【KMeans聚类概述】
文章目录
- 一、KMeans聚类算法是什么?
- 1. 聚类算法分类
- 2. KMeans算法原理
- 二、KMeans算法的应用场景
- 1. 市场细分
- 2. 图像分割
- 3. 文档聚类
- 三、KMeans算法的实现
- 1. 算法流程
- 2. Python实现
- 四、KMeans算法的优化与挑战
- 1. 选择最佳K值
- 2. KMeans算法的局限性
- 3. 改进算法
一、KMeans聚类算法是什么?
KMeans是一种广泛使用的聚类算法,属于无监督学习算法的范畴。它的核心思想是通过迭代寻找数据集中K个簇的中心点(也称为质心),以此来最小化每个点到其簇中心的距离之和。算法的最终目标是将相似的数据点聚集到同一簇中,实现数据的有效分类和组织。
1. 聚类算法分类
聚类算法主要分为两大类:层次聚类和划分聚类。
-
层次聚类(Hierarchical Clustering):这种方法通过创建一个多层次的嵌套分群结构,将数据点逐渐分组在一起。层次聚类可以进一步分为凝聚的层次聚类(自底向上合并)和分裂的层次聚类(自顶向下分割)。这种方法的优点在于不需要预先指定簇的数量,但计算复杂度较高,不适合大规模数据集。
-
划分聚类(Partitioning Clustering):与层次聚类相比,划分聚类直接将数据点分成若干个簇,每个簇至少包含一个对象,每个对象属于且仅属于一个簇。KMeans算法就是划分聚类的一种,特点是需要预先指定簇的数量K,适用于处理大数据集,因为其算法复杂度相对较低。
2. KMeans算法原理
-
初始化中心点:首先随机选择K个数据点作为初始的簇中心。
-
分配簇:对于数据集中的每一个点,计算它与每个簇中心的距离,并将其归类到最近的簇中心所代表的簇。
-
重新计算中心点:一旦所有的数据点都被分配到各自的簇后,重新计算每个簇的中心点,通常是取簇内所有点的均值。
-
迭代优化:重复“分配簇”和“重新计算中心点”的步骤,直到满足终止条件,如簇中心的移动距离小于一个阈值,或达到预设的迭代次数。
KMeans算法的优势在于简单易实现,计算效率高,特别适合处理大数据集。然而它也存在一些局限,比如需要预先指定簇的数量K,对初始中心点的选择敏感,可能陷入局部最优解,且假设簇是凸形和相似大小,这在某些情况下可能不成立。为了克服这些限制,提出了多种改进算法,如KMeans++(用于优化初始中心点的选择)和基于密度的聚类算法(如DBSCAN),它们在特定条件下能提供更好的聚类效果。
二、KMeans算法的应用场景
1. 市场细分
市场细分是将潜在消费者分为不同的群体或市场细分,每个群体的消费者具有相似的需求、偏好或消费行为。KMeans算法通过分析消费者的特征数据(如年龄、性别、收入水平、购买历史等),将消费者聚类成不同的群体。这样,企业可以针对每个消费者群体设计定制化的市场策略,从而实现更精准的市场定位和资源分配。例如,零售商可以使用KMeans算法对顾客进行分群,识别出高价值顾客群体,进而针对这一群体推出特定的营销活动或优惠策略,以增加销售额和顾客忠诚度。
2. 图像分割
