大型语言模型中的幻觉研究综述:原理、分类、挑战和未决问题11.15+11.16+11.17
大型语言模型中的幻觉研究综述:原理、分类、挑战和未决问题11.15
- 摘要
- 1 引言
- 2 定义
- 2.1 LLM
- 2.3 大语言模型中的幻觉
- 3 幻觉的原因
- 3.1 数据的幻觉
- 3.1.1 有缺陷的数据源
- 3.1.2 较差的数据利用率
- 3.1.3 摘要
- 3.2 来自训练的幻觉
- 3.2.1训练前的幻觉
- 3.2.2来自对齐的幻觉
- 3.2.3总结
- 3.3 来自干扰解码的幻觉
- 3.3.1内在抽样随机性
- 3.3.2不完美的解码
- 3.3.3总结
- 4 幻觉检测和基准
- 4.1 幻觉检测
- 4.1.1 幻觉检测
- 4.1.2忠实性幻觉检测
- 4.2 基准
- 4.2.1 幻觉评估基准
- 4.2.2 幻觉检测基准
- 5 减轻幻觉
- 5.1数据相关幻觉
- 5.1.1 减少错误信息和偏见
- 5.1.2 减少知识边界
- 5.1.3减少知识冗余
- 5.1.4减轻知识回忆
- 5.2减轻与培训相关的幻觉
- 5.2.1 减轻预训练相关的幻觉
- 5.2.2 缓解错位幻觉
- 5.3 减轻与推理相关的幻觉
- 5.3.1 真实增强解码
- 5.3.2忠诚度增强解码
- 6 挑战和开放性问题
- 6.1LLM的挑战
- 6.1.1长格式文本生成中的幻觉
- 6.1.2检索增强生成中的幻觉
- 6.1.3 大型视觉语言模型中的幻觉
- 6.2 在LLM幻觉开放问题
- 6.2.1 自我纠正机制是否有助于减轻推理幻觉?
- 6.2.2我们能准确地捕捉LLM知识边界吗?
- 6.2.3 如何在创造性和真实性之间取得平衡?

摘要
大型语言模型(LLM)的出现标志着自然语言处理(NLP)的重大突破,导致文本理解和生成的显着进步。然而,除了这些进步之外,LLM还表现出产生幻觉的关键倾向,导致内容与现实世界的事实或用户输入不一致。这种现象对它们的实际部署提出了重大挑战,并引起了对LLM在现实世界场景中的可靠性的担忧,这吸引了越来越多的关注来检测和减轻这些幻觉。在这项调查中,我们的目标是提供一个全面和深入的概述LLM幻觉领域的最新进展。我们开始与LLM幻觉的创新分类,然后深入研究的因素,有助于幻觉。随后,我们提出了一个全面的概述幻觉检测方法和基准。此外,相应地介绍了旨在减轻幻觉的代表性方法。最后,我们分析了突出当前局限性的挑战,并提出了开放性问题,旨在为未来的幻觉研究描绘道路。
1 引言
最近,大型语言模型(LLM)的出现已经迎来了自然语言处理(NLP)的范式转变,在语言理解方面取得了前所未有的进步,LLM和推理。然而,随着LLM的快速发展,存在一种令人担忧的趋势,即它们表现出产生幻觉的倾向,导致看似合理但事实上不支持的内容。
目前对幻觉的定义与先前的研究一致,将它们表征为对所提供的源内容无意义或不忠实的所生成的内容。这些幻觉进一步分为内在幻觉和外在幻觉类型,这取决于与源内容的矛盾。虽然这一类别在各种自然语言生成(NLG)任务中共享,但确实存在特定于任务的变化。由于LLM非常通用,并且在不同的NLG任务中表现出色,特别是在开放域应用程序中,与特定任务模型相比,它们显着的多功能性放大了幻觉的潜力。在LLM中,幻觉的范围包括更广泛和更全面的概念,主要集中在事实错误上。鉴于LLM时代的演变,有必要调整现有的幻觉分类,提高其适用性和适应性。
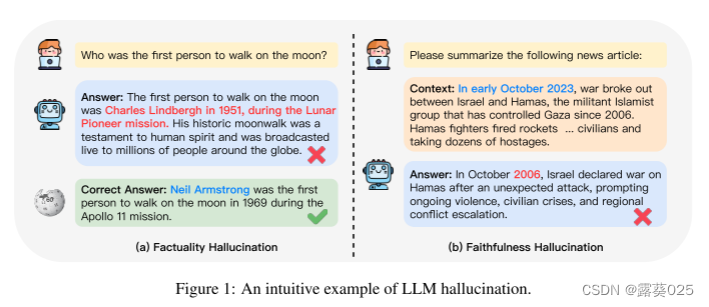
在这项调查中,我们重新定义了幻觉的分类,为LLM应用程序提供了一个更适合的框架。我们把幻觉分为两大类:真实性幻觉和忠实性幻觉。事实幻觉强调生成的内容与可验证的现实世界事实之间的差异,通常表现为事实不一致或捏造。例如,如图1(a)所示,当被问及第一个在月球上行走的人时,这个模型可能会断言它是1951年的查尔斯·林德伯格。而事实是,尼尔阿姆斯特朗是第一个在月球上行走的个人在1969年在阿波罗11号使命。另一方面,忠实性幻觉是指生成的内容与用户指令或输入提供的上下文的分歧,以及生成的内容内的自一致性。如图1(b)所示,当被要求总结一篇新闻文章时,该模型错误地生成了以色列和哈马斯之间冲突的实际事件日期,从2023年10月到2006年10月。关于事实性,我们进一步将其分为两个亚类:事实不一致和事实捏造。为了忠实,我们强调从用户的角度来解决不一致,将其分类为指令不一致,上下文不一致和逻辑不一致,从而更好地与LLM的当前使用保持一致。
至于幻觉的根本原因,虽然在NLG任务的背景下进行了研究,但在尖端LLM中存在独特的挑战,值得深入研究。我们深入分析专门针对LLM中幻觉的独特起源,涵盖了从数据和训练到推理阶段的一系列影响因素。在这个框架内,我们查明了潜在的数据相关原因,如有缺陷的来源和次优利用,可能在预训练和对齐过程中引起幻觉的劣质训练策略,以及那些源于解码策略的随机性和推理过程中的不完美表示。此外,我们全面概述了各种有效的检测方法,专门设计用于检测LLM中的幻觉,以及与LLM幻觉相关的基准的详尽概述,作为适当的测试平台,以评估LLM产生的幻觉程度和检测方法的有效性。此外,我们详细介绍了为减轻幻觉的确定原因而量身定制的综合策略。
通过这项全面的调查,我们的目标是为LLM领域的进步做出贡献,并提供有价值的见解,加深对法学硕士中与幻觉相关的机遇和挑战的理解。这种探索不仅增强了我们对当前LLM局限性的理解,而且为未来的研究和开发更强大,更值得信赖的LLM提供了必要的指导。
与现有调查进行比较。随着对可靠的生成式人工智能的推动加剧,LLM幻觉作为一个主要挑战脱颖而出,导致对其最近进展的大量调查。虽然这些著作从不同的角度探讨了LLM幻觉,并提供了有价值的见解,但有必要区分我们目前调查的独特方面和综合性质。Ji主要阐明了在NLG任务领域内预先训练的语言模型中的幻觉,使LLM超出了他们的讨论范围。Liu从更广的角度讨论了LLM的可信度,而Wang,内迁至中国。相比之下,我们的调查集中在LLM可信度的一部分挑战上,涵盖了事实的各个方面,并进一步扩大了话语范围,包括与忠诚相关的幻觉。据我们所知,与我们的调查最一致的工作是,概述了LLM幻觉现象的分类,评估基准和缓解策略。然而,我们的调查在其分类和组织结构方面都与众不同。我们提出了一个分层和粒度分类的幻觉。在结构上,我们通过追溯LLM的能力来剖析LLM幻觉的原因。更有针对性的是,我们的缓解战略与根本原因紧密相连,确保采取连贯和有针对性的方法。
本次调查的组织。在本文中,我们提出了一个全面的调查的最新进展,幻觉LLM。我们首先定义了LLM,并在此背景下构建了幻觉的分类学(§2)。随后,我们深入分析了导致LLMs幻觉的因素(§3),随后检查了用于可靠检测LLMs幻觉的各种方法和基准(§4)。然后,我们详细介绍了一系列旨在减轻LLM幻觉的方法(§5)。最后,我们深入探讨了该领域当前的局限性和未来前景所面临的挑战和开放性问题,为未来的研究提供了见解和潜在的途径(§6)。
2 定义
为了全面了解LLM中的幻觉,我们首先简要介绍LLM(第2.1节),描述本调查的范围。随后,我们深入研究了LLM的训练过程(§2.2),因为彻底了解潜在的训练机制有助于阐明幻觉的起源。最后,我们阐述了LLM中幻觉的概念(§2.3),进一步将其分为两种不同的类型。
2.1 LLM
在深入研究幻觉的原因之前,我们首先介绍LLM的概念。典型地,LLM指的是一系列通用模型,这些模型利用基于转换器的语言模型体系结构,并在大量文本语料库上进行广泛的训练,其中值得注意的例子包括GPT-3、PaLM、卡拉狄加、LLaMA和GPT-4。通过扩展数据量和模型容量,LLM提高了惊人的涌现能力,通常包括情境学习(ICL)、思想链提示和遵循指令。
前期训练。预培训通常被认为是LLM获得知识和技能的关键阶段。在预训练期间,语言模型的目标是自回归地预测序列中的下一个标记。通过对大量文本语料的自我监督训练,该模型获得了语言句法知识、世界知识和推理能力,为后续的微调任务提供了坚实的基础。此外,最近的研究提出了预测后续单词类似于无损压缩重要信息。语言模型的本质在于预测即将出现的单词的概率分布。准确的预测意味着对知识的深刻掌握,转化为对世界的微妙理解。
监督微调。虽然LLM在预培训阶段获得了大量的知识和能力,但必须认识到预培训主要是为了完成培训。因此,预训练的LLM基本上用作完成机,这可能导致LLM的下一个单词预测目标与用户获得期望响应的目标之间的不对准。为了弥补这一差距,SFT,其涉及使用(指令、响应)对的精心注释的集合来进一步训练LLM,从而导致LLM的增强的能力和改进的可控性。此外,最近的研究已经证实了监督微调的有效性,以实现对看不见的任务的卓越性能,展示了其显着的泛化能力。
从人的反馈中强化学习。虽然SFT过程成功地使LLM能够遵循用户指令,但它们仍有更好地与人类偏好保持一致的空间。在利用人类反馈的各种方法中,RLHF作为通过强化学习与人类偏好一致的研究所解决方案而脱颖而出。通常,RLHF采用偏好模型,训练用于预测偏好排名,同时给出一对人类标记的响应。为了与人的偏好一致,RLHF优化LLM以生成使由经训练的偏好模型提供的回报最大化的输出,典型地采用强化学习算法,诸如邻近策略优化(PPO)。这种将人的反馈整合到训练循环中的做法已被证明在增强LLM的一致性、引导它们产生高质量且无害的响应方面是有效的。
2.3 大语言模型中的幻觉
