51-2 万字长文,深度解读端到端自动驾驶的挑战和前沿
去年初,我曾打算撰写一篇关于端到端自动驾驶的文章,发现大模型在自动驾驶领域的尝试案例并不多。遂把议题扩散了一点,即从大模型开始,逐渐向自动驾驶垂直领域靠近,最后落地到端到端。这样需要阐述的内容就变成LLM基础模型、LLM+自动驾驶以及端到端自动驾驶核心内容三部分。
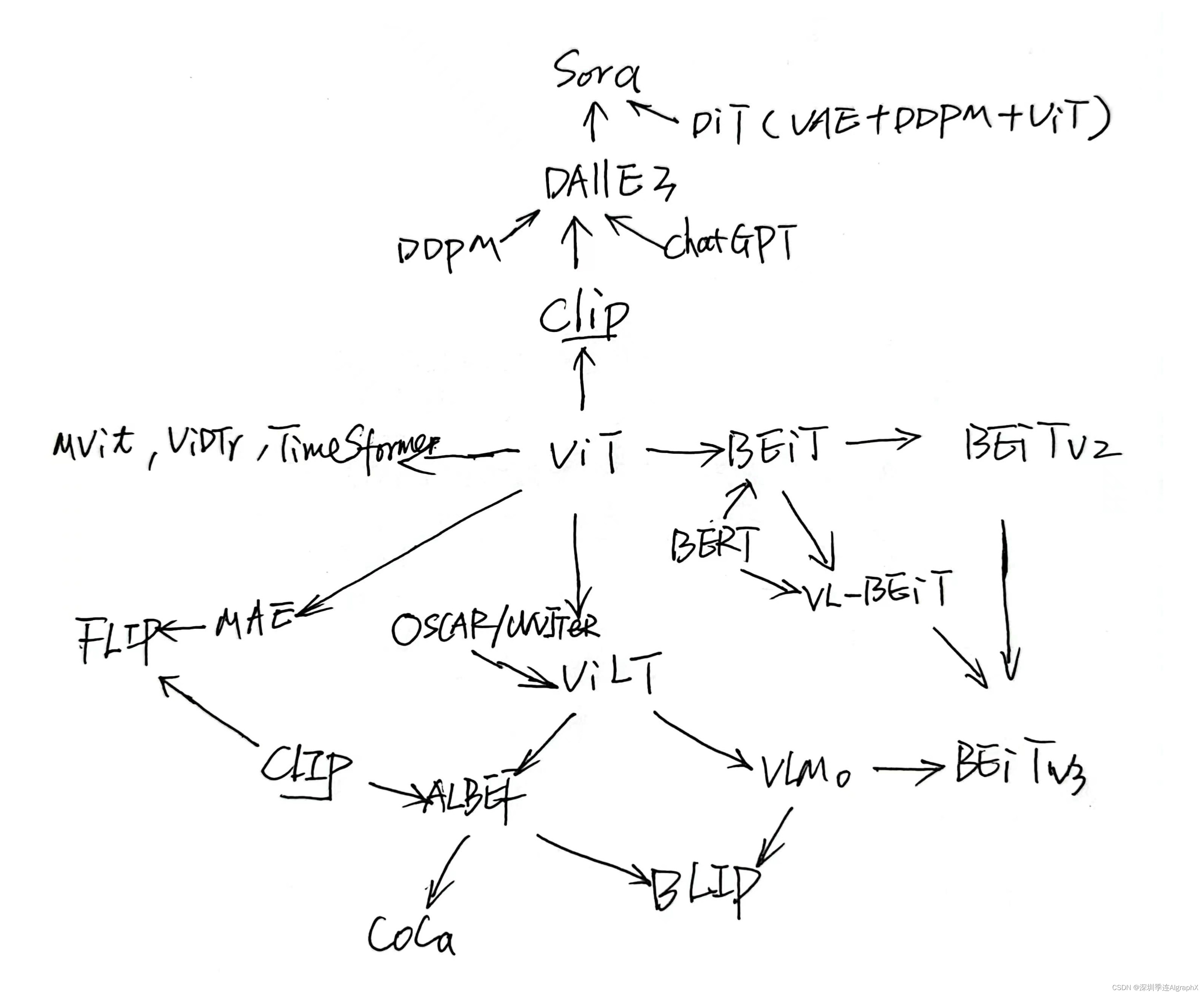
上图是我司总结的大模型经典论文拓扑图,欢迎各位拍砖帮助更新,使得最终能落地到端到端自动驾驶。
LLM基础模型核心论文
- Training language models to follow instructionswith human feedback;
- Learning Transferable Visual Models From NaturalLanguage Supervision;
- NExT-GPT: Any-to-Any Multimodal LLM;
- BLIP:用于统一视觉语言理解和生成的Pre-training;
- BLIP-2: 使用冻结图像编码器和大型语言模型的Pretraining;
- MiniGPT-4: 用高级大型语言模型增强视觉语言理解;
- InstructBLIP: 具有指令调优的通用视觉语言模型.
LLM+自动驾驶核心论文
- DriveGPT4:基于LLM的可解释端到端自动驾驶;
- Driving with LLMs: 融合目标级矢量模态实现可解释自动驾驶;
- GPT-DRIVER:使用GPT学习驾驶;
- DrivingDiffusion:基于扩散模型引导多视图驾驶场景视频生成;
- DriveDreamer: 面向自动驾驶的真实世界驱动世界模型;
- GAIA-1: 自动驾驶的生成世界模型;
- Language Prompt for Autonomous Driving;
- RT-2: 视觉语言动作模型将网络知识转化为机器人控制.
为了方便介绍与总结,本文借助来自香港大学和上海AI lab综述工作的内容展开。另外,本文在这篇综述性质论文的基础上补充了一些大模型当前的相关内容,详情请参见“备注”字样。本文由深圳季连科技有限公司AIgraphX自动驾驶大模型团队编辑。如有错误,欢迎在评论区指正。
论文名称:End-to-end Autonomous Driving: Challenges and Frontiers
论文地址:https://arxiv.org/abs/2306.16927 2023/06
Abstract
自动驾驶社区见证了采用端到端算法框架方法的快速增长,这些方法利用原始传感器输入来生成车辆运动规划,而不是专注于检测和运动预测等单个任务。与模块化pipeline相比,端到端系统受益于感知和规划的联合功能优化。由于大规模数据集的可用性、闭环评估,以及在具有挑战性场景中日益增长的有效自动驾驶算法需求,该领域得以蓬勃发展。在这项综述中,我们对250多篇论文进行了全面分析,涵盖了端到端自动驾驶的动机、路线图、方法、挑战和未来趋势,深入研究了几个关键挑战,包括多模态、可解释性、因果混淆、稳健性和世界模型等。此外,我们还讨论了大模型和视觉预训练的当前进展,以及如何将这些技术纳入端到端的自驾框架。为了促进未来的研究,我们维护了一个活跃的存储库,其中包含相关文献和开源项目的最新链接,网址为https://github.com/OpenDriveLab/End-to-end-Autonomous-Driving.
