Transformer - Attention is all you need 论文阅读
虽然是跑路来NLP,但是还是立flag说要做个project,结果kaggle上的入门project给的例子用的是BERT,还提到这一方法属于transformer,所以大概率读完这一篇之后,会再看BERT的论文这个样子。
在李宏毅的NLP课程中多次提到了RNN, Cycle RNN, LSTM也简单在这里做一个总结(其实在课程上是在ML的课上介绍的)。因此这里大概分成几个部分:
1. 重听ML中RNN和LSTM的部分
2. 做一下总结
3. 像简单搭CNN一样试着搭一下网络
4. Attention is all you need论文阅读
5. (可能的)代码复现
Recurrent Neural Network
看了一下课程的标题,怎么感觉新的里面已经没在讲了(或者即使是讲也倾向于一笔带过)。理解,毕竟现在已经是LLM的天下了,看到2023版里面全是LLM,实火啊。
这里依然采用的是3年前看的视频(真正的回看,真正的复习×)
视频链接:Recurrent Neural Network (Part I)_哔哩哔哩_bilibili
引入
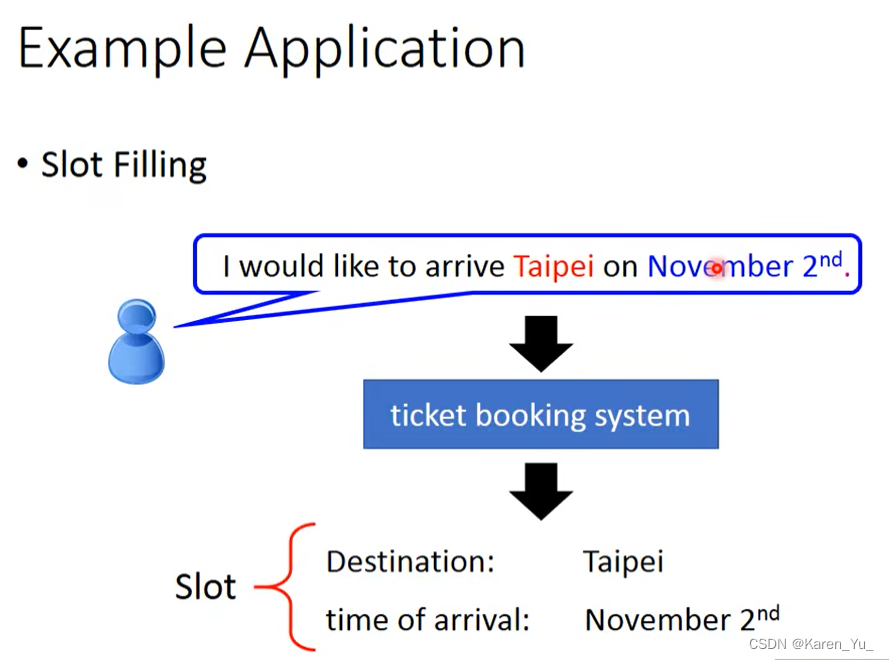
这里举了一个例子,slot filling。假设我们要做一个订票系统,我们告诉系统我们想在11月2日去台北,那么我们就需要知道每一个词汇属于哪一个slot。比如在这里我们需要知道台北属于目的地,11月2日是到达日期。
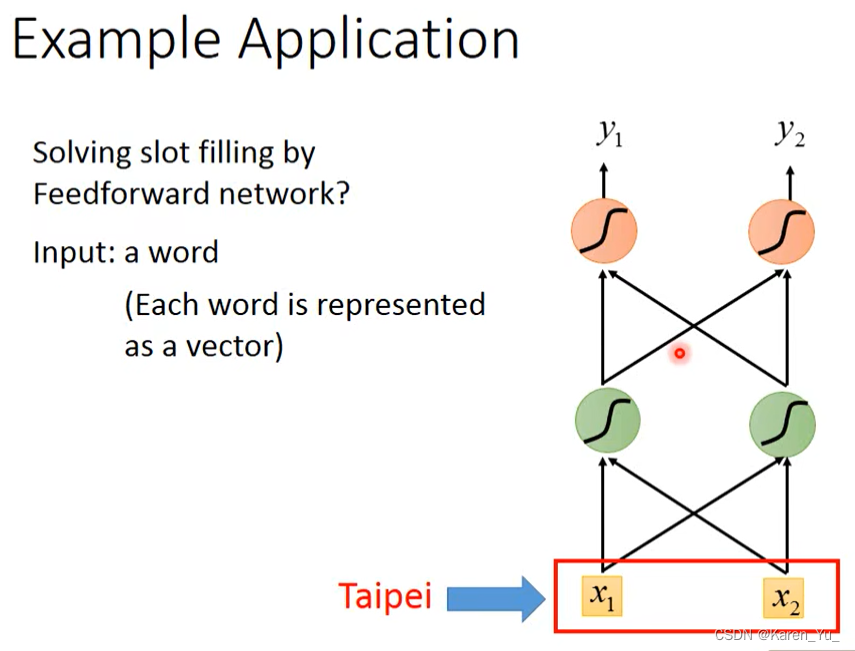
当然,仍然可以用前馈神经网络来解决。这里就是把台北丢进网络(需要变成一个向量),那么怎么把单词变成向量呢?

最简单的策略就是1-of-N encoding。除了字典里的词汇,还需要加一个other(因为会遇到没见过的词->不在词典里的词)。
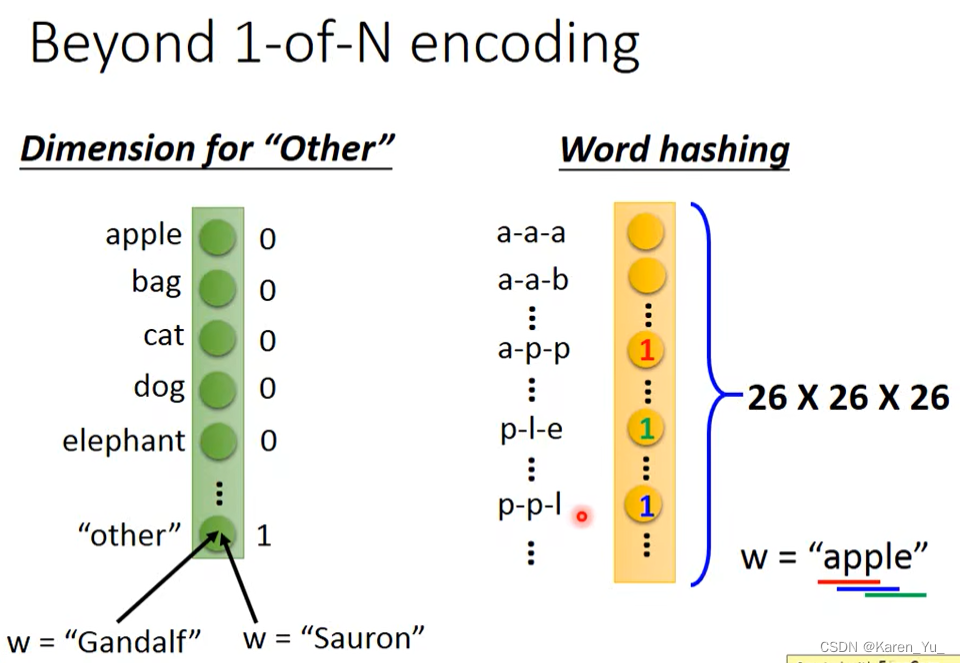
也可以用某一个词汇的n-gram。比如这里,有一个词是Apple,我们统计里面每一段出现的次数。
什么是n-gram,引用一下nlp课程的PPT。(不过感觉这里好像定义的不一样(很有可能是对token的选择不一样,这里显然用的是character))
怎么估测token sequence的概率呢?在DL出现之前,最常用的方法是N-gram。收集大量的文字,然后看这个token sequence出现的概率有多高。但是人类的句子非常复杂,因此随便给一个token sequence在资料中出现的次数可能是0,但是并不代表这种sequence的概率就是0。因此把这个概率拆解成比较小的概率相乘。
上面例子中这种给定一个词汇看下一个词汇出现的概率为2-gram,自然也可以扩展至3-gram,4-gram。


RNN

OK,无论什么办法,反正我们现在是得到了一个vector,我们把这个vector丢进去,希望输出一个概率,表示输入的这个词属于某个slot的概率。比如这里就是输出台北属于destination, time of arrival的概率。

但是仅仅这样是不够的。比如这时候我们又来了一个用户,说“要在11月2日离开台北”,那么这个时候台北就不是目的地,而是出发地了。但是这又是同一个词,只能要不是出发地的概率高,要不就是目的地的概率高。
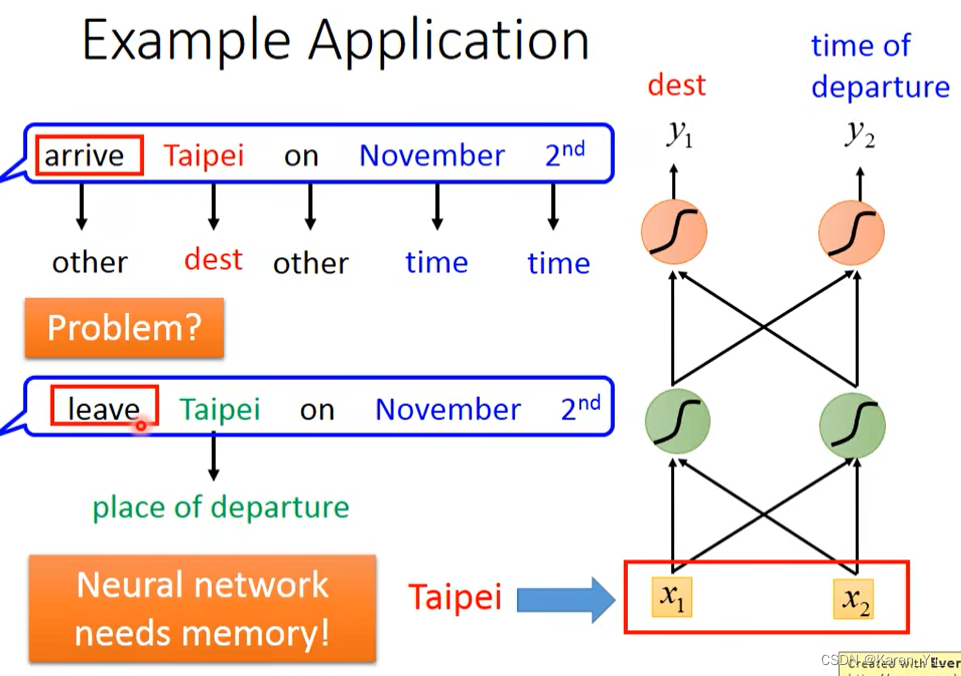
这个时候,我们就希望网络是有记忆的。如果网络在看到台北的时候,能记住前面看到的是离开/到达,根据上下文,产生不同的output。
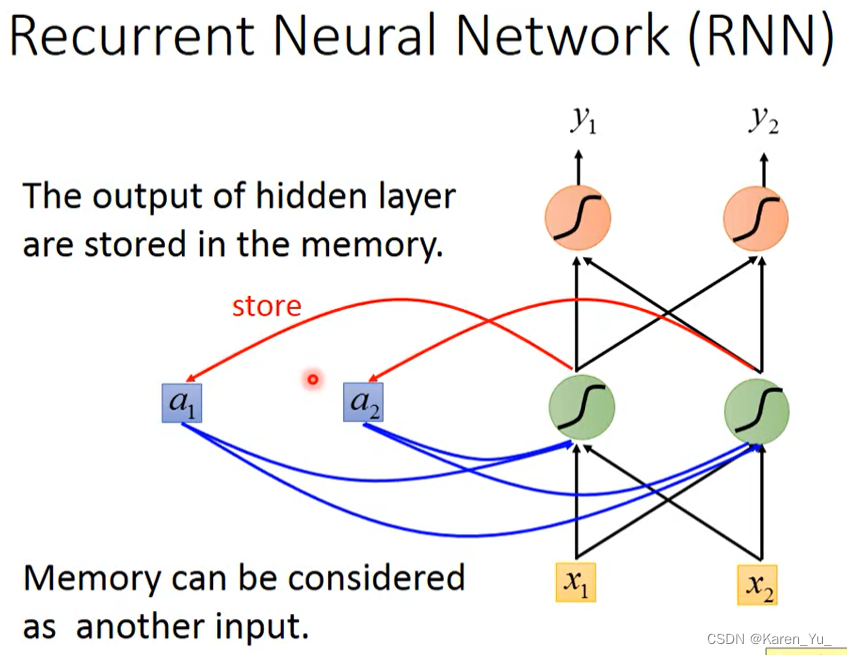
这种有记忆的network就被称为recurrent neural network(RNN)。
在RNN里面,每一次hidden layer里面的neuron产生output的时候,这个output都会被存到memory里面去。下一个input来的时候,neuron不仅会考虑input的x1 x2,还会考虑存在memory里面的值a1 a2。
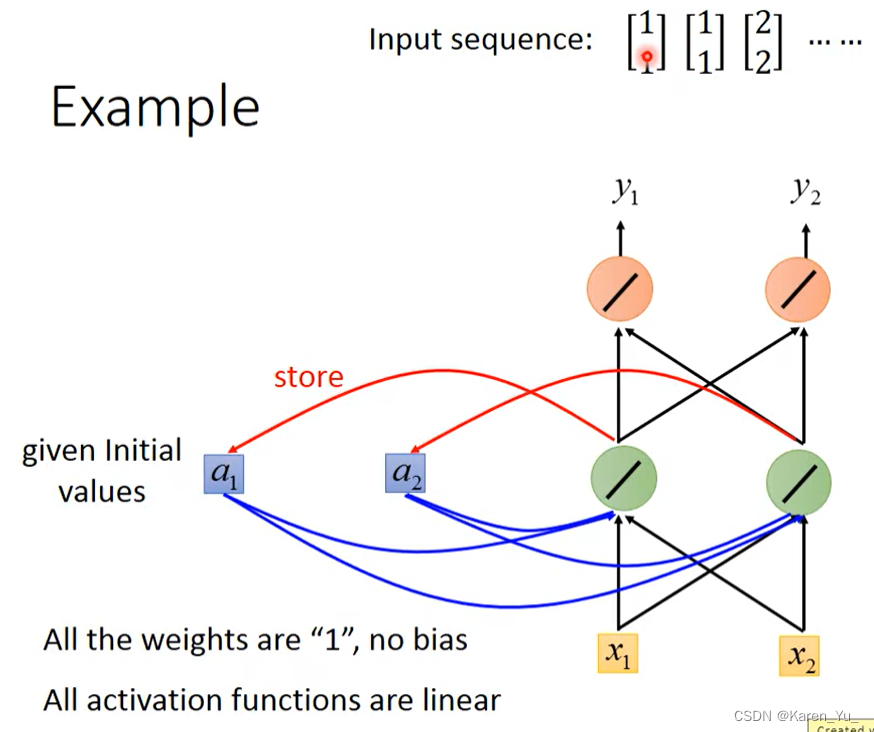
举例:假设上图中这个network所有的weight都是1,所有的neuron都没有bias,所有的激活函数都是线性的。假设我们的input是一个sequence。
在使用RNN之前,我们首先要给memory一个初始值。

在还没有放任何东西进来的时候,给一个初始值,假设是0。
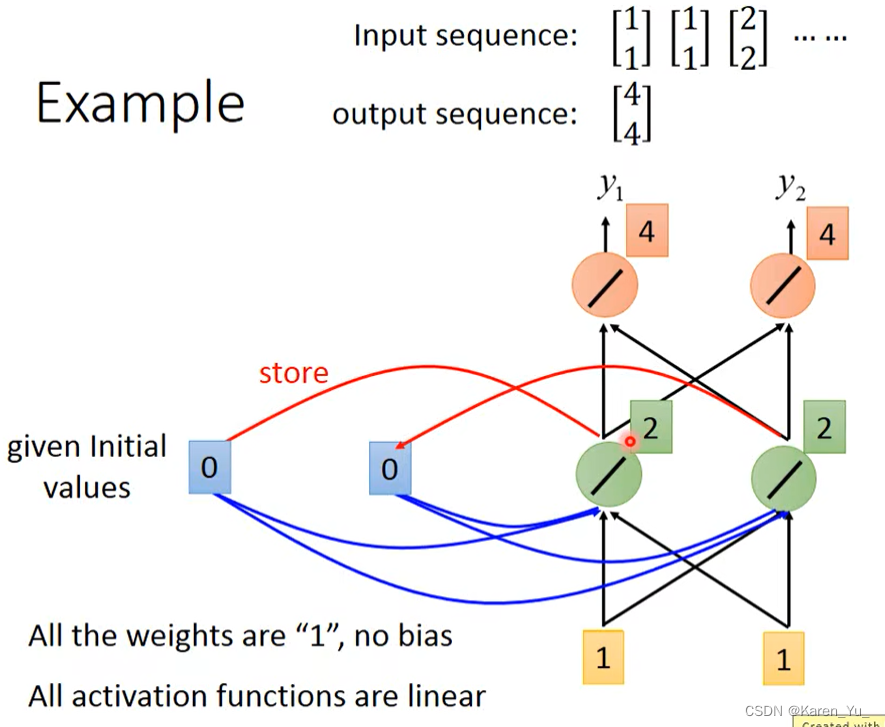
现在我们放进去第一个输入,[1, 1]。对于neuron来说,除了接到input的[1, 1]之外,还接到了memory的[0, 0]。因为这里设置的是所有的weight都是1,所以neuron的output就是2(w1*x1+w1*x2=2),所以橙色的output就是4。

