第8章 python深度学习——波斯美女
第8章 生成式深度学习
本章包括以下内容:
使用 LSTM 生成文本
实现 DeepDream
实现神经风格迁移
变分自编码器
了解生成式对抗网络
人工智能模拟人类思维过程的可能性,并不局限于被动性任务(比如目标识别)和大多数反应性任务(比如驾驶汽车),它还包括创造性活动。
2015 年夏天,我们见识了 Google 的 DeepDream 算法,它能够将一张图像转化为狗眼睛和错觉式伪影( pareidolic artifact )混合而成的迷幻图案。
2016 年,我们使用 Prisma 应用程序将照片变成各种风格的绘画。
2016 年夏天发布了一部实验性短片 Sunspring,它的剧本是由长短期记忆( LSTM )算法写成的,包括其中的对话。
最近可能你听过神经网络生成的实验性音乐。的确,到目前为止,我们见到的人工智能艺术作品的水平还很低。人工智能还远远比不上人类编剧、画家和作曲家。但是,替代人类始终都不是我们要谈论的主题,人工智能不会替代我们自己的智能,而是会为我们的生活和工作带来 更多的智能,即另一种类型的智能。
在许多领域,特别是创新领域中,人类将会使用人工智能作为增强自身能力的工具,实现比 人工智能更加 强大 的智能。
很大一部分的艺术创作都是简单的模式识别与专业技能。这正是很多人认为没有吸引力、甚至可有可无的那部分过程。这也正是人工智能发挥作用的地方。
我们的感知模式、语言和艺术作品都具有统计结构。 学习这种结构是深度学习算法所擅长的。机器学习模型能够对图像、音乐和故事的统计 潜在空间 ( latent space )进行学习,然后从这个空间中 采样 (sample),创造出与模型在训练数据中所见到的艺术作品具有相似特征的新作品。当然,这种采样本身并不是艺术创作行为。它只是一种数学运算,算法并没有关于人类生活、人类情感或我们人生经验的基础知识;相反,它从一种与我们的经验完全不同的经验中进行学习。 作为人类旁观者,只能靠我们的解释才能对模型生成的内容赋予意义 。但在技艺高超的艺术家手中,算法生成可以变得非常有意义,并且很美。潜在空间采样会变成一支画笔,能够提高艺术家的能力,增强我们的创造力,并拓展我们的想象空间。此外,它也不需要专业技能和练习,从而让艺术创作变得 更加容易。它创造了一种纯粹表达的新媒介,将艺术与技巧相分离。
Iannis Xenakis 是电子音乐和算法音乐领域一位有远见的先驱, 20 世纪 60 年代,对于将自动化技术应用于音乐创作,他表达了与上面相同的观点:
作曲家从繁琐的计算中解脱出来,从而能够全神贯注于解决新音乐形式所带来的一般性问题,并在修改输入数据值的同时探索这种形式的鲜为人知之处。例如,他可以测试所有的乐器组合,从独奏到室内管弦乐队再到大型管弦乐队。在电子计算机的帮助下,作曲家变成了一名飞行员:他按下按钮,引入坐标,并监控宇宙飞船在声音空间中的航行,飞船穿越声波的星座和星系,这是以前只能在遥不可及的梦中出现的场景。
本章将从各个角度探索深度学习在增强艺术创作方面的可能性。我们将介绍序列数据生成(可用于生成文本或音乐)、 DeepDream 以及使用 变分自编码器 和生成式对抗网络进行图像生成。我们会让计算机凭空创造出前所未见的内容,可能也会让你梦见科技与艺术交汇处的奇妙可能。让我们开始吧。
8.1 使用 LSTM 生成文本
本节将会探讨如何将循环神经网络用于生成序列数据。我们将以文本生成为例,但同样的技术也可以推广到任何类型的序列数据,你可以将其应用于音符序列来生成新音乐,也可以应用于笔画数据的时间序列(比如,艺术家在 iPad 上绘画时记录的笔画数据)来一笔一笔地生成绘画,以此类推。
序列数据生成绝不仅限于艺术内容生成。它已经成功应用于语音合成和聊天机器人的对话生成。 Google 于 2016 年发布的 Smart Reply(智能回复)功能,能够对电子邮件或短信自动生成一组快速回复,采用的也是相似的技术。
8.1.1 生成式循环网络简史
截至 2014 年年底,还没什么人见过 LSTM 这一缩写,即使在机器学习领域也不常见。用循环网络生成序列数据的成功应用在 2016 年才开始出现在主流领域。但是,这些技术都有着相当长的历,最早的是 1997 年开发的 LSTM 算法 。 这一新算法早期用于逐字符地生成文本。
2002 年,当时在瑞士 Schmidhuber 实验室工作的 Douglas Eck 首次将 LSTM 应用于音乐生成,
并得到了令人满意的结果。 Eck 现在是 Google Brain (谷歌大脑)的研究人员, 2016 年他在那里
创建了一个名为 Magenta 的新研究小组,重点研究将现代深度学习技术应用于制作迷人的音乐。
有时候,好的想法需要 15 年才能变成实践。
在 20 世纪末和 21 世纪初, Alex Graves 在使用循环网络生成序列数据方面做了重要的开创
性工作。特别是他在 2013 年的工作,利用笔触位置的时间序列将循环混合密度网络应用于生成
类似人类的手写笔迹,有人认为这是一个转折点。 a 在那个特定时刻,神经网络的这个具体应
用中, 能够做梦的机器 这一概念适时地引起了我的兴趣,并且在我开始开发 Keras 时为我提供
了重要的灵感。 Graves 在 2013 年上传到预印本服务器 arXiv 上的 LaTeX 文件中留下了一条类似
的注释性评论:“ 序列数据生成是计算机所做的最接近于做梦的事情 。”几年之后,我们将这些
进展视作理所当然,但在当时看到 Graves 的演示,很难不为其中所包含的可能性感到惊叹并受
到启发。
从那以后,循环神经网络已被成功应用于音乐生成、对话生成、图像生成、语音合成和分子设计。它甚至还被用于制作电影剧本,然后由真人演员来表演。
8.1.2 如何生成序列数据
用深度学习生成序列数据的 通用方法,就是使用前面的标记作为输入,训练一个网络(通常是循环神经网络或卷积神经网络)来预测序列中接下来的一个或多个标记。 例如,给定输入the cat is on the ma ,训练网络来预测目标 t ,即下一个字符。与前面处理文本数据时一样,标记( token)通常是单词或字符,给定前面的标记,能够对下一个标记的概率进行建模的任何网络都叫作 语言模型 ( language model )。语言模型能够捕捉到语言的 潜在空间 ( latent space),即语言的统计结构。
一旦训练好了这样一个语言模型,就可以从中 采样 ( sample ,即生成新序列)。向模型中输
入一个初始文本字符串[即 条件数据 ( conditioning data )],要求模型生成下一个字符或下一个
单词(甚至可以同时生成多个标记),然后将生成的输出添加到输入数据中,并多次重复这一过
程(见图 8-1 )。这个循环可以生成任意长度的序列,这些序列反映了模型训练数据的结构,它
们与人类书写的句子 几乎 相同。在本节的示例中,我们将会用到一个 LSTM 层,向其输入从文
本语料中提取的 N 个字符组成的字符串,然后训练模型来生成第 N +1 个字符。 模型的输出是对
所有可能的字符做 softmax , 得到下一个字符的概率分布 。这个 LSTM 叫作 字符级的神经语言模
型(character-level neural language model) 。

8.1.3 采样策略的重要性
生成文本时,如何选择下一个字符至关重要。一种简单的方法是 贪婪采样(greedy sampling) , 就是始终选择 可能性最大的下一个字符 。但这种方法会得到重复的、可预测的字符串,看起来不像是连贯的语言。一种更有趣的方法是做出稍显意外的选择:在采样过程中引入随机性,即从下一个字符的概率分布中进行采样。这叫作 随机采样(stochastic sampling , stochasticity 在这个领域中就是“随机”的意思)。在这种情况下,根据模型结果,如果下一个字符是 e 的概率为 0.3 ,那么你会有 30% 的概率选择它。注意,贪婪采样也可以被看作从一个概率分布中进行采样,即某个字符的概率为 1 ,其他所有字符的概率都是 0 。
从模型的 softmax 输出中进行概率采样是一种很巧妙的方法,它甚至可以在某些时候采样
到不常见的字符,从而生成看起来更加有趣的句子,而且有时会得到训练数据中没有的、听起
来像是真实存在的新单词,从而表现出创造性。但这种方法有一个问题,就是它在采样过程中
无法 控制随机性的大小 。
为什么需要有一定的随机性 ?考虑一个极端的例子——纯随机采样,即从均匀概率分布中抽取下一个字符,其中每个字符的概率相同。这种方案具有最大的随机性,换句话说,这种概率分布具有 最大的熵 。当然,它不会生成任何有趣的内容。再来看另一个极端——贪婪采样。
贪婪采样也不会生成任何有趣的内容,它没有任何随机性,即相应的 概率分布具有最小的熵 。
从“真实”概率分布(即模型 softmax 函数输出的分布)中进行采样,是这两个极端之间的一
个中间点。但是,还有许多其他中间点具有更大或更小的熵,你可能希望都研究一下。 更小的
熵可以让生成的序列具有更加可预测的结构(因此可能看起来更真实),而更大的熵会得到更加
出人意料且更有创造性的序列。 从生成式模型中进行采样时,在生成过程中探索不同的随机性
大小总是好的做法。我们人类是生成数据是否有趣的最终判断者,所以有趣是非常主观的,我
们无法提前知道最佳熵的位置。
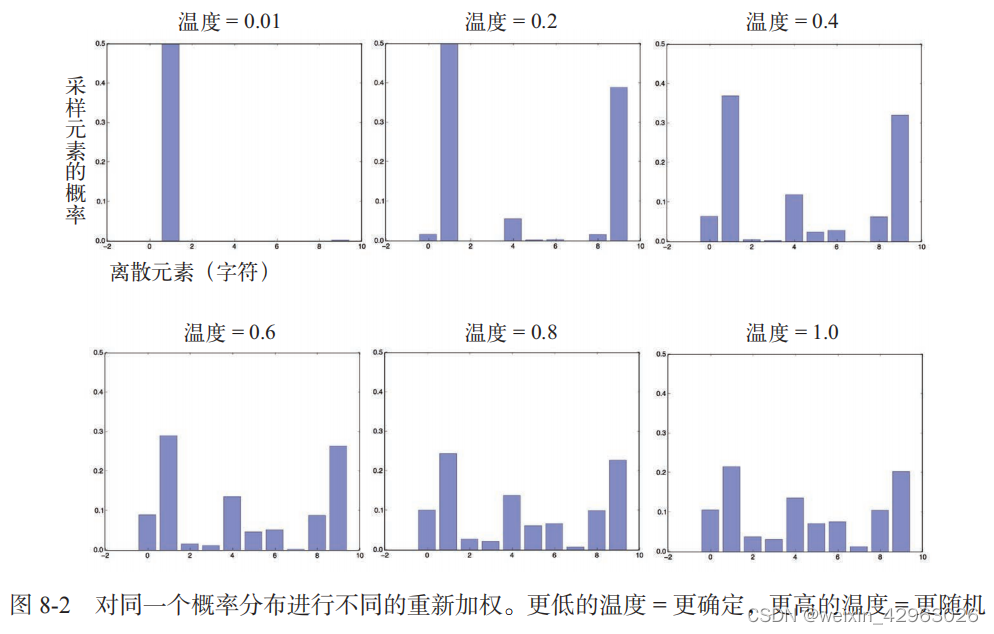
为了在采样过程中控制随机性的大小 ,我们引入一个叫作 softmax 温度(softmax temperature) 的参数,用于表示采样概率分布的熵,即表示所选择的下一个字符会有多么出人意料或多么可预测。给定一个 temperature 值,将按照下列方法对原始概率分布(即模型的 softmax 输出)进行重新加权,计算得到一个新的概率分布。
代码清单 8-1 对于不同的 softmax 温度,对概率分布进行重新加权
import numpy as np# original_distribution 是概率值组成的一维 Numpy 数组,
# 这些概率值之和必须等于 1。temperature 是一个因子,
# 用于定量描述输出分布的熵
def reweight_distribution(original_distribution, temperature=0.5):distribution = np.log(original_distribution) / temperaturedistribution = np.exp(distribution)# 返回原始分布重新加权后的结果。# distribution的求和可能不再等于1,# 因此需要将它除以求和,以得到新的分布return distribution / np.sum(distribution)更高的温度得到的是熵更大的采样分布,会生成更加出人意料、更加无结构的生成数据,而更低的温度对应更小的随机性,以及更加可预测的生成数据(见图 8-2)。
8.1.4 实现字符级的 LSTM 文本生成
下面用 Keras 来实现这些想法。首先需要可用于学习语言模型的大量文本数据。我们可以使用任意足够大的一个或多个文本文件——维基百科、《指环王》等。本例将使用 尼采 的一些作品,他是 19 世纪末期的德国哲学家,这些作品已经被翻译成英文。 因此,我们要学习的语言模型将是针对于尼采的写作风格和主题的模型,而不是关于英语的通用模型。
1. 准备数据
首先下载语料,并将其转换为小写。
import keras
import numpy as np
path = keras.utils.get_file(
'nietzsche.txt',
origin='https://s3.amazonaws.com/text-datasets/nietzsche.txt')
text = open(path).read().lower()
print('Corpus length:', len(text)) 接下来,我们要提取长度为 maxlen 的序列(这些序列之间存在部分重叠),对它们进行
one-hot 编码 ,然后将其打包成形状为 (sequences, maxlen, unique_characters) 的三维Numpy 数组。与此同时,我们还需要准备一个数组 y,其中包含对应的目标,即在每一个所提取的序列之后出现的字符(已进行 one-hot 编码)。
代码清单 8-3 将字符序列向量化
# 代码清单8-3将字符序列向量化
maxlen = 60 # 提取 60 个字符组成的序列
step = 3 # 每 3 个字符采样一个新序列
sentences = [] # 保存所提取的序列
next_chars = [] # 保存目标(即下一个字符)for i in range(0, len(text) - maxlen, step):sentences.append(text[i: i + maxlen])next_chars.append(text[i + maxlen])print('Number of sequences:', len(sentences))chars = sorted(list(set(text))) # 语料中唯一字符组成的列表
print('Unique characters:', len(chars))# 一个字典,将唯一字符映射为它在列表 chars 中的索引
char_indices = dict((char, chars.index(char)) for char in chars)print('Vectorization...')
x = np.zeros((len(sentences), maxlen, len(chars)), dtype=np.bool)
y = np.zeros((len(sentences), len(chars)), dtype=np.bool)# 将字符 one-hot 编码为二进制数组
for i, sentence in enumerate(sentences):for t, char in enumerate(sentence):x[i, t, char_indices[char]] = 1y[i, char_indices[next_chars[i]]] = 12. 构建网络
这个网络是一个单层 LSTM ,然后是一个 Dense 分类器和对所有可能字符的 softmax 。但要
注意, 循环神经网络并不是序列数据生成的唯一方法 ,最近已经证明一维卷积神经网络也可以
成功用于序列数据生成。
# 代码清单8 - 4用于预测下一个字符的单层LSTM模型
from keras import layersmodel = keras.models.Sequential()
model.add(layers.LSTM(128, input_shape=(maxlen, len(chars))))
model.add(layers.Dense(len(chars), activation='softmax')) 目标是经过 one-hot 编码的,所以训练模型需要使用 categorical_crossentropy 作为损失。
# 代码清单 8-5 模型编译配置
optimizer = keras.optimizers.RMSprop(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=optimizer) 3. 训练语言模型并从中采样
给定一个训练好的模型和一个种子文本片段,我们可以通过重复以下操作来生成新的文本。
(1) 给定目前已生成的文本,从模型中得到下一个字符的概率分布。
(2) 根据某个温度对分布进行重新加权。
(3) 根据重新加权后的分布对下一个字符进行随机采样。
(4) 将新字符添加到文本末尾。
下列代码将对模型得到的原始概率分布进行重新加权,并从中抽取一个字符索引[ 采样函
数 ( sampling function )]。
# 代码清单 8-6 给定模型预测,采样下一个字符的函数
def sample(preds, temperature=1.0):preds = np.asarray(preds).astype('float64')preds = np.log(preds) / temperatureexp_preds = np.exp(preds)preds = exp_preds / np.sum(exp_preds)probas = np.random.multinomial(1, preds, 1)return np.argmax(probas) 最后,下面这个循环将反复训练并生成文本。在每轮过后都使用一系列不同的温度值来生成
文本。这样我们可以看到,随着模型收敛,生成的文本如何变化,以及温度对采样策略的影响。
# 代码清单 8-7 文本生成循环for epoch in range(1, 60):print('epoch', epoch)model.fit(x, y, batch_size=128, epochs=1)start_index = random.randint(0, len(text) - maxlen - 1)generated_text = text[start_index: start_index + maxlen]print('--- Generating with seed: "' + generated_text + '"')for temperature in [0.2, 0.5, 1.0, 1.2]: # 尝试一系列不同的采样温度print('------ temperature:', temperature)sys.stdout.write(generated_text)# 从种子文本开始,生成 400个字符for i in range(400):# 对目前生成的字符进行one-hot 编码sampled = np.zeros((1, maxlen, len(chars)))for t, char in enumerate(generated_text):sampled[0, t, char_indices[char]] = 1.# 对下一个字符进行采样preds = model.predict(sampled, verbose=0)[0]next_index = sample(preds, temperature)next_char = chars[next_index]generated_text += next_chargenerated_text = generated_text[1:]sys.stdout.write(next_char) 这里我们使用的 随机种子文本 是 new faculty, and the jubilation reached its climax when kant 。
第 20 轮时, temperature=0.2 的输出如下所示,此时模型还远没有完全收敛。
poch 21
1565/1565 [==============================] - 55s 35ms/step - loss: 1.5468
--- Generating with seed: "this our mode?--from german heart came this vexed ululating?"
epoch 22
1565/1565 [==============================] - 56s 35ms/step - loss: 1.5346
--- Generating with seed: " come to his fantastic consequent
of the so called discretio"
epoch 23
1565/1565 [==============================] - 56s 36ms/step - loss: 1.5224
--- Generating with seed: "or
introspection, and is accustomed to severe discipline and"可见,较小的温度值会得到极端重复和可预测的文本,但局部结构是非常真实的,特别是所有单词都是真正的英文单词(单词就是字符的局部模式)。随着温度值越来越大,生成的文本也变得更有趣、更出人意料,甚至更有创造性,它有时会创造出全新的单词,听起来有几分可信(比如 eterned 和 troveration)。对于较大的温度值,局部模式开始分解,大部分单词看起来像是半随机的字符串。毫无疑问,在这个特定的设置下,0.5 的温度值生成的文本最为有趣。一定要尝试多种采样策略!在学到的结构与随机性之间,巧妙的平衡能够让生成的序列非常有趣。
注意,利用更多的数据训练一个更大的模型,并且训练时间更长,生成的样本会比上面的结果看起来更连贯、更真实。 但是,不要期待能够生成任何有意义的文本,除非是很偶然的情况。
