zookeperkafka学习
1、why kafka
| 优点 | 缺点 | |
| kafka |
| 延迟也会高,不适合电商场景。 |
| RabbitMQ |
| 性能RocketMQ低 |
| RocketMQ |
|
2、Broker:
缓存代理(可以把Broker理解为Kafka的服务器),Kafka 集群中的一台或多台服务器统称为 broker。kafka中支持消息持久化的,生产者生产消息后,kafka不会直接把消息传递给消费者,而是先要在broker中进行存储,持久化是保存在kafka的日志文件中。
3、分区:
一个消费者可以对应多个分区,一个分区只能对应一个消费者。
topic分区有leader和follower。 Log的分区被分布到集群中的多个服务器上。每个服务器处理它分到的分区。 根据配置每个分区还可以复制到其它服务器作为备份容错。 每个分区有一个leader,零或多个follower。Leader处理此分区的所有的读写请求,而follower被动的复制数据。如果leader宕机,其它的一个follower会被推举为新的leader。 一台服务器可能同时是一个分区的leader,另一个分区的follower。 这样可以平衡负载,避免所有的请求都只让一台或者某几台服务器处理。
4、消费者组 :
topic实现JMS模型中消费者组中只有一个消费者,这种情况下topic的消费的offset是无序的。当单个消费者无法跟上数据生成的速度,就可以增加更多的消费者分担负载,每个消费者只处理部分partition的消息,从而实现单个应用程序的横向伸缩。但是不要让消费者的数量多于partition的数量,此时多余的消费者会空闲。此外,Kafka还允许多个应用程序从同一个Topic读取所有的消息,此时只要保证每个应用程序有自己的消费者组即可。
kafka为什么读写快?
利用零拷贝和页面缓存技术,零拷贝技术读取文件数据并发送到网络的步骤如下:
- 将磁盘文件的数据复制到页面缓存。
- 将数据从页面缓存直接发送到网卡从而发到网络中。
rebalance
主要是对partition的个数和group当中的consumer个数重新统计,再重新对应consumer和partition的关系。一个消费者可以对应多个分区。一个分区只能对应一个消费者。
kafka producer API
生产者的分区由key决定
我们创建消息的时候,必须要提供主题和消息的内容,而消息的key是可选的,当不指定key时默认为null。消息的key有两个重要的作用:1)提供描述消息的额外信息;2)用来决定消息写入到哪个分区,所有具有相同key的消息会分配到同一个分区中。
如果key为null,那么生产者会使用默认的分配器,该分配器使用轮询(round-robin)算法来将消息均衡到所有分区。
如果key不为null而且使用的是默认的分配器,那么生产者会对key进行哈希并根据结果将消息分配到特定的分区。
案例:
Here is a simple example of using the producer to send records with strings containing sequential numbers as the key/value pairs.
Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("acks", "all");props.put("retries", 0);props.put("batch.size", 16384); //默认是16kB, 每个Batch要存放batch.size大小的数据后,才可以发送出去。props.put("linger.ms", 1); //一个Batch被创建之后,最多过多久,不管这个Batch有没有写满,都必须发送出去了。props.put("buffer.memory", 33554432); //默认是32MB,KafkaProducer发送出去的消息都是先进入到客户端本地的内存缓冲里,然后把很多消息收集成一个一个的Batch,再发送到Broker上去的。props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");Producer<String, String> producer = new KafkaProducer<>(props);for(int i = 0; i < 100; i++)producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i)));producer.close();
kafka consumer API
案例一:手动同步提交
Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("group.id", "test");props.put("enable.auto.commit", "false");props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);consumer.subscribe(Arrays.asList("foo", "bar"));final int minBatchSize = 200;List<ConsumerRecord<String, String>> buffer = new ArrayList<>();while (true) {ConsumerRecords<String, String> records = consumer.poll(100);for (ConsumerRecord<String, String> record : records) {buffer.add(record);}if (buffer.size() >= minBatchSize) {insertIntoDb(buffer);consumer.commitSync();buffer.clear();}}
案例二:每个partition手动同步提交
try {while(running) {ConsumerRecords<String, String> records = consumer.poll(Long.MAX_VALUE);for (TopicPartition partition : records.partitions()) {//拿到这个partition下面的所有数据List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);for (ConsumerRecord<String, String> record : partitionRecords) {System.out.println(record.offset() + ": " + record.value());}//通过这个partition的list获取最后一个数据的offsetlong lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset();consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(lastOffset + 1)));}}} finally {consumer.close();}
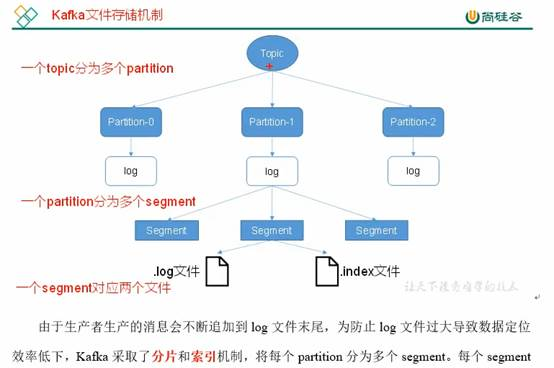
Kafka文件存储:
知道通过分片和索引机制找到offset的就行了。index和log文件以当前的第一条消息的offset命名。