接下来RNN会把绿色的neuron的output存到memory里面,这样memory里面的值就被update成2。

接下来再输入[1, 1],此时绿色的neuron的输入有4个(两个来自input的1和两个来自memory的2),因为这里采用的weight=1且没有bias,所以此时的结果是6(1+1+2+2),最后橙色的neuron的输出就是12(6+6)。
对于RNN来说,就算给的是一样的东西(比如这里两次输入的都是[1,1],最后的output都可能是不一样的,因为存在memory里面的值是不一样的)。
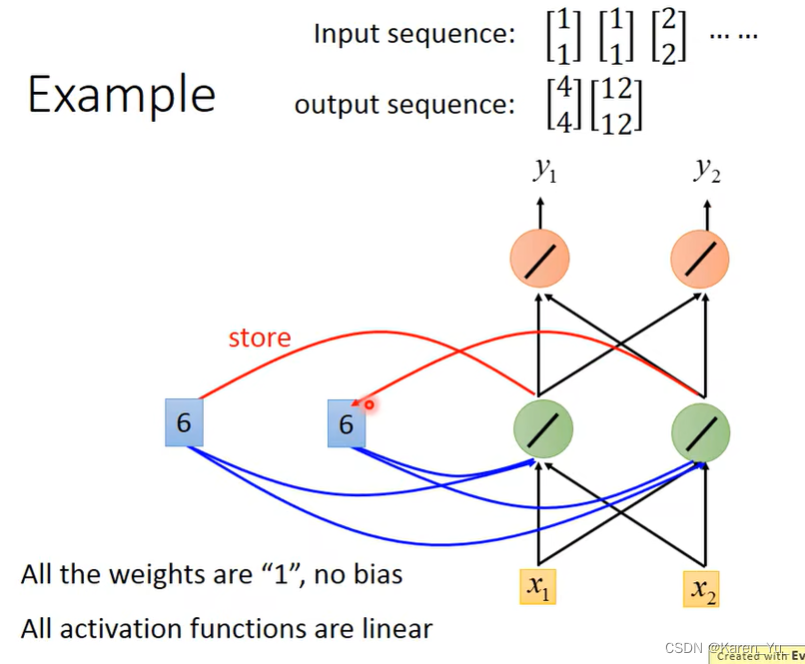
接下来,把绿色neuron里面的6存到memory里面去。
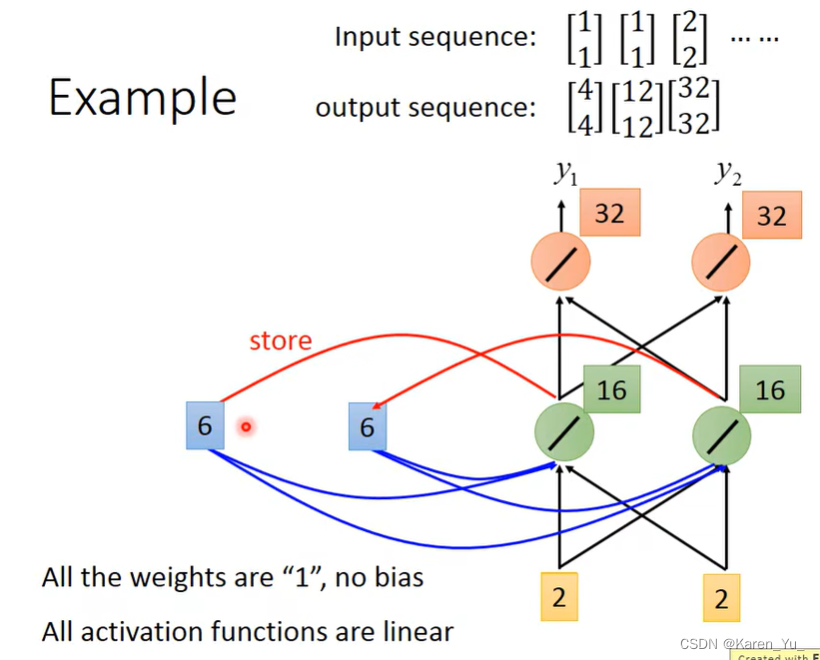
接下来的input是[2, 2],此时这个绿色的neuron考虑的也是四个input(两个来自input,两个来自memory),得到的值是16(6+6+2+2)。橙色的neuron的output是32(16+16)。
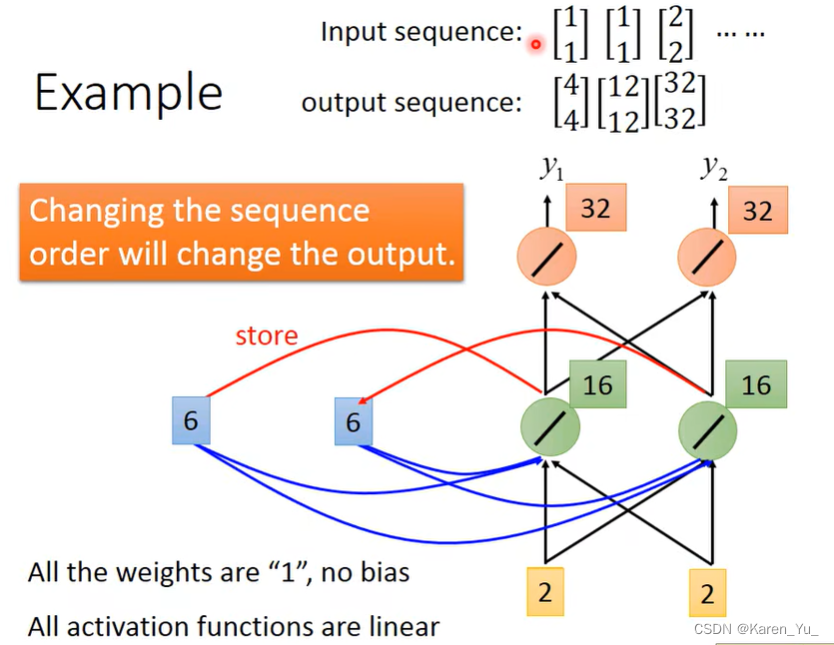
在做RNN的时候要考虑一件事,RNN在考虑input的sequence的时候并不是independent。如果任意调换sequence的顺序,比如把[2,2]挪到前面,那么output就完全不一样了。所以在RNN里面会考虑input的sequence的顺序。


如果这样,我们之前提出的那个问题就有可能解决(因为leave和arrive显然会提供不同的memory)。
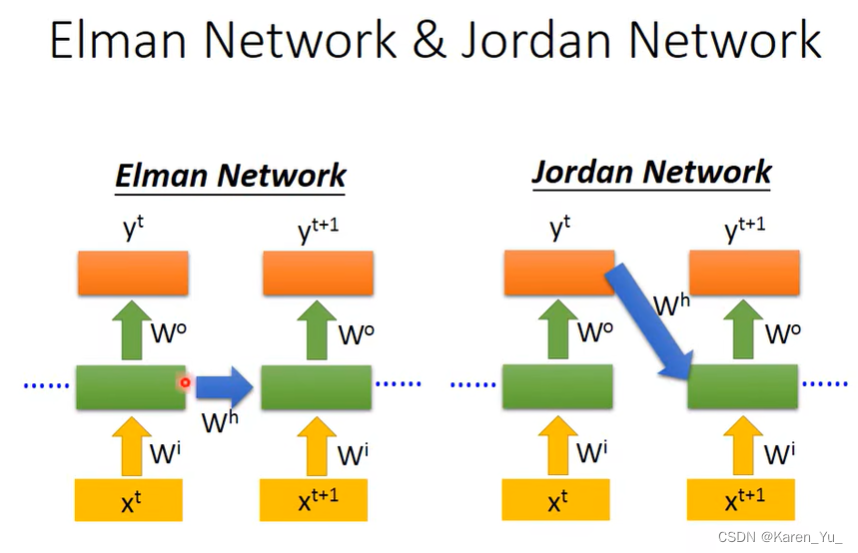
前面的例子中展示的网络为elman network(hidden layer的值存memory,下一次再读memory)。还有另外一种称为Jordan network,此时memory存的是整个network output的值,在下一个时间点再把output的值读进来。
一般认为Jordan network的表现要优于elman network,因为hidden layer里的输出是没有target的,但是Jordan network存的是最后的输出,这里是由target的,也就是我们清楚的知道存在memory里面的是什么东西。
Bidirectional RNN

RNN也可以是双向的。刚刚的例子里,当我们读入一个句子的时候,采用的方法就是从句首读到句尾。假设句子里的每一个词汇都用x^t来表示,就是先读x^t再读x^(t+1)再读x^(t+2)。但是实际上读取方向也可以是反过来的,先读x^(t+2)再读x^(t+1)再读x^t。
我们可以同时train一个正向的RNN和一个逆向的RNN,把他们的hidden layer拿出来,都接到一个output layer。
这么做的好处是,在产生output的时候,看的范围会比较广。假设只有正向的RNN,那么我们的网络只看过当前位置之前的所有的input,如果采用bidirectional RNN,就也含有句尾到当前位置的信息(弹幕在开玩笑说山东人看了很亲切哈哈)。
Long Short-term Memory (LSTM)
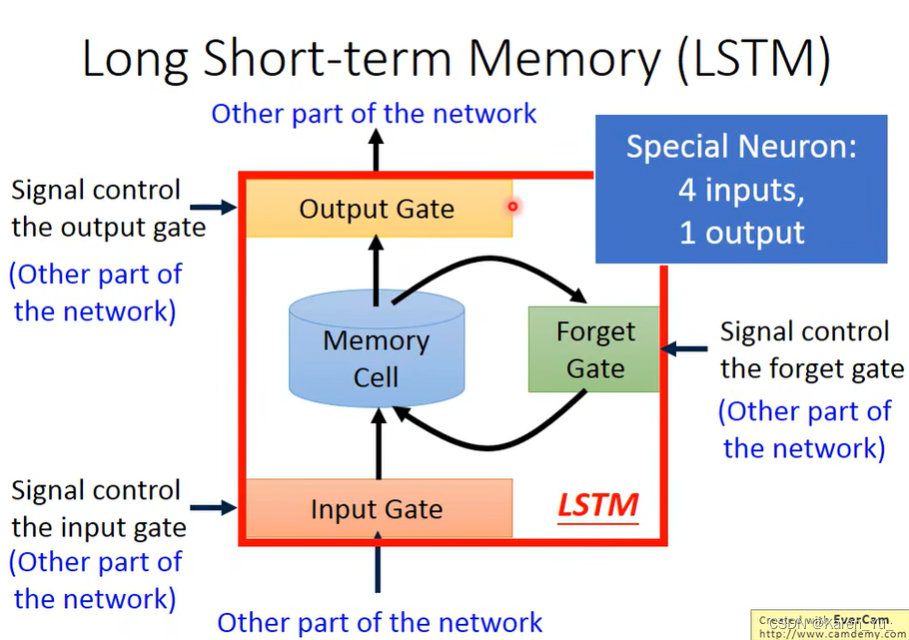
前面介绍的RNN,只是比较简单的版本,可以把值从memory里读进去,也可以把memory里把值读出来。现在比较常用的memory是long short-term memory(LSTM,本质上还是short-term memory,只是比较长的short-term memory)。
这种memory是比较复杂的,它有三个gate。当某个neuron的output想被写到memory cell里面的时候,必须先通过一个input gate。这个input gate只有打开的情况下,才能把值写进memory cell里,如果是关闭的状态,其他的neuron就没办法把值写进去,至于这个门是打开还是关闭,这是让network自己学习的。
输出的地方也有一个output gate,这个output gate决定是外界的其他neuron可不可以从这个memory里面把值读出来,什么时候打开也是network自己学习的。
第三个gate是forget gate,决定什么时候memory要把过去记得的东西忘掉,什么时候学,什么时候忘,也是network自己学的。
这里可以认为整个LSTM有四个input(1. 想要被存到memory cell里面的值(但是不一定存进去)2. 操控input gate的信号 3. 操控output gate的信号 4. 操控forget gate的信号),一个output(输出)。
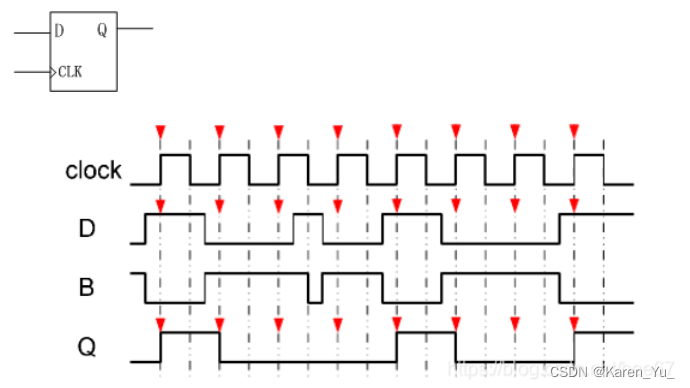
此处我回忆的是之前学的D触发器,找了个图,大致看一下:
什么时候值发生变化,首先是clock上升沿,其次,可以看出B要是低电平。感觉还是很类似的。


假设在输入之前,已经存了值c。

我们首先把Z通过一个激活函数得到g(Z),Z_i通过另一个激活函数得到f(z_i)(f这里通常激活函数会选择sigmoid function->0到1之间,这个值代表了gate被打开的程度)。接下来就把g(Z)乘上f(z_i)。z_f也通过这个sigmoid function得到f(z_f),接下来把存在memory里面的值c乘上f(z_f),接下来:
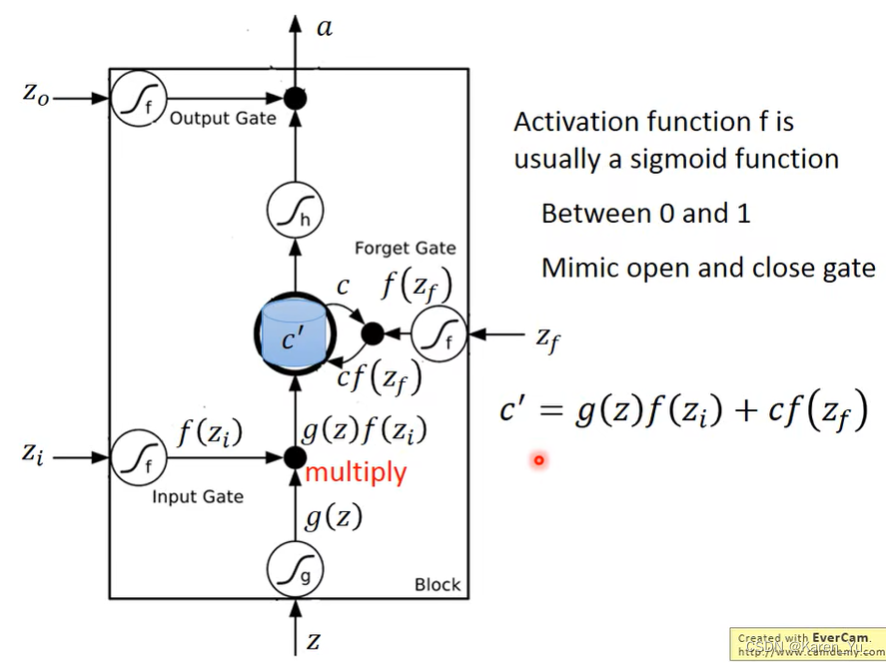
c'就是新的存在memory里面的值
如果f(z_i) = 0,那么输入一乘就还是0,等于没输入,如果f(z_i) = 1,就好像直接把g(z)当做输入一样。同理f(z_f)也决定要不要留下c,一旦为0,就直接把过去存在memory里面的值变成0了。在这里相当于forget gate被打开的时候其实是记住,被关闭的时候实际上才是遗忘。

c'通过h得到h(c'),还有一个output gate,这个output gate受z_o操纵,1or0,如果是1表示h(c')可以output,否则就是0(没办法读取)

