【数据挖掘 机器学习 | 时间序列】时间序列必学模型: ARIMA超详细讲解

🤵♂️ 个人主页: @AI_magician
📡主页地址: 作者简介:CSDN内容合伙人,全栈领域优质创作者。
👨💻景愿:旨在于能和更多的热爱计算机的伙伴一起成长!!🐱🏍

摘要: 本系列旨在普及那些深度学习路上必经的核心概念,文章内容都是博主用心学习收集所写,欢迎大家三联支持!本系列会一直更新,核心概念系列会一直更新!欢迎大家订阅
该文章收录专栏
[✨— 《深入解析机器学习:从原理到应用的全面指南》 —✨]
content
- 传统时间序列系列模型
- ARIMA模型
- AR MA 模型介绍
- **前提假设**
- ARIMA算法步骤
传统时间序列系列模型
以下是一些常见传统时序建模方法。
| 名称 | 介绍 | 优点和缺点 |
|---|---|---|
移动平均模型 (Moving Average Model) MA | 移动平均模型是一种基本的时间序列模型,它假设观测值是过去观测值的线性组合。该模型没有考虑趋势和季节性等因素,适用于平稳的时间序列数据。 | 优点:简单易懂,参数易于解释。缺点:忽略了趋势和季节性等重要因素,不适用于非平稳数据。 |
自回归模型 (Auto Regressive Model) AR | 自回归模型是一种基于时间序列过去值的线性回归模型。它假设观测值与过去观测值之间存在一种自相关关系。AR模型的阶数§表示其依赖的过去观测值的数量。 | 优点:能够捕捉时间序列内在的自相关性。缺点:不考虑其他影响因素,对于复杂的时间序列可能不够准确。 |
移动平均自回归模型 (Autoregressive Moving Average Model) ARMA | 移动平均自回归模型是自回归模型和移动平均模型的结合。ARMA模型包含两个参数,分别表示自回归阶数§和移动平均阶数(q)。 | 优点:结合了自回归和移动平均的优点,能够应对更广泛的时间序列模式。缺点:对于参数的选择和估计需要一定的经验和技巧。 |
季节性自回归移动平均模型 (Seasonal Autoregressive Integrated Moving Average Model) ARIMA | 季节性ARIMA模型是ARMA模型的扩展,用于处理具有明显季节性模式的时间序列。它包含了季节性差分和季节性ARMA模型。 | 优点:适用于具有季节性模式的时间序列数据。缺点:参数选择和估计的复杂性较高,需要较多的历史数据。 |
| 隐马尔可夫模型 (Hidden Markov Model) | 隐马尔可夫模型是一种统计模型,用于建模具有潜在隐状态的时间序列数据。它具有两个基本假设,即当前状态仅取决于前一个状态,并且观测值仅取决于当前状态。 | 优点:适用于具有潜在隐状态的时间序列数据,能够进行状态的预测和估计。缺点:对于较长的时间序列,模型复杂度可能较高,计算开销大。 |
| 长短期记忆网络 (Long Short-Term Memory Network) | 长短期记忆网络是一种特殊类型的循环神经网络 (RNN),用于处理具有长期依赖性的时间序列数据。LSTM通过门控机制来控制信息的流动,能够有效地捕捉时间序列中的长期依赖关系。 | 优点:能够处理长期依赖性,适用于复杂的时间序列模式。缺点:模型复杂度较高,训练和调整参数可能较为困难 |
ARIMA模型
AR MA 模型介绍
我们首先捋清楚下面四个。
