论文导读:消费级大模型Yi (零一万物技术揭密)
零一万物最新发布的技术报告
论文:Yi: Open Foundation Models by 01.AI(https://arxiv.org/pdf/2403.04652.pdf)
公众号阅读:

摘要
我们介绍了Yi模型家族,这是一系列展示出强大多维能力的自然语言和多模态模型。Yi模型家族基于6B和34B预训练语言模型,然后我们将其扩展到聊天模型、20万长上下文模型、深度扩展模型和视觉-语言模型。我们的基础模型在MMLU等广泛基准测试上取得了强大的性能,而我们的微调聊天模型在AlpacaEval和Chatbot Arena [wangxd注:Ilya Sutskever在他的twitter上发帖表示他只认可这个榜单。大模型厂商刷榜太凶。] 等主要评估平台上提供了高人类偏好率。基于我们可扩展的超级计算基础设施和经典的transformer架构,我们将Yi模型的性能主要归因于我们数据工程努力所产生的数据质量。对于预训练,我们使用级联数据去重和质量过滤管道构建了3.1万亿个英文和中文语料库的标记。对于微调,我们在多轮迭代中打磨了一个小型(少于10K)指令数据集,以便每个实例都直接由我们的机器学习工程师验证。对于视觉-语言模型,我们将聊天语言模型与视觉transformer编码器结合,并训练模型使视觉表示与语言模型的语义空间对齐。我们通过轻量级继续预训练进一步将上下文长度扩展到20万,并展示了强大的大海捞针检索性能。我们展示了通过继续预训练扩展预训练检查点的深度可以进一步提高性能。我们相信,鉴于我们目前的成果,继续使用彻底优化的数据来扩展模型参数将导致更强的前沿模型。[wangxd注:(1)在规模上:和moonshot杨植麟信仰的第一性原理彻底的Scaling Law观点基本一致,scaling数据,scaling参数,sacling算力,sacling用户。(2)但是从本文看Yi更强调数据的质量,因此一个超强的数据清洗系统和数据工程至关重要用以确保数据质量。(3)彻底优化数据(提质增量)、持续扩展参数,是催生更强大模型的不二法门]
1 引言
近期在大语言模型方面的突破彻底改变了整个人工智能领域,并可能辐射到整个人类社会。我们对大语言模型的愿景是将它们打造成为下一代计算平台,并赋予整个社区显著增强的智能。作为实现这一使命的一步,我们推出了Yi模型系列,包括6B和34B语言模型,这些模型是在3.1T高度工程化的大量数据上从头开始预训练,并在少量但精心打磨的对齐数据上进行微调。由于我们大量的工程努力所带来的数据质量,我们将在接下来的章节中详细说明,Yi模型实现了接近GPT-3.5的基准分数和人类偏好。
在设计Yi模型系列时,我们主要关注以下几个方面:模型规模、数据规模和数据质量:
(1)在选择模型规模时,我们希望模型足够小,能够在消费级硬件上进行推理,如RTX 4090,其限制因素是其有限的24G内存,同时仍然足够大,具有复杂的推理和涌现能力。这就是为什么我们发现34B提供了良好的性能成本平衡;
(2)由于34B小于Chinchilla [30]和LLaMA [77]通常使用的70B,我们增加了预训练数据规模到3.1T tokens,以补偿减少的计算浮点运算。这使得模型-数据规模组合进入了后Chinchilla最优状态[64],我们在比计算最优(大约1T)更多的tokens(3T)上过度训练模型。好处在于推理方面,因为我们在int4 [81]量化后,可以在24G GPU内存上几乎不损失性能地提供34B聊天模型;
(3)我们的数据工程原则是在预训练和微调中都强调质量优于数量。预训练数据质量由复杂的数据清洗管道保证,该管道包括级联的过滤方法,并有意增强了去重强度;
(4)对于微调数据,我们通过基于用户反馈的多次迭代手工制作不到10K条指令,强调质量。这种方法与FLAN [9]和UltraChat [19]等以数量扩展为导向的指令调整工作显著不同,但更符合LIMA [94]等手工制作风格的作品。
我们的预训练数据清洗系统具有一个复杂的过滤管道,基于语言、启发式文本特征、困惑度、语义、主题和安全性,以及基于段落、MinHash和精确匹配的级联去重过程。这个彻底的管道比现有的CCNet [80]、RefinedWeb [56]和RedPajama [13]等管道有更高的移除比率,我们认为这是数据工程成功的关键。其背后的原理是,尽管预训练需要数据扩展,但我们希望确保使用的数据是高质量的,而不是在大量原始数据上训练模型,即我们更倾向于在没有广泛过滤的情况下,选择3T tokens而不是10T tokens的复杂工程。关于模型架构,我们使用了标准的Transformer架构实现,包括Grouped-Query Attention (GQA) [1]、SwiGLU [68]激活和调整基础频率的RoPE (RoPE ABF) [82]。这种设计选择是源自Transformer原始论文[78]的标准方法,后来由GPT-3和Chinchilla [30]修改,然后被LLaMA [77]、Baichuan [84]、Qwen [3]和许多相关工作跟随。
为了接近GPT-3.5匹配人类偏好,我们的微调数据集是从精心挑选的多轮指令-响应对中策划而来,由我们的机器学习工程师团队直接注释,然后在多次用户反馈迭代中进行打磨。如上所述,我们的微调数据集大小不到10K,但在模型开发时间线上不断改进。得益于数据集的可管理大小,我们进行了广泛的网格搜索,以确定最优的数据组成,促进多样性,并发现有效的超参数。
经过8位和4位量化后,最终的聊天模型可以在消费级GPU上部署,与bf16格式相比几乎没有性能下降。
我们从三个维度进一步扩展了Yi模型的能力:上下文扩展、视觉-语言适应和深度上扩展。为了实现200K的上下文长度,我们继续在大约5B长度上采样的数据上预训练模型,类似于Fu等人[22]的并行工作。为了使模型适应视觉-语言任务,我们集成了一个视觉编码器,并开发了一种多阶段训练方法,遵循并改进了Liu等人[47]的实践。我们还研究了深度上扩展[38]的有效性,即通过继续预训练使模型更深,并确认其有效性以进一步提高模型性能。
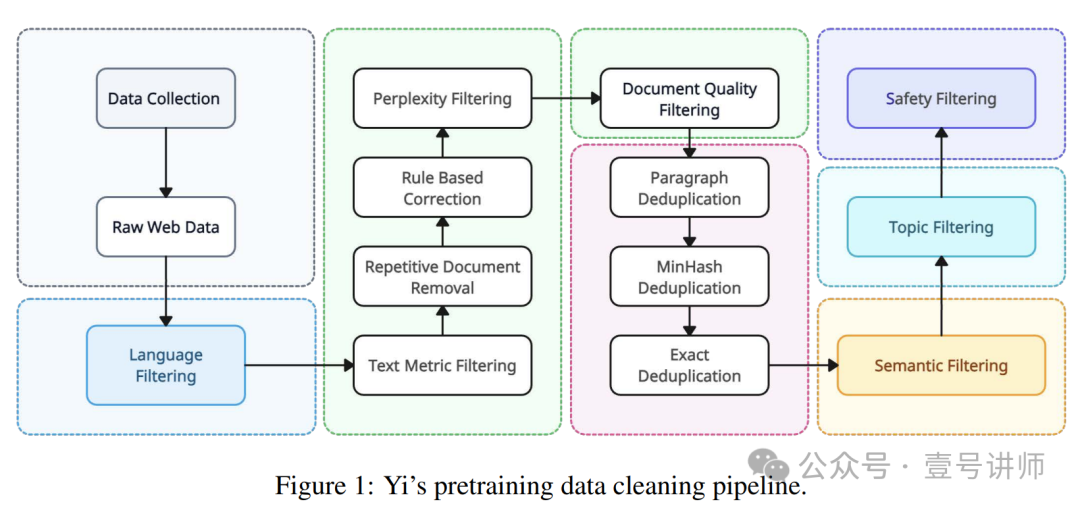
我们的基础设施为Yi模型系列的全栈开发提供了强有力的支持,从预训练到微调再到服务。
为了支持预训练,我们开发了跨云弹性任务调度、自动故障恢复和拓扑感知资源分配,这些共同使我们能够根据实时可用的GPU节点跨集群运行任务,且交换开销有限。为了支持微调,我们构建了一个支持不同模型(例如,政策模型使用Megatron [70],奖励模型使用DeepSpeed [60])的分层调度框架。
