Flask学习三:模型操作
ORM
flask 通过Model操作数据库,不管你的数据库是MySQL还是Sqlite,flask自动帮你生成相应数据库类型的sql语句,所以不需要关注sql语句和类型,对数据的操作flask帮我们自动完成,只需要会写Model就可以了
flask使用对象关系映射(简称为ORM)框架去操控数据库
ORM对象关系映射是一种程序技术,用于实现面向对象变成语言里不同类型系统的数据之间的转换,将对对象的操作转换为原生的SQL语句。简单易用,可以有效减少重复的SQL;性能损耗少;设计灵活,可以轻松实现复杂查询;可移植性好
数据库连接
Flask使用Python自带的ORM:SQLAlchemy。针对于Flask的支持,需要安装相应的插件
pip install flask-sqlalchemy
为什么使用sqlite而不是mysql
SQLite和MySQL是两种常见的数据库管理系统,它们之间有一些重要的区别。
-
数据库类型:SQLite是一种嵌入式数据库,它将整个数据库作为一个文件存储在磁盘上。而MySQL是一种客户端/服务器数据库,它以独立的服务器进程运行,并通过网络接口来处理客户端请求。
-
部署和配置:由于SQLite是一个嵌入式数据库,它非常容易部署和配置。你只需要在应用程序中包含SQLite的库文件即可。MySQL需要单独安装和配置数据库服务器,并通过网络连接来访问。
-
性能和扩展性:SQLite适用于小型应用程序和个人项目,因为它在处理大量数据和高并发访问时可能性能较低。相比之下,MySQL被设计用于处理大型数据集和高负载的应用程序,它具有更好的性能和扩展性。
-
功能和支持:MySQL是一个成熟的数据库管理系统,提供了广泛的功能和丰富的工具。它支持复杂的查询语言(如SQL),事务处理和高级安全特性。相比之下,SQLite是一个轻量级的数据库,功能相对较少。
-
并发处理:MySQL支持多个并发连接,可以同时处理多个客户端请求。SQLite在写操作时会锁定整个数据库文件,因此在高并发访问情况下可能会出现性能问题。
综上所述,SQLite适用于小型应用程序和个人项目,而MySQL适用于中大型应用程序和高负载环境。选择哪种数据库取决于你的具体需求和项目规模。
连接配置
直接看老师讲的视频好了,容易理解。千峰教育 Flask2入门 数据库连接
数据迁移
当数据库和表配置好后,需要进行数据迁移,这样会在项目中生成真正的数据库和表。
基本步骤如下:
- 使用
cmd打开项目目录(app.py所在的目录) - 依次输入下面的命令
flask db init创建迁移文件夹migrates,只调用一次flask db migrate生成迁移文件flask db upgrade执行迁移文件中的升级flask db downgrade执行迁移文件中的降级
初始化

执行完会在项目根目录下生成对应的文件夹instance和migrations
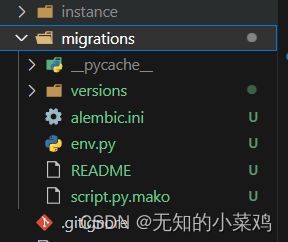
生成迁移文件

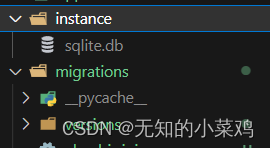
会生成数据库db文件
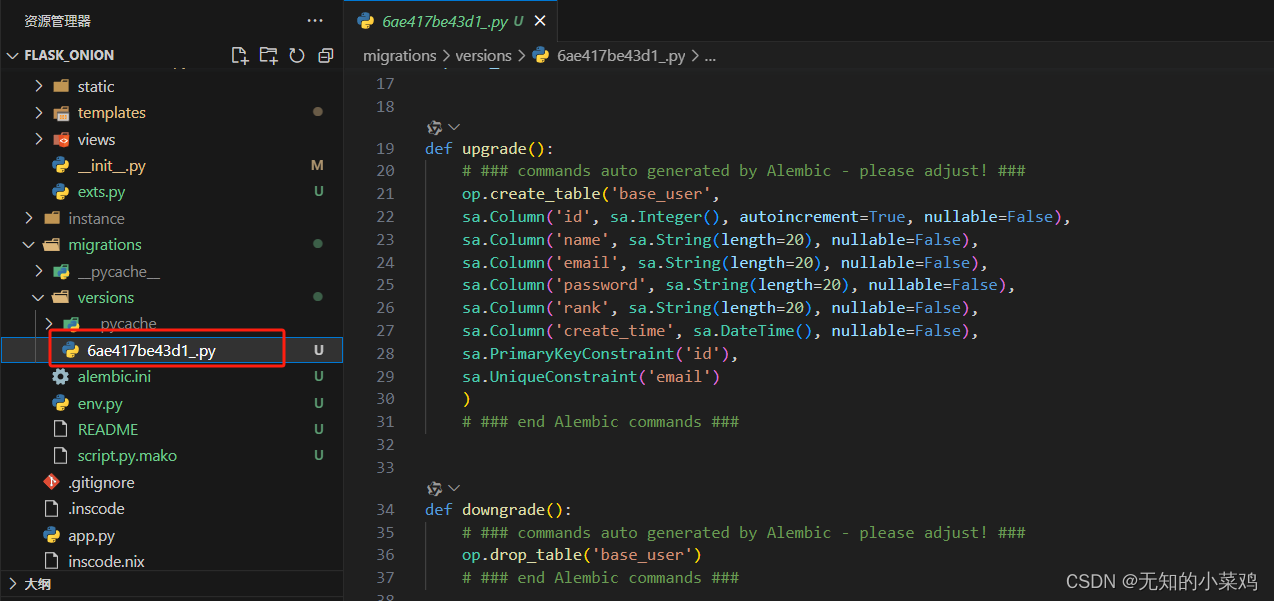
并且会生成一个操作记录的py文件
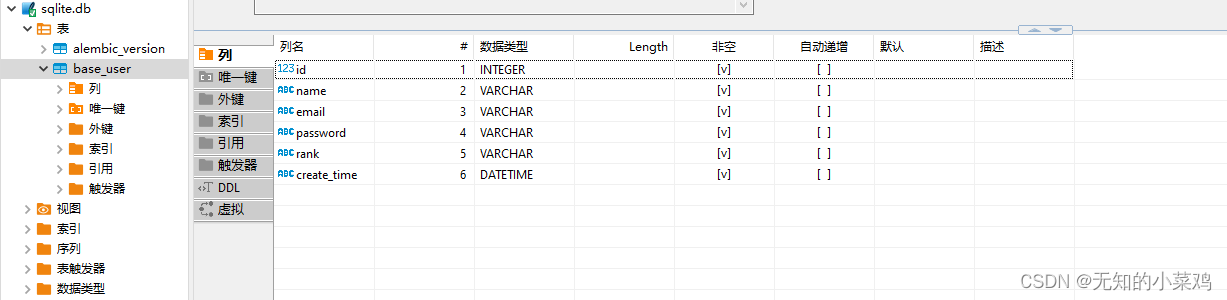
生成表
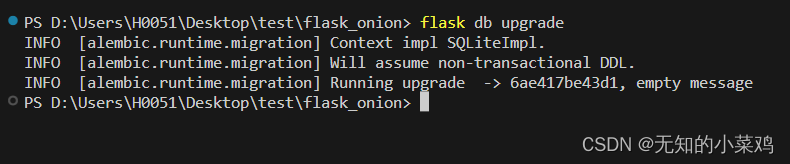
实际上就是执行的上一次生成文件里的upgrade函数,执行完成后,我们可以使用类似dberver的工具来进行查看
修改表结构
在修改表结构时,比如新添加一列。必须要先修改对应的模型,然后在重新进行生成迁移文件、执行迁移文件中的升级。
数据库的常见操作
新增数据
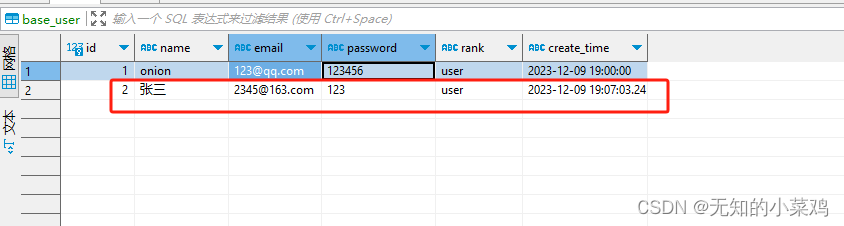
@baseBlue.route("/add-user/")
