DenseNet《Densely Connected Convolutional Networks》
DenseNet学习笔记
- 摘要
- 引言
- DenseNets
- ResNets
- Dense connectivity
- ResNet 和 DenseNet 的对比
- DenseBlock 向前传播的过程
- Composite function
- Pooling layers
- Growth rate
- Bottleneck layers
- Compression 压缩
- 实现细节
- 实验
- 训练
- 代码复现
摘要
最近的研究表明,如果卷积网络在靠近输入和接近输出的层之间包含更短的连接,那么卷积网络可以更深入、更准确、更有效地训练。
在本文中,作者接受了这一观察结果,并引入了密集卷积网络(DenseNet),它以前馈方式将每一层连接到其他每一层。
传统的 L L L 层卷积网络有 L L L 个连接——每一层和它的后续层之间有一个连接,而作者提出的网络有 L ( L + 1 ) 2 \frac{L(L+1)}{2} 2L(L+1) 个直接连接。
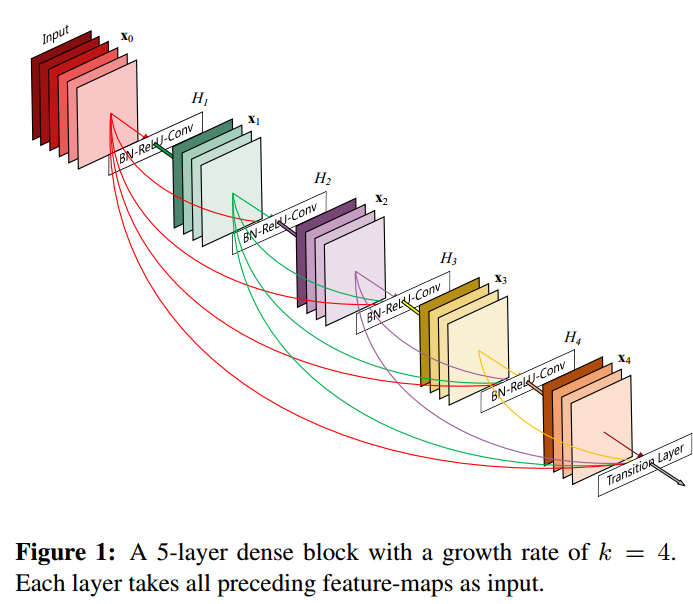
这张配图, H H H 表示的是由批量归一化(BN)、ReLU激活函数和卷积层(Conv)组成的非线性映射层。每个 dense block 包含的非线性映射层数目不固定,它取决于网络的整体设计和深度。在这个示例中,如果考虑到输入层 x 0 x_0 x0,那么这个 dense block 由5层组成,其中包括4个 H H H 非线性映射层和一个输入层。
DenseNet 的一个核心概念是每一层都直接与之前所有层相连(在特征图尺寸相同的情况下),这意味着每一层都会接收到前面所有层的特征图作为其输入,这有助于信息和梯度在网络中的流动,减少了梯度消失的问题,同时每一层都可以访问到前面所有层学习到的特征图。这种密集连接的设计也促进了特征的重用,并允许网络有更高的参数效率。
在 DenseNet 中,由于每一层都向后续层传递其学习到的特征,所以每个非线性映射层产生的输出特征图数(即增长率 k k k)通常可以设置得比传统卷积网络中的小得多。
对于每一层,使用所有之前层的特征图作为输入,并使用其自身的特征图作为所有后续层的输入。DenseNets 有几个引人注目的优点:
- 缓解了梯度消失问题,
- 加强了特征传播,鼓励特征重用,
- 大大减少了参数的数量。
作者在四个高度竞争的目标识别基准任务(CIFAR-10、CIFAR-100、SVHN和ImageNet)上评估了提出的架构。DenseNets在大多数情况下获得了最先进的显著改进,同时需要更少的计算来实现高性能。
引言
随着cnn变得越来越深,一个新的问题出现了:当关于输入或梯度的信息通过许多层时,当到达网络的末端(或开始)时(输入到达末端,梯度反向传播到达开始),输入或梯度可能会消失
一些方法尝试解决这个问题,尽管这些不同的方法在网络拓扑结构和训练过程上各不相同,但它们都有一个关键特征:创建了从早期层到后期层的短路径。
为了确保网络中各层之间的最大信息流,作者将所有层(具有匹配的特征图大小)直接相互连接(在通道维度进行 concatenation )。为了保持前馈性质,每一层从所有之前层获得额外的输入,并将自己的特征图传递给所有后续层。图1说明了这种布局。
关键的是,与 ResNets 相比,作者从未在将特征传递到一个层之前通过求和来组合特征;相反,通过 concatenation 来组合特征。
DenseNet的关键特点在于与ResNet的主要区别:在DenseNet中,层与层之间的特征不是通过特征图的元素级求和(sum)来结合,而是通过通道维度进行拼接(concatenation)来结合。
这意味着,每个层接收到的输入是所有先前层输出特征图的集合,而不是仅仅是前一层的输出或前一层输出的累积。这样做有几个优点:
-
特征传播:由于每个层都直接与之前的所有层相连,信息在网络中的传播更为直接和完整,这有助于减轻梯度消失问题,因为梯度可以直接从损失函数流向任何层。
-
特征重用:每个层都可以利用网络先前学到的所有特征,这鼓励了特征的重复利用。
-
参数效率:由于特征重用,网络不需要重新学习冗余的特征,因此即使是非常深的网络也可以有较少的参数。
传统的前馈体系结构可以被视为具有状态的算法,这种状态在层与层之间传递。每一层从前一层读取状态,并写入后继层。
传统的前馈体系结构改变了状态,但也传递了需要保存的信息。ResNets 通过加性恒等映射使这种信息保存显式地实现。
ResNets 的最新变化表明,许多层的贡献非常小,实际上可以在训练期间随机丢弃。这使得ResNets的状态类似于(展开的)递归神经网络,但ResNets的参数数量要大得多,因为每层都有自己的权重。
作者提出的DenseNet架构明确区分了添加到网络中的信息(当前层的输出)和保留的信息(之前层的输出)。
DenseNet 层网络宽度非常窄(例如,每层12个卷积核),只向网络的“集体知识”(之前所有层输出的特征图集合)中添加一小部分特征图,并保持剩余的特征图不变,最终分类器根据网络中的所有特征图做出决策。
除了更好的参数效率外,DenseNets 的一大优势是其改进了整个网络的信息流和梯度,这使得它们易于训练。每一层都可以直接访问损失函数和原始输入信号的梯度,从而实现隐式深度监督。这有助于训练更深层次的网络架构。
此外,作者还观察到密集连接具有正则化效应,这减少了训练集规模较小的任务的过拟合。
计算机视觉的卷积神经网络某一层的宽度是指的通道数还是神经元数量?
计算机视觉中的卷积神经网络(CNN)中,某一层的“宽度”通常指的是该层的通道数,也就是特征图(feature
maps)的数量。每个通道可以被视为对输入数据的一种特征响应,而不同的通道可能会捕捉到输入数据的不同特征。
如何理解论文中下面这句话? In fact, simply increasing the number of filters in each
layer of ResNets can improve its performance provided the depth is
sufficient.这句话指出的是在深度充分的条件下(即网络足够深),通过简单地增加ResNet中每一层的滤波器(或称为卷积核)数量,可以提升网络的性能。这是因为:
增加特征表示的能力:增加每层的滤波器数量会导致该层可以学习更多的特征表示。不同的滤波器能够捕捉到不同的特征,从而使网络能够从输入数据中提取更丰富的信息。
增强网络的学习能力:随着滤波器数量的增加,网络的学习能力也随之提升。更多的滤波器意味着网络可以在学习过程中探索更多的数据表示形式,这通常会导致性能的提升。
避免过早饱和:在深度学习中,如果网络的深度足够,增加层的宽度(滤波器数量)可以避免学习过程中的过早饱和。如果网络太窄(即层的宽度不足),即使网络很深,也可能无法充分利用其深度,因为层之间无法传递足够多的信息。
适应更深层次的抽象:更深的网络能够捕捉到更复杂和更深层次的数据抽象。随着网络深度的增加,为了充分利用深层次的抽象能力,就需要更多的滤波器来捕捉这些深层次的特征。
参数和特征图之间的平衡:在网络的不同层之间需要保持一种平衡。如果网络的深度很大,但每层的滤波器数量很少,可能会导致信息瓶颈,限制了网络性能的提升。相反,如果增加滤波器数量,就可以保证足够的特征通过网络传播,从而提高性能。
