基于英特尔平台及OpenVINO2023工具套件优化文生图任务
当今,文生图技术在很多领域都得到了广泛的应用。这种技术可以将文本直接转换为逼真的图像,具有很高的实用性和应用前景。然而,由于文生成图任务通常需要大量的计算资源和时间,如何在英特尔平台上高效地完成这些计算是一个重要的挑战。
为了解决这个问题,我们主要使用最优的调度器等方法来优化文生成图任务的计算过程。调度器是一种优化工具,它可以将任务分配到不同的计算节点上,并根据实际情况调整计算节点的负载和使用率,以提高整体的计算效率和性能。
赛题任务:使用stable diffusion2.1在目标英特尔硬件上完成部署优化以及指定图片生成工作。
操作系统:Windows11
硬件平台:使用大赛提供的标准硬件
目标:根据指定的输入输出要求,优化指定文生图模型在端侧设备上的Pipeline性能,在保证文生图效果的情况下,降低pipeline端到端延迟,降低pipeline峰值内存占用。

输入输出要求:
1.Prompt输入:“a photo of an astronaut riding a horse on mars”
2.Negative Prompt输入: “low resolution, blurry”
3.图片输出: 512*512, 24Bit, PNG格式

一、导入模型和相关配置
from diffusers import StableDiffusionPipeline
from pathlib import Path
pipe = StableDiffusionPipeline.from_pretrained("stable-diffusion-2-1-base").to("cpu")# for reducing memory consumption get all components from pipeline independently
text_encoder = pipe.text_encoder
text_encoder.eval()
unet = pipe.unet
unet.eval()
vae = pipe.vae
vae.eval()conf = pipe.scheduler.configdel pipesd2_1_model_dir = Path("sd2.1")
sd2_1_model_dir.mkdir(exist_ok=True)
二、转换Encoder为IR格式
import gc
import torch
import openvino as ovTEXT_ENCODER_OV_PATH = sd2_1_model_dir / 'text_encoder.xml'def cleanup_torchscript_cache():"""Helper for removing cached model representation"""torch._C._jit_clear_class_registry()torch.jit._recursive.concrete_type_store = torch.jit._recursive.ConcreteTypeStore()torch.jit._state._clear_class_state()def convert_encoder(text_encoder: torch.nn.Module, ir_path:Path):"""Convert Text Encoder model to IR. Function accepts pipeline, prepares example inputs for conversion Parameters: text_encoder (torch.nn.Module): text encoder PyTorch modelir_path (Path): File for storing modelReturns:None"""if not ir_path.exists():input_ids = torch.ones((1, 77), dtype=torch.long)# switch model to inference modetext_encoder.eval()# disable gradients calculation for reducing memory consumptionwith torch.no_grad():# export modelov_model = ov.convert_model(text_encoder, # model instanceexample_input=input_ids, # example inputs for model tracinginput=([1,77],) # input shape for conversion)ov.save_model(ov_model, ir_path)del ov_modelcleanup_torchscript_cache()print('Text Encoder successfully converted to IR')if not TEXT_ENCODER_OV_PATH.exists():convert_encoder(text_encoder, TEXT_ENCODER_OV_PATH)
else:print(f"Text encoder will be loaded from {TEXT_ENCODER_OV_PATH}")del text_encoder
gc.collect();
三、转换Unet为IR格式
import numpy as npUNET_OV_PATH = sd2_1_model_dir / 'unet.xml'def convert_unet(unet:torch.nn.Module, ir_path:Path, num_channels:int = 4, width:int = 64, height:int = 64):"""Convert Unet model to IR format. Function accepts pipeline, prepares example inputs for conversion Parameters: unet (torch.nn.Module): UNet PyTorch modelir_path (Path): File for storing modelnum_channels (int, optional, 4): number of input channelswidth (int, optional, 64): input widthheight (int, optional, 64): input heightReturns:None"""dtype_mapping = {torch.float32: ov.Type.f32,torch.float64: ov.Type.f64}if not ir_path.exists():# prepare inputsencoder_hidden_state = torch.ones((2, 77, 1024))latents_shape = (2, num_channels, width, height)latents = torch.randn(latents_shape)t = torch.from_numpy(np.array(1, dtype=np.float32))unet.eval()dummy_inputs = (latents, t, encoder_hidden_state)input_info = []for input_tensor in dummy_inputs:shape = ov.PartialShape(tuple(input_tensor.shape))element_type = dtype_mapping[input_tensor.dtype]input_info.append((shape, element_type))with torch.no_grad():ov_model = ov.convert_model(unet, example_input=dummy_inputs,input=input_info)ov.save_model(ov_model, ir_path)del ov_modelcleanup_torchscript_cache()print('U-Net successfully converted to IR')if not UNET_OV_PATH.exists():convert_unet(unet, UNET_OV_PATH, width=96, height=96)del unetgc.collect()
else:del unet
gc.collect();
四、转换Vae为IR格式
VAE_ENCODER_OV_PATH = sd2_1_model_dir / 'vae_encoder.xml'def convert_vae_encoder(vae: torch.nn.Module, ir_path: Path, width:int = 512, height:int = 512):"""Convert VAE model to IR format. VAE model, creates wrapper class for export only necessary for inference part, prepares example inputs for onversion Parameters: vae (torch.nn.Module): VAE PyTorch modelir_path (Path): File for storing modelwidth (int, optional, 512): input widthheight (int, optional, 512): input heightReturns:None"""class VAEEncoderWrapper(torch.nn.Module):def __init__(self, vae):super().__init__()self.vae = vaedef forward(self, image):return self.vae.encode(x=image)["latent_dist"].sample()if not ir_path.exists():vae_encoder = VAEEncoderWrapper(vae)vae_encoder.eval()image = torch.zeros((1, 3, width, height))with torch.no_grad():ov_model = ov.convert_model(vae_encoder, example_input=image, input=([1,3, width, height],))ov.save_model(ov_model, ir_path)del ov_modelcleanup_torchscript_cache()print('VAE encoder successfully converted to IR')def convert_vae_decoder(vae: torch.nn.Module, ir_path: Path, width:int = 64, height:int = 64):"""Convert VAE decoder model to IR format. Function accepts VAE model, creates wrapper class for export only necessary for inference part, prepares example inputs for conversion Parameters: vae (torch.nn.Module): VAE model ir_path (Path): File for storing modelwidth (int, optional, 64): input widthheight (int, optional, 64): input heightReturns:None"""class VAEDecoderWrapper(torch.nn.Module):def __init__(self, vae):super().__init__()self.vae = vaedef forward(self, latents):return self.vae.decode(latents)if not ir_path.exists():vae_decoder = VAEDecoderWrapper(vae)latents = torch.zeros((1, 4, width, height))vae_decoder.eval()with torch.no_grad():ov_model = ov.convert_model(vae_decoder, example_input=latents, input=([1,4, width, height],))ov.save_model(ov_model, ir_path)del ov_modelcleanup_torchscript_cache()print('VAE decoder successfully converted to IR')if not VAE_ENCODER_OV_PATH.exists():convert_vae_encoder(vae, VAE_ENCODER_OV_PATH, 768, 768)
else:print(f"VAE encoder will be loaded from {VAE_ENCODER_OV_PATH}")VAE_DECODER_OV_PATH = sd2_1_model_dir / 'vae_decoder.xml'if not VAE_DECODER_OV_PATH.exists():convert_vae_decoder(vae, VAE_DECODER_OV_PATH, 96, 96)
else:print(f"VAE decoder will be loaded from {VAE_DECODER_OV_PATH}")del vae
gc.collect();
五、核心代码
import inspect
from typing import List, Optional, Union, Dictimport PIL