幻觉的概念起源于病理学和心理学领域,被定义为对现实中不存在的实体或事件的感知。在NLP领域内,幻觉通常被称为一种现象,其中生成的内容看起来对所提供的源内容无意义或不忠实。这个概念与人类心理学中观察到的幻觉现象有着松散的相似之处。通常,自然语言生成任务中的幻觉可分为两种主要类型:内在幻觉和外在幻觉。具体来说,内在幻觉是与原始内容相冲突的LLM的输出。相反,外在幻觉是指无法从源内容中验证的LLM生成。
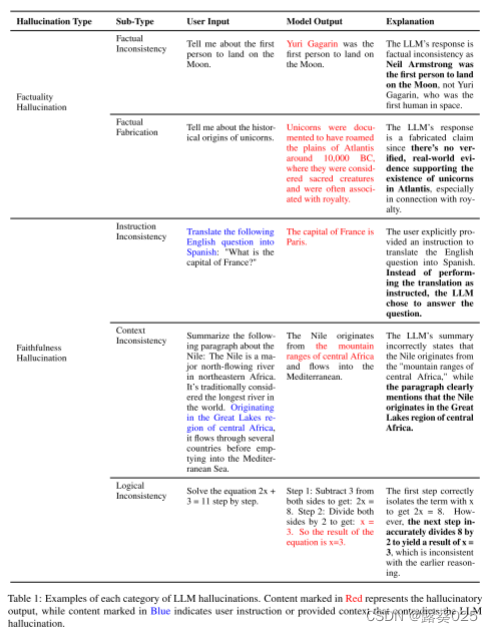
然而,在大型语言模型的时代,这些模型的多功能性促进了它们在不同领域的广泛使用,突出了现有特定任务分类范式的局限性。考虑到LLM非常重视以用户为中心的交互,并优先考虑与用户指令的一致性,再加上他们的幻觉主要出现在事实层面的事实,我们引入了一个更细粒度的分类法,该分类法建立在Ji的基础工作之上。这种精细的分类法试图概括与LLM幻觉相关的独特复杂性。为了更直观地说明我们对LLM幻觉的定义,我们在表1中给出了每种幻觉类型的例子,并附有相应的解释。我们建议的类别详情如下:
真实的幻觉。LLM的出现标志着从传统的特定任务工具包到AI助手的重大转变,这些助手更加关注开放领域的交互。这种转变主要归因于他们大量的参数化事实知识。然而,现有的LLM偶尔会表现出产生与现实世界事实不一致或潜在误导的输出的趋势,这对人工智能的可信度构成了挑战。在这种情况下,我们将这些事实错误归类为事实性幻觉。根据生成的事实内容是否可以根据可靠来源进行验证,它们可以进一步分为两种主要类型:
- 事实不一致 是指LLM的输出包含可以基于真实世界信息的事实,但存在矛盾的情况。这种类型的幻觉发生得最频繁,并且来自不同的来源,包括LLM对事实知识的捕获,存储和表达。如表1所示,当被问及“第一个登上月球的人”时,模型错误地生成了“尤里·加加林”,这与现实世界的事实相矛盾。
- 事实捏造 是指LLM的输出包含无法根据既定的现实世界知识进行验证的事实的情况。如表1所示,虽然“独角兽的起源”传统上缺乏经验基础,但该模型为独角兽编造了一个合理的历史起源。
忠诚幻觉。对LLM进行了固有培训,以符合用户说明。随着LLM的使用转向更加以用户为中心的应用程序,确保其与用户提供的说明和上下文信息的一致性变得越来越重要。此外,LLM的忠实性还体现在其生成内容的逻辑一致性上。从这个角度来看,我们将忠诚幻觉分为三种亚型:
- 指令不一致。是指LLM的输出偏离用户的指令。虽然有些偏差可能符合安全准则,但此处的不一致表示与非恶意用户指令的无意不一致。如表1所示,用户的实际意图是翻译,然而,LLM错误地偏离了用户的指令,而是执行了问答任务。
- 上下文不一致。指向LLM的输出与用户提供的上下文信息不忠实的情况。例如,如表1所示,用户提到尼罗河的源头在中非的五大湖地区,但LLM的回应与上下文相矛盾。
- 逻辑不一致。强调LLM输出表现出内部逻辑矛盾时,通常在推理任务中观察到。这表现为推理步骤本身之间以及推理步骤与最终答案之间的不一致。例如,如表1所示,虽然等式两边除以2的推理步骤是正确的,但x=4的最终答案与推理链不一致,导致不正确的结果。
3 幻觉的原因
幻觉有多方面的起源,跨越了LLM能力获取过程的整个范围。在本节中,我们深入研究了LLM中幻觉的根本原因,主要分为三个关键方面:数据(§3.1),训练(§3.2)和推理(§3.3)。
3.1 数据的幻觉
培训前的数据是LLM的基础,使他们能够获得一般能力和实际知识。然而,它可能会在无意中成为LLM幻觉的来源。这主要表现在两个方面:一是数据不完善带来的潜在风险来源(§3.1.1),以及对数据中获取的事实知识的劣质利用(§3.1.2)。
3.1.1 有缺陷的数据源
虽然扩大培训前的数据大大提高了LLM的能力,在保持一致的数据质量方面出现了挑战,这可能潜在地引入错误信息和偏见。此外,数据中缺乏特定领域知识和最新事实会导致LLM形成知识边界,这对LLM在特定场景中造成了限制。在此基础上,我们将可能导致幻觉的因素初步归类为错误信息、偏见和知识边界限制。为了更全面地理解,表2中给出了每种类型的数据诱导幻觉的说明性示例。

错误信息和偏见。随着对大规模语料库需求的增加,启发式数据收集方法被用来有效地收集大量数据。在提供大量数据的同时,它们可能无意中引入错误信息,增加了模仿谎言的风险。此外,社会偏见可能会无意中引入LLM的学习过程。这些偏见主要包括重复偏见和各种社会偏见,可能导致幻觉。
- 模仿性谎言。LLM预训练的主要目的是模拟训练分布。当LLM在事实上不正确的数据上被训练时,它们可能无意中放大这些不准确性,潜在地导致事实上不正确的幻觉,被称为“模仿性谬误”。例如,如表2所示,“托马斯爱迪生发明了灯泡”这句话实际上是一个误解,随着时间的推移,人们普遍误解了它。对此类事实错误数据进行培训的LLM可能导致误导性输出。
- 复制偏差。神经网络,尤其是大型语言模型,具有记忆训练数据的内在倾向。研究进一步表明,这种记忆倾向随着模型尺寸。然而,固有的记忆能力在预训练数据中存在重复信息的情况下变得有问题。这种重复可以将LLM从概括转变为记忆,最终导致重复偏见,其中LLM过度优先考虑重复数据的回忆,并导致偏离所需内容的幻觉。在表2中,当用户请求“列出一些红色水果,不包括苹果”时,训练数据集中频繁重复的“红苹果、西瓜、樱桃和草莓”等语句的存在导致模型在输出中产生记忆过度的语句。
- 社会偏见。某些偏见与幻觉有着内在的联系,特别是与性别有关的偏见和国籍。例如,即使在用户提供的上下文中没有明确提到性别,LLM也可能会将护理职业与女性联系起来,这是第2.3节中讨论的上下文不一致性幻觉的例证。这种偏见可能无意中从基于互联网的文本中获得,这些文本充斥着不同的和有偏见的观点,并随后传播到生成的内容中。除了这些偏差,数据分布的差异也是幻觉的潜在原因。在自然界中McKenna发现,LLM倾向于通过对训练数据中确认的假设的偏见而错误地标记。
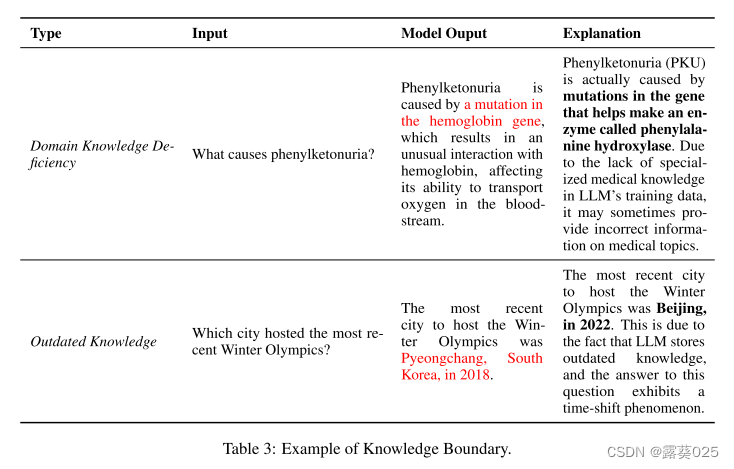
知识边界。虽然庞大的预培训语料库赋予了LLM广泛的事实知识,但他们天生就有边界。这种局限性主要表现在两个方面:缺乏最新的事实知识和专业领域知识。表3中给出了一个示例。 - 领域知识缺乏。LLM在通用领域的广泛下游任务中表现出卓越的性能。然而,鉴于这些通用LLM主要是在广泛的公开可用数据集上训练的,他们在专业领域的专业知识本质上受到缺乏专有培训数据的限制。因此,当遇到需要特定领域知识的问题时,例如医学和法律的问题,这些模型可能会表现出明显的幻觉,往往表现为事实捏造。
- 过时的事实知识。除了特定领域知识的不足之外,关于LLMs内的知识边界的另一个内在限制是它们对最新知识的有限能力。嵌入在LLM中的事实知识表现出明确的时间界限并且可以随着时间变得过时。一旦这些模型被训练,它们的内部知识就永远不会更新。鉴于我们这个世界的动态和不断旋转的性质,这构成了一个挑战。当遇到超越时间范围的问题时,LLM常常会编造事实或提供过去可能正确但现在已经过时的答案。
3.1.2 较差的数据利用率
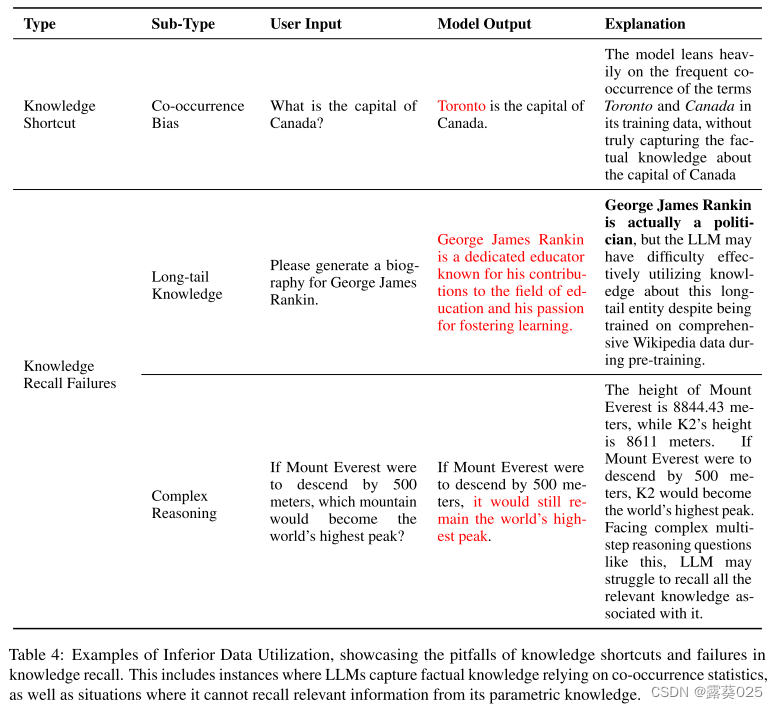
预训练数据体现了丰富的真实世界的事实知识,使LLM能够捕获并随后编码大量的事实知识在其参数内。然而,尽管有这个巨大的知识库,LLM仍然可以产生知识诱导的幻觉,由于参数知识的利用率较低。在这种情况下,我们深入研究了两个关键的挑战:捕获事实知识的虚假相关性及其在知识回忆中的斗争。表4中给出了与较差数据利用相关的每种幻觉类型的示例,以进一步说明。
知识库。虽然在探索它们的知识储存方面已经作出了重大努力和探测,LLM获取事实知识的确切机制仍然难以捉摸。最近的研究指出,LLM往往不真正理解事实知识的错综复杂,而是诉诸捷径。它们表现出过度依赖位置接近的趋势、共现统计和相关文献计数,这可能引入对伪相关性的偏差,如果偏差反映了事实上不正确的信息,则可能导致幻觉。例如,如表4所示,当查询“the capital ofCanada”时,模型错误地返回“多伦多”。这种错误可能是由于加拿大和多伦多在其训练数据中的共同出现频率较高,导致模型错误地捕获了有关加拿大首都的事实知识。
知识回忆失败。当LLM努力有效地利用他们广泛的知识时,可能会出现幻觉。我们探讨了知识召回的两个主要挑战:在召回长尾知识和困难的复杂情况下,需要多跳推理和逻辑推理的不足。
- 长尾知识 在LLM所利用的巨大知识景观中,一个值得注意的挑战以长尾知识利用的形式出现。这种长尾知识的特点是在预训练数据中相对罕见,这对LLM提出了固有的挑战,LLM主要依赖于共现模式来记忆事实知识。因此,当遇到与这种长尾知识有关的查询时,LLM面临着更高的幻觉风险,试图生成事实上不准确的响应。例如,如表4所示,当提示为维基百科训练数据中以前遇到的长尾实体生成传记时,LLM错误地将该职业归因于将政治家描述为教育家。
- 除了长尾知识带来的挑战之外,知识的有效利用与推理能力密不可分。例如,在多跳问答场景中,即使LLM拥有必要的知识,如果问题之间存在多个关联,由于其推理的局限性,它也可能难以产生准确的结果。此外,Berglund揭示了LLM中一个特定的推理失败,称为Reversal Curse。具体地说,当问题被公式化为“A是B”时,模型可以正确回答,而当被问到“B是A”时,它表现出失败的逻辑推理。这种推理上的差异超出了简单的演绎。在回收增强环境中,Liu等人强调了相关挑战。尽管在模型的上下文窗口中有包含正确答案的文档,但由于模型在有效利用所提供的证据方面的不足,该模型仍然难以生成精确的响应。如表4所示,尽管LLM认为珠峰是世界最高峰,但他们无法确定如果珠峰的海拔降低500米,哪座山将成为最高峰,这是一项需要复杂推理能力的任务。