需要注意的是,尽管增加滤波器数量可以提升性能,但这也会导致计算成本和模型参数的增加,这可能会导致更高的训练时间和更大的过拟合风险。因此,在实际应用中需要在模型大小、计算成本和性能之间找到一个平衡点。
DenseNets 不是从极深或极宽的网络结构中提取表征能力,而是通过特征重用利用网络的潜力,产生易于训练且参数效率高的浓缩模型。将不同层学习到的特征图连接起来,增加了后续层输入的变化,提高了效率。这是 DenseNets 和 ResNets 之间的主要区别。
还有其他值得注意的网络架构创新产生了竞争性结果。
在深度监督网络(DSN)中,内部层由辅助分类器直接监督,这可以增强之前层接收到的梯度。
深度融合网络(deep - fused Nets, DFNs),通过结合不同基础网络的中间层来改善信息流。
DenseNets
考虑单张图像 x 0 \textbf{x}_0 x0 通过 L L L 层的卷积网络,每一层实现一个非线性映射 H ℓ ( ⋅ ) H_{\ell}(\cdot) Hℓ(⋅)
H ℓ ( ⋅ ) H_{\ell}(\cdot) Hℓ(⋅) 是由一组操作组成的复合函数,
具体而言是这三个操作,Batch Normalization, ReLU, 卷积或池化。
将 ℓ t h \ell^{th} ℓth 层的输出记为 x ℓ \textbf{x}_{\ell} xℓ
ResNets
传统的前馈网络将 ℓ t h \ell^{th} ℓth 层的输出作为 ( ℓ + 1 ) t h (\ell+1)^{th} (ℓ+1)th 层的输入,那么对于 ResNets 可以导出如下的 layer transition: x ℓ = H ℓ ( x ℓ − 1 ) + x ℓ − 1 ( 1 ) \textbf{x}_{\ell}=H_{\ell}(\textbf{x}_{\ell-1})+\textbf{x}_{\ell-1}\ \ \ \ \ (1) xℓ=Hℓ(xℓ−1)+xℓ−1 (1) ResNets 的一个优点是梯度可以直接通过恒等映射从深层反向传播到浅层。
然而,恒等映射和 H ℓ H_{\ell} Hℓ 的输出以元素求和的方式组合在一起,这可能会阻碍网络中的信息流动。
Dense connectivity
如图 1, ℓ t h \ell^{th} ℓth 层接收之前所有层的特征图( x 0 , ⋯ , x ℓ − 1 \textbf{x}_0,\cdots,\textbf{x}_{\ell-1} x0,⋯,xℓ−1)作为输入: x ℓ = H ℓ ( [ x 0 , x 1 , ⋯ , x ℓ − 1 ] ) ( 2 ) \textbf{x}_{\ell}=H_{\ell}([\textbf{x}_0,\textbf{x}_1,\cdots,\textbf{x}_{\ell-1}])\ \ \ \ (2) xℓ=Hℓ([x0,x1,⋯,xℓ−1]) (2)其中 [ x 0 , x 1 , ⋯ , x ℓ − 1 ] [\textbf{x}_0,\textbf{x}_1,\cdots,\textbf{x}_{\ell-1}] [x0,x1,⋯,xℓ−1] 这个整体代表在 0 , ⋯ , ℓ − 1 0,\cdots,\ell-1 0,⋯,ℓ−1 层生成的特征图经过 concatenation 拼接的特征图
为便于实现,作者将等式 (2) 中 H ℓ ( ⋅ ) H_{\ell}(\cdot) Hℓ(⋅) 的多个输入 concatenate 连接到一个张量中,形成 [ x 0 , x 1 , ⋯ , x ℓ − 1 ] [\textbf{x}_0,\textbf{x}_1,\cdots,\textbf{x}_{\ell-1}] [x0,x1,⋯,xℓ−1]
ResNet 和 DenseNet 的对比

DenseBlock 向前传播的过程
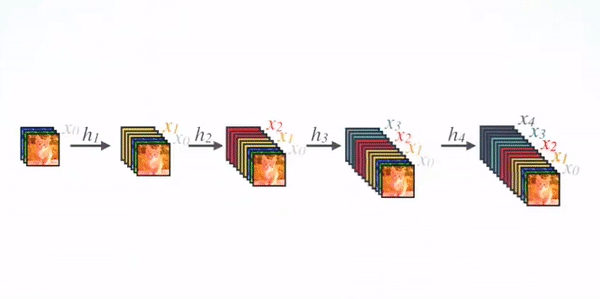
Composite function
将 H ℓ ( ⋅ ) H_{\ell}(\cdot) Hℓ(⋅) 定义为一个由三个连续操作组成的复合函数,三个连续操作分别为:
批归一化(BN),修正线性单元激活函数(ReLU) ,3 × 3 卷积(Conv)
Pooling layers
特征图的大小发生变化时,等式 (2) 中使用的 concatenate 操作是不可行的。
可以通过下采样改变特征图的大小

一个有三个 DenseBlock 的 DenseNet。两个相邻 DenseBlock 之间的层称为 Transition layers 过渡层,通过卷积和池化来改变特征图的大小。
为了便于下采样,作者将网络划分为多个紧密连接的密集块;
如上图。将块之间的层称为过渡层,它们进行卷积和池化。
作者实验中使用的 过渡层包括一个批处理归一化层和一个 1 × 1 1×1 1×1 卷积层,然后是一个 2 × 2 2×2 2×2 平均池化层。
Growth rate
DenseNet 和现有网络架构的一个重要区别是,DenseNet 可以有宽度非常窄的层,例如, k = 12 k = 12 k=12。作者将超参数 k k k 称为网络的增长率。
在第 4 节中表明,相对较小的增长率足以在作者测试的数据集上获得 SOTA 表现。
对此的一种解释是,每一层都可以访问其所在块中的所有之前层的特征图,因此可以访问网络的“集体知识”。
可以将特征图视为网络的全局状态。每一层向这个状态添加 k k k 个自己的特征图。
增长率决定了每一层对全局状态贡献多少新信息。
一旦写入全局状态,就可以从网络中的任何地方访问它,且与传统网络体系结构不同,不需要从一层到另一层复制它。
Bottleneck layers
虽然每一个非线性映射层只产生 k k k 个输出特征图,但通常有更多的输入特征图。
相关文献指出,可以在每次 3 × 3 3×3 3×3 卷积之前引入 1 × 1 1×1 1×1 卷积作为瓶颈层,以减少非线性映射层输入特征图的数量,从而提高计算效率。
作者发现这种设计对 DenseNet 特别有效,DenseNet 将具有这种瓶颈层的网络
即作为 DenseNet-B, H ℓ = B N − R e L U − C o n v ( 1 × 1 ) − B N − R e L U − C o n v ( 3 × 3 ) H_{\ell}= BN-ReLU-Conv(1× 1)-BN-ReLU-Conv(3×3) Hℓ=BN−ReLU−Conv(1×1)−BN−ReLU−Conv(3×3)
在作者的实验中, 让每个 1 × 1 1×1 1×1 卷积生成 4 k 4k 4k 个特征图。
Bottleneck layers 的作用
DenseNet中的bottleneck layers是为了提高网络计算效率和减少参数数量而设计的。在DenseNet中,由于每个层都与前面所有层直接连接,这就意味着随着网络深度的增加,后面的层会收到越来越多的输入特征图。这样一来,如果直接对这些特征图进行卷积,将会产生巨大的计算量和参数数量。为了解决这个问题,DenseNet在执行3x3卷积之前,引入了bottleneck layers,通常是一个1x1的卷积层。
bottleneck layer的作用是将输入的特征图数量减少,从而减少3x3卷积层的输入深度(通道数),这可以大幅降低参数数量和计算成本。
1x1的卷积(也被称为点卷积)的目的是进行特征图的线性组合,这样可以在不显著丢失信息的前提下减少特征图的数量。
