YOLOv5改进 | 一文汇总:如何在网络结构中添加注意力机制、C3、卷积、Neck、SPPF、检测头
一、本文介绍
本篇文章的内容是在大家得到一个改进版本的C3一个新的注意力机制、或者一个新的卷积模块、或者是检测头的时候如何替换我们YOLOv5模型中的原有的模块,从而用你的模块去进行训练模型或者检测。因为最近开了一个专栏里面涉及到挺多改进的地方,不能每篇文章都去讲解一遍如何修改,就想着在这里单独出一期文章进行一个总结性教程,大家可以从我的其它文章中拿到修改后的代码,从这篇文章学会如何去添加到你的模型结构中去,本文的内容已经包含了YOLOv5所有改进的修改教程。
本文目前的改进教程包括:注意力机制、C3(改进后的)、卷积(主干上的)、Neck、检测头、损失函数、SPPF。
欢迎大家订阅我的专栏一起学习YOLO!
目录
一、本文介绍
二、Conv的修改教程
2.1 AKConv的核心代码
2.2 AKConv的添加教程
2.2.1 修改一
2.2.2 修改二
2.2.3 修改三
2.2.4 修改四
2.3 AKConv的yaml文件
三、注意力机制和C3的修改教程
3.1 AcMix的核心代码
3.2 ACmix添加步骤
3.2.1 修改一
3.2.2 修改二
3.2.3 修改三
3.2.4 修改四
3.3 ACmix注意力的yaml文件
3.4ACmix注意力C3的yaml文件
四、 Neck的修改教程
4.1 BiFPN代码
4.2 细节修改教程
4.2.1 修改一
4.2.2 修改二
4.2.3 修改三
4.2.4 修改四
4.3 BiFPN的yaml文件
五、检测头的修改教程
5.1 CLLAHead的核心代码
5.2 手把手教你添加CLLAHead检测头
5.2.1 修改一
5.2.2 修改二
5.2.3 修改三
5.2.4 修改四
5.2.5. 修改五
5.2.6 修改六
5.3 DynamicHead检测头的yaml文件
六、 损失函数
6.1 MPDIoU的代码复现
6.2 手把手教你添加MPDIoU到你的模型中
6.2.1 修改一
6.2.2 修改二
6.2.3 使用方式
七、SPPF的修改方式
7.1 SPPF的核心代码
7.2 手把手教你添加FocalModulation
7.2.1 修改一
7.2.2 修改二
7.2.3 修改三
7.2.4 修改四
7.3 FocalModulation的yaml文件
八、本文总结
二、Conv的修改教程
2.1 AKConv的核心代码
在AKConv的官方代码中有一个版本的警告我给进行了一定的处理解决了,该代码的使用方式我们看章节四进行使用。
(同时我修改了AKConv官方版本在训练到最后一个轮次报错和版本警告的问题RuntimeError: CUDA error: device-side assert triggered)
下面代码里面已经集成了,AKConv和替换了AKConv的C3和Bottleneck模块。
import torch.nn as nn
import torch
from einops import rearrange
import mathfrom models.common import Convclass AKConv(nn.Module):def __init__(self, inc, outc, num_param, stride=1, bias=None):super(AKConv, self).__init__()self.num_param = num_paramself.stride = strideself.conv = nn.Sequential(nn.Conv2d(inc, outc, kernel_size=(num_param, 1), stride=(num_param, 1), bias=bias),nn.BatchNorm2d(outc),nn.SiLU()) # the conv adds the BN and SiLU to compare original Conv in YOLOv5.self.p_conv = nn.Conv2d(inc, 2 * num_param, kernel_size=3, padding=1, stride=stride)nn.init.constant_(self.p_conv.weight, 0)self.p_conv.register_full_backward_hook(self._set_lr)@staticmethoddef _set_lr(module, grad_input, grad_output):grad_input = (grad_input[i] * 0.1 for i in range(len(grad_input)))grad_output = (grad_output[i] * 0.1 for i in range(len(grad_output)))def forward(self, x):# N is num_param.offset = self.p_conv(x)dtype = offset.data.type()N = offset.size(1) // 2# (b, 2N, h, w)p = self._get_p(offset, dtype)# (b, h, w, 2N)p = p.contiguous().permute(0, 2, 3, 1)q_lt = p.detach().floor()q_rb = q_lt + 1q_lt = torch.cat([torch.clamp(q_lt[..., :N], 0, x.size(2) - 1), torch.clamp(q_lt[..., N:], 0, x.size(3) - 1)],dim=-1).long()q_rb = torch.cat([torch.clamp(q_rb[..., :N], 0, x.size(2) - 1), torch.clamp(q_rb[..., N:], 0, x.size(3) - 1)],dim=-1).long()q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], dim=-1)q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], dim=-1)# clip pp = torch.cat([torch.clamp(p[..., :N], 0, x.size(2) - 1), torch.clamp(p[..., N:], 0, x.size(3) - 1)], dim=-1)# bilinear kernel (b, h, w, N)g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_lt[..., N:].type_as(p) - p[..., N:]))g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_rb[..., N:].type_as(p) - p[..., N:]))g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_lb[..., N:].type_as(p) - p[..., N:]))g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_rt[..., N:].type_as(p) - p[..., N:]))# resampling the features based on the modified coordinates.x_q_lt = self._get_x_q(x, q_lt, N)x_q_rb = self._get_x_q(x, q_rb, N)x_q_lb = self._get_x_q(x, q_lb, N)x_q_rt = self._get_x_q(x, q_rt, N)# bilinearx_offset = g_lt.unsqueeze(dim=1) * x_q_lt + \g_rb.unsqueeze(dim=1) * x_q_rb + \g_lb.unsqueeze(dim=1) * x_q_lb + \g_rt.unsqueeze(dim=1) * x_q_rtx_offset = self._reshape_x_offset(x_offset, self.num_param)out = self.conv(x_offset)return out# generating the inital sampled shapes for the AKConv with different sizes.def _get_p_n(self, N, dtype):base_int = round(math.sqrt(self.num_param))row_number = self.num_param // base_intmod_number = self.num_param % base_intp_n_x, p_n_y = torch.meshgrid(torch.arange(0, row_number),torch.arange(0, base_int), indexing='xy')p_n_x = torch.flatten(p_n_x)p_n_y = torch.flatten(p_n_y)if mod_number > 0:mod_p_n_x, mod_p_n_y = torch.meshgrid(torch.arange(row_number, row_number + 1),torch.arange(0, mod_number),indexing='xy')mod_p_n_x = torch.flatten(mod_p_n_x)mod_p_n_y = torch.flatten(mod_p_n_y)p_n_x, p_n_y = torch.cat((p_n_x, mod_p_n_x)), torch.cat((p_n_y, mod_p_n_y))p_n = torch.cat([p_n_x, p_n_y], 0)p_n = p_n.view(1, 2 * N, 1, 1).type(dtype)return p_n# no zero-paddingdef _get_p_0(self, h, w, N, dtype):p_0_x, p_0_y = torch.meshgrid(torch.arange(0, h * self.stride, self.stride),torch.arange(0, w * self.stride, self.stride),indexing='xy')p_0_x = torch.flatten(p_0_x).view(1, 1, h, w).repeat(1, N, 1, 1)p_0_y = torch.flatten(p_0_y).view(1, 1, h, w).repeat(1, N, 1, 1)p_0 = torch.cat([p_0_x, p_0_y], 1).type(dtype)return p_0def _get_p(self, offset, dtype):N, h, w = offset.size(1) // 2, offset.size(2), offset.size(3)# (1, 2N, 1, 1)p_n = self._get_p_n(N, dtype)# (1, 2N, h, w)p_0 = self._get_p_0(h, w, N, dtype)p = p_0 + p_n + offsetreturn pdef _get_x_q(self, x, q, N):b, h, w, _ = q.size()padded_w = x.size(3)c = x.size(1)# (b, c, h*w)x = x.contiguous().view(b, c, -1)# (b, h, w, N)index = q[..., :N] * padded_w + q[..., N:] # offset_x*w + offset_y# (b, c, h*w*N)index = index.contiguous().unsqueeze(dim=1).expand(-1, c, -1, -1, -1).contiguous().view(b, c, -1)# 根据实际情况调整index = index.clamp(min=0, max=x.shape[-1] - 1)x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N)return x_offset# Stacking resampled features in the row direction.@staticmethoddef _reshape_x_offset(x_offset, num_param):b, c, h, w, n = x_offset.size()# using Conv3d# x_offset = x_offset.permute(0,1,4,2,3), then Conv3d(c,c_out, kernel_size =(num_param,1,1),stride=(num_param,1,1),bias= False)# using 1 × 1 Conv# x_offset = x_offset.permute(0,1,4,2,3), then, x_offset.view(b,c×num_param,h,w) finally, Conv2d(c×num_param,c_out, kernel_size =1,stride=1,bias= False)# using the column conv as follow, then, Conv2d(inc, outc, kernel_size=(num_param, 1), stride=(num_param, 1), bias=bias)x_offset = rearrange(x_offset, 'b c h w n -> b c (h n) w')return x_offsetclass Bottleneck_AKConv(nn.Module):# Standard bottleneckdef __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = AKConv(c_, c2, 3, 1)self.add = shortcut and c1 == c2def forward(self, x):return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))class C3_AKConv(nn.Module):# CSP Bottleneck with 3 convolutionsdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)self.m = nn.Sequential(*(Bottleneck_AKConv(c_, c_, shortcut, g, e=1.0) for _ in range(n)))def forward(self, x):return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))2.2 AKConv的添加教程
2.2.1 修改一
我们找到如下的目录'yolov5-master/models'在这个目录下创建一整个文件目录(注意是目录,因为我这个专栏会出很多的更新,这里用一种一劳永逸的方法)文件目录起名modules,然后在下面新建一个AKConv.py文件,将我们的代码复制粘贴进去。
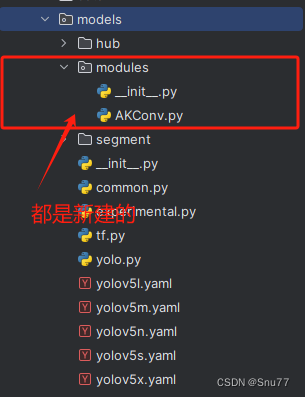
2.2.2 修改二
然后新建一个__init__.py文件,然后我们在里面添加一行代码。注意标记一个'.'
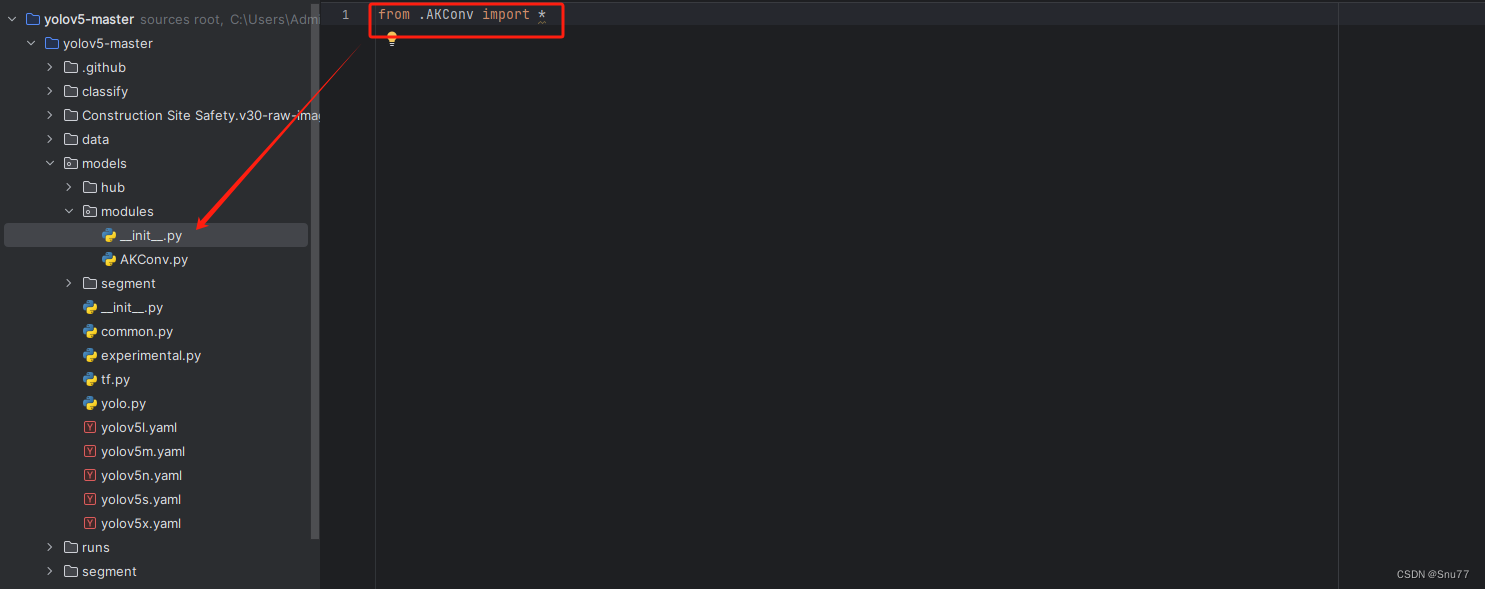
2.2.3 修改三
然后我们找到如下文件''models/yolo.py''在开头的地方导入我们的模块按照如下修改->
注意标记一个'.'
