如何开始定制你自己的大型语言模型
2023年的大型语言模型领域经历了许多快速的发展和创新,发展出了更大的模型规模并且获得了更好的性能,那么我们普通用户是否可以定制我们需要的大型语言模型呢?
首先你需要有硬件的资源,对于硬件来说有2个路径可以选。高性能和低性能,这里的区别就是是功率,因为精度和消息长度直接与参数计数和GPU功率成比例。
定制语言模型的目标应该是在功能和成本之间取得平衡。只有知道自己的需求和环境,才能够选择响应的方案。因为无论你计划如何训练、定制或使用语言模型,都是要花钱的。你能做的唯一免费的事情就是使用一个开源的语言模型。

GPU
无论是租用的云GPU还是在购买的GPU都无关紧要。因为我们使用的库和代码是通用的,这里关键的区别在于价格。
高性能模型
我们这里定义的高性能模型的参数至少有25B+
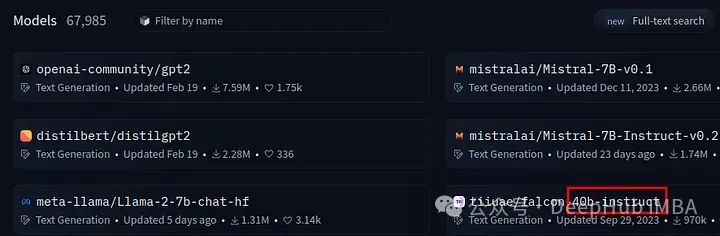
如果想要好一些的模型,40B+才可以,如上图所示。
但是模型参数大意味着需要更多的预算,下面我们看看如果需要使用这个模型需要什么样的GPU。48GB VRAM每月600+美元,如果希望使用远程服务器创建自己的高性能LLM,那么这将是最低的成本。

如果我们要购买这个GPU,则需要大概5000美元:

所以如果你想选择高性能的模型,这个是最低的预算了,下面我们看看如果我们不太看重性能,或者只想进行学习,我们应该怎么选择。
低性能模型
我们可以以更便宜的价格使用性能较低的模型。但是要记住,任何低于7B的参数都可以不考虑,因为目前来看0.5B到4B参数对于测试、开发模型和微调来说是很好的,但对于实际使用来说效果很差,所以建议最少使用7B参数。
对于较低的7B模型,我认为你至少需要12GB的VRAM。理想情况下,最好有大约20GB的VRAM。
这种GPU我们就可以直接购买了,因为如果使用云GPU的话就不太值。
让我们看看价格:
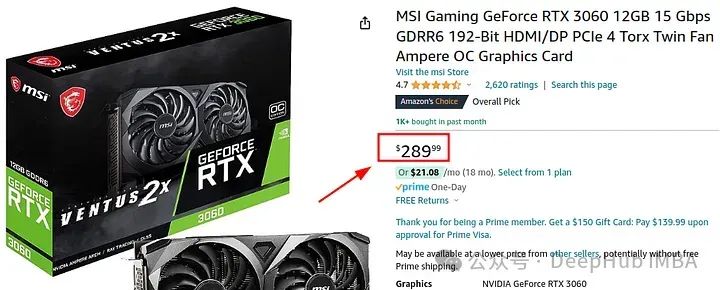
最便宜的12GB的3060不到美元。在家里做个开发,或者玩玩你游戏都可以,不过我还是建议16G以上的GPU,这样用起来更方便一些。