在DenseNet中,这个bottleneck layer通常会将输入特征图的数量缩减到4k个(其中k是网络的增长率,即每个非线性映射层新增加的特征图数量)。因此,bottleneck layer有以下几个作用:
减少参数:通过减少进入3x3卷积层的特征图数量,bottleneck layer有效地降低了网络参数的数量。
提高计算效率:较少的输入特征图意味着3x3卷积的计算量减少,从而提高了网络的计算效率。
维持特征图的多样性:尽管1x1卷积减少了特征图的数量,但它通过线性组合的方式保持了特征的多样性。
降低过拟合风险:由于参数数量减少,bottleneck layers也可能帮助网络减少过拟合的风险。
过渡层下采样的原因:
DenseNet的每个DenseBlock后面跟着一个过渡层,其主要作用是减少特征图的数量(通过特征图数量的减少)和尺寸(通过平均池化)。这样做可以控制模型的计算和参数数量,使其不至于随着网络深度的增加而无限增长。
Compression 压缩
为了进一步提高模型的紧凑性,可以减少过渡层的特征图的数量。
如果一个密集块包含 m m m 个特征图,让其之后的过渡层生成 ⌊ θ m ⌋ ⌊θm⌋ ⌊θm⌋ 个输出特征图,
其中 0 < θ ≤ 1 0<θ≤1 0<θ≤1被称为压缩因子
当 θ = 1 θ = 1 θ=1 时,跨越过渡层的特征图数量保持不变。
将 θ < 1 θ <1 θ<1 的 DenseNet 称为 DenseNet- c,实验中取 θ = 0.5 θ = 0.5 θ=0.5
当瓶颈层和过渡层同时取 θ < 1 θ < 1 θ<1 ,作者将对应模型称为 DenseNet-BC。
实现细节
在除 ImageNet 以外的所有数据集上,实验中使用的 DenseNet 有 3 3 3 个密集块,每个块都有相同数量的层。
在进入第一个密集块之前,对输入图像执行输出通道为 16 16 16 的卷积(或DenseNet-BC增长率的两倍)
对于卷积核大小为 3 × 3 3×3 3×3 的卷积层,设置 p a d d i n g = 1 padding = 1 padding=1,以保持特征图大小不变
使用 1 × 1 1×1 1×1 卷积和 2 × 2 2×2 2×2 平均池化作为两个连续密集块之间的过渡层。
在最后一个密集块结束时,执行全局平均池化,然后附加一个 softmax 分类器。
三个密集块输出的特征图大小分别为 32 × 32 32× 32 32×32, 16 × 16 16×16 16×16 和 8 × 8 8×8 8×8。
对基本的 DenseNet 结构进行了实验,配置为
L = 40 , k = 12 {L = 40, k = 12} L=40,k=12, L = 100 , k = 12 {L = 100, k = 12} L=100,k=12 和 L = 100 , k = 24 {L = 100, k = 24} L=100,k=24
对于 DenseNetBC,计算配置为
L = 100 , k = 12 {L= 100, k= 12} L=100,k=12, L = 250 , k = 24 {L= 250, k= 24} L=250,k=24 和 L = 190 , k = 40 {L= 190, k= 40} L=190,k=40
在 ImageNet 上的实验中,作者在 224 × 224 224×224 224×224 输入图像上使用具有 4 4 4 个密集块的 DenseNet-BC 结构。
初始卷积层包括 2 k 2k 2k 个卷积,卷积核大小为 7 × 7 7×7 7×7,步长为 2 2 2 ;
所有其他层中的特征图的数量也遵循设置 k k k。
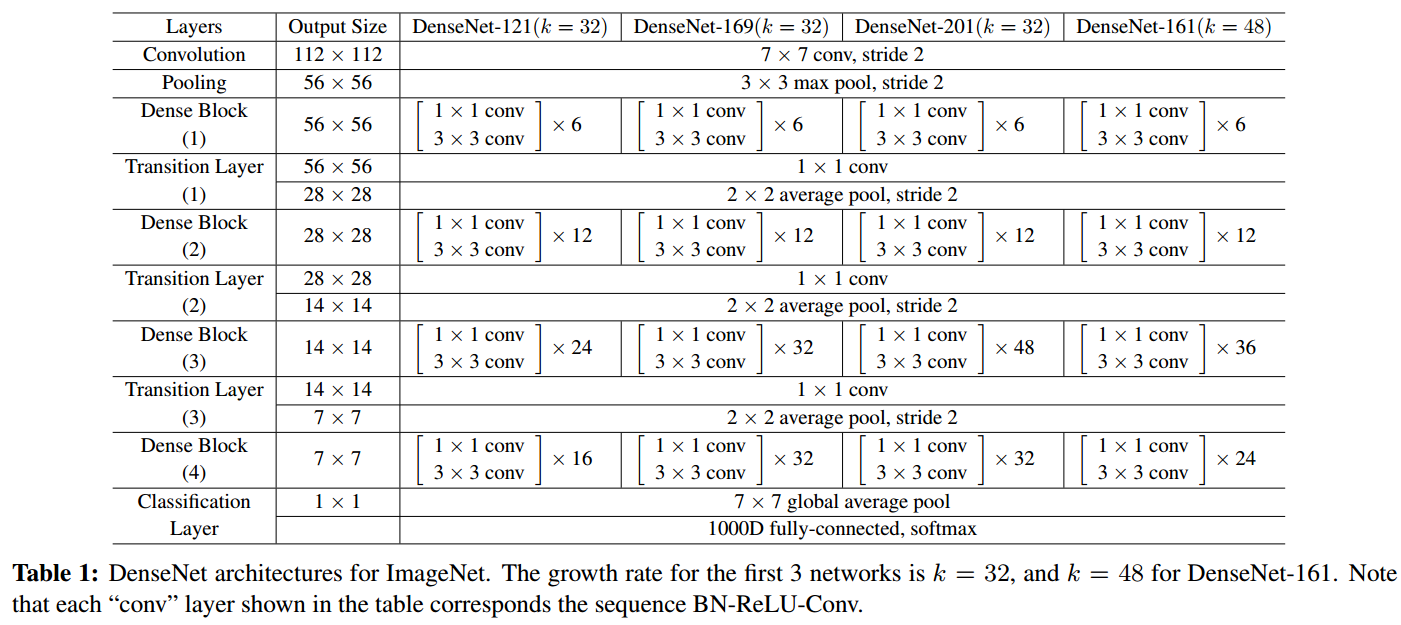
作者在 ImageNet 上使用的确切网络配置如表 1 所示。
实验
Output Size 这一列指的是当前这一行对应层输出的特征图尺寸
训练
在每个卷积层(除了第一层)之后添加一个dropout层 ,并将dropout率设置为0.2
代码复现
import torch
import torch.nn as nn
import torch.nn.functional as Fimport torchvision'''-------------构建初始卷积层和池化层-----------------------------'''
#定义一个名为Conv1的函数
def Conv1(in_planes, places, stride = 2):return nn.Sequential(#首先是2d卷积层,padding之所以为3是因为为了保持输出的特征图尺寸不变,按照计算公式,padding=(kernel_size-1)/2=3nn.Conv2d(in_channels=in_planes,out_channels=places,kernel_size=7,stride=stride,padding=3,bias=False),#然后是BN层nn.BatchNorm2d(places),#然后是激活层nn.ReLU(inplace=True),#最后是最大池化层nn.MaxPool2d(kernel_size=3, stride=2,padding=1))'''-------------构建DenseLayer非线性映射层,也就是H(*)映射-----------------------------'''
#最终返回的 torch.cat([x,y], 1) 是输入到下一个非线性映射层的特征图
class _DenseLayer(nn.Module):#定义__init__()方法,参数包含输入通道数 inplace,增长率,bn_size 定义了 bottleneck 层的大小,丢弃率#bn_size通常设置为4,意味着bottleneck层的输出通道数会是增长率growth_rate的4倍def __init__(self, inplace, growth_rate, bn_size, drop_rate=0):#调用父类__init__()方法,super(_DenseLayer,self).__init__()self.drop_rate = drop_rate#初始化 H 非线性映射self.dense_layer = nn.Sequential(#首先是BN层nn.BatchNorm2d(inplace),#然后是ReLunn.ReLU(inplace=True),#然后是卷积层,首先是 1*1 卷积核,输出通道数是bn_size*growth_rate意味着# 经过bottleneck layer将输入特征图数量减小为bn_size*growth_ratenn.Conv2d(in_channels=inplace, out_channels=bn_size*growth_rate, kernel_size=1, stride=1, padding=0, bias=False),#然后继续是BN-ReLu-3*3Convnn.BatchNorm2d(bn_size * growth_rate),nn.ReLU(inplace=True),#每个非线性映射层输出通道数是增长率nn.Conv2d(in_channels=bn_size * growth_rate, out_channels=growth_rate, kernel_size=3, stride=1, padding=1, bias=False),)# p 表示dropout层在训练过程中随机将输入的一部分元素置为 0 的概率。其目的是防止模型过拟合self.dropout = nn.Dropout(p=self.drop_rate)def forward(self, x):y = self.dense_layer(x)if self.drop_rate > 0:y = self.dropout(y)#参数1代表的是拼接的维度。在PyTorch中,维度0通常代表批量大小(batch size),维度1代表特征图的通道数。#在这个语句中,将输入x和新生成的特征y沿着通道维度进行拼接,生成下一个非线性映射层输入的特征图return torch.cat([x,y], 1)'''---构造DenseBlock模块---'''