def addUser():# 创建一个对象user = BaseModel()user.name = "张三"user.email = "2345@163.com"user.password = "123"user.create_time = datetime.now()# 将对象添加进session中db.session.add(user)# 将数据提交到数据库db.session.commit()data = {"code": 0, "data": '', "msg": "添加成功"}return jsonify(data)

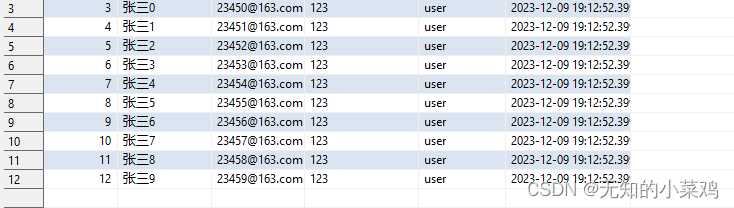
如果添加多条数据时可以使用add_all,例如
users =[]for i in range(10):user = BaseModel()user.name = "张三" + str(i)user.email = "2345@163.com"user.password = "123"user.create_time = datetime.now()users.append(user)db.session.add_all(users)db.session.commit()
同时可以添加异常处理
def addUser():# 创建一个对象user = BaseModel()user.name = "张三"user.email = "2345@163.com"user.password = "123"user.create_time = datetime.now()try:# 将对象添加进session中db.session.add(user)# 将数据提交到数据库db.session.commit()data = {"code": 0, "data": '', "msg": "添加成功"}except Exception as e:data = {"code": 1, "data": '', "msg": "添加失败"}db.session.rollback() # 回滚db.session.flush() # 清空sessionprint("addUser error:"+str(e))return jsonify(data)
删除数据
def delUser(id):try:user = BaseModel.query.get(id)db.session.delete(user)db.session.commit()data = {"code": 0, "data": '', "msg": "删除成功"}except Exception as e:data = {"code": 1, "data": '', "msg": "删除失败"}db.session.rollback() # 回滚db.session.flush() # 清空sessionprint("delUser error:"+str(e))return jsonify(data)
修改数据
def updateUser(id):try:user = BaseModel.query.get(id)user.name="李四"db.session.commit()data = {"code": 0, "data": '', "msg": "修改成功"}except Exception as e:data = {"code": 1, "data": '', "msg": "修改失败"}db.session.rollback() # 回滚db.session.flush() # 清空sessionprint("updateUser error:"+str(e))return jsonify(data)
查询数据
过滤器
filter()把过滤器添加到原查询上,返回一个新的查询limit()使用指定的值限制原查询返回的结果数量,返回一个新的查询offset()偏移原查询返回的结果,返回一个新的查询order_by()根据指定条件对原查询结果进行排序,返回一个新查询group_by()根据指定条件对原查询结果进行分组,返回一个新的查询
常用查询