比如这个4060ti,450美元,我这里就把它当作入门的最低配置了
训练
有了GPU,下一步就是训练了,一般情况下transformers 都为我们准备好了,我们只需要准备好数据集即可。
首先加载模型:
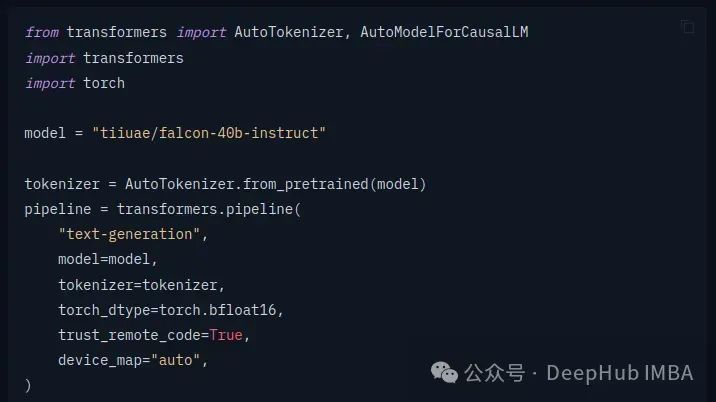
HuggingFace的transformers 库已经将方法全部封装好了,我们只要按照文档调用即可。如果你想深入学习,可以在使用transformer库一段时间后,切换到纯PyTorch或开始更详细地了解如何训练模型。
然后我们需要定义数据集,创建一个
Dataset
类来加载您的训练数据和验证数据。这里是一个简单的示例:
classTextDataset(Dataset):def__init__(self, tokenizer, data_file, block_size=128):self.examples= []withopen(data_file, 'r', encoding='utf-8') asf:lines=f.readlines()forlineinlines:line=line.strip()tokenized_text=tokenizer.convert_tokens_to_ids(tokenizer.tokenize(line))foriinrange(0, len(tokenized_text) -block_size+1, block_size):self.examples.append(tokenizer.build_inputs_with_special_tokens(tokenized_text[i:i+block_size]))def__len__(self):returnlen(self.examples)def__getitem__(self, idx):returntorch.tensor(self.examples[idx], dtype=torch.long)
这里根据不同的目标可能有所不同
然后就是数据加载:
train_data_file='path_to_train_data.txt'eval_data_file='path_to_eval_data.txt'train_dataset=TextDataset(tokenizer, train_data_file)eval_dataset=TextDataset(tokenizer, eval_data_file)train_loader=DataLoader(train_dataset, batch_size=4, shuffle=True)eval_loader=DataLoader(eval_dataset, batch_size=4, shuffle=False)
定义训练参数
training_args=TrainingArguments(output_dir='./results', # 训练结果的输出目录num_train_epochs=3,per_device_train_batch_size=4,per_device_eval_batch_size=4,logging_dir='./logs',logging_steps=500,save_steps=1000,evaluation_strategy='steps',eval_steps=500,warmup_steps=500,weight_decay=0.01,logging_first_step=True,load_best_model_at_end=True,metric_for_best_model="loss",)
定义训练器和开始训练
trainer=Trainer(model=model,args=training_args,data_collator=lambdadata: torch.tensor(data).long(),train_dataset=train_dataset,eval_dataset=eval_dataset,)trainer.train()
保存微调后的模型
model.save_pretrained("path_to_save_model")
这样我们就根据自己的数据训练出了一个定制的模型
使用
我们要使用或者看看我们的模型效果怎么样,这时就可以使用Ollama 和Open Web UI了
我们可以通过Ollama加载自定义模型,模型交付给Open Web UI,看起来像这样:
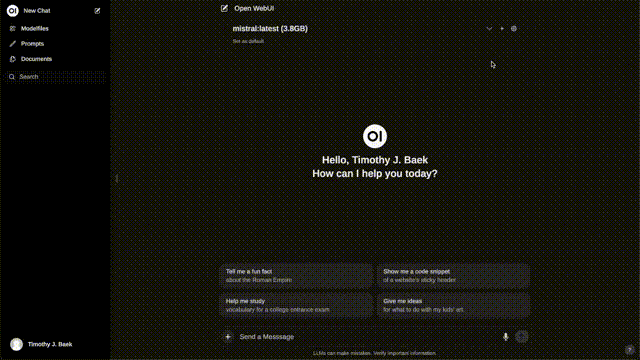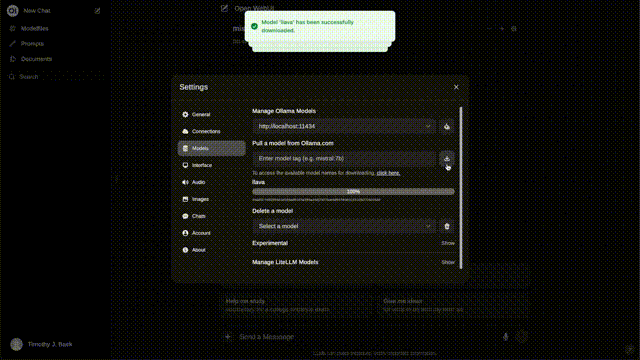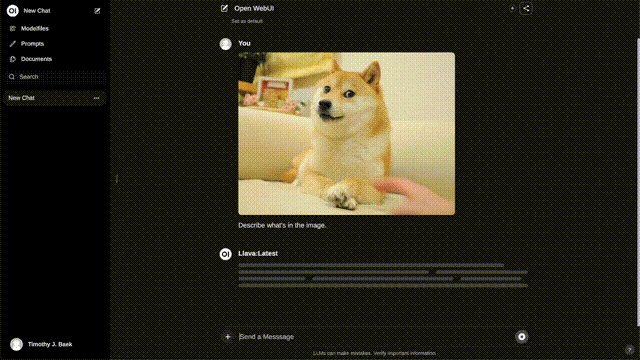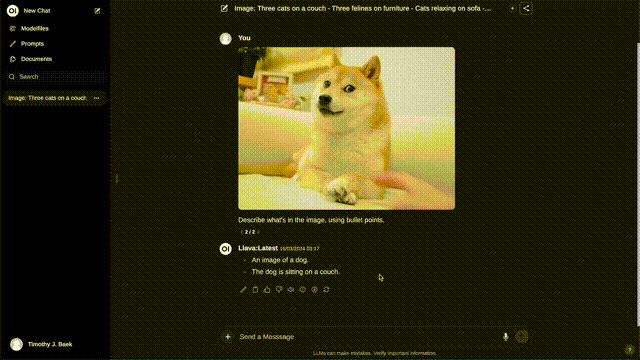
也就是说,我们把Ollama当作后端,Open Web UI作为前端,创建了一个类似chatgpt的聊天机器人。
总结
虽然深度学习的感念抽象的,并且数学的原理学习起来非常的复杂,但是已经有现成的库、方法和框架,将这些概念汇总和抽象出来,我们只要会一些python的开发就可以直接拿来使用。
如果你想深入的学习,也可以从最顶层最抽象的部分开始,然后往下一步一步进行学习,这样就不会因为底层的概念太过复杂而放弃。
当然最后所有的基础是你需要有一块能够工作的GPU。
https://avoid.overfit.cn/post/ebd03e3eb42942a8b13e246a82a3d079
作者:Jesse Nerio