3.1.3 摘要
LLM中与数据相关的幻觉主要源于有缺陷的数据源和低劣的数据利用率。数据源中的错误信息和固有偏见不仅传播了模仿性的错误,而且还引入了有偏见的输出,导致各种形式的幻觉。LLM中的知识边界在处理特定领域的查询或遇到快速更新的事实知识时变得明显。关于数据利用,LLM倾向于捕捉虚假的相关性,并在回忆知识,特别是长尾信息,以及复杂的推理场景中表现出困难,进一步加剧了幻觉。这些挑战突出表明,迫切需要提高数据质量和模型更有效地学习和回忆事实知识的能力。
3.2 来自训练的幻觉
LLM的训练过程主要包括两个主要阶段:
1)预培训阶段,LLM学习通用表示并捕获世界知识,以及
2)调整阶段,LLM经过调整以更好地与用户指令和偏好保持一致。虽然这个过程使LLM具有非凡的能力,但这些阶段的任何不足都可能无意中导致幻觉。
3.2.1训练前的幻觉
预训练是LLM的基础阶段,通常采用基于转换器的体系结构在庞大的语料库上进行因果语言建模。然而,与幻觉相关的问题可能来自于固有的结构设计和所采用的特定训练策略。在本节中,我们将深入研究架构缺陷带来的挑战和暴露偏差的影响。
架构缺陷。LLM通常采用遵循GPT建立的基于变换器的架构,其中他们通过因果语言建模目标来获取表示,因果语言建模目标是由诸如OPT、Falcon和美洲驼-2。尽管它取得了成功,但它并非没有陷阱,特别是关于单向表征不足和注意力故障。
其局限性 它只从一个方向利用上下文,这阻碍了它捕获复杂的上下文依赖性的能力,潜在地增加了幻觉出现的风险。
- 注意力故障。基于transformer的架构,配备了自我注意模块,在捕获远程依赖关系方面表现出了卓越的能力。然而,最近的研究已经表明,它们偶尔会在算法推理的上下文中表现出不可预测的推理错误,跨越长距离和短距离的依赖关系,无论模型规模如何。一个潜在的原因是软注意力的局限性,随着序列长度的增加,注意力在各个位置上都会被稀释。
暴露偏倚。除了架构缺陷之外,训练策略也起着至关重要的作用。值得注意的是,暴露偏倚现象,由于自回归生成模型中的训练和推理之间的差异而脱颖而出。在训练过程中,这些模型通常采用强制的最大似然估计(MLE)训练策略,其中提供地面实况标记作为输入。但是,在推理期间,模型依赖于其自己生成的标记来进行后续预测。这种不一致性可能导致幻觉,尤其是当模型生成的错误表征在整个后续序列中级联错误时,类似于滚雪球效应。
3.2.2来自对齐的幻觉
对齐通常涉及两个主要过程,监督微调和从人类反馈中强化学习,是解锁LLM功能并使其与人类偏好保持一致的关键一步。虽然对齐显著提高了LLM响应的质量,但它也引入了幻觉的风险。在本节中,我们将把与幻觉相关的对齐不足分为两部分:能力失调和信念失调。
能力失调 。考虑到LLM具有在预训练期间建立的固有能力边界,SFT利用高质量指令沿着其对应的响应,使LLM能够遵循用户的指示,在这个过程中解锁他们获得的能力。然而,随着LLM能力的扩展,一个重大的挑战出现了:LLM的内在能力和注释数据中描述的那些能力之间的潜在不匹配。当比对数据的需求超过这些预定义的能力边界时,LLM会接受训练,以产生超出其自身知识边界的内容,从而放大幻觉的风险。
信念失调。一些研究已经证明LLM的激活包含了与其生成的陈述的真实性相关的内部信念。然而,这些内部信念和生成的输出之间偶尔会出现偏差。即使当利用人的反馈来改进LLM时,他们有时会产生与他们的内部信念不同的输出。这种行为被称为阿谀奉承,强调了该模型的倾向,以安抚人类评价者,往往是以牺牲真实性为代价的。最近的研究表明,通过RLHF训练的模型表现出明显的迎合用户意见的行为。这种阿谀奉承的行为并不限于没有明确答案的模棱两可的问题,就像政治立场一样,但是当模型选择了明显不正确的答案时也会出现,尽管意识到其不准确性。深入研究这一现象,认为,阿谀奉承的根源可能在于RLHF模型的培训过程。通过进一步探讨人类偏好在这一行为中的作用,研究表明,阿谀奉承的倾向可能是由人类和偏好模型共同驱动的,偏好模型显示出对拍马屁反应的偏好高于真实反应。
3.2.3总结
在训练LLM时,基础预训练和随后的对齐都提出了可能引起幻觉的独特挑战。在训练前的阶段,架构缺陷,特别是不充分的单向表征,以及注意故障,再加上众所周知的暴露偏见,都会导致幻觉。同时,在整合阶段,也出现了能力错位和信念错位的问题。前者有可能将LLM推到他们不知道的地方。边缘边界,而后者揭示了LLM的信念和它的输出之间的差距。这些挑战强调了培训法学硕士以确保其真实性的重要性。从基础模型设计和培训策略,以符合人类的期望,它仍然是一个多方面的奋进。
3.3 来自干扰解码的幻觉
在预训练和对齐后表现LLM的能力方面起着重要作用。然而,解码策略中的某些缺陷可能导致LLM幻觉。在这一节中,我们将深入探讨解码过程中的潜在原因,强调两个关键因素:解码策略的固有随机性(3.3.1节)和不完美的解码表示(3.3.2节)。
3.3.1内在抽样随机性
LLM在生成高度创造性和多样化的内容方面表现出了非凡的才能,这种能力在很大程度上取决于随机性在其解码策略中的关键作用。随机抽样是目前这些LLM所采用的主要解码策略。将随机性纳入解码策略的基本原理源于这样的认识,即高似然序列通常会导致令人惊讶的低质量文本,这被称为似然陷阱。解码策略中的随机性所引入的多样性是有代价的,因为它与幻觉风险的增加正相关。采样温度的升高导致更均匀的令牌概率分布,从而增加了从分布的尾部对具有较低频率的token进行采样的可能性。因此,这种对不经常出现的记号进行采样的高度倾向加剧了幻觉的风险。
3.3.2不完美的解码
表示在解码阶段,LLM使用其toplayer表示来预测下一个token。然而,顶层表示有其局限性,主要表现在两个方面:上下文注意力不足和Softmax瓶颈。
上下文注意不足。先前的研究,特别是在像机器翻译的领域中的研究和总结已经突出了在采用编码器-解码器体系结构的生成模型中的过度置信的问题。这种过度自信源于对部分生成的内容的过度关注,通常以忠实地遵守源上下文为代价来优先考虑流利性。虽然主要采用因果语言模型架构的大型语言模型已经获得了广泛的使用,但过度自信现象仍然持续存在。在生成过程中,下一个单词的预测取决于语言模型上下文和部分生成的文本。然而,如先前的研究,语言模型经常在它们的注意机制内表现出局部化的焦点,优先考虑附近的单词并导致上下文注意的显著不足。此外,这种担心在有产生冗长和全面反应倾向的LLM中得到进一步放大。在这种情况下,甚至存在对遗忘指令的风险的更高的敏感性。这种注意力不足会直接导致忠实幻觉,其中模型输出的内容偏离了原始上下文。
Softmax瓶颈。大多数语言模型利用在语言模型内的最后层的表示上操作的softmax层,结合单词嵌入,来计算与单词预测相关联的最终概率。然而,基于Softmax的语言模型的功效受到称为Softmax瓶颈的公认限制的阻碍,其中与分布式字嵌入相结合的softmax的使用被限制在给定阻止LM输出期望分布的上下文的情况下输出概率分布的表达性。此外,发现,当输出单词嵌入空间内的期望分布呈现出多种模式时,语言模型在准确地将所有模式中的单词优先排序为下一个单词时面临挑战,这也引入了幻觉的风险。
3.3.3总结
在解码阶段,挑战来自固有的解码策略和用于预测的表示。前者强调其解码算法中的随机性,随着随机性的增加,可能成为幻觉的来源。而在表示方面,过度依赖附近内容和softmax瓶颈等问题可能会限制模型表达不同输出概率的能力,从而导致令牌预测不准确的风险。这些复杂性强调了在整个解码过程中保持真实性和忠实性的必要性。
4 幻觉检测和基准
LLM所展示的幻觉由于其对模型可靠性和现实世界部署的影响而引起了大量关注。随着模型越来越擅长生成类似人类的文本,区分准确和虚幻的内容成为一个关键问题。两个主要方面涵盖了幻觉缓解的广泛范围:检测机制和评估基准。本节将深入探讨检测幻觉的最新技术(第4.1节)和评估其威力的基准(第4.2节)。
4.1 幻觉检测
检测LLM中的幻觉对于确保所生成内容的可靠性和可信度至关重要。传统的衡量标准主要取决于单词重叠,无法区分似是而非和幻觉内容之间的细微差异。这样的挑战突出了针对LLM幻觉的更复杂检测方法的必要性。鉴于这些幻觉的不同性质,检测方法也相应地不同。因此,在本节中,我们提供了一个全面的概述初级幻觉检测策略,针对真实性和忠诚性幻觉。
4.1.1 幻觉检测
Chen和Shu的研究强调了人类在识别ChatGPT产生的错误信息方面面临的挑战,导致越来越多的研究旨在设计检测方法目标事实性幻觉。在这种情况下,我们提出了一个概述,建立的方法,通常分为外部因素和不确定性估计。

