探索ChatGPT时代下的下一代信息检索系统:机遇与挑战
1 Introduction
2022 年 11 月 30 日,OpenAI 推出了 ChatGPT,这是一款由先进的 GPT3.5 和更高版本的 GPT-4 生成语言模型提供支持的 AI 聊天机器人应用程序。该应用迅速吸引了全球超亿用户,创下了产品快速传播的新纪录。

它能够以对话的方式与人交互, 包括根据上下文回答问题、 承认错误、 挑战错误、 拒绝用户不恰当的请求等。以 ChatGPT 为代表 的大型语言模型 (Large Language Models, LLMs) 不仅能够理解用户的意图和情感, 还能够生成有趣和有创意的内容, 如诗歌、 故事、 歌词等。
GPT-4 进一步扩展了这些功能,提供增强的理解、准确性和上下文相关性。从 GPT-3.5 到 GPT-4 的演变在众多信息检索任务中显示出了巨大的前景,特别是在文本分类、文档排名、问答系统和多模态检索方面。ChatGPT 的引入利用了这些进步,刺激了该领域的进步,凸显了大型语言模型 (LLM) 在理解和生成语义信息方面的令人印象深刻的能力。
2 ChatGPT in IR
随着预训练大型语言模型(PLLM)的出现,信息检索领域经历了显着的转变。这种从最初的简单模型发展到当前先进的密集检索模型的演变,显着拓宽了信息检索及相关领域的范围和能力。下表未近年来预训练大模型的比较。
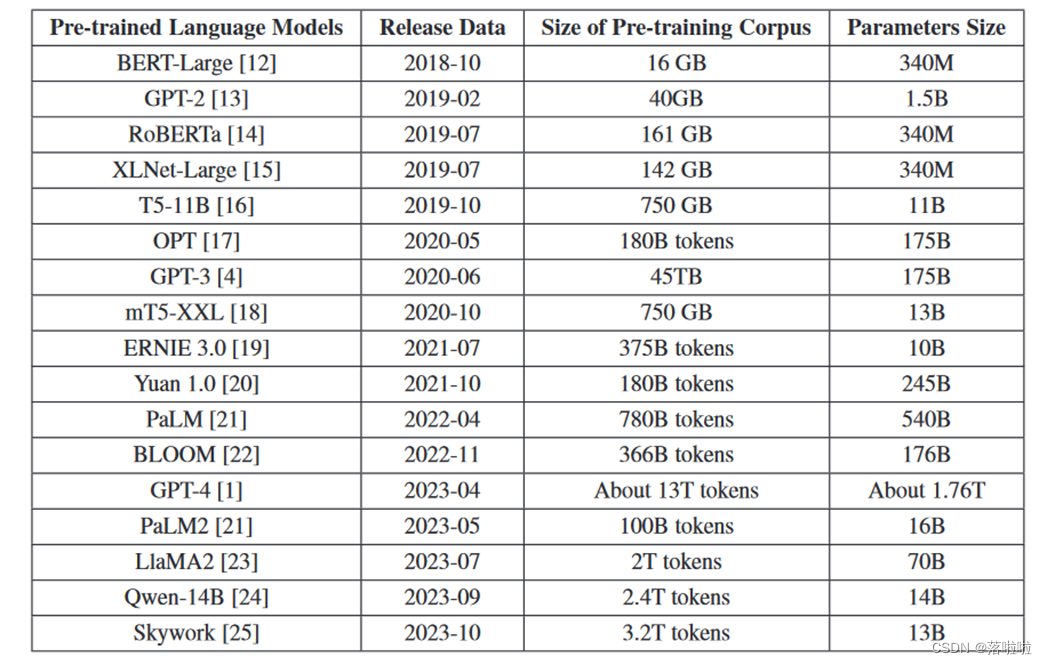
ChatGPT 通过使用其广泛的内部知识库理解和响应查询,为 IR 做出了重大贡献。与传统搜索引擎不同,ChatGPT 通过生成有用的答案来简化用户体验,而不需要用户具备特定知识,使其成为执行各种任务的宝贵工具。一个典型的场景是 ChatGPT 在理解包含语法或拼写错误的查询方面的稳健性。即使用户提交的查询存在如此不准确的情况,ChatGPT 也会有效地解释其预期含义,并提供包含正确语法和拼写的响应。此功能增强了用户体验,确保由于语言熟练程度或打字错误而导致的沟通障碍不会妨碍准确且相关的信息的检索。
3 潜在机遇
在大模型时代,以ChatGPT为代表的生成模型正在为信息检索的核心任务引入新的视角和方法论。 IR 系统旨在从大量文本数据中提取相关信息。传统的 IR 系统通常依赖于关键字匹配。然而,随着神经网络和深度学习的出现,信息检索正在逐步向基于语义的检索发展。
- GPT-X的深度神经网络能够深刻理解文本语义,提高语义级检索的精度,超越传统的关键词级文本匹配。他们的生成框架允许制定精确的查询表达式并生成描述性检索结果,从而增强了 IR 的灵活性和表现力。
- 端到端的训练方法最大限度地减少错误传播,并直接优化从输入到输出的性能,提高检索准确性和效率。
- 多模态信息检索的潜力将范围从文本扩展到图像和视频,提供更丰富、更准确的检索结果。
- 集成知识图谱在检索过程中利用结构化知识,同时帮助知识图谱的构建和更新,从而为IR提供更丰富的知识库。
3.1 信息提取
信息提取(IE)是信息检索中的一项基本任务,包括命名实体识别(NER)和事件提取(EE)等子任务。多年来,IE 已经发生了显著的发展。最初,重点是结构化和半结构化数据提取,采用各种技术、工具和系统自动提取有用信息。早期的 IE 系统主要是基于规则的,依赖于大量的人类参与,并且针对化学或医学搜索等特定领域进行定制。

进入当代,该领域已经转向采用深度学习技术,该技术擅长从非结构化文本中提取结构化信息,而不受特定领域的限制。深度学习的核心思想是从原始数据中提取特征,以数据驱动的方式,通过一系列非线性变换,从低层到高层、从具体到抽象。这些方法显着提高了语音识别、视觉目标识别、目标检测等各个领域的先进水平,展示了深度学习在处理复杂IE任务方面的功效。
