Flink CDC 3.0 正式发布,详细解读新一代实时数据集成框架
01
Flink CDC 概述
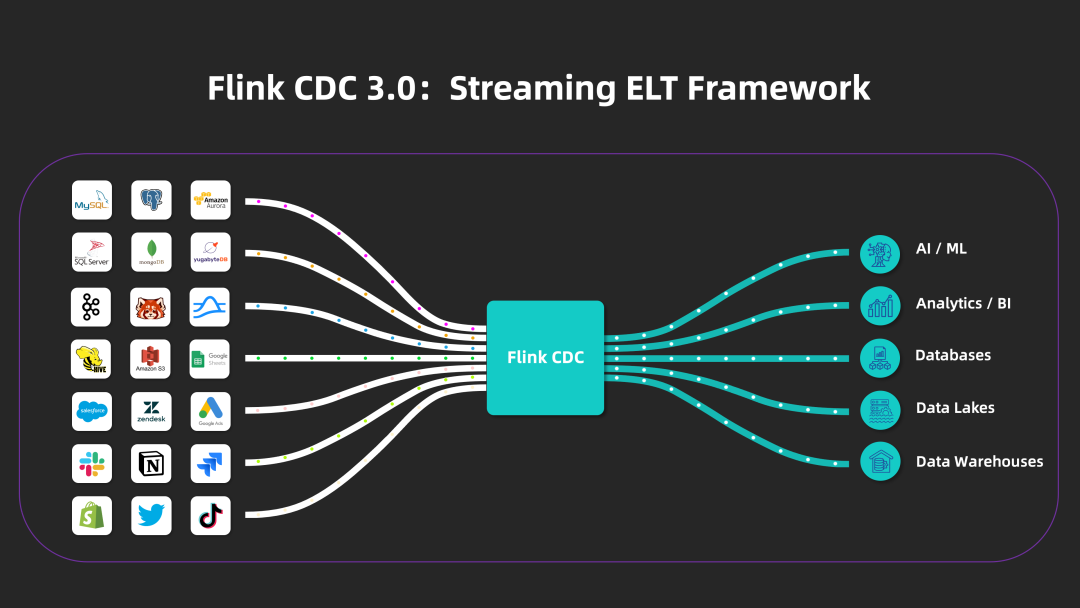
Flink CDC 是基于数据库日志 CDC(Change Data Capture)技术的实时数据集成框架,支持了全增量一体化、无锁读取、并行读取、表结构变更自动同步、分布式架构等高级特性。配合 Flink 优秀的管道能力和丰富的上下游生态,Flink CDC 可以高效实现海量数据的实时集成。Flink CDC 社区发展迅速,在开源的三年时间里,社区已经吸引了 111 位贡献者,培养了 8 位 Maintainer,社区钉钉用户群超过 9800 人。
在社区用户与开发者的共同努力下,Flink CDC 于 2023 年 12 月 7 日重磅推出了其全新的 3.0 版本 [1] ,3.0 版本的发布对 Flink CDC 而言具有里程碑式的意义,自此 Flink CDC 从捕获数据变更的 Flink 数据源正式迈向为以 Flink 为基础的端到端流式 ELT 数据集成框架。在该版本中,社区首先支持实时同步 MySQL 数据至 Apache Doris [2] 和 StarRocks [3] 两条链路。
02
Flink CDC 3.0 设计动机
2.1 Flink CDC 与数据同步面临的挑战
虽然 Flink CDC 有很多技术优势,社区用户增长很快,但随着 Flink CDC 项目用户基数的日益增长,以及应用场景的不断扩大,社区收到了很多用户反馈:
用户体验:只提供 Flink source,不支持端到端数据集成, SQL 和 DS API 构建作业流程复杂
维护频繁:上游数据库表结构变更非常常见 ,增加、删除表的业务需求普遍存在
扩展性:全量和增量阶段资源难以灵活扩缩容 ,千表同步、万表入湖入仓资源消耗大
中立性:项目使用 Apache License V2 协议,不属于 Apache Flink ,版权归属于 Alibaba (Ververica)
针对这些反馈,社区的 Maintainer 也在思考在 Flink CDC 的不足,思考 CDC 乃至数据集成领域面临的技术挑战:
历史数据规模大:数据库的历史数据规模大,100T+ 规模很常见
增量数据实时性要求高:数据库的增量数据业务价值高,且价值随时间递减,需要实时处理
数据的保序性:CDC 数据的加工结果通常需要强一致性语义,需要处理工具支持全局保序
表结构动态变化:增量数据随时间增长,数据对应的表结构会不断演进
在梳理这些问题时,我们也在思考,能否在 Flink CDC 项目中帮助用户解决这些技术挑战?能否为用户打磨一款面向 CDC 和海量数据集成的开源产品?