检索外部事实。为了有效地指出LLM输出中的事实错误,一种直观的策略涉及将模型生成的内容与可靠的知识源进行比较,如图3所示。这种方法与事实核查任务的工作流程紧密一致。然而,传统的事实核查方法通常包含简化的实用性假设,在应用于复杂的现实世界场景时会导致差异。认识到这些限制,Chen等人更加强调了现实世界的场景,其中证据是从时间受限的、未经策划的网络资源中获取的。他们开创了一个集成了多个组件得全自动化管道:索赔分解,原始文档检索,细粒度检索,以索赔为中心得摘要以及准确性分类.Galitsky(2023)进一步解决了潜在冲突检索证据的情况,方法是找到最少失败的权威来源并避免最多失败的来源。此外,Min等人(2023年)引入了FACTSCORE,这是一种专门用于长格式文本生成的细粒度事实度量。它将生成内容分解为原子事实,然后计算由可靠知识源支持的百分比。最近,Huo等人(2023)通过查询扩展增强了检索幻觉检测支持证据的标准方法。通过在检索过程中将原始问题与LLM生成的答案相结合,他们解决了主题漂移问题,确保检索到的段落与问题和LLM的回答保持一致。从更广泛的角度来看,Chern等人(2023)提出了一个统一的框架,使LLM能够通过利用一套外部工具来收集证据来检测事实错误。
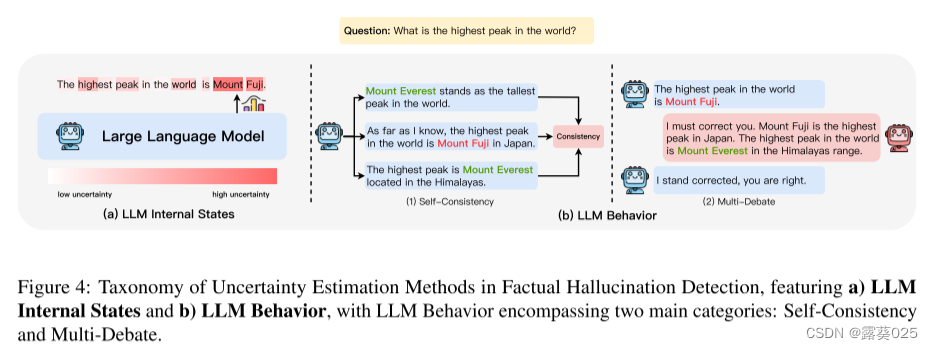
不确定性估计。虽然许多幻觉检测方法依赖于外部知识源来进行事实检查,但已经设计了几种方法来解决零资源环境中的问题,从而消除了检索的需要。这些策略背后的基本前提是LLM幻觉的起源与生俱来地与模型的不确定性有关。因此,通过估计模型产生的事实内容的不确定性,检测幻觉变得可行。不确定性估计的方法大致可以分为两种方法:基于内部状态的方法和基于LLM行为的方法,如图4所示。前者在假设可以访问模型的内部状态的情况下运行,而后者则推广到更受约束的环境,仅利用模型的可观察行为来推断其潜在的不确定性。
- LLM内部状态。LLM的内部状态可以作为其不确定性的信息指示符,通常通过像令牌概率或熵这样的度量来表现。Varshney等人(2023)通过考虑这些概念中的最小标记概率,确定了模型对关键概念的不确定性。其基本原理是,低概率可作为模型不确定性的有力指标,而概念中出现的较高概率表征的影响较小。类似地,Luo等人(2023 a)采用了一种基于自我评估的方法来进行不确定性估计,其基本原理是,语言模型能够熟练地从其生成的解释中重构原始概念,这表明了其对该概念的熟练程度。通过最初提示模型生成给定概念的解释,然后采用约束解码来使模型基于其生成的解释重新创建原始概念,来自响应序列的概率得分可以用作概念的熟悉度得分。此外,Yao等人(2023 a)通过对抗性攻击的透镜解释了幻觉。他们利用基于梯度的标记替换,设计了诱导幻觉的提示。值得注意的是,他们观察到,与对抗性攻击相比,从原始提示生成的第一个令牌通常表现出低熵。基于这一观察结果,他们提出设置熵阈值来定义这种幻觉攻击。
- LLM行为。然而,当系统只能通过API调用访问时,可能无法访问输出的令牌级概率分布。考虑到这一限制,一些研究已经将重点转移到探索模型的不确定性,或者通过自然语言提示或通过检查其行为表现。例如,Manakul et al.(2023)通过对LLM对同一提示的多个反应进行采样,通过评估事实陈述之间的一致性来检测幻觉。然而,这些方法主要依赖于直接查询,这些直接查询显式地请求来自模型的信息或验证。Agrawal等人(2023年)受调查性访谈的启发,主张使用间接询问。与直接提问不同的是,这些间接提问者往往提出开放式问题,以获取具体信息。通过使用这些间接查询,可以更好地评估跨多个模型生成的一致性。除了从单个LLM的多个代的自一致性评估不确定性之外,还可以通过加入额外的LLM来包含多主体的观点。从法律的交叉询问实践中汲取灵感,Cohen等人(2023)引入了LMvLM方法。该策略利用“审查者”LM来询问"被审查者“LM,旨在揭示多轮交互期间的声明不一致性。
4.1.2忠实性幻觉检测
确保LLM提供上下文或用户指令的忠实性对于其在无数应用中的实际效用至关重要,从总结交互式对话系统。忠实性幻觉检测主要关注于确保生成的内容与给定的上下文保持一致,避免无关或矛盾输出的潜在陷阱。在这一小节中,我们探索了检测LLM代中不忠的方法,并在图5中提供了概述。
基于事实的调查 在评估忠实性的领域中,最直观的方法之一涉及测量生成内容和源内容之间的关键事实的重叠。考虑到事实的不同表现形式,度量可以基于实体、关系三元组和知识进行分类。
- 基于N-gram的。当把源内容作为参考时,传统的基于n元语法重叠的评价指标,如Rouge和Parent-T,也可以用来评估忠诚度。然而,由于语言表达的自然多样性及其对表层匹配的依赖,这些指标与人类的相关性较差。
- 基于知识。摘要任务中普遍采用基于实体重叠的度量,因为这些关键实体的任何遗漏或不准确生成都可能导致不真实的摘要。Nan等人(2021年)引入了一种量化实体幻觉程度的指标,该指标计算了摘要中命名实体与源实体的精确度。
- 基于关系。注意,即使实体匹配,它们之间的关系也可能是错误的。因此,古德里奇等人(2019)专注于关系元组的重叠,并引入了一个度量,该度量计算使用训练的端到端事实提取模型提取的关系元组的重叠。
- 基于知识。同样,对于以知识为基础的对话任务,事实往往与对话中呈现的知识相对应。Shuster等人(2021)引入了知识F1指标,以评估模型的生成与所提供知识的一致性。
基于分类器 除了计算事实重叠之外,评估模型的忠实度的另一种直接方法涉及利用分类器,该分类器被训练为包括任务特定的幻觉和忠实内容,以及来自相关任务的数据或合成生成的数据。它可以大致分为以下几种类型:
- 基于蕴涵。在使用自然语言推理(NLI)来评估生成文本的忠实性时,一个流行的概念是基于这样的想法,即真正忠实的内容应该固有地由其源内容所包含。与此相一致的是,许多研究已经在NLI数据集上训练了分类器来识别事实上的不准确性,尤其是在摘要摘要的背景下。但是,Mishra等人(2021)强调,传统NLI数据集和不一致性检测数据集之间的输入粒度不匹配限制了其有效检测不一致性的适用性。在此基础上,更先进的研究提出方法,例如对对抗性数据集进行微调,在依存关系弧级分解蕴涵决定,将文档分割成句子单元,然后聚合句子对之间的得分。这些集体努力强调了提高幻觉检测准确性的潜力。
- 每周监督。虽然使用来自相关任务的数据来微调分类器在评估忠实度方面显示出了希望,但认识到相关任务与下游任务之间的内在差距是至关重要的。注释数据的稀缺性进一步限制了其适用性。为了应对这一挑战,Kryscinski等人(2020)分析了尖端概括模型造成的误差,并引入了一种方法,使用基于规则的转换来创建弱监督数据,以微调分类器。同时,Zhou等人(2021)设计了一种自动生成表征级幻觉数据并执行表征的方法水平幻觉检测。在Kryovski等人的工作的基础上,Dhani等人(2021年b)利用扰动方法生成对抗性合成数据,旨在增强基于知识的对话任务中的幻觉检测,而Santhanam等人(2021年)则关注对话领域的事实一致性。
基于问答的指标。与基于分类器的度量相比,基于QA的度量最近因其捕获模型的生成和其源之间的信息重叠的增强能力而受到关注。这些度量通过从LLM的输出内的信息单元中最初选择目标答案来操作,然后由问题生成模块生成问题。这些问题随后被用于基于用户上下文生成源答案。最后,通过比较源答案和目标答案之间的匹配分数来计算LLM的回答的忠实度。虽然这些方法不同的学科都有一个共同的主题方法,它们在答案选择、问题生成和答案重叠等方面表现出可变性,导致不同的绩效结果。在这项基础工作的基础上,Fabbri等人(2022)对基于QA的指标中的组件进行了深入评估,进一步增强了忠诚度评估。
不确定性估计。根据第4.1.1节的见解,条件文本生成中的幻觉与高模型不确定性密切相关。不确定性估计在贝叶斯深度学习中得到了广泛的研究。从贝叶斯的角度来看,预测的总不确定性由输出分布的预测熵来表征。此外,一些工作试图使用对数概率来量化模型的不确定性。基于这些原理,我们将现有的通过不确定性估计进行幻觉检测的方法分为以下类型:
- 基于熵。观察到数据到文本生成中的幻觉可能性与预测不确定性之间的正相关性,预测不确定性由深度集合估计利用Monte Carlo Dropout产生的假设方差作为神经机器翻译(NMT)中的不确定性度量。最近,货车der Poel等人(2022)采用了条件熵,以评估抽象总结中的模型不确定性。
- 基于对数概率。Guerreiro等人(2023a)使用长度归一化序列对数概率来衡量模型置信度。
- 基于模型。Miao等人(2023)通过使用SelfCheck(一种逐步检查器,用于评估LLM中的每个推理步骤)来集中研究复杂推理中的错误检测。该系统通过目标提取、信息收集、步骤再生和结果比较的简化过程来汇总置信度分数,从而提高问答准确性。
基于网络的度量
最近,LLM显著的指令遵循能力强调了其自动评估的潜力。利用这种能力,研究人员已经冒险进入用于评估模型生成的内容的忠实性的新颖范例。通过向LLM提供具体的评估指南,并向他们提供模型生成的内容和源内容,他们可以有效地评估忠诚度。最终的评估输出可以是对忠实性的二元判断或指示忠诚度的k点Likert度量。对于提示选择,评估提示可以是直接提示、思路链提示,使用上下文学习或允许模型产生伴随解释的评估结果。
4.2 基准
在本节中,我们全面概述了现有的幻觉基准,这些基准可以分为两个主要领域:幻觉评估基准(§4.2.1),用于评估现有尖端LLM产生的幻觉程度,以及幻觉检测基准(§4.2.2),专门用于评估现有幻觉检测方法的性能。总的来说,这些基准建立了一个统一的框架,使LLM的幻觉模式的细致入微和彻底的探索。
4.2.1 幻觉评估基准