此外,研究人员希望这些大规模语言模型能够有效地处理文本并提取有价值的信息,而无需重新训练,从而有可能取代手动注释。在 ChatGPT 上进行的多项广泛的 IE 实验激发了 IE 的新研究视角,例如 IE 任务可以分解为多个更简单的子任务的可能性 ,对评估策略的重新思考可能反映 ChatGPT 更准确的性能 ,通过及时的工程设计可以显着提高ChatGPT的性能。
3.2 文本分类
传统的文本分类方法通常依赖于统计学习范式,例如朴素贝叶斯和 K 最近邻。这些方法需要在特征工程方面付出大量努力来构建有意义的文本表示。随后,随着深度神经网络的出现,RNN、CNN 和图神经网络 (GNN) 等模型已成为主流范式,显着自动化了文本丰富语义表示的构建。
进入LLMs时代,ChatGPT 等模型对文本分类任务产生了显着影响。这些模型通过有监督的预训练技术,从海量文本语料库中实现高质量的文本语义建模,大大提高了文本分类任务的性能。特别是在解决开放域任务、域适应、少样本(模型从一小组标记示例中学习)和零样本(模型泛化到看不见的类)问题时,这些大型模型表现出令人印象深刻的性能和出色的泛化能力。
从信息检索的角度来看,文本分类是对文本数据进行排序和分类的重要机制,有助于有效地检索和管理信息。文本分类任务结合知识图谱和基于LLM的小样本学习能力,可以从海量数据中提取和利用相关信息,实现更准确、更高效的分类。
3.3 文档排序
文档排序是信息检索系统中的一个关键过程,它根据估计的与查询的相关性来确定检索到的文档的呈现顺序。从历史上看,用于文档排名的方法主要集中在基于术语的匹配,利用术语频率-逆文档频率(TF-IDF)和 BM25 等标准技术。这些传统方法评估文档中术语的重要性及其与当前查询的相应相关性。然而,它们常常无法捕捉术语之间的语义关系,并且可能会忽略上下文相关性,而上下文相关性对于提高文档检索的精度越来越重要。
深度学习模型开始受到关注后, CNN、RNN 和基于注意力的机制(例如 BERT )已被用来增强文本数据的表示并提高对自然语言查询的理解。大语言模型的出现为 IR 中的文档排名开辟了新的可能性。调查显示,在正确指导下,与流行 IR 基准上的监督方法相比,ChatGPT 可以提供有竞争力甚至更优越的排名性能 。 GPT-4 的出现进一步突破了界限,展示了人工智能驱动的文档排名,对搜索引擎领域产生了重大影响。
此外,特定领域的文档排名成为 GPT-4 应用的一个有前景的领域。目前,排名方法严重依赖训练数据和微调。然而,医学和法律等专业领域高质量注释数据集的稀缺构成了重大挑战,阻碍了部署预训练模型对文档进行排名的有效性。像 GPT-4 这样的LLMs由于其庞大的训练数据范围而被赋予了广泛的知识和显着的泛化能力,提供了一个可行的解决方案。这些模型有潜力在这种情况下充当数据增强工具,合成伪标签数据,可以提高检索模型在数据稀缺情况下的性能。通过生成相关的数据,GPT-4 可以显着增强模型在特定领域场景中对文档进行准确排名的能力,从而弥合数据差距并促进提高文档检索任务的性能。
3.4 会话搜索
多年来,会话搜索 (CS) 取得了显着发展,从基于规则的模型过渡到当今流行的更先进的机器学习和深度学习模型 。传统上,它分为两个主要子任务:面向任务和开放对话/交互式任务。
- 面向任务的会话式IR(信息检索)系统采用管道方法,集成了意图识别、对话管理和响应生成等多个模块来处理用户交互。
- 开放对话式 IR 系统旨在让用户参与更多社交、更少目标导向的对话。
最初,这些系统依赖于基于检索的方法,但生成模型的出现允许更流畅和自然的响应 。它们的功能类似于 IR 系统,从预先设计的数据库中提取相关信息。基于 Transformer 的模型的引入,例如 OpenAI 的 ChatGPT,标志着 CS 领域的范式转变。这些模型能够根据给定的上下文生成类似人类的文本,从而扩展了面向任务和开放域 CS 系统的可能性。