all()以列表形式返回查询的所有结果,返回列表first()返回查询的第一个结果,如果没有结果返回Noneget()返回指定主键对应的行,如果没有对应的行,则返回Nonecount()返回查询结果的数量paginate()返回一个Paginate对象,它包含指定范围内的结果
逻辑运算
and_逻辑与,filter()默认为逻辑与,多个条件时用逗号分隔or_逻辑或not_逻辑非
查询属性
contains(),contains('3')模糊查找,类似于sql中的likein_(),in_([1,2,3])其中之一startswith()和endswidth()以什么开始和以什么结束
根据用户名模糊查询
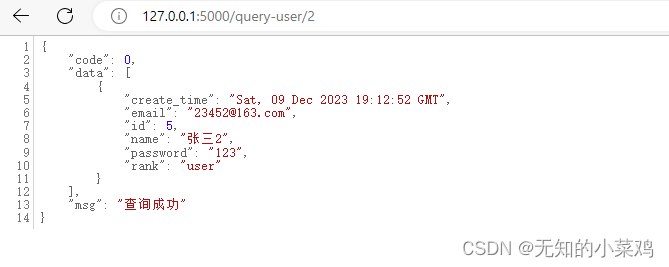
def queryUser(name):try:users = BaseModel.query.filter(BaseModel.name.like("%"+name+"%")).all()res = [user.to_dict() for user in users]data = {"code": 0, "data": res, "msg": "查询成功"}except Exception as e:data = {"code": 1, "data": '', "msg": "查询失败"}print("queryUser error:"+str(e))return jsonify(data)
注意:查询返回的结果是模型对象,因此需要将模型对象转换为字典
class BaseModel(db.Model):# 表的名字__tablename__ = 'base_user'# 表的结构id = db.Column(db.Integer, primary_key=True, autoincrement=True) # 主键name = db.Column(db.String(20), unique=False, nullable=False) # 用户名email = db.Column(db.String(20), unique=True, nullable=False) # 邮箱password = db.Column(db.String(20), nullable=False) # 密码rank = db.Column(db.String(20), nullable=False,default='user') # 用户等级,admin为管理员,user为普通用户create_time = db.Column(db.DateTime, nullable=False) # 创建时间# 将模型对象转换为字典def to_dict(self):return {c.name: getattr(self, c.name) for c in self.__table__.columns}
query.filter就相当于sql中的where查询,如果存在多个查询条件时可以如下操作
from sqlalchemy import and_, or_# 示例查询条件
condition1 = BaseModel.column1 == value1
condition2 = BaseModel.column2 > value2
condition3 = BaseModel.column3.like("%" + value3 + "%")# 使用 and_ 方法将多个条件组合为与关系
query = BaseModel.query.filter(and_(condition1, condition2, condition3))# 或者使用 or_ 方法将多个条件组合为或关系
query = BaseModel.query.filter(or_(condition1, condition2, condition3))# 执行查询
results = query.all()
或者
from sqlalchemy import or_conditions = [User.username == 'user1',User.id > 5,# ...