幻觉评估基准旨在评估LLM产生幻觉的倾向,特别强调识别事实不准确和测量与原始上下文的偏差。目前,这些基准的主要重点是评估LLM生成内容的真实性。虽然大多数都是以问答形式组织的,但他们的主要重点仍然是LLM的真实性。他们独特的特征源于他们所选择的知识领域,语言和响应格式。我们在下面详细介绍了最具代表性的基准,并同时提供了对常见LLM性能的评估这些基准的要求(§A)。
真实的QA。TruthfulQA由817个问题组成,涵盖健康、法律、金融和政治等38个不同类别,是一项专门用于评估语言模型真实性的基准测试。它采用了对抗性方法,旨在引出“模仿性谎言”–由于模型频繁出现在训练数据中,可能会产生误导性反应。该性能指标评测分为两部分,其中一部分包含手动策划的问题,这些问题通过筛选GPT-3正确回答的问题而得到进一步优化,最终得到437个筛选问题。另一部分包括380个未过滤的非对抗性问题。在评估方面,TruthfulQA提供了两种类型的问题回答任务:生成和多项选择,并采用人工评估来衡量模型的真实性和信息量。此外,该性能指标评测还引入了一个名为GPT-judge的自动度量,该度量在6.7B GPT-3模型上进行了微调。
REALTIMEQA。由于世界知识是不断发展的,因此,如何验证逻辑学习模型对当前世界的真实性就成为一个关键问题。该基准测试提供了从新发布的新闻文章中提取的实时开放域多项选择题,涉及政治、商业、体育和娱乐等多个主题。此外,该性能指标评测还提供了一个用于实时评估的平台,可以通过按准确性评估的多选格式,也可以通过使用精确匹配和基于令牌的F1指标评估的生成设置。
Med-HALT。鉴于幻觉在医疗领域对病人护理的严重后果,意识到了具体到医学领域的LLM的挑战。Med-HALT结合了来自不同国家的多项选择问题,专门用于评估LLM在医学背景下的推理和记忆能力。推理任务有18,866个样本,测试了LLM使用多项选择医学问题区分不正确或不相关选项和虚假问题的能力。同时,包括4,916个样本的记忆任务通过从PubMed摘要/标题生成链接或从给定链接和PMID生成标题来评估LLM回忆和生成准确事实信息的能力。对于评估,LLM的表现是通过他们在测试问题上的准确性来衡量的,或者通过一个点态分数来衡量,该分数考虑了正确答案的积极分数和不正确答案的消极惩罚。
因子。为了定量评估LM的真实性,Muhlgay等人(2023)引入了一种方法,该方法通过扰动指定语料库中的事实陈述来自动创建基准。产生两个基准:Wiki-FACTOR和News-FACTOR。具体地,对于给定的前缀文本,来自语料库的原始完成用作事实上正确的答案。然后,InstructGPT将在包含特定错误类型的提示的指导下生成非事实性的完成。这些生成的回答随后被过滤以获得流畅性和自我一致性,作为多项选择任务的基础。为了评估,LM的真实性通过模型产生真实正确的完成的可能性是否超过产生其他非真实完成的可能性来衡量。
中国事实评估。ChineseFactEval从常识、科学研究、医学、法律、金融、数学和中国近代史等多个领域收集问题,采用125个问题对6位当代中国法学硕士的事实能力以及GPT-4进行了评估。为了进行评估,根据不同的LLM所达到的准确性对问题进行分类,并为不同难度的问题分配不同的分数。来自所有LLM的响应主要由人注释,并由FacTool补充(Chern等人,2023年)。然后,使用LLM的最终分数来评估其真实性。
HalluQA。图纸来自TruthfulQA的施工方法(Lin等人,2022),HalluQA专门评估中国大语言模型中的幻觉,重点是模仿性错误和事实错误。该基准测试包括30个领域的450个手工设计的对抗性问题,分为两个部分。误导部分捕获了成功欺骗GLM-130 B的问题,而知识部分保留了ChatGPT和Puyu一贯回答错误的问题。为了进行评估,LLM生成对这些问题的回答,然后使用GPT-4将其与正确答案进行比较,以确定答案是否包含幻觉。
FreshQA。认识到幻觉可能部分地由经验学习理论中过时的知识引起,引入基准来评估现有经验学习理论的真实性。该基准包括600个手工编制的问题,这些问题的答案可能会随着时间的推移而变化,或者其前提事实上是不正确的。该基准主要评估法律硕士对快速变化的知识的才能,以及他们识别错误前提问题的能力。对于评估,基准测试提供了两种模式的评估过程:RELAXED(仅评估主要答案的正确性)和STRICT(进一步评估答案中每个事实的准确性)。在这两种模式中,LLM的真实性由其响应的准确性来反映,如通过人工注释所确定的。
4.2.2 幻觉检测基准
对于幻觉检测基准,大多数先前的研究主要集中在任务特异性幻觉上,例如抽象概括,数据到文本,以及机器翻译。然而,在这些研究中产生的内容通常源自具有较小能力的模型,例如BART和PEGASUS。因此,它们可能无法准确地反映幻觉检测策略的有效性。因此,这些研究不属于我们目前讨论的范围。
SelfCheckGPT-Wikibio。Miao等人(2023)基于WikiBio数据集的概念,通过使用GPT-3生成合成维基百科文章,引入了句子级幻觉检测数据集。这些段落的真实性,然后手动注释的时态水平,共生成238篇文章的1908句句子。
HaluEval。为了评估LLM在识别幻觉方面的能力,HaluEval是通过自动生成和人工注释的组合构建的,产生了5,000个与ChatGPT响应配对的一般用户查询和30,000个特定任务样本。自动生成采用了“采样-然后过滤”的方法。该基准测试基于来自问题回答、基于知识的对话和文本摘要的特定任务数据集,首先使用ChatGPT根据任务相关的幻觉模式对多方面的幻觉答案进行采样,然后通过ChatGPT选择最合理的幻觉样本。对于人工注释,ChatGPT处理来自羊驼的查询,以采集多个响应,然后手动评估是否存在幻觉内容。
竹子。在Li等人(2023c)提出的方法基础上,该基准引入了两个新的数据集,SenHallu和AbsHallu,旨在检测长文本背景下的幻觉。这些数据集是通过诱导ChatGPT产生给定学术论文的幻觉而构建的,分别产生200个样本。
FELM。与以前主要集中在诸如总结之类的特定任务上的研究不同(Fabbri等人,2021年; Tang等人,2022)或诸如世界知识的特定领域(Miao等人,2023年),该基准评估了五个领域的真实性:世界知识、科学和技术、数学、写作和推荐以及推理。虽然早期的研究有意地诱导LLM基于特定模式产生幻觉(Li等人,2023 c),该基准测试采用ChatGPT在零触发设置下生成响应,总共产生817个样本(包括3948个片段)。每个段都标注了真实性、错误原因、错误类型和外部引用。作为事实性检测器的测试平台,该基准测试采用F1评分和平衡分类准确度来评估细分和响应级别的事实性错误。
PHD。该基准并不侧重于句子级的幻觉检测,而是强调段落级的检测。基准的构建始于从Wikipedia转储中提取实体,然后使用ChatGPT生成段落。认识到当LLM缺乏足够的知识时,往往会出现真实性错误,基准测试根据Google搜索返回的相关条目的数量选择实体。这种分类导致三个不同的组:PHD-低、PHD中和PHD-高。从每个类别中,抽取100个实体,然后在段落级别上进行人工注释,如事实,非事实或无法验证。在评估过程中,基准采用精确度,召回率和F1措施来评估检测非事实段落的方法的有效性。
屏幕评估。ScreenEval基准测试基于主要关注短文档的现有研究,将范围扩展到长格式对话中的事实不一致性。基于SummScreen数据集(Chen等人,2022 a),该基准测试在句子级为Longformer和GPT-4生成的摘要引入了事实不一致性注释,得到了一个包含52个文档和624个摘要句子的数据集。至于评价,幻觉检测方法在该基准上使用AUROC评分进行评价。
RealHall。该基准的构建遵循以下原则:幻觉检测基准内的任务应该对LLM提出实质性挑战,并与现实世界的应用相关,同时确保多样性的广度。与此相一致,基准集中在问答任务上,根据提示中参考文本的可用性将其分为封闭和开放组。基准测试中的每个问题最初都使用ChatGPT来生成响应,随后通过人工注释、GPT 4评估和基于规则的自动评估的组合方法为响应分配布尔地面实况标签。应用于该基准的幻觉检测方法的功效使用AUROC评分来量化。
LSum。基准测试的中心是在由LLM承担的摘要任务中检测事实一致性。基于XSum构建(Narayan等人,2018年),基准涉及使用各种LLM生成摘要,来自GPT系列,GLM系列和LLaMA通过使用ChatGPT和GPT 4在句子水平上注释事实一致性,总共产生6,166个注释摘要。
SAC。该基准测试由两个数据集组成:HotpotQA-halu和NQopen-halu。这些数据集是通过从HotpotQA的训练集中抽样250个例子来构建的(Yang等人,2018 b)和NQ开放(Kwiatkowski等人,2019年)。然后使用gpt-3.5turbo生成幻觉答案。然后,对答案进行人工注释,其中包括将其与地面真相和相关知识来源进行比较。
5 减轻幻觉
在本节中,我们提出了一个全面的审查当代方法,旨在减轻幻觉LLM。我们从《幻觉的原因》(§3)中讨论的观点出发,根据幻觉的根本原因对这些方法进行了系统的分类。具体而言,我们关注的是解决数据相关幻觉(§5.1)、培训相关幻觉(§5.2)和推理相关幻觉(§5.3)的方法,每种方法都提供了量身定制的解决方案,以应对各自原因所固有的特定挑战。
5.1数据相关幻觉