为了高效推理,我们使用了4位模型和8位KV缓存量化,结合了PagedAttention [41]和动态批处理。广泛的实验表明,Yi-34B在性能和效率上都能与GPT-3.5相匹配。在大多数标准基准测试中,如MMLU [27](用于基础模型)和LMSys ELO评分[93](用于聊天模型),Yi-34B通常能够与GPT-3.5取得相当的分数。在模型参数和KV缓存量化之后,推理成本也得到了控制,使得广泛的社区能够在成本效益高的设备上部署模型。我们进一步报告了Yi与主要大型语言模型在常识推理、大学考试、数学、编码、阅读理解以及在多个评估基准上的人类偏好胜率方面的详细性能比较。
自从Yi模型系列发布以来,它从以下几个方面惠及了社区:
(1)它为研究人员提供了与GPT-3.5相匹配的质量但成本效益更高的模型,并使开发人员能够构建像基于语言模型的智能体这样的AI原生应用;(2)它赋予了终端用户本地可运行的聊天机器人,从而有助于保护用户数据隐私;
(3)它为进一步的数据和模型扩展指明了方向,以实现更强的前沿模型,无论是研究还是商业用途。
2 预训练
我们的预训练方法是在大量精心设计的预训练语料库上训练标准的稠密transformer架构,我们的底层假设是,当在足够高质量的广泛数据上训练时,标准架构可以展现出先进的能力。这就是说,我们可能不需要太多的架构修改,尽管我们确实进行了广泛的初步架构实验。在以下的小节中,我们首先详细介绍我们的数据工程流程,然后简要讨论模型架构。[wangxd注:数据工程的依重度比模型工程更高]
2.1 数据处理
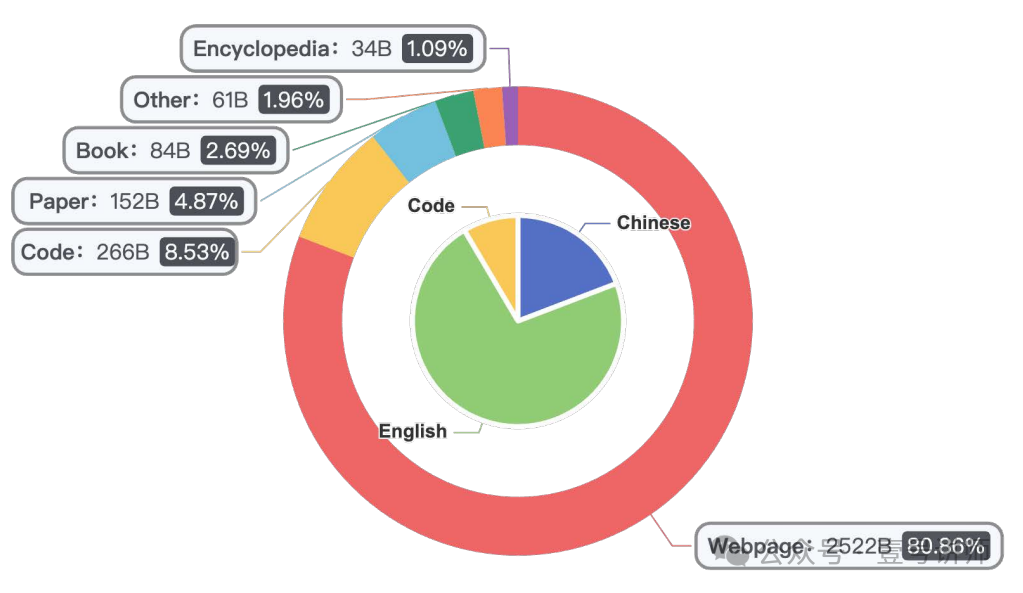
图2:Yi的预训练数据混合物。总的来说,我们的数据由3.1T高质量的tokens组成,包括英文和中文,来自各种来源。我们与现有的已知混合物(如LLaMA [76]和Falcon [56])的主要区别在于我们是双语的,并且由于我们更严格的清洗流程,质量更高。
Yi数据配比如图2所示。为了产生高质量的双语预训练数据,我们精心设计了一个级联数据处理流程,如图1所示。这个流程包括一系列针对质量和多样性的数据清洗策略。我们从Common Crawl的网络文档开始,使用CCNet管道[79]进行语言识别和困惑度评分。然后我们使用以下详细描述的过滤和去重过程。
启发式规则过滤器 这部分过滤器的目的是移除质量低的文本。我们基于以下标准过滤文本:(1)URL、域名、单词黑名单和乱码文本过滤器;(2)文档长度、特殊符号比例和短、连续或不完整的行的比例;(3)重复的单词、n-gram或段落[58];过滤阈值基于对大型文档样本的统计分析,如Nguyen等人[52]所述。此外,我们识别并匿名化个人身份信息(PII),如电子邮件地址和电话号码。
学习型过滤器 我们使用学习型过滤器来处理超出标准启发式规则能力的微妙情况。值得注意的是,从Common Crawl提取的中文内容提出了独特的挑战,尤其是不适当内容(如色情和赌博)的比例较高。传统的基于启发式规则的过滤器难以有效识别和消除所有有害内容。为了增强我们的过滤过程,我们集成了一系列用于过滤的学习型评分器,即困惑度评分器、质量评分器、安全评分器和文档连贯性评分器:
(1)困惑度评分器,利用KenLM库,如CCNet [80]所述,评估大量网络文档,丢弃那些困惑度得分远高于平均值的文档;
(2)质量评分器是一个训练有素的分类器,用于识别和偏爱质量类似于维基百科的页面,并相应地分配分数。未达到质量标准的文档随后被移除;
(3)文档连贯性评分器识别由不同句子或段落组成的低质量网络文档,因此缺乏连贯性。这类文档要么被分割以进行进一步分析,要么完全移除;
(4)安全评分器识别并移除包含有害内容的网络文档,如暴力、色情和政治宣传。
基于聚类的过滤器 我们进一步使用无监督语义聚类来对网络文档进行分组。这个聚类过程使得能够高效地识别和分析具有相似语义特征的文档。聚类数据随后被标注了质量标签,为优化Yi的数据混合物策略提供了必要的参考。通过自动和手动验证识别为低质量的文档被排除在数据集之外。
去重 在过滤之后,我们按照Penedo等人(2023)[56]的程序实施了一个全面的去重流程。这个流程整合了文档级别的MinHash去重和子文档精确匹配去重,有效地识别和移除文档内部和跨文档的重复内容。我们进一步使用主题模型将网络文档分类到特定的主题,预测标签如新闻、广告和基于知识的内容包括。在最终的预训练数据集中,我们对不太有帮助的内容(主要是广告)进行了下采样,以确保信息密度。Yi预训练数据的最终组成如图2所示。
2.2 分词
我们使用在SentencePiece框架[40]中实现的byte-pair encoding (BPE) [69]来对预训练数据进行分词。词表大小64,000,以平衡计算效率和词语理解。具体来说,我们将数拆分为单个数字,以便于更好地理解数值数据。我们允许罕见字符回退到unicode字节编码,以确保容错性。我们采用identity分词器,以避免将所有标点符号转换为半角格式。通常优先考虑英语的LLMs在其分词器中使用虚拟前缀(文本开头的空白字符),以泛化不同句子位置中的相同单词。我们不采用这种方法,因为即使在英语语境中,这种假设也并不总是成立,特别是对于以引号开头的句子,而且它在中文语境中也没有显示出积极效果。

2.3 模型架构
Yi使用了一个修改版的经典的仅解码器Transformer架构[78],代码基于LLaMA的[77]实现。主要参数设置总结在表1中。从LLaMA到Yi的修改进一步总结如下:
注意力机制 LLaMA 2只在其最大的70B模型上使用分组查询注意力(GQA)[1],而其7B和13B模型使用全注意力。我们在Yi-6B和Yi-34B中都融入了GQA。
GQA将查询头分成G组,在每组查询中共享单一的键和值头[1]。这种方法相比原始的多头注意力(MHA)[16, 57, 67],提供了训练和推理成本的大幅降低。我们在6B较小模型上应用GQA后,没有观察到性能下降。
激活函数 我们使用SwiGLU[68]作为Yi的后注意力层,将其激活大小从4h减少到8/3h(h表示隐藏大小),以与正常的后注意力层保持一致。这个调整也补偿了由于GQA导致的参数减少,使得整体参数数量与现有的7B和34B模型相当。
位置嵌入和长上下文 我们使用标准的旋转位置嵌入(RoPE)[73]。我们调整了基频率(RoPE ABF),这是Xiong等人[82]引入的,以支持长达200K的上下文窗口,而基础模型本身是在4K上下文长度上训练的。为了使基础模型适应更长的上下文,我们继续在预训练数据混合中对模型进行预训练,使用稍微上采样的长序列,主要来自书籍。我们观察到,只需要1-2B个tokens就足以让模型在4K-200K长度上收敛到低损失,而轻量级的微调进一步诱导近乎完美的长上下文检索性能。基于这一观察,我们倾向于认为,模拟比预训练长度(4K)更长的依赖关系的能力是一种内在能力(而不是通过后训练注入的)。这就是说,基础模型已经具备了模拟比4K更长依赖关系的能力,即使模型训练得更短,而后训练/微调过程只是释放了这种能力。
3 微调