图像分割是将图像分成多个具有相似特征的区域的过程,KMeans算法可以应用于图像分割和颜色量化,通过聚类分析图像中的颜色信息,将具有相似颜色的像素点分为一组,实现图像内容的分割。例如,在医学成像中,KMeans可以帮助识别和分割不同的组织类型,以便于疾病诊断;在卫星图像处理中,KMeans可以用来识别水体、植被、城市等不同的地物类型。颜色量化则是减少图像中颜色的数目,以减少图像文件的大小,同时保持视觉上的相似性,KMeans通过将大量颜色聚类为少数代表颜色来实现这一目的。
3. 文档聚类
文档聚类是指将文档集合中相似的文档归为一类的过程,KMeans算法通过分析文档中的关键词出现频率等特征,将文档聚类成不同的主题或类别。帮助组织和管理大量的文档资料,如自动分类新闻文章、研究论文或网页内容。例如,一个大型新闻门户网站可以使用KMeans算法自动将新闻按主题分类,提高信息检索的效率和用户体验。在学术研究中,文档聚类可以帮助研究人员快速找到与其研究领域相关的文献,加速文献综述的过程。
三、KMeans算法的实现
使用鸢尾花数据集(Iris dataset)是学习机器学习算法的经典案例之一。这个数据集包含了三种不同鸢尾花(Setosa、Versicolour和Virginica)的150个样本,每个样本有四个特征:萼片长度、萼片宽度、花瓣长度和花瓣宽度。通过这些特征,KMeans算法可以将花朵分为不同的簇。
1. 算法流程
- 数据加载:加载鸢尾花数据集,并确定数据的特征。
- 选择簇的数量K:在这个案例中,我们已经知道有三种鸢尾花,因此K=3。
- 初始化中心点:随机选择三个样本作为初始的簇中心,或使用KMeans++方法选择初始中心,以提高算法的收敛速度和稳定性。
- 分配样本到最近的簇中心:计算每个样本到各个簇中心的距离,并将样本分配到最近的簇中心所在的簇。
- 更新簇中心:对于每个簇,计算簇中所有样本点的均值,并将该均值设为新的簇中心。
- 迭代优化:重复步骤4和步骤5,直到簇中心不再发生变化,或者变化小于某个预定阈值,或者达到最大迭代次数。
2. Python实现
from sklearn.cluster import KMeans
from sklearn import datasets
import matplotlib.pyplot as plt
from sklearn.metrics import silhouette_score# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data# 应用KMeans算法
kmeans = KMeans(n_clusters=3).fit(X)# 打印簇中心
print("簇中心:\n", kmeans.cluster_centers_)# 轮廓系数
print("轮廓系数:", silhouette_score(iris.data, kmeans.labels_))# 打印每个样本所属的簇标签
print("样本的簇标签:\n", kmeans.labels_)# 创建一个三维图形实例
