PostgreSQL 作为向量数据库:入门和扩展
PostgreSQL 拥有丰富的扩展和解决方案生态系统,使我们能够将该数据库用于通用人工智能应用程序。本指南将引导您完成使用 PostgreSQL 作为向量数据库构建生成式 AI 应用程序所需的步骤。
我们将从pgvector 扩展开始,它使 Postgres 具有特定于向量数据库的功能。然后,我们将回顾增强在 PostgreSQL 上运行的 AI 应用程序的性能和可扩展性的方法。最后,我们将拥有一个功能齐全的生成式人工智能应用程序,向前往旧金山旅行的人推荐 Airbnb 房源。
Airbnb的推荐服务
该示例应用程序是住宿推荐服务。想象一下,您计划访问旧金山,并希望住在金门大桥附近的一个不错的街区。您访问该服务,输入提示,应用程序将建议三个最相关的住宿选项。
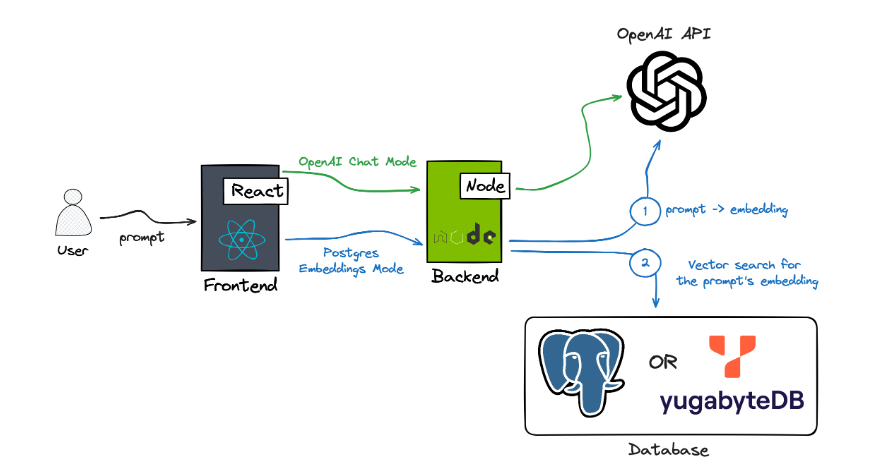
该应用程序支持两种不同的模式:
-
OpenAI 聊天模式:在此模式下,Node.js 后端利用OpenAI 聊天完成 API和 GPT-4 模型根据用户的输入生成住宿推荐。虽然此模式不是本指南的重点,但我们鼓励您尝试一下。
-
Postgres Embeddings 模式:最初,后端使用OpenAI Embeddings API将用户的提示转换为嵌入(文本数据的矢量化表示)。接下来,该应用程序在 Postgres 或 YugabyteDB(分布式 PostgreSQL)中进行相似性搜索,以查找与用户提示匹配的 Airbnb 属性。Postgres 利用 pgvector 扩展在数据库中进行相似性搜索。本指南将深入研究该特定模式在应用程序中的实现。
先决条件
-
可以访问嵌入模型的OpenAI订阅。
-
最新的Node.js 版本
-
最新版本的Docker
使用 Pgvector 启动 PostgreSQL
pgvector 扩展将向量数据库的所有基本功能添加到 Postgres 中。它允许您存储和处理具有数千个维度的向量,计算向量化数据之间的欧几里德距离和余弦距离,并执行精确和近似最近邻搜索。
1. 在 Docker 中使用 pgvector 启动 Postgres 实例:
docker run --name postgresql \-e POSTGRES_USER=postgres -e POSTGRES_PASSWORD=password \-p 5432:5432 \-d ankane/pgvector:latest
2. 连接到数据库容器并打开 psql 会话:
docker exec -it postgresql psql -h 127 .0.0.1 -p 5432 -U postgres3.启用pgvector扩展:
create extension vector;4. 确认向量存在于扩展列表中:
select * from pg_extension;oid | extname | extowner | extnamespace | extrelocatable | extversion | extconfig | extcondition
-------+---------+----------+--------------+----------------+------------+-----------+--------------13561 | plpgsql | 10 | 11 | f | 1.0 | |16388 | vector | 10 | 2200 | t | 0.5.1 | |
(2 rows)加载 Airbnb 数据集
该应用程序使用 Airbnb 数据集,其中包含旧金山列出的 7,500 多个出租房产。每个列表都提供了详细的属性描述,包括房间数量、设施类型、位置和其他功能。该信息非常适合根据用户提示进行相似性搜索。
按照以下步骤将数据集加载到启动的 Postgres 实例中:
1. 克隆应用程序存储库:
git clone https://github.com/YugabyteDB-Samples/openai-pgvector-lodging-service.git2. 将 Airbnb 架构文件复制到 Postgres 容器(将 替换{app_dir}为应用程序目录的完整路径):
docker cp {app_dir}/sql/airbnb_listings.sql postgresql:/home/airbnb_listings.sql3.从下面的 Google Drive 位置下载包含 Airbnb 数据的文件。文件大小为 174MB,前提是它已包含使用 OpenAI 嵌入模型为每个 Airbnb 房产的描述生成的嵌入。
4. 将数据集复制到 Postgres 容器(将 替换{data_file_dir}为应用程序目录的完整路径)。
docker cp {data_file_dir}/airbnb_listings_with_embeddings.csv postgresql:/home/airbnb_listings_with_embeddings.csv5. 创建 Airbnb 架构并将数据加载到数据库中:
# Create schemadocker exec -it postgresql \psql -h 127.0.0.1 -p 5432 -U postgres \-a -q -f /home/airbnb_listings.sql# Load datadocker exec -it postgresql \psql -h 127.0.0.1 -p 5432 -U postgres \-c "\copy airbnb_listing from /home/airbnb_listings_with_embeddings.csv with DELIMITER '^' CSV;"
每个 Airbnb 嵌入都是一个 1536 维浮点数数组。它是 Airbnb 房产描述的数字/数学表示。
docker exec -it postgresql \psql -h 127.0.0.1 -p 5432 -U postgres \-c "\x on" \-c "select name, description, description_embedding from airbnb_listing limit 1"# Truncated output
name | Monthly Piravte Room-Shared Bath near Downtown !3
description | In the center of the city in a very vibrant neighborhood. Great access to other parts of the city with all modes of public transportation steps away Like the general theme of San Francisco, our neighborhood is a melting pot of different people with different lifestyles ranging from homeless people to CEO''s
description_embedding | [0.0064848186,-0.0030366974,-0.015895316,-0.015803888,-0.02674906,-0.0083198985,-0.0063770646,0.010318241,-0.011003947,-0.037981577,-0.008783566,-0.0005710134,-0.0028015983,-0.011519859,-0.02011404,-0.02023159,0.03325347,-0.017488765,-0.014902675,-0.006527267,-0.027820067,0.010076611,-0.019069154,-0.03239144,-0.013243919,0.02170749,0.011421901,-0.0044701495,-0.0005861153,-0.0064978795,-0.0006775427,-0.018951604,-0.027689457,-0.00033081227,0.0034317947,0.0098349815,0.0034775084,-0.016835712,-0.0013787586,-0.0041632145,-0.0058219694,-0.020584237,-0.007386032,0.012486378,0.012473317,0.005815439,-0.010990886,-0.015111651,-0.023366245,0.019069154,0.017828353,0.030249426,-0.04315376,-0.01790672,0.0047444315,-0.0053419755,-0.02195565,-0.0057338076,-0.02576948,-0.009769676,-0.016914079,-0.0035232222,...嵌入是使用 OpenAI 的text-embedding-ada-002模型生成的。如果您需要使用不同的模型,那么:
-
{app_dir}/backend/embeddings_generator.js 更新和{app_dir}/backend/postgres_embeddings_service.js文件中的模型
-
通过使用node embeddings_generator.js命令启动生成器来重新生成嵌入。
查找最相关的 Airbnb 房源
至此,Postgres 已准备好向用户推荐最相关的 Airbnb 房产。应用程序可以通过将用户的提示嵌入与 Airbnb 描述的嵌入进行比较来获取这些推荐。
首先,启动 Airbnb 推荐服务的实例:
1. 使用您的 OpenAI API 密钥更新{app_dir}/application.properties.ini :
OPENAI_API_KEY=<your key>2.启动Node.js后端:
cd {app_dir}npm icd backendnpm start
3.启动React前端:
cd {app_dir}/frontendnpm inpm start
应用程序 UI 应在您的默认浏览器中自动打开。否则,在地址http://localhost:3000/打开。
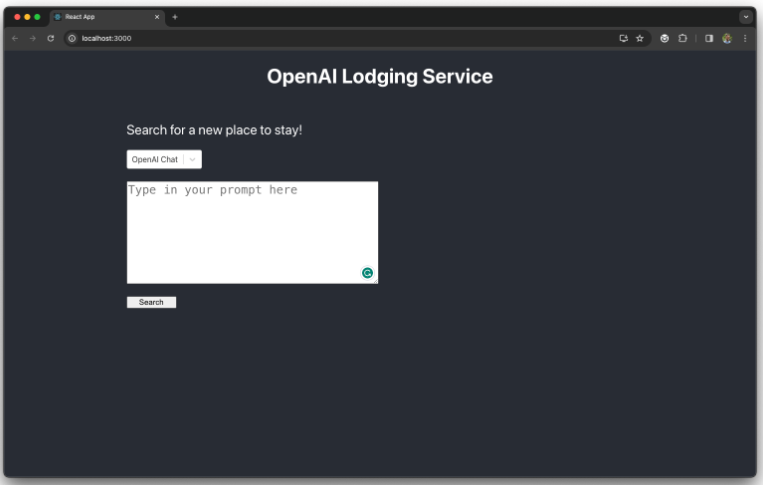
现在,从应用程序 UI 中选择Postgres Embeddings模式,并要求应用程序推荐一些与以下提示最相关的 Airbnb 房源:
I'm looking for an apartment near the Golden Gate Bridge with a nice view of the Bay.该服务将推荐三种住宿选择:
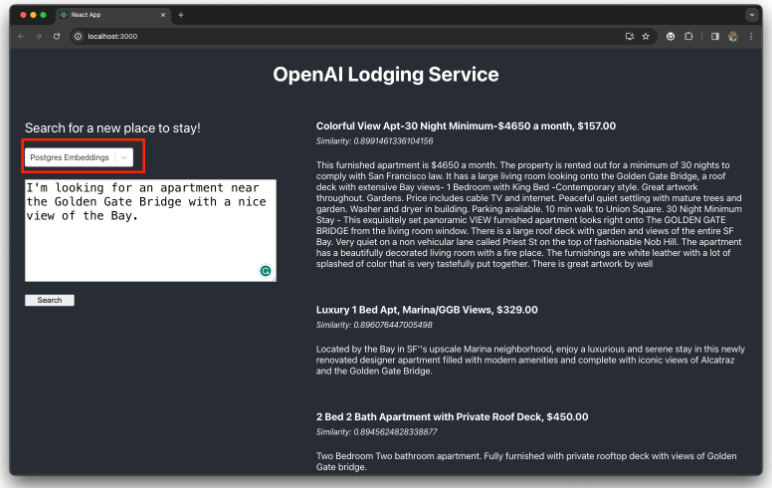
在内部,应用程序执行以下步骤来生成建议({app_dir}/backend/postgres_embeddings_service.js有关详细信息,请参阅 ):
1. 应用程序使用 OpenAI Embeddings 模型生成用户提示的矢量化表示 ( text-embedding-ada-002):
const embeddingResp = await this.#openai.embeddings.create({model: "text-embedding-ada-002",input: prompt});
2. 应用程序使用生成的向量来检索存储在 Postgres 中最相关的 Airbnb 属性:
const res = await this.#client.query("SELECT name, description, price, 1 - (description_embedding <=> $1) as similarity " +"FROM airbnb_listing WHERE 1 - (description_embedding <=> $1) > $2 ORDER BY description_embedding <=> $1 LIMIT $3",['[' + embeddingResp.data[0].embedding + ']', matchThreshold, matchCnt]);相似度计算为description_embedding列中存储的嵌入与用户提示向量之间的余弦距离。
3. 建议的 Airbnb 属性以 JSON 格式返回到 React 前端:
let places = [];for (let i = 0; i < res.rows.length; i++) {const row = res.rows[i];places.push({"name": row.name, "description": row.description, "price": row.price, "similarity": row.similarity });
}return places;扩展的方法
目前,Postgres 存储了 7,500 多个 Airbnb 房产。数据库需要几毫秒的时间来执行精确的最近邻搜索,比较用户提示和 Airbnb 描述的嵌入。
然而,精确最近邻搜索(全表扫描)有其局限性。随着数据集的增长,Postgres 将需要更长的时间来对多维向量执行相似性搜索。
为了在数据量和流量不断增加的情况下保持 Postgres 的性能和可扩展性,您可以使用矢量化数据的专用索引和/或使用Postgres 的分布式版本水平扩展存储和计算资源。
pgvector 扩展支持多种索引类型,包括性能最好的 HNSW 索引(分层可导航小世界)。该索引对矢量化数据执行近似最近邻搜索 (ANN),使数据库即使在数据量很大的情况下也能保持较低且可预测的延迟。然而,由于搜索是近似的,搜索的召回率可能不是 100% 相关/准确,因为索引仅遍历数据的子集。
例如,以下是如何在 Postgres 中为 Airbnb 嵌入创建 HNSW 索引:
CREATE INDEX ON airbnb_listingUSING hnsw (description_embedding vector_cosine_ops)WITH (m = 4, ef_construction = 10);
借助分布式 PostgreSQL,当单个数据库服务器的容量不再充足时,您可以轻松扩展数据库存储和计算资源。尽管 PostgreSQL 最初是为单服务器部署而设计的,但其生态系统现在包含多个扩展和解决方案,使其能够在分布式配置中运行。其中一个解决方案是 YugabyteDB,这是一种分布式 SQL 数据库,它扩展了 Postgres 的分布式环境功能。
YugabyteDB 从 2.19.2 版本开始支持 pgvector 扩展。它将数据和嵌入分布在节点集群中,促进大规模的相似性搜索。因此,如果您希望 Airbnb 服务在 Postgres 的分布式版本上运行:
1. 部署多节点YugabyteDB集群。
2. 更新文件中的数据库连接设置{app_dir}/application.properties.ini:
# Configuration for a locally running YugabyteDB instance with defaults.DATABASE_HOST=localhostDATABASE_PORT=5433DATABASE_NAME=yugabyteDATABASE_USER=yugabyteDATABASE_PASSWORD=yugabyte
3. 从头开始加载数据(或使用 YugabyteDB Voyager 从正在运行的 Postgres 实例迁移数据)并重新启动应用程序。不需要进行其他代码级别的更改,因为 YugabyteDB 的功能和运行时与 Postgres 兼容。
作者:Denis Magda
更多技术干货请关注公号【云原生数据库】
squids.cn,云数据库RDS,迁移工具DBMotion,云备份DBTwin等数据库生态工具。
irds.cn,多数据库管理平台(私有云)。