我们的微调方法显著强调数据质量而非数量。我们的方法不遵循现有的数据密集型方法,如FLAN[9]和UltraChat[19],这些方法将SFT数据扩展到数百万条条目,但每个条目可能没有仔细检查,因为规模太大。相反,我们的方法与LIMA[94]和DEITA[48]的方法一致,它们专注于数据选择而非扩展。规模小于10K,我们能够检查和优化每一个数据点。下面我们讨论我们的数据构建和训练细节。[wangxd注:对行业垂直领域微调是个利好,不用太多量,量少而精]
3.1 数据预处理
质量是你需要的一切 我们的微调数据集包含不到10K个多轮指令-响应对话对,每一个条目都是经过多次迭代和用户反馈精心构建和打磨的。我们采取这种方法,因为在我们初步实验中,我们观察到,与数十万条开源数据相比,较小的、手动注释的数据集的结果更优越[wangxd注:对行业垂直领域微调是个利好,专而精的领域场景微调数据集的价值凸显] 。这些观察与Gemini Team等人[23],Touvron等人[77],Zhou等人[94]报告的一致。
我们使用以下技术来改进提示分布选择、响应格式化和思维链格式化:
(1)对于提示分布选择,受到WizardLM[83]的启发,我们开发了复合指令,并逐步发展它们以增加复杂性。这种方法显著减少了我们实验中的SFT数据量;
(2)对于响应格式化,我们通常使用从LIMA[94]扩展的默认风格。总体上,响应以引言-正文-结论的格式构建,其中正文通常是项目列表;
(3)对于CoT数据格式化,我们采用了“后退”模式,受到Zheng等人[92]的启发,通过执行抽象来制定更高层次的解决方案,然后再深入推理原始的、更具体的问题。
我们额外努力减少幻觉和重复:
(1)为了减少幻觉,我们检查并确保响应中的知识不包含在模型中,并消除可能导致记忆的响应;
(2)为了减少重复,我们重写了响应中通常存在但可能在微调数据中被忽视的重复轮次。
多样性和混合 为了确保不同能力的覆盖,我们包括了广泛的开源提示,涵盖问答、创意写作、对话、推理、数学、编程、安全、双语能力等领域。为了获得对不同能力方向的精细控制,受到InsTag[49]的启发,我们开发了一个指令标记系统。通过设计一个以多样性为中心的采样算法,我们仔细平衡了各种标签的指令分布。这种方法确保了一个多样化的微调数据集,旨在实现增强的跨任务鲁棒性。
为了实现平衡不同能力方向的最佳数据比例,我们使用近似网格搜索来确定我们的数据混合。受到Dong等人[20]的启发,这个过程涉及尝试{1, 1/2, 1/4, 1/8, 1/16, 1/32, 1/64}比例的每种能力。搜索过程由验证结果和我们的内部人工评估集指导。
ChatML格式 除了关注数据质量和多样性之外,我们的观察发现数据的格式对模型的最终性能有重大影响[wangxd注:质量 + 多样性 + 格式都很重要。所以基于Yi模型进行微调时很有可能微调完之后,能力反而越调越差能力退化了]。为此,我们实现了ChatML风格的格式[53]。这种结构化方法使模型能够区分各种信息类型,如系统配置、用户输入和助手响应。
3.2 训练方法
我们使用下一个词预测损失进行微调,只在响应上计算损失,而不是系统和用户指令。我们使用AdamW优化器,β1设置为0.9,β2设置为0.999,ϵ设置为10^-8。我们使用4096的序列长度,以及64的批量大小。我们将训练步骤设置为300,学习率恒定为1×10^-5,权重衰减为0.1,梯度裁剪的最大阈值为1.0,以及NEFTune[34],Yi-34B-Chat的噪声比例为45,Yi-6B-Chat为5。
4 基础设施
我们构建了支持全栈数据处理、预训练、微调和服务的基础设施[wangxd注:大模型更依重于工程,而不是科学] 。我们的基础设施特点包括:
(1)自动化管理和监控计算资源;
(2)通过优化的并行策略、内核效率和长上下文支持提高训练速度;
(3)统一的微调框架支持异构分布式训练后端,例如在直接偏好优化(DPO)[59]中同时使用Megatron和DeepSpeed进行多个模型的训练;
(4)通过各种LLM服务加速技术(如量化、连续批处理和分页注意力)降低部署成本。
下面我们将逐一解释这些技术。
计算资源管理 为了高效地调度大规模语言模型开发,特别是可能需要在数千个GPU上进行数月的预训练,我们构建了一个高效的多云任务调度算法来管理不同优先级的预训练、SFT和RLHF任务。我们还构建了一个高性能的内部训练框架,允许我们根据GPU可用性自动弹性地将预训练作业扩展到不同的节点大小。更重要的是,所有与训练相关的超参数将同时无缝地进行缩放。
在大语言模型训练阶段,各种故障经常发生,从GPU崩溃到通信织物错误再到损失峰值。我们采用以下策略来应对这些可靠性挑战:[wangxd注:字节跳动的万卡集群训练大模型的论文中列举类似的诸多挑战]
(1)我们应用自动化检查、预测和标记节点,以识别不同类别的软硬件错误。被标记为有问题的节点将暂时从资源池中移除,直到错误被清除。
(2)我们实现了一个带有预检的任务排队系统,以及在训练任务失败时快速、自动恢复的能力。
(3)我们开发了一个用户友好的多任务提交和管理控制台,使开发人员能够无缝地管理和跟踪他们的训练任务和超参数。
性能和成本效率 内存和通信限制是大规模模型训练的两大技术挑战,需要超越仅仅增加更多GPU的综合性解决方案。我们使用并改进以下技术来应对内存和通信限制:
(1)ZeRO-1[60]通过在数据并行进程之间划分优化器状态来消除内存消耗;
(2)在每个计算节点内结合张量并行和流水线并行[70]以避免节点间通信瓶颈,3D并行策略经过精心设计和优化,以避免使用激活检查点并最小化流水线气泡;
(3)内核融合技术如flash attention[15][14]和JIT内核,以减少冗余的全局内存访问和消耗;
(4)拓扑感知资源分配(排名策略),以最小化不同层交换机之间的通信,这是典型胖树拓扑的限制。
微调框架 与预训练不同,微调LLM可能需要协调多个模型,正如DPO[59]和PPO[54]的实践一样。在这样的训练作业中,一个典型的过程是使用参考/奖励模型预测一批数据(这同样需要不平凡的时间),然后让目标模型使用这些数据计算损失并更新参数。为此,我们构建了一个多模型调度框架,以支持单个作业中不同LLM的多个后端。例如,在DPO中微调语言模型时,参考模型的中间结果可以被缓存和重用,提高训练速度和资源成本,接近于有监督微调的对应物。
快速高效的推理 我们主要使用量化、动态批处理和分页注意力来提高解码速度和内存使用。我们使用量化来减少内存占用和计算需求。通过4位模型量化[81]和8位KV缓存量化[18],我们能够在几乎不影响性能(例如,在MMLU/CMMLU基准测试中精度下降不到1%)的情况下实现显著的GPU内存节省。我们使用动态批处理[86]来最小化响应时间并提高批处理效率。我们使用PagedAttention[41]来提高内存利用率和改善解码。
