Google发布Genie硬杠Sora:通过大量无监督视频训练最终生成可交互虚拟世界
前言
Sora 问世才不到两个星期,谷歌的世界模型也来了,能力看似更强大:它生成的虚拟世界自主可控
第一部分 首个基础世界模型Genie
1.1 Genie是什么
Genie是第一个以无监督方式从未标记的互联网视频中训练的生成式交互环境(the first generative interactive environment trained in an unsupervised manner from unlabelled Internet video)的基础世界模型
其训练数据集包含超过200000小时公开可用的互联网游戏视频,尽管没有动作或文本注释的训练(没有任何动作标签数据),但可以通过学习到的潜在动作空间逐帧进行控制(Our approach, Genie, is trained from a large dataset of over 200,000 hours of publicly available Internet gaming videos and, despite training without action or text annotations, is controllable on a frame-by-frame basis via a learned latent action space)
这点其实非常牛,因为互联网上视频太多了,很多都是没有任何标签或描述的,有的只是一个个动作、一帧帧画面,但模型如果能根据已经看到的动作或画面去预测下一个可能的画面(已有动作 + 预测接下来潜在可能的动作 = 下一个画面 ),之后再把预测的画面与真实画面建loss去优化预测策略,那说的极端点,哪个视频不可以用作训练视频呢?
总之,因为互联网视频通常没有关于正在执行哪个动作、应该控制图像哪一部分的标签,但 Genie 能够专门从互联网视频中学习细粒度的控制
且尽管所用数据更多是 2D Platformer 游戏游戏和机器人视频,但可扩展到更大的互联网数据集
对于 Genie 而言,它不仅了解观察到的哪些部分通常是可控的,而且还能推断出在生成环境中一致的各种潜在动作
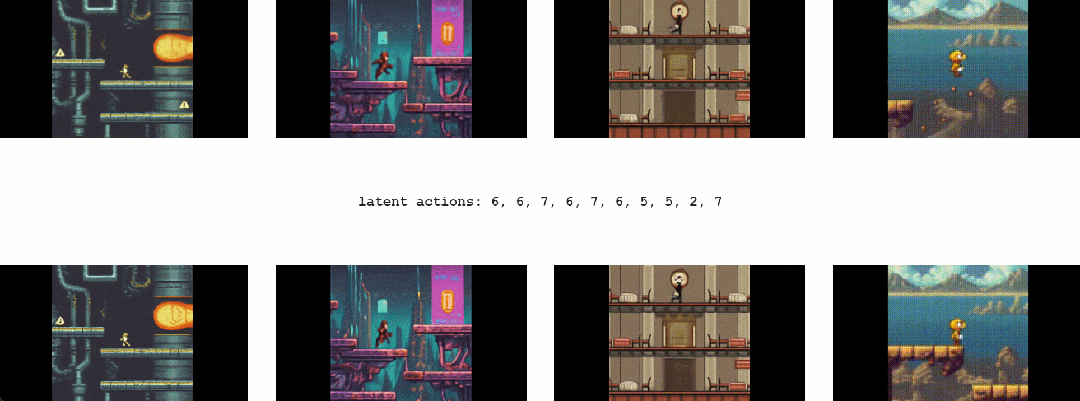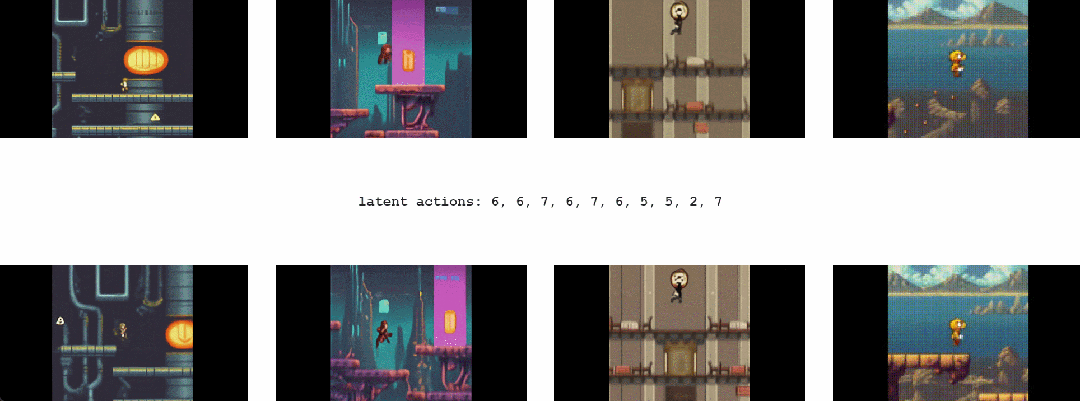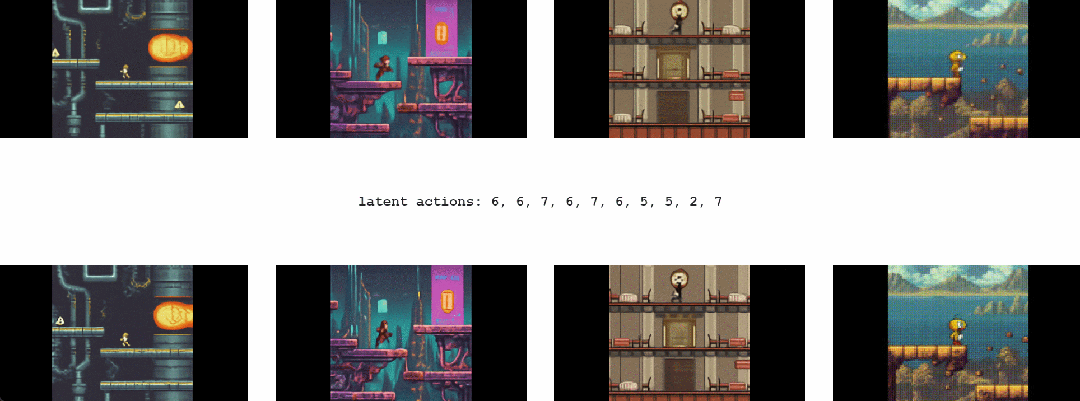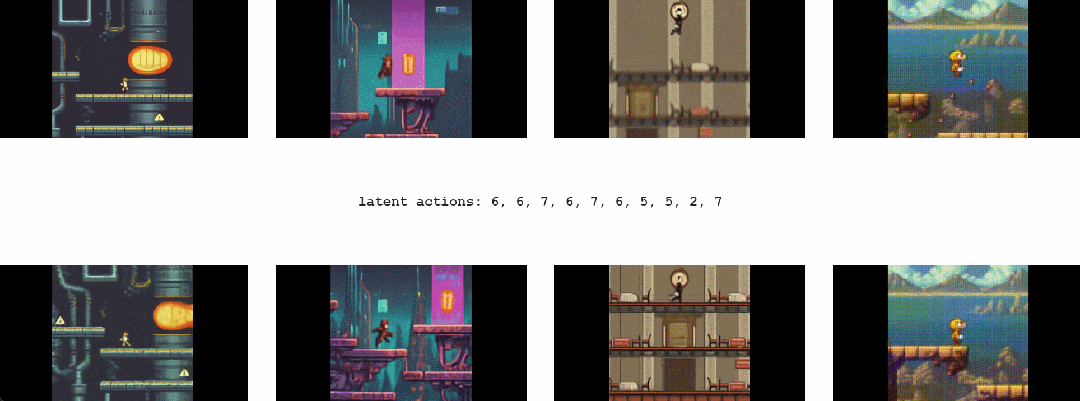
1.2 Genie能干啥
最终,只需要一张图像就可以创建一个全新的交互环境,例如,可以使用最先进的文本生成图像模型来生成起始帧,然后与 Genie 一起生成动态交互环境
在如下动图中,谷歌使用 Imagen2 生成了图像,再使用 Genie 将它们变为现实:

Genie 能做到的不止如此,它还可以应用到草图等人类设计相关的创作领域

或者,应用在真实世界的图像中:

此文,谷歌在 RT1 的无动作视频上训练了一个较小的 2.5B 模型。与 Platformers 的情况一样,具有相同潜在动作序列的轨迹通常会表现出相似的行为。
这表明 Genie 能够学习一致的动作空间,这可能适合训练机器人,打造通用化的具身智能

第二部分 技术揭秘:论文《Genie: Generative Interactive Environments》
Genie对应的论文为《Genie: Generative Interactive Environments》,其项目主页为:https://sites.google.com/view/genie-2024/home
论文的共同一作多达 6 人,其中包括华人学者石宇歌Yuge (Jimmy) Shi,她目前是谷歌 DeepMind 研究科学家,2023 年获得牛津大学机器学习博士学位
2.1 ST-transformer 架构
视频最多可以包含 𝑂(10^4 ) 个 token,而 Transformer 的二次内存成本对于视频生成的压力是比较大的,因此,Genie在所有模型组件中采用内存高效的 ST-transformer 架构

与传统的Transformer不同,每个token都会与其他所有token进行关注(Unlike a traditional transformer where every token attends to all other),ST-transformer包含 个时空块,其中交替出现空间和时间注意力层,然后是标准的前馈层FFW注意力块
- 空间层中的自注意力关注每个时间步内的
个token,而时间层中的自注意力关注跨越
个token的
个时间步
- 与序列转换器类似,时间层假设具有因果结构和因果掩码。 重要的是,我们架构中计算复杂性的主导因素(即空间注意力层)与帧数呈线性关系,而不是二次关系,使其在具有一致动态的长时间交互视频生成中更加高效
Similar to sequence transformers, the temporal layer assumes a causal structure with a causal mask. Crucially, the dominating factor of computation complexity (i.e. the spatial attention layer) in our architecture scales linearly with the number of frames rather than quadratically, making it much more efficient for video generation with consistent dynamics over extended interactio - 此外,在ST块中,仅包含一个FFW在空间和时间组件之后,省略了post-spatial FFW,以便扩展模型的其他组件(we include only one FFW after both spatial and temporal components, omitting the post-spatial FFW to allow for scaling up other components of the model)
2.2 三个关键组件:视频Tokenizer、潜在动作模型LAM、动态模型
Genie 包含三个关键组件,如下图所示
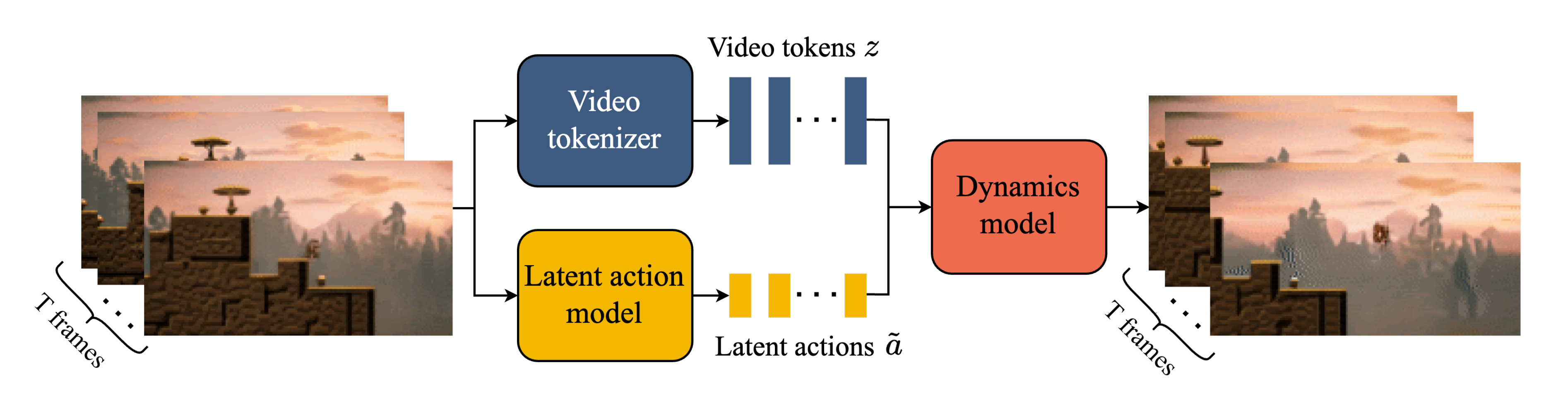
- 视频Tokenizer,用于将原始视频的一系列帧转换为离散 token 𝒛;
- 潜在动作模型(Latent Action Model,LAM),用于推断每对帧之间的潜在动作𝒂
- 一个自回归动力学模型MaskGIT,用于在给定潜在动作和过去帧 token的情况下,预测视频的下一帧
2.2.1 视频Tokenizer:基于ST-ViViT编码
在之前研究的基础上,谷歌将视频压缩为离散 token,以降低维度并实现更高质量的视频生成。实现过程中,谷歌使用了 VQ-VAE,其将视频的 𝑇 帧作为输入,从而为每个帧生成离散表示:
,其中𝐷 是离散潜在空间大小。分词器在整个视频序列上使用标准的 VQ-VQAE 进行训练

