构建自己的私人GPT
创作不易,请大家多鼓励支持。
在现实生活中,很多人的资料是不愿意公布在互联网上的,但是我们又要使用人工智能的能力帮我们处理文件、做决策、执行命令那怎么办呢?于是我们构建自己或公司的私人GPT变得非常重要。

一、本地部署PrivateGPT
快速本地安装步骤:
1. 克隆存储库:
git clone
git clone https://github.com/imartinez/privateGPT
文件目录
2. 安装 Python :
pyenv install 3.11
pyenv local 3.11(如果报错可以直接安装python3.11)
系统之前已经安装过3.10的旧版本,为了避免干扰需要从系统变量path中删除:C:\Program Files\Python310\Scripts\;C:\Program Files\Python310\
3. 安装依赖:
poetry install --with ui,local
4. 下载嵌入和 LLM 模型:
poetry run python scripts/setup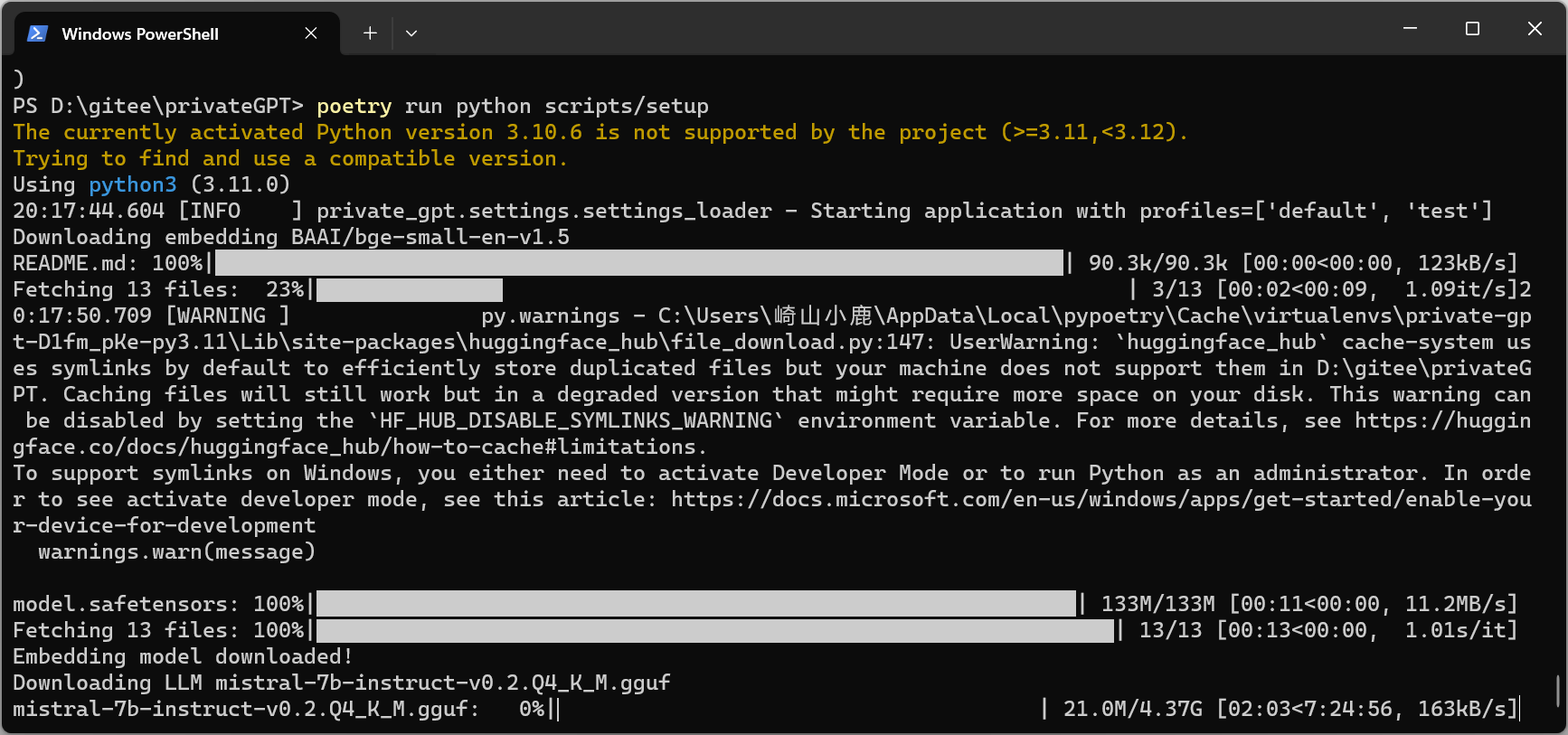


5. (可选,在powershell中运行)启用GPU:
$env:CMAKE_ARGS='-DLLAMA_CUBLAS=on'; poetry run pip install --force-reinstall --no-cache-dir llama-cpp-python6. 运行本地服务器:
set PGPT_PROFILES=local
poetry run python -m private_gpt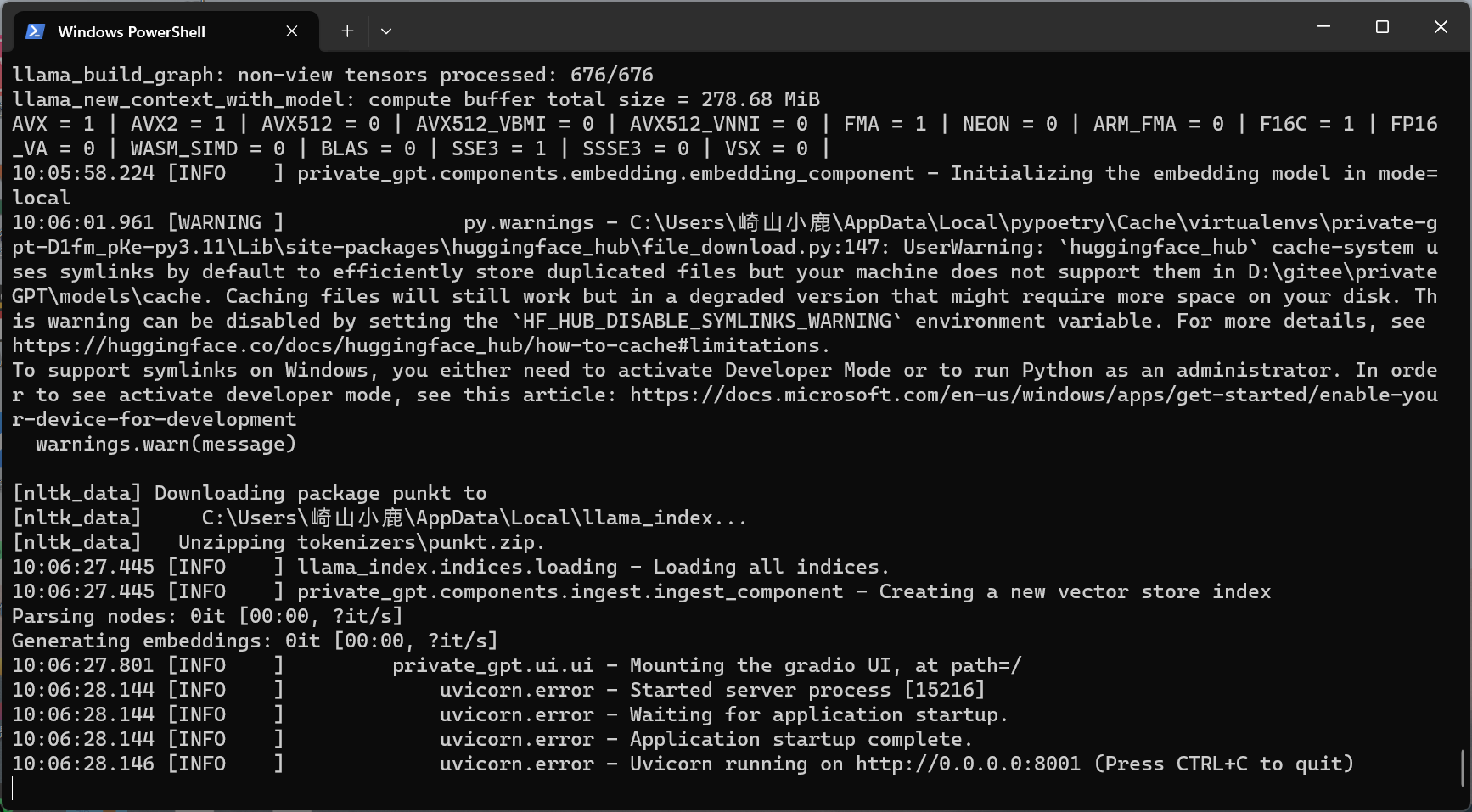
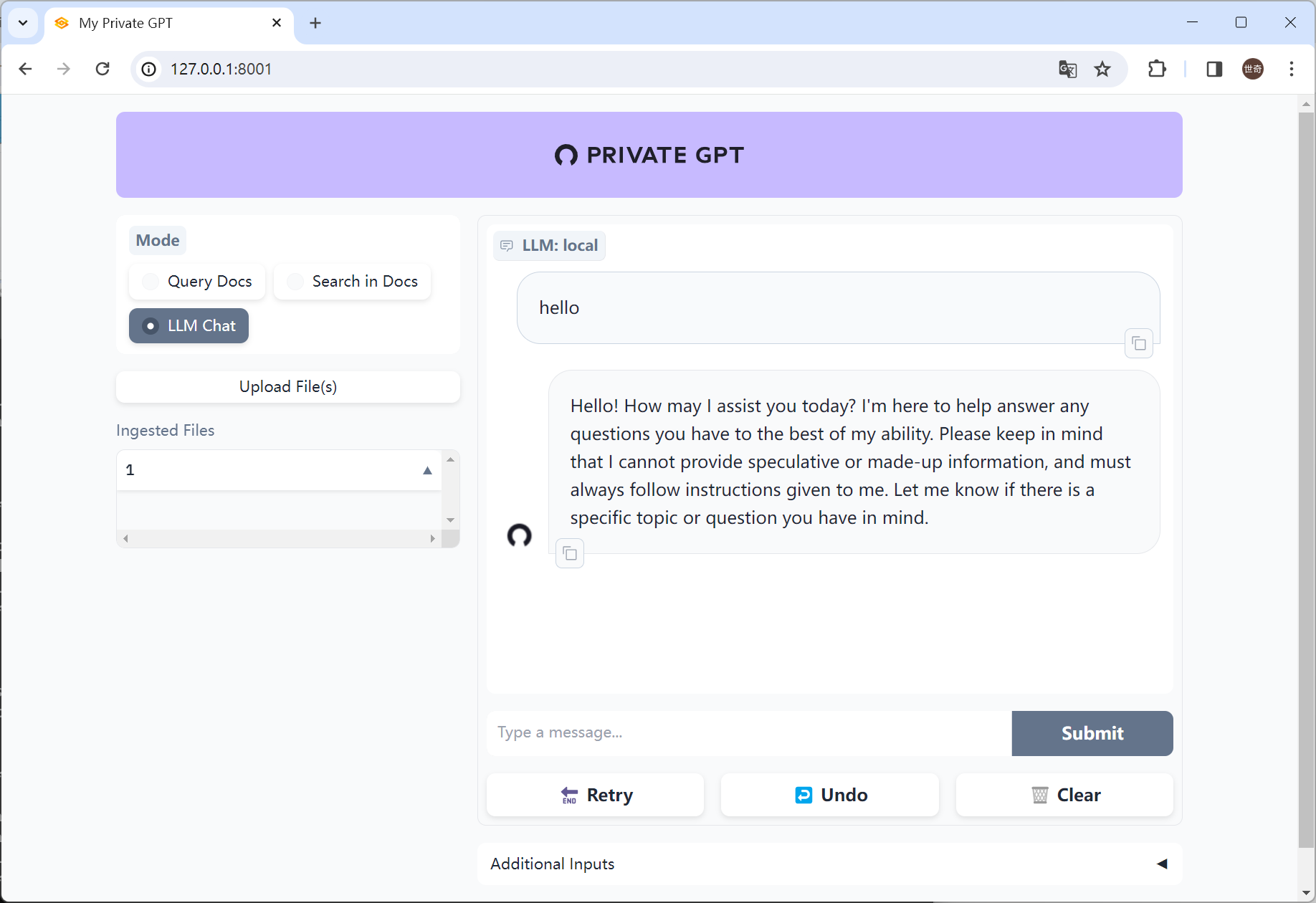
7. 导航到 UI:在浏览器中打开 http://localhost:8001/。
二、对GPT3.5进行微调
将数据接入GPT需要遵循以下步骤:
1. 收集数据:通过各种方式收集需要用来训练GPT的数据,包括文本、图片、语音等。
2. 清洗数据:对收集到的数据进行清洗、去重、去噪、标注等处理,确保数据质量和准确性。
3. 数据格式转换:将收集到的数据按照GPT所需的格式进行转换,例如将文本数据转换成json格式,或将图片和语音数据转换成tensor格式。
4. 数据上传:将处理后的数据上传到GPT平台,可以使用云存储等方式进行上传,确保数据传输的速度和稳定性。
5. 训练模型:通过GPT平台提供的训练接口,训练自己的模型。在训练模型的过程中,调整超参数、优化算法、监控模型性能等。
6. 模型部署:训练完成后,将模型部署到生产环境中,以供实际应用。需要注意的是,为了保护数据的安全性,需要采取一系列的措施,如数据加密、权限控制、访问审计等,防止数据泄漏和滥用。同时,也需要保证数据的合法性和版权问题,遵守相关的法律法规和道德规范。
首先,我们需求准备数据集。为了锻炼ChatGPT模型,我们需求一个大型的文本数据集,其中包含大量的对话和文本对话。我们能够运用现有的公开数据集,如Common Crawl或Wikipedia,也能够本人构建数据集。
接下来,我们需求将数据集转换为模型能够运用的格式。这通常触及到将文本转换为数字向量,以便模型能够学习从文本到数字的映射。我们能够运用现有的工具,如Word2Vec或FastText,将文本转换为向量。
然后,我们需求定义模型架构。ChatGPT是一个序列到序列的模型,其中输入是一个句子,输出是另一个句子。我们能够运用现有的深度学习框架,如PyTorch或TensorFlow,来定义模型架构。
3.5只支持4096个token的限制
更多资料:
创建自己的私人GPT