import cv2
import torchfrom transformers import CLIPTokenizer
from diffusers.pipelines.pipeline_utils import DiffusionPipeline
from diffusers.schedulers import DDIMScheduler, LMSDiscreteScheduler, PNDMSchedulerdef scale_fit_to_window(dst_width:int, dst_height:int, image_width:int, image_height:int):"""Preprocessing helper function for calculating image size for resize with peserving original aspect ratio and fitting image to specific window sizeParameters:dst_width (int): destination window widthdst_height (int): destination window heightimage_width (int): source image widthimage_height (int): source image heightReturns:result_width (int): calculated width for resizeresult_height (int): calculated height for resize"""im_scale = min(dst_height / image_height, dst_width / image_width)return int(im_scale * image_width), int(im_scale * image_height)def preprocess(image: PIL.Image.Image):"""Image preprocessing function. Takes image in PIL.Image format, resizes it to keep aspect ration and fits to model input window 512x512,then converts it to np.ndarray and adds padding with zeros on right or bottom side of image (depends from aspect ratio), after thatconverts data to float32 data type and change range of values from [0, 255] to [-1, 1], finally, converts data layout from planar NHWC to NCHW.The function returns preprocessed input tensor and padding size, which can be used in postprocessing.Parameters:image (PIL.Image.Image): input imageReturns:image (np.ndarray): preprocessed image tensormeta (Dict): dictionary with preprocessing metadata info"""src_width, src_height = image.sizedst_width, dst_height = scale_fit_to_window(512, 512, src_width, src_height)image = np.array(image.resize((dst_width, dst_height),resample=PIL.Image.Resampling.LANCZOS))[None, :]pad_width = 512 - dst_widthpad_height = 512 - dst_heightpad = ((0, 0), (0, pad_height), (0, pad_width), (0, 0))image = np.pad(image, pad, mode="constant")image = image.astype(np.float32) / 255.0image = 2.0 * image - 1.0image = image.transpose(0, 3, 1, 2)return image, {"padding": pad, "src_width": src_width, "src_height": src_height}class OVStableDiffusionPipeline(DiffusionPipeline):def __init__(self,vae_decoder: ov.Model,text_encoder: ov.Model,tokenizer: CLIPTokenizer,unet: ov.Model,scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler],vae_encoder: ov.Model = None,):"""Pipeline for text-to-image generation using Stable Diffusion.Parameters:vae_decoder (Model):Variational Auto-Encoder (VAE) Model to decode images to and from latent representations.text_encoder (Model):Frozen text-encoder. Stable Diffusion uses the text portion of[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specificallythe clip-vit-large-patch14(https://huggingface.co/openai/clip-vit-large-patch14) variant.tokenizer (CLIPTokenizer):Tokenizer of class CLIPTokenizer(https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).unet (Model): Conditional U-Net architecture to denoise the encoded image latents.vae_encoder (Model):Variational Auto-Encoder (VAE) Model to encode images to latent representation.scheduler (SchedulerMixin):A scheduler to be used in combination with unet to denoise the encoded image latents. Can be one ofDDIMScheduler, LMSDiscreteScheduler, or PNDMScheduler."""super().