]query = User.query
query = query.filter(or_(*conditions))users = query.all()
分页查询
SQLAlchemy内部提供了paginate方法来实现分页的功能。
# 分页查询
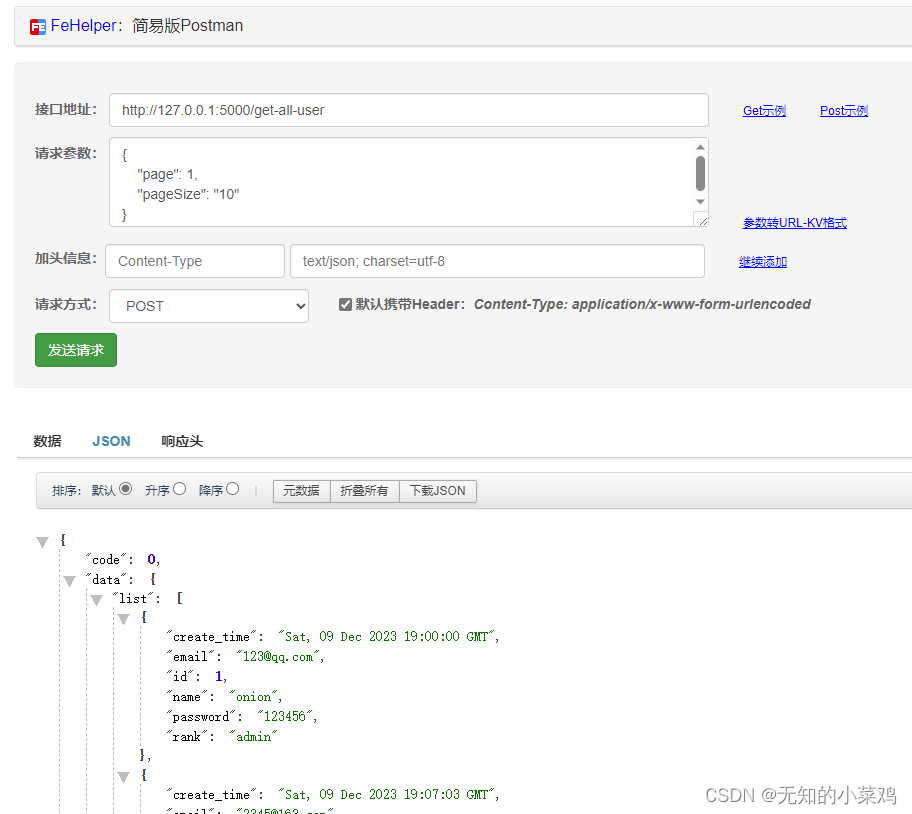
@baseBlue.route("/get-all-user", methods=['POST'])
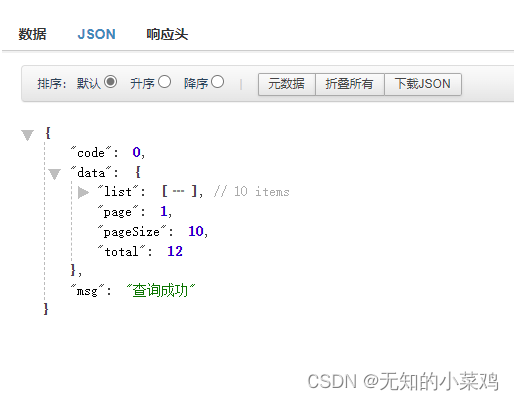
def getAllUser():# 获取前端传递过来的参数page = int(request.form.get("page"))page_size = int(request.form.get("pageSize"))p = BaseModel.query.paginate(page=page, per_page=page_size, error_out=False)# 将模型对象转换为字典data = [item.to_dict() for item in p.items]res = {"code": 0,"data": {"total": p.total,"page": p.page,"pageSize": p.per_page,"list": data},"msg": "查询成功"}return jsonify(res)
paginate对象的属性:
items:返回当前页的内容列表has_next:是否还有下一页has_prev:是否还有上一页next(error_out=False):返回下一页的Pagination对象prev(error_out=False):返回上一页的Pagination对象page:当前的页码(从1)开始pages:总页数pre_page:每页显示的数量prev_num:上一页页码数next_num:下一页页码数total:查询返回的记录总数
多表操作
一对多
学生、班级表
class Grade(db.Model):# 表名__tablename__ = 'grade'# 表结构id = db.Column(db.Integer, primary_key=True, autoincrement=True, doc="主键")name = db.Column(db.String(10), unique=True, nullable=False, doc="班级名称")# 建立联系# 参数1:表名,类的名称,这里要用字符串# 参数2:反向引用的名称,grade对象,让student去反过来得到grade对象的名称# 这样Student表可以直接使用Grade中的字段,而不是使用班级id再去表里查询# 参数3:懒加载# 这里的students不是表字段,是一个类属性students = db.relationship('Student', backref="grade", lazy=dynamic)# 学生表
class Student(db.Model):__tablename__ = 'student'# 字段id = db.Column(db.Integer, primary_key=True, autoincrement=True, doc="主键")name = db.Column(db.String(10), unique=True, nullable=False, doc="学生姓名")grade_id = db.Column(db.Integer, db.ForeignKey('grade.id'), nullable=False, doc="班级id")
lazy属性
lazy属性:懒加载,可以延迟在使用关联属性的时候才建立关联
lazy='dynamic':会返回一个query对象(查询集),可以继续使用其他的查询方法,比如all()lazy='select':首次访问到属性的时候,就会全部加载该属性的数据lazy='joined':在对关联的两个表进行join操作是,从而获取到所有相关的对象lazy=True:返回一个可用的列表对象,同select
增加数据