长上下文窗口支持 我们实现并改进了计算-通信重叠、序列并行性和通信压缩,以支持高达200K上下文长度的连续预训练和微调。我们扩展上下文长度到200K的方法完全基于工程,也就是说,我们没有修改模型架构,如稀疏、局部或滑动窗口注意力——即使输入是200K,模型仍然使用全注意力。
5 安全性
为了增强模型的可信度和安全性,我们开发了一个全栈的负责任的人工智能安全引擎(RAISE)。RAISE确保安全的预训练、对齐和部署。本节讨论了我们在预训练和对齐阶段的安全措施。
预训练中的安全性 遵循标准的预训练数据安全实践[5, 58, 77],我们构建了一组基于启发式规则、关键词匹配和学习分类器的过滤器,以移除包含个人标识符和私人数据的文本,并减少色情、暴力和极端内容。
对齐中的安全性 根据现有研究[24, 35],我们首先构建了一个全面的安全分类法。这个分类法涵盖了广泛的潜在问题,包括环境不和谐、迷信、宗教敏感性、歧视性做法、药物滥用、暴力行为、非法活动、仇恨言论、伦理违规、隐私泄露、自残、性暗示内容、心理健康问题和网络安全威胁。我们策划了反映这些类别的数据集,以实现强大的对齐,并将其与我们的对话SFT数据混合。我们还在对齐阶段包括了一组针对性的提示,模拟攻击场景,这有效地提高了模型对恶意使用的抵抗力。
6 评估
我们的评估表明,Yi模型系列在广泛的任务上取得了鼓舞人心的性能,并提供了接近GPT-3.5的用户偏好率。我们首先报告基础模型在标准基准测试上的性能,然后讨论聊天模型的性能及其用户偏好率。
6.1 基础模型性能
6.1.1 主要结果
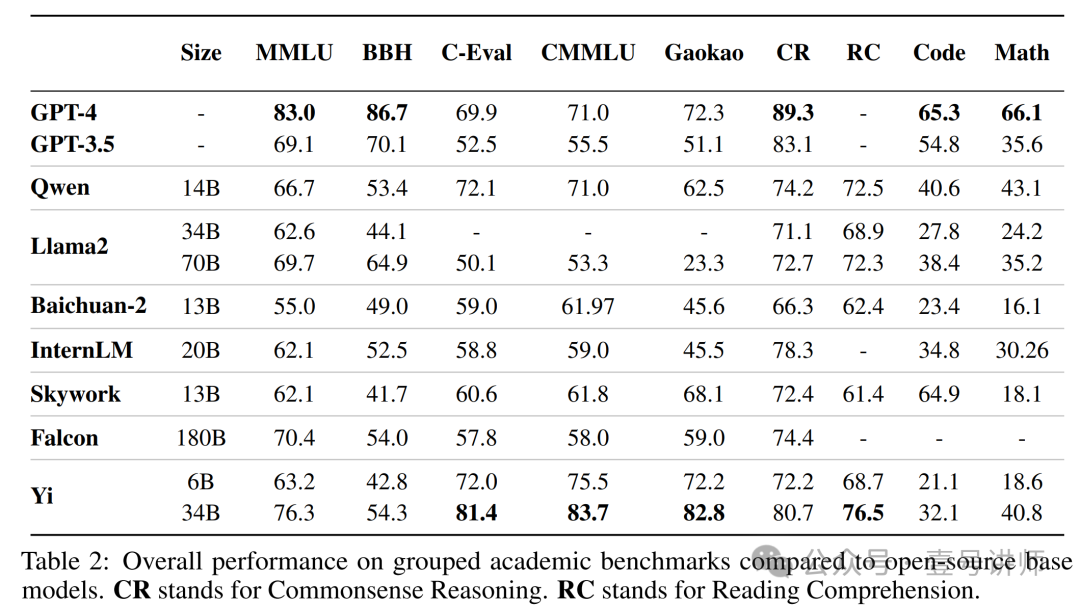
在这里,我们展示了我们的基础模型和几个其他知名基础模型在标准学术基准测试上的结果。在基准测试开源模型时,我们观察到我们的流水线生成的结果与公共来源报告的结果之间存在差异。在对这种差异进行更深入的调查后,主要是由于不同的模型使用不同的提示、后处理策略和采样技术。这些差异可能会在结果中引起显著变化。我们的提示和后处理策略与原始基准测试的默认设置保持一致[2, 4, 7, 8, 10–12, 27, 28, 42, 50, 61–63, 72, 74, 75, 89, 90]。我们使用贪婪解码而不进行任何后处理来生成内容。对于没有公开报告的分数(或以不同设置报告的分数),我们尝试用我们的流水线获得结果。对于可以公开找到的分数,我们直接报告现有数字。我们使用以下基准测试,主要遵循LLaMA 2 [77]的做法:
常识推理:我们包括PIQA[4]、SIQA[63]、HellaSwag[89]、WinoGrande [62]、ARC[11]、OpenBookQA(OBQA)[50]和CommonsenseQA(CSQA)[75]来评估常识推理。CSQA专门使用7次shot设置进行测试,而所有其他测试都是在0次shot配置下进行的。
阅读理解:对于阅读理解,我们报告了SQuAD[61]、QuAC[8]和BoolQ[10]的0次shot平均值。
数学:我们报告了GSM8K[12](8次shot)和MATH[28](4次shot)基准测试的平均值,使用pass@1准确率,没有任何特定的提示策略(例如,思维链提示)和其他集成技术(例如,多数投票)。
代码:我们报告了我们的模型在HumanEval[7](Chen等人,2021年)和MBPP[2](Austin等人,2021年)上的平均pass@1分数。
流行的聚合基准:我们报告了MMLU[27](5次shot)、CMMLU[42](5次shot)、高考-Bench[90](5次shot)和BigBench[72] Hard(BBH[74])(3次shot)的总体结果。
通过在比之前工作(通常≤2T)更多的tokens(3.1T)上进行训练,我们观察到在基准测试中取得了显著的性能提升,如表2所示。然而,值得注意的是,我们的模型与现有的开源和闭源模型之间仍然存在明显差异,特别是在与数学和编码相关的任务中。由于这些领域的性能可以通过持续的预训练和指令微调显著提高,我们在最初的设计选择时避免在预训练语料库中纳入大量的数学和编码内容。我们确实计划在未来发布具有增强数学和编码能力的模型。
6.1.2 讨论
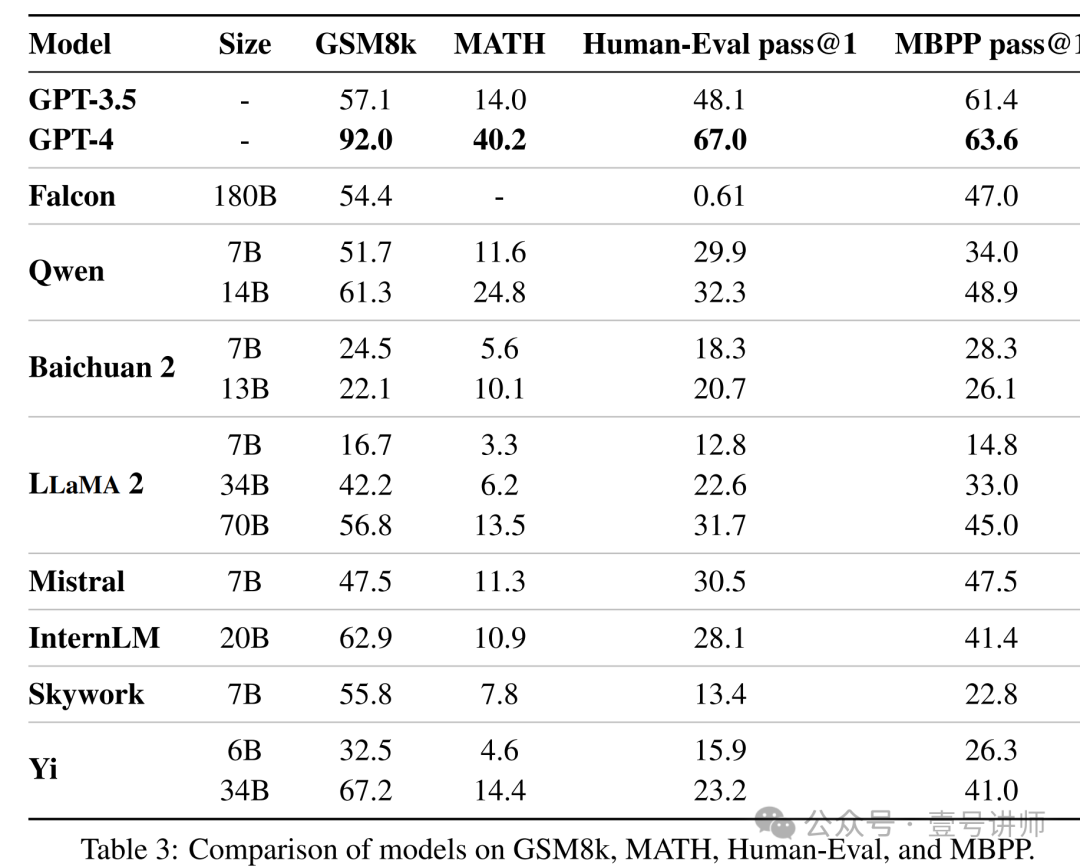
模型规模的收益。我们观察到Yi-34B与Yi-6B相比有显著的性能提升,尽管它们使用了相同的预训练语料库。更大的模型规模在代码和数学基准测试上带来了更高的性能提升,参见表3,与关注常识推理、阅读理解或知识的基准测试相比。
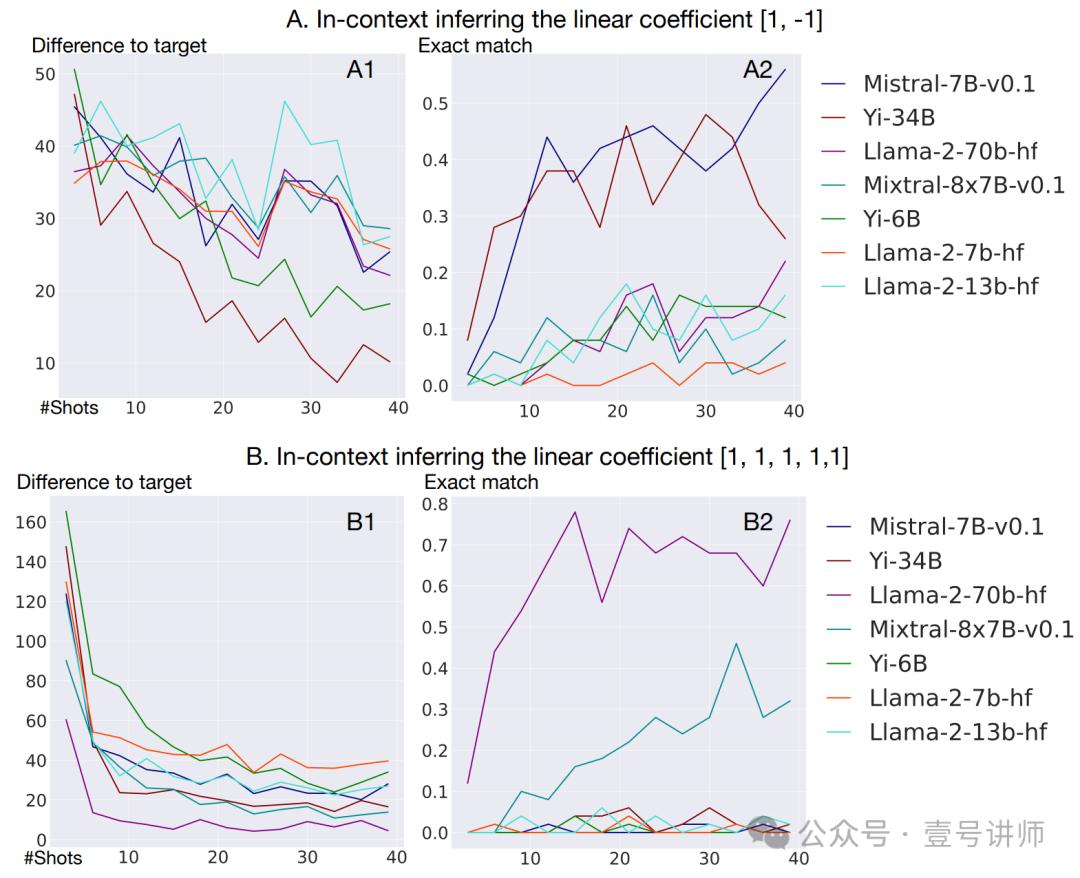
图 3:通过推断加权和的线性系数来评估语言模型的上下文学习能力。考虑到关于涌现能力是否是测量结果的产物的讨论[65],我们使用与目标的差异(目标数字 - 模型预测)作为连续的衡量标准,以及完全匹配(目标数字 == 模型预测)作为不连续的衡量标准。A:当有两个线性系数时,Yi-34B在通过与目标数字的差异来衡量时表现最佳。B:将线性系数的数量增加到5,只有足够大的模型(LLaMA2 70B和Mixtral 8x7B)能够实现有意义的完全匹配,这表明上下文学习复杂函数是一种涌现的能力。
数据质量。较小的高质量预训练数据模型,如Yi-34B或Qwen-14B,通常比使用更大尺寸但(据推测)数据质量较低的模型,如Falcon-180B(尽管Falcon-180B的重点可能更多在于扩展方面,这本身就是非常重要的价值)表现出更好的性能。
GPT-4与开源LLM之间的差距。根据表2,我们注意到开源LLM在各种基准测试上仍然落后于GPT-4和GPT-3.5的性能。然而,代表性的双语LLM,例如Qwen-14B和Yi-34B,可以在与中文知识相关的基准测试上匹配甚至超过GPT-4的性能,包括C-Eval [31]、CMMLU [42]和高考[90]。然而,在与推理相关的基准测试上,如BBH [72]、代码(HumanEval)和数学(MATH),GPT-4与开源模型之间仍然存在巨大差距。
6.1.3 上下文学习研究
我们进一步研究了上下文学习能力,即在少量输入输出演示的基础上推断底层函数的能力。我们考虑推断加权和的线性系数的任务。具体来说,定义 y = w1x1 + w2x2 + ... + wnxn,我们的少量演示是 x1, x2, ..., xn, y,我们要求模型(隐式地)通过预测给定新输入集 x 的 y 来推断 w1, w2, ..., wn。我们使用 (a). 模型预测 y 与真实值 y∗ 之间的绝对差异,即 |y − y∗| 作为连续的衡量标准,以及 (b). 完全匹配 y == y∗ 作为不连续的衡量标准。我们还注意到,大多数模型在加法和减法上表现合理,因此,作为混淆因素的算术能力可以排除在外。
