论文精读--GPT1
把transformer的解码器拿出来,在没有标号的大量文本数据上训练一个语言模型,来获得预训练模型,然后到子任务上微调,得到每个任务所需的分类器
Abstract
Natural language understanding comprises a wide range of diverse tasks such as textual entailment, question answering, semantic similarity assessment, and document classification. Although large unlabeled text corpora are abundant, labeled data for learning these specific tasks is scarce, making it challenging for discriminatively trained models to perform adequately. We demonstrate that large gains on these tasks can be realized by generative pre-training of a language model on a diverse corpus of unlabeled text, followed by discriminative fine-tuning on each specific task. In contrast to previous approaches, we make use of task-aware input transformations during fine-tuning to achieve effective transfer while requiring minimal changes to the model architecture. We demonstrate the effectiveness of our approach on a wide range of benchmarks for natural language understanding.Our general task-agnostic model outperforms discriminatively trained models that use architectures specifically crafted for each task, significantly improving upon the state of the art in 9 out of the 12 tasks studied. For instance, we achieve absolute improvements of 8.9% on commonsense reasoning (Stories Cloze Test), 5.7% on question answering (RACE), and 1.5% on textual entailment (MultiNLI).
翻译:
自然语言理解包括各种各样的任务,如文本蕴涵、问题回答、语义相似性评估和文档分类。尽管大量未标记的文本语料库丰富,但用于学习这些特定任务的标记数据很少,这使得判别训练模型难以充分执行。我们证明,通过在不同的未标记文本语料库上对语言模型进行生成式预训练,然后对每个特定任务进行判别性微调,可以实现这些任务的巨大收益。与以前的方法相反,我们在微调期间利用任务感知输入转换来实现有效的传输,同时需要对模型体系结构进行最小的更改。我们在自然语言理解的广泛基准上证明了我们的方法的有效性。我们的通用任务不可知模型优于为每个任务使用专门设计的架构的判别训练模型,在研究的12个任务中的9个任务中显著提高了技术水平。例如,我们在常识性推理(故事完形测试)上实现了8.9%的绝对改进,在问题回答(RACE)上实现了5.7%的绝对改进,在文本蕴涵(MultiNLI)上实现了1.5%的绝对改进。
总结:
微调时只改变输入的形式,而不需要改变模型
Introduction
The ability to learn effectively from raw text is crucial to alleviating the dependence on supervised learning in natural language processing (NLP). Most deep learning methods require substantial amounts of manually labeled data, which restricts their applicability in many domains that suffer from a dearth of annotated resources [61]. In these situations, models that can leverage linguistic information from unlabeled data provide a valuable alternative to gathering more annotation, which can be time-consuming and expensive. Further, even in cases where considerable supervision is available, learning good representations in an unsupervised fashion can provide a significant performance boost. The most compelling evidence for this so far has been the extensive use of pretrained word embeddings [10, 39, 42] to improve performance on a range of NLP tasks [8, 11, 26, 45].
翻译:
在自然语言处理(NLP)中,从原始文本中有效学习的能力对于减轻对监督学习的依赖至关重要。大多数深度学习方法需要大量的人工标记数据,这限制了它们在许多缺乏注释资源的领域的适用性[61]。在这些情况下,可以利用未标记数据中的语言信息的模型为收集更多注释提供了有价值的替代方法,而收集更多注释既耗时又昂贵。此外,即使在有大量监督的情况下,以无监督的方式学习良好的表示也可以显著提高性能。到目前为止,最令人信服的证据是广泛使用预训练词嵌入[10,39,42]来提高一系列NLP任务的性能[8,11,26,45]。
Leveraging more than word-level information from unlabeled text, however, is challenging for two main reasons. First, it is unclear what type of optimization objectives are most effective at learning text representations that are useful for transfer. Recent research has looked at various objectives such as language modeling [44], machine translation [38], and discourse coherence [22], with each method outperforming the others on different tasks.1 Second, there is no consensus on the most effective way to transfer these learned representations to the target task. Existing techniques involve a combination of making task-specific changes to the model architecture [43, 44], using intricate learning schemes [21] and adding auxiliary learning objectives [50]. These uncertainties have made it difficult to develop effective semi-supervised learning approaches for language processing.