Introduction
传统自动驾驶系统采用模块化部署策略,其中每个功能,如感知、预测和规划,都是单独开发并集成到车辆中。负责产生转向和加速输出的规划或控制模块,在决定驾驶体验方面起着至关重要的作用。在模块化pipeline中,基于规则的规划方法在处理大量驾驶情形时往往显得力不从心,常常是无效的。因此,利用大规模数据和使用基于学习的规划正逐渐成为一种可行的替代方案,并呈现出越来越大的趋势。
我们将端到端自动驾驶系统定义为完全可微分的程序,将原始传感器数据作为输入,并产生规划和/或低级控制动作作为输出。
图1 (a)-(b)说明了经典方法和端到端方法之间的差异。
传统方法将每个组件的输出,如边界框和车辆轨迹,直接输入到后续单元(虚线箭头)。相反,端到端范式跨组件传播特征表示(灰色实线箭头)。优化函数设置为规划性能,损失通过反向传播(红色箭头)最小化。在这个过程中,几个任务是联合和全局优化的。
在本次综述中,我们对这个新兴主题进行了广泛的回顾。
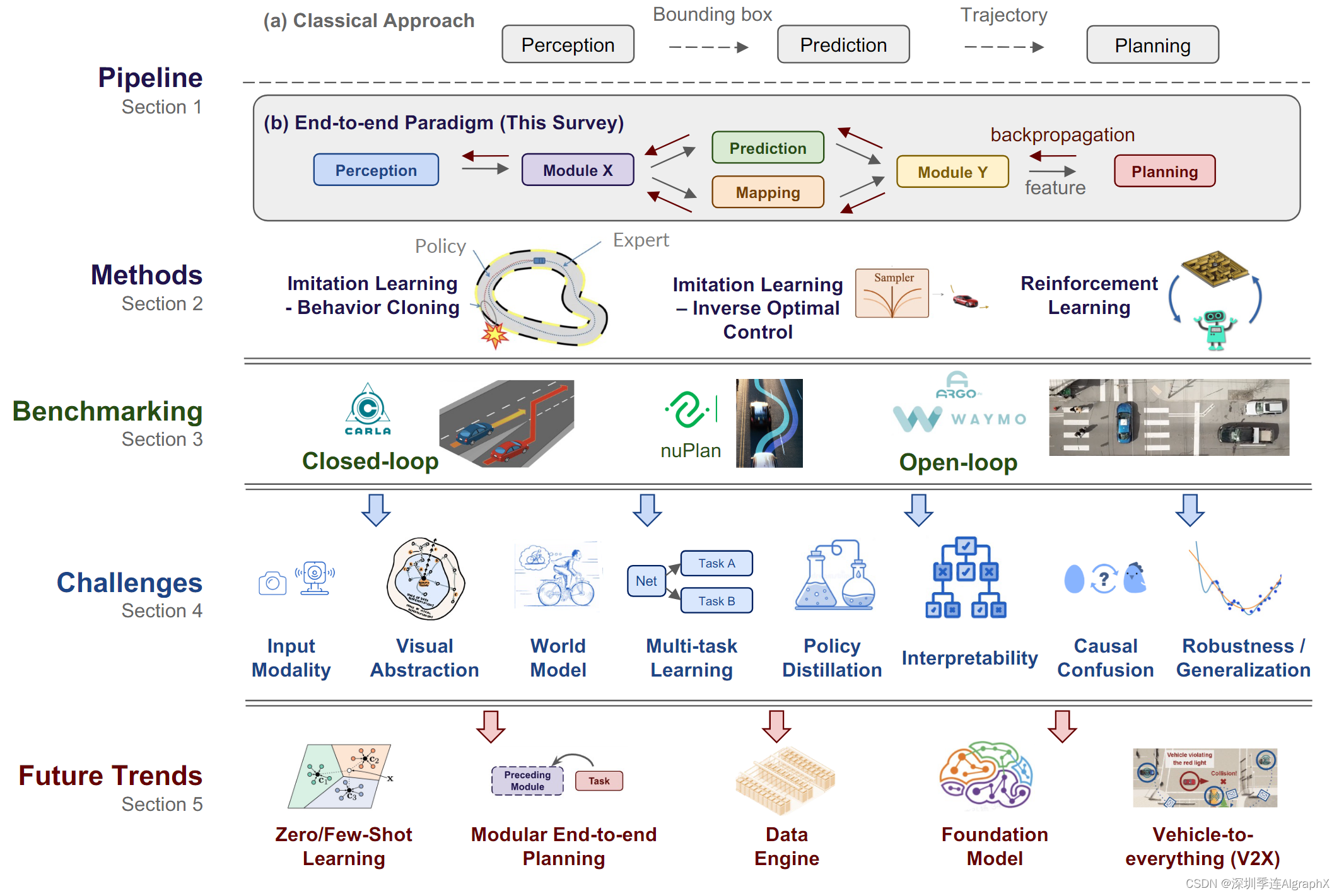
Fig.1: Our Survey at a glance.
(I. 管道和方法。将端到端自动驾驶定义为基于学习的算法框架,具有原始传感器输入和规划/控制输出。调查了250+ 篇论文分为模仿学习 (IL) 和强化学习 (RL)。II. 基准。将流行的基准分别分为闭环和开环评估,内容涵盖了闭环模拟的各个方面以及该问题开环评估的局限性。III.挑战。这是本工作的主要部分:从广泛的主题中列出了关键挑战,并广泛分析了这些问题至关重要的原因。其中还评论了这些挑战的有希望的解决方案。IV。未来的趋势。讨论了端到端自动驾驶如何从大模型的快速发展、视觉预训练等中受益。)
我们首先讨论端到端自动驾驶的动机和路线图。端到端方法可以大致分为模仿IL和强化学习RL,我们简要回顾了这些方法,涵盖了闭合和开环评估的数据集和基准。我们总结了一系列关键挑战,包括可解释性、泛化、世界模型、因果混淆等。最后,我们讨论了社区应该接受的未来趋势,将数据引擎、大模型和vehicle-to-everything等方面的最新发展纳入了其中。
Motivation of an End-to-end System
在经典流行pipeline中,每个模型都服务于一个独立的组件,并对应于一个特定的任务(例如,红绿灯检测)。这样的设计在可解释性、可验证性和易于调试方面是有益的。然而,由于模块之间的优化目标不同,感知中的检测追求平均精度(mAP),而规划的目标是驾驶安全和舒适,因此整个系统可能无法与统一的目标(即最终规划/控制任务)保持一致。随着任务的顺序进行,每个模块的错误可能会加剧,并导致驾驶系统的信息丢失。此外,多任务、多模型部署可能会增加计算负担,并可能导致计算的次优使用。
与传统方法相比,端到端自驾系统具有几个优点。(a) 最明显的优点是将感知、预测和规划结合到一个可以联合训练的单一模型中,实现简洁性。(b) 整个系统,包括中间表示,都针对最终任务进行优化。(c) 共享主干网络可以增加计算效率。(d) 数据驱动的优化有可能提供通过简单扩展训练资源来提高系统的涌现能力。
请注意,端到端范式并不一定表示一个只有计划/控制输出的黑盒。它可以是具有中间表示和输出的模块(图1(b)),如在经典方法中一样。事实上,一些最先进的系统,譬如Planning-oriented Autonomous Driving、MP3: A Unified Model to Map, Perceive, Predict and Plan,两篇工作提出了模块化设计,但同时优化了所有组件,以实现卓越的性能。
Roadmap
图2描绘了端到端自动驾驶关键成就时间路线图,其中每一部分都表明了显著的范式转变或性能提升。

端到端自动驾驶历史可以追溯到1988年的ALVINN,当时的输入是来自相机和激光测距仪的两个“视网膜”,以及一个简单神经网络生成的转向输出。End to End Learning for Self-Driving Cars,设计了一个用于模拟和道路测试的端到端CNN原型系统,在GPU计算的新时代重新确立了这一理念。随着深度神经网络的发展,模仿学习和强化学习已经取得了显著的进展。LBC和最近相关方法提出的策略蒸馏范式,通过模仿行为良好的专家策略,显著提高了闭环性能。由于专家和学习策略之间的差异,为了提高泛化能力,有些工作提出在训练期间对策略数据进行聚合。
端到端自动驾驶在2021年出现了一个重大转折点。在合理的计算预算内,有了各种各样的传感器配置,人们的注意力集中在结合更多的模态和高级架构(例如,Transformer),以捕捉全局上下文和代表性特征,如TransFuser及许多变体。结合对模拟环境的更多见解,这些先进的设计在闭环CARLA基准测试中产生了实质性的性能提升。为了提高自驾系统的可解释性和安全性,NEAT、NMP和BDD-X等方法明确纳入了各种辅助模块,以更好地监督学习过程或利用注意力可视化。
最近的工作优先考虑生成关键安全数据、预训练大模型或策略学习骨干网络,并倡导模块化端到端规划理念。同时,引入了新的、具有挑战性的CARLA v2和nuPlan基准,以促进该领域的研究。
Comparison to Related Surveys
我们想澄清一下,本综述与以前的相关综述之间的差异。一些先前的综述在端到端系统意义上涵盖了与我们相似的内容。然而,它们没有涵盖随着该领域最近的重大转变而出现的新基准和方法,并且对前沿和挑战内容强调得也很少。之前的其余工作集中在该领域的特定主题上,如模仿学习或强化学习。相比之下,我们的综述提供了该领域最新发展和技术的最新信息,涵盖了广泛的主题,并对关键挑战进行了深入的讨论。
Contributions
总而言之,这项综述有三个关键贡献:
(a)我们首次提供了端到端自动驾驶的全面分析,包括高层次的动机、方法、基准等。我们提倡将算法框架作为一个整体来设计,而不是优化单个模块,最终目标是实现安全舒适的驾驶。
(b)我们广泛研究了并行方法面临的关键挑战。在250多篇被综述的论文中,我们总结了主要方面并提供了深入的分析,包括可推广性,语言引导学习,因果混淆等主题。
(c)我们涵盖了如何采用大型基础模型和数据引擎的更广泛影响。我们相信,这条研究路线及其提供的大量高质量数据可以显著推动这一领域的发展。为了促进未来的研究,我们维护了一个活跃的存储库,更新了新的文献和开源项目。
Methods
本节回顾大多数现有端到端自驾系统方法背后的基本原则。2.1节讨论使用模仿学习,并详细介绍两个最流行的子类别,即行为克隆和逆最优控制。第2.2节总结遵循强化学习范式的方法。
Imitation Learning
模仿学习(IL),也被称为从示范中学习,通过模仿专家行为来训练智能体学习最优策略。IL需要一个包含在专家策略πβ下收集的轨迹数据集D = {ξi},其中每个轨迹是一个状态-动作对序列{(s0,a0, s1, a1,···)}。IL的目标是学习一个匹配πβ代理策略π。
IL的一个重要且广泛使用的类别是行为克隆(BC),它将问题简化为监督学习。
逆最优控制(IOC),也称为逆强化学习(IRL),是另一种利用专家演示来学习奖励函数的IL方法。
我们将在以下部分详细说明这两个类别。
备注:相比于强化学习(reinforcement learning,RL),给定奖赏函数,寻找最优策略的过程。逆强化学习(Inverse Reinforcement learning, IRL),给定最优策略或最优行为轨迹,寻找可解释这些策略或行为的奖赏函数。与之相关的概念为Inverse Optimal Control(IOC)。
Behavior Cloning
在行为克隆中,智能体策略与专家策略相匹配的目标,通过最小化规划损失来实现。这是对收集数据集的监督学习问题:(πθ (s), a),这里πθ (s), a)表示衡量代理行为和专家行为之间距离损失函数。
BC在驾驶任务中的早期应用,是利用端到端神经网络从摄像头输入生成控制信号。进一步的改进工作,如多传感器输入、辅助任务和改进的专家设计等已经被提出。