结果如图 3 所示。当设置线性系数为 [1, -1] 时,我们看到 Yi-34B 和 LLaMA-2 70B 在答案完全匹配方面表现最佳。如果我们将线性系数的数量增加到 [1, 1, 1, 1, 1],我们观察到只有大型模型(LLaMA-2 70B 和 Mixtral)能够在完全匹配上取得好成绩,尽管与目标的差异更为连续。这些观察为 Yi-34B 在上下文学习方面的性能提供了旁证,并表明进一步的扩展可能允许模型通过上下文学习推理更复杂的函数。
6.2 聊天模型性能
在本节中,我们报告了聊天模型的自动和人类偏好评估。我们使用贪婪解码来生成响应。对于自动评估基准,我们从模型生成的输出中提取答案并计算准确性。在评估过程中,我们观察到不同的提示对结果有不同的影响。因此,对于同一组问题,我们使用相同的提示来评估所有模型,旨在确保尽可能公平和无偏见的结果。
6.2.1 自动评估
对于自动评估,我们使用与基础模型相同的基准,详细内容见第 6.1.1 节。我们使用零次shot和少量shot方法,但通常零次shot更适合聊天模型。我们的评估涉及在明确或隐式遵循指令的情况下生成响应(例如,少量shot示例中的格式)。然后,我们从生成的文本中分离出相关答案。与基础模型不同,在 GSM8K 和 BBH 数据集上的零次shot评估中,我们采用思维链(CoT)方法来指导模型在得出答案之前进行深思熟虑。
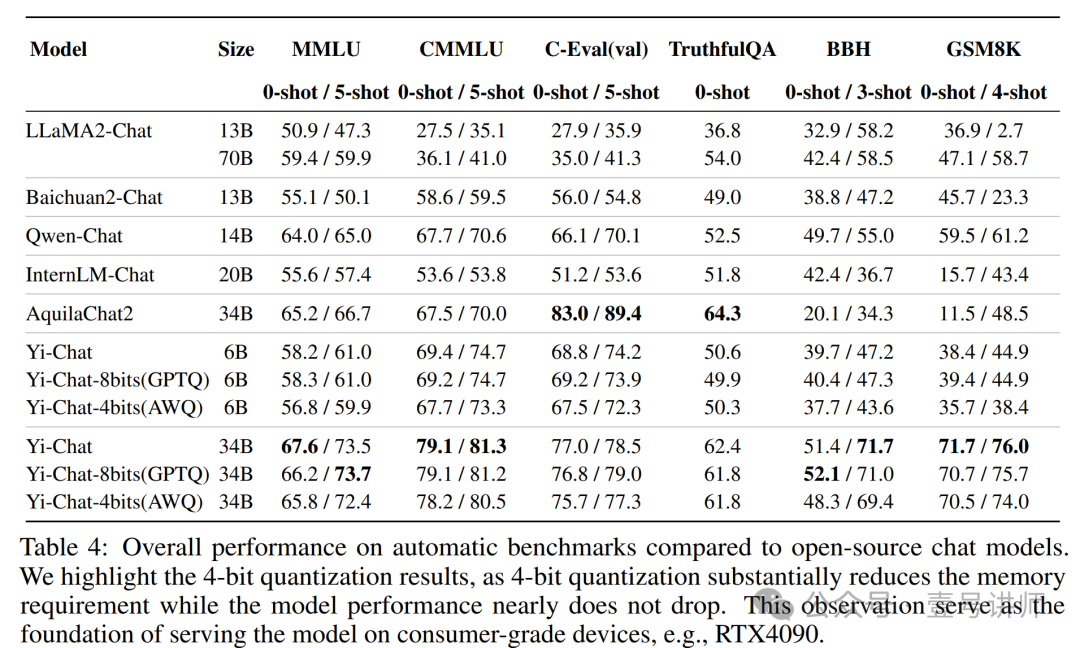
表 4 显示的结果证明了我们的聊天模型在理解人类指令和生成适当的指令遵循响应方面的有效性。我们特别强调了 4 位量化的结果,因为 4 位量化大大减少了内存需求,而模型性能几乎没有下降。这一观察为在消费级设备上提供模型服务奠定了基础。
与Goodhart’s原则一致,当一个测量指标成为我们追求的目标时,它就不再作为可靠的评估标准。因此,我们在基准测试上的评估结果仅用于确保我们的对齐训练不会对基础模型的基础知识和能力产生不利影响。我们不会针对提高基准性能的目标对聊天模型进行针对性优化。
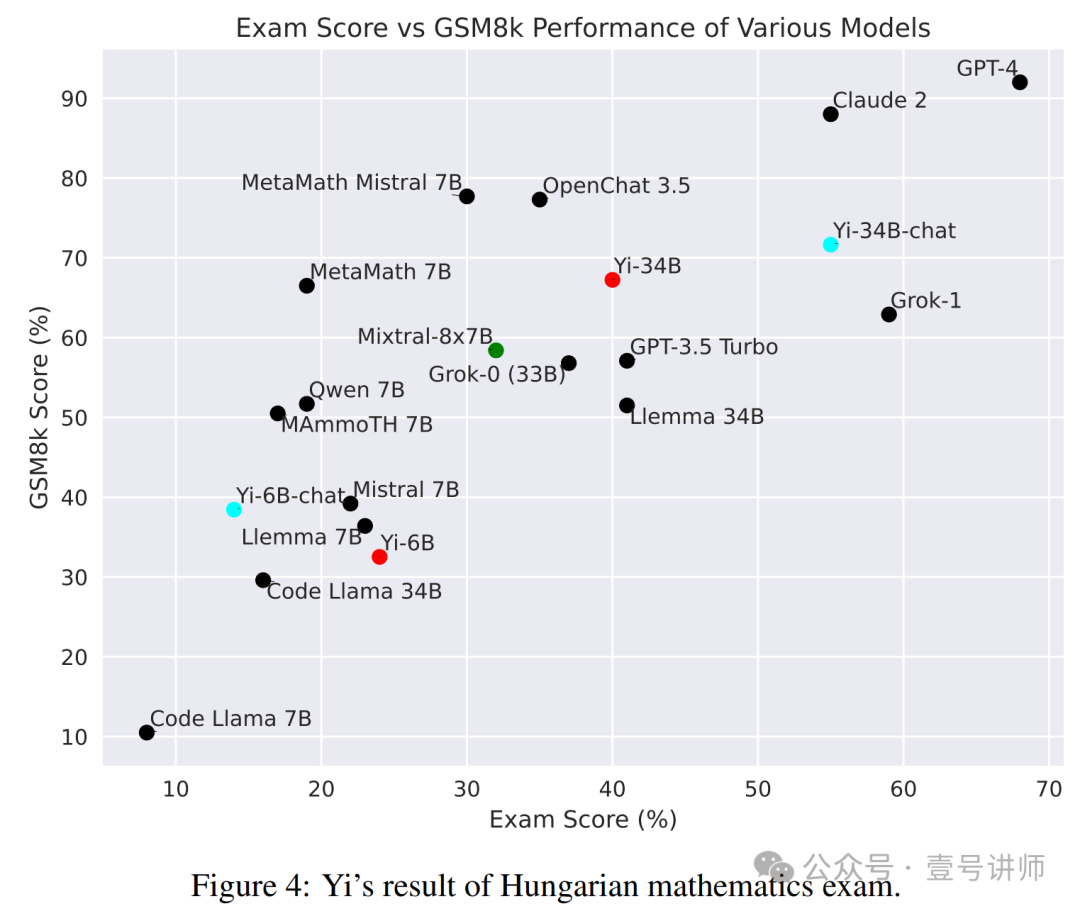
为了进一步评估我们模型能力的普适性,我们通过将其置于 2023 年匈牙利高中数学期末考试问题中,对其进行了数学计算能力的评估,这些问题最初由 xAI Grok 团队提出,然后由 Paster [55] 复制。这一评估的目的是确定我们的模型是否表现出对数学导向的训练数据集过度拟合的迹象。图 4 的结果表明,Yi-34B-Chat 在 GSM8K 和匈牙利数学考试上表现鼓舞人心。然而,请注意,Yi-6B-Chat 在数学能力上(无论是 GSM8K 还是匈牙利数学考试)表现不强。我们推测,较小的模型可能需要更多的数据来在 SFT 阶段激活其相应的能力。
6.2.2 人类评估
在本节中,我们对模型的对话能力进行了评估,考虑了确保其有效性和安全性的方面。我们从社区收集并构建了不同难度级别的数据,以全面评估聊天模型的对话能力。然而,无论是公共评估集还是自建评估集,评估结果都受到评估标准和提示设计的强大影响。我们的内部评估结果可能对其他模型不公平,使得准确代表我们模型的真实能力水平变得困难。因此,在这里我们只呈现外部评估结果,以展示我们聊天模型当前的对话能力。我们考虑:
(1). AlapcaEval1 [44],它旨在通过比较指定模型与 Davinci003 [21] 的参考回复来评估模型的英语对话能力,以计算胜率;
(2). LMSys2 [93] Chatbot Arena,它通过对话平台展示不同模型的响应,然后要求用户根据他们的偏好进行选择,然后计算 Elo 得分;
(3). SuperClue3 另一方面,是一个旨在全面评估模型中文语言能力的排行榜。
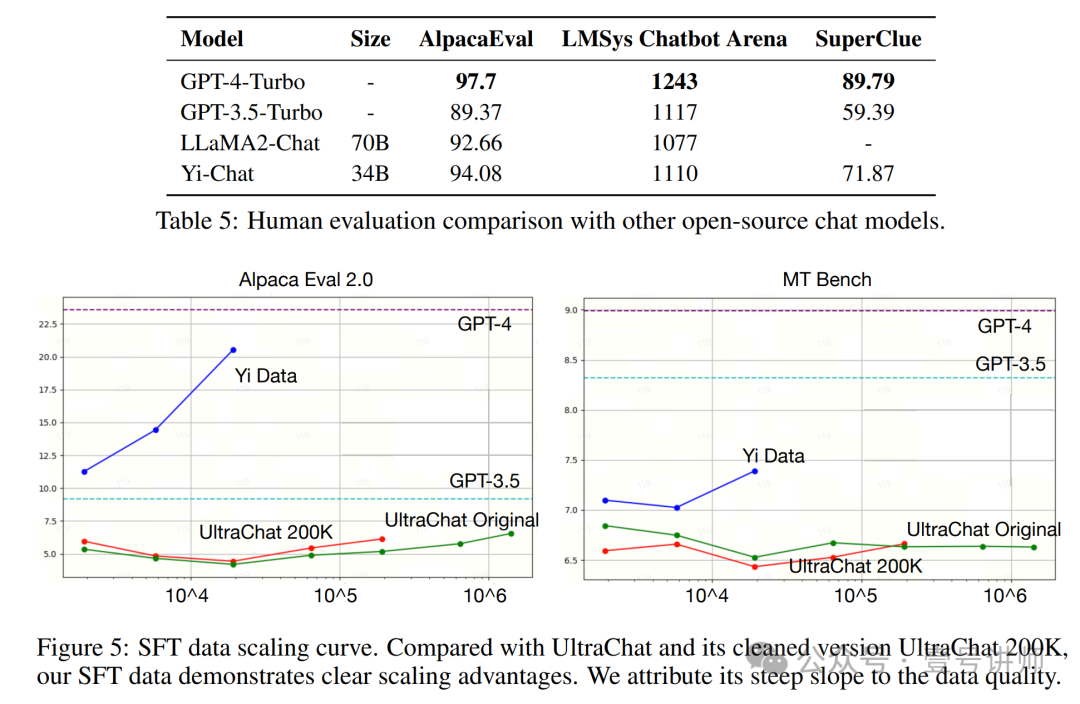
表 5 展示了我们在三个第三方评估中考虑的 Yi-34B-Chat 的性能结果,结果截止日期为 2023 年 12 月 21 日。数据显示,尽管与 GPT-4 相比仍有差距,但我们的模型展现了熟练的双语(中文和英文)对话能力,并与用户偏好良好对齐。各种模型的额外比较结果可以在官方网站上查看。我们通过比较数据扩展期间偏好增加的速度进一步展示了数据质量。如图 5 所示,与 UltraChat [19] 及其清理版本 UltraChat 200K 相比,我们看到在扩展 Yi 数据时性能提升的明显趋势。
7 能力扩展
在本节中,我们将讨论我们的后训练方法,以将Yi基础模型扩展到20万长上下文,为其配备视觉理解能力,并通过深度升级增强6B模型。
7.1 长上下文建模
我们的长上下文解决方案包括一个持续的预训练阶段和一个微调阶段,两者都很轻量级。我们坚持一个基本假设,即在20万输入上下文中任何地方利用信息的潜力已经存在于基础模型中(与Fu等人的研究相同),持续的预训练阶段“解锁”了这种能力,这一点通过在大海捞针测试中的出色表现得到了证实,然后微调阶段进一步适应响应的风格,以遵循人类指令和偏好。
继续预训练 我们继续使用序列并行和分布式注意力对全注意力模型进行预训练。也就是说,我们不使用任何稀疏或线性注意力,而是使用全注意力的蛮力实现。我们继续对Yi 6B/34B基础模型进行预训练,数据混合包括(1)原始预训练数据,如第2节所述;(2)长度上采样的长上下文数据,其中长文档主要来自书籍;(3)多文档问答合成数据,我们构建了问答对,其中答案包含了答案前相关段落的复述。我们的数据方法主要遵循Fu等人[22]和Yu等人[87]的数据工程实践。我们继续在5B token上进行预训练,批量大小为4M,相当于100个优化步骤。与Fu等人[22]的并行工作一致,我们观察到这种轻量级的继续预训练已经能够在大海捞针测试中实现强大的性能,如图6所示。
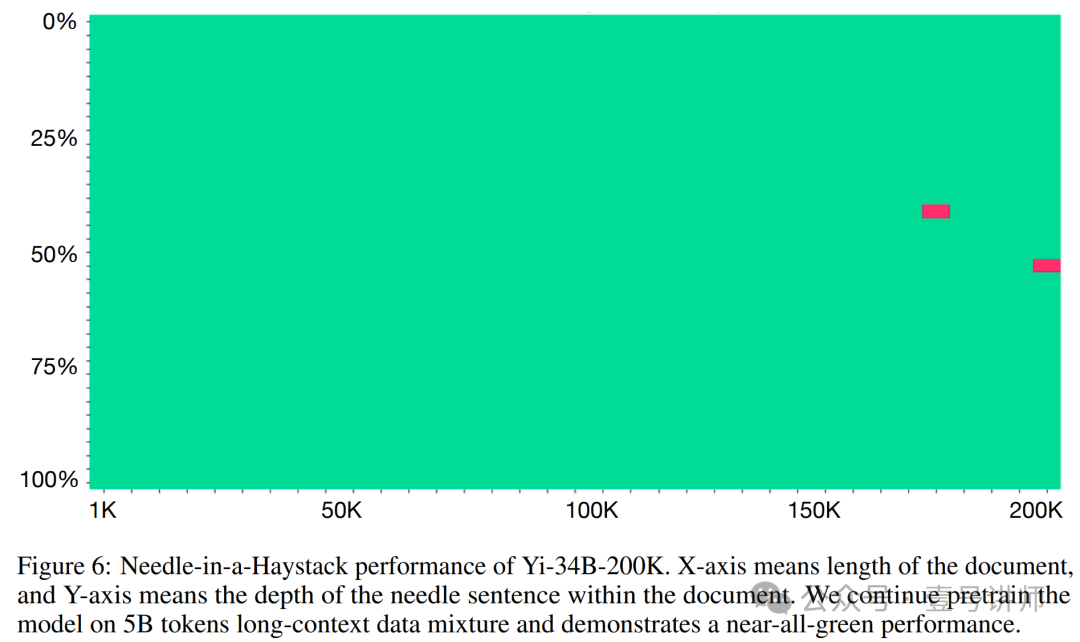
监督微调 我们将短上下文SFT数据与长上下文文档问答数据混合。我们使用模型辅助的自动化方法(即合成数据)来构建文档QA。具体来说,我们随机将多个文档连接成一个序列,从长序列中抽取一个或多个段落,并要求聊天模型基于抽取的段落构建问题和答案对。一个重要的细节是复述和改述:在给出答案之前,我们要求模型复述或改述原始段落。这种数据格式鼓励模型的检索行为,从而抑制幻觉行为:给定一个问题,模型更有可能使用输入内的信息来构建答案,而不是使用其内部知识,这可能相关但可能不准确。我们的微调模型部署在www.wanzhi01.com,我们鼓励读者尝试它。
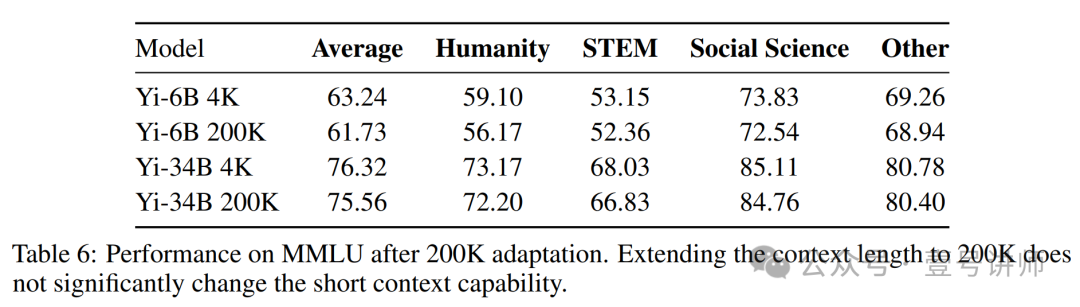
200K模型的性能如图6和表6所示。具体来说,图6显示了Yi-34B-200K著名的大海捞针测试,尽管我们倾向于认为这种检索对于长上下文LLM来说相对容易。表6显示,我们的上下文扩展并没有显著影响短上下文通用能力。
7.2 视觉-语言
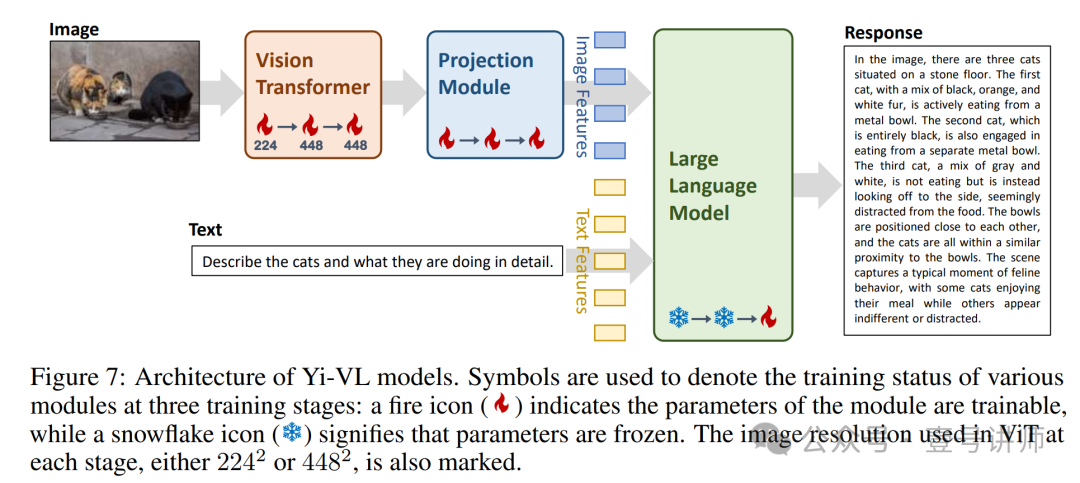