AR(自回归)模型是一种仅使用过去观测值来预测未来观测值的模型。它基于一个假设,即当前观测值与过去观测值之间存在一种线性关系,可以用来描述时间序列数据的自相关性。AR模型的阶数表示过去的观测值对当前观测值的影响程度,例如AR(1)表示只考虑一个过去观测值的影响。
MA(移动平均)模型是一种把一个时间序列看作是过去若干期噪声的加权平均,即当前的观察值是由过去的白噪声通过一定的线性组合得到的。基本思想是:大部分时候时间序列应当是相对稳定的。在稳定的基础上,每个时间点上的标签值受过去一段时间内、不可预料的各种偶然事件影响而波动。即在一段时间内,时间序列应该是围绕着某个均值上下波动的序列,时间点上的标签值会围绕着某个均值移动,因此模型才被称为“移动平均模型 Moving Average Model”. MA模型的阶数表示考虑过去的预测误差的数量,例如MA(1)表示只考虑一个过去的预测误差。
解释一下上述这段定义:
- 均值稳定:时间序列的均值或期望值是恒定的,不随时间变化。这就是公式中的μ项,它对所有时间点都是相同的。这也是为什么会说“时间序列应该是围绕着某个均值上下波动的序列”。在许多实际的时间序列分析中,我们可能需要通过一些预处理步骤(如差分或去趋势)将原始时间序列转换为均值稳定的序列。
- 方差稳定:时间序列的方差也是恒定的,不随时间变化。换句话说,时间序列的波动程度是一致的,不会在不同的时间点表现出明显的扩大或缩小。在MA模型中,这个特性主要由白噪声项 ϵt 来保证,因为白噪声的方差是常数。
- 无自相关:在理想的MA模型中,不同时间点的观察值之间没有自相关性。这意味着过去的值不能用来预测未来的值,除非你考虑到了白噪声项。这就是为什么会说“每个时间点上的标签值受过去一段时间内、不可预料的各种偶然事件影响而波动”。
ARMA(自回归移动平均)模型是AR和MA模型的结合。它综合考虑了过去观测值和过去的白噪声序列对当前观测值的影响。ARMA模型的阶数分别表示AR部分和MA部分的阶数,例如ARMA(1,1)表示考虑一个过去观测值和一个过去的预测误差。
ARIMA(自回归综合移动平均)模型是在ARMA模型的基础上引入了差分操作,用于处理非平稳时间序列(季节性)。ARIMA模型包括差分操作、自回归部分和移动平均部分。通过差分操作,ARIMA模型可以将非平稳时间序列转化为平稳时间序列,然后使用ARMA模型进行建模。ARIMA模型的阶数分别表示差分操作、AR部分和MA部分的阶数,例如ARIMA(1,1,1)表示进行一阶差分,考虑一个过去观测值和一个过去的预测误差。
前提假设
1、平稳性:MA模型假设时间序列是平稳的。这意味着序列的主要统计属性,如均值和方差,不随时间变化。这个假设强调了序列在长期内保持稳定的行为,而在短期内可能会受到随机因素的影响。
2、白噪声:MA模型假设存在一个白噪声序列。白噪声是随机误差项,它的均值为0,方差为常数,且各个时间点上的值是相互独立的。这个假设强调了在一段较短的时间内,时间序列的波动可能受到不可预测的随机因素的影响。
3、线性:MA模型假设时间序列可以被过去的白噪声项的线性组合表示。这就是模型被称为“移动平均”模型的原因,因为它的预测值是过去白噪声的加权平均。
4、有限历史影响:MA模型假设只有过去的q个白噪声才对当前时间点的值有影响,其中q是模型的阶数。换句话说,过去更久的白噪声对当前值没有直接影响。
5、标签值的关联性与白噪声的独立性:AR模型假设不同时间点的标签值之间是关联的,这反映了历史标签影响时间序列的长期趋势。而MA模型假设偶然事件在不同时间点上产生的影响(即白噪声)是相互独立的,这反映了在短期内,时间序列的波动可能受到不可预测的随机因素的影响。