与之前专注于仅在Tokenizer阶段进行空间压缩的工作不同
- Genie在编码器和解码器中都使用了ST-transformer来融入时间动态,从而提高了视频生成质量
Unlike prior works that focus on spatial-only compression in the tokenization phase, we utilize the ST-transformer in both the encoder and decoder to incorporate temporal dynamics in the encodings, which improves the video generation quality
由于ST-transformer的因果性质,每个离散编码包含了视频
中所有先前帧的信息
By the causal nature of the STtransformer, each discrete encoding 𝑧𝑡 contains information from all previously seen frames of the video 𝒙1:𝑡 . - Phenaki也使用了一种具有时间感知的分词器C-ViViT,但这种架构的计算成本随着帧数的增加呈二次增长
Phenaki (Villegas et al., 2023) also uses a temporal-aware tokenizer, C-ViViT, but this architecture is compute intensive, as the cost grows quadratically with the number of frames
相比之下,我们基于ST-transformer的tokenizer(ST-ViViT)在计算效率上更高,其成本的主导因素呈线性增长
in comparison, our ST-transformer based tokenizer (ST ViViT) is much more compute efficient with the dominating factor in its cost increasing linearly
2.2.2 潜在动作模型LAM:也基于ST-transformer实现
为了实现可控的视频生成,谷歌将前一帧所采取的动作作为未来帧预测的条件。然而,此类动作标签在互联网的视频中可用的很少,并且获取动作注释的成本会很高。相反,谷歌以完全无监督的方式学习潜在动作

- 首先,编码器将所有先前的帧
以及下一帧
作为输入,并输出相应的一组连续的潜在动作
First, an encoder takes as inputs all previous frames 𝒙1:𝑡 = (𝑥1, · · · 𝑥𝑡) as well as the next frame 𝑥𝑡+1, and outputs a corresponding set of continuous latent actions ˜𝒂1:𝑡 = (˜𝑎1, · · · ˜𝑎𝑡). - 然后,解码器将所有先前的帧
作为输入,并预测下一帧
A decoder then takes all previous frames and latent actions as input and predicts the next frame 𝑥ˆ𝑡+1
为了训练模型
- 我们利用了基于VQ-VAE的目标函数,这使我们能够将预测的动作数量限制在一个小的离散代码集合中。 我们将VQ codebook的词汇大小(如果你不了解什么是VQ codebook,请参见此文的1.2.3节VAE的改进:VQ-VAE/VQ-VAE2),即可能的潜在动作的最大数量,限制在一个小的值上,以便实现人类可玩性并进一步强制可控性(在我们的实验中,我们使用了| 𝐴 | = 8)
To train the model, we leverage a VQ-VAEbased objective, which enables us to limit the number of predicted actions to a small discrete set of codes. We limit the vocabulary size |𝐴| of the VQ codebook, i.e. the maximum number of possible latent actions, to a small value to permit human playability and further enforce controllability (use |𝐴| = 8 in our experiments) - 由于解码器只能访问历史记录和潜在动作,
应该编码过去和未来之间最有意义的变化,以便解码器能够成功重构未来的帧(As the decoder only has access to the history and latent action, ˜𝑎𝑡 should encode the most meaningful changes between the past and the future for the decoder to successfully reconstruct the future frame)
2.2.3 动力学模型:仅解码的MaskGIT Transformer
动力学模型是一个仅解码的MaskGIT transformer