举例:假设network里面只有一个LSTM的cell,input都是三维的vector,output都是一维的vector。output和memory里面的关系是:假设第二个dimension是1的时候,x1的值就会被写到memory里,是-1的时候就会被reset(memory里面的值会被遗忘),假设x3=1的时候,才会把output打开,才能看到输出。
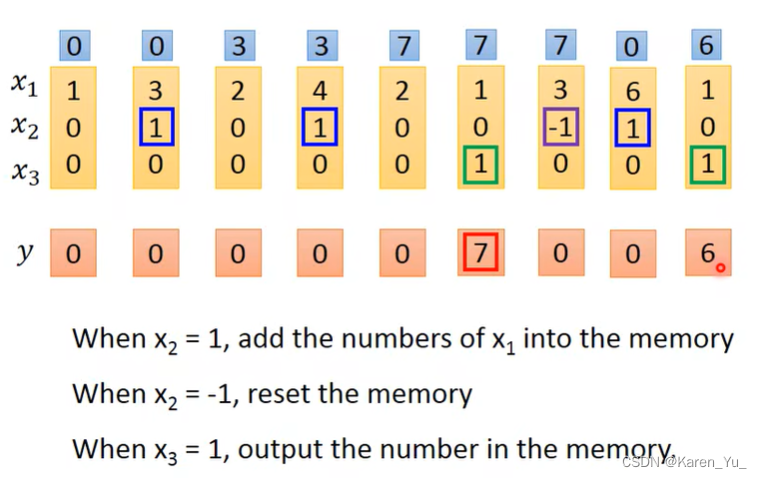
假设我们一开始memory里面存的值是0。
第二列里x2=1,也就是可以把第二列的x1放进memory里面->memory里面的值变成3
第四列里x2=1,把此刻x1放入memory->memory里面的值变成7(3+4)
第六列里x3=1,把此刻memory里的值输出->输出7(但是memory没有接到reset指令,仍然保持7)
第七列里x2=-1,把memory里面的值洗掉->memory变成0
第八列里x2=1,把此刻的x1放入memory->memory里面的值变成6(0+6)
第九列里x3=1,把此刻memory里面的值输出->输出6
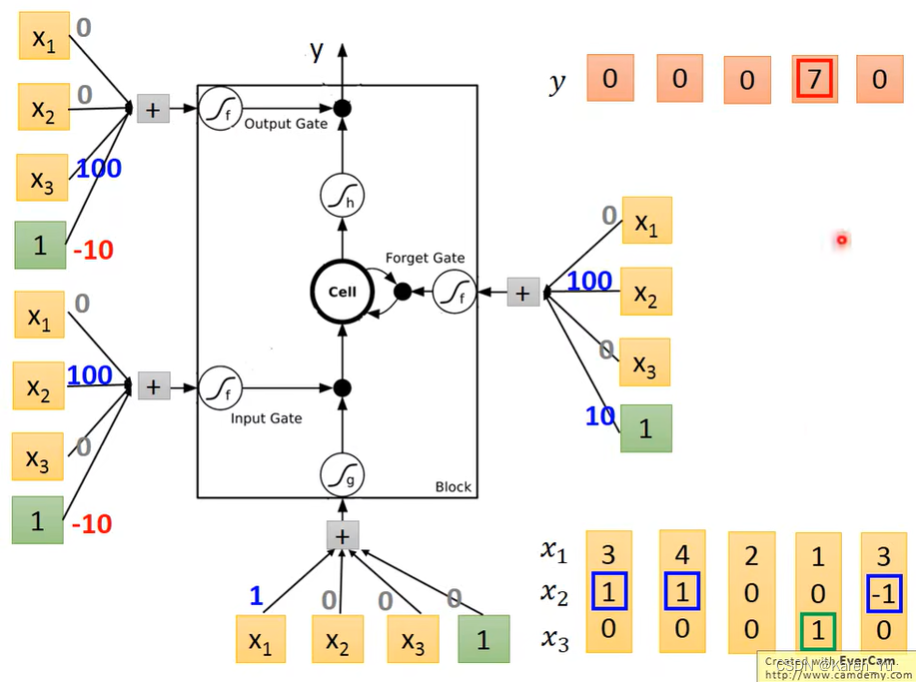
现在看具体的cell
这里input的值是前面例子中的三维的vector乘一个linear的transform(乘上weight),再加上bias,就得到input。这里的weight和bias是可以通过gradient descend学到的。
我们在这里假设我们已经知道这些weight和bias了。
input这里x1*1,其他都是0,就是相当于直接把x1当做input。
input gate这里x2*100-10,如果x2没有值的时候,就是-10(就是bias),也就是说平时这个input gate都是被关闭的,只有在x2有值的时候,才能把门打开。
类似的forget gate平时都是被打开的,只有在x2给一个比较大的负值的时候,才会把门关上(注意,打开->记住cell里面的值,关闭->忘记cell里面的值)。
output gate平时都是关闭的(-10),如果x3给一个比较大的正值的时候,才会把门打开。

假设g和h都是linear的。
假设cell里面存的初始值是0。
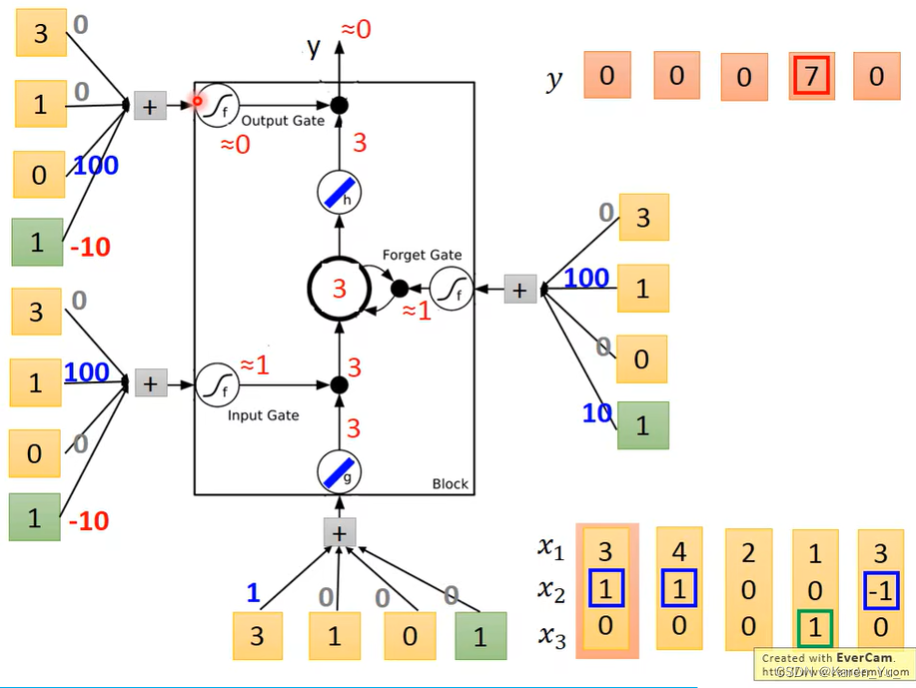
现在我们输入第一个vector[3, 1, 0]。input gate被打开,forget gate被打开(记住),0*1+1*3=3->存在memory里面的值变成3,output gate是被关闭的(不让输出),所以此时输出是0。
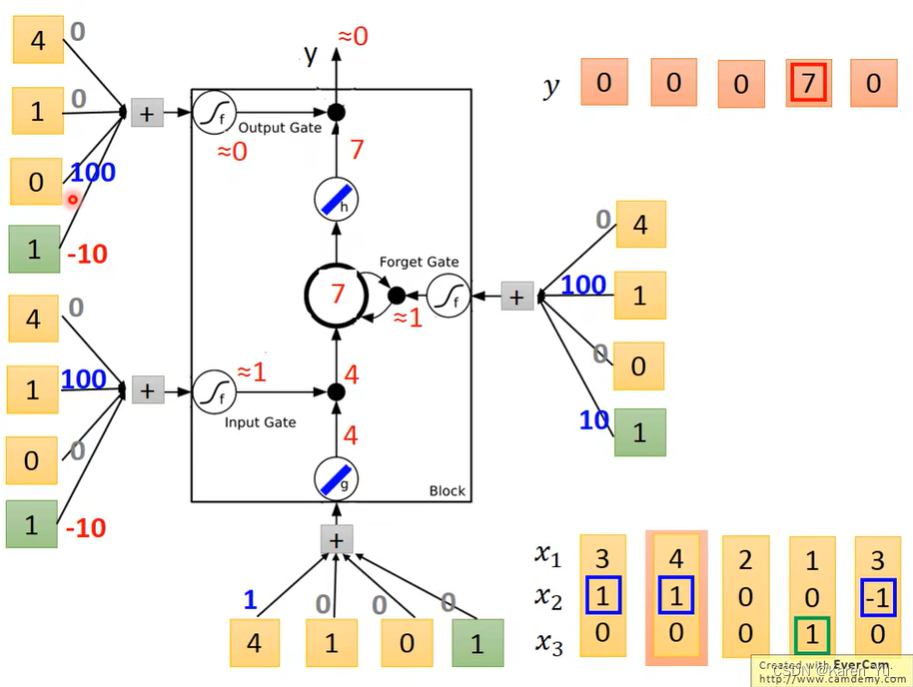
接下来进来[4,1,0],input gate打开,forget gate打开,3*1+1*4=7,存在memory里的值变为7,output gate仍然关闭,输出0.
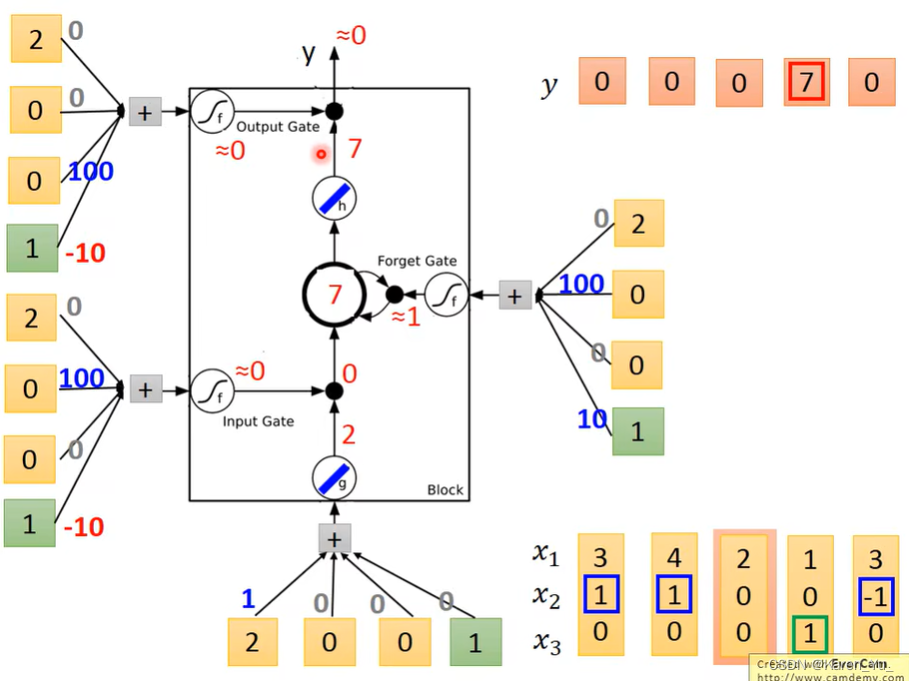
接下来进来[2,0,0]不让输入,2*0+7*1=7,保持,不允许输出,输出0

接下来进来[1,0,1],input gate关闭,memory gate打开,1*0+7*1=7,output gate被打开,输出7(7*1,这里1是output gate的状态)
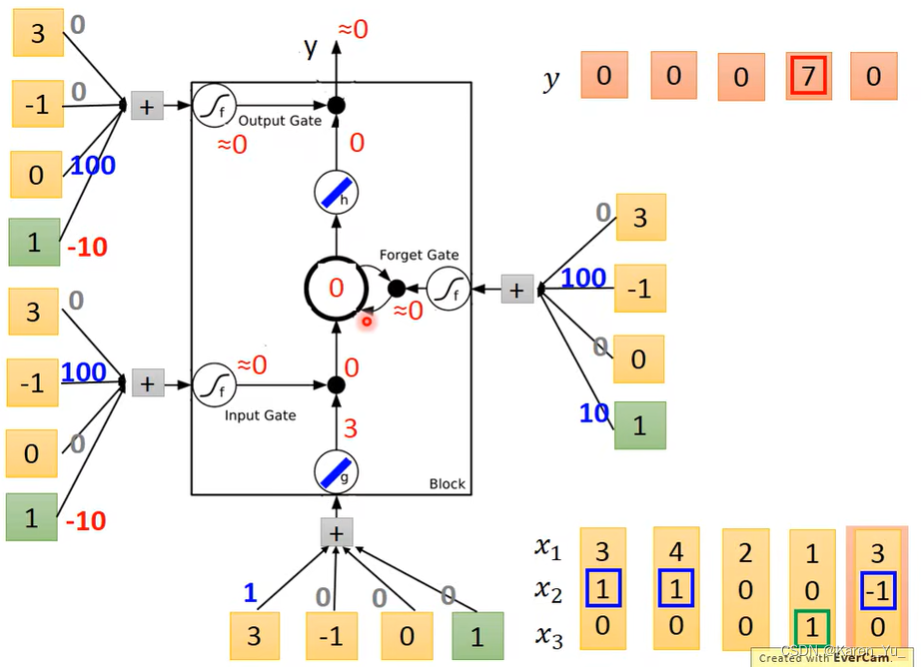
接下来进来[3,-1,0],input gate被关闭,forget gate被关闭(忘记),memory里面的值被洗掉,变为0(0*0+7*0),output gate关闭,输出0。
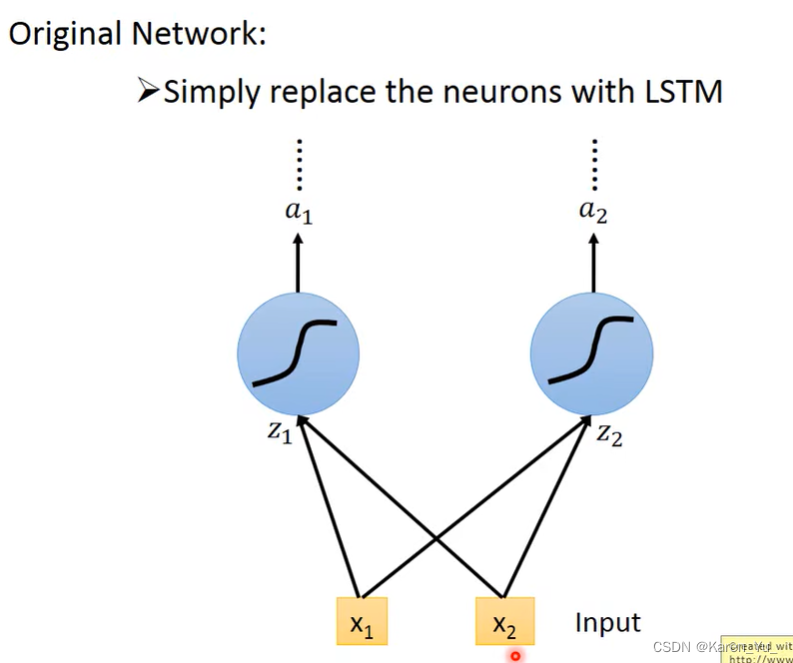
在原来的neural network里面,我们有很多neuron,我们会把input乘上不同的weight,当做是不同neuron的输入,然后每一个neuron都是一个function。
对于LSTM来说,只要把LSTM的memory cell想成是一个neuron就好了
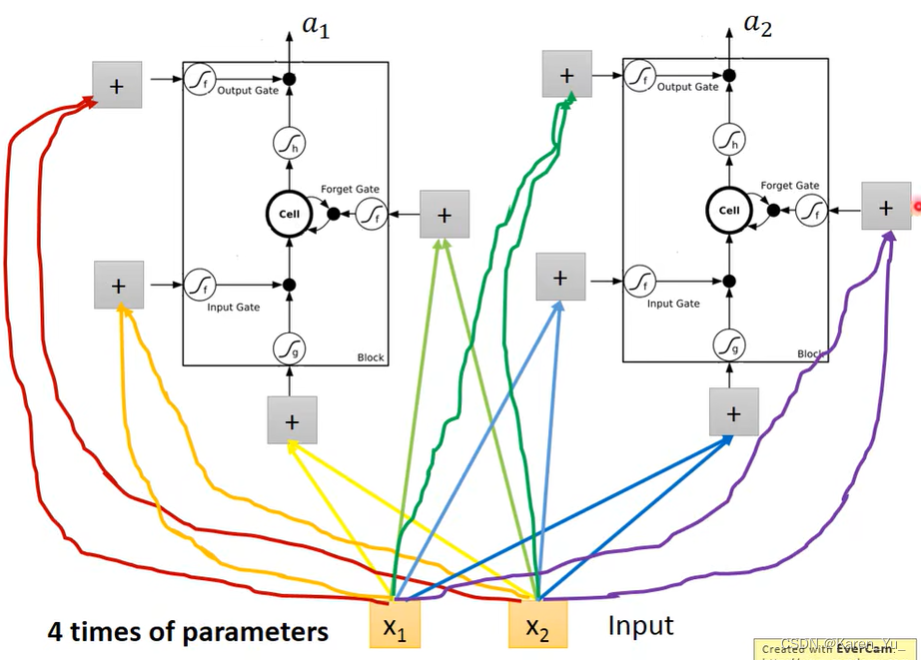
现在的input会乘上不同的weight,当做LSTM的不同的输入。
假设我们这一层只有两个neuron,x1 x2乘上不同的weight分别控制每个LSTM的input, input gate,output gate, forget gate。里面所有的input都是不一样的(老师举例,有的机器插一根电源线就能用,有的机器插四根电源线才能用)。
->LSTM需要的参数是一般nn的四倍
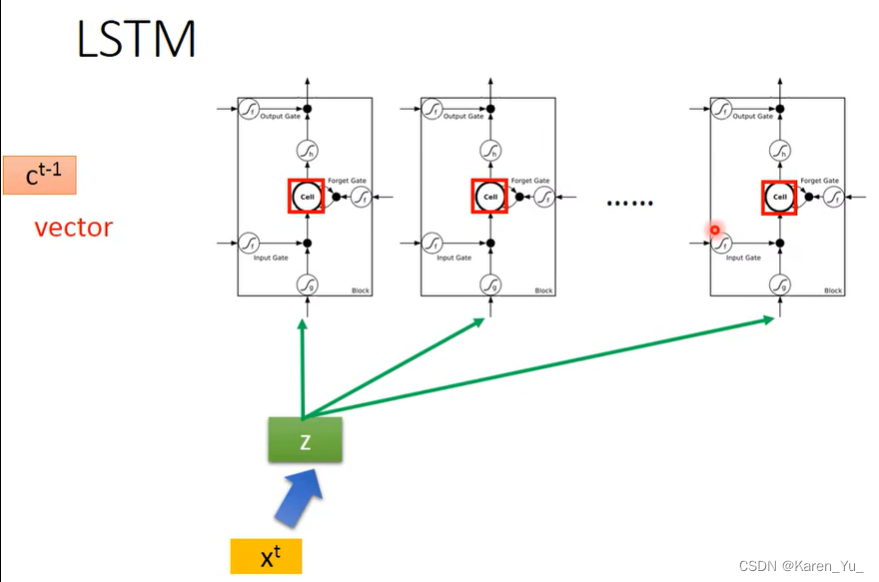
假设我们现在有一整排的LSTM,每一个memory里面都存了一个值,把这些值接起来就组成了一个vector,这里写作c^(t-1)。
在时间点t,input一个vector,x^t,这个vector首先会乘上一个linear的transform(乘上一个matrix)变成另一个vector z,z这个vector的每一个dimension就代表了操控LSTM的一个input,其dimension就正好是所操控的LSTM的memory cell数目(解释一下,就相当于,假设我们现在有俩memory cell,那么z就是一个二维的向量[z1, z2],或者说,向量的长度是2)第一维就丢给第一个cell,第二维就丢给第二个cell……

x^t这个vector会乘上第二个transform,得到zi,用来操控input gate,zi的dimension也和memory cell的个数一样,也像之前那么分配,第一维就丢给第一个cell,第二维就丢给第二个cell……