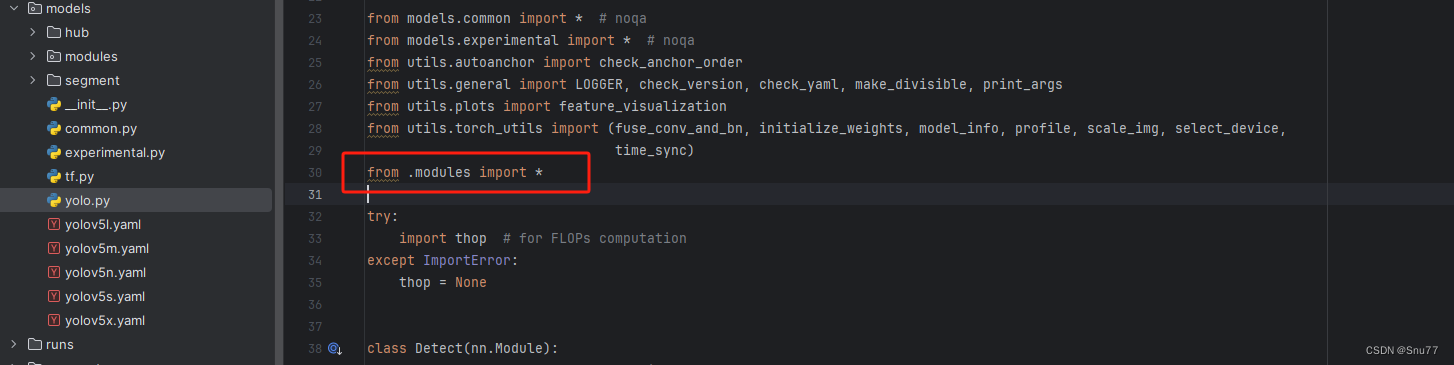
2.2.4 修改四
然后我们找到parse_model方法,按照如下修改->
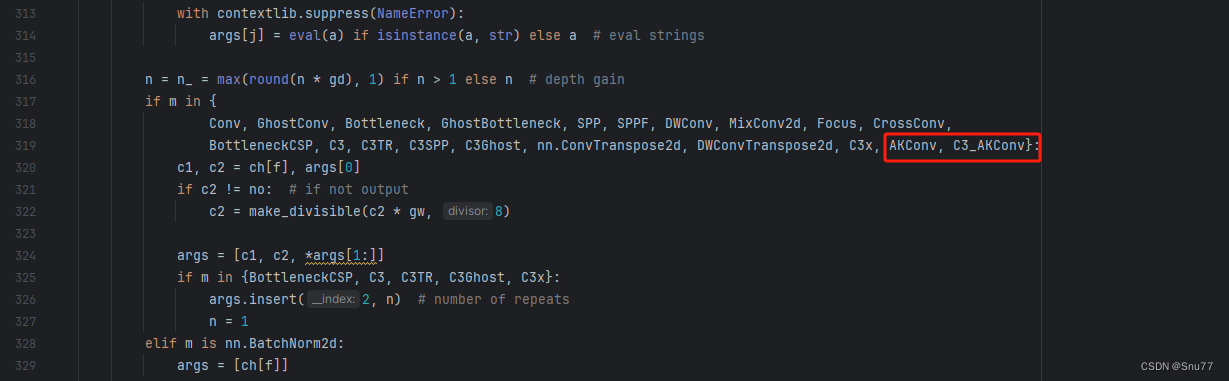
到此就修改完成了,复制下面的ymal文件即可运行。
2.3 AKConv的yaml文件
下面的配置文件为我修改的AKConv的位置。
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, AKConv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, AKConv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, AKConv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, AKConv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, AKConv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, AKConv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, AKConv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, AKConv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]三、注意力机制和C3的修改教程
3.1 AcMix的核心代码
该代码本身存在一个bug,会导致验证的适合报类型不匹配的错误,我将其进行了解决,这也是一个读者和我说的想要帮忙解决一下这个问题困扰了他很久。
import torch
import torch.nn as nndef position(H, W, type, is_cuda=True):if is_cuda:loc_w = torch.linspace(-1.0, 1.0, W).cuda().unsqueeze(0).repeat(H, 1).to(type)loc_h = torch.linspace(-1.0, 1.0, H).cuda().unsqueeze(1).repeat(1, W).to(type)else:loc_w = torch.linspace(-1.0, 1.0, W).unsqueeze(0).repeat(H, 1)loc_h = torch.linspace(-1.0, 1.0, H).unsqueeze(1).repeat(1, W)loc = torch.cat([loc_w.unsqueeze(0), loc_h.unsqueeze(0)], 0).unsqueeze(0)return locdef stride(x, stride):b, c, h, w = x.shapereturn x[:, :, ::stride, ::stride]def init_rate_half(tensor):if tensor is not None:tensor.data.fill_(0.5)def init_rate_0(tensor):if tensor is not None:tensor.data.fill_(0.)class ACmix(nn.Module):def __init__(self, in_planes, kernel_att=7, head=4, kernel_conv=3, stride=1, dilation=1):super(ACmix, self).__init__()out_planes = in_planesself.in_planes = in_planesself.out_planes = out_planesself.head = headself.kernel_att = kernel_attself.kernel_conv = kernel_convself.stride = strideself.dilation = dilationself.rate1 = torch.nn.Parameter(torch.Tensor(1))self.rate2 = torch.nn.Parameter(torch.Tensor(1))self.head_dim = self.out_planes // self.headself.conv1 = nn.Conv2d(in_planes, out_planes, kernel_size=1)self.conv2 = nn.Conv2d(in_planes, out_planes, kernel_size=1)self.conv3 = nn.Conv2d(in_planes, out_planes, kernel_size=1)self.conv_p = nn.Conv2d(2, self.head_dim, kernel_size=1)self.padding_att = (self.dilation * (self.kernel_att - 1) + 1) // 2self.pad_att = torch.nn.ReflectionPad2d(self.padding_att)self.unfold = nn.Unfold(kernel_size=self.kernel_att, padding=0, stride=self.stride)self.softmax = torch.nn.Softmax(dim=1)self.fc = nn.Conv2d(3 * self.head, self.kernel_conv * self.kernel_conv, kernel_size=1, bias=False)self.dep_conv = nn.Conv2d(self.kernel_conv * self.kernel_conv * self.head_dim, out_planes,kernel_size=self.kernel_conv, bias=True, groups=self.head_dim, padding=1,stride=stride)self.reset_parameters()def reset_parameters(self):init_rate_half(self.rate1)init_rate_half(self.rate2)kernel = torch.zeros(self.kernel_conv * self.kernel_conv, self.kernel_conv, self.kernel_conv)for i in range(self.kernel_conv * self.kernel_conv):kernel[i, i // self.kernel_conv, i % self.kernel_conv] = 1.kernel = kernel.squeeze(0).repeat(self.out_planes, 1, 1, 1)self.dep_conv.weight = nn.Parameter(data=kernel, requires_grad=True)self.dep_conv.bias = init_rate_0(self.dep_conv.bias)def forward(self, x):q, k, v = self.conv1(x), self.conv2(x), self.conv3(x)scaling = float(self.head_dim) ** -0.5b, c, h, w = q.shapeh_out, w_out = h // self.stride, w // self.stride# ### att# ## positional encodingpe = self.conv_p(position(h, w, x.dtype, x.is_cuda))q_att = q.view(b * self.head, self.head_dim, h, w) * scalingk_att = k.view(b * self.head, self.head_dim, h, w)v_att = v.view(b * self.head, self.head_dim, h, w)if self.stride > 1:q_att = stride(q_att, self.stride)q_pe = stride(pe, self.stride)else:q_pe = peunfold_k = self.unfold(self.pad_att(k_att)).view(b * self.head, self.head_dim,self.kernel_att * self.kernel_att, h_out,w_out) # b*head, head_dim, k_att^2, h_out, w_outunfold_rpe = self.unfold(self.pad_att(pe)).view(1, self.head_dim, self.kernel_att * self.kernel_att, h_out,w_out) # 1, head_dim, k_att^2, h_out, w_outatt = (q_att.unsqueeze(2) * (unfold_k + q_pe.unsqueeze(2) - unfold_rpe)).sum(1) # (b*head, head_dim, 1, h_out, w_out) * (b*head, head_dim, k_att^2, h_out, w_out) -> (b*head, k_att^2, h_out, w_out)att = self.softmax(att)out_att = self.unfold(self.pad_att(v_att)).view(b * self.head, self.head_dim, self.kernel_att * self.kernel_att,h_out, w_out)out_att = (att.unsqueeze(1) * out_att).sum(2).view(b, self.out_planes, h_out, w_out)## convf_all = self.fc(torch.cat([q.view(b, self.head, self.head_dim, h * w), k.view(b, self.head, self.head_dim, h * w),v.view(b, self.head, self.head_dim, h * w)], 1))f_conv = f_all.permute(0, 2, 1, 3).reshape(x.shape[0], -1, x.shape[-2], x.shape[-1])out_conv = self.dep_conv(f_conv)return self.rate1 * out_att + self.rate2 * out_convdef autopad(k, p=None, d=1): # kernel, padding, dilation# Pad to 'same' shape outputsif d > 1:k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-sizeif p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn pclass Conv(nn.Module):# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)default_act = nn.SiLU() # default activationdef __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):super().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):return self.act(self.conv(x))class Bottleneck(nn.Module):# Standard bottleneckdef __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_, c2, 3, 1, g=g)self.Attention = ACmix(c2, 11)self.add = shortcut and c1 == c2def forward(self, x):return x + self.Attention(self.cv2(self.cv1(x))) if self.add else self.Attention(self.cv2(self.cv1(x)))class C3_ACmix(nn.Module):# CSP Bottleneck with 3 convolutionsdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))def forward(self, x):return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))if __name__ == "__main__":# Generating Sample imageimage_size = (1, 24, 224, 224)image = torch.rand(*image_size)# Modelmobilenet_v1 = ACmix(24, 24)out = mobilenet_v1(image)print(out)3.2 ACmix添加步骤
3.2.1 修改一
首先我们找到如下的目录'yolov5-master/models',然后在这个目录下在创建一个新的目录然后这个就是存储改进的仓库,大家可以在这里新建所有的改进的py文件,对应改进的文件名字可以根据你自己的习惯起(不影响任何但是下面导入的时候记住改成你对应的即可),然后将ACmix的核心代码复制进去。
3.2.2 修改二
然后在新建的目录里面我们在新建一个__init__.py文件(此文件大家只需要建立一个即可),然后我们在里面添加导入我们模块的代码。注意标记一个'.'其作用是标记当前目录。
3.2.3 修改三
然后我们找到如下文件''models/yolo.py''在开头的地方导入我们的模块按照如下修改->
(如果你看了我多个改进机制此处只需要添加一个即可,无需重复添加)
注意的添加位置要放在common的导入上面!!!!!

3.2.4 修改四
然后我们找到''models/yolo.py''文件中的parse_model方法,按照如下修改->

elif m in {'此处添加大家修改的对应机制即可'}:args = [ch[f], *args]到此就修改完成了,复制下面的ymal文件即可运行。
3.3 ACmix注意力的yaml文件
下面的添加ACmix是我实验结果的版本,我仅在大目标检测层的输出添加了一个ACmix模块。
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[-1, 1, ACmix, []], # 24# 这里是在大物体检测层的输出加一个注意力机制,如果你是其它物体检测比如做小目标检测可以加在17层后面,20层就是标准物体检测[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]3.4ACmix注意力C3的yaml文件
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3_ACmix, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3_ACmix, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3_ACmix, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3_ACmix, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3_ACmix, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3_ACmix, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3_ACmix, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3_ACmix, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]四、 Neck的修改教程
4.1 BiFPN代码
看到这里不知道大家有没有理解BiFPN,BiFPN是一种结构、一种思想,并不是特指某些卷积、某些注意力机制那样,所以其重要的是如何配置yaml文件实现BiFPN的那种结构和思想,但是其也和其它的FPN有一个区别就是它的拼接方式并不是Concat那样,所以需要下面的代码来配合实现BiFPN。
同样该代码的使用方式我们复制'ultralytics/nn/modules'到该目录下,创建一个py文件粘贴进去,我这里起名为BiFPN(这里有一个注意点是不要和定义的类重名有时候会报错)。
import torch.nn as nn
import torchclass swish(nn.Module):def forward(self, x):return x * torch.sigmoid(x)class Bi_FPN(nn.Module):def __init__(self, length):super().__init__()self.weight = nn.Parameter(torch.ones(length, dtype=torch.float32), requires_grad=True)self.swish = swish()self.epsilon = 0.0001def forward(self, x):weights = self.weight / (torch.sum(self.swish(self.weight), dim=0) + self.epsilon) # 权重归一化处理weighted_feature_maps = [weights[i] * x[i] for i in range(len(x))]stacked_feature_maps = torch.stack(weighted_feature_maps, dim=0)result = torch.sum(stacked_feature_maps, dim=0)return result4.2 细节修改教程
4.2.1 修改一
我们找到如下的目录'yolov5-master/models'在这个目录下创建一个文件目录(注意是目录,因为我这个专栏会出很多的更新,这里用一种一劳永逸的方法)文件目录起名modules,然后在下面新建一个文件,将我们的代码复制粘贴进去。
4.2.2 修改二
然后新建一个__init__.py文件,然后我们在里面添加一行代码。注意标记一个'.'其作用是标记当前目录。

4.2.3 修改三
然后我们找到如下文件''models/yolo.py''在开头的地方导入我们的模块按照如下修改->
(如果你看了我多个改进机制此处只需要添加一个即可,无需重复添加)

4.2.4 修改四
然后我们找到parse_model方法,按照如下修改->

elif m is Bi_FPN:length = len([ch[x] for x in f])args = [length]到此就修改完成了,复制下面的ymal文件即可运行。
4.3 BiFPN的yaml文件
复制粘贴下面的代码即可运行,现在是三个头的,我前面的文章说过要出一个四个头的检测头,估计这两天会配合这个BiFPN更新。
