超短代码实现!!基于langchain+chatglm3+BGE+Faiss创建拥有自己知识库的大语言模型(持续更新)本人python版本3.11.0 windows环境
前言
众所周知,大语言模型在落地应用时会遇到各种各样的问题。而其中模型的“致幻性”是非常可怕。目前主流之一的玩法就是通过知识库对回答范围进行限制。
项目介绍
本来想等langchain-ChatChat大佬们的0.3.0版本。等待是折磨的,那不如在等待的时候,自己来瞎折腾玩玩。
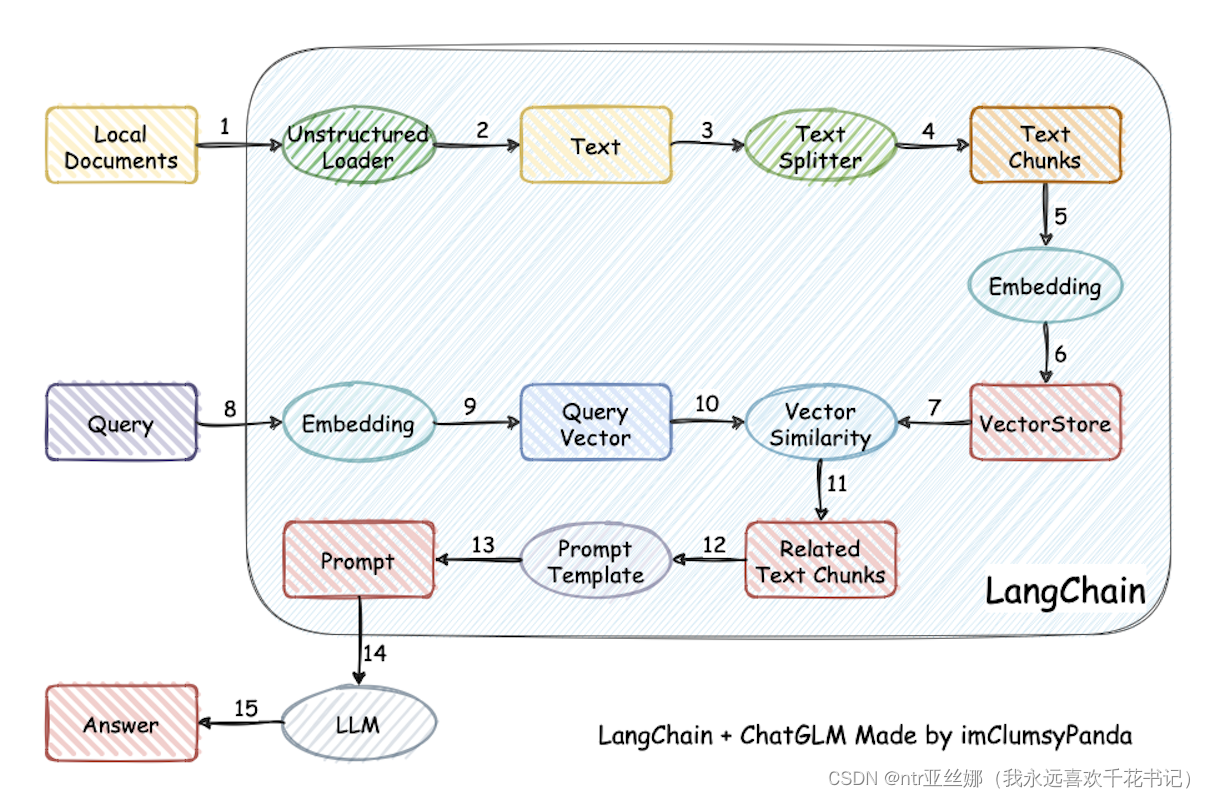
为了快速跑通,目前大家比较喜欢的就是用langchain来把Embedding模型和向量数据库和LLM模型串联起来。借用清华的图片,就像下面这样:
安装依赖
本人python版本3.11.0
transformers
langchain-community
unstructured
faiss-cpu
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple langchain-community unstructured faiss-cpu
代码
1.通过embedding模型和Faiss对输入语句和知识库内容匹配
from langchain_community.document_loaders import UnstructuredFileLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.embeddings import HuggingFaceBgeEmbeddings
from langchain_community.vectorstores import FAISS# 文件路径
file_path = '资料文件路径'# 加载文档
loader = UnstructuredFileLoader(file_path=file_path)
docs = loader.load()# 按字符分割文档
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=200)
docs = text_splitter.split_documents(docs)# 加载预训练的句子嵌入模型
model_name = "embedding模型路径"
model_kwargs = {"device": "cuda"}
encode_kwargs = {"normalize_embeddings": True}
embeddings = HuggingFaceBgeEmbeddings(model_name=model_name, model_kwargs=model_kwargs, encode_kwargs=encode_kwargs
)
vector_store = FAISS.from_documents(docs, embeddings)query = "提出你的问题"docs = vector_store.similarity_search(query, k=5)
context = [doc.page_content for doc in docs]prompt = f'根据以下内容:\n{context}\n,回答用户的问题:\n{query}\n'
print(prompt)
2.生成的prompt导入LLM模型(本文以glm3为例)
from transformers import AutoTokenizer, AutoModel
import os
current_length = 0
past_key_values, history = None, []
for response, history, past_key_values in model.stream_chat(tokenizer, prompt, history=history, top_p=1,temperature=0.01,past_key_values=past_key_values,return_past_key_values=True):print(response[current_length:], end="", flush=True)current_length = len(response)
print("")
3.报错
raise pickle.UnpicklingError(UNSAFE_MESSAGE + str(e)) from None
_pickle.UnpicklingError: Weights only load failed. Re-runningtorch.loadwithweights_onlyset toFalsewill likely succeed, but it can result in arbitrary code execution.Do it only if you get the file from a trusted source. WeightsUnpickler error: [enforce fail at C:\cb\pytorch_1000000000000\work\c10\core\impl\alloc_cpu.cpp:72] data. DefaultCPUAllocator: not enough memory: you tried to allocate … bytes.
其实就是显存爆了,毕竟embedding也是吃显存的,这再加个glm模型,12G显存不炸才怪。
待更新~