同理forget gate和output gate也是一样,最后这四个vector一起操控这些memory cell。

所有的cell都可以一起运算。
这里的圈圈表示是element-wise的。
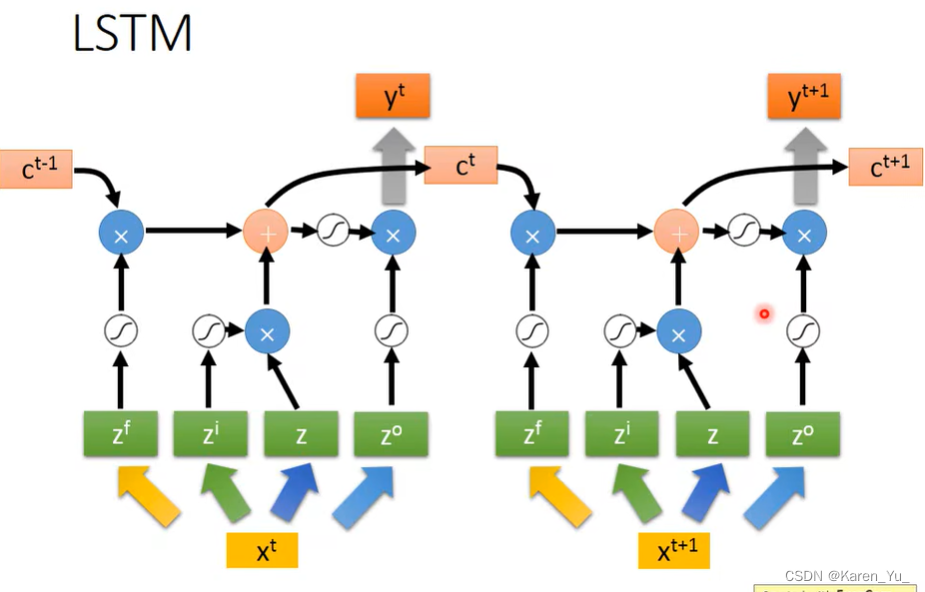
反复进行下去。

不过这也只是LSTM的简化版本。实际上会把hidden layer的输出接进来,当做下一个时间点的input->也就是下一个时间点的,操控这些gate的值不是只看这个时间点的input x,还要看前一个时间点的output。
不仅如此,还需要加一个peephole,把存在memory cell 里面的值也加进来。
->同时考虑x h c

一般也不会只有一层。
如何learning
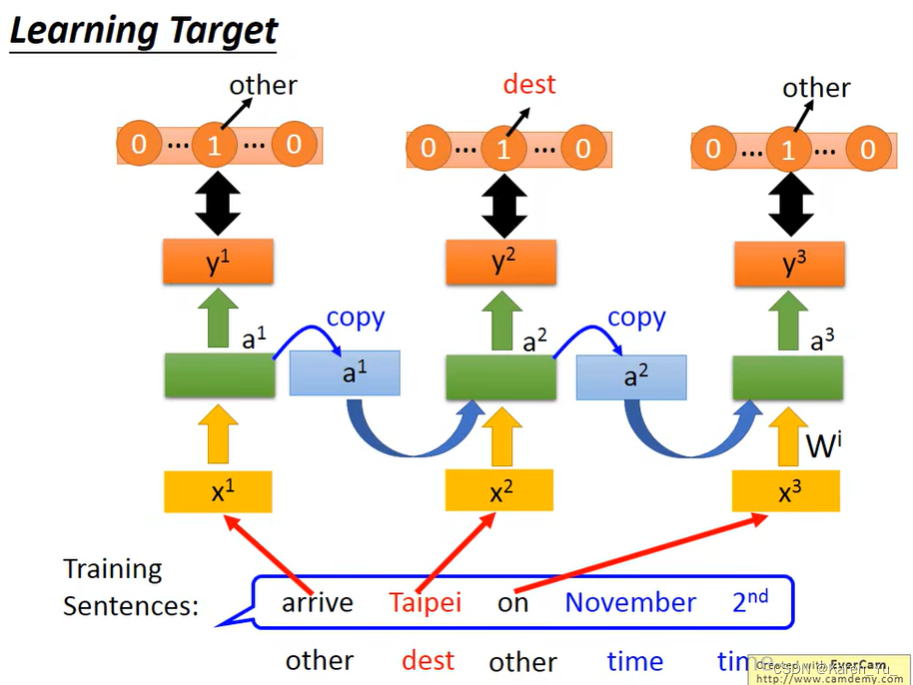
如何定义cost。
比如我们现在有一个training sentence,给sentence做label,第一个Word属于other这个slot,台北属于dest这个slot……
如果我们现在丢进去的arrive,我们希望输出的y1和一个reference的vector计算cross entropy,希望,reference的vector是对应到other那个slot是1,其他的是0。这个reference的长度就是slot的数目(比如有40个slot,reference的长度就是40)。
->每一个时间点的RNN的output和reference vector的cross entropy的和就是loss

怎么training呢?还是用gradient descend。
假设我们已经定义出来了loss function L,计算w对L的偏微分。

然而,RNN的training是比较困难的。
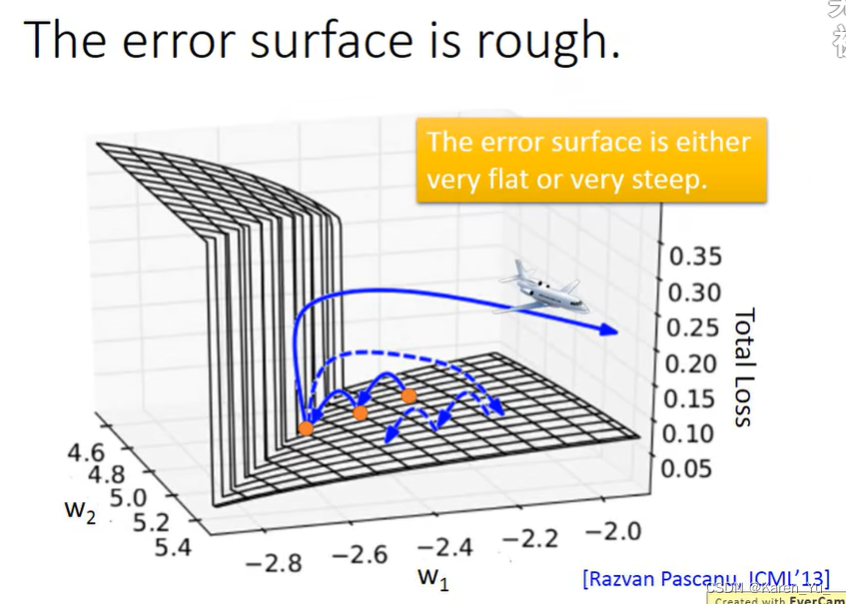
RNN的errorsurface是非常崎岖的,有的地方很陡峭,都得地方是平坦的。

->采取的方法是clipping,不让gradient超过某个特定的值

那么为什么RNN会这样呢?和sigmoid function有没有关系呢?(之前的课程介绍过,gradient vanish这个问题是由于sigmoid function)并不是。
现在看一个简单的RNN,只有一个neuron,并且这个neuron是linear的,只有一个input(,input的weight是1,没有bias,output的weight也是1,也没有bias,transition的部分的weight是w。也就是说从memory接到neuron的input的weight是w。
假设给这个network的input是1 0 0 0 0 ……
这个network在第1000个时间点的output是?w^999(因为一开始进去是1,然后乘上w,进入下一个输入,下一个时间点的输入是0,只有来自前面的w,因此再传递就是w*w,以此类推)。想知道这个w对network的output的影响有多大。
可以看出增加一点点w,就会有很大的影响->w的gradient会很大->只要把learning rate设小一点就好了。
但是如果w=0.99,最后就是0了,如果w=0.01,最后也是0,所以这个时候又需要大的learning rate。
也就是说在非常小的区域内,gradient就会有很大的变化。
->因此可以总结出来问题来自于,同样的东西在transition的时候反复使用,从memory接到neuron的都是反复使用的,所以w只要一有变化,可能完全没影响,也可能造成很大的影响。
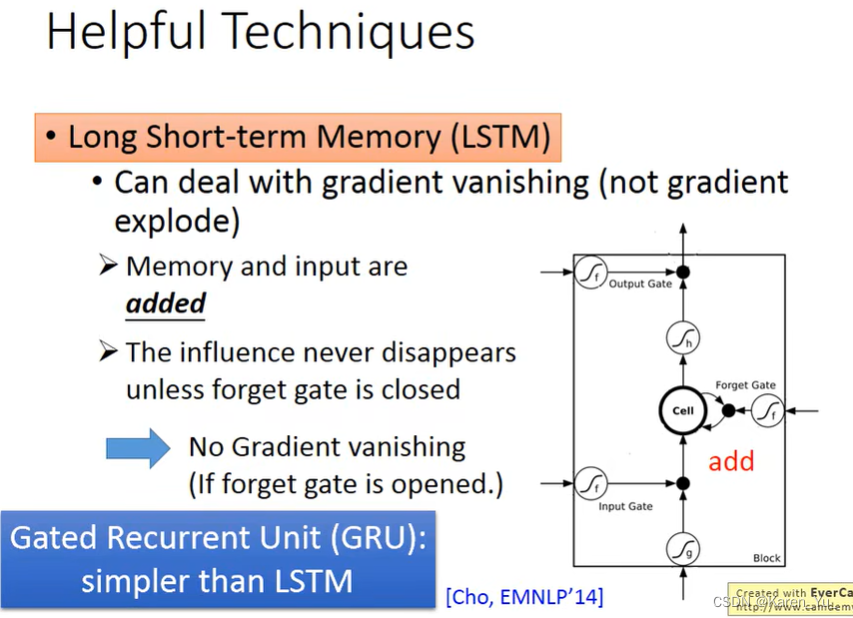
如何解决这一问题?
最广泛被使用的技巧是LSTM,会把比较平坦的地方去掉,也就是让error surface不要那么崎岖(可以解决gradient vanish的问题),这个时候就可以放心的把learning rate设的小一点->可以在learning rate特别小的情况下训练。
(在之前写intuition的时候,看到有提过LSTM可以解决gradient vanish的问题,但是并没有给出原因)Why?
RNN和LSTM在面对memory的时候,处理的operation其实是不一样的。在RNN里面,其实在每一个时间点,memory里面的信息都会被洗掉,在每一个时间点,output的值都会被放到memory里面去,所以每个时间点memory里面的值都会被覆盖掉。但是在LSTM里面不一样,是把原来memory里面的值乘上一个值,再加上input的值加起来放到memory里面。所以,如果现在的weight可以影响到memory里面的值,一旦发生影响,这个影响会一直存在。
不像RNN里面每个时间点的memory里面的值都会被format掉,只要一被format掉,这个值就消失了。但是在LSTM里面,一旦能对memory造成影响,那个影响会永远保留,除非forget gate决定吧当前memory里面的值洗掉(关闭forget gate)。
即使这样,也有forget gate,这也有可能会把memory里面的值洗掉。事实上在最开始的结构里是没有forget gate的(因为设计出来就是为了解决gradient vanish的问题的),forget gate实际上是后面加进来的,一般而言是给forget gate比较大的bias,确保forget gate在大部分时间是开启的。
(摘自弹幕:LSTM可以解决梯度消失的原因是来自上一时序的信息以相加的方式保存在memory unit中,所以当forget gate一直保持开启时,这部分梯度就始终存在)
还有一个新的策略,只有两个gate,也因此参数量就比较少,也因此在training的时候是比较robust的。所以如果在train LSTM的时候觉得overfitting很严重,可以试一下用GRU。GRU的思路就是把input gate和forget gate联动起来,老师的说法是“旧的不去新的不来”。当input gate打开的时候,forget gate就会自动关闭(memory里的值洗掉),当forget gate打开的时候(记住之前的值),是不打开input gate的(不读入)。换言之就是,除非要把memory里面的值清掉,否则不会放新的值进来。

也有其他的方法可以解决gradient vanish。
应用
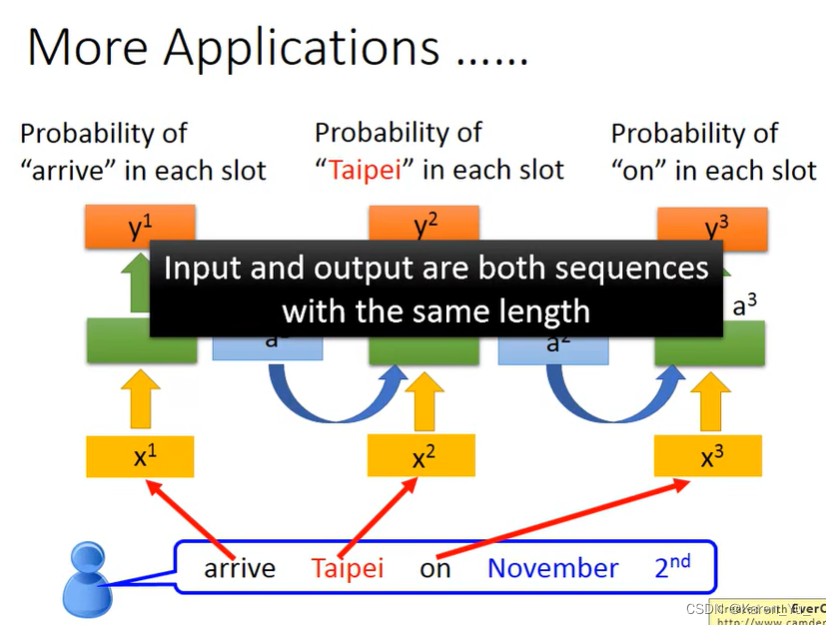
RNN有很多应用,在前面举的例子中,假设input和output的element的数目是一样多的,也就是说input有几个Word,就给每一个word一个slot的label。但是实际上,RNN可以做更复杂的事情。
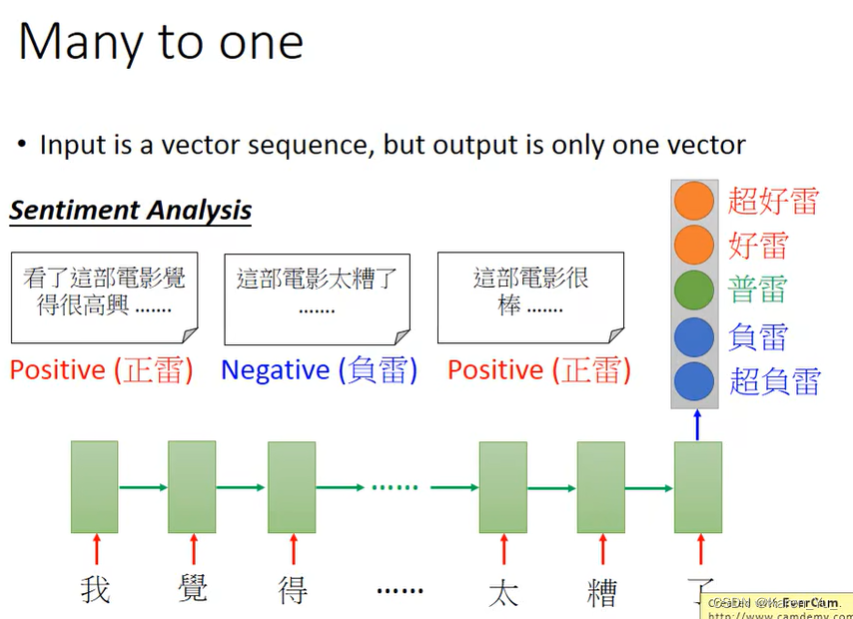
比如sentiment analysis。比如想知道网络上的评价是什么样的,就可以写一个爬虫,把相关的文章爬下来,训练一个classifier,判断哪些是positive,哪些是negative。input是一个character sequence,RNN把文章读一遍,在最后一个时间点把hidden layer拿出来,通过几个transform,判断评价。
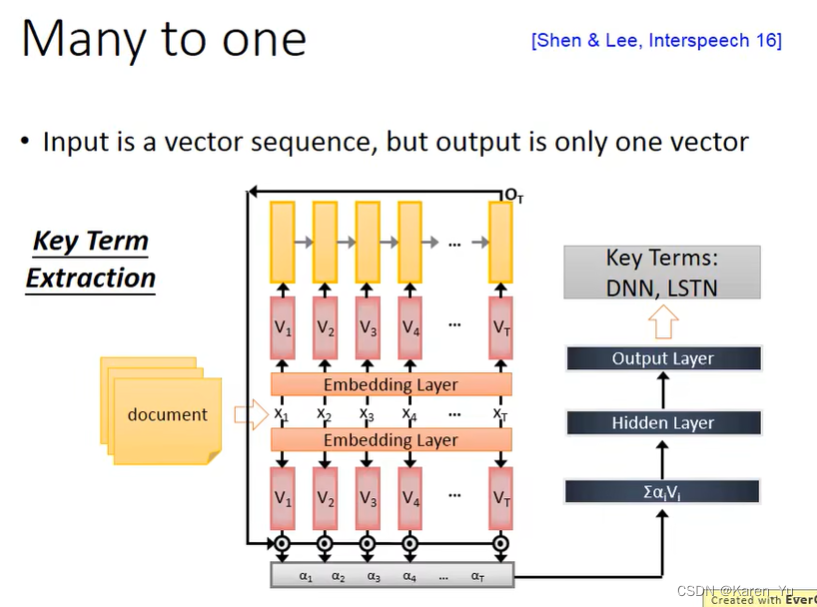
还有比如key extraction(不太确定,但是听起来像这个单词),就是给machine看一篇文章,让machine决定文章里面有哪些关键词汇。document当做input,通过embedding layer,把出现在最后的时间点的output做attention,把information抽出来丢到feedforward network里面去,得到最后的output。