举个例子:影响明日会不会下雨的真正因素不仅是“今天”或“昨天”这些过去的天气,而是还有风、云、日照等更加客观和科学的因素(这些其实就是MA模型认为的“偶然因素”)。随着季节的变化、时间自有自己的周期,因此天气也会存在季节性的周期,因此从长期来看时间序列的趋势是恒定的。
ARIMA算法步骤
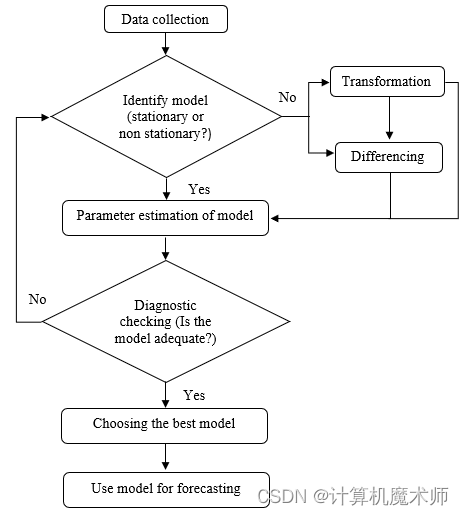
-
数据准备:首先,收集时间序列数据,并进行必要的预处理。确保数据是连续的,并处理任何缺失值或异常值。
-
平稳性检验:通过绘制时间序列图,自相关图及其单位根检验观察数据的整体趋势、季节性和噪声。这将帮助我们选择合适的ARIMA模型参数。(确定是否符合假设,并进行平稳性检验)
-
确定差分阶数(d):(绘图看趋势 & ADF等检验),如果时间序列是非平稳的,需要进行差分操作,使其变为平稳序列。通过计算一阶差分、二阶差分等,直到得到平稳序列。差分阶数d即为使时间序列平稳所需的差分次数。
-
进行白噪声检验:如果通过白噪声检验(非平稳一定不是白噪声检验),这意味着该时间序列在统计上表现出了随机性,时间序列中没有明显的模式或趋势。可能需要重新考虑研究假设或采用不同的分析方法。
-
确定自回归(AR)和移动平均(MA)的阶数(p和q)
-
建立公式如下
AR部分(Autoregressive Part):
AR ( p ) : X t = ϕ 0 + ∑ i = 1 p ϕ i X t − i + ε t \text{AR}(p): \quad X_t = \phi_0 + \sum_{i=1}^{p} \phi_i X_{t-i} + \varepsilon_t AR(p):Xt=ϕ0+i=1∑pϕiXt−i+εt其中:
- X t X_t Xt 是时间序列在时间点t的观测值。
- ϕ 0 \phi_0 ϕ0 是常数项。
- ϕ i \phi_i ϕi 是自回归系数,表示时间序列在过去p个时间点的滞后值与当前值之间的线性关系。
- ε t \varepsilon_t εt 是白噪声随机干扰误差项。
差分部分(Integrated Part):
I ( d ) : Y t = ( 1 − L ) d X t \text{I}(d): \quad Y_t = (1 - L)^d X_t I(d):Yt=(1−L)dXt其中:
- Y t Y_t Yt 是经过d阶差分处理后的时间序列。
- L L L 是滞后 算子,表示对时间序列进行一步滞后操作,即 L X t = X t − 1 LX_t = X_{t-1} LXt=Xt−1。
移动平均部分(Moving Average Part):
MA ( q ) : X t = μ + ε 0 + ∑ i = 1 q θ i ε t − i \text{MA}(q): \quad X_t = μ + \varepsilon_{0} + \sum_{i=1}^{q} \theta_i \varepsilon_{t-i} MA(q):Xt=μ+ε0+i=1∑qθiεt−i其中:
-
θ i \theta_i θi 是移动平均系数,表示误差项在过去q个时间点的滞后值与当前值之间的线性关系。 $\varepsilon_{0} $ 为零均值白噪声序列, μ μ μ为均值。
-
在实际计算时,MA模型规定 ϵ 等同于模型的预测值 Y^t 与真实标签 Yt 之间的差值(Residuals),即:
ϵ t = Y t − Y t ϵt=Yt−Y^t ϵt=Yt−Yt
MA模型使用预测标签与真实标签之间的差异就来代表“无法被预料、无法被估计、无法被模型捕捉的偶然事件的影响”。MA模型相信这些影响累加起来共同影响下一个时间点的标签值,因此 Yt 等于所有 ϵ 的线性组合(加权求和)。 ϵt的前面没有需要求解的系数(即默认系数为1),这可能代表当前的“偶然事件”对 ϵt 的标签的影响程度是100%。
-
具体地说,给定过去q个时刻的误差项,当前时刻t的误差项ε_t可以通过以下方式计算:
ε t = X t − μ − θ 1 ε ( t − 1 ) − θ 2 ε ( t − 2 ) − . . . − θ q ε ( t − q ) ε_t = X_t - μ - θ_1ε_(t-1) - θ_2ε_(t-2) - ... - θ_qε_(t-q) εt=Xt−μ−θ1ε(t−1)−θ2ε(t−2)−...−θqε(t−q)
也就是说,当前时刻的误差项是观测值与序列均值以及过去q个时刻的误差项的加权差。(将公式变换一下)
综合起来,ARIMA(p, d, q)模型的数学公式可以表示为:
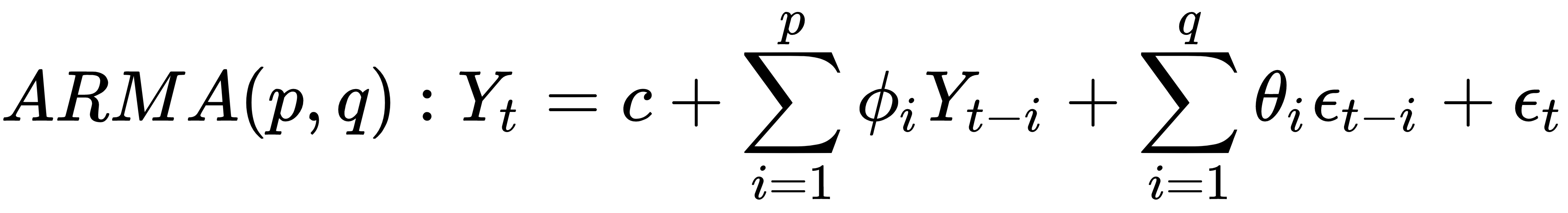
这个公式描述了ARIMA模型中时间序列的变化规律,其中p、d和q分别表示AR、差分和MA的阶数。通过拟合ARIMA模型到历史数据,并使用该模型进行预测,可以获得对未来时间序列值的估计。
-
模型训练:使用最大似然估计或其他优化算法,对ARIMA模型的参数进行估计和优化。
-
模型评估:使用各种评估指标(如均方根误差RMSE、平均绝对误差MAE等)来评估模型的拟合效果。如果模型拟合效果不好,可以调整参数并重新拟合模型。
-
模型预测:使用训练好的ARIMA模型进行未来时间点的差分预测并通过逆差分得到目标数据。可以通过逐步预测或一次性预测多个时间点。
下面是一个使用Python库实现ARIMA模型的模板示例:
import pandas as pd
from statsmodels.datasets import get_rdataset
from statsmodels.tsa.arima.model import ARIMA# 获取AirPassengers数据集
data = get_rdataset('AirPassengers').data# 将Month列转换为日期类型
data['Month'] = pd.to_datetime(data['Month'])# 将Month列设置为索引列
data.set_index('Month', inplace=True)# 拆分数据集为训练集和测试集
train_data = data[:'1959']
test_data = data['1960':]# 创建ARIMA模型
model = ARIMA(train_data, order=(2, 1, 2))# 拟合模型
model_fit = model.fit()# 预测未来值
predictions = model_fit.predict(start='1960-01-01', end='1960-12-01', dynamic=False)# 打印预测结果
print(predictions)

🤞到这里,如果还有什么疑问🤞🎩欢迎私信博主问题哦,博主会尽自己能力为你解答疑惑的!🎩🥳如果对你有帮助,你的赞是对博主最大的支持!!🥳