通常是偏见、错误信息和知识差距的副产品,这些因素从根本上植根于训练数据。在这种情况下,我们探索各种策略来减轻这种幻觉,旨在尽量减少错误信息和偏见的发生,同时还提供知识增强和提高知识的有效利用LLM。
5.1.1 减少错误信息和偏见
为了减少错误信息和偏见的存在,最直观的方法是收集高质量的事实数据,以防止引入错误信息,并进行数据清理以消除偏见。
事实数据增强.保持训练数据的事实正确性在减轻诸如模仿性虚假的问题中是至关重要的(Lin等人,2022年)。最直接的方法是对预训练数据集进行手动管理。早在GPT-2出现时,拉德福等人(2019)强调了专门抓取经过人类专家严格管理和过滤的网页的重要性。然而,随着预训练数据集的不断扩展,手动管理成为一个挑战。鉴于学术或专业领域的数据通常都是真实准确的,因此收集高质量的数据成为了一项主要策略。值得注意的例子包括桩(Gao等人,2021)和“教科书式”数据源(Gunasekar等人,2023年; Li等人,2023 f)。另外,在预训练阶段期间对事实数据进行上采样已被证明在增强LLM的事实正确性方面是有效的(Touvron等人,#20320;,从而缓解幻觉。
德拜斯。预训练数据中的偏差通常可以分为两大类:重复偏差和社会偏差,每一类都需要不同的去偏差方法。
- 复制偏差。重复数据删除是预培训阶段的一个关键步骤。现有的做法通常分为两类:完全重复和近似重复。对于完全重复的字符串,最直接的方法是进行完全子字符串匹配,以识别相同的字符串。然而,给定大量的预训练数据,该过程可能是计算密集型的。此外,一种更有效的方法利用后缀数组的构造(Manber和Myers,1993),使得能够在线性时间内有效地计算大量子串查询。关于近似重复,识别通常涉及近似全文匹配,通常利用基于散列的技术来识别具有显著ngram重叠的文档对。此外,MinHash(Broder,1997)作为用于大规模重复数据删除任务的流行算法而脱颖而出(Gyawali等人,2020年)。此外,SemDeDup(Abbas等人,2023)利用来自预训练模型的嵌入来识别语义重复,语义重复指的是具有语义相似性但不完全相同的数据对。
- 社会偏见。鉴于预训练数据的庞大性和不可测性,直接解决社会偏见的根本原因是一项艰巨的挑战(费拉拉,2023)。因此,当前的主流解决方案严重依赖于精心策划的培训语料库。通过精心挑选多样化、均衡、有代表性的通过使用代表性的训练数据,我们可以减轻偏差(Paullada et al.,2021年; Narayanan Venkit等人,2023年; Ladhak等人,#20203;可能会引发幻觉。此外,还引入了工具包(Viswanath和Zhang,2023),使用户能够消除现有模型和自定义模型的偏差。
5.1.2 减少知识边界
受训练数据的覆盖范围和时间边界的约束,不可避免地形成知识边界,带来了显著的挑战。为了应对这些挑战,两种流行的方法得到了极大的关注。一种是知识编辑(Sinitsin et al.,2020; Yao等人,2023 c),其目的是直接编辑模型参数,以弥合知识差距。另一种是通过检索增强生成(RAG)利用非参数知识源(刘易斯等人,2020 b; Guu等人,2020年; Shuster等人,2021年)。
知识编辑。知识编辑De Cao et al.(2021); Sinitsin et al.(2020)已经引起了研究人员越来越多的关注,其目的是通过整合额外的知识来矫正模型行为。当前的知识编辑技术可以修复事实错误并刷新过时的信息以减轻知识差距,这可以被分类为两类:通过修改模型参数或使用外部模型插件来改变模型的行为,其中原始模型被冻结(Yao等人,2023 c)。
-
修改模型参数。这些技术直接将知识注入到原始模型中,导致模型输出的实质性改变,这可以进一步分为定位然后编辑方法和元学习方法。
定位然后编辑方法(Dai等人,2022 a; Meng等人,2022)由两个阶段组成,首先定位模型参数的“错误”部分,然后对它们应用更新以改变模型的行为。例如,罗马(Meng等人,2022)通过破坏并随后恢复激活来定位编辑相关层,然后以编辑知识的定向方式更新FFN的参数。MEMIT(Meng等人,2023)采用了与罗马相同的知识定位方法,使多个层次的并发更新,以方便对知识的定位数千种编辑知识的同步整合。然而,Yao等人(2023c)发现这些方法缺乏非平凡的泛化能力,并且对不同的模型架构具有不同的性能和适用性。性能最好的方法罗马(Meng等人,2022)和MEMIT(Meng等人,2023)经验上仅在仅解码器LLM上工作良好。
元学习方法 训练外部超网络以预测原始模型的权重更新。然而,元学习方法通常需要额外的训练和存储器成本,需要专门的设计来减少LLM时代的超网络的大小(例如,低秩分解(Mitchell等人,2022 a))。虽然这些方法可以细粒度地调整模型的行为,但对参数的修改可能对模型的固有知识产生潜在的有害影响。 -
保留模型参数。一系列研究不是直接修改模型参数,而是将额外的模型插件应用到原始模型中,以实现模型行为的所需更改。SERAC(Mitchell等人,2022 b)采用范围分类器来将与存储在外部编辑存储器中的新知识相关联的输入路由到反事实模型,这可以帮助基础模型处理更新的信息。
与整个模型相比,存在涉及并入附加参数层(例如,适配器层(Hartvigsen等人,2022))作为插件插入原始模型。T-Patcher(Huang等人,2023 d)和NKB(Dai等人,2022 b)都将补丁添加到FFN层中,FFN层被确认为存储知识的库(Geva等人,#20201;纠正错误。CALINET(Dong等人,2022)提出了一种用于识别PLM中错误知识的评估方法,并通过引入类似FFN的存储槽来调整FFN的输出,这有利于缓解知识缺口。这些方法需要额外的步骤来训练参数模块,精心设计训练函数和结构,以促进插件在更新的知识中发挥作用,同时保持由原始模块处理的未编辑事实。知识编辑方法可以有效地引入知识,在一定程度上缓解模型的知识缺口。然而,知识编辑的影响仍有提高的余地。(Zhong等人,2023 b)提出了MQUAKE来评估注入知识的泛化,并发现编辑后的模型可以成功地回忆编辑后的事实,但在复杂的多跳问题中失败。也有一些研究(Wu等人,2023; Wang等人,2023 e),这表明现有的编辑方法表现出有限的跨语言泛化能力。此外,Pinter和Elhadad(2023)认为,知识编辑技术在试图减轻LLM的幻觉时会给用户带来潜在风险,并建议使用包含明确知识的方法(例如检索增强方法)。
检索增强。减轻知识差距的直观方式是检索扩增生成(RAG)(刘易斯等人,2020 b; Guu等人,2020年; Shuster等人,2021),在生成过程中,通过对从外部知识源检索的相关文档进行调节,使LLM成为基础。典型地,RAG遵循检索-读取流水线,其中相关的上下文文档首先由检索器检索(Karpukhin等人,2020),然后由生成器根据输入文本和检索到的文档两者来生成所需的输出。我们将使用检索增强来减轻幻觉的方法分为三种类型,包括一次性检索、迭代检索和事后检索。
- 一次性检索。一次检索的目的是将一次检索所获得的外部知识直接前置到学习资源管理者的提示中。Ram et al.(2023)引入了Incontext RALM,它需要一种简单而有效的策略,将所选文档预先添加到LLM的输入文本中。实证结果表明,在不同规模的语料库和不同的语料库中,语境中的RALM的使用都能持续地提高学习绩效。值得注意的是,排名机制的结合已被证明可以进一步放大性能增益。
除了传统的知识库,如维基百科,正在进行的研究努力探索替代途径,特别是知识图(KG)的利用。这些KG充当促进LLM的关键工具,促进它们与最新知识的交互,并引出强大的推理途径(Wen et al.,2023; Qi等人,2023年; Baek等人,2023年)。Varshney et al.(2023)介绍了参数知识指导(PKG)框架,增强了具有特定领域知识的LLM。PKG采用可训练的背景知识模块,将其与任务知识对齐并生成相关的上下文信息。PKG的有效性突出了通过整合检索到的背景知识来提高LLM的忠诚度的潜力。 - 迭代检索。然而,当面对复杂的挑战,如多步推理时和长式问答,传统的一次性检索可能会有所不足。