__init__()self.scheduler = schedulerself.vae_decoder = vae_decoderself.vae_encoder = vae_encoderself.text_encoder = text_encoderself.unet = unetself._text_encoder_output = text_encoder.output(0)self._unet_output = unet.output(0)self._vae_d_output = vae_decoder.output(0)self._vae_e_output = vae_encoder.output(0) if vae_encoder is not None else Noneself.height = self.unet.input(0).shape[2] * 8self.width = self.unet.input(0).shape[3] * 8self.tokenizer = tokenizerdef __call__(self,prompt: Union[str, List[str]],image: PIL.Image.Image = None,negative_prompt: Union[str, List[str]] = None,num_inference_steps: Optional[int] = 50,guidance_scale: Optional[float] = 7.5,eta: Optional[float] = 0.0,output_type: Optional[str] = "pil",seed: Optional[int] = None,strength: float = 1.0,):"""Function invoked when calling the pipeline for generation.Parameters:prompt (str or List[str]):The prompt or prompts to guide the image generation.image (PIL.Image.Image, *optional*, None):Intinal image for generation.negative_prompt (str or List[str]):The negative prompt or prompts to guide the image generation.num_inference_steps (int, *optional*, defaults to 50):The number of denoising steps. More denoising steps usually lead to a higher quality image at theexpense of slower inference.guidance_scale (float, *optional*, defaults to 7.5):Guidance scale as defined in Classifier-Free Diffusion Guidance(https://arxiv.org/abs/2207.12598).guidance_scale is defined as `w` of equation 2.Higher guidance scale encourages to generate images that are closely linked to the text prompt,usually at the expense of lower image quality.eta (float, *optional*, defaults to 0.0):Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to[DDIMScheduler], will be ignored for others.output_type (`str`, *optional*, defaults to "pil"):The output format of the generate image. Choose between[PIL](https://pillow.readthedocs.io/en/stable/): PIL.Image.Image or np.array.seed (int, *optional*, None):Seed for random generator state initialization.strength (int, *optional*, 1.0):strength between initial image and generated in Image-to-Image pipeline, do not used in Text-to-ImageReturns:Dictionary with keys: sample - the last generated image PIL.Image.Image or np.array"""if seed is not None:np.random.seed(seed)# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`# corresponds to doing no classifier free guidance.do_classifier_free_guidance = guidance_scale > 1.0# get prompt text embeddingstext_embeddings = self._encode_prompt(prompt, do_classifier_free_guidance=do_classifier_free_guidance, negative_prompt=negative_prompt)# set timestepsaccepts_offset = "offset" in set(inspect.signature(self.scheduler.set_timesteps).parameters.keys())extra_set_kwargs = {}if accepts_offset:extra_set_kwargs["offset"] = 1self.scheduler.set_timesteps(num_inference_steps, **extra_set_kwargs)timesteps, num_inference_steps = self.get_timesteps(num_inference_steps, strength)latent_timestep = timesteps[:1]# get the initial random noise unless the user supplied itlatents, meta = self.prepare_latents(image, latent_timestep)# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502# and should be between [0, 1]accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())extra_step_kwargs = {}if accepts_eta:extra_step_kwargs["eta"] = etafor t in self.progress_bar(timesteps):# expand the latents if we are doing classifier free guidancelatent_model_input = np.concatenate([latents] * 2) if do_classifier_free_guidance else latentslatent_model_input = self.scheduler.scale_model_input(latent_model_input, t)# predict the noise residualnoise_pred = self.unet([latent_model_input, np.array(t, dtype=np.float32), text_embeddings])[self._unet_output]# perform guidanceif do_classifier_free_guidance:noise_pred_uncond, noise_pred_text = noise_pred[0], noise_pred[1]noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)# compute the previous noisy sample x_t -> x_t-1latents = self.scheduler.step(torch.from_numpy(noise_pred), t, torch.from_numpy(latents), **extra_step_kwargs)["prev_sample"].numpy()# scale and decode the image latents with vaeimage = self.vae_decoder(latents * (1 / 0.18215))[self._vae_d_output]image = self.postprocess_image(image, meta, output_type)return {"sample": image}def _encode_prompt(self, prompt:Union[str, List[str]], num_images_per_prompt:int = 1, do_classifier_free_guidance:bool = True, negative_prompt:Union[str, List[str]] = None):"""Encodes the prompt into text encoder hidden states.Parameters:prompt (str or list(str)): prompt to be encodednum_images_per_prompt (int): number of images that should be generated per promptdo_classifier_free_guidance (bool): whether to use classifier free guidance or notnegative_prompt (str or list(str)): negative prompt to be encodedReturns:text_embeddings (np.ndarray): text encoder hidden states"""batch_size = len(prompt) if isinstance(prompt, list) else 1# tokenize input promptstext_inputs = self.tokenizer(prompt,padding="max_length",max_length=self.tokenizer.model_max_length,truncation=True,return_tensors="np",)text_input_ids = text_inputs.input_idstext_embeddings = self.text_encoder(text_input_ids)[self._text_encoder_output]# duplicate text embeddings for each generation per promptif num_images_per_prompt != 1:bs_embed, seq_len, _ = text_embeddings.shapetext_embeddings = np.tile(text_embeddings, (1, num_images_per_prompt, 1))text_embeddings = np.reshape(text_embeddings, (bs_embed * num_images_per_prompt, seq_len, -1))# get unconditional embeddings for classifier free guidanceif do_classifier_free_guidance:uncond_tokens: List[str]max_length = text_input_ids.shape[-1]if negative_prompt is None:uncond_tokens = [""] * batch_sizeelif isinstance(negative_prompt, str):uncond_tokens = [negative_prompt]else:uncond_tokens = negative_promptuncond_input = self.tokenizer(uncond_tokens,padding="max_length",max_length=max_length,truncation=True,return_tensors="np",)uncond_embeddings = self.text_encoder(uncond_input.input_ids)[self._text_encoder_output]# duplicate unconditional embeddings for each generation per prompt, using mps friendly methodseq_len = uncond_embeddings.shape[1]uncond_embeddings = np.tile(uncond_embeddings, (1, num_images_per_prompt, 1))uncond_embeddings = np.reshape(uncond_embeddings, (batch_size * num_images_per_prompt, seq_len, -1))# For classifier free guidance, we need to do two forward passes.