翻译:
然而,由于两个主要原因,从未标记的文本中利用超过单词级别的信息是具有挑战性的。首先,目前还不清楚哪种类型的优化目标在学习对迁移有用的文本表示时最有效。最近的研究着眼于不同的目标,如语言建模[44]、机器翻译[38]和话语连贯[22],每种方法在不同的任务上都优于其他方法。其次,对于将这些习得表征转移到目标任务的最有效方法尚无共识。现有的技术包括对模型架构进行特定于任务的更改[43,44],使用复杂的学习方案[21]和添加辅助学习目标[50]。这些不确定性使得开发有效的半监督学习语言处理方法变得困难。
总结:
两个挑战:(1)不同任务目标函数不同(2)nlp领域子任务差别较大,一种表示难以一致地迁移到所有子任务上
In this paper, we explore a semi-supervised approach for language understanding tasks using a combination of unsupervised pre-training and supervised fine-tuning. Our goal is to learn a universal representation that transfers with little adaptation to a wide range of tasks. We assume access to a large corpus of unlabeled text and several datasets with manually annotated training examples (target tasks). Our setup does not require these target tasks to be in the same domain as the unlabeled corpus. We employ a two-stage training procedure. First, we use a language modeling objective on the unlabeled data to learn the initial parameters of a neural network model. Subsequently, we adapt these parameters to a target task using the corresponding supervised objective.
翻译:
在本文中,我们探索了一种半监督方法,使用无监督预训练和监督微调相结合的方法来完成语言理解任务。我们的目标是学习一种普遍的表征,这种表征可以在很少的适应下转移到广泛的任务中。我们假设可以访问大量未标记文本的语料库和几个带有手动注释的训练示例(目标任务)的数据集。我们的设置不要求这些目标任务与未标记的语料库在同一域中。我们采用两阶段的训练程序。首先,我们在未标记数据上使用语言建模目标来学习神经网络模型的初始参数。随后,我们使用相应的监督目标将这些参数调整到目标任务中。
For our model architecture, we use the Transformer [62], which has been shown to perform strongly on various tasks such as machine translation [62], document generation [34], and syntactic parsing [29].This model choice provides us with a more structured memory for handling long-term dependencies in text, compared to alternatives like recurrent networks, resulting in robust transfer performance across diverse tasks. During transfer, we utilize task-specific input adaptations derived from traversal-style approaches [52], which process structured text input as a single contiguous sequence of tokens. As we demonstrate in our experiments, these adaptations enable us to fine-tune effectively with minimal changes to the architecture of the pre-trained model.
翻译:
对于我们的模型体系结构,我们使用Transformer[62],它已被证明在各种任务上表现出色,如机器翻译[62]、文档生成[34]和语法解析[29]。与循环网络等替代方案相比,这种模型选择为我们提供了更结构化的记忆来处理文本中的长期依赖关系,从而在不同任务之间实现了强大的传输性能。在迁移过程中,我们利用基于遍历式方法([52])获得的任务特定输入适应性,将结构化文本输入处理为一个连续的标记序列。正如我们在实验中所展示的那样,这些适应性使我们能够在对预训练模型的架构进行最小更改的情况下有效地进行微调。
总结:
基于transformer架构,因为transformer在迁移学习时相较于RNN,学到的特征更稳健一些;作者认为可能是因为transformer有更结构化的记忆,使得能处理更长的文本信息,从而抽取出更好的句子层面和段落层面的语义信息
We evaluate our approach on four types of language understanding tasks – natural language inference, question answering, semantic similarity, and text classification. Our general task-agnostic model outperforms discriminatively trained models that employ architectures specifically crafted for each task, significantly improving upon the state of the art in 9 out of the 12 tasks studied. For instance, we achieve absolute improvements of 8.9% on commonsense reasoning (Stories Cloze Test) [40], 5.7% on question answering (RACE) [30], 1.5% on textual entailment (MultiNLI) [66] and 5.5% on the recently introduced GLUE multi-task benchmark [64]. We also analyzed zero-shot behaviors of the pre-trained model on four different settings and demonstrate that it acquires useful linguistic knowledge for downstream tasks.