为了满足这些苛刻的信息需求,最近的研究提出了迭代检索,它允许在整个生成过程中不断收集知识。一个新兴的研究方向努力通过将这些复杂的任务分解为更易于管理的子任务来解决这些复杂的任务。认识到思维链提示在多步推理中给LLM带来的实质性进步Wei et al.(2022),许多研究尝试在每个推理步骤中融入外部知识,并进一步指导基于正在进行的推理的检索过程,减少推理链中的事实错误。在思维链提示的基础上,Press等人(2022)引入了自我提问。与传统的连续的、未描述的思维链提示不同,自我提问在每一步都描述了它打算解决的问题,随后结合了基于后续问题的搜索动作是的。Feng et al.(2023 b)和Shao et al.(2023)都采用了迭代检索生成协作框架,而不是仅仅依赖于提示检索指导的思想链,其中模型的响应作为一个有洞察力的上下文来获取更多相关知识,随后在后续迭代中细化响应。除了多步推理任务之外,Jiang等人(2023)将重点转移到长形式生成。他们提出了一个主动检索增强生成框架,该框架迭代地将即将到来的预测视为检索相关文档的查询。如果预测包含低置信度的标记,则句子经历再生。除了使用迭代检索来改进中间代,Zhang等人(2023 e)提出了MixAlign,它使用基于模型的指导迭代地细化用户问题并寻求用户的澄清,最终增强了问题和知识之间的一致性。 - 事后检索。除了传统的先检索后阅读的模式,一系列的工作已经深入到事后检索,通过后续的基于检索的修订来精炼LLM输出。为了提高LLM的可信度和归属性,Gao et al.(2023 a)采用了研究-然后-修订的工作流程,该流程首先研究相关证据,然后根据检测到的与证据不符的情况修改初始生成。类似地,Zhao等人(2023 a)引入了verify-andedit框架,通过合并外部知识来提高推理链的事实准确性。对于一致性低于平均水平的推理链,框架会生成验证问题,然后根据检索到的知识细化推理,确保做出更符合事实的回答。Yu等人(2023 d)通过不同的答案生成增强了事后检索方法。他们不是只生成一个答案,而是对各种可能的答案进行采样,从而获得更全面的检索反馈。此外,通过采用在检索之前和之后考虑答案的可能性的集成技术,它们进一步减轻了误导性检索反馈的风险。
5.1.3减少知识冗余
当LLM依靠虚假的相关性(例如预训练语料库的共现统计数据)来捕获事实知识时,知识捷径就会出现。Kang和Choi(2023)建议对通过排除有偏样本构建的去偏数据集进行微调。虽然这会导致当更多的样本被排除时,对频繁事实的回忆会显着下降,但当在微调过程中看不到罕见事实时,这种方法很难概括。
5.1.4减轻知识回忆
失败LLM中幻觉的普遍来源是他们无法准确检索和应用嵌入其参数知识中的相关信息。在信息完整性至关重要的复杂推理场景中,这一挑战尤其严峻。通过增强知识回忆,我们可以更好地将模型的输出锚到可验证的知识,从而提供更强大的防御来防止产生幻觉内容。通常,最直接的方法来回忆知识是使LLMs能够通过思路链提示进行推理。Zhong等人(2023b)认为,简单地应用CoT可以提高知识回忆,这大大提高了在多跳设置下编辑事实的性能。Zheng et al.(2023)认为,直接用相关信息补充问题可以增强模型回忆关键知识的能力,而不是整合推理步骤。Wang等人(2023g)采用概念化的方法推进了这一点,概念化将原始的常识知识提炼成高级抽象知识,从而提高了知识的回忆率。
5.2减轻与培训相关的幻觉
与培训相关的幻觉通常源于LLM所采用的架构和培训策略的内在局限性。在这种情况下,我们讨论了各种优化方法,包括训练阶段(§5.2.1)和对齐阶段(§5.2.2),旨在减轻训练过程中的幻觉。
5.2.1 减轻预训练相关的幻觉
为了解决预训练相关的幻觉,大多数研究强调探索新的模型架构和改进预训练目标。
缓解有缺陷的模型架构。减轻预训练相关幻觉的一个重要研究途径集中在模型架构固有的局限性上,特别是单向表示和注意力故障。有鉴于此,许多研究已经深入研究设计专门针对这些缺陷的新型模型架构。
- 缓解单向表示。为了解决单向代表中固有的局限性,介绍了采用双向自回归方法的BATGPT。这种设计允许模型基于所有先前看到的令牌预测下一个令牌,同时考虑过去和未来的上下文,从而捕获两个方向的依赖关系。基于这一想法,Liu等人(2023 e)强调了编码器-解码器模型更好地利用其上下文窗口的潜力,为未来的LLM架构设计提出了一个有希望的方向。
- 减轻注意力故障。认识到软注意力在基于自我注意力的架构中的局限性,Liu et al.(2023a)提出了注意力锐化正则化器。这种即插即用的方法使用可微损失项来稀疏化自我注意力架构(Zhang等人,2018),以促进稀疏,导致推理幻觉显着减少。
缓解次优预训练目标
在LLM的预训练阶段,目标的选择在确定模型的性能方面起着关键作用。然而,传统的目标可能会导致模型输出的碎片化表示和不一致。最近的进展试图通过改进预训练策略,确保更丰富的上下文理解和规避偏见来应对这些挑战。本节阐明了这些开创性的方法,包括新的培训目标和努力,以抵消暴露偏见。
- 培训目标。为了解决训练LLM的固有局限性,即由于GPU内存限制和计算效率,文档级的非结构化事实知识经常被分块,导致信息碎片化和实体关联不正确,Lee等人(2022b)引入了一种事实增强训练方法。该方法通过在事实文档中的每个句子后附加一个TOPICPREFIX,将其转换为独立的事实,显著减少了事实错误,增强了模型对事实关联的理解。类似地,考虑到在预训练期间随机连接较短的文档可能会在模型输出中引入不一致,提出上下文预训练,一种创新的方法,其中LLM在相关文档的序列上进行训练。该方法通过改变文档的顺序,使上下文窗口内的相似度最大化。它明确地鼓励LLM跨越文档边界进行推理,从而潜在地增强了各代之间的逻辑一致性。
- 暴露偏倚。暴露偏倚诱发的幻觉与错误累积有着错综复杂的联系。虽然Chen et al.(2020); Welleck et al.(2020); Bertsch et al.(2023)提出了几种方法来减轻暴露偏倚,但很少有研究与幻觉直接相关。为了填补这一空白,Wang等人(2023 b)引入了中间序列作为置换多任务学习框架内的监督信号,以减轻NMT中域转移场景中的虚假相关性。另外,通过采用最小贝叶斯风险解码,它可以进一步减少与暴露偏见相关的幻觉。
5.2.2 缓解错位幻觉
在对齐过程中产生的幻觉往往源于能力错位和信念错位。然而,定义LLM的知识边界证明是具有挑战性的,使得难以弥合LLM的固有能力和人类注释数据中呈现的知识之间的差距。虽然有限的研究解决能力失调,重点主要转向信念失调。
源于信念错位的幻觉通常表现为阿谀奉承,这是LLMs以不受欢迎的方式寻求人类认可的一种倾向。这种阿谀奉承的行为可以归因于这样的事实:人类的偏好判断通常偏爱阿谀奉承的反应而不是更真实的反应,为奖励黑客铺平了道路。为了解决这个问题,一个简单的策略就是改进人类的偏好判断,进而改进偏好模型。最近的研究已经研究了LLM的使用,以帮助人类贴标人识别被忽视的缺陷。此外,Sharma等人(2023)发现,聚合多种人类偏好可以提高反馈质量,从而减少奉承。
此外,对LLM内部激活的修改也显示出改变模型行为的潜力。这可以通过诸如微调的方法来实现或推理期间的激活操纵。具体而言,Wei等人(2023)提出了一种合成数据干预,即使用合成数据对语言模型进行微调,其中声明的基本事实独立于用户的意见,旨在减少谄媚倾向。
另一个研究途径是通过激活导向来减轻谄媚。该方法涉及使用成对的阿谀奉承/非阿谀奉承提示来生成阿谀奉承导向向量,该向量是从平均中间激活的差异中导出的。在推理过程中,减去此向量可以产生不那么谄媚的LLM输出。
5.3 减轻与推理相关的幻觉
大型语言模型中的解码策略在决定生成内容的真实性和忠实性方面起着关键作用。然而,正如§3.3节中所分析的,不完美的解码通常会导致输出缺乏真实性或偏离原始上下文。在本小节中,我们探讨了两种先进的策略,旨在完善解码策略,以提高LLM输出的真实性和忠实性。
5.3.1 真实增强解码
事实增强解码的重点是确保LLM产生的信息的真实性。通过强调事实的准确性,这一战略旨在产生严格遵循真实世界信息的产出,并抵制产生误导或虚假陈述。
独立解码。考虑到采样过程中的随机性可能会将非事实内容引入开放式文本生成中,Lee等人(2022 b)引入了事实核采样算法,该算法在整个句子生成过程中动态调整“核”p。通过基于衰减因子和下边界动态地调整核概率,并在每个新句子的开始处重置核概率,解码策略在生成事实内容和保持输出多样性。
此外,一些研究认为LLM的激活空间包含与真实性相关的可解释结构。基于这一想法,Li等人(2023 d)引入了推理时间干预(ITI)。该方法首先确定与事实正确的陈述相关联的激活空间中的方向,然后在推理过程中沿着与事实相关的方向沿着调整激活。通过反复应用这种干预,可以引导LLM产生更真实的反应。
同样,Chuang et al.(2023)从事实知识存储的角度深入研究了增强LLM解码过程的真实性。他们利用Transformer LLM中事实知识的分层编码,注意到较低级别的信息在较早的层中捕获,语义信息在较晚的层中捕获。从Li等人(2022 c)中汲取灵感,他们引入了DoLa,这是一种动态选择和对比不同层的logit以改进解码真实性的策略。通过强调来自高层的知识并淡化来自低层的知识,DoLa展示了其使LLM更真实的潜力,从而减少幻觉。
后期编辑解码。与直接修改概率分布以防止在初始解码期间出现幻觉的方法不同,后编辑解码寻求利用LLM的自校正能力来精炼原始生成的内容而不依赖于外部知识库。Dhuliawala等人(2023年)介绍了验证链(COVE),其运行假设是,在适当提示下,LLM可以自我纠正错误,并提供更准确的事实。它从初稿开始,首先提出核查问题,然后系统地回答这些问题,以便最后提出一份经过改进的订正答复。类似地,Ji等人(2023 b)专注于医学领域,并引入了迭代的自我反思过程。这个过程利用LLM的固有能力,首先生成事实知识,然后细化响应,直到它与提供的背景知识一致。
5.3.2忠诚度增强解码
另一方面,忠诚度增强解码优先考虑与用户指令或提供的上下文的一致性,并强调增强所生成内容的一致性。因此,在本节中,我们将现有的工作总结为两类,包括上下文一致性和逻辑一致性。