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:- [10, 13, 16, 30, 33, 23] # P3/8- [30, 61, 62, 45, 59, 119] # P4/16- [116, 90, 156, 198, 373, 326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[4, 1, Conv, [256]], # 10[6, 1, Conv, [256]], # 11[9, 1, Conv, [256]], # 12[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 13 P5->P4[[-1, 11], 1, Bi_FPN, []], # 14[-1, 3, C3, [256]], # 15 (T1/8-small)[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 16 P4->P3[[-1, 10], 1, Bi_FPN, []], # 17[-1, 3, C3, [256]], # 18 (T2/8-small)[2, 1, Conv, [256, 3, 2]], # 19[[-1, 10, 18], 1, Bi_FPN, []], # 20[-1, 3, C3, [256]], # 21 (T3/8-small)[-1, 1, Conv, [256, 3, 2]], # 22[[-1, 11, 15], 1, Bi_FPN, []], # 23[-1, 3, C3, [512]], # 24 (T4/16-medium)[-1, 1, Conv, [256, 3, 2]], # 25 P4->P5[[-1, 12], 1, Bi_FPN, []], # 26[-1, 3, C3, [1024]], # 27 (T5/32-large)[[21, 24, 27], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]五、检测头的修改教程
5.1 CLLAHead的核心代码
import math
import torch
import torch.nn as nn
from ultralytics.utils.tal import dist2bbox, make_anchorsfrom utils.general import check_versiondef autopad(k, p=None, d=1): # kernel, padding, dilation# Pad to 'same' shape outputsif d > 1:k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-sizeif p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn pclass Conv(nn.Module):# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)default_act = nn.SiLU() # default activationdef __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):super().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):return self.act(self.conv(x))class Proto(nn.Module):# YOLOv5 mask Proto module for segmentation modelsdef __init__(self, c1, c_=256, c2=32): # ch_in, number of protos, number of maskssuper().__init__()self.cv1 = Conv(c1, c_, k=3)self.upsample = nn.Upsample(scale_factor=2, mode='nearest')self.cv2 = Conv(c_, c_, k=3)self.cv3 = Conv(c_, c2)def forward(self, x):return self.cv3(self.cv2(self.upsample(self.cv1(x))))class DFL(nn.Module):"""Integral module of Distribution Focal Loss (DFL).Proposed in Generalized Focal Loss https://ieeexplore.ieee.org/document/9792391"""def __init__(self, c1=16):"""Initialize a convolutional layer with a given number of input channels."""super().__init__()self.conv = nn.Conv2d(c1, 1, 1, bias=False).requires_grad_(False)x = torch.arange(c1, dtype=torch.float)self.conv.weight.data[:] = nn.Parameter(x.view(1, c1, 1, 1))self.c1 = c1def forward(self, x):"""Applies a transformer layer on input tensor 'x' and returns a tensor."""b, c, a = x.shape # batch, channels, anchorsreturn self.conv(x.view(b, 4, self.c1, a).transpose(2, 1).softmax(1)).view(b, 4, a)# return self.conv(x.view(b, self.c1, 4, a).softmax(1)).view(b, 4, a)class CLLA(nn.Module):def __init__(self, range, c):super().__init__()self.c_ = cself.q = nn.Linear(self.c_, self.c_)self.k = nn.Linear(self.c_, self.c_)self.v = nn.Linear(self.c_, self.c_)self.range = rangeself.attend = nn.Softmax(dim = -1)def forward(self, x1, x2):b1, c1, w1, h1 = x1.shapeb2, c2, w2, h2 = x2.shapeassert b1 == b2 and c1 == c2x2_ = x2.permute(0, 2, 3, 1).contiguous().unsqueeze(3)pad = int(self.range / 2 - 1)padding = nn.ZeroPad2d(padding=(pad, pad, pad, pad))x1 = padding(x1)local = []for i in range(int(self.range)):for j in range(int(self.range)):tem = x1tem = tem[..., i::2, j::2][..., :w2, :h2].contiguous().unsqueeze(2)local.append(tem)local = torch.cat(local, 2)x1 = local.permute(0, 3, 4, 2, 1)q = self.q(x2_)k, v = self.k(x1), self.v(x1)dots = torch.sum(q * k / self.range, 4)irr = torch.mean(dots, 3).unsqueeze(3) * 2 - dotsatt = self.attend(irr)out = v * att.unsqueeze(4)out = torch.sum(out, 3)out = out.squeeze(3).permute(0, 3, 1, 2).contiguous()# x2 = x2.squeeze(3).permute(0, 3, 1, 2).contiguous()return (out + x2) / 2# return outclass CLLABlock(nn.Module):def __init__(self, range=2, ch=256, ch1=128, ch2=256, out=0):super().__init__()self.range = rangeself.c_ = chself.cout = outself.conv1 = nn.Conv2d(ch1, self.c_, 1)self.conv2 = nn.Conv2d(ch2, self.c_, 1)self.att = CLLA(range = range, c = self.c_)self.det = nn.Conv2d(self.c_, out, 1)def forward(self, x1, x2):x1 = self.conv1(x1)x2 = self.conv2(x2)f = self.att(x1, x2)return self.det(f)class CLLAHead(nn.Module):# YOLOv5 Detect head for detection modelsstride = None # strides computed during builddynamic = False # force grid reconstructionexport = False # export modedef __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layersuper().__init__()self.nc = nc # number of classesself.no = nc + 5 # number of outputs per anchorself.nl = len(anchors) # number of detection layersself.na = len(anchors[0]) // 2 # number of anchorsself.grid = [torch.empty(0) for _ in range(self.nl)] # init gridself.anchor_grid = [torch.empty(0) for _ in range(self.nl)] # init anchor gridself.