翻译:
我们在四种类型的语言理解任务上评估了我们的方法——自然语言推理、问题回答、语义相似性和文本分类。我们的一般任务不可知模型优于为每个任务专门设计的架构的判别训练模型,在研究的12个任务中的9个任务中显著提高了技术水平。例如,我们在常识性推理(故事完形测试)[40]上取得了8.9%的绝对进步,在问答(RACE)[30]上取得了5.7%的绝对进步,在文本蕴涵(MultiNLI)[66]上取得了1.5%的绝对进步,在最近引入的GLUE多任务基准测试上取得了5.5%的绝对进步[64]。我们还分析了四种不同设置下预训练模型的零射击行为,并证明它为下游任务获得了有用的语言知识。
Related Work
Semi-supervised learning for NLP
Our work broadly falls under the category of semi-supervised learning for natural language. This paradigm has attracted significant interest, with applications to tasks like sequence labeling [24, 33, 57] or text classification [41, 70]. The earliest approaches used unlabeled data to compute word-level or phrase-level statistics, which were then used as features in a supervised model [33]. Over the last few years, researchers have demonstrated the benefits of using word embeddings [11, 39, 42], which are trained on unlabeled corpora, to improve performance on a variety of tasks [8, 11, 26, 45]. These approaches, however, mainly transfer word-level information, whereas we aim to capture higher-level semantics.
Recent approaches have investigated learning and utilizing more than word-level semantics from unlabeled data. Phrase-level or sentence-level embeddings, which can be trained using an unlabeled corpus, have been used to encode text into suitable vector representations for various target tasks [28, 32, 1, 36, 22, 12, 56, 31].
翻译:
我们的工作大致属于自然语言的半监督学习范畴。这种范式已经引起了极大的兴趣,并应用于序列标记[24,33,57]或文本分类[41,70]等任务。最早的方法是使用未标记的数据来计算词级或短语级统计,然后将其用作监督模型中的特征[33]。在过去的几年里,研究人员已经证明了使用词嵌入的好处[11,39,42],它是在未标记的语料库上训练的,可以提高各种任务的性能[8,11,26,45]。然而,这些方法主要是传递词级信息,而我们的目标是捕获更高级别的语义。
最近的方法研究了从未标记数据中学习和利用超过单词级别的语义。短语级或句子级嵌入可以使用未标记的语料库进行训练,已用于将文本编码为适合各种目标任务的向量表示。
Unsupervised pre-training
Unsupervised pre-training is a special case of semi-supervised learning where the goal is to find a good initialization point instead of modifying the supervised learning objective. Early works explored the use of the technique in image classification [20, 49, 63] and regression tasks [3]. Subsequent research [15] demonstrated that pre-training acts as a regularization scheme, enabling better generalization in deep neural networks. In recent work, the method has been used to help train deep neural networks on various tasks like image classification [69], speech recognition [68], entity disambiguation [17] and machine translation [48].
The closest line of work to ours involves pre-training a neural network using a language modeling objective and then fine-tuning it on a target task with supervision. Dai et al [13] and Howard and Ruder [21] follow this method to improve text classification. However, although the pre-training phase helps capture some linguistic information, their usage of LSTM models restricts their prediction ability to a short range. In contrast, our choice of transformer networks allows us to capture longerrange linguistic structure, as demonstrated in our experiments. Further, we also demonstrate the effectiveness of our model on a wider range of tasks including natural language inference, paraphrase detection and story completion. Other approaches [43, 44, 38] use hidden representations from a pre-trained language or machine translation model as auxiliary features while training a supervised model on the target task. This involves a substantial amount of new parameters for each separate target task, whereas we require minimal changes to our model architecture during transfer.