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')# 绘制数据点
ax.scatter(X[:, 0], X[:, 1], X[:, 2], c=kmeans.labels_, cmap='viridis')# 绘制簇中心
ax.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], kmeans.cluster_centers_[:, 2], c='red', marker='x', s=100)# 设置中文
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 设置轴标签和标题
ax.set_xlabel('花萼长度')
ax.set_ylabel('花萼宽度')
ax.set_zlabel('花瓣长度')
ax.set_title('KMeans聚类')plt.show()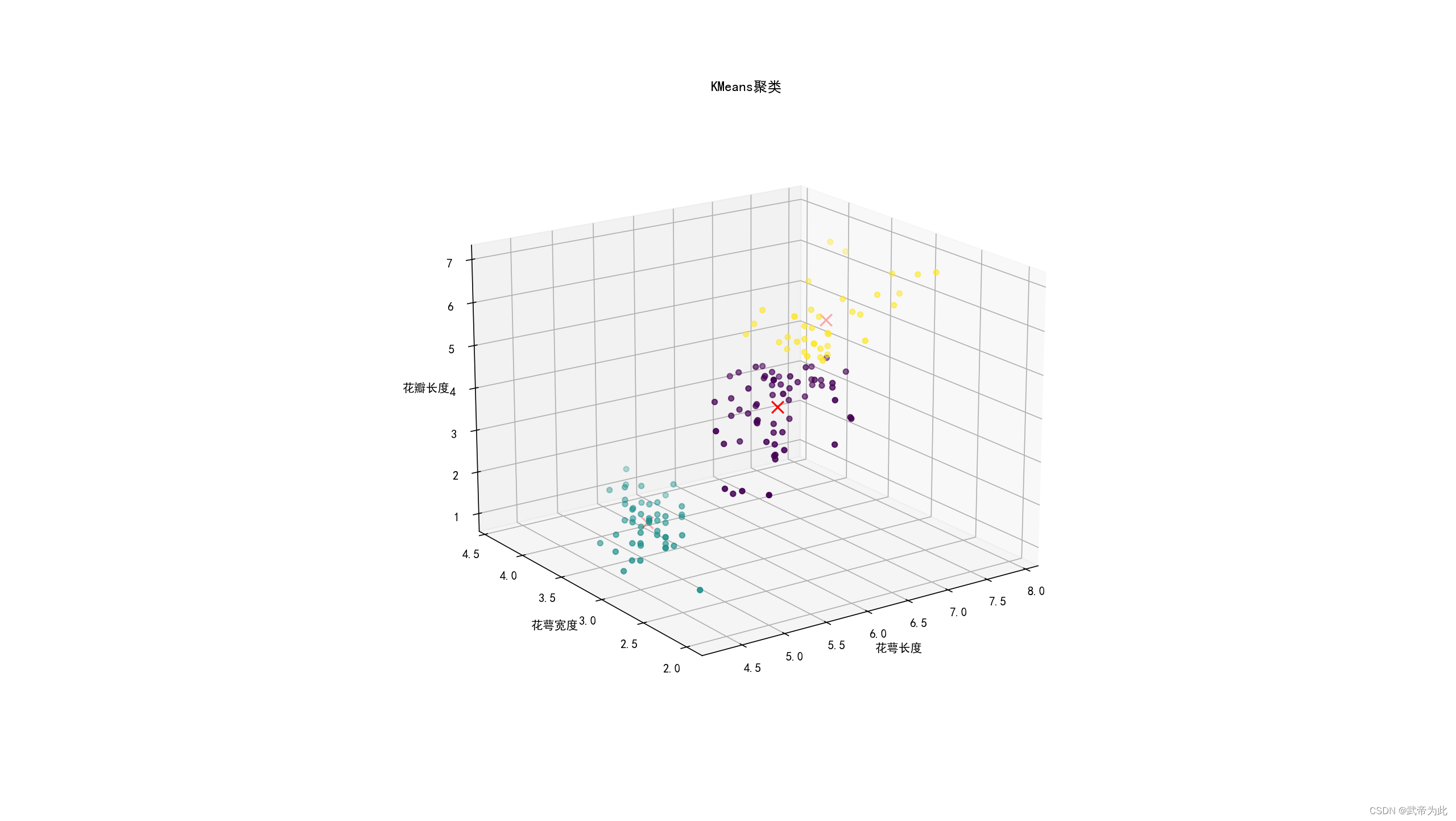
四、KMeans算法的优化与挑战
尽管KMeans聚类算法在多个领域内被广泛应用,它仍然面临着一些挑战和限制。理解这些挑战有助于在适当的情况下选择和优化算法。
1. 选择最佳K值
确定最佳簇数量K是使用KMeans算法时的一个关键挑战。选择不合适的K值可能会导致较差的聚类效果。
- 肘方法(Elbow Method):这是一种常用的确定K值的技术,它通过比较聚类数量与聚类内方差(Within-Cluster Sum of Square,WCSS)的关系来工作。随着K值的增加,样本将更紧密地聚集到它们的簇中心,WCSS会减少。肘方法的思想是找到WCSS迅速下降趋于平缓的点,这个点通常被认为是最佳的K值。虽然肘方法在许多情况下有效,但它并不总能明显指出最佳K值,特别是在数据分布复杂时。
2. KMeans算法的局限性
-
对初始值敏感:KMeans算法的结果很大程度上依赖于初始簇中心的选择。不恰当的初始值可能导致较差的聚类效果或陷入局部最优解。
-
难以聚类非球形数据:由于KMeans算法在聚类时最小化点到簇中心的欧氏距离,它天然偏好于球形的簇。对于非球形或大小差异大的簇,KMeans可能无法有效地识别。
-
需要预先指定簇的数量:与基于密度的聚类算法(如DBSCAN)不同,KMeans需要在聚类前指定簇的数量,这在没有足够先验知识的情况下可能是个挑战。
3. 改进算法
-
KMeans++初始化方法:为了减少对初始簇中心选择的敏感性,KMeans++提供了一种更加精确的初始化方法。它通过一种概率技术选择初始簇中心,以尽可能使它们彼此远离,这通常可以导致更好的聚类结果和更快的收敛。
-
层次KMeans:结合了层次聚类算法的优点和KMeans的效率,首先使用层次聚类方法生成簇的层次结构,然后根据需要的簇数量切割这个层次结构,以获得最终的聚类结果。
-
谱聚类(Spectral Clustering):谱聚类使用数据的相似性矩阵,并通过图论中的拉普拉斯矩阵的特征向量进行聚类。它特别适用于非球形的数据聚类,可以视为对KMeans的一种补充。