2.2 Flink CDC 3.0 定位
针对这些想法,我们在 Flink CDC 社区里面与 Maintainer 一起展开了多轮讨论和设计。最终,面向数据集成用户、面向端到端实时数据集成的框架 Flink CDC 3.0 应运而生。在产品设计上我们追求简洁,秉持以下原则和目标进行设计:
端到端体验:Flink CDC 3.0 定位为端到端的数据集成框架,API 设计直接面向数据集成场景,帮助用户轻松构建同步作业
自动化:上游 schema 变更自动同步到下游,已有作业支持动态加表
极致扩展:空闲资源自动回收,一个 sink 实例支持写入多表
推动捐赠:推动 Flink CDC 成为 Apache Flink 的子项目,版权属于中立的 Apache 基金会,吸引更多的公司和开发者参与。
03
Flink CDC 3.0 整体设计
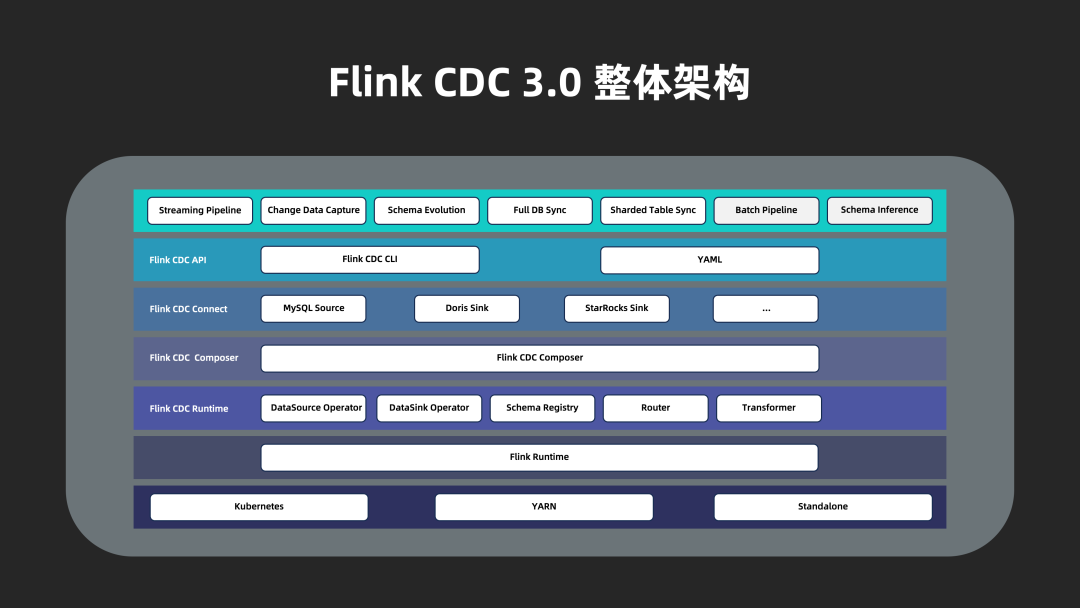
3.1 Flink CDC 3.0 架构
Flink CDC 3.0 的整体架构自顶而下分为 4 层:
Flink CDC API:面向终端用户的 API 层,用户使用 YAML 格式配置数据同步流水线,使用 Flink CDC CLI 提交任务
Flink CDC Connect:对接外部系统的连接器层,通过对 Flink 与现有 Flink CDC source 进行封装实现对外部系统同步数据的读取和写入
Flink CDC Composer:同步任务的构建层,将用户的同步任务翻译为 Flink DataStream 作业
Flink CDC Runtime:运行时层,根据数据同步场景高度定制 Flink 算子,实现 schema 变更、路由、变换等高级功能
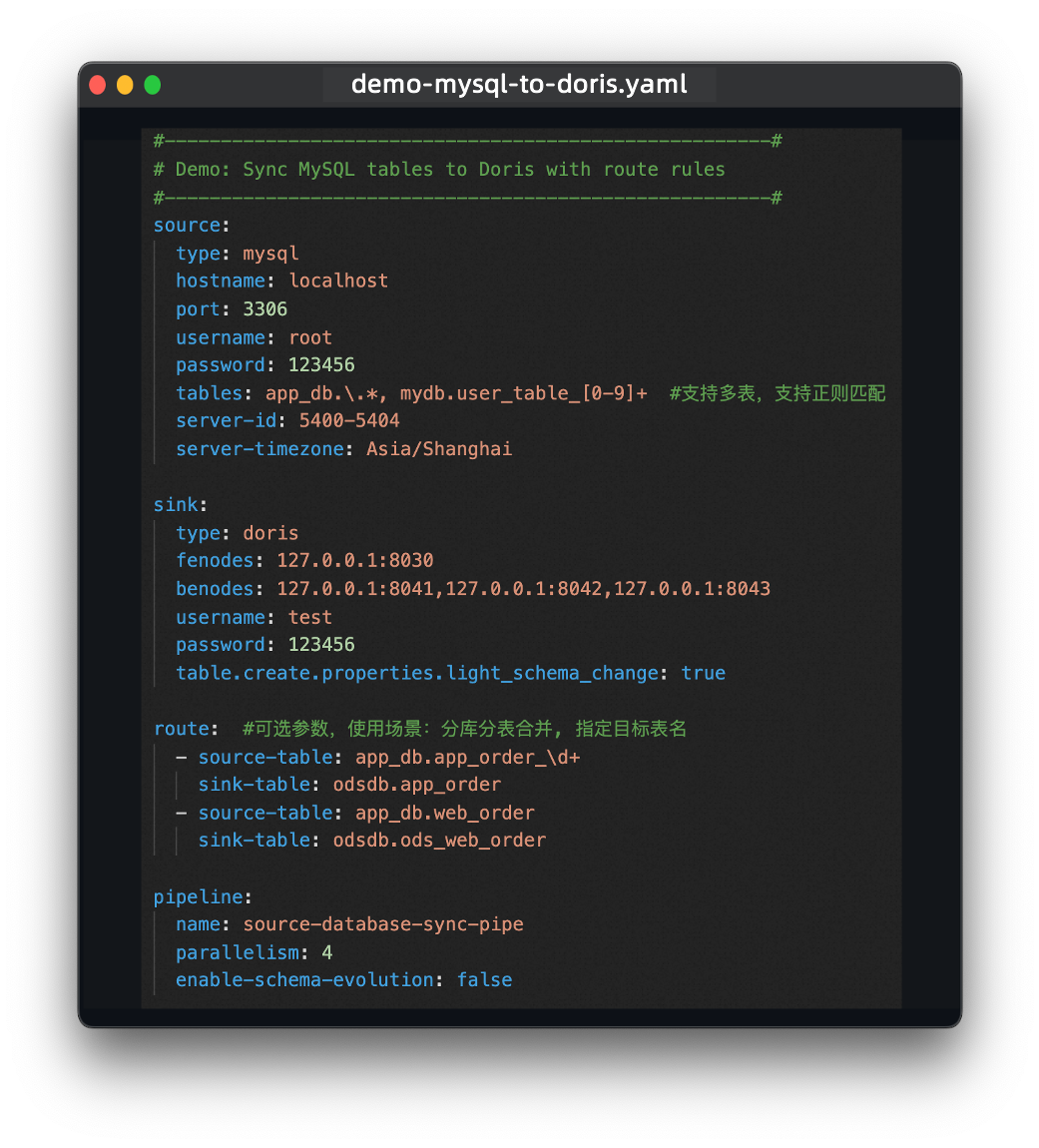
3.2 面向数据集成用户的 API 设计
Flink CDC 3.0 的用户 API 设计专注于数据集成场景,用户无需关注框架实现,只需使用 YAML 格式描述数据来源与目标端即可快速构建一个数据同步任务。以从 MySQL 同步数据至 Apache Doris 为例:
3.3 Pipeline Connector API 设计
为了更好地将外部系统对接至 Flink CDC 3.0 的数据同步流水线,Flink CDC 3.0 定义了 Pipeline Connector API:
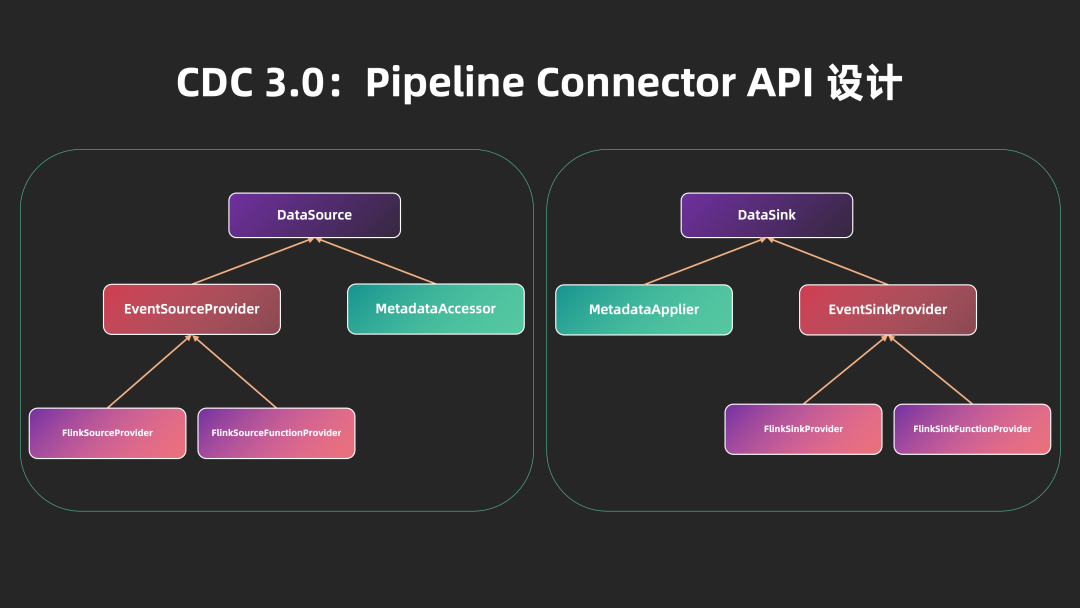
DataSource:Flink CDC 3.0 的数据源,由负责构建 Flink Source 的 EventSourceProvider 和提供元信息读取能力的 MetadataAccessor 组成。DataSource 从外部系统中读取变更事件 Event,并传递给下游算子。
DataSink:Flink CDC 3.0 的数据目标端,由负责构建 Flink Sink 的 EventSinkProvider 和提供对目标端元信息修改能力的 MetadataApplier 构成。DataSink 将上游算子传递来的变更事件 Event 写出至外部系统,MetadataApplier 负责处理上游的 schema 变更信息并应用至外部系统,实现 schema 变更的实时处理。
为尽可能对接 Flink 现有的生态系统,DataSource 和 DataSink 在设计上复用 Flink Source 和 Sink,开发者可以快速基于 Flink connector 对接 Flink CDC 3.0 框架,将外部系统高效地接入 Flink CDC 的上下游生态。在接下来的 Flink CDC 3.1 版本中,社区计划对接 Paimon、Iceberg、Kafka、MongoDB 等外部系统,从而进一步扩大 Flink CDC 的生态与使用场景。
3.4 Flink CDC 3.0 核心设计解析