你所做的只是从一个统计模型中对数据进行采样,这个模型是关于字符先后顺序的模型。语言
是一种信息沟通渠道,信息的内容与信息编码的统计结构是有区别的。为了展示这种区别,我
们来看一个思想实验:如果人类语言能够更好地压缩通信,就像计算机对大部分数字通信所做
的那样,那么会发生什么?语言仍然很有意义,但不会具有任何内在的统计结构,所以不可能
像刚才那样学习一个语言模型。
8.1.5 小结
我们可以生成离散的序列数据,其方法是:给定前面的标记,训练一个模型来预测接下来的一个或多个标记。
对于文本来说,这种模型叫作 语言模型 。它可以是单词级的,也可以是字符级的。
对下一个标记进行采样,需要在坚持模型的判断与引入随机性之间寻找平衡。
处理这个问题的一种方法是使用 softmax 温度 。一定要尝试多种不同的温度,以找到合适的那一个。
8.2 DeepDream
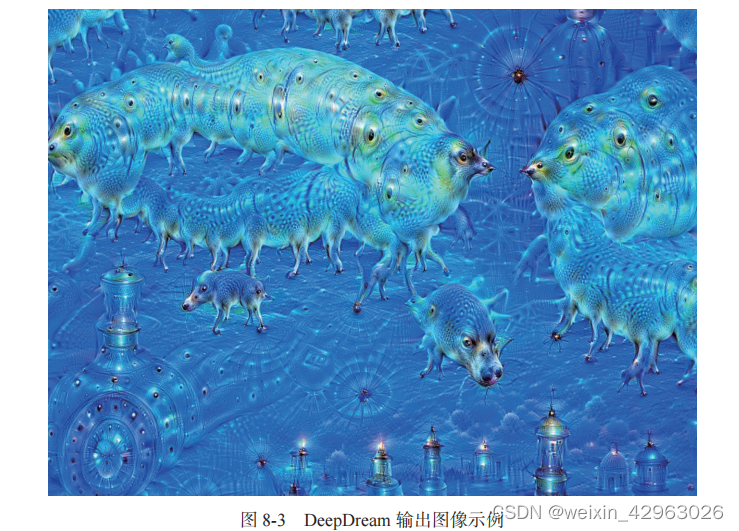
DeepDream 是一种艺术性的图像修改技术,它用到了 卷积神经网络 学到的表示。DeepDream 由 Google 于 2015 年夏天首次发布,使用 Caffe 深度学习库编写实现(当时比 TensorFlow 的首 次公开发布要早几个月)。 a它很快在网上引起了轰动,这要归功于它所生成的迷幻图像(比如 图 8-3 ),图像中充满了算法生成的错觉式伪影、鸟羽毛和狗眼睛。这是 DeepDream 卷积神经网络在 ImageNet 上训练的副作用,因为 ImageNet 中狗和鸟的样本特别多。
参见 Alexander Mordvintsev 、 Christopher Olah 和 Mike Tyka 于 2015 年 7 月 1 日在 Google Research Blog 上发表的 文章“ DeepDream: a code example for visualizing neural networks ”。
DeepDream 算法与第 5 章介绍的卷积神经网络过滤器可视化技术几乎相同,都是反向运行
一个卷积神经网络:对卷积神经网络的输入做梯度上升,以便将卷积神经网络靠顶部的某一层
的某个过滤器激活最大化。 DeepDream 使用了相同的想法,但有以下这几个简单的区别。
使用 DeepDream ,我们尝试 将所有层的激活最大化 ,而不是将某一层的激活最大化,因此需要同时将大量特征的可视化混合在一起。
不是从空白的、略微带有噪声的输入开始,而是 从现有的图像开始 ,因此所产生的效果能够抓住已经存在的视觉模式,并以某种艺术性的方式将图像元素扭曲。
输入图像是 在不同的尺度上 [叫作 八度 ( octave )]进行处理的,这可以提高可视化的质量。
我们来生成一些 DeepDream 图像。
8.2.1 用 Keras 实现 DeepDream
我们将从一个在 ImageNet 上预训练的卷积神经网络开始。 Keras 中有许多这样的卷积神经网络: V GG16、VGG19、Xception、ResNet50 等。我们可以用其中任何一个来实现 DeepDream,但我们选择的卷积神经网络会影响可视化的效果,因为不同的卷积神经网络架构会学到不同的特征。最初发布的 DeepDream 中使用的卷积神经网络是一个 Inception 模型 ,在实践中,人们已经知道 Inception 能够生成漂亮的 DeepDream 图像,所以我们将使用 Keras 内置的 Inception V3模型。
接下来,我们要计算 损失(loss) ,即在梯度上升过程中需要最大化的量。在第 5 章的过滤器可视化中,我们试图将某一层的某个过滤器的值最大化。这里,我们要将多个层的所有过滤
器的激活同时最大化。具体来说,就是对一组靠近顶部的层激活的 L2 范数进行加权求和,然
后将其最大化。选择哪些层(以及它们对最终损失的贡献)对生成的可视化结果具有很大影响,
所以我们希望让这些参数变得易于配置。更靠近底部的层生成的是几何图案,而更靠近顶部的
层生成的则是从中能够看出某些 ImageNet 类别(比如鸟或狗)的图案。我们将随意选择 4 层的
配置,但你以后一定要探索多个不同的配置。
代码清单 8-8 加载预训练的 Inception V3 模型