基于BC的端到端驾驶模型能够处理具有挑战性的城市驾驶场景。
行为克隆因其简单和高效而具有优势,因为它不需要手工制作奖励设计,这对强化学习至关重要。然而,还是存在一些与行为克隆相关的常见问题。
在训练过程中,行为克隆将每个状态视为独立且相同的分布,从而导致一个重要的问题,即协变量移位。
对于一般IL,已经提出了几种策略上的方法来解决这个问题。在端到端自动驾驶的背景下,有些采用了DAgger。
行为克隆的另一个常见问题是因果混淆,即模仿者利用并依赖于某些输入组件和输出信号之间的错误相关性。
这个问题已经在端到端自动驾驶的背景下进行了讨论。对于基于模仿学习的端到端自动驾驶来说,这两个具有挑战性的问题将分别在第4.8节和第4.7节中进一步讨论。
Inverse Optimal Control
传统的IOC算法从专家演示中学习马尔可夫决策过程(MDP)中的未知奖励函数R(s, a),其中专家的奖励函数可以表示为特征的线性组合。然而,在连续高维自动驾驶场景中,奖励的定义是隐含的,难以优化。
生成对抗性模仿学习(GAIL)是IOC中的一种专门方法,它将奖励函数设计为对抗性目标,以区分专家和学习的策略,类似于生成对抗性网络概念。
最近,一些工作提出了利用辅助感知任务来优化cost volume or cost function。
由于损失是奖励的替代表示,我们将这些方法归类为属于IOC领域。我们将损失学习框架定义如下:端到端方法与其他辅助任务一起学习合理的损失函数 c(·),并使用简单的不可学习算法轨迹采样器以最小的代价选择轨迹τ *,如图3所示。

因此,损失学习范式有两个方面:如何设计损失以及如何对轨迹进行采样,以端到端方式进行优化。
关于损失设计,NMP 利用鸟瞰图 (BEV) 中的学习cost volume。它还并行执行对象检测,但不直接将损失与检测输出联系起来。有些工作预测所有代理未来运动,并使用联合能量作为交互损失来生成最终的规划结果。Dfferentiable Raycasting for Self-supervised Occupancy Forecasting,提出估计一组概率语义占用或自由空间层作为中间表示,这提供了明确的线索,即车辆不应该机动以确保安全。另一方面,轨迹通常从固定的专家轨迹集中采样,或者通过运动学模型的参数采样进行处理。然后,像传统的IOC方法一样,采用最大边际损失,以奖励专家演示的损失最低,而其他损失较高。
损失学习方法仍然存在一些挑战。特别是,为了产生更真实的损失,通常会合并高清地图、辅助感知任务和多个传感器,这增加了多模态、多任务框架学习和构建数据集的难度。
为了解决这个问题,MP3 、ST-P3 和 IVMP 丢弃了先前工作中使用的高清地图输入,并利用预测的 BEV 图来计算交通规则的损失,例如保持靠近中心线并避免与道路边界的碰撞。
Reinforcement Learning
强化学习(RL)是试错学习领域。深度Q网络(DQN)在Atari 2600基准上成功实现了人类水平的控制,这普及推广了深度强化学习。
DQN 训练一个称为评论家(或 Q 网络)的神经网络,它将当前状态和动作作为输入,并预测该动作的未来奖励(之后遵循相同的策略)。策略是通过选择Q值最高动作的隐式定义。RL 需要一个环境,允许执行潜在的不安全动作,因为它需要探索(例如,有时在数据收集期间执行随机动作)。此外,RL 比监督学习需要更多的数据来训练。出于这个原因,现代 RL 方法通常在多个环境中并行化数据收集。在真实世界的汽车中,满足这些要求是一个巨大的挑战。因此,几乎所有在自动驾驶中使用 RL 的论文都只研究了仿真技术。大多数工作都使用 DQN 的不同扩展。然而,社区还没有收敛到特定的 RL 算法。
强化学习已经证明,在一条空荡荡的街道上,在一辆真正的汽车上成功地学习了车道跟随。尽管这是一个令人鼓舞的早期结果,但必须注意的是,三十年前模仿学习已经完成了类似的任务。
到目前为止,没有任何报告显示端到端RL训练结果与模仿学习具有竞争力。
在与CARLA模拟器相结合的直接比较中,强化学习远远落后于模块化pipeline和端到端模仿学习。这种失败的原因很可能是,通过强化学习获得的梯度不足以训练深度感知架构(ResNet 网络)。Atari 2600等基准测试中使用的模型(RL 成功)相对较浅,仅包含几层。
与监督学习相结合,强化学习已成功应用于自动驾驶。隐式可视性和GRI都使用带有语义分割和分类等辅助任务的监督学习对其架构的CNN编码器部分进行预训练。在第二阶段,预训练编码器被冻结,并使用现代版本的 Q 学习对冻结图像编码器的隐式可供性进行训练。这两项工作在撰写本文时都在 CARLA 排行榜上报告了最先进的性能。强化学习也已成功用于微调CARLA上的完整架构,这些架构使用模仿学习进行预训练。
RL 还有效地应用于规划和控制任务,其网络可以访问特权模拟器信息。本着同样的精神,RL 已应用于自动驾驶以进行数据集管理。Roach训练了一种基于特权BEV语义分割的RL方法,并使用该策略自动收集数据集,用于训练下游模仿学习代理。WOR采用 Q 函数和表格动态规划来为静态数据集生成额外或改进的标签。
该领域未来的挑战是将RL研究结果从模拟应用到现实世界。
在 RL 中,目标表示为奖励函数,大多数算法要求这些奖励函数是密集的,并在每个环境步骤中提供反馈。目前的工作通常使用简单的目标,例如进度和避免碰撞,并线性组合它们。这些简单的奖励函数因鼓励风险行为而受到批评。
设计或学习更好的奖励函数仍然是一个悬而未决的问题。另一个方向是开发 RL 能够处理稀疏奖励的算法,可以直接优化相关指标。
RL 可以有效地与世界模型相结合,尽管这带来了第4.3节中讨论的具体挑战。
目前自动驾驶的RL解决方案严重依赖于场景的低维表示,表示学习将在第4.2节中进一步讨论。
BenchMarking
自动驾驶系统需要对其可靠性进行全面评估以确保安全。为了实现这一目标,研究人员必须使用适当的数据集、模拟器和指标对这些系统进行基准测试。本节描述了端到端自动驾驶系统大规模基准测试的两种方法:(1)模拟中的在线或闭环评估,(2)对人类驾驶数据集的离线或开环评估。我们特别关注更具原则性的在线设置,并为完整性,提供离线评估的简要总结。
Online Evaluation (Closed-loop)
在现实世界中,进行自动驾驶系统测试既昂贵又有风险。为了应对这一挑战,模拟是一种可行的替代方案。
模拟器有助于快速原型设计和测试,实现思想的快速迭代,并提供对各种场景的低损失访问。
此外,模拟器还提供了可靠、准确地测量性能的工具。然而,它们的主要缺点是,在模拟环境中获得的结果不一定适用于现实世界(第4.8.3节)。闭环评估包括构建一个与真实世界驾驶环境非常相似的模拟环境。驾驶系统的评估需要将系统部署在模拟环境中,并随着时间的推移测量其性能。系统必须在模拟交通中安全导航,同时向指定的目标位置前进。
开发此类评估模拟器主要涉及三个子任务:参数初始化、交通模拟和传感器仿真。
我们在下面简要描述了这些子任务,然后总结了当前可用于闭环基准测试的开源模拟器。
Parameter Initialization
模拟器提供了对环境高维控制的便利,包括天气和照明条件、地图和3D环境条件,以及低级别属性,如交通场景中目标的排列和姿态情况。虽然功能强大,但这些参数的数量很大,这导致了一个具有挑战性的设计问题。
目前模拟器通过两种方式来解决这个问题:
Procedural Generation过程生成:传统上,初始参数由3D艺术家和工程师手动调整,我们称之为过程生成。每个属性通常都是从具有手动设置参数的概率分布中采样的,这是一个耗时的过程,需要大量的专业知识。这限制了可扩展性。尽管如此,这仍然是最常用的初始化方法之一。过程生成算法将规则、启发式和随机化相结合,以创建不同的道路网络、交通模式、照明条件和对象放置。
Data-Driven数据驱动:数据驱动的仿真初始化方法旨在学习所需的参数。