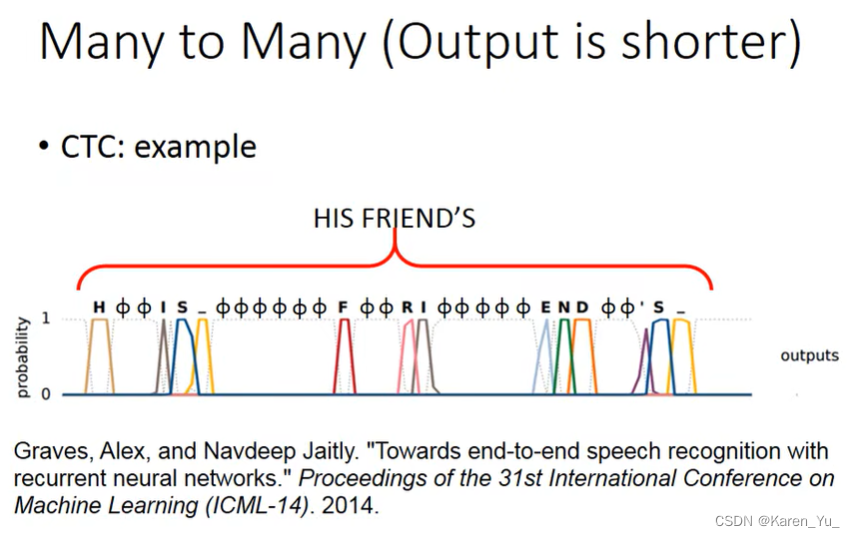
也可以是多对多的。input和output都是sequence(但是output的sequence更短)。比如语音识别,input是一串acoustic feature sequence(声音信号),一般处理方法是每隔一小段时间就用一个vector表示,这个一小段时间一般比较短,比如0.01秒,output是character的sequence。
如果只是采用原来的RNN(slot fitting),最多可以告诉每一个vector对应到哪一个character。但是可能会有重复,这个时候我们又不知道怎么去掉重复(因为文本中可能本来就应该有重复)

解决方法比如CTC,在output的时候,不止output所有character,还多output一个符号Φ,表示null。

在训练的时候的思路是穷举所有可能的alignment。(具体参见NLP)
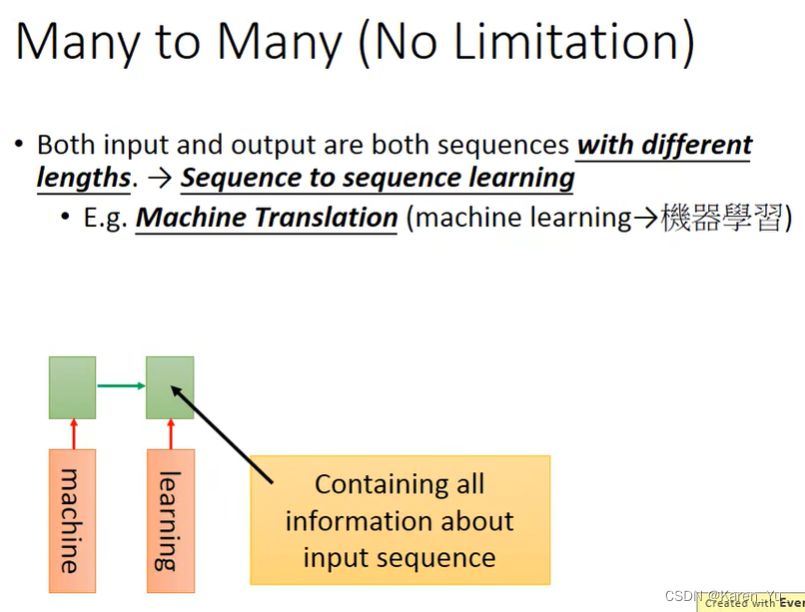
另一个应用是sequence to sequence learning。这里RNN的input和output都是sequence,sequence的长度是不一样的(不确定谁长谁短)。比如翻译。


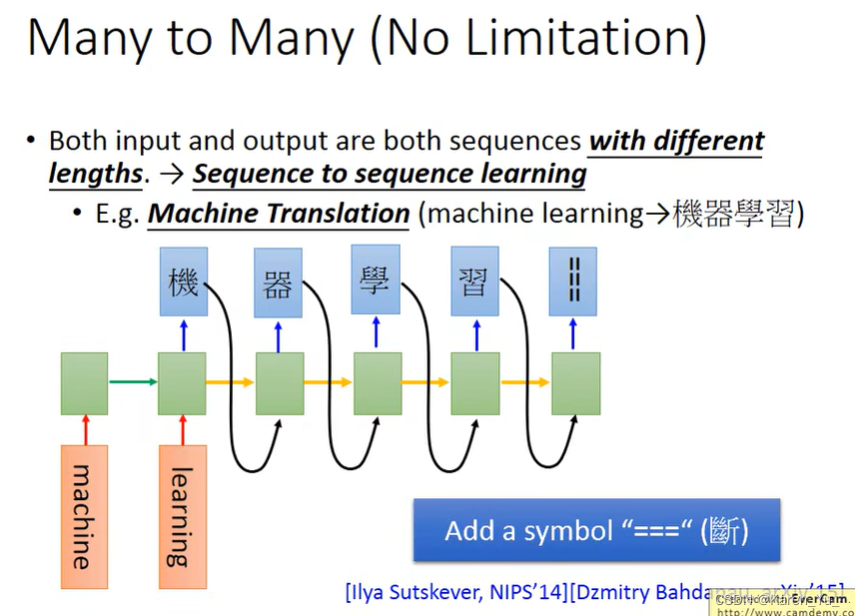

直接input一种语言的声音信号,output另一种语言的文字,完全不做语音识别,直接把声音信号丢进去。这样也许就可以用来训练没有文字的语言翻译成其他语言。
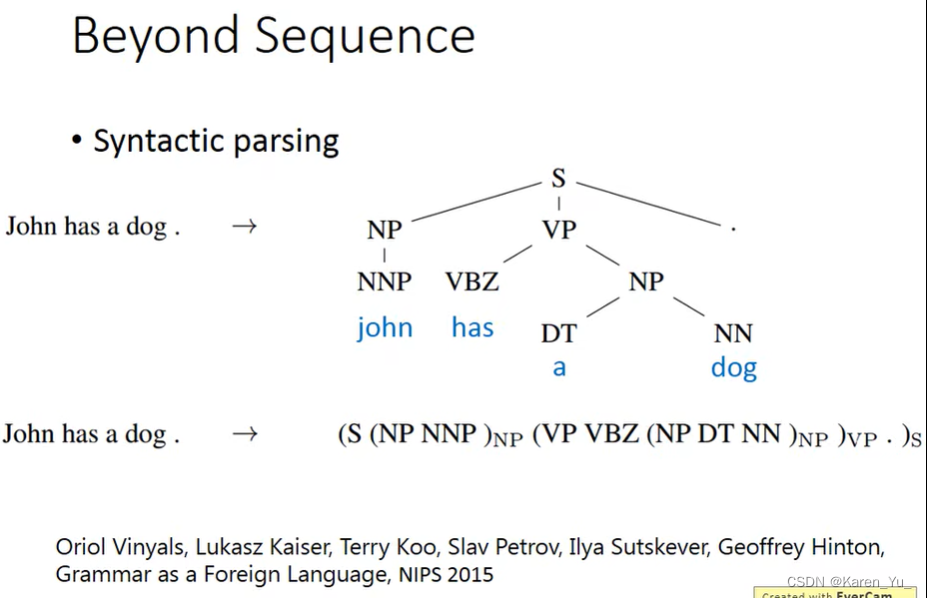
还可以用到Beyond sequence。

如果要把一个document表示成一个vector的话,往往会采用bag of word的方法,但是这种方法,会忽略掉word order。
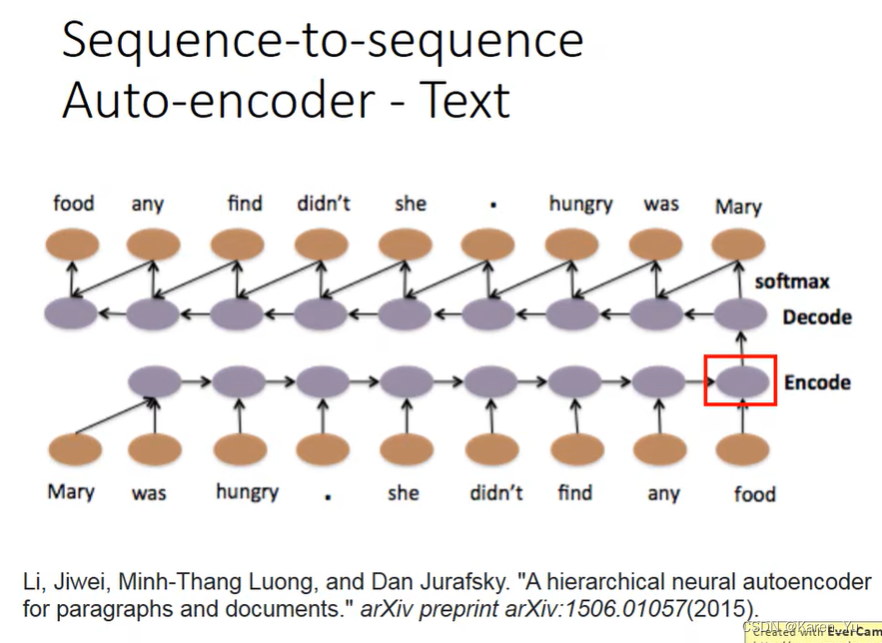
可以考虑使用sequence-to-sequence auto-encoder这种方法,在考虑word order的情况下,把一个document变成vector。input一个word sequence,比如“Mary was hungry. she didn't find any food”,通过一个recurrent neural network变成一个embedded的vector,再把这个embedded的vector当做decoder的输入,让这个decoder找回一个一模一样的句子。
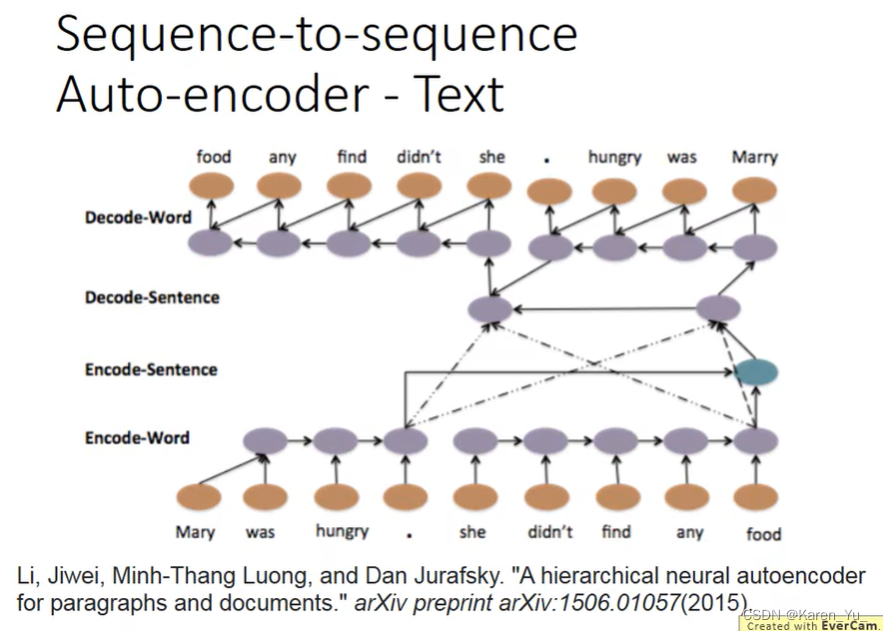
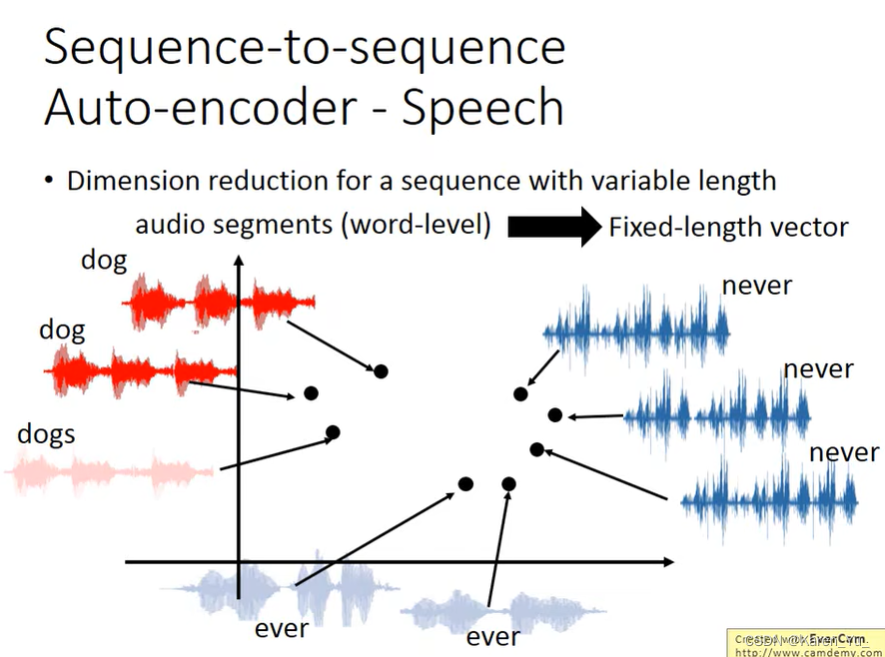
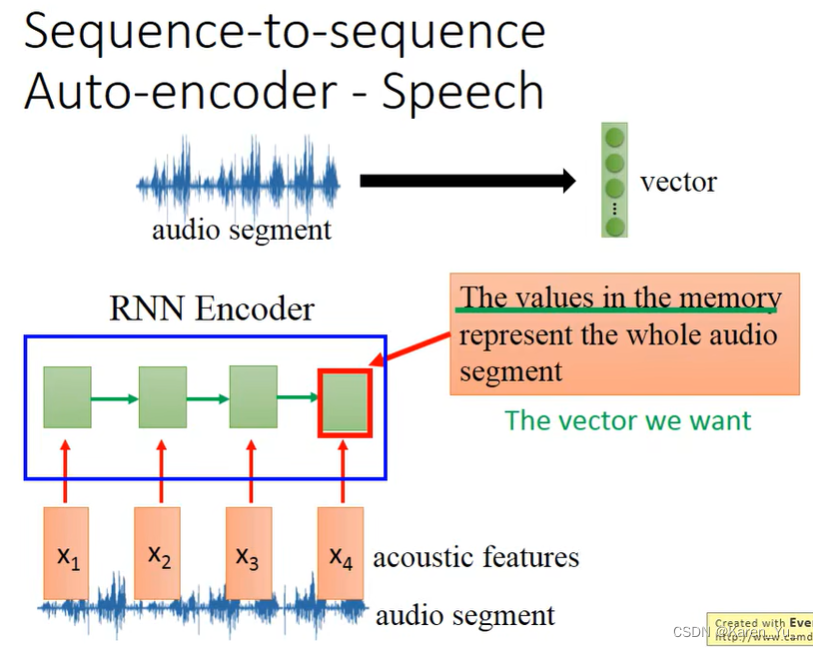
也可以用在语音上,把一段audio的 segment,变成fixed-length的vector
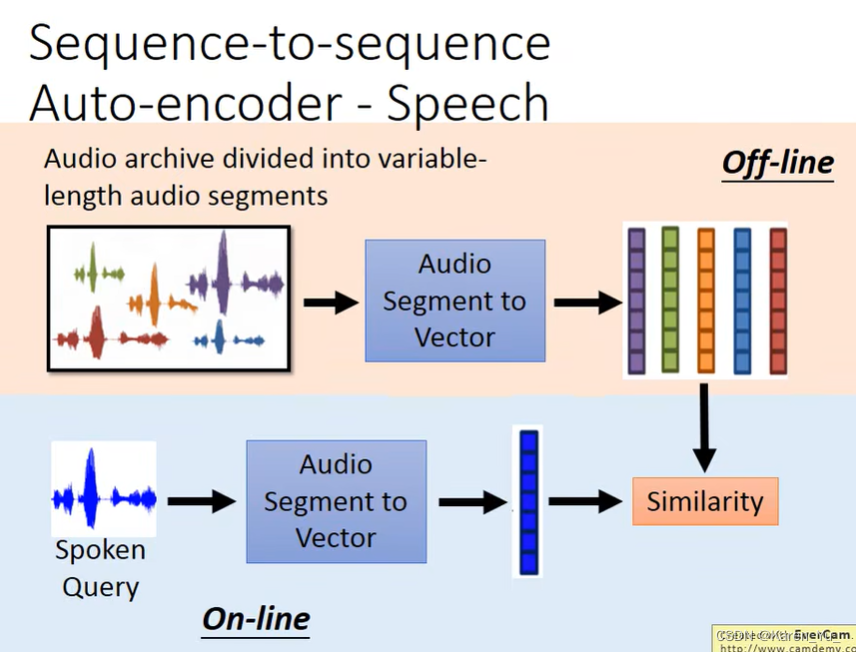