class DenseBlock(nn.Module):#首先__init__()方法的参数要有非线性映射层的个数,输入通道数,增长率,bottleneck 层的大小,丢弃率def __init__(self, num_layers, inplaces, growth_rate, bn_size, drop_rate=0):super(DenseBlock, self).__init__()#创建一个非线性映射层列表,将所有的非线性映射层顺序排列layers = []#因为每个非线性映射层输出的特征图数量是 growth_rate,#所以随着层的增加,第i个非线性映射层的输入通道数是inplaces + i * growth_ratefor i in range(num_layers):# 向layers列表逐个添加非线性映射层layers.append(_DenseLayer(inplaces + i * growth_rate, growth_rate, bn_size, drop_rate))# nn.Sequential 创建一个顺序容器Sequential。这个容器将按照layers列表中的顺序,串联起所有的非线性映射层。# 这意味着输入数据会顺序通过这些层,每层的输出都会作为下一层的输入self.layers = nn.Sequential(*layers)def forward(self, x):return self.layers(x)'''-------------构造Transition layer-----------------------------'''
class _TransitionLayer(nn.Module):def __init__(self, inplace, place):super(_TransitionLayer, self).__init__()self.transition_layer = nn.Sequential(#首先是BN层nn.BatchNorm2d(inplace),#然后是ReLUnn.ReLU(inplace=True),nn.Conv2d(in_channels=inplace, out_channels=place, kernel_size=1, stride=1, padding=0, bias=False),nn.AvgPool2d(kernel_size=2, stride=2))def forward(self, x):return self.transition_layer(x)'''-------------搭建DenseNet-121-----------------------------'''
class DenseNet(nn.Module):def __init__(self, init_channels=64, growth_rate=32, blocks=[6, 12, 24, 16], num_classes=10):super(DenseNet, self).__init__()#为什么不将这两个属性设置为参数?#在设计类时,如果bn_size和drop_rate通常不需要经常改变,#或者如果它们通常有一个标准的值(如文中的bn_size=4和drop_rate=0),# 则可以将它们设置为固定的类属性bn_size = 4drop_rate = 0#首先是初始卷积层Conv1,输入通道数为3代表RGB图像,self.conv1 = Conv1(in_planes=3, places=init_channels)#然后是4个DenseBlock以及中间3个TransitionLayer#num_features用于统计特征图的数量,也就是上一层输出的通道数,当前层的输入通道数num_features = init_channels#第一个 DenseBlock 块,需要指定非线性映射层的个数,有6个非线性映射层self.layer1 = DenseBlock(num_layers=blocks[0], inplaces=init_channels, growth_rate=growth_rate, bn_size=bn_size, drop_rate=drop_rate)#经过第一个 DenseBlock 块之后,输出的特征图数量, blocks[0]是非线性映射层的数量,每个非线性映射层输出growth_rate个特征图num_features += blocks[0] * growth_rate#然后是 Transition Layer1, // 是整除运算符,向下取整,根据论文中的表格,过渡层会将特征图数量减半self.transition_1 = _TransitionLayer(inplace=num_features, place=num_features // 2)#由于经过 Transition Layer 会将特征图数量减半,所以需要更新num_featuresnum_features = num_features // 2#然后同样地,经过第二个 DenseBlock 块和 Transition Layer2self.layer2 = DenseBlock(num_layers=blocks[1], inplaces=num_features, growth_rate=growth_rate, bn_size=bn_size, drop_rate=drop_rate)num_features += blocks[1] * growth_rateself.transition_2 = _TransitionLayer(inplace=num_features, place=num_features // 2)num_features = num_features // 2self.layer3 = DenseBlock(num_layers=blocks[2], inplaces=num_features, growth_rate=growth_rate, bn_size=bn_size, drop_rate=drop_rate)num_features += blocks[2] * growth_rateself.transition_3 = _TransitionLayer(inplace=num_features, place=num_features // 2)num_features = num_features // 2#第四个 DenseBlockself.layer4 = DenseBlock(num_layers=blocks[3], inplaces=num_features, growth_rate=growth_rate, bn_size=bn_size, drop_rate=drop_rate)num_features += blocks[3] * growth_rate#第四个 DenseBlock 之后是一个全局平均池化层self.avgpool = nn.AvgPool2d(kernel_size=7, stride=1)#然后是全连接层将特征映射到 10 个识别类别上# 这里是(1024*10)的形状self.fc = nn.Linear(num_features, num_classes)def forward(self, x):#向前传播,首先要经过初始卷积层Conv1x = self.conv1(x)#然后经过构建的4组DenseBlock,和 transition layerx = self.layer1(x)x = self.transition_1(x)x = self.layer2(x)x = self.transition_2(x)x = self.layer3(x)x = self.transition_3(x)x = self.layer4(x)#然后经过最大池化层和全连接层x = self.avgpool(x) #平均池化层会将每个通道内的空间维度缩减为1x1print(x.shape) #所以输出[1, 1024, 1, 1]# 1是批量大小(1张图像),1024是特征图数量(通道数),1,1是其空间尺寸# view将四维的特征图 x 重塑为二维的张量。x.size(0)得到的是批量大小x = x.view(x.size(0),-1)print(x.shape) #所以输出[1, 1024]x = self.fc(x)return xif __name__=='__main__':model = DenseNet()print(model)#随机初始化 1 张图像,通道数为3,空间尺寸为224*224input = torch.randn(1, 3, 224, 224)out = model(input)print(out.shape)
_DenseLayer 类实现了带有 bottleneck layer 的 DenseNet 中的非线性映射层
-
1x1卷积核的bottleneck layer:确实,这里的1x1卷积层作为一个bottleneck layer的核心作用是减小后续3x3卷积层输入特征图的通道数。它可以降低计算复杂性和参数数量,同时聚合前面层的特征信息。
-
3x3卷积核的作用:紧跟在1x1卷积之后的3x3卷积层的目的是提取特征。3x3是常见的卷积尺寸,能够有效捕捉特征图中的空间信息。
-
y的生成和输入的拼接:
y是输入x经过非线性映射层处理之后的输出,x和y通过torch.cat([x, y], 1)进行通道维度的拼接,会作为 DenseBlock 中下一个非线性映射层的输入。 -
特征图的累积:随着非线性映射层的增加,输出
y在通道维度上累积了之前所有非线性映射层输出的特征图。每一个 DenseLayer 输出新的特征图,这些新的特征图与输入特征图拼接后传递给下一层,使得网络中的信息流和梯度流通得更加顺畅。
如果设置了dropout(通过self.drop_rate控制),则会在特征图 y 上应用dropout操作,这有助于防止过拟合。整个过程构成了DenseNet中的一个典型的密集连接模式。
下面的局部模型打印信息里,
DenseNet((conv1): Sequential((0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)#conv1输出的特征图个数是 64,因为MaxPool2d进行了padding保持特征图尺寸不变)(layer1): DenseBlock((layers): Sequential((0): _DenseLayer((dense_layer): Sequential(#第一个DenseBlock的第一个非线性映射层接收conv1输出的通道数64(0): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)#第一个DenseBlock的第一个非线性映射层输出了32个特征图# 因为增长率被设为32,每个非线性映射层输出的特征图 = growth_rate(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(1): _DenseLayer((dense_layer): Sequential(#第二个非线性映射层输入通道数是96# 96 = 第一个非线性层输出特征图数32+Conv1输出的特征图64(0): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(96, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(2): _DenseLayer((dense_layer): Sequential(# 第三个非线性映射层输入通道数是128# 128=第二个非线性映射层输出32+第二个非线性映射层输入96(0): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(3): _DenseLayer((dense_layer): Sequential(#同理(0): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(160, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(5): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(224, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(224, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))))(transition_1): _TransitionLayer((transition_layer): Sequential((0): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)#_TransitionLayer 进行下采样将特征图数量减半(2): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): AvgPool2d(kernel_size=2, stride=2, padding=0)))(layer2): DenseBlock((layers): Sequential((0): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))