可以说,最简单的数据驱动初始化方法是直接从真实世界的驾驶数据日志中进行采样。在该方法中,直接从预先记录的数据集中提取诸如道路地图或交通模式之类的参数。日志采样的优势在于它能够捕捉真实世界数据中存在的自然变化,从而产生比过程生成更真实的模拟场景。然而,它可能不包括罕见或极端的情况,这对测试自动驾驶系统的稳健性至关重要。可以优化初始参数以增加这种场景的表示。
另一种先进的数据驱动初始化方法是生成建模,其中利用机器学习算法来学习真实世界数据的底层结构和分布。然后,这些算法可以生成与现实世界相似但未包含在原始数据中的新场景。
Traffic Simulation
交通模拟涉及在具有真实运动的环境中生成和定位虚拟实体。这些实体通常包括车辆(如卡车、汽车、摩托车、自行车等)和行人。交通模拟器必须考虑速度、加速度、制动、障碍物和其他实体行为的影响。此外,红绿灯状态必须定期更新,以模拟真实的城市驾驶。有两种流行的交通模拟方法,我们将在下面进行描述。
Rule-Based基于规则:基于规则的交通模拟器使用预定义的规则来生成交通实体的运动。这种方法实现起来很简单,但产生的运动可能不太现实。这一概念最突出的实现是Intelligent Driver Model(IDM)。IDM是一个跟车模型,它根据每辆车的当前速度、前车速度和所需安全距离来计算每辆汽车的加速度。尽管IDM被广泛使用,但它可能不足以捕捉城市环境中复杂的相互作用。
Data-Driven数据驱动:真实的人类交通行为是高度互动和复杂的,包括变道、并线、突然停车等。为了对这种行为进行建模,数据驱动的交通模拟利用了从真实世界驾驶中收集的数据。这些模型可以捕捉更细微、更真实的行为,但需要大量的标记数据进行训练。目前很多工作已经为这项任务提出了各种各样的基于学习的技术。
Sensor Simulation
传感器仿真对于评估端到端的自动驾驶系统至关重要。这涉及生成模拟的原始传感器数据,例如驾驶系统将从模拟器中的不同视点从环境接收的相机图像或激光雷达扫描。此过程需要考虑噪声和遮挡以便真实地评估自治系统的性能。在关于传感器模拟的文献中有两个分支的思想,如下所述。
Graphics-Based基于图形:最近的计算机图形模拟器使用环境的3D模型,以及车辆和交通实体模型,通过近似传感器中的物理渲染过程来生成传感器数据。例如,在模拟相机图像时,这可以考虑真实世界环境中存在的遮挡、阴影和反射。然而,基于图形的模拟的真实性往往较差,或者以极其繁重的计算为代价,这使得并行化变得不平凡。它与3D模型的质量以及传感器建模中使用的近似值密切相关。Synthetic Datasets for Autonomous Driving: A Survey,提供了对基于图形的驾驶数据渲染的全面综述。
Data-Driven数据驱动:数据驱动的传感器模拟利用并调整真实世界的传感器数据,以创建一个新的模拟,其中自车和背景交通的移动方式可能与原始数据中的不同。
一种流行的方法是使用神经辐射场(NeRF),它可以通过学习场景几何和外观的隐式表示来生成场景的新视图。与基于图形的方法相比,这些方法可以产生更真实的传感器数据,但它们有局限性,如渲染时间长或需要对每个重建的场景进行独立训练。
数据驱动传感器模拟的另一种方法是域适应domain adaptation,旨在最大限度地减少真实和基于图形的模拟传感器数据之间的分布偏移。机器学习技术,如GANs或风格转移,可以用来提高真实感。有关这些想法的更多详细信息,请参见第4.8.3节。
Benchmarks
我们在表1中简要概述了最新的驾驶基准CARLA和nuPlan。2019年,CARLA发布的原始基准以接近完美的分数解决。

随后的NoCrash基准涉及在特定天气条件下对一个CARLA城镇(Town01)进行训练,并测试对另一个城镇和一组天气的泛化能力。Town05基准涉及对CARLA中所有可用城镇的培训,而不是单个城镇,同时保留Town05进行测试。同样,除Town02和Town05外,所有城镇的LAV基准列车都保留用于测试,以增加测试路线的多样性。Roach扩展到一个有3个测试城镇的环境,尽管都是在训练期间看到的,并且没有Town05和LAV中使用的安全关键场景。最后,Longest6基准使用了6个测试城镇。
CARLA 代理的两个在线提交服务器,称为排行榜(v1 和 v2),可在Leaderboard - CARLA Autonomous Driving Leaderboard上获得。排行榜通过对评估路线保密来确保公平的比较。排行榜v2由于路线长度超长(平均超过8公里,而v1为1-2公里)和各种新的交通场景,极具挑战性。目前还没有对任何方法进行基准测试。由于传感器数据和相应的传感器模拟方面(第3.1.3节)尚未公开,目前端到端系统无法访问nuPlan模拟器。然而,有两个现有的基准,代理直接在其上输入地图和对象属性,这些属性可通过nuPlan的数据驱动参数初始化获得(第3.1.1节)。Parting with Misconceptions about Learning-based Vehicle Motion Planning使用了可公开访问nuPlan。排行榜是一个在私人测试集上进行测试的提交服务器,用于2023年的nuPlan挑战。不幸的是,目前已不再公开供提交。
备注:nuPlan开环和闭环测试指标应该还是有很多问题。2023年,参赛者采用了一个非常简单的MLP规划器,输入为自车运动历史信息和道路参考线,输出为自车预测轨迹,取得了nuPlan 开环评分的第一名。这里甚至都没有考虑周边其它车辆的运动信息。
Offline Evaluation (Open-loop)
开环评估包括根据预先记录的专家驾驶行为来评估系统的性能。该方法需要评估数据集,包括(1)传感器读数、(2)目标位置和(3)相应的未来驾驶轨迹,通常从人类驾驶员那里获得。给定数据集中的传感器输入和目标位置作为输入,通过将系统预测的未来轨迹与人类在驾驶日志中的轨迹进行比较来测量性能。系统的评估基于其轨迹预测与人类地面实况的匹配程度,以及辅助指标,如与其他代理的碰撞概率。开环评估的优点是易于实现,并且不需要模拟器,因此可以获得真实的交通和传感器数据。
开环评估关键的缺点是,它不能度量系统在部署过程中遇到的实际测试分布中的性能。
在测试过程中,驾驶系统可能会偏离专家驾驶通道,验证系统从这种漂移中恢复的能力至关重要。此外,在多模式场景中,预测轨迹和观测轨迹之间的距离不是一个合适的性能指标。例如,在并入转弯车道的情况下,立即或稍后并入的两种选择都是有效的,但开环评估会惩罚数据中未观察到的选项。类似地,预测的轨迹可能取决于只有在未来才能获得的观测结果,例如,在仍然是绿色但很快就会变红的灯处停止,这种情况无法用单一的地面实况轨迹进行评估。
这种方法需要一个全面的轨迹数据集。为此目的,最流行的数据集包括nuScenes、Argoverse、Waymo和nuPlan。所有这些数据集都包括来自现实世界驾驶环境的大量带标注的轨迹,这些轨迹具有不同程度的难度。然而,由于上述缺点,开环结果并不能提供闭环中驾驶行为改善的确凿证据。总的来说,如果可行且适用,建议在未来的研究中采用现实的闭环基准。
Challenges
Input Modality
Multi-sensor Fusion
在这里省略了相关回顾工作。
最近,研究人员利用Transformers对特征对之间的相互作用进行建模。transfuser使用两个独立的卷积编码器处理图像和LiDAR输入,将每个特征与Transformer编码器互连,从而实现四阶段特征融合。自注意力层用于传感器token、关注感兴趣区域并从其他模态更新信息。MMFN在Transfurser之上进一步集成了OpenDrive地图和雷达输入。采用one-stage transformer编码器架构,在最后一个编码器块之后融合各种特征。
注意力机制在聚合不同传感器输入的上下文和实现更安全的端到端驾驶性能方面表现出极大的有效性。