翻译:
无监督预训练是半监督学习的一种特殊情况,其目标是找到一个好的初始点,而不是修改监督学习目标。早期的作品探索了该技术在图像分类[20,49,63]和回归任务[3]中的应用。随后的研究[15]表明,预训练作为一种正则化方案,可以在深度神经网络中实现更好的泛化。在最近的工作中,该方法已被用于帮助训练深度神经网络完成各种任务,如图像分类[69]、语音识别[68]、实体消歧[17]和机器翻译[48]。
与我们最接近的工作包括使用语言建模目标预训练神经网络,然后在监督下对目标任务进行微调。Dai等人[13]和Howard和Ruder[21]采用这种方法改进了文本分类。然而,尽管预训练阶段有助于捕获一些语言信息,但他们对LSTM模型的使用限制了他们的预测能力在很短的范围内。相比之下,我们对transformer的选择使我们能够捕获更远距离的语言结构,正如我们的实验所证明的那样。此外,我们还证明了我们的模型在更广泛的任务上的有效性,包括自然语言推理、释义检测和故事完成。其他方法[43,44,38]使用来自预训练语言或机器翻译模型的隐藏表示作为辅助特征,同时在目标任务上训练监督模型。这涉及到每个单独的目标任务的大量新参数,而我们需要在转移期间对模型体系结构进行最小的更改。
Auxiliary training objectives
Adding auxiliary unsupervised training objectives is an alternative form of semi-supervised learning. Early work by Collobert and Weston [10] used a wide variety of auxiliary NLP tasks such as POS tagging, chunking, named entity recognition, and language modeling to improve semantic role labeling. More recently, Rei [50] added an auxiliary language modeling objective to their target task objective and demonstrated performance gains on sequence labeling tasks. Our experiments also use an auxiliary objective, but as we show, unsupervised pre-training already learns several linguistic aspects relevant to target tasks.
翻译:
添加辅助无监督训练目标是半监督学习的另一种形式。Collobert和Weston[10]的早期工作使用了各种辅助NLP任务,如词性标注、分块、命名实体识别和语言建模,以改进语义角色标注。最近,Rei[50]在他们的目标任务目标中添加了一个辅助语言建模目标,并证明了序列标记任务的性能提升。我们的实验也使用了辅助目标,但正如我们所示,无监督的预训练已经学习了与目标任务相关的几个语言方面。
Framework
Unsupervised pre-training
Given an unsupervised corpus of tokens U = {u1, ...,un}, we use a standard language modeling objective to maximize the following likelihood:
where k is the size of the context window, and the conditional probability P is modeled using a neural network with parameters Θ. These parameters are trained using stochastic gradient descent [51].
In our experiments, we use a multi-layer Transformer decoder [34] for the language model, which is a variant of the transformer [62]. This model applies a multi-headed self-attention operation over the input context tokens followed by position-wise feedforward layers to produce an output distribution over target tokens:
where U = (u−k; ... ; u−1) is the context vector of tokens, n is the number of layers, We is the token embedding matrix, and Wp is the position embedding matrix.
