机器学习流程—数据预处理上篇
机器学习流程—数据预处理上篇
数据清洗因为它涉及识别和删除任何丢失、重复或不相关的数据。数据清理的目标是确保数据准确、一致且无错误,因为不正确或不一致的数据会对 ML 模型的性能产生负面影响。专业数据科学家通常会在这一步投入大量时间,因为他们相信Better data beats fancier algorithms。
我们可以再次看一下我们整个机器学习的流程,当然我们这里将一些过程合并了,提取出来了这么六个环节
’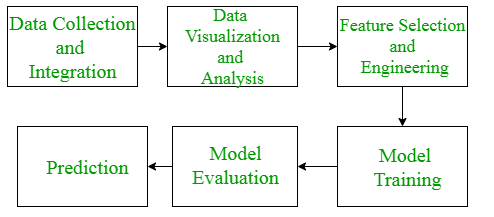
我们完整的一个机器学习的步骤包括下面的环节
- 定义问题:确定您想要解决的问题并确定是否可以使用机器学习来解决它。
- 收集数据:收集并清理将用于训练模型的数据。模型的质量将取决于数据的质量。
- *探索数据:*使用数据可视化和统计方法来了解数据中的结构和关系。
- 预处理数据:根据需要对数据进行规范化、转换和清理,为建模准备数据,也就是特征工程
- 拆分数据:将数据分为训练数据集和测试数据集以验证您的模型。
- 选择模型:选择适合您的问题和您收集的数据的机器学习模型。
- *训练模型:*使用训练数据训练模型,调整其参数以尽可能准确地拟合数据。
- *评估模型:*使用测试数据评估模型的性能并确定其准确性。
- *微调模型:*根据评估结果,通过调整模型参数并重复训练过程来微调模型,直到达到所需的准确度。
- *部署模型:*将模型集成到您的应用程序或系统中,使其可供其他人使用。
- *监控模型:*持续监控模型的性能,以确保它随着时间的推移继续提供准确的结果。
这些工作流程主要是工程实践上总结出的一些经验。并不是每个项目都包含完整的一个流程。这里的部分只是一个指导性的说明,只有大家自己多实践,多积累项目经验,才会有自己更深刻的认识。
定义问题
这里我们需要说明一下,虽然这里我们讲的是数据预处理,但是我们这里为了更加充分的理解我们后面的数据预处理,这里我们说明一下我们要解决什么样的问题,也就是定义问题。
itanic数据集作为kaggle比赛中的经典数据集,今天我们使用的数据也是这个数据集,这个数据集描述的主要是泰坦尼克号邮轮上乘客的数据,我们要做的事情就是根据乘客的数据预测乘客在泰坦尼克号沉没的时候时候可以活下来。
数据预处理
接下来我们看一下数据预处理的流程,数据预处理的前提是我们已经收集到数据了,这个环节的一些操作其实没有太多顺序上的要求,只要我们保证处理后的数据是符合我们要求的即可,这里的要求可以参考这几个标准,完整的,没有缺失值的,一致的,都是和业务相关的。
数据加载与展示
import pandas as pd
import numpy as np# Load the dataset
path ='D:\\代码\\ml-base\jupyter\\ML\\dataset\\'
df = pd.read_csv(path+'titanic.csv')
df.head()
数据大致如下

- PassengerId(乘客ID)
- Name(姓名)
- Ticket(船票信息)存在唯一性
- Survived(获救情况)变量为因变量,其值只有两类1或0,代表着获救或未获救
- Pclass(乘客等级)
- Sex(性别)
- Embarked(登船港口)是明显的类别型数据,
- Age(年龄)
- SibSp(堂兄弟妹个数)
- Parch(父母与小孩的个数);
- Fare(票价);
- Cabin(船舱);
重复数据处理
重复数据处理的方式其实很简单,直接删除就行了,因为重复数据对我们的分析没有意义,但是我们需要去搞清楚数据为什么重复了能不能从源头上避免
df.duplicated().value_counts()
可以看到,统计值都是False 也就是说没有重复的,如果有True 就说明有重复的

value_counts() 其实就是统计不同值的个数,等价于GROUP BY,如果有重复的,我们直接运行下面的代码删除重复数据就可以了
df.drop_duplicates()
数据类型
因为我们无法很直观的从上一步的结果中获取数据类型,而且有时候有的数值型会因为某些原因导致在pandas中被认为是字符串
df.dtypes
我们可以通过dtypes 查看每一列的数据类型
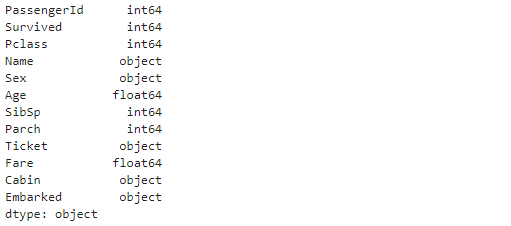
如果数据类型没有问题,我们可以数值类型和字符类型进行区分,方便我们后面的数据探索,因为我们对于数值类型可能会查看有没有异常值,对于字符类型可能会查看数据的分类统计情况
# Categorical columns
cat_col = [col for col in df.columns if df[col].dtype == 'object']
print('Categorical columns :',cat_col)
# Numerical columns
num_col = [col for col in df.columns if df[col].dtype != 'object']
print('Numerical columns :',num_col)

其实这里我们注意到一个问题那就是PassengerId 是数值型的,但是其实这个数值型对我们的分析没有意义
空值处理
其实处理之前,我们需要知道空值的分布情况,我们可以使用df.isnull() 来获取每个值是不是空值
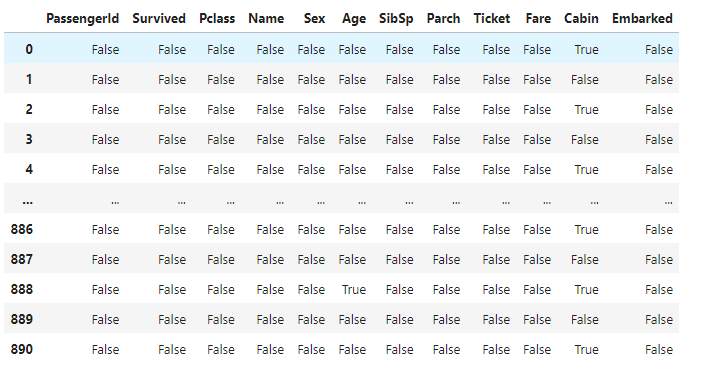
然后我们可以基于上面的数据进行统计,这里我们可以使用.sum() 函数进行统计,对于False 而言,在求和的时候值是0,True 是一,这样我们得到的就是空值的数量,这里不能使用count,因为True 和Flase 都会被count 统计到,也就是无法区分
df.isnull().sum()
其实这里我们可以看到Age,Cabin 都存在大量的空值
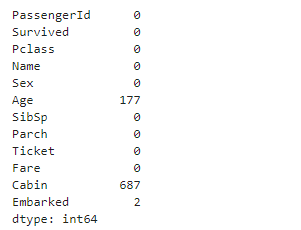
其实我们除了df.isnull().sum() 我们可以直接对df 进行count 操作,只不过算出来是非空的数量

我们看到Age,Cabin 的非空数量比其他字段的都少,也就是说这两个字段存在空值,有了个数其实看起来还是不够直观,这里我们可以使用百分比
round((df1.isnull().sum()/df1.shape[0])*100,2)
Cabin 的空值占比达到了77%

既然空值的分布已经知道了,接下来我们对空值进行处理,由于船舱Cabin缺失值太多,我们可以直接删除这一列,Embarked 存在着少量的空值,只有两条,在我们的样本中占比非常低,只有0.22%,所以我们删除这样的样本。
Age 在我们的样本中存在相对比较多的空值,而且我们预测年龄和我们需要预测的结果其实有比较大的联系,因为我们可以大致认为成年人的生存能力肯定是要大于小孩和老人的,也就是说获救的可能性比较大。
删除Cabin 列
df2 = df1.drop(columns='Cabin')
删除空值所在的行
df2.dropna(subset=['Embarked'], axis=0, inplace=True)
如果我们要是对只要有空值的列就进行删除,不加相关的参数即可
df2.dropna()
接下来我们补全Age 列,这里我们使用均值进行填充
# Mean imputation
df3 = df2.fillna(df2.Age.mean())
# 再次检查
df3.isnull().sum()
我们可以看到空值已经没了

无关特征删除
其实前面我们已经删除过一个特征了,也就是Cabin 列,这里其实我们从字段的定义都可以得知Name 和 Ticket ,`` 对我们的结果其实意义不大
df4 = df3.drop(columns=['Name','Ticket','PassengerId'])
数据分布
这里我们要预测的是乘客是否可以存活下来,所以我们已有数据数据的分布其实对我们来说很重要,如果我们要预测的数据存在严重的数据倾斜,例如某一类特别少,这个时候就会影响我们的预测,那我们这个时候就要考虑问题的定义是不是正确,或者要不要重新收集数据了。
这里我们主要看一下Survived的数据分布,value_counts() 我们前面解释过了,我们直接看结果
df['Survived'].value_counts()
我们看到1 也就是获救的人数是342 ,未获救的是549
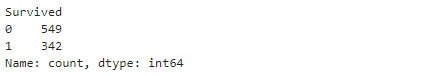
我们其实可以画个饼图,更加直观的看看,尤其当分类多的时候,因为我们这里就只有两类
#导入数据可视化所需要的库
import matplotlib.pyplot as plt # Matplotlib – Python画图工具库
plt.pie(x=df['Survived'].value_counts(),labels=Survived.index,autopct='%.2f%%')
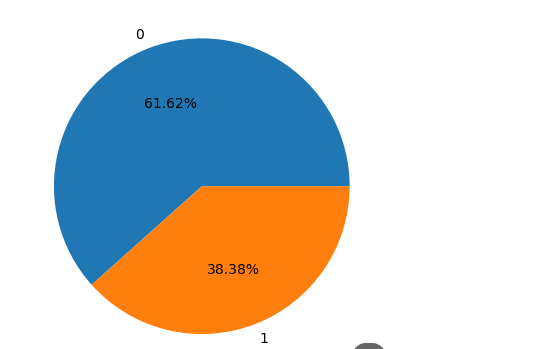
其实可以看到我们的数据没有存在严重的倾斜,也就是说我们的样本分布还算均匀。
其实除了上面的方式,我们还可以使用describe() 方法,这个方法可以返回数据的个数,均值,最大值,最小值,以及分位数
df.describe()
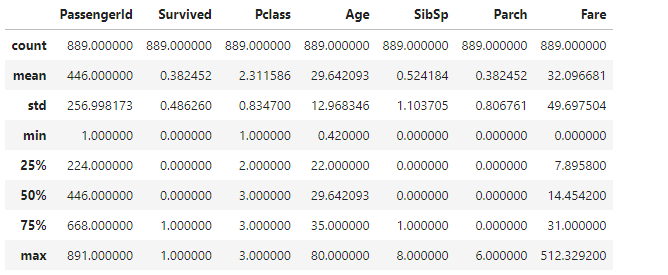
删除异常值
异常值对我们的模型影响很大,严重影响我们模型预测的精度,这里我们看一下异常值如何处理,其实我们处理的方式是比较简单的,就是直接删除,或者使用其他值进行填充,例如平均值。
主要的问题是如何发现异常值,这里我们使用的方式有两种,一种是看统计数据,一种是以图的方式进行展现观察,看统计数据我们前面已经说过了,就是使用describe() 方法
第二种方式我们可以使用箱线图进行观察
#导入数据可视化所需要的库
import matplotlib.pyplot as plt # Matplotlib – Python画图工具库
plt.boxplot(df3[num_col],labels=num_col)
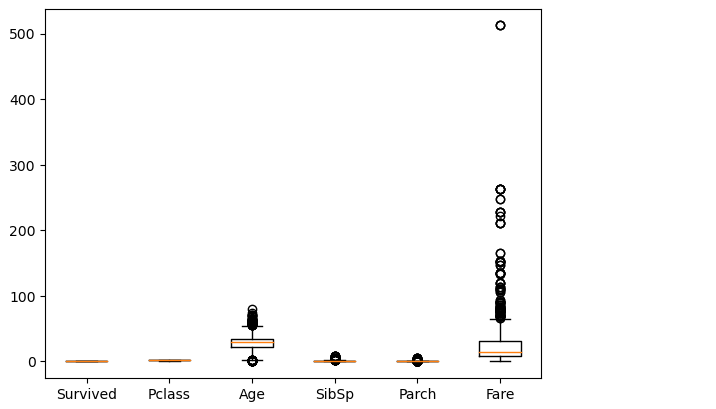
箱线图是由五个数值点组成,分别是最小值 (min)、下四分位数 (Q1)、中位数 (median)、上四分位数 (Q3) 和最大值 (max)。在统计学上,这叫做五数概括。这五个数值可以清楚地为我们展示数据的分布和离散程度。
我们可以看到从图上看的话,我们的Fare 和Age 可能存在异常值,其实这里有个问题就是我们数值类型有的列的范围可能很大,有的列很小,所以不适合放在一起展示,所以你可以单独使用
plt.boxplot(df3['Fare'])
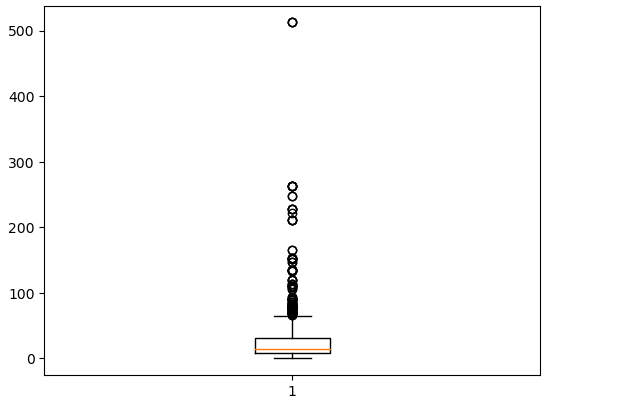
或者是针对不同类别的的数据进行使用,例如这里我想看一下在Survived 分别是0 和 1 的情况下,年龄的分布
import seaborn as sns # Seaborn – 统计学数据可视化工具库
sns.boxplot(x='Survived', y="Age", data=df3) # 用seaborn的箱线图画图
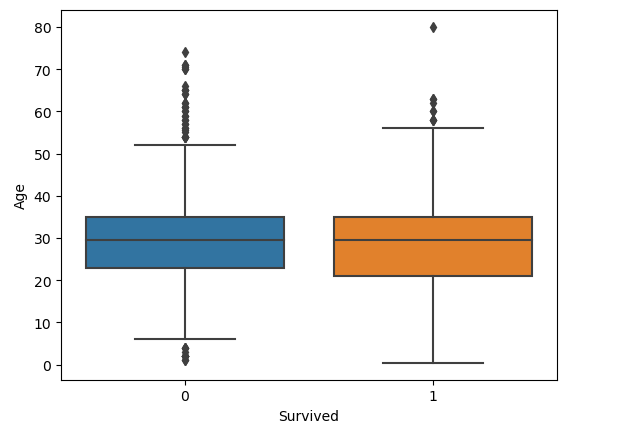
这里我们看到没有明显的差别,这里我们可以使用下面的代码删除可能存在的异常值
# calculate summary statistics
mean = df3['Age'].mean()
std = df3['Age'].std()# Calculate the lower and upper bounds
lower_bound = mean - std*2
upper_bound = mean + std*2print('Lower Bound :',lower_bound)
print('Upper Bound :',upper_bound)# Drop the outliers
df4 = df3[(df3['Age'] >= lower_bound) & (df3['Age'] <= upper_bound)]
生成标签和特征
对于监督学习,这里我们将数据集里的特征和标签进行提取,这里Y 就是标签,也就是后面模型需要预测的值,X 就是特征
X = df4[['Pclass','Sex','Age', 'SibSp','Parch','Fare','Embarked']]
Y = df4['Survived']
归一化或者标准化
数据的归一化和标准化是特征缩放(feature scaling)的方法,是数据预处理的关键步骤。不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据归一化/标准化处理,以解决数据指标之间的可比性。
机器学习中有部分模型是基于距离度量进行模型预测和分类的。由于距离对特征之间不同取值范围非常敏感,所以基于距离读量的模型是十分有必要做数据标准化处理的。
另外,线性回归类的几个模型一般情况下也是需要做数据标准化处理的。逻辑回归、决策树、基于决策树的Boosting和Bagging等集成学习模型对于特征取值大小并不敏感。所以这类模型一般不需要做数据标准化处理。
归一化/标准化实质是一种线性变换,线性变换有很多良好的性质,这些性质决定了对数据改变后不会造成“失效”,反而能提高数据的表现,这些性质是归一化/标准化的前提。
归一化一般是将数据映射到指定的范围,用于去除不同维度数据的量纲以及量纲单位。常见的映射范围有 [0, 1] 和 [-1, 1] ,最常见的归一化方法就是 Min-Max 归一化。
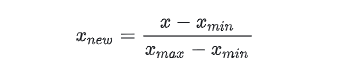
其中max为样本数据的最大值,min为样本数据的最小值。这种归一化方法比较适用在数值比较集中的情况。但是,如果max和min不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定,实际使用中可以用经验常量值来替代max和min。而且当有新数据加入时,可能导致max和min的变化,需要重新定义。
标准化是依照特征矩阵的列处理数据。数据标准化方法有多种,如:直线型方法(如极值法、标准差法)、折线型方法(如三折线法)、曲线型方法(如半正态性分布)。不同的标准化方法,对系统的评价结果会产生不同的影响。其中,最常用的是Z-Score 标准化。
这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,转化函数为:
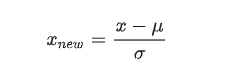
其中分子是样本数据的均值(mean),分母是样本数据的标准差(std)。此外,标准化后的数据保持异常值中的有用信息,使得算法对异常值不太敏感,这一点归一化就无法保证。