不同模式通常会增加视野和感知精度,但融合它们来提取端到端自动驾驶的关键信息需要进一步的探索。必须在统一的空间中对这些模式进行建模,如BEV,识别与策略相关的上下文,并丢弃无关的感官信息。此外,充分利用强大的Transformer架构仍然是一个挑战。自注意层将所有token连接起来,自由地对其感兴趣的领域进行建模,但它会产生大量的计算成本,并且不能保证提取有用的信息。
在感知领域,更先进的基于transformer的多传感器融合机制,如DeepFusion,X-Align,有望应用于端到端驾驶任务。
Language as Input
人类驾驶汽车既使用视觉感知,也使用内在知识,如交通规则和期望的路线,它们共同形成因果行为。在一些与自动驾驶相关的领域,如机器人和室内导航(也称为嵌入式AI),将自然语言作为细粒度指令来控制视觉运动智能体已经取得了显著进展。然而,在以下情况下,室外自动驾驶任务与室内机器人应用具有不同的特点:
(1)室外环境未知,车辆无法来回探索。
(2)有特色的锚点地标很少,给语言指令的落地带来了很大的挑战。
(3)驾驶场景更加复杂,具有连续的动作空间和高速动态的agent。
在机动过程中,安全是头等大事。为了将语言知识整合到驾驶行为中,Talk2Car数据集提供了在室外环境中定位参考对象的基准。Talk2Nav、TouchDown和Map2Seq数据集介绍了使用谷歌街景的视觉语言导航任务。它们将世界建模为一个离散的连接图,并要求以节点选择格式导航到目标。HAD首先采用人对车的建议,并使用基于LSTM的控制器添加视觉任务。Sriram等人将自然语言指令编码为左转、右转、不左转等高级行为,并在CARLA模拟器中验证了他们的语言引导导航方法。有些工作通过关注文本操作命令来解决底层实时控制问题。
最近,CLIP- MC和LM-Nav利用得益于大规模视觉语言预训练的CLIP,从指令中提取语言知识,从图像中提取视觉特征。他们展示了预训练模型的优点,并为解决多模态模型的复杂导航任务提供了一个有吸引力的原型。
尽管已经成功尝试使用CLIP进行地标性特征提取,但大型语言模型如GPT-3或指导性语言模型如ChatGPT在自动驾驶领域的应用尚不清楚。现代LLM提供了更多的机会来处理复杂的语言指令。然而,考虑到它们较长的推理时间和不稳定性,确定道路应用的交互模式也是至关重要的。此外,当前的语言引导导航工作验证了它们在模拟或特定机器人实施例中的有效性,然缺少包括有意义的语言提示的大规模基准。
Visual Abstraction
端到端自动驾驶系统实现机动任务,大致分为两个阶段:将状态空间编码为潜在特征表示,然后用中间特征解码驾驶策略。在城市驾驶的情况下,与视频游戏等常见的策略学习基准相比,输入状态(即周围环境和自我状态)更加多样化和高维化。因此,首先使用代理预训练任务对网络的视觉编码器进行预训练是有帮助的。这使得网络能够有效地提取有用的驾驶信息,从而便于后续的策略解码阶段,同时满足所有端到端算法的内存和模型大小约束。此外,这可以提高RL方法的采样效率。
视觉抽象或表征学习的过程通常包含一定的归纳偏差或先验信息。
为了获得比原始图像更紧凑的表示,一些方法直接利用预训练分割网络中的语义分割掩码作为后续策略训练的输入表示。SESR在此基础上更进一步,通过VAE将分割掩码编码为class-disentangled表示。Policy-Based Reinforcement Learning for Training Autonomous Driving Agents in Urban Areas With Affordance Learning,预测的可用性指标,如交通灯状态、速度、与车道中心的偏移量、危险指标和与领先车辆的距离,被用作策略学习的表示。在观察到分割或启示作为表征可能会造成人类定义的瓶颈并导致有用信息的丢失之后,一些人选择了预训练任务中的中间潜在特征作为有效表征。PIE-G已经证明ImageNet预训练模型的早期层可以作为有效的表示。Multi-Task Long-Range Urban Driving Based on Hierarchical Planning and Reinforcement Learning 等采用语义分割和/或可视性预测等任务预训练的潜在表征作为RL训练的输入,取得了优异的性能。
Latent Attention Augmentation for Robust Autonomous Driving Policies,通过从分割扩散边界获得的注意图来增强VAE中的潜在特征,以突出显示重要区域的深度图。PPGeo提出通过运动预测和深度估计,以一种自监督的方式对未标记的驾驶视频进行有效表征。TARP利用一系列先前任务的数据来执行不同任务相关的预测任务,以获得有用的表征。Jianda chen等人,潜在表征是通过近似π-双仿真度量来学习的,π-双仿真度量由动态模型的奖励和输出的差异组成。除了这些有监督预测的预训练任务外,有些工作还采用了基于增强视图的无监督对比学习。ACO进一步在对比学习结构中加入了转向角辨别。
由于目前的方法主要依赖于人类定义的预训练任务,因此在学习到的表示中不可避免地存在信息瓶颈,并且可能包含与驾驶决策无关的冗余信息。因此,如何在表征学习过程中更好地提取驾驶策略的关键信息仍然是一个悬而未决的问题。
World Model and Model-based RL
除了更好地抽象感知表征的能力之外,端到端模型对未来做出合理预测以采取安全操作也是必不可少的。在本节中,我们主要讨论当前基于模型策略学习工作的挑战,其中世界模型为策略模型提供明确的未来预测。深度强化学习通常会面临高样本复杂性的挑战,由于样本空间很大,这在自动驾驶等任务中尤为明显。
基于模型的强化学习(MBRL)通过允许智能体与学习的世界模型而不是实际环境进行交互,为提高样本效率提供了一个有前途的方向。
MBRL方法显式地对世界模型/环境模型进行建模,该模型由过渡动力学和奖励函数组成,并且agent可以低成本与之交互。这在自动驾驶中特别有用,因为像CARLA这样的3D模拟器相对较慢。
对高度复杂和动态的驾驶环境进行建模是一项具有挑战性的任务。为了简化问题,Chen等人假设世界在轨道上,将过渡动力学分解为非反应性世界模型和简单运动学自行车模型。他们通过利用这个分解的世界模型和奖励函数来丰富静态数据集的标签,通过动态规划优化更好的标签。Interpretable End-to-end Urban Autonomous Driving with Latent Deep Reinforcement Learning,为了降低强化学习的样本复杂度,使用了概率序列潜在模型作为世界模型。为了解决学习世界模型的潜在不准确性,Jingda wu等人使用多个世界模型的集合来提供不确定性评估。基于不确定性,可以截断世界模型和策略代理之间的假想rollout,并进行相应的调整。受MBRL模型dream的启发,ISO-Dream考虑了环境中的不确定性因素,并将视觉动态解耦合为可控和不可控状态。然后,在disentangled状态上训练策略,明确考虑不可控因素(如其他代理的运动)。
值得注意的是,在原始图像空间中学习世界模型并不适合自动驾驶。重要的小细节,如交通灯,很容易在预测图像中被遗漏。为了解决这个问题,MILE在BEV语义分割空间中引入了世界模型。它将世界建模与模仿学习相结合,采用做梦者式世界模型学习作为辅助任务。SEM2也扩展了做梦者结构,但使用BEV分割图,并使用RL进行训练。除了直接使用MBRL的学习世界模型外,DeRL还将无模型的actor-critic框架与世界模型结合在一起。具体来说,学习世界模型提供了对当前行为的自我评估,它与评论家的状态值相结合,以更好地访问actor的表现。
端到端自动驾驶世界模型学习或MBRL是一个新兴有前途的方向。
因为它大大降低了RL的样本复杂度,并且理解世界有助于驾驶。然而,由于驾驶环境是高度复杂和动态的,需要进一步研究确定需要建模的内容以及如何有效地对世界进行建模。
备注:世界模型首先被LeCun提出,他理想中的AI远超现在的GPT性能,甚至说GPT活不过五年。

回到当下,大模型最新论文NExT-GPT: Any-to-Any Multimodal LLM框架图如上,2023年11月发布。