- 在每个时间步
,它接收分词视频
和停止梯度的潜在动作
,并预测下一个帧token
At each time step 𝑡 ∈ [1, 𝑇], it takes in the tokenized video 𝒛1:𝑡−1 and stopgrad latent actions ˜𝒂1:𝑡−1 and predicts the next frame tokens ˆ𝑧𝑡 - 我们再次使用ST-transformer,其因果结构使我们能够使用所有
帧
和潜在动作
作为输入,并为所有下一个帧生成预测
,该模型通过预测token
之间的交叉熵损失进行训练
We again utilize an ST-transformer,whose causal structure enables us to use tokens from all (𝑇 − 1) frames 𝒛1:𝑇 −1 and latent actions ˜𝒂1:𝑇 −1 as input, and generate predictions for all next frames ˆ𝒛2:𝑇 . The model is trained with a cross entropy loss between the predicted tokens ˆ𝒛2:𝑇 and ground-truth tokens 𝒛2:𝑇 . - 在训练时,我们根据均匀采样的伯努利分布掩盖率随机屏蔽输入token
,掩盖率在0.5和1之间
At train time we randomly mask the input tokens 𝒛2:𝑇 −1 ac-cording to a Bernoulli distribution masking rate sampled uniformly between 0.5 and 1.
请注意,训练世界模型的常见做法,包括基于transformer的模型,是将时间 𝑡的动作连接到相应的帧上,然而,他们发现将潜在的行动作为additive embeddings来处理,对于潜在的行动和动力学模型都有助于提高生成的可控性
Note that a common practice for training world-models, including transformer-based models, is to concate- nate the action at time 𝑡 to the corresponding frame (Micheli et al., 2023; Robine et al., 2023).
However, we found that treating the latent actions as additive embeddings for both the latent action and dynamics models helped to improve the controllability of the generations
2.3 Genie 的推理过程
如下图所示

- 图像使用视频编码器进行token,得到
(The image is tokenized using the video encoder,yielding 𝑧1)
- 然后玩家通过选择
中的任意整数来指定一个离散的潜在行动
值
The player then specifies a discrete latent action 𝑎1 to take by choosing any integer value within [0, | 𝐴|). - 动力学模型接收帧token
,通过使用离散输入
。这个过程重复进行,以自回归方式生成序列的其余部分
The dynamics model takesthe frame tokens 𝑧1 and corresponding latent ac-tion ˜𝑎1, which is obtained by indexing into the VQ codebook with the discrete input 𝑎1, to predict the next frame tokens 𝑧2. This process is repeated to generate the rest of the sequence ˆ𝒛2:𝑇 in an au-toregressive manner as actions continue to be passed to the model, while tokens are decoded into video frames ˆ𝒙2:𝑇 with the tokenizer’s de-coder.
注意,我们可以通过向模型传递起始帧和从视频中推断出的动作来重新生成数据集中的真实视频,或者通过更改动作来生成全新的视频
Note that we can regenerate ground truth videos from the dataset by passing the model the starting frame and inferred actions from the video, or generate completely new videos (or tra-jectories) by changing the action
// 待更
参考文献与推荐阅读
- 刚刚,谷歌发布基础世界模型:11B参数,能生成可交互虚拟世界
- ..