DenseNet((conv1): Sequential((0): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False))(layer1): DenseBlock((layers): Sequential((0): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(1): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(96, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(2): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(3): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(160, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(4): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(192, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(5): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(224, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(224, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))))(transition_1): _TransitionLayer((transition_layer): Sequential((0): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)#_TransitionLayer 进行下采样将特征图数量减半(2): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): AvgPool2d(kernel_size=2, stride=2, padding=0)))(layer2): DenseBlock((layers): Sequential((0): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(1): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(160, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(2): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(192, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(3): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(224, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(224, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(4): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(5): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(288, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(288, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(6): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(320, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(7): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(352, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(352, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(8): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(384, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(9): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(416, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(416, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(10): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(448, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(11): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(480, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))))(transition_2): _TransitionLayer((transition_layer): Sequential((0): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): AvgPool2d(kernel_size=2, stride=2, padding=0)))(layer3): DenseBlock((layers): Sequential((0): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(1): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(288, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(288, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(2): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(320, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(320, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(3): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(352, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(352, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(4): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(384, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(384, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(5): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(416, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(416, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(6): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(448, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(448, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(7): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(480, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(480, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(8): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(9): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(544, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(544, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(10): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(576, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(576, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(11): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(608, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(608, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(12): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(640, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(640, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(13): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(672, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(14): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(704, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(704, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(15): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(736, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(736, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(16): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(768, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(768, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(17): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(800, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(800, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(18): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(832, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(832, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(19): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(864, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(864, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(20): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(896, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(21): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(928, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(928, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(22): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(960, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(960, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(23): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(992, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(992, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))))(transition_3): _TransitionLayer((transition_layer): Sequential((0): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): AvgPool2d(kernel_size=2, stride=2, padding=0)))(layer4): DenseBlock((layers): Sequential((0): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(1): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(544, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(544, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(2): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(576, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(576, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(3): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(608, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(608, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(4): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(640, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(640, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(5): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(672, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(672, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(6): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(704, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(704, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(7): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(736, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(736, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(8): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(768, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(768, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(9): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(800, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(800, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(10): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(832, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(832, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(11): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(864, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(864, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(12): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(896, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(896, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(13): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(928, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(928, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(14): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(960, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(960, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))(15): _DenseLayer((dense_layer): Sequential((0): BatchNorm2d(992, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(1): ReLU(inplace=True)(2): Conv2d(992, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(4): ReLU(inplace=True)(5): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False))(dropout): Dropout(p=0, inplace=False))))(avgpool): AvgPool2d(kernel_size=7, stride=1, padding=0)(fc): Linear(in_features=1024, out_features=10, bias=True)
)
torch.Size([1, 10])