def addGradeStudent():student = Student()student.name = '张三'student.grade_id = 1try:db.session.add(student)db.session.commit()data = {"code": 0, "data": '', "msg": "添加成功"}except Exception as e:data = {"code": 1, "data": '', "msg": "添加失败"}db.session.rollback() # 回滚db.session.flush() # 清空session
修改、删除操作基本上也与单表操作一致。需要注意的是,比如在删除班级时,这个班级里有学生。删除后学习表里的学生不会被删除,但是学习对应的班级id会变为null
查询
# 查询学生所在班级的班级名称
def getGradeName():try:student = Student.query.get(1)# 这里使用了反向引用,这样就不许要再查询班级表gradeName = student.grade.nameres = {"code": 0, "data": gradeName, "msg": "查询成功"}data = {"code": 0, "data": res, "msg": "查询成功"}except Exception as e:data = {"code": 1, "data": '', "msg": "查询失败"}print("getGradeName error:"+str(e))
# 查询班级下的所有学生grade = Grade.query.get(1)students = grade.students
多对多
多对多需要创建一个中间表,比如用户收藏电影,需要有用户表、收藏表、电影表,收藏表就是这个中间表。
用户表、电影表、收藏表
# 用户表
class User(db.Model):__tablename__ = 'user'id = db.Column(db.Integer, primary_key=True, autoincrement=True, doc="主键")username = db.Column(db.String(10), unique=True, nullable=False, doc="用户名")# 类属性,不是表字段。collections = db.relationship("Collection", back_populates="user")# 电影表
class movie(db.Model):__tablename__ = 'movie'id = db.Column(db.Integer, primary_key=True, autoincrement=True, doc="主键")name = db.Column(db.String(10), unique=True, nullable=False, doc="电影名称")score = db.Column(db.Float, nullable=False, doc="评分")collections = db.relationship("Collection", back_populates="movie")# 收藏表
class Collection(db.Model):id = db.Column(db.Integer, primary_key=True,doc="主键")user_id = db.Column(db.Integer, db.ForeignKey("user.id"),doc="用户id")movie_id = db.Column(db.Integer, db.ForeignKey("movie.id"),doc="电影id")user = db.relationship("User", back_populates="collections")movie = db.relationship("Movie", back_populates="collections")
back_populates 是 SQLAlchemy 关系的一个参数,用于指定两个模型之间的双向关联关系。当在一个模型类中定义了一个关系并指定了另一个模型类时,back_populates 参数允许你在另一个模型类中定义一个相反方向的关系。
与 backref 不同,back_populates 必须在双方都明确声明,而 backref 只需要在一方声明即可自动创建另一方的反向引用。back_populates 更适合于复杂的关系映射和控制反向引用的名称。