Multi-task Learning with Policy Prediction
多任务学习(Multi-task learning, MTL)是基于一个共享的表示,通过不同的分支/头来联合执行多个相关的任务。MTL通过对多个任务使用单个模型,显著降低了计算成本。此外,在共享模型中共享相关领域知识,可以更好地利用任务关系来提高模型的泛化能力和鲁棒性。因此,MTL非常适合端到端自动驾驶,在这种情况下,最终的策略预测需要对当前环境有全面的了解。与需要密集预测的常见视觉任务不同,端到端自动驾驶预测的是稀疏信号。这里的稀疏监督给输入编码器提取有用信息决策带来了挑战。
对于图像输入,端到端自动驾驶模型通常采用语义分割和深度估计等辅助任务。语义分割确保模型获得对场景的高级理解,并识别不同类别的对象。深度估计使模型能够理解环境的3D几何形状,并更好地估计关键物体的距离。通过执行这些任务,图像编码器可以更好地提取有用和有意义的特征表示,以供后续规划。除了映射图像的辅助任务外,3D物体检测对LiDAR编码器也很有用。随着BEV成为自动驾驶的一种自然而流行的表征,高清地图映射和BEV分割等任务被包含在聚集BEV空间特征的模型中。此外,除了这些作为多任务的视觉任务外,Safety-Enhanced Autonomous Driving Using Interpretable Sensor Fusion Transformer等论文,还可以预测视觉可视性,包括交通灯状态、到路口的距离以及到对面车道的距离等。
端到端自动驾驶的多任务学习已经证明了其在提高性能和提供自动驾驶模型可解释性方面的有效性。
然而,辅助任务的最佳组合及其损失的适当加权以达到最佳性能仍有待探索。此外,构建具有多种类型对齐且高质量注释的大规模数据集是一个重大挑战。
Policy Distillation
由于模仿学习或其主要子类行为克隆是简单的监督学习,模仿专家的行为,相应的方法通常遵循“教师-学生”范式。老师们,比如由CARLA提供的手工制作的专家自动驾驶仪,可以访问周围代理和地图元素的ground-truth状态,而学生则直接由收集的专家轨迹或控制信号进行监督,仅使用原始传感器输入。这对学生模型提出了巨大的挑战,因为他们不仅要提取感知特征,还要从头开始学习驾驶策略。
为了解决上述困难,一些研究建议将学习过程分为两个阶段,即训练一个教师网络,然后将策略蒸馏为最终的学生网络。特别是,Chen等人首先使用特权代理来学习如何在直接访问环境状态的情况下采取行动。然后,他们让感觉运动代理(学生网络)密切模仿特权代理,在输出阶段进行蒸馏。特权代理使用更紧凑的BEV表示作为输入,提供比原专家更强的泛化能力和监督能力。该过程如图5所示。

LAV进一步授权特权代理预测附近所有车辆的轨迹,并将这种能力提取到使用视觉特征的学生网络中。
除了直接监督规划结果外,一些作品还通过在特征级别提取知识来训练他们的预测模型。例如FM-Net使用现成的网络,包括分割和光流模型,作为辅助教师指导特征训练。SAM在教师网络和学生网络之间增加了L2特征损失,其中教师网络从真值语义分割图和停止意图值中预测控制信号。WoR学习了一个基于模型的动作值函数,然后用它来监督视觉运动策略。CaT最近在基于 IL 的特权专家训练中引入了BEV安全提示,并在BEV空间中提炼以对齐特征。Roach提出用强化学习训练更强的特权专家,消除模仿学习的上界。它结合了多个蒸馏目标,即动作分布预测、值估计和潜在特征。通过利用强大的强化学习专家,TCP在CARLA排行榜上实现了一个新的最先进的技术,使用单个摄像机作为视觉输入。尽管在设计更健壮的专家和将知识从教师传递给不同层次的学生方面已经投入了大量的努力,但师生范式仍然存在效率低下的问题。正如之前所有的研究所示,视觉运动网络与其特权代理相比表现出很大的性能差距。例如,特权代理可以访问交通灯的真实状态,交通灯是图像中的小物体,对提取相应的特征提出了挑战。这可能会导致学生产生因果混淆,如第4.7节所述。因此,如何从机器学习中的一般蒸馏方法中汲取更多的灵感,将差距最小化,是值得探索的。
Interpretability
可解释性在自动驾驶中起着至关重要的作用。它使工程师和研究人员能够更好地测试、调试和改进系统,从社会角度提供性能保证,增加用户的信任,并促进公众接受。然而,在通常称为黑盒的端到端自动驾驶模型中实现可解释性具有挑战性。给定一个经过训练的自动驾驶模型,一些事后 X-AI(可解释的 AI)技术可以应用于学习模型,以获得显著图。显著图突出显示视觉输入中的特定区域,模型主要依赖这些区域进行规划。然而,这种方法提供的信息有限,而且有效性难以评估。相反,我们专注于直接增强模型设计中可解释性的自动驾驶框架。我们将在下图中介绍每个类别的可解释性。

Attention Visualization
注意力机制通常提供一定程度的可解释性,应用学习到的注意力权重来聚合中间特征图的重要特征。学习注意力权重以自适应地组合来自不同对象区域的 ROI 池化特征或固定网格。NEAT 迭代地聚合特征以预测注意力权重并细化聚合特征。最近,Transformer 注意力机制在许多自动驾驶模型中被广泛使用。采用 Transformer 注意块来更好地聚合来自传感器输入的信息,注意力图在驾驶决策的输入中显示出重要区域。在PlanT中,注意层处理来自不同车辆的特征,为相应的动作提供可解释的见解。与事后显著性方法类似,尽管学习到的注意力图可以提供一些关于模型焦点的直接线索,但它们的可靠性和实用性仍然有限。
Interpretable Tasks
在深度学习模型中,输入最初被编码为中间表示,用于后续预测。因此,许多基于IL的工作通过将潜在特征表示解码为其他有意义的信息,如语义分割、深度估计、目标检测、可视性预测、运动预测和注视图估计。尽管这些方法提供了可解释的信息,但它们中的大多数都仅将这些预测视为辅助任务,对最终的驾驶决策没有明显的影响。一些确实将这些输出用于最终的驾驶行为,但它们仅用于执行额外的安全检查。
Cost Learning
如第 2.1.2 节所述,基于损失学习的方法与传统的模块化自动驾驶系统有一些相似之处,因此表现出一定程度的可解释性。NMP和DSDNet结合检测和运动预测结果构建了损失量。P3将预测的语义占用图与舒适和交通规则约束相结合,构建代价函数。采用概率占用和时间运动场、紧急占用和自由空间等各种表示对采样轨迹进行评分。ST-P3明确包括基于感知和预测输出的安全、舒适、交通规则和路线等因素来构建损失量。
Linguistic Explainability
由于可解释性的一个方面是帮助人类理解系统,因此自然语言是实现这一目的的合适选择。Kim等生成BDD-X数据集,将驾驶视频与描述/解释配对。他们还提出了一个带有车辆控制器和解释生成器的自动驾驶模型,并强制两个模块的空间注意力权重对齐。BEF提出了一个解释模块,该模块融合了预测轨迹和中间感知特征,以预测决策的合理性。Explainable Object-induced Action Decision for Autonomous Vehicles,引入了一个名为BBDOIA的数据集,其中包括对高密度交通场景的驾驶决策和解释的注释。最近,ADAPT 提出了一种基于 Transformer 的网络,基于来自 BBD-X 数据集的驾驶视频联合动作估计、叙述和推理。鉴于多模态和大模型的最新进展,我们相信,进一步将语言与自动驾驶模型相结合,有望实现卓越的可解释性和性能。
Uncertainty Modeling