# Here we concatenate the unconditional and text embeddings into a single batch# to avoid doing two forward passestext_embeddings = np.concatenate([uncond_embeddings, text_embeddings])return text_embeddingsdef prepare_latents(self, image:PIL.Image.Image = None, latent_timestep:torch.Tensor = None):"""Function for getting initial latents for starting generationParameters:image (PIL.Image.Image, *optional*, None):Input image for generation, if not provided randon noise will be used as starting pointlatent_timestep (torch.Tensor, *optional*, None):Predicted by scheduler initial step for image generation, required for latent image mixing with nosieReturns:latents (np.ndarray):Image encoded in latent space"""latents_shape = (1, 4, self.height // 8, self.width // 8)noise = np.random.randn(*latents_shape).astype(np.float32)if image is None:# if we use LMSDiscreteScheduler, let's make sure latents are mulitplied by sigmasif isinstance(self.scheduler, LMSDiscreteScheduler):noise = noise * self.scheduler.sigmas[0].numpy()return noise, {}input_image, meta = preprocess(image)latents = self.vae_encoder(input_image)[self._vae_e_output]latents = latents * 0.18215latents = self.scheduler.add_noise(torch.from_numpy(latents), torch.from_numpy(noise), latent_timestep).numpy()return latents, metadef postprocess_image(self, image:np.ndarray, meta:Dict, output_type:str = "pil"):"""Postprocessing for decoded image. Takes generated image decoded by VAE decoder, unpad it to initila image size (if required), normalize and convert to [0, 255] pixels range. Optionally, convertes it from np.ndarray to PIL.Image formatParameters:image (np.ndarray):Generated imagemeta (Dict):Metadata obtained on latents preparing step, can be emptyoutput_type (str, *optional*, pil):Output format for result, can be pil or numpyReturns:image (List of np.ndarray or PIL.Image.Image):Postprocessed images"""if "padding" in meta:pad = meta["padding"](_, end_h), (_, end_w) = pad[1:3]h, w = image.shape[2:]unpad_h = h - end_hunpad_w = w - end_wimage = image[:, :, :unpad_h, :unpad_w]image = np.clip(image / 2 + 0.5, 0, 1)image = np.transpose(image, (0, 2, 3, 1))# 9. Convert to PILif output_type == "pil":image = self.numpy_to_pil(image)if "src_height" in meta:orig_height, orig_width = meta["src_height"], meta["src_width"]image = [img.resize((orig_width, orig_height),PIL.Image.Resampling.LANCZOS) for img in image]else:if "src_height" in meta:orig_height, orig_width = meta["src_height"], meta["src_width"]image = [cv2.resize(img, (orig_width, orig_width))for img in image]return imagedef get_timesteps(self, num_inference_steps:int, strength:float):"""Helper function for getting scheduler timesteps for generationIn case of image-to-image generation, it updates number of steps according to strengthParameters:num_inference_steps (int):number of inference steps for generationstrength (float):value between 0.0 and 1.0, that controls the amount of noise that is added to the input image. Values that approach 1.0 allow for lots of variations but will also produce images that are not semantically consistent with the input."""