在多模态研究的新兴领域中,将图像理解能力整合到大语言模型中变得越来越可行。受到开源LLaVA[46, 47]的启发,我们提出了Yi视觉语言(Yi-VL)模型,即基于Yi-6B-Chat和Yi-34B-Chat语言模型的Yi-VL-6B和Yi-VL-34B。Yi-VL模型的架构如图7所示,包括三个主要模块。用于图像编码的视觉transformer(ViT)初始化为CLIP ViT-H/14模型[33]。一个投影模块,旨在使图像特征与文本特征空间对齐,由两层多层感知器(MLP)组成,具有层归一化。最后,大型语言模型,初始化为Yi-Chat模型,展现出在理解和生成英语和中文方面的卓越能力。为了增强Yi-VL模型在双语多模态理解和生成方面的性能,我们利用了丰富的双语图像-文本对数据集。
Yi-VL模型经历了三个阶段的训练过程:
第一阶段:我们使用2242的图像分辨率训练ViT和投影模块的参数。训练利用了一个包含1亿图像-文本对的大量数据集,来自LAION-400M[66]。主要目标是增强ViT在我们指定的架构内的知识获取,并实现ViT与LLM之间更好的对齐。
第二阶段:我们将ViT的图像分辨率扩展到4482,旨在进一步提高模型辨别复杂视觉细节的能力。这一阶段使用的数据集包括来自LAION-400M的2000万图像-文本对。此外,我们还整合了大约480万来自不同来源的图像-文本对,例如CLLaVA[45]、LLaVAR[91]、Flickr[85]、VQAv2[25]、RefCOCO[37]、Visual7w[95]等。
第三阶段:整个模型的参数进行训练。主要目标是提高模型在多模态聊天交互中的熟练度,从而使其能够无缝整合和解释视觉和语言输入。为此,训练数据集涵盖了多种来源,总计约100万图像-文本对,包括GQA[32]、VizWiz VQA[26]、TextCaps[71]、OCR-VQA[51]、Visual Genome[39]、ShareGPT4V[6]等。为确保数据平衡,我们对任何单一来源的最大数据贡献设定了上限,限制在不超过50,000对。
在第一阶段和第二阶段,我们将全局批量大小、学习率、梯度裁剪和时代数分别设定为4096、1e-4、0.5和1。在第三阶段,这些参数调整为256、2e-5、1.0和2。训练消耗了128个NVIDIA A100 GPU。Yi-VL-6B的总训练时间约为3天,Yi-VL-34B约为10天。
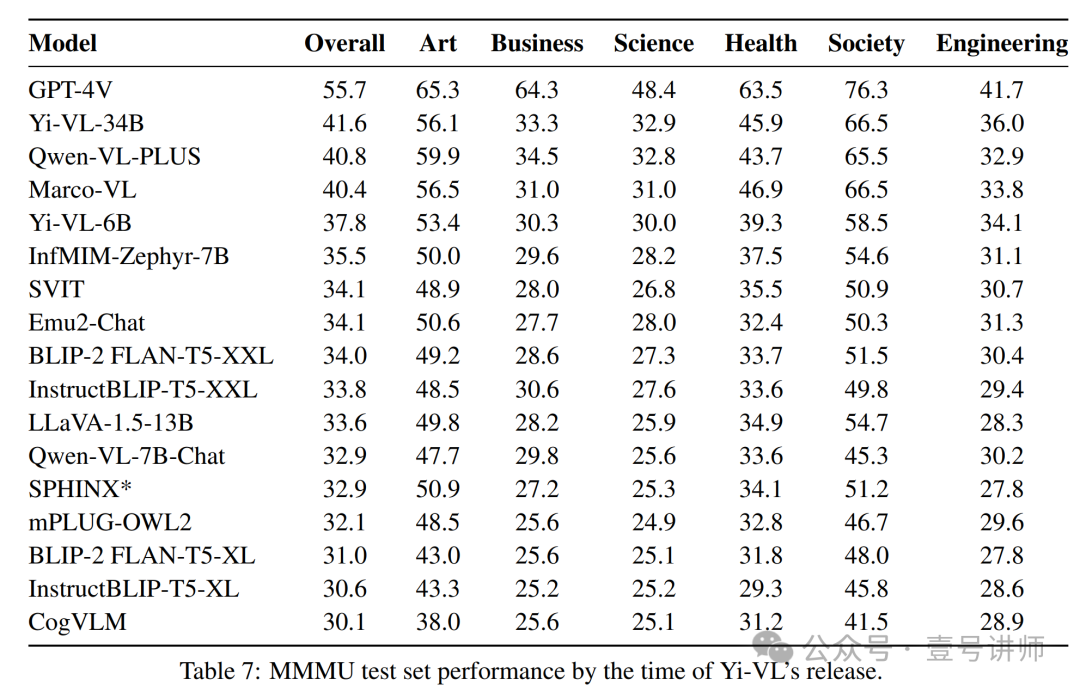
表7显示了Yi-VL发布时的MMMU测试集排行榜。我们注意到这个领域目前正在积极研究中,与社区的进步保持一致,我们将继续改进Yi-VL的性能。
7.3 深度升级
最近关于伸缩定律[29, 30, 36]的研究强调了随着计算预算、模型大小和数据大小的增加,模型性能的可预测提升。然而,在扩展计算预算时,确定模型和数据大小之间最有效的资源分配仍然是伸缩定律领域中的一项巨大挑战。此外,DeepSeek-AI等人[17]的研究表明,将增加的计算预算分配给模型扩展应与可用数据的质量成比例。
鉴于这些见解,我们提出了一种新方法,旨在通过一系列阶段性训练过程动态调整数据和模型大小之间的资源分配。这种策略根据伸缩定律迭代地微调数据特性和模型大小之间的平衡,提高模型训练效率和性能。
方法 遵循Kim等人[38]概述的方法,我们的目标是将我们的Yi-6B基础模型(具有32层)升级到一个名为Yi-9B基础模型的9B模型,该模型具有48层,通过复制原始的16个中间层12-28。深度升级涉及扩展基础模型的深度,然后继续对增强模型进行预训练阶段。
我们的调查表明,决定复制哪些层可以通过评估每层输入和输出之间的余弦相似度分数来指导。这种方法允许有针对性的模型扩展,而不需要额外的预训练,只会导致最小的性能影响。这种对性能影响最小的原因在于复制层的输入和输出之间具有高余弦相似度,接近1,如图8所示。
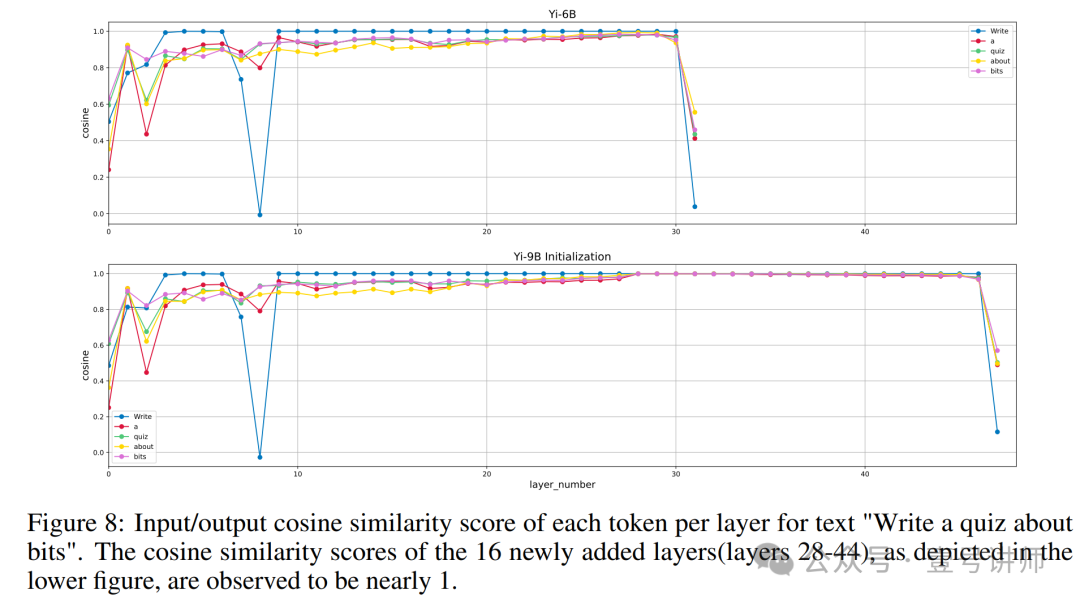
这一观察表明,复制这些层并不会显著改变原始模型产生的输出logits。这种方法通过优化其层的内部处理动态来确保模型的有效扩展。
继续预训练 数据集由大约8000亿个token组成,分为两个阶段,大约70%是最近收集并精心挑选的。我们在最后阶段增强了代码覆盖率以提高代码性能。
为了优化训练过程,我们保持恒定的学习率为3e-5,并采取策略性的方法,每当模型损失稳定时,逐渐将批量大小从4M tokens增加。这种批量大小的增量调整,以及保持所有其他参数与已建立的Yi-6B基础模型配置一致,对于应对大规模训练的挑战至关重要。
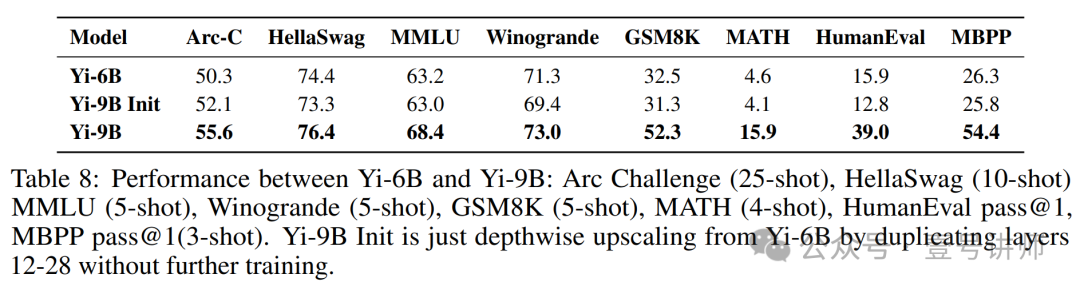
这些策略的有效性在表8中得到展示,该表详细列出了Yi-9B基础模型在各种基准测试中的性能,包括常识、推理、知识、编码和数学。它强调了Yi-9B基础模型在特定领域的竞争优势,展示了我们的方法通过最佳调整数据特性和模型大小之间的相互作用来增强模型性能的有效性。
8 最终讨论
在这份报告中,我们讨论了Yi语言模型家族的全栈开发。Yi-34B实现了与GPT-3.5相匹配的性能,并且可以在消费级设备上部署(感谢4/8位量化),使其成为本地部署的理想模型。
Yi预训练过程的关键要点是数据的数量和质量:
(1)。在比Chinchilla最优更多的数据上训练模型可以带来清晰且一致的性能提升,我们强烈建议所有预训练团队这样做。我们的模型是在3.1T tokens上训练的,但我们相信,有了更多的数据,我们可以继续提高模型性能(即,模型在3.1T时还没有饱和);
(2)。当谈到预训练数据质量时,我们认为最关键的两个因素是数据来源(例如,文本是为专业使用还是为随意的社交媒体发帖)和数据清洗的细节(例如,过滤和去重的强度)。由于数据清洗是一个非常复杂的流程,而且进行广泛的网格搜索式优化极其困难,我们目前的解决方案仍有改进的空间。
Yi微调过程的关键要点是在少量数据(≤ 10K)上进行大量迭代,逐个案例,通过机器学习工程师直接进行,并通过真实用户反馈进行改进。这种方法明显偏离了指令扩展方法,该方法最初由FLAN系列[9]引入,然后被UltraChat系列[19]跟进。
正如我们目前的结果所展示的,我们认为,当预训练数据量固定时,推理能力(我们视为语言模型在现实世界部署的核心能力)与模型规模强烈相关。我们相信,鉴于我们目前的结果,继续使用彻底优化的数据来扩展模型参数,将导致我们即将推出的下一个版本中出现更强大的前沿模型。[wangxd注:彻底优化数据(提质增量)、持续扩展参数,是催生更强大模型的不二法门。]
References
[1] Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. arXiv preprint arXiv:2305.13245, 2023.