随着 ChatGPT 和 GPT-4 等模型的贡献,该领域不断进步。得益于这些模型的意图理解、语义解析和 API 集成能力,现在可以在单一技术框架下实现面向任务和开放领域对话的结合。这种结合可能会促进 CS 系统的开发,这些系统不仅具有功能性,而且具有情感智能,可以满足用户的实际需求。此外,追求创建更加个性化的计算机科学系统仍然是一个重要的研究和开发领域。这些领域的进步预计将推动 CS 系统更接近提供真正的类人且丰富的对话体验。
4 未解决的挑战
4.1 幻觉
幻觉( Hallucination )是一种模型生成令人信服但事实上不正确或误导性内容的现象,存在严重风险。这在决策等关键应用中尤其令人担忧,其中错误信息的传播可能会导致不良结果。
信息检索策略有望有助于解决幻觉挑战。一种可行的方法是建立一个连续的反馈循环,其中模型的输出经过严格评估,并根据发现的不准确之处进行改进。这个迭代过程旨在随着时间的推移提高模型的准确性和可靠性。具体来说,将 IR 模型与LLMs结合起来可以提供一个强大的解决方案 。通过利用从外部来源提取的更新且准确的信息来增强LLMs,IR 模型可以潜在地减少事实上不准确的反应的产生,从而减少幻觉的发生。
4.2 道德和安全问题
由于 ChatGPT 深刻的语言理解和生成能力,围绕 ChatGPT 的道德和安全问题是多方面的。
- 模型的广泛训练数据和复杂性引入了与偏见和公平相关的风险。由于训练数据源自人类生成的内容,可能会无意中延续现有的社会偏见。模型表现出性别或种族偏见的例子就是这个问题的象征。
- 生成式人工智能的出现带来了与错误信息和滥用相关的挑战。他们生成文本的能力可被用来制造误导性信息,助长在线错误信息活动,甚至生成有害或辱骂性内容。 ChatGPT 生成的内容缺乏来源归属加剧了这个问题,用户可能很难辨别生成内容的真实性。
- 生成式人工智能可能被滥用于欺诈或骚扰等犯罪活动。LLMs可用于为邪恶目的创建虚假内容,从而降低成本并提高执行欺诈活动的效率。
- 模型的可扩展性加剧了隐私问题。随着模型变得越来越大并且需要更多的计算资源,将处理卸载到云服务器的需求也随之增加。这种集中化可能会增加数据泄露和个人信息滥用的风险,特别是在没有采取足够措施来保护用户数据的情况下。
4.3 可解释性
随着语言模型随着参数和深度的增加而变得更加复杂,它们的决策过程变得越来越难以解释。这种复杂性也挑战了理解深度神经网络中的向量和参数表示。虽然用户可以观察输入和输出,但其间复杂的过程仍然隐藏,从而无法清楚地理解模型如何从给定输入导出特定输出。这种不透明性导致无法辨别模型认为重要的输入数据的哪些方面,从而模糊了可解释性。
检索增强机器学习提出了一种解决可解释性问题的方法。在预训练的语言模型中,训练知识嵌入在学习的模型参数中,使得模型预测难以理解。相反,当推理过程依赖于检索到的信息时,预测可以直接链接到特定数据,通常以可访问的文本格式存储。此功能提高了模型输出的可解释性。
5 总结与未来工作
ChatGPT 标志着生成人工智能领域的显着进步,丰富了多种信息检索任务。然而,这一进步并非没有挑战。错误信息、虚假信息和潜在滥用有害内容等道德困境引起了严重关注。此外,可解释性的挑战仍然是一个巨大的障碍。为了应对这些挑战,最近的工作在这些领域取得了长足的进步。我们注意到,公平检索方法已显示出减轻 PLLM 偏见的潜力,促进更公平和公正的内容生成。此外,检索增强学习方法的应用已被认为有利于解决可解释性问题。
ChatGPT 的出现体现了人工智能发展的更广泛的前景,充满了技术创新的潜力以及解决道德、安全和隐私挑战的必要性。持续研究和积极采取措施来缓解这些挑战,同时探索负责任地利用这些模型的力量的新方法,将有助于应对人工智能的复杂性。研究人员、从业者和政策制定者之间的合作对于实现人工智能显着增强人类能力同时维护道德和社会价值观的未来至关重要。
参考文献