为了实现 schema 变更、整库同步、分库分表等用户场景的高性能同步,得益于 Flink CDC 社区贡献者对 Apache Flink 项目的深度理解(Flink CDC 项目核心贡献者包含多名 Flink PMC 成员和 Flink Committer),Flink CDC 3.0 不仅在实现上巧妙利用 Apache Flink 提供的各种能力,还通过定制化 Flink 算子等方式实现了各种同步模式的支持。
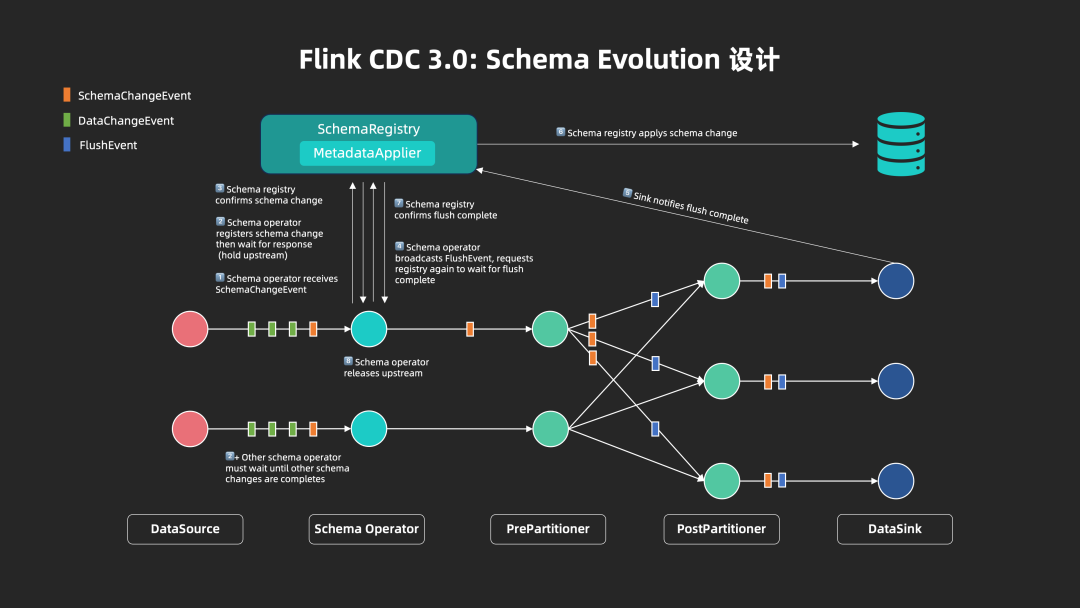
■ 3.4.1 Schema Evolution 设计
Schema 变更处理是上游数据库中十分常见的用户场景,也是数据同步框架实现的难点。针对该场景,Flink CDC 3.0 在作业拓扑中引入了 SchemaRegistry,结合 SchemaOperator 协调并控制作业拓扑中的 schema 变更事件处理。
当上游数据源发生 schema 变更时,SchemaRegistry 会控制 SchemaOperator 以暂停数据流,并将流水线中的数据从 sink 全部刷出以保证 schema 一致性。当 schema 变更事件在外部系统处理成功后,SchemaOperator 恢复数据流,完成本次 schema 变更的处理。
■ 3.4.2 整库同步设计
用户可以在 Flink CDC 3.0 的配置文件中指定 DataSource 同步任务捕获上游多表或整库变更,结合 Schema Evolution 的设计,SchemaRegistry 会在读取到新表的数据后,自动在目标端外部系统建表,实现自动化的数据整库同步。

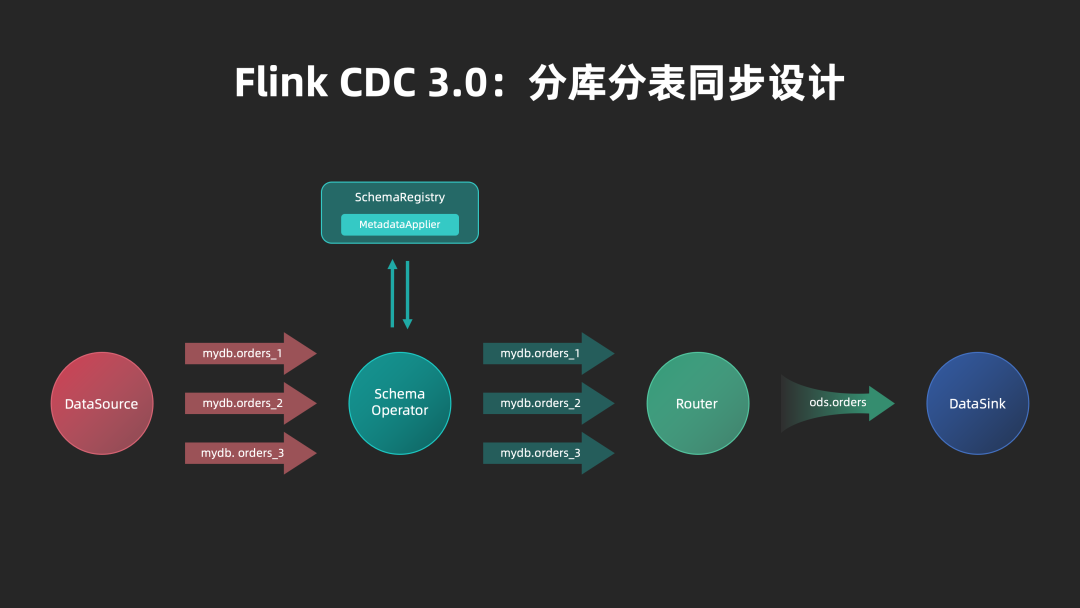
■ 3.4.3 分库分表同步设计
在数据同步中,一个常见的使用场景是将上游由于业务或数据库性能问题而拆分的多表在下游系统合并为一张表。Flink CDC 3.0 使用路由(Route)机制实现分库分表合并的能力。用户可以在配置文件中定义 route 规则使用正则表达式匹配多张上游表,并将其指向同一张目标表,实现分库分表数据的归并。
■ 3.4.4 高性能数据结构设计
为了降低数据在 Flink 作业中流转时产生的额外序列化开销,Flink CDC 3.0 设计了一套高性能数据结构:
变更数据与 Schema 信息的分离:在发送变更数据前,source 先发送 schema 信息对其进行描述并由框架追踪,因此 schema 信息无需绑定在每条变更数据之上,大大降低了在宽表场景下 schema 信息的序列化成本。
二进制存储格式:数据在同步过程中使用二进制存储,并只在需要读取某个字段的详细数据时(如按主键进行分区)再进行反序列化,进一步降低序列化成本。

正是这些核心设计使得 Flink CDC 具备了优秀的端到端数据集成能力,为用户提供了 schema evolution、整库同步、分库分表同步等开箱即用能力,高效的数据结构设计让数据集成作业可以获得更好的性能优势。
总体来说,Flink CDC 3.0 不仅提供基础的数据同步能力,schema 变更自动同步、整库同步、分库分表等增强功能使 Flink CDC 3.0 在更复杂的数据集成与用户业务场景中发挥作用:用户无需在数据源发生 schema 变更时手动介入,大大降低用户的运维成本;只需对同步任务进行简单配置即可将多表、多库同步至下游,并进行合并等逻辑,显著降低用户的开发难度与入门门槛。
04
快速上手 Flink CDC 3.0
保持之前社区一贯的优秀习惯,Flink CDC 社区提供了详细的用户文档,包括CDC 3.0 架构和核心概念介绍 [4],同时提供了 MySQL 同步至 Apache Doris [5]、MySQL 同步至 StarRocks [6] 的快速上手教程帮助用户快速体验。社区也提供了 demo,用户可以通过以下 demo 了解 Flink CDC 3.0 的极简开发体验:
【DEMO 视频】
05
致谢
感谢 Flink CDC 用户对社区的反馈和信赖,特别感谢 Apache Doris [2] 和 StarRocks [3] 社区和开发者对 Flink CDC 3.0 版本的支持,由衷感谢为 Flink CDC 3.0 版本贡献的每一位开发者,贡献者列表如下(按字母排序):