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)self.det = CLLABlock(range=2, ch=ch[1], ch1=ch[0], ch2=ch[1], out=self.no * 3)self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch * 3) # output convself.inplace = inplace # use inplace ops (e.g. slice assignment)def forward(self, x):y1 = x[0]z = [] # inference outputfor i in range(self.nl):if i == 1:x[i] = self.det(y1, x[1])else:x[i] = self.m[i](x[i]) # convbs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()if not self.training: # inferenceif self.dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)if isinstance(self, Segment_AFPN): # (boxes + masks)xy, wh, conf, mask = x[i].split((2, 2, self.nc + 1, self.no - self.nc - 5), 4)xy = (xy.sigmoid() * 2 + self.grid[i]) * self.stride[i] # xywh = (wh.sigmoid() * 2) ** 2 * self.anchor_grid[i] # why = torch.cat((xy, wh, conf.sigmoid(), mask), 4)else: # Detect (boxes only)xy, wh, conf = x[i].sigmoid().split((2, 2, self.nc + 1), 4)xy = (xy * 2 + self.grid[i]) * self.stride[i] # xywh = (wh * 2) ** 2 * self.anchor_grid[i] # why = torch.cat((xy, wh, conf), 4)z.append(y.view(bs, self.na * nx * ny, self.no))return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)def _make_grid(self, nx=20, ny=20, i=0, torch_1_10=check_version(torch.__version__, '1.10.0')):d = self.anchors[i].devicet = self.anchors[i].dtypeshape = 1, self.na, ny, nx, 2 # grid shapey, x = torch.arange(ny, device=d, dtype=t), torch.arange(nx, device=d, dtype=t)yv, xv = torch.meshgrid(y, x, indexing='ij') if torch_1_10 else torch.meshgrid(y, x) # torch>=0.7 compatibilitygrid = torch.stack((xv, yv), 2).expand(shape) - 0.5 # add grid offset, i.e. y = 2.0 * x - 0.5anchor_grid = (self.anchors[i] * self.stride[i]).view((1, self.na, 1, 1, 2)).expand(shape)return grid, anchor_gridclass Segment_AFPN(CLLAHead):# YOLOv5 Segment head for segmentation modelsdef __init__(self, nc=80, anchors=(), nm=32, npr=256, ch=(), inplace=True):super().__init__(nc, anchors, ch, inplace)self.nm = nm # number of masksself.npr = npr # number of protosself.no = 5 + nc + self.nm # number of outputs per anchorself.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output convself.proto = Proto(ch[0], self.npr, self.nm) # protosself.detect = CLLAHead.forwarddef forward(self, x):p = self.proto(x[0])x = self.detect(self, x)return (x, p) if self.training else (x[0], p) if self.export else (x[0], p, x[1])if __name__ == "__main__":# Generating Sample imageimage1 = (16, 64, 80, 80)image2 = (16, 128, 40, 40)image3 = (16, 256, 20, 20)image1 = torch.rand(image1)image2 = torch.rand(image2)image3 = torch.rand(image3)image = [image1, image2, image3]channel = (64, 128, 256)num_classes = 80num_layers = 3use_dfl = Truereg_max = 16head = CLLAHead(num_classes, channel)out = head(image)print(len(out))5.2 手把手教你添加CLLAHead检测头
这里教大家添加检测头,检测头的添加相对于其它机制来说比较复杂一点,修改的地方比较多。
5.2.1 修改一
首先我们找到如下的目录'yolov5-master/models',然后在这个目录下在创建一个新的目录然后这个就是存储改进的仓库,大家可以在这里新建所有的改进的py文件,对应改进的文件名字可以根据你自己的习惯起(不影响任何但是下面导入的时候记住改成你对应的即可),然后将CLLAHead的核心代码复制进去。
5.2.2 修改二
然后在新建的目录里面我们在新建一个__init__.py文件(此文件大家只需要建立一个即可),然后我们在里面添加导入我们模块的代码。注意标记一个'.'其作用是标记当前目录。

5.2.3 修改三
然后我们找到如下文件''models/yolo.py''在开头的地方导入我们的模块按照如下修改->
(如果你看了我多个改进机制此处只需要添加一个即可,无需重复添加)
注意的添加位置要放在common的导入上面!!!!!
5.2.4 修改四
我下面的修改都是按照顺序来的,总共还需要修改三处位置即可,按照我的来添加即可。

5.2.5. 修改五
同理按照我的修改即可。

5.2.6 修改六
同理按照我的修改即可

到此就修改完成了。
5.3 DynamicHead检测头的yaml文件
大家复制运行即可。
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, CLLAHead, [nc, anchors]], # Detect(P3, P4, P5)]六、 损失函数
6.1 MPDIoU的代码复现
论文中不仅提出了MPDIoU还提出了一个LMPDIoU但是这个LMPDIoU我用了以后模型根本收敛不了,所以我不知道这是我数据集的原因还是其它原因导致的,但是MPDIoU我使用效果是非常好的,其中我还添加了Focus和Inner的思想, 如果你Inner和MPDIoU都设置为True使用的就是InnerMPDIoU,如果Inner为False但是MPDIoU设置为True就是MPDIoU,Focus同理,大家可以多进行尝试。
import numpy as np
import torch
import mathdef xyxy2xywh(x):# Convert nx4 boxes from [x1, y1, x2, y2] to [x, y, w, h] where xy1=top-left, xy2=bottom-righty = x.clone() if isinstance(x, torch.Tensor) else np.copy(x)y[..., 0] = (x[..., 0] + x[..., 2]) / 2 # x centery[..., 1] = (x[..., 1] + x[..., 3]) / 2 # y centery[..., 2] = x[..., 2] - x[..., 0] # widthy[..., 3] = x[..., 3] - x[..., 1] # heightreturn yclass WIoU_Scale:''' monotonous: {None: origin v1True: monotonic FM v2False: non-monotonic FM v3}momentum: The momentum of running mean'''iou_mean = 1.monotonous = False_momentum = 1 - 0.5 ** (1 / 7000)_is_train = Truedef __init__(self, iou):self.iou = iouself._update(self)@classmethoddef _update(cls, self):if cls._is_train: cls.iou_mean = (1 - cls._momentum) * cls.iou_mean + \cls._momentum * self.iou.detach().mean().item()@classmethoddef _scaled_loss(cls, self, gamma=1.9, delta=3):if isinstance(self.monotonous, bool):if self.monotonous:return (self.iou.detach() / self.iou_mean).sqrt()else:beta = self.iou.detach() / self.iou_meanalpha = delta * torch.pow(gamma, beta - delta)return beta / alphareturn 1def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, EIoU=False, SIoU=False, WIoU=False, ShapeIoU=False,hw=1, mpdiou=False, Inner=False, alpha=1, ratio=0.7, eps=1e-7, scale=0.0):"""Calculate Intersection over Union (IoU) of box1(1, 4) to box2(n, 4).Args:box1 (torch.Tensor): A tensor representing a single bounding box with shape (1, 4).box2 (torch.Tensor): A tensor representing n bounding boxes with shape (n, 4).xywh (bool, optional): If True, input boxes are in (x, y, w, h) format. If False, input boxes are in(x1, y1, x2, y2) format. Defaults to True.GIoU (bool, optional): If True, calculate Generalized IoU. Defaults to False.DIoU (bool, optional): If True, calculate Distance IoU. Defaults to False.CIoU (bool, optional): If True, calculate Complete IoU. Defaults to False.EIoU (bool, optional): If True, calculate Efficient IoU. Defaults to False.SIoU (bool, optional): If True, calculate Scylla IoU. Defaults to False.eps (float, optional): A small value to avoid division by zero. Defaults to 1e-7.Returns:(torch.Tensor): IoU, GIoU, DIoU, or CIoU values depending on the specified flags."""if Inner:if not xywh:box1, box2 = xyxy2xywh(box1), xyxy2xywh(box2)(x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)b1_x1, b1_x2, b1_y1, b1_y2 = x1 - (w1 * ratio) / 2, x1 + (w1 * ratio) / 2, y1 - (h1 * ratio) / 2, y1 + (h1 * ratio) / 2b2_x1, b2_x2, b2_y1, b2_y2 = x2 - (w2 * ratio) / 2, x2 + (w2 * ratio) / 2, y2 - (h2 * ratio) / 2, y2 + (h2 * ratio) / 2# Intersection areainter = (b1_x2.minimum(b2_x2) - b1_x1.maximum(b2_x1)).clamp_(0) * \(b1_y2.minimum(b2_y2) - b1_y1.maximum(b2_y1)).clamp_(0)# Union Areaunion = w1 * h1 * ratio * ratio + w2 * h2 * ratio * ratio - inter + epsiou = inter / union# Get the coordinates of bounding boxeselse:if xywh: # transform from xywh to xyxy(x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1)w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_else: # x1, y1, x2, y2 = box1b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + epsw2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps# Intersection areainter = (b1_x2.minimum(b2_x2) - b1_x1.maximum(b2_x1)).clamp_(0) * \(b1_y2.minimum(b2_y2) - b1_y1.maximum(b2_y1)).clamp_(0)# Union Areaunion = w1 * h1 + w2 * h2 - inter + eps# IoUiou = inter / unionif CIoU or DIoU or GIoU or EIoU or SIoU or ShapeIoU or mpdiou or WIoU:cw = b1_x2.maximum(b2_x2) - b1_x1.minimum(b2_x1) # convex (smallest enclosing box) widthch = b1_y2.maximum(b2_y2) - b1_y1.minimum(b2_y1) # convex heightif CIoU or DIoU or EIoU or SIoU or mpdiou or WIoU or ShapeIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squaredrho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 + (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center dist ** 2if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47v = (4 / math.pi ** 2) * (torch.atan(w2 / h2) - torch.atan(w1 / h1)).pow(2)with torch.no_grad():alpha = v / (v - iou + (1 + eps))return iou - (rho2 / c2 + v * alpha) # CIoUelif EIoU:rho_w2 = ((b2_x2 - b2_x1) - (b1_x2 - b1_x1)) ** 2rho_h2 = ((b2_y2 - b2_y1) - (b1_y2 - b1_y1)) ** 2cw2 = cw ** 2 + epsch2 = ch ** 2 + epsreturn iou - (rho2 / c2 + rho_w2 / cw2 + rho_h2 / ch2) # EIoUelif SIoU:# SIoU Loss https://arxiv.org/pdf/2205.12740.pdfs_cw = (b2_x1 + b2_x2 - b1_x1 - b1_x2) * 0.5 + epss_ch = (b2_y1 + b2_y2 - b1_y1 - b1_y2) * 0.5 + epssigma = torch.pow(s_cw ** 2 + s_ch ** 2, 0.5)sin_alpha_1 = torch.abs(s_cw) / sigmasin_alpha_2 = torch.abs(s_ch) / sigmathreshold = pow(2, 0.5) / 2sin_alpha = torch.where(sin_alpha_1 > threshold, sin_alpha_2, sin_alpha_1)angle_cost = torch.cos(torch.arcsin(sin_alpha) * 2 - math.pi / 2)rho_x = (s_cw / cw) ** 2rho_y = (s_ch / ch) ** 2gamma = angle_cost - 2distance_cost = 2 - torch.exp(gamma * rho_x) - torch.exp(gamma * rho_y)omiga_w = torch.abs(w1 - w2) / torch.max(w1, w2)omiga_h = torch.abs(h1 - h2) / torch.max(h1, h2)shape_cost = torch.pow(1 - torch.exp(-1 * omiga_w), 4) + torch.pow(1 - torch.exp(-1 * omiga_h), 4)return iou - 0.5 * (distance_cost + shape_cost) + eps # SIoUelif ShapeIoU:#Shape-Distance #Shape-Distance #Shape-Distance #Shape-Distance #Shape-Distance #Shape-Distance #Shape-Distanceww = 2 * torch.pow(w2, scale) / (torch.pow(w2, scale) + torch.pow(h2, scale))hh = 2 * torch.pow(h2, scale) / (torch.pow(w2, scale) + torch.pow(h2, scale))cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # convex widthch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # convex heightc2 = cw ** 2 + ch ** 2 + eps # convex diagonal squaredcenter_distance_x = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2) / 4center_distance_y = ((b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4center_distance = hh * center_distance_x + ww * center_distance_ydistance = center_distance / c2#Shape-Shape #Shape-Shape #Shape-Shape #Shape-Shape #Shape-Shape #Shape-Shape #Shape-Shape #Shape-Shapeomiga_w = hh * torch.abs(w1 - w2) / torch.max(w1, w2)omiga_h = ww * torch.abs(h1 - h2) / torch.max(h1, h2)shape_cost = torch.pow(1 - torch.exp(-1 * omiga_w), 4) + torch.pow(1 - torch.exp(-1 * omiga_h), 4)return iou - distance - 0.5 * shape_costelif mpdiou:cw2 = torch.pow(cw ** 2 + eps, alpha)ch2 = torch.pow(ch ** 2 + eps, alpha)d12 = ((b2_x1 - b1_x1) - (b2_y1 - b1_y1)) ** 2d22 = ((b2_x2 - b1_x2) - (b2_y2 - b1_y2)) ** 2return iou - ((d12 + d22) / (cw2 + ch2))elif WIoU:self = WIoU_Scale(1 - iou)dist = getattr(WIoU_Scale, '_scaled_loss')(self)return iou * dist # WIoU https://arxiv.org/abs/2301.10051return iou - rho2 / c2 # DIoUc_area = cw * ch + eps # convex areareturn iou - (c_area - union) / c_area # GIoU https://arxiv.org/pdf/1902.09630.pdfreturn iou # IoU6.2 手把手教你添加MPDIoU到你的模型中
6.2.1 修改一
我们找到如下的文件'yolov5-master/utils/metrics.py'其中有一个和代码块一同名的函数,我们将其进行完全替换,用代码块一替换下面的代码。

6.2.2 修改二
我们找到'yolov5-master/utils/loss.py'进行修改,在其中我们首先找到'class ComputeLoss:类'然后在其前向传播中,有下面一串代码,我们用代码块二进行替换。

6.2.3 使用方式
我们在这一行代码中进行修改我们使用的损失函数即可,这里就是使用CIoU。
iou = bbox_iou(pbox, tbox[i], mpdiou=True, Inner=False).squeeze() # iou(prediction, target)七、SPPF的修改方式
7.1 SPPF的核心代码
我们将在“ultralytics/nn/modules”目录下面创建一个文件将其复制进去,使用方法在后面会讲。
class FocalModulation(nn.Module):def __init__(self, dim, focal_window=3, focal_level=2, focal_factor=2, bias=True, proj_drop=0.,use_postln_in_modulation=False, normalize_modulator=False):super().__init__()self.dim = dimself.focal_window = focal_windowself.focal_level = focal_levelself.focal_factor = focal_factorself.use_postln_in_modulation = use_postln_in_modulationself.normalize_modulator = normalize_modulatorself.f_linear = nn.Conv2d(dim, 2 * dim + (self.focal_level + 1), kernel_size=1, bias=bias)self.h = nn.Conv2d(dim, dim, kernel_size=1, stride=1, bias=bias)self.act = nn.GELU()self.proj = nn.Conv2d(dim, dim, kernel_size=1)self.proj_drop = nn.Dropout(proj_drop)self.focal_layers = nn.ModuleList()self.kernel_sizes = []for k in range(self.focal_level):kernel_size = self.focal_factor * k + self.focal_windowself.focal_layers.append(nn.Sequential(nn.Conv2d(dim, dim, kernel_size=kernel_size, stride=1,groups=dim, padding=kernel_size // 2, bias=False),nn.GELU(),))self.kernel_sizes.append(kernel_size)if self.use_postln_in_modulation:self.ln = nn.LayerNorm(dim)def forward(self, x):"""Args:x: input features with shape of (B, H, W, C)"""C = x.shape[1]# pre linear projectionx = self.f_linear(x).contiguous()q, ctx, gates = torch.split(x, (C, C, self.focal_level + 1), 1)# context aggreationctx_all = 0.0for l in range(self.focal_level):ctx = self.focal_layers[l](ctx)ctx_all = ctx_all + ctx * gates[:, l:l + 1]ctx_global = self.act(ctx.mean(2, keepdim=True).mean(3, keepdim=True))ctx_all = ctx_all + ctx_global * gates[:, self.focal_level:]# normalize contextif self.normalize_modulator:ctx_all = ctx_all / (self.focal_level + 1)# focal modulationx_out = q * self.h(ctx_all)x_out = x_out.contiguous()if self.use_postln_in_modulation:x_out = self.ln(x_out)# post linear porjectionx_out = self.proj(x_out)x_out = self.proj_drop(x_out)return x_out7.2 手把手教你添加FocalModulation
7.2.1 修改一
我们找到如下的目录'yolov5-master/models'在这个目录下创建一整个文件目录(注意是目录,因为我这个专栏会出很多的更新,这里用一种一劳永逸的方法)文件目录起名modules,然后在下面新建一个文件,将我们的代码复制粘贴进去。

7.2.2 修改二
然后新建一个__init__.py文件,然后我们在里面添加一行代码。注意标记一个'.'其作用是标记当前目录。
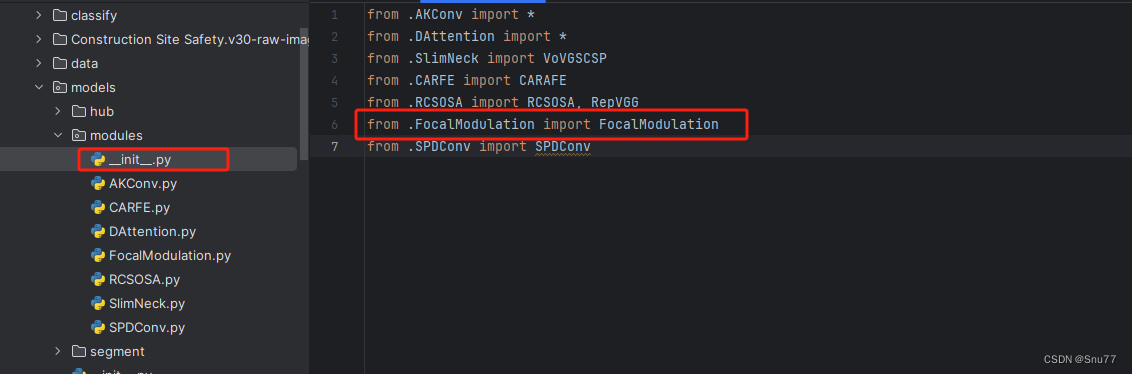
7.2.3 修改三
然后我们找到如下文件''models/yolo.py''在开头的地方导入我们的模块按照如下修改->
(如果你看了我多个改进机制此处只需要添加一个即可,无需重复添加。)
7.2.4 修改四
然后我们找到parse_model方法,按照如下修改->
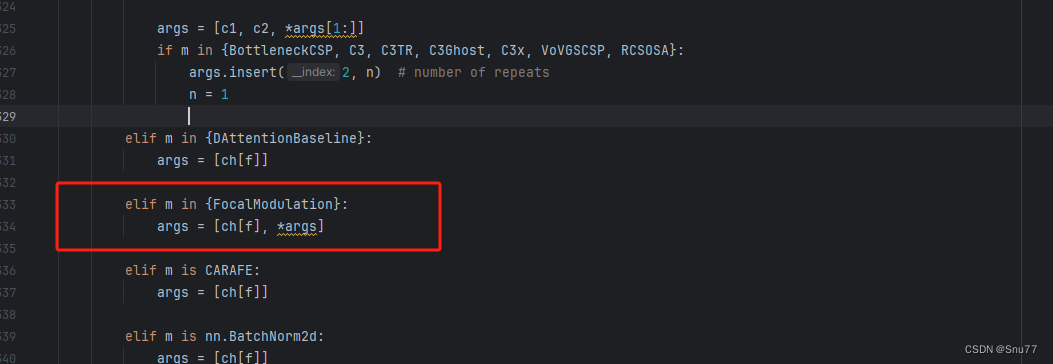
到此就修改完成了,复制下面的ymal文件即可运行。
7.3 FocalModulation的yaml文件
复制如下的yaml文件即可运行。
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, FocalModulation, []], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
八、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv5改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾:YOLOv5改进专栏——持续复现各种顶会内容——内含100+创新