不确定性是解释模型输出可靠性的定量方法。由于规划结果并不总是准确或最佳,对于设计师和用户来说,识别不确定性以进行改进或必要的干预是至关重要的。对于深度学习,有两种不确定性:任意不确定性和认知不确定性。任意不确定性是任务固有的,而认知不确定性是由于有限的数据或建模能力。Evaluating Uncertainty Quantification in End-to-End Autonomous Driving Control,对端到端自动驾驶系统的不确定性进行了定量评估,利用模型中的某些随机正则化作为样本,执行多个前向传递来衡量不确定性。然而,在实时场景中,多次前向传递的要求是不可行的。RIP 提出使用一组专家似然模型捕获认知不确定性并聚合结果以执行安全规划。关于建模任意不确定性的方法,Probabilistic End-to-End Vehicle Navigation in Complex Dynamic Environments with Multimodal Sensor Fusion,明确预测了驾驶行为/规划和不确定性(通常用方差表示)。在预测的不确定性下,有些工作从多个输出中选择不确定性最低的输出,有些生成建议动作的加权组合。VTGNet则不直接使用不确定性进行规划,但证明了建模数据的不确定性可以提高总体性能。
目前,预测不确定性主要与硬编码规则结合使用。探索更好的方法来建模和利用自动驾驶的不确定性是必要的。
Causal Confusion
驾驶是一项表现出时间平稳性的任务,这使得过去的运动成为下一步行动的可靠预测因素。然而,使用多帧训练的方法可能会过度依赖这种捷径,并在部署过程中遭受灾难性失败。这个问题在一些著作中被称为模仿问题,是因果混淆的一种表现,在这种情况下,获得更多的信息会导致更差的表现。LeCun等人最早报道了这种效应。他们使用单帧输入来指导预测,以避免这种外推。尽管过于简单,但这仍然是当前最先进模仿学习的首选解决方案。不幸的是,使用单帧的缺点是无法提取周围actor的速度。造成混淆的另一个原因是速度测量。

汽车当前的动作与低维虚假特征(如速度或汽车过去的轨迹)密切相关。端到端模型可能会锁定它们,导致因果混淆。
当使用多帧时,有多种方法可以解决因果混淆问题。ChaffeurNet通过在BEV中使用中间视觉抽象来解决这个问题。一个抽象是自车代理的过去,而其他抽象不包含这些信息。在训练过程中,自车代理的过去动作以50%的概率被放弃。然而,这种方法需要显式的抽象才能有效地工作。Fighting Copycat Agents in Behavioral Cloning from Observation Histories,作者试图通过训练预测自车过去动作的对抗性模型,从学习的中间bottleneck表示中去除虚假的时间相关性。这导致了最小-最大优化问题,其中模仿损失被最小化并且对抗性损失被最大化。直观地说,这训练网络从其中间层消除其自身的过去。这种方法在MuJoCo中效果很好,但不能扩展到复杂的基于视觉的驾驶。
第一个研究驾驶复杂性的是Keyframe-Focused Visual lmitation Learning。他们建议在训练损失中增加关键帧的权重。关键帧是发生决策更改的帧(因此无法通过推断过去来预测)。为了找到关键帧,他们训练一个策略,该策略仅以自车代理的过去作为输入来预测动作。与关键帧相比,PrimeNet通过使用集合提高了性能,其中单帧模型的预测作为多帧模型的额外输入。Chuang等人也做了同样的事情,但用动作残差而不是动作来监督多帧网络。OREO将图像映射到表示语义对象的离散代码,并将随机dropout掩码,应用于共享相同离散代码的单元。这有助于混淆的 Atari,其中先前的动作在屏幕上呈现。在自动驾驶中,可以通过仅使用激光雷达历史(具有单帧图像)并将点云重新排列到同一坐标系中来避免因果混淆的问题。这删除了关于自车运动的信息,同时保留了关于其他车辆过去状态的信息。这项技术已被用于多项工作,尽管其动机并非如此。近二十年来,模仿学习中的因果混淆一直是一个持续的挑战。近年来,人们在研究这一问题方面做出了重大努力。然而,这些研究使用了经过修改的环境来简化因果混淆问题的研究。展示最先进的性能改进仍然是一个悬而未决的问题。
Robustness
Long-tailed Distribution
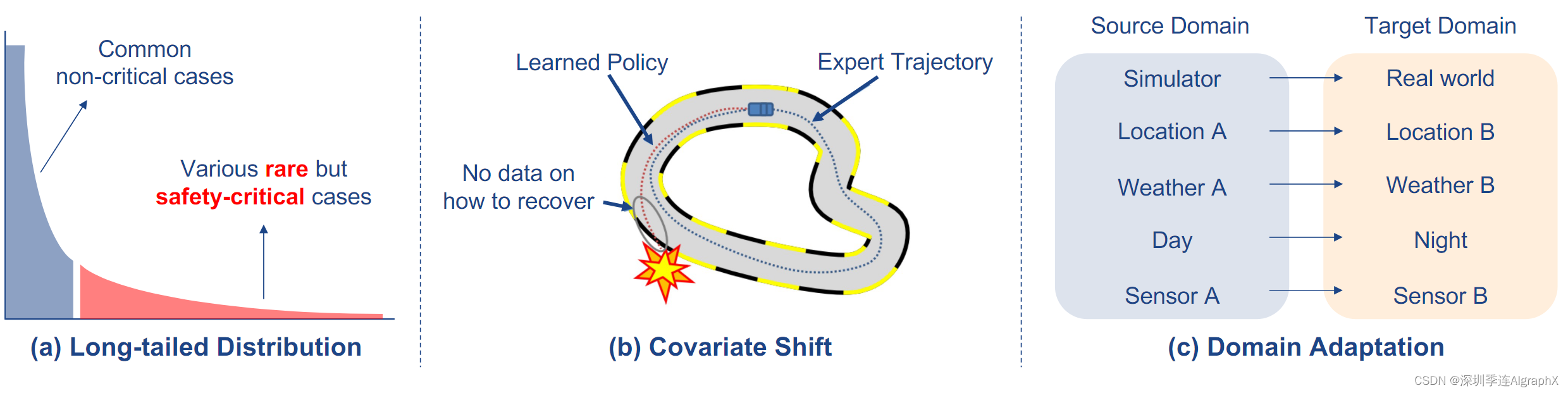
长尾分布问题的一个重要方面是数据集不平衡,其中少数类占多数,其他类只有有限量的样本,如图 8 (a) 所示。
这对模型泛化到各种环境提出了很大的挑战。有各种通过数据处理来解决这个问题的方法,包括过采样、欠采样和数据增强。此外,基于加权的方法也通常用于缓解数据集不平衡问题。
在端到端自动驾驶的背景下,长尾分布的问题特别严重。数据集不平衡在驾驶数据集中尤其成问题,因为大多数典型驾驶是重复而无趣,例如,许多帧的车道。相反,有趣的关键安全场景很少发生,但本质上是多样的。为了解决这个问题,一些作品依赖于手工制作场景,在仿真中生成更多样化和有趣的数据。LBC利用特权代理创建以不同导航命令为条件的虚构监督。LAV 认为,尽管用于数据收集的自车很少有事故倾向的情况,其他代理可能会经历一些关键安全或有趣的场景。因此,它包含了其他代理的训练轨迹,以促进数据的多样性。
Scalable End-to-End Autonomous Vehicle Testing via Rare-event Simulation,提出了一个仿真框架,应用重要性采样策略来加速罕见事件概率的评估。另一些研究通过对抗性攻击以数据驱动的方式生成关键安全场景。Generating Adversarial Driving Scenarios in High-Fidelity Simulators,贝叶斯优化用于生成对抗场景。Learning to Collide: An Adaptive Safety-Critical Scenarios Generating Method,学习碰撞将驾驶场景表示为building block的联合分布,并应用策略梯度RL方法生成危险场景。AdvSim 修改代理的轨迹,同时仍然遵守物理合理性,导致故障并相应地更新 LiDAR。最近的工作,KING 提出了一种优化算法,用于通过可微运动学模型使用梯度进行关键安全扰动。
一般来说,有效地生成覆盖长尾分布的真实关键安全场景,仍然是一个重大挑战。虽然许多工作都专注于模拟器中的对抗性场景,但最好利用真实世界的数据进行关键场景挖掘和潜在的模拟适应也很重要。此外,在这些长尾分布、关键安全场景下,系统、严格、全面和真实的测试框架对于评估端到端自动驾驶方法至关重要。
Covariate Shift
如第2.1节所讨论的,行为克隆的一个重要挑战是协变量移位。
备注:协变量偏移(Covariate Shift)是指训练集和测试集数据分布不一致,导致模型在训练集上表现良好,但在测试集上表现不佳。
专家策略状态分布与经过训练的代理策略状态分布不同,导致训练代理部署在看不见的测试环境,或来自训练时其他代理的反应不同,有复合错误。这可能会导致经过训练的代理处于超出专家训练分布的状态,从而导致严重的故障。图 8 (b) 给出了一个说明。
DAgger,数据集聚合是一种常用的克服这一问题的方法。DAgger 是一个迭代训练过程,在每次迭代中推出当前训练策略以收集新数据,专家用于标记访问的状态。这是通过添加从不完美的策略可能访问的次优状态中,恢复样本来丰富训练数据集。然后在增强数据集上训练策略,并且过程重复。然而,DAgger 的一个缺点是需要可用的专家在线查询。
对于端到端自动驾驶,Agile Autonomous Driving using End-to-End Deep Imitation Learning 采用基于 MPC 的专家和 DAgger 一起使用。为了减少不断查询专家并提高安全性的成本,SafeDAgger 通过学习估计当前策略和专家策略偏差的安全策略来扩展原始 DAgger 算法。专家只有在偏差较大时才能查询,专家才会在这些危险情况下接管。MetaDAgger 将元学习与 DAgger 相结合来聚合来自多个环境的数据。LBC 采用DAgger对数据进行重采样,使损失较高的样本更频繁地采样。DARB 工作则对 DAgger 进行了一些修改以适应驾驶任务。为了更好地利用故障或安全相关的样本,文中提出了几种机制,包括基于任务、基于策略、基于策略和专家的机制,以对此类关键状态进行采样。它还使用固定大小的重放缓冲区进行迭代训练,以增加多样性并减少数据集偏差。