BIN, Dian Qi, EchoLee5, FlechazoW, FocusComputing, Hang Ruan, He Wang, Hongshun Wang, Jiabao Sun, Josh Mahonin, Kunni, Leonard Xu, Maciej Bryński, Malcolmjian, North.Lin, Paddy Gu, PengFei Li, Qingsheng Ren, Shawn Huang, Simonas Gelazevicius, Sting, Tyrantlucifer, TJX2014, Xin Gong, baxinyu, chenlei677, e-mhui, empcl, gongzhongqiang, gaotingkai, ice, joyCurry30, l568288g, lvyanquan, pgm-rookie, rookiegao, skylines, syyfffy, van, wudi, wuzhenhua, yunqingmo, yuxiqian, zhaomin, zyi728, zhangjianFlink CDC 项目由阿里巴巴旗下的 Ververica 公司使用 Apache License V2 协议开源,项目版权属于 Ververica。目前阿里巴巴和 Flink CDC 社区已经发起了将 Flink CDC 项目捐赠给 Apache Flink 社区的讨论 [7],捐赠完成之后,Flink CDC 项目的版权将会属于中立的 Apache 基金会, Flink CDC 也能与 Apache Flink 进行更深度的集成,在为用户提供更好的实时数据集成体验的同时扩展 Apache Flink 的社区生态,感兴趣的开发者可以关注 Flink 社区的讨论邮件。
参考
[1] Flink CDC 3.0 release notes:
https://github.com/ververica/flink-cdc-connectors/releases/tag/release-3.0.0