老师提出的应用,类似检索,但是是直接对声音进行检索,找到说相关内容的片段。
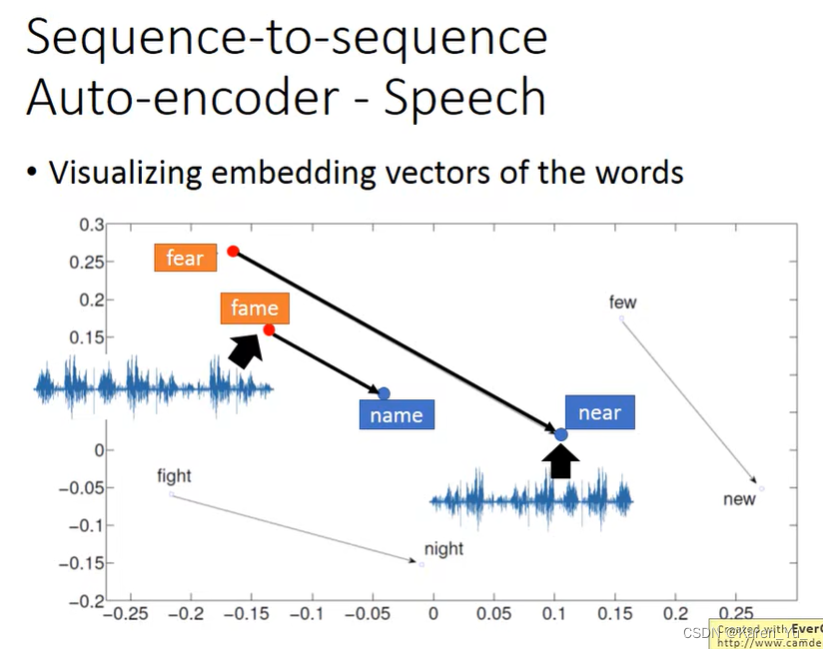
比如这个例子里看到把f替换成n,变化的方向都是一致的。

chat-bot。
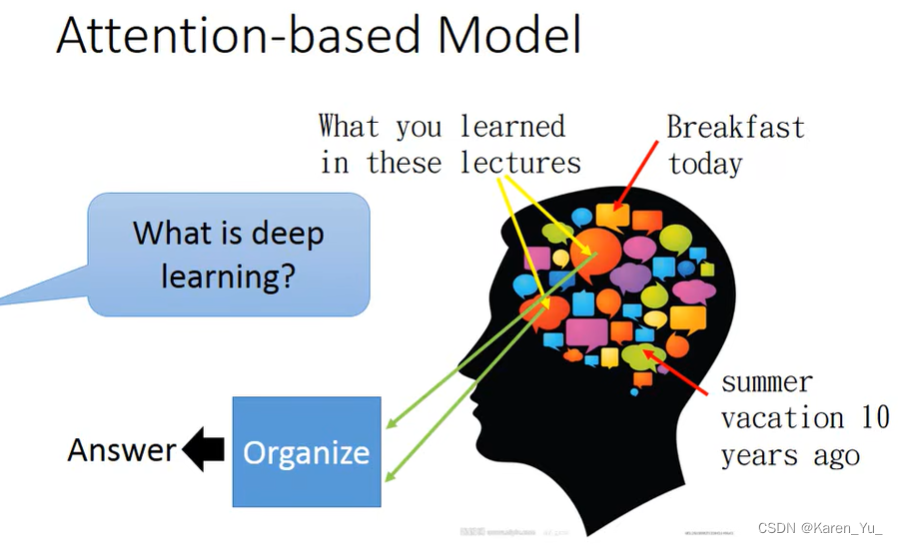

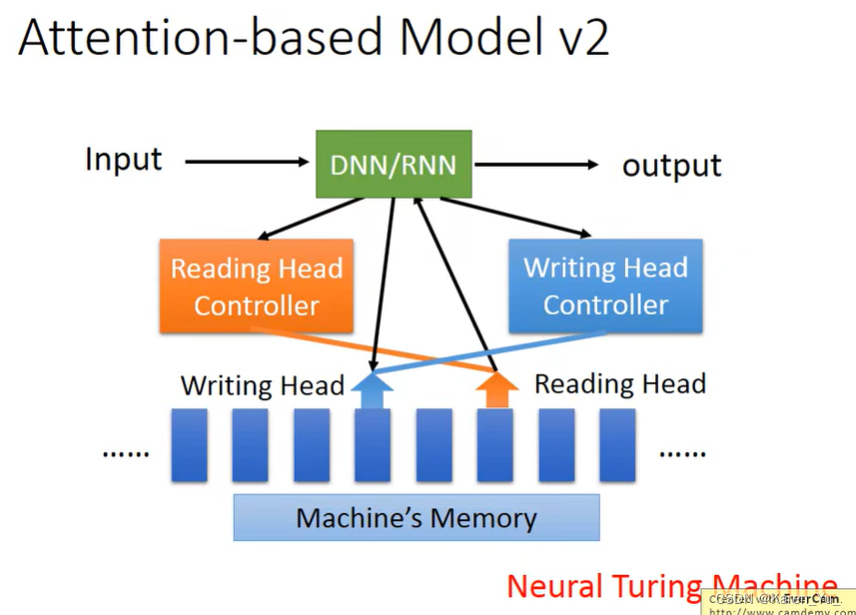
除了RNN外,现在还有用到的是attention-based model。machine也可以记住大量的信息。

这一模型可以被用于reading comprehension里面,每一个句子用一个vector表示,每一个vector代表这句话的语义。
machine可以从多个地方读取。比如我们现在需要xxx相关的内容,我们就去找哪些句子和xxx有关,就把reading head放到这个地方,读取,接着可以换个地方读取,最后汇总到一起给一个最终的答案。

蓝色代表了reading head的位置。

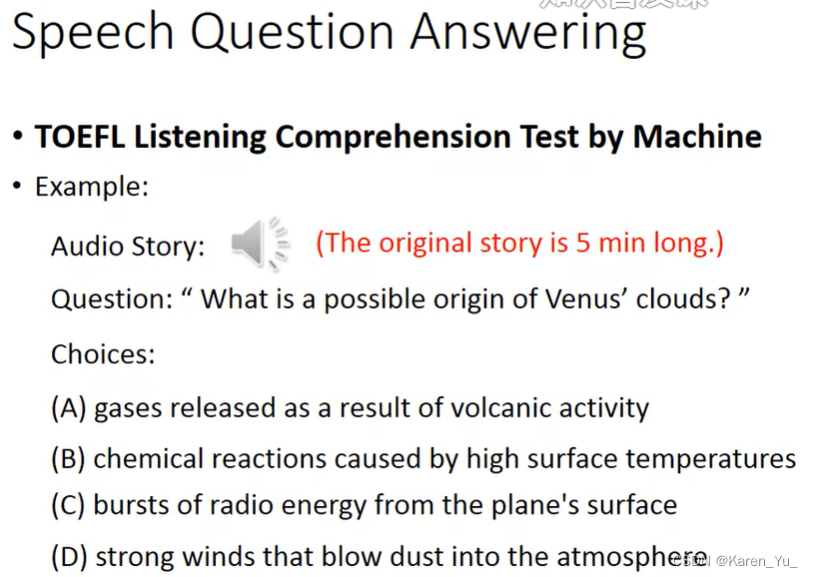
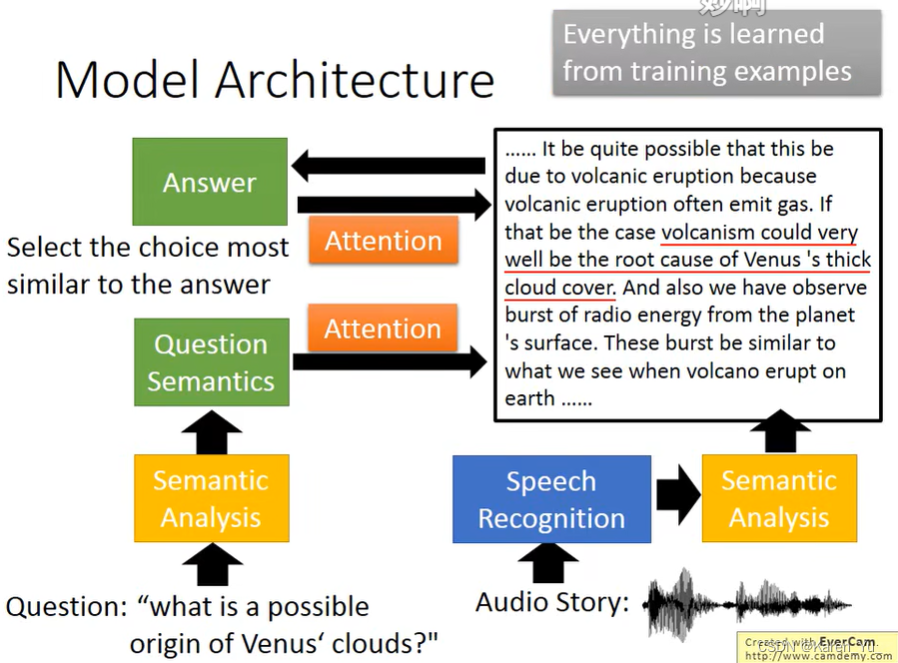
summary



RNN PyTorch Tutorial
Welcome to PyTorch Tutorials — PyTorch Tutorials 2.2.0+cu121 documentation
NLP From Scratch: Classifying Names with a Character-Level RNN — PyTorch Tutorials 2.2.0+cu121 documentation
RNN — PyTorch 2.1 documentation
这里学习的事第二个链接:CLASSIFYING NAMES WITH A CHARACTER-LEVEL RNN
简单来说就是采用character作为token对名字进行分类,训练来自18种语言的几千个姓氏,并根据拼写预测一个名字来自哪种语言。
(如果会科学上网的话,也可以直接去colab看:char_rnn_classification_tutorial.ipynb - Colaboratory (google.com))
Recommended Preparation
总的来说:1.安装PyTorch;2.了解Python语言;3.了解张量(Tensor)
文中给出了相应的tutorial:
1. pytorch安装https://pytorch.org/
2. pytorch intro &Tensor intro (视频形式)Deep Learning with PyTorch: A 60 Minute Blitz — PyTorch Tutorials 2.2.0+cu121 documentation
3. pytorch intro (代码案例)Learning PyTorch with Examples — PyTorch Tutorials 2.2.0+cu121 documentation
4. RNN介绍The Unreasonable Effectiveness of Recurrent Neural Networks (karpathy.github.io)
5. LSTM介绍Understanding LSTM Networks -- colah's blog
考虑到如果这些也塞在这里略显拥挤,所以这部分内容会放到另一篇博客里写,附链接如下:
PyTorch Tutorial-CSDN博客
数据集准备
数据集链接:https://download.pytorch.org/tutorial/data.zip
“data/names”目录下包含18个文本文件,文件名为“[Language].txt”。每个文件包含一堆名称,每行一个名称,大多数是romanized(用罗马字体书写的?)(但我们仍然需要从Unicode转换为ASCII)。
我们最终会得到一个包含每种语言名称列表的字典,{language: [names…]}。通用变量“category”和“line”(在本例中表示语言和名称)用于以后的可扩展性。
from io import open
import glob
import osdef findFiles(path): return glob.glob(path)print(findFiles('data/names/*.txt'))import unicodedata
import stringall_letters = string.ascii_letters + " .,;'"
n_letters = len(all_letters)# Turn a Unicode string to plain ASCII, thanks to https://stackoverflow.com/a/518232/2809427
def unicodeToAscii(s):return ''.join(c for c in unicodedata.normalize('NFD', s)if unicodedata.category(c) != 'Mn'and c in all_letters)print(unicodeToAscii('Ślusàrski'))# Build the category_lines dictionary, a list of names per language
category_lines = {}
all_categories = []# Read a file and split into lines
def readLines(filename):lines = open(filename, encoding='utf-8').read().strip().split('\n')return [unicodeToAscii(line) for line in lines]for filename in findFiles('data/names/*.txt'):category = os.path.splitext(os.path.basename(filename))[0]all_categories.append(category)lines = readLines(filename)category_lines[category] = linesn_categories = len(all_categories)glob.glob(path):返回一个与path匹配的路径名列表(允许为空)
print(findFiles('data/names/*.txt')):找到data/names/文件夹下所有的txt文件
string.ascii_letters + " .,;'":ascii_letters是生成所有的字母a-z和A-Z,加上了一些其他字符,作为token。
unicodedata.normalize('NFD', s):使用unicodedata.normalize进行规范化. 函数的第一个参数是的设置有四个选择: - NFC(Normalization Form C)使用最少的码位构成等价的字符串 - NFD 把组合字符分解成基字符和单独的组合字符 - NFKC 较严格的规范化形式,对“兼容字符”有影响 - NFKD 较严格的规范化形式,对“兼容字符”有影响。
unicodedata.category(c):在Unicode中,每个字符还会被赋予上Category的属性,而这个属性跟语种是无关的。总体而言,Category一共分为 Letter, Mark, Number, Punctuation, Symbol, Seperator, Other 七大类, 而每个类别下面还有进一步的二级分类。在 Python 中,我们可以利用unicodedata.category来获取这个属性。这里用到的'Mn'指的是Mark和nonspacing。因此这里就是替代非英文字母的字母。
['data/names/Arabic.txt', 'data/names/Chinese.txt', 'data/names/Czech.txt', 'data/names/Dutch.txt', 'data/names/English.txt', 'data/names/French.txt', 'data/names/German.txt', 'data/names/Greek.txt', 'data/names/Irish.txt', 'data/names/Italian.txt', 'data/names/Japanese.txt', 'data/names/Korean.txt', 'data/names/Polish.txt', 'data/names/Portuguese.txt', 'data/names/Russian.txt', 'data/names/Scottish.txt', 'data/names/Spanish.txt', 'data/names/Vietnamese.txt']
Slusarski
Python进阶14_Unicode字符的规范化 - 知乎 (zhihu.com)
关于处理文本文件这里有一个很有意思和形象的比喻:“Unicode 三明治”。可以想象成三部曲吧: - 第一步:要尽早把输入的字节序列解码输入的字节序列 - 然后:只处理文本 - 最后:要尽量晚地把字符串编码成字节序列 具体如下图:

现在我们有了category_lines,这是一个将每个类别(语言)映射到行(名称)列表的字典。我们还记录了all_categories(只是一个语言列表)和n_categories,以供以后参考。
print(category_lines['Italian'][:5])['Abandonato', 'Abatangelo', 'Abatantuono', 'Abate', 'Abategiovanni']
把名字改成Tensor
为了表示一个字母,我们采用one-hot方法,把当前的字母锁在的位置设为1,其他都为0,有几个字母就贴几行
import torch# Find letter index from all_letters, e.g. "a" = 0
def letterToIndex(letter):return all_letters.find(letter)# Just for demonstration, turn a letter into a <1 x n_letters> Tensor
def letterToTensor(letter):tensor = torch.zeros(1, n_letters)tensor[0][letterToIndex(letter)] = 1return tensor# Turn a line into a <line_length x 1 x n_letters>,
# or an array of one-hot letter vectors
def lineToTensor(line):tensor = torch.zeros(len(line), 1, n_letters)for li, letter in enumerate(line):tensor[li][0][letterToIndex(letter)] = 1return tensorprint(letterToTensor('J'))print(lineToTensor('Jones').size())tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0.]])
torch.Size([5, 1, 57])
建立网络
这里用的方法是前面RNN中的第一种方法,即使用上一个hidden layer的输出和和当前输入共同构成新的输入。
import torch.nn as nnclass RNN(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(RNN, self).__init__()self.hidden_size = hidden_sizeself.i2h = nn.Linear(input_size + hidden_size, hidden_size)self.h2o = nn.Linear(hidden_size, output_size)self.softmax = nn.LogSoftmax(dim=1)def forward(self, input, hidden):combined = torch.cat((input, hidden), 1)hidden = self.i2h(combined)output = self.h2o(hidden)output = self.softmax(output)return output, hiddendef initHidden(self):return torch.zeros(1, self.hidden_size)n_hidden = 128
rnn = RNN(n_letters, n_hidden, n_categories)训练
input = lineToTensor('Albert')
hidden = torch.zeros(1, n_hidden)output, next_hidden = rnn(input[0], hidden)
print(output)def categoryFromOutput(output):top_n, top_i = output.topk(1)category_i = top_i[0].item()return all_categories[category_i], category_iprint(categoryFromOutput(output))tensor([[-2.9083, -2.9270, -2.9167, -2.9590, -2.9108, -2.8332, -2.8906, -2.8325,
-2.8521, -2.9279, -2.8452, -2.8754, -2.8565, -2.9733, -2.9201, -2.8233,
-2.9298, -2.8624]], grad_fn=<LogSoftmaxBackward0>)('Scottish', 15)
criterion = nn.NLLLoss()训练这个网络所需要做的就是给它看一堆例子,让它猜测,然后告诉它是否错了。这里选择nn.NLLLoss的原因是RNN的最后一层是nn.LogSoftmax
(我简单查了一下,好像中文互联网上没有特别对应的解释,国外的网友从两方面给出了原因,但是我也不是专家orz,所以也就姑妄言之,大家当听个乐
1. 首先是nn.NLLLoss和nn.LogSoftmax为什么能绑定,对于nn.NLLLoss来说,需要作为输入对数概率,因此它与产生概率的Softmax层的输出不兼容;
2.对于nn.LogSoftmax,使用的原因是比softmax函数更快。softmax函数返回的区间在[0,1]之间,而nn.LogSoftmax其实就是给softmax加了一个log,这样范围就落到了(-inf,0]
参考:
Pytorch avoid softmax with nllloss | Amazon CodeGuru, Detector Library
Does NLLLoss handle Log-Softmax and Softmax in the same way? - PyTorch Forums
machine-learning-articles/how-to-use-pytorch-loss-functions.md at main · christianversloot/machine-learning-articles · GitHubLosses Learned (sebastianraschka.com))
Each loop of training will:
Create input and target tensors
Create a zeroed initial hidden state
Read each letter in and
Keep hidden state for next letter
Compare final output to target
Back-propagate
Return the output and loss
训练的每次循环,要做
1. 创建input和target的Tensor
2. 初始化hidden state为0
3. 读入每个字母,并且保留在hidden state中,留给下一个字母使用
4. 比较最终的输出与target
5. 反向传播
6. 返回output和loss
learning_rate = 0.005
# If you set this too high, it might explode. If too low, it might not learndef train(category_tensor, line_tensor):hidden = rnn.initHidden()rnn.zero_grad()for i in range(line_tensor.size()[0]):output, hidden = rnn(line_tensor[i], hidden)loss = criterion(output, category_tensor)loss.backward()# Add parameters' gradients to their values, multiplied by learning ratefor p in rnn.parameters():p.data.add_(p.grad.data, alpha=-learning_rate)return output, loss.item()回顾一下:
def initHidden(self):return torch.zeros(1, self.hidden_size)是一个向量,长度是hidden layer的neuron的个数,这个是指定的,比如这里是128.
现在我们只需要用一堆例子来运行它。由于训练函数返回输出和损失,我们可以打印它的猜测并跟踪损失以便绘制。
import time
import mathn_iters = 100000
print_every = 5000
plot_every = 1000# Keep track of losses for plotting
current_loss = 0
all_losses = []def timeSince(since):now = time.time()s = now - sincem = math.floor(s / 60)s -= m * 60return '%dm %ds' % (m, s)start = time.time()for iter in range(1, n_iters + 1):category, line, category_tensor, line_tensor = randomTrainingExample()output, loss = train(category_tensor, line_tensor)current_loss += loss# Print ``iter`` number, loss, name and guessif iter % print_every == 0:guess, guess_i = categoryFromOutput(output)correct = '✓' if guess == category else '✗ (%s)' % categoryprint('%d %d%% (%s) %.4f %s / %s %s' % (iter, iter / n_iters * 100, timeSince(start), loss, line, guess, correct))# Add current loss avg to list of lossesif iter % plot_every == 0:all_losses.append(current_loss / plot_every)current_loss = 05000 5% (0m 33s) 2.6379 Horigome / Japanese ✓
10000 10% (1m 7s) 2.0172 Miazga / Japanese ✗ (Polish)
15000 15% (1m 41s) 0.2680 Yukhvidov / Russian ✓
20000 20% (2m 15s) 1.8239 Mclaughlin / Irish ✗ (Scottish)
25000 25% (2m 50s) 0.6978 Banh / Vietnamese ✓
30000 30% (3m 23s) 1.7433 Machado / Japanese ✗ (Portuguese)
35000 35% (3m 57s) 0.0340 Fotopoulos / Greek ✓
40000 40% (4m 31s) 1.4637 Quirke / Irish ✓
45000 45% (5m 5s) 1.9018 Reier / French ✗ (German)
50000 50% (5m 39s) 0.9174 Hou / Chinese ✓
55000 55% (6m 12s) 1.0506 Duan / Vietnamese ✗ (Chinese)
60000 60% (6m 47s) 0.9617 Giang / Vietnamese ✓
65000 65% (7m 21s) 2.4557 Cober / German ✗ (Czech)
70000 70% (7m 55s) 0.8502 Mateus / Portuguese ✓
75000 75% (8m 28s) 0.2750 Hamilton / Scottish ✓
80000 80% (9m 2s) 0.7515 Maessen / Dutch ✓
85000 85% (9m 36s) 0.0912 Gan / Chinese ✓
90000 90% (10m 9s) 0.1190 Bellomi / Italian ✓
95000 95% (10m 43s) 0.0137 Vozgov / Russian ✓
100000 100% (11m 17s) 0.7808 Tong / Vietnamese ✓
import matplotlib.pyplot as plt
import matplotlib.ticker as tickerplt.figure()
plt.plot(all_losses)
训练结果评估
混淆矩阵,表示网络猜测的每种语言(行)(列)。为了计算混淆矩阵,使用evaluate()在网络中运行一堆样本,这与train()减去backprop相同。
# Keep track of correct guesses in a confusion matrix
confusion = torch.zeros(n_categories, n_categories)
n_confusion = 10000# Just return an output given a line
def evaluate(line_tensor):hidden = rnn.initHidden()for i in range(line_tensor.size()[0]):output, hidden = rnn(line_tensor[i], hidden)return output# Go through a bunch of examples and record which are correctly guessed
for i in range(n_confusion):category, line, category_tensor, line_tensor = randomTrainingExample()output = evaluate(line_tensor)guess, guess_i = categoryFromOutput(output)category_i = all_categories.index(category)confusion[category_i][guess_i] += 1# Normalize by dividing every row by its sum
for i in range(n_categories):confusion[i] = confusion[i] / confusion[i].sum()# Set up plot
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(confusion.numpy())
fig.colorbar(cax)# Set up axes
ax.set_xticklabels([''] + all_categories, rotation=90)
ax.set_yticklabels([''] + all_categories)# Force label at every tick
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))# sphinx_gallery_thumbnail_number = 2
plt.show()
def predict(input_line, n_predictions=3):print('\n> %s' % input_line)with torch.no_grad():output = evaluate(lineToTensor(input_line))# Get top N categoriestopv, topi = output.topk(n_predictions, 1, True)predictions = []for i in range(n_predictions):value = topv[0][i].item()category_index = topi[0][i].item()print('(%.2f) %s' % (value, all_categories[category_index]))predictions.append([value, all_categories[category_index]])predict('Dovesky')
predict('Jackson')
predict('Satoshi')> Dovesky
(-0.57) Czech
(-0.97) Russian
(-3.43) English> Jackson
(-1.02) Scottish
(-1.49) Russian
(-1.96) English> Satoshi
(-0.42) Japanese
(-1.70) Polish
(-2.74) Italian
Attention is all you need论文阅读
论文链接:https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
其他参考:Transformer论文逐段精读【论文精读】 - 哔哩哔哩
Transformer论文逐段精读【论文精读】_哔哩哔哩_bilibili
本段思路准备先跟视频一起读论文,然后再自己看一遍。
Transformer论文逐段精读【论文精读】_哔哩哔哩_bilibili
摘要
在主流的序列转录模型中,主要是依赖循环或者卷积神经网络,一般是使用encoder和decoder的架构,在一些性能最好的模型中,通常也会在encoder和ecoder之间使用一个称为attention mechanism(注意力机制)
这篇文章主要是要做序列到序列的生成,采用一个新的简单的网络结构,仅仅依赖注意力机制,而完全没有采用之前的循环或者卷积。作者做了两个翻译的任务,显示模型的性可以并行,并且所需要训练的时间更短。
2 个机器翻译任务的实验结果
英 - 德:比当时最好的结果提高了2个BLEU
英 - 法:单模型,41.8 BLEU,只需8GPUs的3.5天的训练
(BLUE Score是一个翻译领域的衡量机制,bilingual evaluation understudy。用来评估机器翻译质量的工具。BLEU的设计思想:机器翻译结果越接近专业人工翻译的结果,则越好。BLEU算法实际上就是在判断两个句子的相似程度。想知道一个句子翻译前后的表示是否意思一致,直接的办法是拿这个句子的标准人工翻译与机器翻译的结果作比较,如果它们是很相似的,说明我的翻译很成功。
将自动翻译的连续短语与其在参考翻译中找到的连续短语进行比较,并以加权方式计算匹配次数。这些匹配是位置无关的。匹配度越高,表示与参考译文的相似度越高,得分越高。可理解性和语法正确性不被考虑在内。
BLEU指标在0到1的范围内对翻译进行评分,试图衡量MT输出的充分性和流畅性。测试句子得分越接近1,与人类参考翻译的重叠越多,因此,系统被认为越好。为了简化沟通,BLEU分数通常以1到100的范围表示,但这不应该与准确性百分比混淆。
只有当它与参考的人工翻译相同时,机器翻译的输出才会得到1分。但是,即使是两个称职的人翻译完全相同的材料,也可能只得到0.6或0.7分,因为他们可能使用不同的词汇和短语。我们应该警惕非常高的BLEU分数(超过0.7),因为它可能测量不正确或过拟合。
BLEU score评估模型 - 知乎 (zhihu.com)
BLEU:一种自动评估机器翻译的方法 - 知乎 (zhihu.com)
What is a BLEU score? - Custom Translator - Azure AI services | Microsoft Learn
BLEU score in Python - Beginners Overview - AskPython
Foundations of NLP Explained — Bleu Score and WER Metrics | by Ketan Doshi | Towards Data ScienceA Gentle Introduction to Calculating the BLEU Score for Text in Python - MachineLearningMastery.comUnderstanding MT Quality: BLEU Scores (rws.com))
结论
第一个仅仅使用注意力做sequence transduction的模型,把之前的所有recurrent layers都换成了multi-headed self-attention。transformer训练的速度要快很多。认为可以用在文本以外的任务上,包括图片、语音、视频;使生成不那么时序化。
导言
在时序模型中,2017年常用方法是RNN包括LSTM, GRU。其中有两个比较主流的模型,一个是语言模型,一个是encoder-decoder模型(当输出的结构化信息比较多的时候结构化数据与非结构化数据有什么区别? - 知乎 (zhihu.com))
在RNN里面,给一个sequence,RNN的计算是把这个序列从左向右一步一步做,假设序列是一个句子的话,就是一个词一个词看,对第t个词会计算它的隐藏状态h_t,h_t是由h_(t-1)(前一个词的隐藏状态)和当前第t个词决定的。这样就可以把前面学到的历史信息,通过h_(t-1)放到当下,和当前的词做一些计算,然后输出->这是RNN能处理时序信息的关键所在:把之前的信息全部放到隐藏状态里面,然后一个一个放下去。
但是问题也来源于此。第一个是因为它是一个时序的(一步一步计算的过程),所以在算第t个词的h_t时候,必须确保前面的词h_(t-1)输入完成,假设这个句子又100个词,就得时序得算100步,导致时间上无法并行,计算性能较差。也因此历史信息是一步一步向后传递的,如果时序比较长的话,在很早期的时序信息,在后面可能会丢掉。如果不想丢掉,可能h_t要比较大,但是如果h_t设置的比较大,那么在每一步计算都要去存,会导致内存开销比较大。
之前的一些尝试并没有解决太多的问题。
在这篇文章之前,attention已经被用于encoder-decoder里了,作用是把encoder的东西有效的传给decoder。因为这里完全不用recurrent,所以并行度是很高的->可以在很短的时间内得到更好的结果。
相关工作
用卷积神经网络替换掉循环神经网络,以减少时序的计算,但是使用卷积神经网络对比较长的序列难以建模(因为卷积做计算的时候,每一次去看一个比较小的窗口,比如一个3×3的像素块,如果两个像素隔得比较远,要用很多层卷积,一层一层上去才能把这两个隔得远的像素融合起来)。如果使用Transformer里面的注意力机制的话,每一次都能看到所有的像素,所以一层就能够看到整个序列。同时文章也提到卷积好的地方还在于,卷积可以做多个输出通道。没个输出通道都可以看做是识别不一样的模式,因此也希望能够实现这种效果。因此提出了一个叫做Multi-Head Attention(多头注意力机制),可以模拟卷积神经网络多输出通道的效果。
自注意力机制,在之前就已经有相关的研究。
模型
目前的序列模型中比较好的都采用了encoder-decoder架构。
对encoder来说,会将输入(长为n的一个x1……xn的sequence(假设是一个句子,一共有n个词,那么xt就代表第t个词)),表示成一个长度为n的z1……zn的sequence,其中这里的每一个zt对应的是xt的一个向量表示(假设是一个句子,一共有n个词,zt就表示第t个词的向量表示)->将一些原始的输入变成机器学习可以理解的向量。
对decoder来说,会拿到encoder的输出,生成一个长为m的序列(这里n和m是不一定一样长的)。与encoder不同的是decoder的词是一个一个生成的,而编码器很有可能是一次性看完整个句子(称为auto-regressive自回归)。在这里,输入又是输出,给定z,要生成第一个输出y1,在拿到y1之后就可以去生成y2,入股要生成yt,就可以把之前所有的y_1到y_(t-1)都拿到(所以在翻译的时候就是一个词一个词往外蹦)->在过去时刻的输出也会作为当前时刻的输入(这个就叫做自回归)。
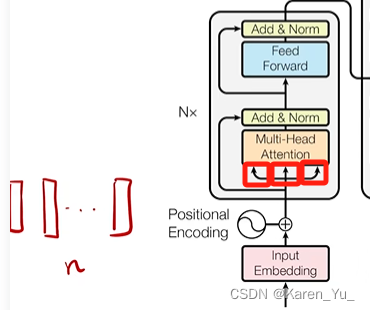
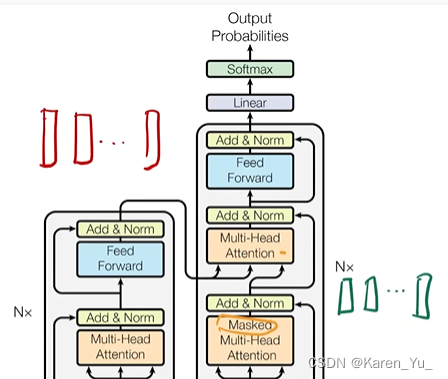
Transformer使用的是一个encoder-decoder的架构,具体来说是将一些自注意和point-wise fully connected layers堆在一起。如下图:

读图
首先这是一个encoder-decoder架构,左侧的是encoder,右侧是decoder。左下角是encoder的输入(比如中文翻译英文,那么这里就是中文的句子),右下角是decoder的输入,decoder在做预测的时候是没有输入的,实际上是decoder在之前时刻的输出作为这里的输入(所以这里写的是output,一个一个往右移(Shifted right 指的是 decoder 在之前时刻的一些输出,作为此时的输入。一个一个往右移。 )
输入进来先进入一个embedding,就是把进来的一个一个的词表示成一个一个的向量,在后面还加了一个positional encoding(稍后提到),再向上就是一个核心的encoder的架构了。这里的N×表示有N个(也就是有N个这样的层垒在一起,可以类似resnet定义为Transformer block),具体进去看到的第一个是multi-head attention,再有一个前馈神经网络,有两条拐弯的线就是残差的连接,再有一些normalization。
Transformer 的block
Multi-Head attention
Add & Norm: 残差连接 + Layernorm
Feed Forward: 前馈神经网络 MLP
https://www.bilibili.com/read/cv13759416/?jump_opus=1
encoder的输出会作为decoder的输入。decoder和encoder比较像,就是多了一个masked multi-head attention,也是作为一个block垒N次。最后的输出进入输出层,做一个softmax得到输出。
具体模块实现
encoder
encoder是用N个(N=6)的完全一样的层,每个layer里面会有两个sub-layers,第一个sub-layer叫做multi-head self-attention,第二个是叫做simple, positionwise fully connected fead-forward network(其实就是一个MLP),对每一个sub-layer用了一个残差链接,再使用一个layer normalization。最后每个sub-layer的输出可以写作:LayerNorm(x + Sublayer(x))。因为这里做了残差链接,而残差链接需要输入和输出的大小一致,如果大小不一致,需要做投影,简单起见,把每一层的输出维度变为512。
Batch Normalization
这里做一个插入,在resnet的时候我们用过了batch normalization,本质上就是为了让每一次的输出都别太离谱,不要出现什么梯度减没了或者上天了,以至于影响了训练的问题。在此回顾一下,也提供部分可以参考的博客、文章:
什么是批标准化 (Batch Normalization) - 知乎 (zhihu.com)
1805.11604.pdf (arxiv.org)
Batch Normalization(BN)超详细解析_batchnorm在预测阶段需要计算吗-CSDN博客
Batch Norm Explained Visually — How it works, and why neural networks need it | by Ketan Doshi | Towards Data Science
批量归一化(Batch Normalization)-CSDN博客
Batch Normalization原理与实战 - 知乎 (zhihu.com)
【基础算法】六问透彻理解BN(Batch Normalization) - 知乎 (zhihu.com)
在有些文章中指出BN使为了适应Internal Covariate Shift,但是第二个链接指向的论文似乎对这一理由存疑(说他们发现了更深层的原因),但是由于时间原因(当然也有篇幅原因),在我看完Transformer和BERT并且完成kaggle上面的练习之后会来读这篇文章。
Layer Normalization
Batch Normalization针对单个神经元进行,利用网络训练时一个 mini-batch 的数据来计算该神经元x_i的均值和方差。
Layer Normalization综合考虑一层所有维度的输入,计算该层的平均输入值和输入方差,然后用同一个规范化操作来转换各个维度的输入。
简单来说就是前一个针对的是不同样本的同一特征,而后一个针对的是同一样本的不同的特征,也就是说前一个不care特征和特征之间的关系,但是care样本和样本之间的关系,后者则更关心一个样本内不同特征之间的大小关系。
为什么不用batch normalization,因为RNN每个sequence的长度是不固定的,而batch normalization需要对不同样本的同一位置做标准化,那么很可能就会出现,有的样本有,有的样本没有的问题。同样对于NLP而言,同一个样本的特征和特征之间的关系反应的是时序上的变化,自然也不希望被norm掉。
参考:
模型优化之Layer Normalization - 知乎 (zhihu.com)
一文搞懂Batch Normalization 和 Layer Normalization - 知乎 (zhihu.com)
NLP中 batch normalization与 layer normalization - 知乎 (zhihu.com)
BN与LN的区别_bn和ln的区别-CSDN博客
Transformer中的归一化(五):Layer Norm的原理和实现 & 为什么Transformer要用LayerNorm - 知乎 (zhihu.com)
为什么Transformer要用LayerNorm? - 知乎 (zhihu.com)
[1607.06450] Layer Normalization (arxiv.org)
这里最后一篇也是论文,准备到时候和前面batch normalization一起读,放在一起写。


什么是LayerNorm?