[2] Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program Synthesis With lLarge Language Models. arXiv preprint arXiv:2108.07732, 2021.
[3] Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu,Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu,Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu,Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang,Chang Zhou, Jingren Zhou, Xiaohuan Zhou, and Tianhang Zhu. Qwen Technical Report. 09URL https://arxiv.org/pdf/2309.16609.pdf.
[4] Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. PIQA: Reasoning about Physical Commonsense in Natural Language. ArXiv, abs/1911.11641, 2019. URL https://api.semanticscholar.org/CorpusID:208290939.
[5] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal,Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
[6] Lin Chen, Jisong Li, Xiaoyi Dong, Pan Zhang, Conghui He, Jiaqi Wang, Feng Zhao, and Dahua Lin. Sharegpt4v: Improving large multi-modal models with better captions. arXiv preprint arXiv:2311.12793, 2023.
[7] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pondé de Oliveira Pinto, Jared Kaplan, Harrison Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Joshua Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer,Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. Evaluating Large Language Models Trained on Code. CoRR, abs/2107.03374, 2021.URL https://arxiv.org/abs/2107.03374.
[8] Eunsol Choi, He He, Mohit Iyyer, Mark Yatskar, Wen tau Yih, Yejin Choi, Percy Liang, and Luke Zettlemoyer. QuAC : Question Answering in Context, 2018.
[9] Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416, 2022.
[10] Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions, 2019.
[11] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge, 2018.
[12] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training Verifiers toSolve Math Word Problems. arXiv preprint arXiv:2110.14168, 2021.20
[13] Together Computer. Redpajama: an open dataset for training large language models, 2023. URL https://github.com/togethercomputer/RedPajama-Data.
[14] Tri Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning. 2023.
[15] Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. In Advances in Neural Information Processing Systems, 2022.
[16] Michiel de Jong, Yury Zemlyanskiy, Joshua Ainslie, Nicholas FitzGerald, Sumit Sanghai, Fei Sha, and William Cohen. FiDO: Fusion-in-Decoder Optimized for Stronger Performance and Faster Inference. arXiv preprint arXiv:2212.08153, 2022.
[17] DeepSeek-AI, :, Xiao Bi, Deli Chen, Guanting Chen, Shanhuang Chen, Damai Dai, Chengqi Deng, Honghui Ding, Kai Dong, Qiushi Du, Zhe Fu, Huazuo Gao, Kaige Gao, Wenjun Gao, Ruiqi Ge, Kang Guan, Daya Guo, Jianzhong Guo, Guangbo Hao, Zhewen Hao, Ying He, Wenjie Hu, Panpan Huang, Erhang Li, Guowei Li, Jiashi Li, Yao Li, Y. K. Li, Wenfeng Liang, Fangyun Lin, A. X. Liu, Bo Liu, Wen Liu, Xiaodong Liu, Xin Liu, Yiyuan Liu, Haoyu Lu, Shanghao Lu,Fuli Luo, Shirong Ma, Xiaotao Nie, Tian Pei, Yishi Piao, Junjie Qiu, Hui Qu, Tongzheng Ren, Zehui Ren, Chong Ruan, Zhangli Sha, Zhihong Shao, Junxiao Song, Xuecheng Su, Jingxiang Sun, Yaofeng Sun, Minghui Tang, Bingxuan Wang, Peiyi Wang, Shiyu Wang, Yaohui Wang, Yongji Wang, Tong Wu, Y. Wu, Xin Xie, Zhenda Xie, Ziwei Xie, Yiliang Xiong, Hanwei Xu, R. X. Xu, Yanhong Xu, Dejian Yang, Yuxiang You, Shuiping Yu, Xingkai Yu, B. Zhang,Haowei Zhang, Lecong Zhang, Liyue Zhang, Mingchuan Zhang, Minghua Zhang, Wentao Zhang, Yichao Zhang, Chenggang Zhao, Yao Zhao, Shangyan Zhou, Shunfeng Zhou, Qihao Zhu, and Yuheng Zou. Deepseek llm: Scaling open-source language models with longtermism. 2024.
[18] Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. Llm. int8 (): 8-bit matrix multiplication for transformers at scale. arXiv preprint arXiv:2208.07339, 2022.
[19] Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Zhi Zheng, Shengding Hu, Zhiyuan Liu, Maosong Sun, and Bowen Zhou. Enhancing chat language models by scaling high-quality instructional conversations. arXiv preprint arXiv:2305.14233, 2023.
[20] Guanting Dong, Hongyi Yuan, Keming Lu, Chengpeng Li, Mingfeng Xue, Dayiheng Liu, Wei Wang, Zheng Yuan, Chang Zhou, and Jingren Zhou. How abilities in large language models are affected by supervised fine-tuning data composition, 2023.
[21] Yann Dubois, Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy Ba, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Alpacafarm: A simulation framework for methods that learn from human feedback, 2023.
[22] Yao Fu, Rameswar Panda, Xinyao Niu, Xiang Yue, Hannaneh Hajishirzi, Yoon Kim, and Hao Peng. Data engineering for scaling language models to 128k context. arXiv preprint arXiv:2402.10171, 2024.
[23] Gemini Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. Gemini: A family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023.
[24] Amelia Glaese, Nat McAleese, Maja Tr˛ebacz, John Aslanides, Vlad Firoiu, Timo Ewalds, Maribeth Rauh, Laura Weidinger, Martin Chadwick, Phoebe Thacker, et al. Improving alignment of dialogue agents via targeted human judgements. arXiv preprint arXiv:2209.14375, 2022.
[25] Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering.In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6904–6913, 2017.
[26] Danna Gurari, Qing Li, Abigale J Stangl, Anhong Guo, Chi Lin, Kristen Grauman, Jiebo Luo, and Jeffrey P Bigham. Vizwiz grand challenge: Answering visual questions from blind people. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3608–3617, 2018
[27] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring Massive Multitask Language Understanding. CoRR, abs/2009.03300,URL https://arxiv.org/abs/2009.03300.
[28] Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring Mathematical Problem Solving With the MATH Dataset.arXiv preprint arXiv:2103.03874, 2021.
[29] Tom Henighan, Jared Kaplan, Mor Katz, Mark Chen, Christopher Hesse, Jacob Jackson,Heewoo Jun, Tom B. Brown, Prafulla Dhariwal, Scott Gray, Chris Hallacy, Benjamin Mann, Alec Radford, Aditya Ramesh, Nick Ryder, Daniel M. Ziegler, John Schulman, Dario Amodei,and Sam McCandlish. Scaling laws for autoregressive generative modeling. 2020.
[30] Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.
[31] Yuzhen Huang, Yuzhuo Bai, Zhihao Zhu, Junlei Zhang, Jinghan Zhang, Tangjun Su, Junteng Liu, Chuancheng Lv, Yikai Zhang, Jiayi Lei, et al. C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models. arXiv preprint arXiv:2305.08322, 2023.
[32] Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6700–6709, 2019.
[33] Gabriel Ilharco, Mitchell Wortsman, Ross Wightman, Cade Gordon, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Hannaneh Hajishirzi,Ali Farhadi, and Ludwig Schmidt. Openclip, July 2021. URL https://doi.org/10.5281/zenodo.5143773.
[34] Neel Jain, Ping-yeh Chiang, Yuxin Wen, John Kirchenbauer, Hong-Min Chu, Gowthami Somepalli, Brian R Bartoldson, Bhavya Kailkhura, Avi Schwarzschild, Aniruddha Saha, et al. Neftune: Noisy embeddings improve instruction finetuning. arXiv preprint arXiv:2310.05914, 2023.
[35] Jiaming Ji, Mickel Liu, Juntao Dai, Xuehai Pan, Chi Zhang, Ce Bian, Chi Zhang, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. Beavertails: Towards improved safety alignment of llm via a human-preference dataset, 2023.
[36] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. 2020.
[37] Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. Referitgame: Referring to objects in photographs of natural scenes. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 787–798, 2014.
[38] Dahyun Kim, Chanjun Park, Sanghoon Kim, Wonsung Lee, Wonho Song, Yunsu Kim, Hyeonwoo Kim, Yungi Kim, Hyeonju Lee, Jihoo Kim, Changbae Ahn, Seonghoon Yang, Sukyung Lee, Hyunbyung Park, Gyoungjin Gim, Mikyoung Cha, Hwalsuk Lee, and Sunghun Kim. Solar 10.7b: Scaling large language models with simple yet effective depth up-scaling. 2023.
[39] Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A Shamma, et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. International journal of computer vision, 123:32–73, 2017.
[40] Taku Kudo and John Richardson. SentencePiece: A Simple and Language Independent Subword Tokenizer and Detokenizer for Neural Text Processing. arXiv preprint arXiv:1808.06226, 2018.
[41] Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient Memory Management for Large Language Model Serving with PagedAttention. arXiv preprint arXiv:2309.06180, 2023. 22
[42] Haonan Li, Yixuan Zhang, Fajri Koto, Yifei Yang, Hai Zhao, Yeyun Gong, Nan Duan, and Timothy Baldwin. CMMLU: Measuring Massive Multitask Language Understanding in Chinese. arXiv preprint arXiv:2306.09212, 2023.
[43] Shenggui Li, Fuzhao Xue, Chaitanya Baranwal, Yongbin Li, and Yang You. Sequence parallelism: Long sequence training from system perspective. arXiv preprint arXiv:2105.13120, 2021.
[44] Xuechen Li, Tianyi Zhang, Yann Dubois, Rohan Taori, Ishaan Gulrajani, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Alpacaeval: An automatic evaluator of instruction-following models. https://github.com/tatsu-lab/alpaca_eval, 2023.
[45] LinkSoul-AI. Chinese llava. https://github.com/LinkSoul-AI/Chinese-LLaVA, 2023.
[46] Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. arXiv preprint arXiv:2310.03744, 2023.
[47] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. arXiv preprint arXiv:2304.08485, 2023.
[48] Wei Liu, Weihao Zeng, Keqing He, Yong Jiang, and Junxian He. What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning. arXiv preprint arXiv:2312.15685, 2023.
[49] Keming Lu, Hongyi Yuan, Zheng Yuan, Runji Lin, Junyang Lin, Chuanqi Tan, Chang Zhou, and Jingren Zhou. #instag: Instruction tagging for analyzing supervised fine-tuning of large language models, 2023.
[50] Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering, 2018.
[51] Anand Mishra, Shashank Shekhar, Ajeet Kumar Singh, and Anirban Chakraborty. Ocr-vqa: Visual question answering by reading text in images. In 2019 international conference on document analysis and recognition (ICDAR), pages 947–952. IEEE, 2019.
[52] Thuat Nguyen, Chien Van Nguyen, Viet Dac Lai, Hieu Man, Nghia Trung Ngo, Franck Dernoncourt, Ryan A Rossi, and Thien Huu Nguyen. CulturaX: A Cleaned, Enormous, and Multilingual Dataset for Large Language Models in 167 Languages. arXiv preprint arXiv:2309.09400, 2023.
[53] OpenAI. ChatML, 2022. URL https://github.com/openai/openai-python/blob/ e389823ba013a24b4c32ce38fa0bd87e6bccae94/chatml.md.
[54] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training Language Models to Follow Instructions with Human Feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
[55] Keiran Paster. Testing language models on a held-out high school national finals exam. https: //huggingface.co/datasets/keirp/hungarian_national_hs_finals_exam, 2023.
[56] Guilherme Penedo, Quentin Malartic, Daniel Hesslow, Ruxandra Cojocaru, Alessandro Cappelli, Hamza Alobeidli, Baptiste Pannier, Ebtesam Almazrouei, and Julien Launay. The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only, 2023.
[57] Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Jonathan Heek, Kefan Xiao, Shivani Agrawal, and Jeff Dean. Efficiently Scaling Transformer Inference. Proceedings of Machine Learning and Systems, 5, 2023.
[58] Jack W Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, Francis Song, John Aslanides, Sarah Henderson, Roman Ring, Susannah Young, et al. Scaling Language Models: Methods, Analysis & Insights from Training Gopher. arXiv preprint arXiv:2112.11446, 2021. 23
[59] Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. arXiv preprint arXiv:2305.18290, 2023.
[60] Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. ZeRO: Memory Optimizations Toward Training Trillion Parameter Models. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–16. IEEE, 2020.
[61] Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. SQuAD: 100,000+ Questions for Machine Comprehension of Text, 2016.
[62] Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. WinoGrande: An Adversarial Winograd Schema Challenge at Scale, 2019.
[63] Maarten Sap, Hannah Rashkin, Derek Chen, Ronan LeBras, and Yejin Choi. SocialIQA: Commonsense Reasoning about Social Interactions, 2019.
[64] Nikhil Sardana and Jonathan Frankle. Beyond chinchilla-optimal: Accounting for inference in language model scaling laws. arXiv preprint arXiv:2401.00448, 2023.
[65] Rylan Schaeffer, Brando Miranda, and Sanmi Koyejo. Are emergent abilities of large language models a mirage? Advances in Neural Information Processing Systems, 36, 2024.
[66] Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, and Aran Komatsuzaki. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs. arXiv preprint arXiv:2111.02114, 2021.
[67] Noam Shazeer. Fast Transformer Decoding: One Write-Head is All You Need. arXiv preprint arXiv:1911.02150, 2019.
[68] Noam Shazeer. GLU Variants Improve Transformer. arXiv preprint arXiv:2002.05202, 2020.
[69] Yusuxke Shibata, Takuya Kida, Shuichi Fukamachi, Masayuki Takeda, Ayumi Shinohara, Takeshi Shinohara, and Setsuo Arikawa. Byte Pair Encoding: A Text Compression Scheme That Accelerates Pattern Matching. Technical report, Technical Report DOI-TR-161, Department of Informatics, Kyushu University, 1999.
[70] Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. arXiv preprint arXiv:1909.08053, 2019.
[71] Oleksii Sidorov, Ronghang Hu, Marcus Rohrbach, and Amanpreet Singh. Textcaps: a dataset for image captioning with reading comprehension. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part II 16, pages 742–758. Springer, 2020.
[72] Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R. Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, Agnieszka Kluska, Aitor Lewkowycz, Akshat Agarwal, Alethea Power, Alex Ray, Alex Warstadt, Alexander W. Kocurek, Ali Safaya, Ali Tazarv, Alice Xiang, Alicia Parrish, Allen Nie, Aman Hussain, Amanda Askell, Amanda Dsouza, Ambrose Slone, Ameet Rahane, Anantharaman S. Iyer, Anders Andreassen, Andrea Madotto, Andrea Santilli, Andreas Stuhlmüller, Andrew Dai, Andrew La, Andrew Lampinen, Andy Zou, Angela Jiang, Angelica Chen, Anh Vuong, Animesh Gupta, Anna Gottardi, Antonio Norelli, Anu Venkatesh, Arash Gholamidavoodi, Arfa Tabassum, Arul Menezes, Arun Kirubarajan, Asher Mullokandov, Ashish Sabharwal, Austin Herrick, Avia Efrat, Aykut Erdem, Ayla Karaka¸s, B. Ryan Roberts, Bao Sheng Loe, Barret Zoph, Bartłomiej Bojanowski, Batuhan Özyurt, Behnam Hedayatnia, Behnam Neyshabur, Benjamin Inden, Benno Stein, Berk Ekmekci, Bill Yuchen Lin, Blake Howald, Bryan Orinion, Cameron Diao, Cameron Dour, Catherine Stinson, Cedrick Argueta, César Ferri Ramírez, Chandan Singh, Charles Rathkopf, Chenlin Meng, Chitta Baral, Chiyu Wu, Chris Callison-Burch, Chris Waites, Christian Voigt, Christopher D. Manning, Christopher Potts, Cindy Ramirez, Clara E. Rivera, Clemencia Siro, Colin Raffel, Courtney Ashcraft, Cristina Garbacea, Damien Sileo, Dan Garrette, Dan Hendrycks, Dan Kilman, Dan Roth, Daniel Freeman, Daniel Khashabi, 24 Daniel Levy, Daniel Moseguí González, Danielle Perszyk, Danny Hernandez, Danqi Chen, and Daphne Ippolito et al. (351 additional authors not shown). Beyond the Imitation Game: Quantifying and Extrapolating the Capabilities of Language Models, 2023.
[73] Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. Roformer: Enhanced Transformer with Rotary Position Embedding. arXiv preprint arXiv:2104.09864, 2021.
[74] Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V Le, Ed H Chi, Denny Zhou, et al. Challenging BigBench Tasks and Whether Chain-of-Thought can Solve Them. arXiv preprint arXiv:2210.09261, 2022.
[75] Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge, 2019.
[76] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
[77] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. Llama 2: Open Foundation and Fine-Tuned Chat Models, 2023.
[78] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention Is All You Need. Advances in Neural Information Processing Systems, 06 2017. URL https://arxiv.org/pdf/1706.03762.pdf.
[79] Guillaume Wenzek, Marie-Anne Lachaux, Alexis Conneau, Vishrav Chaudhary, Francisco Guzmán, Armand Joulin, and Edouard Grave. CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data. arXiv preprint arXiv:1911.00359, 11 2019. URL https: //arxiv.org/pdf/1911.00359.pdf.
[80] Guillaume Wenzek, Marie-Anne Lachaux, Alexis Conneau, Vishrav Chaudhary, Francisco Guzmán, Armand Joulin, and Edouard Grave. CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data. arXiv preprint arXiv:1911.00359, 2019.
[81] Xiaoxia Wu, Cheng Li, Reza Yazdani Aminabadi, Zhewei Yao, and Yuxiong He. Understanding int4 quantization for transformer models: Latency speedup, composability, and failure cases. arXiv preprint arXiv:2301.12017, 2023.
[82] Wenhan Xiong, Jingyu Liu, Igor Molybog, Hejia Zhang, Prajjwal Bhargava, Rui Hou, Louis Martin, Rashi Rungta, Karthik Abinav Sankararaman, Barlas Oguz, et al. Effective long-context scaling of foundation models. arXiv preprint arXiv:2309.16039, 2023.
[83] Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, and Daxin Jiang. Wizardlm: Empowering large language models to follow complex instructions. arXiv preprint arXiv:2304.12244, 2023.
[84] Aiyuan Yang, Bin Xiao, Bingning Wang, Borong Zhang, Ce Bian, Chao Yin, Chenxu Lv, Da Pan, Dian Wang, Dong Yan, Fan Yang, Fei Deng, Feng Wang, Feng Liu, Guangwei Ai, Guosheng Dong, Haizhou Zhao, Hang Xu, Haoze Sun, Hongda Zhang, Hui Liu, Jiaming Ji,Jian Xie, JunTao Dai, Kun Fang, Lei Su, Liang Song, Lifeng Liu, Liyun Ru, Luyao Ma, Mang Wang, Mickel Liu, MingAn Lin, Nuolan Nie, Peidong Guo, Ruiyang Sun, Tao Zhang, Tianpeng Li, Tianyu Li, Wei Cheng, Weipeng Chen, Xiangrong Zeng, Xiaochuan Wang, Xiaoxi Chen, Xin Men, Xin Yu, Xuehai Pan, Yanjun Shen, Yiding Wang, Yiyu Li, Youxin Jiang, Yuchen Gao, Yupeng Zhang, Zenan Zhou, and Zhiying Wu. Baichuan 2: Open Large-scale Language Models. 09 2023. URL https://arxiv.org/pdf/2309.10305.pdf.
[85] Peter Young, Alice Lai, Micah Hodosh, and Julia Hockenmaier. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Transactions of the Association for Computational Linguistics, 2:67–78, 2014.
[86] Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. Orca: A Distributed Serving System for Transformer-Based Generative Models. In 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22), pages 521–538, 2022.
[87] Yijiong Yu, Zhe Zhou, Zhixiao Qi, and Yongfeng Huang. Paraphrasing the original text makes high accuracy long-context qa. arXiv preprint arXiv:2312.11193, 2023.
[88] Ji Yunjie, Deng Yong, Gong Yan, Peng Yiping, Niu Qiang, Zhang Lei, Ma Baochang, and Li Xiangang. Exploring the impact of instruction data scaling on large language models: An empirical study on real-world use cases. arXiv preprint arXiv:2303.14742, 2023.
[89] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a Machine Really Finish Your Sentence?, 2019.
[90] Xiaotian Zhang, Chunyang Li, Yi Zong, Zhengyu Ying, Liang He, and Xipeng Qiu. Evaluating the Performance of Large Language Models on GAOKAO Benchmark. arXiv preprint arXiv:2305.12474, 2023.
[91] Yanzhe Zhang, Ruiyi Zhang, Jiuxiang Gu, Yufan Zhou, Nedim Lipka, Diyi Yang, and Tong Sun. Llavar: Enhanced visual instruction tuning for text-rich image understanding. arXiv preprint arXiv:2306.17107, 2023.
[92] Huaixiu Steven Zheng, Swaroop Mishra, Xinyun Chen, Heng-Tze Cheng, Ed H. Chi, Quoc V Le, and Denny Zhou. Take a step back: Evoking reasoning via abstraction in large language models, 2023.
[93] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric. P Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena, 2023.
[94] Chunting Zhou, Pengfei Liu, Puxin Xu, Srini Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, Susan Zhang, Gargi Ghosh, Mike Lewis, Luke Zettlemoyer, and Omer Levy. Lima: Less is more for alignment, 2023.
[95] Yuke Zhu, Oliver Groth, Michael Bernstein, and Li Fei-Fei. Visual7w: Grounded question answering in images. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4995–5004, 2016.