大语言模型系列-GPT-2
文章目录
- 前言
- 一、GPT-2做的改进
- 二、GPT-2的表现
- 总结
前言
《Language Models are Unsupervised Multitask Learners,2019》
前文提到,GPT-1利用不同的模型结构微调初步解决了多任务学习的问题,但是仍然是预训练+微调的形式,GPT-1在未经微调的任务上有一定效果(zero-shot ),但是其泛化能力远远低于经过微调的有监督任务,GPT-2主要基于该点进行了改进。
ps:GPT1:发现预训练模型具有 zero-shot 的能力,并且能随着预训练的进行不断增强。为了进一步验证 zero-shot 的能力,OpenAI 在 GPT-1 提出一年后,推出了 GPT-2。
GPT-2的目标旨在训练一个泛化能力更强的词向量模型,它并没有对GPT-1的网络进行过多的结构的创新与设计,只是使用了更多的网络参数(1.5B)和更大的数据集。
GPT-2 的核心思想就是,当模型的容量非常大且数据量足够丰富时,仅仅靠语言模型的学习便可以完成其他有监督学习的任务,不需要在下游任务微调。即为多任务学习,和T5类似。
也就是说所有的有监督学习都是无监督语言模型的一个子集。例如当模型训练完“Micheal Jordan is the best basketball player in the history”语料的语言模型之后,便也学会了(question:“who is the best basketball player in the history ?”,answer:“Micheal Jordan”)的Q&A任务。
few-shot:在模型做预测的时候,给模型少量标注后的优质样本来作为条件。(如GPT-3)
one-shot:和few-shot类似,但是只允许看到一个样本。
zero-shot:和one-shot类似,但是不允许看到任何样本。直接做预测。(如GPT-2)
ps:few-shot、one-shot、zero-shot均在推理输入阶段起作用,不会更新梯度,举例如下:
- few-shot:“这个任务要求将中文翻译为英文。你好->hello,再见->goodbye,购买->purchase,销售->”
- one-shot:“这个任务要求将中文翻译为英文。你好->hello,销售->”
- zero-shot:“这个任务要求将中文翻译为英文。销售->”
一、GPT-2做的改进
- 去掉了fine-tuning层: 不再针对不同任务分别进行微调建模,即不定义这个模型应该做什么任务,模型自动识别需要做什么任务。就像T5的text to text。
- Larger Dataset: WebText,GPT-2收集了更加广泛、数量更多的语料组成数据集。该数据集包含800万个网页,大小为40G
- Larger Model: GPT-2将Transformer堆叠的层数从12层增加到48层,隐层的维度为1600,参数量达到了15亿(Bert的参数量3亿、T5参数量110 亿)。
- Larger dictionary,larger sequnece length and larger batch size。 GPT-2将词汇表数量增加到50257个;最大的上下文大小 (context size) 从GPT的512提升到了1024 tokens;batchsize增加到512。
- 调整LN层:将layer normalization放到每个sub-block之前,并在最后一个Self-attention后再增加一个layer normalization。
- 初始化:修改初始化的残差层权重,维缩放为原来的 1 / N 1/ \sqrt N 1/N,其中N是残差层的数量。
二、GPT-2的表现
- 在8个语言模型任务中,仅仅通过zero-shot学习,GPT-2就有7个超过了state-of-the-art的方法;