老师在这里也对比了batch norm,包括也回答了为什么不用batch norm。
(弹幕:batchnorm会对一个batch里面的元素归一化,但是nlp任务长度不固定,如何加入0值的话,batchnorm会对这些0值一起归一化,所以用layernorm)
考虑一个最简单的二维输入的情况。那么输入就是一个矩阵。每一行是一个样本,每一列是一个feature。batch norm做的事就是,每一次把每一列,就是每一个特征,在一个小mini-batch里,把均值变成0,把方差变为1。(怎么把一个向量的均值变为0,方差变为1呢?把向量本身的均值减掉,再除以方差就可以了)在训练的时候,把每一个mini-batch里面的每个向量里面算出均值&方差,在预测的时候,会把全局的一个均值算出来。batch norm还会去学λ, γ,可以把这个向量通过学习放成一个任意均值、方差的。
layer norm是对每个样本做normalization。前面是把每一列的均值变0,方差变1,这里是把每一行的均值变0,方差变1。
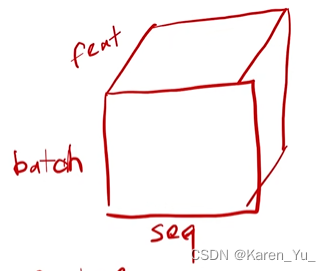
在正常的情况下,输入的是一个三维的。这个时候列就是sequence的长度,行就是batch,每一格都是一个词的vector。

(弹幕:feature是一个词的向量表示(512),seq是你这一句话里有多少个词,batch是一共几句话)
如果还是使用batch norm,每次都是取一个特征,把每个样本里所有的元素在这个特征下的值都搞出来,然后把他们的均值变为0,方差变为1。

(弹幕:LayerNorm:沿feature垂直于batch平面切割,BatchNorm:沿batch平面切割)
如果是layer norm的话,就是对每一个样本的所有信息做normalization。
切的方向不一样,会带来不一样的结果(这就很好理解之前说的layer norm实际上可以保留一个样本中不同特征的大小关系,因为做normalization的对象是某一个样本的所有feature,那么他们都经过相同的变换,自然大小关系得到了保留。而batch norm保留了某个特征下不同样本的大小关系也很好理解了。)
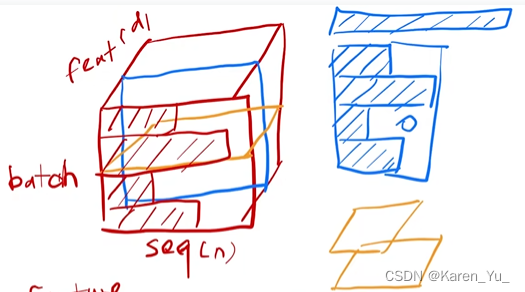
在时序的模型里,每一个样本的长度可能会有变化。一般没有数据的,我们会用0来填充。如果是batch norm,就有点类似于我们经常在B站看到的那种做饼干条,然后切片的那种视频,每一片切下来都是一样大小的。对于layer norm,每一片切出来的大小是不一定一样的。在算均值和方差的时候,batch norm(蓝色的图),只有话阴影的部分是有效的。如果样本长度变化比较大,每次做mini-batch的时候,算出来的均值和方差的抖动是比较大的。另外,在做预测的时候,我们需要记录全局的均值和方差。这个全局的均值&方差如果碰到一个新的预测样本,如果特别特别长(画在最上方的蓝色阴影块),在训练的时候没见过,那么训练时计算的均值和方差可能就不好用了。

对于layer norm就不存在这个问题,因为,也不需要存下来是每个样本自己算均值和方差,也不需要,因此无论长短,算均值和方差都是在specific的某个样本里面算,相对来说,稳定一些的。
(弹幕:感觉是,LayerNormalization关注于样本自身结构之间的关系,学习内部结构的特征;而,BatchNormalization是关注于突出样本之间的不同,学习样本之间的差异
做norm的目的是为了解决梯度弥散的问题啊,保证梯度不会往奇怪的方向发展,比如变得巨大或者巨小)
decoder
也是由6个同样的层构成的,每个层里都用了两个和encoder一样的sub-layer,也用到了残差链接和layer norm。在decoder这里,做的是自回归,也就是说当前的输入,其实是上面一些时刻的输出。也就是说在decoder训练的时候,在预测第t个时刻的输出的时候,不应该看到t时刻以后的输入(当然我们知道在注意力机制下,其实是能看到整个句子的),方法是使用了一个带mask(掩码)的注意力机制,保证不会看到t时候之后的输入。
Attention
注意力函数是将一个query和一些key-value对映射成一个输出的函数。这里的query、key、value和输出都是向量。具体来说,这里的输出是value的加权和,因此输出的维度和value的维度是一样的。对应每一个value的权重,是这个value对应的key和查询的query的相似度(compatibility function)
(弹幕:query查询,key键,value值。查询来自用户输入,键来自词典库,将查询与键(二者属性相同可比较),得到相似度权重,由value可数值化运算)

假设我有三个value和三个对应的key,假设我们现在给一个query,这个query跟第一个和第二个key比较近,输出就是这三个value的相加,但是第一个的权重会更大一些,第二个的权重也会更大一些,相比之下第三个value的权重就会更小一些。

如果再给一个离第三个key比较近的query,那就应该第三个和第二个value的权重更大,第一个相对更小。
Scaled Dot-Product Attention
这里query和key的长度是相等的,都等于d_k,value的长度是d_v,对每一个query和key做内积。如果内积越大(余弦值越大),就说明这两个向量的相似度越高,如果是0,就是这两个向量正交(没有相似度)。算出来之后再除以query的长度开根号,再用一个softmax得到权重(得到一系列非负的并且和为1 的权重)。
(弹幕:query就是你在b站搜索栏输入的文本,key就是与你搜索相关联的分类,value就是b站给你的最匹配视频)

attention = softmax(两个向量的内积值 / sqrt(d_k)) * V ,dk 是向量query的长度。
n:query的个数,m:key-value pair的个数,得到一个n×m的矩阵,这里每一行蓝色的线就是query对所有key的内积值。

这里的n×d_v的每一行就是我们要的输出了。(V是value)
一般有2 种常见的注意力机制:加性的注意力机制(它可以处理你的 query 和 key 不等长的情况),点积 dot-product 的注意力机制,这里基本上就是点积但是除了个数->所以叫scaled。
为什么要除以sqrt(d_k)?当向量长度比较长的时候,点积的值就可能比较大(也可能比较小),当值比较大的时候,相对的差距就会比较大,更大的值softmax之后就会更加靠近1,剩下的值就会更加靠近0(值更加向两端靠拢),这个时候梯度会比较小。softmax希望预测值,置信的地方尽量靠近1,不置信的地方尽量靠近0。
在transformer中,采用的d_k比较大(512),所以除以了一个sqrt(d_k)
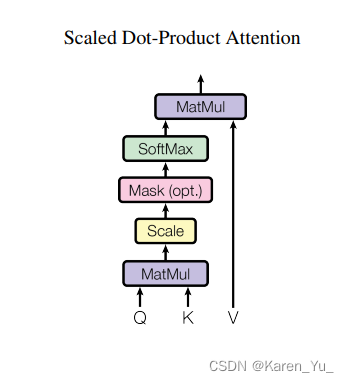
masked
怎么做mask(避免在时间t看到时间t以后的东西)。假设query和key是等长的,长度都为n,而且在时间上是能对应起来的。对于时刻t的query,在做计算的时候,应该只看k_1,……,k_(t-1),而不应该看k_t和之后的东西,因为k_t在当前时刻还没有。而在注意力机制中,我们实际上会看到所有,query实际上会和可以的所有做运算。但是问题不大,只要在算出来之后,在计算权重的时候,不要用到后面的东西就行了。
把 t 时刻以后 Qt 和 Kt 的值换成一个很大的负数,如 1 ^ (-10),在进入 softmax 后,权重变为0,这样就只有前面的值有效果。 --> 和 V 矩阵做矩阵乘法时,没看到 t 时刻以后的内容,只看 t 时刻之前的 key - value pair。
Multi-Head Attention
把query,key,value投影到一个低维,投影h次,再做h次的注意力函数,把每个函数的输出并在一起,再投影回来,得到最终的输出。
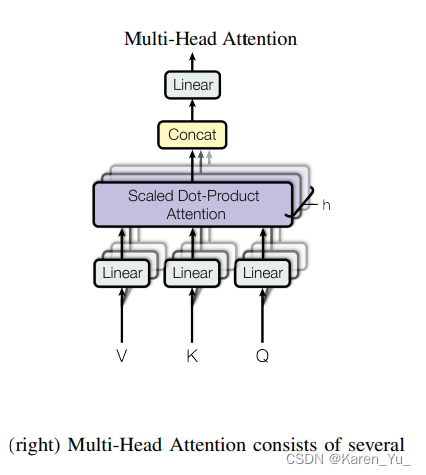
输入是:原始的 value、key、query
进入一个线形层,线形层把 value、key、query 投影到比较低的维度。然后再做一个 scaled dot product 。
执行h次会得到h个输出,再把h个输出向量全部合并在一起,最后做一次线性的投影
为什么要multi-head?一个 dot product 的注意力里面,没有什么可以学的参数。具体函数就是内积,为了识别不一样的模式,希望有不一样的计算相似度的办法。 类似于CNN的多个channel。
(弹幕:我认为就是解空间其实有很多,给模型充分的自由去学习。)
这里采用h=8。因为这里还用到残差链接,因此输入和输出的的维度是一样的。所以投影的维度就是输出的维度/h(这样直接拼接也就能恰好得到输出的维度了),这里就是512/8=64

三种不同的注意力层(图中阴影位置)。
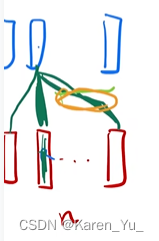
首先看encoder的注意力机制。假设句子长度为n,那么输入就是n个长为d的向量。注意力层有三个输入,分别是key, value, query。这里是同一个东西复制了三份,既作为key也作为value,也作为query(key、value 和 query 其实就是一个东西)。这里输入了n个query,每个query都有一个输出,那么总共就应该拿到n个输出。 输出和value的长度是一样的,所以输出的维度也是d(这说明输入和输出的大小是一样的)

这个输出实际上就是value的加权和,权重是query和key的相似度。图中绿色线代表权重,和自己的相似度最大、权重线最粗。假设和最右侧向量 相似度比较高,权重也会高一些、绿色线会粗一些。 假设我这里会学习h个不一样的们不考虑multi-head(有投影)的情况,输出实际上就是输入的加权和,权重来自于自己本身和各个向量之间的相似度。如果有multi-head的话(有投影),会学习h个不同的距离空间,使得输出不一样。
同样的,decoder这里,也是复制三份,只是长度不一样(m),维度也是一样的。所以和encoder是一样的自注意力。唯一不一样的事这里加了mask。也就是黄色圈圈画的地方要设置成0。
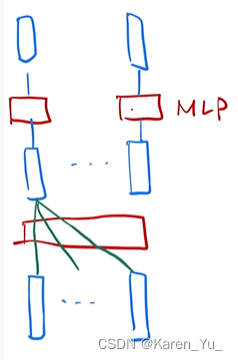
decoder的另一个注意力层,不再是自注意力,这里的key和value来自于encoder的输出,query来自于decoder下一个attention的输入。我们知道encoder的输出是n个长为d的向量(红色),decoder的masked attention的输出也是m个长为d的向量(绿色)。

输出(蓝色)是value的加权和,也就是来自encoder输出的加权和。这个粗细程度取决于query和key的相似度(权重 取决于红色和绿色的相似度)。
举例:Hello World --> 你好世界
计算 “好” 的时候,“好”作为 query ,会跟 “hello” 向量更相近一点,给 “hello” 向量一个比较大的权重。但是 "world" 跟后面的词相关, "world" 跟 当前的query (“好” )相关度没那么高。在算 “好” 的时候,我会给“hello” 向量一个比较大的权重。在算 query “世” 的时候,会给第二个 "world" 向量,一个比较大的权重。根据decoder的输入的不一样,会根据当前的 query 向量,去在encoder的输出里面去挑我(当前 query)感兴趣的东西。
query 注意到 当前的 query 感兴趣的东西,对当前的 query的不感兴趣的内容,可以忽略掉。 -> attention 作用:在 encoder 和 decoder 之间传递信息
Position-wise Feed-Forword Networks
其实就是一个fully connected feed-forward network,但是对每个词作用一次(position-wse)。Linear + ReLU + Linear,单隐藏层的 MLP,中间 W1 扩维到4倍 2048,最后 W2 投影回到 512 维度大小,便于残差连接。
如果使用pytorch实现:2个线性层。pytorch在输入是3d的时候,默认在最后一个维度做计算。
这里考虑一个最简单的情况:没有残差链接,也没有layer norm,attention也是单头的(没有投影)。输入是一串长为n的向量。在进入attention(红色大框框)之后,会得到同样长度的输出。在这里,attention就是对输入做一个加权的和。然后进入MLP,每个红色小方块的权重是一样的,得到一个transformer块的输出。->attention其实做的是把序列中的信息抓取出来,做一次aggregation(已经把感兴趣的东西抓取出来了)。在做MLP的时候映射到更想要的语义空间。所有感兴趣的东西都被抓出来了,经过attention之后的那个向量已经包含了序列信息,所以这里的MLP可以对每个点分开做。

作为对比,我们看一下RNN是怎么做的。输入是一样的,一些向量,对于第一个点,做一个线性层(假设这里做一个最简单的没有hidden layer的MLP),对下一个点怎么利用序列信息呢?还是用之前的MLP(权重是一样的),(绿色)是把上一个时刻的输出作为输入,并进当前的输入(新的输入是蓝色的线)。
都是用一个线性层/MLP来做语义空间的转换,不同的事如何传递序列的信息。RNN是把上一个时刻的信息输出传入下一个时刻的输入。在transformer里面是通过一个attention层,全局的拉取整个序列的信息,再用MLP做语义空间的转换。关注点都是怎么有效的使用序列信息。
Embeddings and Softmax
embedding,将输入的词(token)映射成向量。给任何一个词,学一个长度为d的向量来表示(这里d=512)。在encoder、decoder、softmax前面都需要embedding。采用相同的权重(这样训练起来简单一点)这里权重×了sqrt(d)。 学embedding的时候,会把每一个向量的 L2 Norm 学的比较小。比如:学成 1, 不论维度多大,最后的值都会 = 1。 如果维度大,学到的一些权重值就会变小,但之后还需要加上 positional encoding(不会随着维度的增加而变化),这样就可以让两个的scale差不多,方便做加法。
Positional Encoding
为什么需要?因为attention不会有时序信息。输出是value的加权和,权重是query和key之间的距离,与序列信息是无关的,根本不会看key-value pair在序列的什么地方。所以给一句话,无论怎么颠倒打乱,attention出来的结果都是一样的(顺序会变,值不会变)。所以在处理时序数据的时候,假设把句子打乱,语义肯定会发生变化,但是attention不会处理这个情况,所以要把时序信息加进来。
RNN是把上一时刻的输出作为下一时刻的输入来传递时序信息(所以本来就是时序的)。但是attention不是->在输入里加入时序信息。
在计算机里如何表示一个数字,假设用32位整数来表示一个数字->用32个bit,每个bit上有不同的值->一个数字是由一个长为32的数字来表示的。现在一个词会embedded成一个长为512的向量->同样,用一个长为512的向量来表示一个数字(位置),具体怎么算是使用周期不一样的sin和cos算出来的。
任何一个值可以用一个长为 512 的向量来表示。 这个长为 512 、记录了时序信息的一个positional encoding+ 嵌入层相加 --> 完成把时序信息加进数据。
输入进来进入 embedding 层之后,那么对每个词都会拿到那个向量长为 512 的一个向量。positional encodding (这个词在句子中的位置),返回一个长为 512 的向量,表示这个位置,然后把 embeding 和 positional encodding 加起来就行了。
positional encodding 是 cos 和 sin 的一个函数,在 [-1, +1] 之间抖动的。所以 input embedding * sqrt(d) ,使得乘积后的每个数字也是在差不多的 [-1, +1] 数值区间。相加完成 --> 在输入里面添加时序信息。
Why Self-Attention
比较四种不一样的层,比较计算复杂度(越低越好),顺序计算(越少越好)->不需要等,并行度更高,信息从一个数据点走到另一个数据点的路径长度(越短越好)

--------------------------------------------------------------------------------------
后续实验部分略,请参考:
Transformer论文逐段精读【论文精读】 - 哔哩哔哩
https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf