,x[N];
pair<int,int>a[N];
ll ans;
int main()
{
ios::sync_with_stdio(0),cin.tie(0),cout.tie(0);
cin>>n;
for(int i=1;i<=n;i++){
cin>>x[i];
a[i].second=x[i];
}
for(int i=1;i<=n;i++)
cin>>a[i].first;
sort(a+1,a+n+1);
sort(x+1,x+n+1);
for(int i=1;i<=n;i++){
//cout<<"("<<x[i]<<","<<a[i].first<<"-"<<a[i].second<<")"<<"-----"<<lower_bound(x+1,x+n+1,a[i].second)-x-n-1<<" "<<i+lower_bound(x+1,x+n+1,a[i].second)-x-n-1<<endl;
ans+=(i+lower_bound(x+1,x+n+1,a[i].second)-x-n-1)*1LL*a[i].second;
}
cout<<ans;
}