- 在“Children’s Book Test”数据集上的命名实体识别任务中,GPT-2超过了state-of-the-art的方法约7%;
- “LAMBADA”是测试模型捕捉长期依赖的能力的数据集,GPT-2将困惑度从99.8降到了8.6;
- 在阅读理解数据中,GPT-2超过了4个baseline模型中的三个;
- 在法译英任务中,GPT-2在zero-shot学习的基础上,超过了大多数的无监督方法,但是比有监督的state-of-the-art模型要差;
- GPT-2在文本总结的表现不理想,但是它的效果也和有监督的模型非常接近。
总结
先看一下GTP2在不同数据集上的精度:
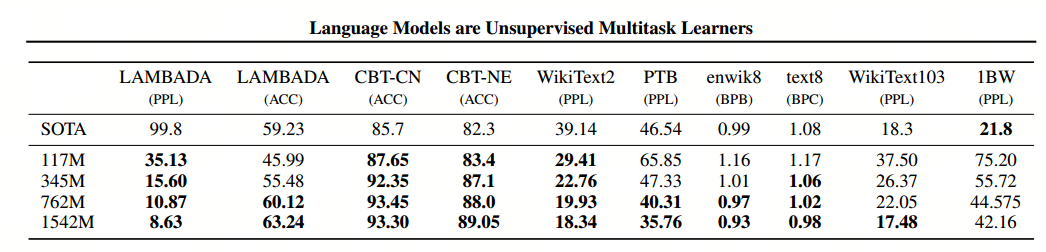
ps:模型精度指标:
- PPL(Perplexity,困惑度):在自然语言处理中,语言模型的任务是对给定的文本序列进行概率估计,即根据先前的单词预测下一个单词的概率。困惑度提供了一个衡量语言模型对给定文本序列预测的不确定性程度的度量。
具体来说,困惑度是对模型在给定数据集上的概率分布进行评估的指标。在一个给定的文本序列上,困惑度是一个标量值,表示模型对该序列的预测的平均困惑程度,即模型认为该序列所对应的概率的逆数。困惑度越低,表示模型在给定的序列上的预测越准确,模型对数据集的拟合程度越好。
即, P P L = 2 H ( P , Q ) PPL=2^{H(P,Q)} PPL=2H(P,Q), H ( P , Q ) = − ∑ x P ( x ) l o g Q ( x ) H(P,Q)=-\sum_xP(x)logQ(x) H(P,Q)=−∑xP(x)logQ(x),预测序列Q和真实序列P- ACC(Accuracy,准确率):衡量模型在指定任务上(完形填空任务、文本分类任务等)的准确率。
- BPC(Bits Per Character,每字符比特数):BPC 是一种衡量模型性能的指标,用于评估模型生成文本的效率和质量。BPC 衡量了模型生成的文本与真实文本之间的差异,其计算方式通常是使用交叉熵损失(Cross Entropy Loss)除以每个字符的比特数。这个值越低,表示模型生成的文本越接近真实文本,模型的性能越好。


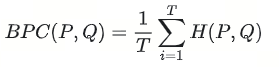
ps:数据集解释:
- LAMBADA:LAMBADA是一个用于语言模型评估的数据集,其中包含了来自小说文本的句子。任务是给定前文并要求模型预测下一个单词,但这些句子在结尾处被截断,要求模型在没有上下文线索的情况下进行预测。即英文完形填空模式:
- CBT-CN 和 CBT-NE:CBT(Children’s Book Test)是一个用于测试机器阅读理解的数据集,由Facebook于2016年提出。任务是从一本儿童读物中选出21个连续的句子。然后,将前20个句子视为上下文,然后推断第21个句子中缺少的单词。CBT-CN(Children’s Book Test-Chinese)和CBT-NE(Children’s Book Test-Natural Language Explanation)是CBT的中文版本和自然语言解释版本。
- WikiText2 和 WikiText103:WikiText是从维基百科收集的用于语言模型预训练和评估的数据集。WikiText2是包含较小语料库的版本,而WikiText103是包含较大语料库的版本。(其中的文本被用来训练模型以预测下一个单词或字符,即在给定先前的文本序列后预测下一个单词或字符的概率。)
- PTB(Penn Treebank):PTB是一个常用的用于语言建模和序列预测任务的数据集,包含了华尔街日报的文章。
- enwik8 和 text8:这是两个常用的用于字符级别语言建模任务的数据集。enwik8是维基百科的一个子集,而text8是enwik8的一个更小的子集,用于快速训练和评估模型。
- 1BW:1BW是一个用于预训练语言模型的数据集,包含来自互联网的多语言文本,总计约10亿字节。