Domain Adaptation
域适应 (DA) 是一种迁移学习,其中目标任务与源任务相同,但域不同。在这里,我们讨论了可用于源域标签的场景,而目标域没有可用的标签或有限数量的标签。如图 8 (c) 所示,自动驾驶任务的域适应包括几个案例:
• Sim-to-real:用于仿真与真实世界之间。
• Geography-to-geography:具有不同环境外观的不同地理位置。
• Weather-to-weather:由降雨、雾和雪等天气条件引起的传感器输入变化。
• Day-to-night::传感器输入的光照变化。
• Sensor-to-sensor:传感器特征可能存在差异,例如分辨率和相对位置。
请注意,上述情况经常重叠。VVISRI使用转换网络将模拟图像映射到真实图像,语义分割图作为中间表示。RL 代理基于转换的模拟图像进行训练。Learning to Drive from Simulation without Real World Labels,通过图像转换和鉴别器实现域不变特征学习,将图像从两个域映射到常见的潜在空间。类似地,LUSR 采用 CycleConsistent VAE 将图像投影到由特定领域部分和通用部分组成的潜在表示中,在此基础上学习策略。UAIIL 通过将来自不同天气条件的图像,分解为可区分的样式空间和与 GAN 共享内容空间,达到天气到天气的适应。在 SESR 中,从语义分割掩码中提取class disentangled 编码,以减少模拟器和现实世界中图像之间的域差距。
域随机化也是模拟器中强化策略学习,Sim-to-real 一种简单有效的技术,并进一步适应端到端自动驾驶。它是通过随机化模拟器的渲染和物理设置来实现的,以覆盖训练过程中真实世界的可变性,并获得具有良好泛化能力的训练策略。
目前,通过源-目标图像映射或域不变特征学习进行模拟到真实的自适应是端到端自动驾驶的重点。
其他域适应案例,例如地理到地理或天气到天气适应,通过训练数据集的多样性和规模进行处理。由于激光雷达已成为驾驶流行输入模式,因此还必须设计针对激光雷达特征量身定制的特定适应技术,因为目前的工作主要集中在基于图像的适应上。此外,应将注意力吸引到交通代理在模拟器和现实世界之间的行为和交通规则差距中,因为目前的方法只关注图像中的视觉差距。
通过NeRF等技术将真实世界的数据纳入模拟是另一个有前途的方向。
Future Trends
Zero-shot and Few-shot Learning
自动驾驶模型不可避免地会遇到超出训练数据分布的真实场景。这就提出了一个问题,即我们是否可以成功地将模型适应用于有限或没有标记数据、看不见的目标域。将端到端驾驶任务正则化,并结合零样本/少样本学习技术,是实现这一目标的关键步骤。
Modular End-to-end Planning
模块化端到端规划框架优化了多个模块,同时优先考虑下游规划任务,这具有可解释性的优点,如第4.6节所示。这在最近的文献Planning-oriented Autonomous Driving,DiffStack: A Differentiable and Modular Control Stack for Autonomous Vehicles和某些行业解决方案(Tesla, Wayve等)中提倡这一点,涉及类似的想法。
在设计这些可微感知模块时,损失函数的选择会出现几个问题,例如 3D 边界框用于目标检测的必要性,占用表示是否足以检测一般障碍物,或者选择BEV分割相对于车道拓扑进行静态场景感知的优势。
Data Engine
大规模和高质量数据对自动驾驶的重要性怎么强调都不算过分。使用自动标注pipeline建立数据引擎可以极大地促进数据和模型的迭代开发。自动驾驶的数据引擎,尤其是模块化的端到端规划系统,需要借助大型感知模型自动简化标注高质量感知标签。它还应该支持挖掘hard/corner cases、场景生成和编辑,以促进第 3.1 节中讨论的数据驱动评估,并促进数据的多样性和模型的泛化能力(第 4.8 节)。数据引擎将使自动驾驶模型能够做出一致的改进。
Foundation Model
语言和视觉大型基础模型的最新进展对社会的各个方面都产生了重大影响。利用大规模数据和模型容量,已经释放了人工智能在高级推理任务中的巨大潜力。微调、提示学习、自监督重建、对比学习和数据流水线等形式的优化都适用于端到端自动驾驶领域。
然而,我们认为直接采用LLM进行自动驾驶任务,似乎存在目标不一致的情形。自动智能体的输出通常需要稳定和准确的度量数据,而语言模型中的生成序列输出旨在表现得像人类,而不管其准确性如何。
开发大型自动驾驶模型的一个可行的解决方案是训练一个视频预测器,可以实现环境中的长预测。
为了在规划等下游任务上表现良好,针对大型模型进行优化的目标需要足够复杂,超出帧级感知。
备注:许多开创性的工作已经探索了使用大型语言模型来增强AV系统在开环环境中的推理能力、可解释性和整体性能的潜力。最常见的策略之一[Driving with LLMs: Fusing Object-Level Vector Modality for Explainable Autonomous Driving]是:1)首先使用LLM将场景感知结果和导航命令转换为文本描述;2) 将这些文本描述输入LLM以生成文本驾驶决策;然后3)将文本驾驶决策转换为可执行的控制命令。虽然这显示了良好的初步结果,但这种类型的方法,即不同的LLM单独处理子任务,很难以端到端的方式进行训练,失去了利用大量数据进行扩展的能力,并且对感知错误和不确定性不强。例如,由于后两个阶段中的LLM不能访问传感器数据,因此第一阶段中的不准确或遗漏检测可能导致后两个步骤中的大的累积误差。为了解决这些问题,DRIVEGPT4已经提出了端到端的基于语言的驾驶方法。
此外,视觉大语言模型(VLLM)进一步引入了视觉编码器,并为LLM打开了大门,不仅可以解释文本数据,还可以解释其他模态的图像和数据。在自动驾驶领域,最近的研究将LLM集成到自动驾驶系统中,以更好地解释和与人类的自然互动。一些研究采用了视觉语言模型方法,该方法可以处理多模态输入数据,并为驾驶场景提供文本描述和控制信号。例如,DRIVEGPT4提出了一种多模式LLM框架,该框架将一系列帧作为输入,然后生成对人类询问的响应,并预测下一步的控制信号。然而,由于该框架缺乏输入命令,预测的控制无法遵循特定的导航命令,这表明该框架很难在真实场景中部署。与此同时,更多的研究人员专注于将驾驶情况转换为文本描述,作为LLM的输入,以直接解释和推理综合驾驶情况。在这一系列工作中,GPT Driver通过将异构场景输入转换为语言标记,将运动规划重新表述为自然语言建模的任务。LanguageMPC利用LLM来推理复杂场景并输出高级驾驶决策。然后,该方法调节参数矩阵以将决策转换为低电平控制信号。LLM-Driver利用数字矩阵作为输入模态和融合的矢量化对象级2D场景表示,以使LLM能够基于当前环境回答问题。
Vehicle-to-everything (V2X)
感知范围之外的遮挡和障碍物是现代计算机视觉技术的两个根本挑战,当人类驾驶员需要快速反应穿越代理时,这可能会给人类驾驶员带来很大的困难。车辆到车辆 (V2V)、车辆到基础设施 (V2I) 和车辆到一切 (V2X) 系统为解决这一关键提供了有希望的解决方案,其中来自不同视点的信息补充了自我盲点。这些系统见证了多智能体场景信息传输机制的进展,可以为自动驾驶汽车之间实现高级决策智能提供解决方案。
Conclusion
在本综述中,我们给出了基本方法的概述,并总结了模拟和基准测试的各个方面。我们彻底分析了迄今为止广泛的文献,并强调了广泛的关键挑战和有希望的解决方案。最后讨论了未来的努力,以拥抱快速发展的基础模型和数据引擎。端到端自动驾驶面临着巨大的机遇和挑战,最终目标是建立通才智能体。在这个新兴技术的时代,我们希望这项综述能作为一个起点,揭示这个领域的新曙光。