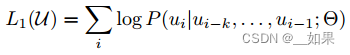

翻译:
给定一个无监督的token语料库U = {u1, ...,un},我们使用标准的语言建模目标来最大化以下可能性:
其中k是上下文窗口的大小,条件概率P使用参数为Θ的神经网络建模。这些参数是用随机梯度下降法训练的[51]。
在我们的实验中,我们为语言模型使用了多层Transformer解码器[34],这是Transformer[62]的一种变体。该模型在输入上下文令牌上应用多头自注意力操作,然后在位置前馈层上生成目标token的输出分布:
其中U = (u−k; ... ; u−1)为token的上下文向量,n为层数,We为词嵌入矩阵,Wp为位置嵌入矩阵。
总结:
没有标号的文本中每个词表示成ui,语言模型用前k个词预测第i个词出现的概率
transformer编码器与解码器的区别在于mask,导致解码器对第i个词抽特征时只能看到第i个词及其之前的词
对词进行词嵌入投影,再加上位置编码得到第一层输入h0,然后做n层的transformer块;因为transformer块不会改变输入输出的形状,所以做完投影之后softmax就得到了概率分布
与BERT对比
GPT的任务更难:预测未来肯定比完形填空难,所以一开始GPT1的效果并不如BERT,但后面模型变大之后效果就很明显了
Supervised fine-tuning
After training the model with the objective in Eq. 1, we adapt the parameters to the supervised target task. We assume a labeled dataset C, where each instance consists of a sequence of input tokens, x1,...,xm, along with a label y. The inputs are passed through our pre-trained model to obtain the final transformer block’s activation hl^m, which is then fed into an added linear output layer with parameters Wy to predict y:
This gives us the following objective to maximize:
We additionally found that including language modeling as an auxiliary objective to the fine-tuning helped learning by (a) improving generalization of the supervised model, and (b) accelerating convergence. This is in line with prior work [50, 43], who also observed improved performance with such an auxiliary objective. Specifically, we optimize the following objective (with weight λ):
L3(C) = L2(C) + λ ∗ L1(C)
Overall, the only extra parameters we require during fine-tuning are Wy, and embeddings for delimiter tokens (described below in Section 3.3).
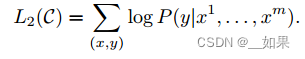
翻译:
在使用Eq. 1中的目标训练模型后,我们将参数调整为监督目标任务。我们假设一个有标签的数据集C,其中每个实例由一系列输入令牌x1,…,xm,以及标签y。输入通过我们的预训练模型获得最终变压器块的激活hl^m,然后将其馈送到一个附加的线性输出层,参数为Wy,以预测y:
这给了我们以下最大化的目标:
我们还发现,将语言建模作为微调的辅助目标有助于学习(a)提高监督模型的泛化,(b)加速收敛。这与先前的研究一致[50,43],他们也观察到使用这种辅助目标可以提高性能。具体来说,我们优化以下目标(权重为λ):
L3(C) = L2 (C) + λ * L1(C)
总的来说,我们在微调期间需要的唯一额外参数是Wy,以及分隔符标记的嵌入(将在下面的3.3节中描述)。
总结:
每次给长为m的词序列,并且告诉序列的标号y,将预训练最后一层得到的hm词嵌入投影后的softmax作为预测概率
作者发现把之前无监督学习时的目标函数L1放进微调的目标函数中效果会更好,也就是说有两个目标函数,一个是给你一个序列预测下一个词,另一个是预测序列对应的标号
Task-specific input transformations

分类问题:文本之前放一个初始的词元,在后面加一个抽取的词元,序列放进transformer的解码器,模型对最后一个词抽取的特征hm放进一个线性层,投影到我要的标号的空间
蕴含问题:start、delim、extract不是真实的词,而是符号,将两个文本拼起来,三分类问题
相似度问题:GPT中U是有先后顺序的,所以AB、BA都要有
多选题:n个答案就有n个序列
不管输入怎么变,模型构造和输出都是不变的
Experiments
Model specifications
Our model largely follows the original transformer work [62]. We trained a 12-layer decoder-only transformer with masked self-attention heads (768 dimensional states and 12 attention heads). For the position-wise feed-forward networks, we used 3072 dimensional inner states.