# get the original timestep using init_timestepinit_timestep = min(int(num_inference_steps * strength), num_inference_steps)t_start = max(num_inference_steps - init_timestep, 0)timesteps = self.scheduler.timesteps[t_start:]return timesteps, num_inference_steps - t_start
六、构建ov_pipe
import ipywidgets as widgets
from transformers import CLIPTokenizercore = ov.Core()device = 'GPU.1'ov_config = {"INFERENCE_PRECISION_HINT": "f32"} if device != "CPU" else {}text_enc = core.compile_model(TEXT_ENCODER_OV_PATH, device)
unet_model = core.compile_model(UNET_OV_PATH, device)
vae_decoder = core.compile_model(VAE_DECODER_OV_PATH, device, ov_config)
vae_encoder = core.compile_model(VAE_ENCODER_OV_PATH, device, ov_config)scheduler = DPMSolverMultistepScheduler.from_config(conf)
tokenizer = CLIPTokenizer.from_pretrained('clip-vit-large-patch14')ov_pipe = OVStableDiffusionPipeline(tokenizer=tokenizer,text_encoder=text_enc,unet=unet_model,vae_encoder=vae_encoder,vae_decoder=vae_decoder,scheduler=scheduler
)
七、开始推理
import os
from PIL import Image def generate(prompt, negative_prompt, seed, num_steps): result = ov_pipe( prompt, negative_prompt=negative_prompt, num_inference_steps=int(num_steps), seed=seed, ) return result["sample"][0] def save_image(image, file_path): # 确保目录存在 os.makedirs(os.path.dirname(file_path), exist_ok=True) # 保存图像 image.save(file_path, format="PNG", optimize=True) def generate_and_save_images(prompt, negative_prompt, seed, num_steps, image_dir): for i in range(20): image = generate(prompt, negative_prompt, seed + i, num_steps) image = image.resize((512, 512)) # 调整图像大小为512x512像素 # 保存图片到文件 file_path = os.path.join(image_dir, f"image_{i}.png") save_image(image, file_path) # 使用函数生成图片
prompt = "a photo of an astronaut riding a horse on mars"
negative_prompt = "low resolution, blurry"
num_inference_steps = "25"
seed = "42"
output_dir = "output_images"
generate_and_save_images(prompt , negative_prompt , seed , num_inference_steps , output_dir )
推理过程如下:
推理结果保存在对应output_dir路径下:

推理个例如下:

八、优化
首先,我们基于英特尔的独立显卡GPU.1硬件进行SD文生图模型的部署,这在一定程度上已经相比其它硬件平台有了一定的优化,然后,我们基于SD模型的调度器进行了替换优化。
原先模型使用的调度器主要为LMSDiscreteScheduler,由于不同的调度器往往有不一定的推理效果,所以我针对各种优化器进行了对比,其中主要有DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler、DPMSolverMultistepScheduler以及FlaxLMSDiscreteScheduler。
其中DPMSolverMultistep是DPM-Solver: 10步左右扩散概率模型采样快速ODE求解器和DPM-Solver++:扩散概率模型引导采样快速求解器的多步调度程序,由陆成、周宇浩、包凡、陈建飞、李冲轩、朱军等人提出。
DPMSolver(及其改进版本DPMSolver++)是一种快速的、具有收敛阶保证的扩散ode专用高阶求解器。从经验上看,DPMSolver采样只需要20步就可以生成高质量的样本,即使是10步也可以生成相当好的样本。
最后通过综合比对,我们发现DPMSolver不仅出图速度相较于其它调度器较快,出图的质量也很高,最后采用了该调度器进行SD文升图的优化。
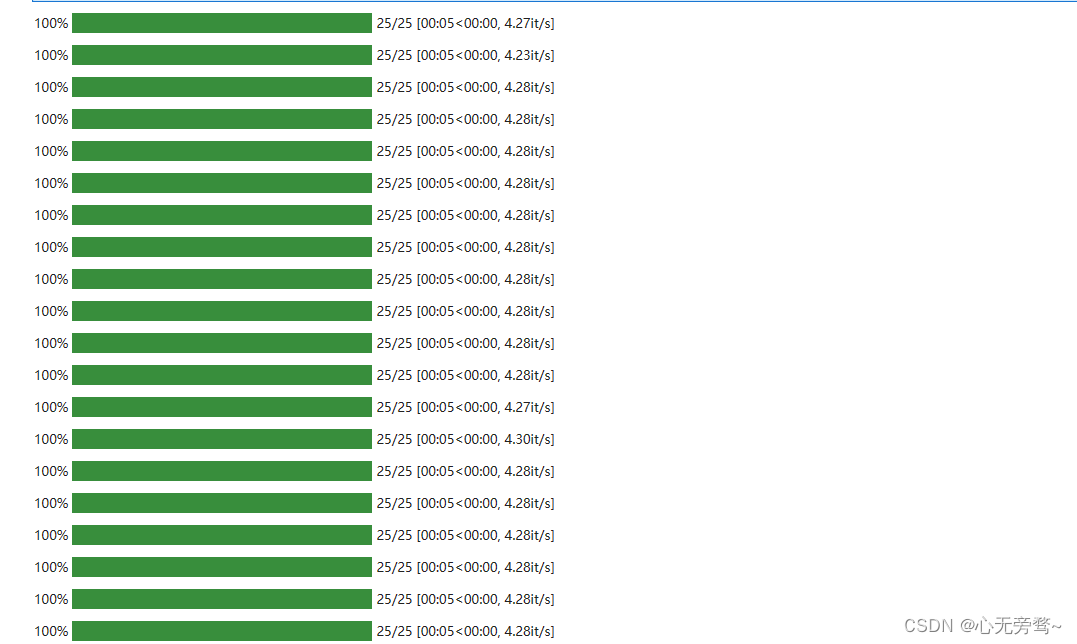
内存占有率也是限制在11.8到12.2左右。
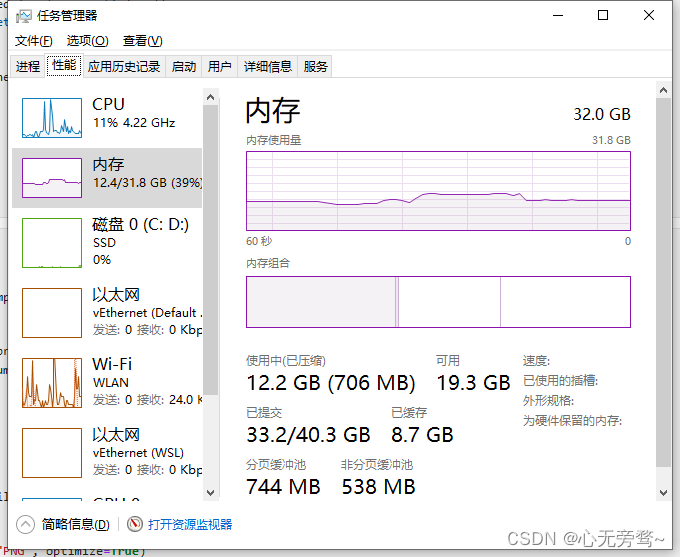
同时,基本也是5秒一张图。
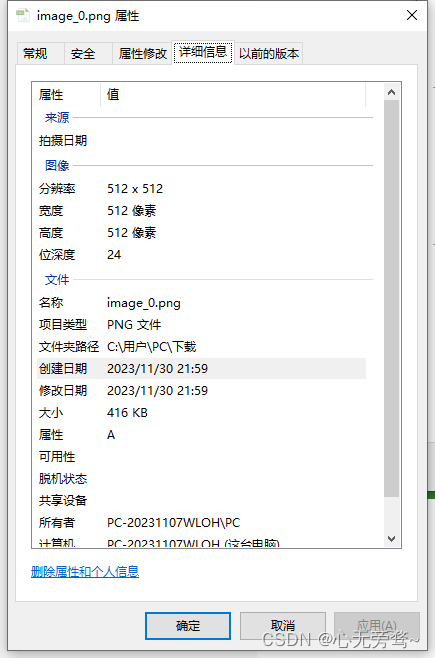
生成的图片格式也符合要求:
而使用其它优化器的内存占有率高达16GB左右。
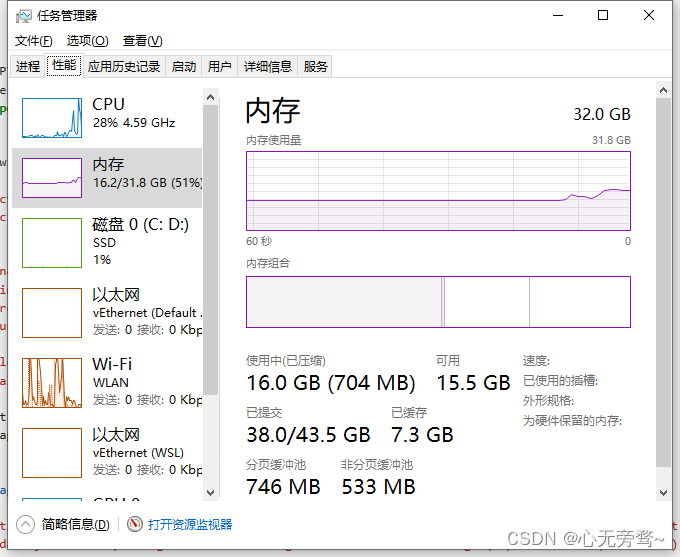
文升图推理速度也是高达15s左右。