上下文一致性。设计了优先考虑上下文一致性的解码策略,以增强LLM对用户指令和所提供上下文的忠实度。在LLM时代之前,先前的研究广泛地探索了语境一致性的改进,主要集中在抽象概括和数据文本领域。Tian等人(2019)提出了置信解码,即在解码过程中加入置信度评分,以测量模型对源的关注度。当置信度较高时,他们会更加强调来源,从而减轻由于缺乏对情境的关注而产生的幻觉。货车der Poel等人(2022)将解码目标转移到逐点互信息。这种方法鼓励模型优先考虑与源文档相关的标记,特别是当模型不确定性增加时,旨在防止幻觉。与之前强调加强对来源的关注以支持上下文一致性的策略相反,Wan等人(2023)深入研究了更好地探索搜索空间是否可以提高忠实度。通过使用自动忠诚度指标来对波束搜索生成的候选人进行排名,并结合为下一代分配忠诚度评分的前瞻性算法,与现有的解码策略相比,他们在忠诚度方面取得了显着的改进。
然而,在LLM时代,由于对情境关注不足而产生的幻觉问题依然存在。Shi等人(2023 b)提出了上下文感知解码(CAD),其通过减少对先验知识的依赖来修改输出分布,从而促进模型对上下文信息的关注。然而,由于多样性和归属之间的内在权衡,过分强调上下文信息会减少多样性。作为回应,Chang等人(2023a)引入了一种创新的采样算法,以在保持多样性的同时支持归因。该方法涉及两个并行的解码,一个考虑源,另一个不考虑,并动态调整温度使用的KL分歧之间的令牌分布,以反映源属性。Lei等人(2023)探索了一种更通用的编辑后框架,以减轻推理过程中的忠实幻觉。该方法首先在句子和实体级别检测幻觉,然后利用该检测反馈来细化所生成的响应。此外,Choi等人(2023年)引入了知识约束解码(KCD),该解码采用表征级幻觉检测来识别幻觉,并通过对表征分布进行重新加权来指导生成过程,从而更好地估计未来的知识基础。另外,考虑到softmax瓶颈制约了多样性表达和忠实表达。一系列工作探索了克服瓶颈的方法,或者通过混合Softmax,其使用多个隐藏状态来多次计算Softmax并合并所得到的分布(Yang等人,2019)或使用指针网络来使LLM能够复制上下文词语,进一步减少幻觉。
逻辑一致性。逻辑一致性在LLM中是至关重要的,以确保一致的反应和防止幻觉,特别是在多步推理期间。为了增强思维链激励中固有的自我一致性,Wang等人采用了一种知识提炼框架。他们首先使用对比解码产生一致的基本原理,然后用反事实推理目标微调学生模型,这有效地消除了推理捷径,在不考虑基本原理情况下得出答案。此外,通过直接使用对比解码,LLM可以减少表面级复制并防止遗漏推理步骤。
6 挑战和开放性问题
在本节中,我们深入研究了LLM中围绕幻觉的各种挑战和开放性问题,旨在指导这个关键领域的未来方向。
6.1LLM的挑战
在追求可靠和真实的LLM,解决幻觉是必不可少的,鉴于其固有的复杂性。虽然在减轻LLM幻觉方面取得了重大进展,但仍然存在显着的挑战。在这种情况下,我们深入研究了这些挑战,强调了它们在长文本生成(§6.1.1),检索增强生成(§6.1.2)和大型视觉语言模型(§6.1.3)等领域的表现。
6.1.1长格式文本生成中的幻觉
长格式文本生成在LLM中得到了广泛的应用。然而,随着所生成内容的长度增加,幻觉倾向也增加,导致评估这种幻觉的挑战。首先,现有的LLM幻觉基准通常以factoid问题和答案的形式呈现,更多地关注事实幻觉。在长文本生成领域中,明显缺乏人工标注的幻觉基准,这阻碍了研究人员在这一背景下研究特定类型的幻觉。其次,在长文本生成中评估幻觉是一个挑战。虽然有一些可用的评价指标,它们有局限性,当事实更加细微、开放和有争议时,或者当知识来源存在冲突时,它们不适用。这对现实世界场景中的实际应用造成了障碍。
6.1.2检索增强生成中的幻觉
检索增强生成(RAG)已成为减轻LLM幻觉的一种有前途的策略。随着人们对LLM幻觉的担忧加剧,RAG越来越受到关注,为一系列商业应用铺平了道路,如困惑2、YOU.com 3和新Bing 4。通过从外部知识库中检索证据,RAG使LLM能够掌握最新的知识,并根据相关证据做出反应。但是,尽管有它的优点,RAG也患有幻觉。一个值得注意的问题是,RAG管道不相关的证据可能会传播到生成阶段,可能会污染输出。另一个关注点在于生成检索的竞技场,它偶尔会遭受引用不准确。虽然引用的目的是提供一个可追溯的路径,以验证信息的来源,在这个领域的错误可能会导致用户误入歧途。此外,现有的RAG可能遭受多样性和真实性之间的折衷(Liu等人,2023 f),这在多样性的需要方面提出了新的挑战。
6.1.3 大型视觉语言模型中的幻觉
大型视觉语言模型(LVLM)具有视觉感知能力,沿着卓越的语言理解和生成能力,已经表现出卓越的视觉语言能力的报告。与先前的从大规模视觉语言预训练数据集中获得有限的视觉语言能力的预训练多模态模型不同,LVLM利用高级的大语言模型来更好地与人类和环境交互。LVLM随之而来的各种应用也为保持此类系统的可靠性带来了新的挑战,因此必须进一步研究和缓解。
Li等人(2023 e)、Lovenia等人(2023)在评估LVLM中的客体幻觉方面迈出了第一步。评估和实验表明,当前的LVLM易于生成关于相关图像的不一致响应,包括不存在的对象、错误的对象属性、不正确的语义关系等。此外,Liu等人(2023 c),Zong等人(2023)和Liu等人(2023 b)表明,LVLM很容易被愚弄,并且由于过度依赖强语言先验,以及其抵抗不适当的用户输入的较差能力。目前的评价和讨论主要集中在客体幻觉上。然而,尽管存在感知错误,LVLM在正确识别所有视觉元素的情况下仍会产生有缺陷的逻辑推理结果,这一问题有待于进一步研究。
已经努力建立一个更强大的大型视觉语言模型。Gunjal等人(2023),Lu等人(2023)和Liu等人(2023 c)建议进一步微调模型,以产生更真实和有用的反应。另一种工作方式选择事后校正所生成的不一致内容,诸如(Zhou等人,2023 b),以及(Yin等人,2023年)。虽然这些方法被证明是有效的,但通常需要额外的数据注释、视觉专家或训练阶段,这阻碍了LVLM有效地扩展和推广到各个领域。因此,预计未来将采用更普遍的方法来建立更可靠的系统。更重要的是,当呈现多个图像时,LVLM有时会混淆或错过部分视觉上下文,并且无法理解它们之间的时间或逻辑联系,这可能会阻碍它们在许多场景中的使用,但正确识别这种疾病的原因并解决它们仍然需要继续努力。
6.2 在LLM幻觉开放问题
随着对LLM幻觉研究的进展,有几个问题需要持续讨论。这些包括LLM自我纠正机制在减少幻觉方面的有效性(§6.2.1),对LLM内知识边界的理解(§6.2.2)以及他们的创造力和真实性之间的平衡(§6.2.3)。深入研究这些开放性问题为更深刻地理解LLM的能力和幻觉的复杂性铺平了道路。
6.2.1 自我纠正机制是否有助于减轻推理幻觉?
虽然LLM已经显示出通过思维链提示处理复杂推理任务的非凡能力,他们偶尔表现出不忠实的推理,其特征在于推理步骤或结论内的不一致性,这些不一致性在逻辑上不遵循推理链。研究表明,将外部反馈整合到LLM中可以显著减轻推理中的幻觉。这种反馈通常通过检索过程来自外部知识源,与其他LLM的互动辩论或来自外部评估指标的指导。
尽管如此,研究的一个分支探索自我纠正机制的潜力,其中LLM使用其内置功能纠正其初始响应,独立于外部反馈。虽然自我纠正已经显示出实现忠实和准确推理的希望,特别是在迭代设置中,但某些研究质疑自我纠正机制的有效性,指出LLM仍然很难自我纠正他们的推理链。因此,自我纠正机制在缓解推理幻觉方面的有效性仍然是一个值得进一步探讨的问题。
6.2.2我们能准确地捕捉LLM知识边界吗?
尽管LLM从大量数据中获取事实知识的能力令人印象深刻,但在认识自己的知识边界方面仍面临挑战。这种不足导致幻觉的发生,其中LLM自信地制造谎言,而没有意识到他们自己的知识限制。许多研究深入探讨了LLM的知识边界,利用诸如在多项选择设置中评估正确回答的概率的策略,或者通过评估具有不确定含义的句子集合之间的相似性来量化模型的输出不确定性。
此外,一系列的工作揭示了LLM在其激活空间中包含与真实性信念相关的潜在结构。最近的研究还发现了大量的证据,证明LLM有能力对问题的不可回答性进行编码,尽管这些模型在面对无法回答的问题时表现出过度自信并产生幻觉。尽管如此,Levinstein和Herrmann(2023)已经采用了经验和概念工具来探索LLM是否有信念。他们的经验结果表明,目前用于LLM的测谎仪方法还不完全可靠,并且Burns等人提出的探测方法,2022)和(Azaria和米切尔,2023)没有充分概括。因此,我们是否可以有效地探测LLM的内部信念正在进行中,需要进一步的研究。
6.2.3 如何在创造性和真实性之间取得平衡?
在开发真实可靠的LLM过程中,平衡创造性和真实性的挑战是一个重要的问题。确保真实性对于用于实际应用的LLM至关重要;任何不准确的信息都可能误导用户并污染在线环境。这种错误信息的影响可能是显著的,可能滚雪球和级联到数据用于后续的LLM培训。相反,幻觉有时候也能提供有价值的视角,特别是在创造性的努力中,比如讲故事、头脑风暴和产生超越传统思维的解决方案。
虽然目前对LLM的研究严重倾向于减少幻觉,但它往往忽视了他们创造能力的重要作用。随着LLM的不断发展,在创造性和事实准确性之间取得平衡的挑战仍然没有得到解决。不仅在多模态文本生成任务中探索平衡也是有趣的而且在视觉生成任务中也是如此。这一问题超出了单纯的技术性问题,需要对人工智能的本质及其对人类互动和知识交流的影响进行更广泛的思考。