翻译:
我们的模型在很大程度上遵循了原来的transformer工作[62]。我们训练了一个只有12层解码器的transformer,它具有掩码自注意力头(768维状态和12个注意头)。对于位置前馈网络,我们使用了3072维的内部状态。
Analysis
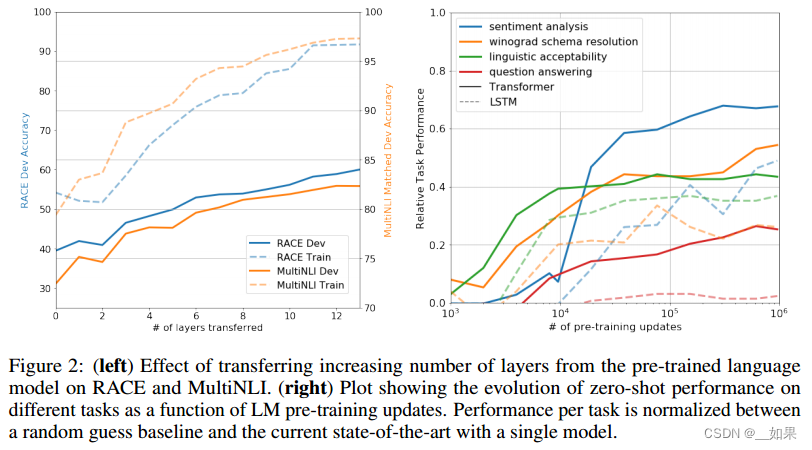
Zero-shot Behaviors
We’d like to better understand why language model pre-training of transformers is effective. A hypothesis is that the underlying generative model learns to perform many of the tasks we evaluate on in order to improve its language modeling capability and that the more structured attentional memory of the transformer assists in transfer compared to LSTMs. We designed a series of heuristic solutions that use the underlying generative model to perform tasks without supervised finetuning. We visualize the effectiveness of these heuristic solutions over the course of generative pre-training in Fig 2(right). We observe the performance of these heuristics is stable and steadily increases over training suggesting that generative pretraining supports the learning of a wide variety of task relevant functionality. We also observe the LSTM exhibits higher variance in its zero-shot performance suggesting that the inductive bias of the Transformer architecture assists in transfer.
翻译:
我们想更好地理解为什么语言模型预训练的transformer是有效的。一种假设是,底层生成模型学习执行我们评估的许多任务,以提高其语言建模能力,并且与lstm相比,transformer的更结构化的注意力记忆有助于迁移。我们设计了一系列启发式解决方案,使用底层生成模型在没有监督微调的情况下执行任务。我们在图2(右)中可视化了这些启发式解决方案在生成式预训练过程中的有效性。我们观察到这些启发式的性能是稳定的,并且在训练中稳步增长,这表明生成式预训练支持各种任务相关功能的学习。我们还观察到,在零样本性能方面,LSTM表现出更高的方差,这表明Transformer架构的归纳偏置有助于迁移学习。
Conclusion
We introduced a framework for achieving strong natural language understanding with a single task-agnostic model through generative pre-training and discriminative fine-tuning. By pre-training on a diverse corpus with long stretches of contiguous text our model acquires significant world knowledge and ability to process long-range dependencies which are then successfully transferred to solving discriminative tasks such as question answering, semantic similarity assessment, entailment determination, and text classification, improving the state of the art on 9 of the 12 datasets we study. Using unsupervised (pre-)training to boost performance on discriminative tasks has long been an important goal of Machine Learning research. Our work suggests that achieving significant performance gains is indeed possible, and offers hints as to what models (Transformers) and data sets (text with long range dependencies) work best with this approach. We hope that this will help enable new research into unsupervised learning, for both natural language understanding and other domains, further improving our understanding of how and when unsupervised learning works.
翻译:
我们引入了一个框架,通过生成式预训练和判别微调,使用单一任务不可知论模型实现强自然语言理解。通过在具有长段连续文本的不同语料库上进行预训练,我们的模型获得了重要的世界知识和处理远程依赖关系的能力,然后成功地转移到解决判别性任务,如问题回答、语义相似性评估、蕴意确定和文本分类,提高了我们研究的12个数据集中的9个数据集的技术水平。长期以来,使用无监督(预)训练来提高识别任务的性能一直是机器学习研究的一个重要目标。我们的工作表明,实现显著的性能提升确实是可能的,并提供了关于哪种模型(transformer)和数据集(具有长期依赖关系的文本)最适合这种方法的提示。我们希望这将有助于对自然语言理解和其他领域的无监督学习进行新的研究,进一步提高我们对无监督学习如何以及何时起作用的理解。