[2] Apache Doris:
https://doris.apache.org/
[3] StarRocks:
https://www.starrocks.io/
[4] CDC 3.0 架构和核心概念介绍:
https://ververica.github.io/flink-cdc-connectors/release-3.0/content/overview/cdc-pipeline.html
[5] MySQL 同步至 Apache Doris:
https://ververica.github.io/flink-cdc-connectors/release-3.0/content/%E5%BF%AB%E9%80%9F%E4%B8%8A%E6%89%8B/mysql-doris-pipeline-tutorial-zh.html
[6] MySQL 同步至 StarRocks:
https://ververica.github.io/flink-cdc-connectors/release-3.0/content/%E5%BF%AB%E9%80%9F%E4%B8%8A%E6%89%8B/mysql-starrocks-pipeline-tutorial-zh.html
[7] 将 Flink CDC 项目捐赠给 Apache Flink 社区的讨论:
https://lists.apache.org/thread/o7klnbsotmmql999bnwmdgo56b6kxx9l
Flink Forward Asia 2023
本届 Flink Forward Asia 更多精彩内容,可点击「阅读原文」或扫描图片二维码在线阅读全部议题 PPT ~

关注 Apache Flink 公众号,回复 FFA 2023 即可获取演讲 PPT 在线阅读地址
▼ 关注「Apache Flink」,获取更多技术干货 ▼

 点击「阅读原文」,直达 FFA 2023 演讲 PPT 合集列表~
点击「阅读原文」,直达 FFA 2023 演讲 PPT 合集列表~