Redis持久化:RDB与AOF
redis将数据以键值对的形式存储在内存之中,而内存中的数据会掉电丢失,因此仅仅是把数据存储在内存是无法做到数据持久化的,因此还需要把数据转移到硬盘中去。Redis数据持久化有两只方式:定期备份RDB、实时备份AOF。
RDB(Redis DataBase):
数据备份存储的位置:(我们可以从redis.conf配置文件中学习到很多细节)

redis会定期把redis内存中的数据,都写入硬盘生成一个“快照”,后续redis重启,内存数据没了可以从“快照”中重新加载,这个快照就是dump.rdb文件,保存在/var/lib/redis中。
手动触发:
save:
执行save命令redis会全力以赴生成快照文件,然后删除旧的dump.rdb文件,将新的快照文件更名为dump.rdb;为什么是先生成新的快照文件,再去删除rdb文件做替换呢,这是因为如果在save命令执行过程中突然发生意外(比如redis服务进程突然被杀死),下一次启动redis服务的时候依然可以从未删除的rdb文件加载数据。需要注意的是,save命令和keys * 一样运行时间可能较长,导致redis服务阻塞,影响redis处理其他客户的请求,所以一般不建议使用save命令生成快照。
bgsave(background save):
采用多进程的形式去完成缓存数据备份,具体过程如下,这个命令不会影响redist处理其他用户的请求。(并发编程的场景:多进程、多线程,java中并不提倡多进程编程)

fork是Linux系统中的一个系统调用,用处创建子进程,子进程会复制父进程的所有内容。所以上图子进程会拥有父进程fork之前同样的内存内容,也就意味这子进程拥有生成此刻快照的能力。如果已经有一个子进程正在运行,redis又收到一个save或者bgsave命令就不会做任何处理,同时父进程还可以正常响应其他请求。
"fork"系统调用用于在当前进程的基础上创建一个新的子进程。子进程是父进程的一个副本,它继承了父进程的内存、文件描述符和执行状态。子进程和父进程几乎是相同的,从创建时刻开始,在此后它们的执行是独立的,它们有各自独立的内存空间。
当调用"fork"时,操作系统会复制父进程的地址空间,并为子进程分配一个唯一的进程标识符(PID),用于在系统中标识该进程。然后,父进程和子进程在不同的执行路径上继续执行代码。在父进程中,"fork"的返回值是子进程的PID,而在子进程中,返回值为0。这样,通过检查返回值可以确定当前代码是在父进程还是子进程中执行。
"fork"的主要作用之一是实现并发和并行编程。通过创建子进程,可以同时执行多个独立的代码路径,从而实现并发执行。子进程可以执行不同的任务,或者在某些情况下,可以使用其中一个进程作为工作进程,而另一个进程作为控制进程。
此外,"fork"还用于创建进程层次结构。通过连续调用"fork",可以创建多个子进程,并形成进程树。在这种层次结构中,父进程可以拥有多个子进程,而每个子进程又可以拥有自己的子进程,以此类推。
需要注意的是,"fork"操作是一种资源消耗较大的操作,因为它需要复制父进程的地址空间。因此,在使用"fork"时需要谨慎,避免不必要的资源浪费。此外,在子进程中应当及时释放不需要的资源,以避免资源泄漏。
总结起来,"fork"是一种创建新进程的操作,它在当前进程的基础上创建一个子进程,子进程是父进程的副本,具有独立的执行路径和内存空间。通过"fork",可以实现并发执行和创建进程层次结构,是进程管理和并发编程中常用的机制之一。
自动触发:
也就是根据配置自动触发bgsave命令:
900秒内至少1个key改变;300秒内至少10key改变;60秒内至少10000个key改变就会触发自动备份;save "" 表示不自动备份,这里的数字都是可以修改的,修改配置文件重启redis服务即可生效。每次生成快照备份都需要创建子进程,成本还是比较高的,因此这个备份不能过于频繁。

如果热redis中新增了数据,但是还没有来的备份redis服务就因为意外(服务器掉电,kill -9 )突然被杀死,那么这些没有被持久化的数据就会丢失。如果是正常关闭redis,在redis关闭之前会做一次自动保存。
自动触发备份的几种情况:

刚才提到了备份时是先生成一个临时快照文件,然后删除原dump.rdb,再将临时文件更名为dump.rdb,而不是在原来的基础之上去修改。我们可以通过Linux中的stat命令来去观察应证。



如图所示,dump.rdb是二进制文件,执行flushall会清空dump.rdb;
如果dump.rdb被故意修改了会怎样:如果是在正确的内容后面追加内容,那么在redis重启加载时并会有什么影响,如果是篡改删除中间部分的内容,就可能导致redis启动失败,也可碰巧修改之后的格式也嫩被正确解读。为此redis提供了检查工具,去校验dump.rdb内容是否正确。


另外需要注意的是,redis不同版本的dump.rdb组织数据的规则可能不一样,也就是说如果直接把redis7的dump.rdb直接替换成redis5的dump.rdb,可能会启动失败。那如果相同真的要做redis版本升级怎么办呢,可以写脚本呀,获取数据然后重新写一个redis7版本的dump.rdb。
RDB的优缺点:
- RDB 是⼀个紧凑压缩的⼆进制文件,代表 Redis 在某个时间点上的数据快照。非常适用于备份,全 量复制等场景。比如每 6 小时执行 bgsave 备份,并把 RDB 文件复制到远程机器或者文件系统中 (如 hdfs)用于灾备。
- Redis 加载 RDB 恢复数据远远快于 AOF 的方式。
- RDB 方式数据没办法做到实时持久化 / 秒级持久化。因为 bgsave 每次运行都要执行 fork 创建子进 程,属于重量级操作,频繁执行成本过高。
- RDB 文件使用特定⼆进制格式保存,Redis 版本演进过程中有多个 RDB 版本,兼容性可能有风险。
RDB最大的问题就是不能实时持久化,两次快照之间的数据可能会丢失。
AOF(Append Only File):
类似于mysql的binlog,就是把用户的每一个操作都存储到aof中,redis重启的时候读取aof就可以恢复数据了。aof默认是关闭的,修改配置文件来开启aof功能:

 aof是一个文本文件,每次操作都会被记录下来。
aof是一个文本文件,每次操作都会被记录下来。
redis之所以快是因为他是单线程的,出来的任务也都是短平快的,而且只是操作内存。如果要实时持久化,那就不及要写内存也要写硬盘了吗?速度还会快吗?
实际上redis并非是直接让工作线程把数据写进硬盘中,而是先写在一个内存中的缓冲区,数据积累的到一定程度,在统一写入硬盘。(硬盘上顺序读写速度要不随机读写要快,将缓冲区数据写入硬盘就是顺序读写,当然这个速度还是会比操作内存要慢)。如果写入了缓冲区还没来得及刷新到硬盘就掉电了,那数据会丢失吗?答案是会的,因为缓冲区也是内存。



aof工作流程: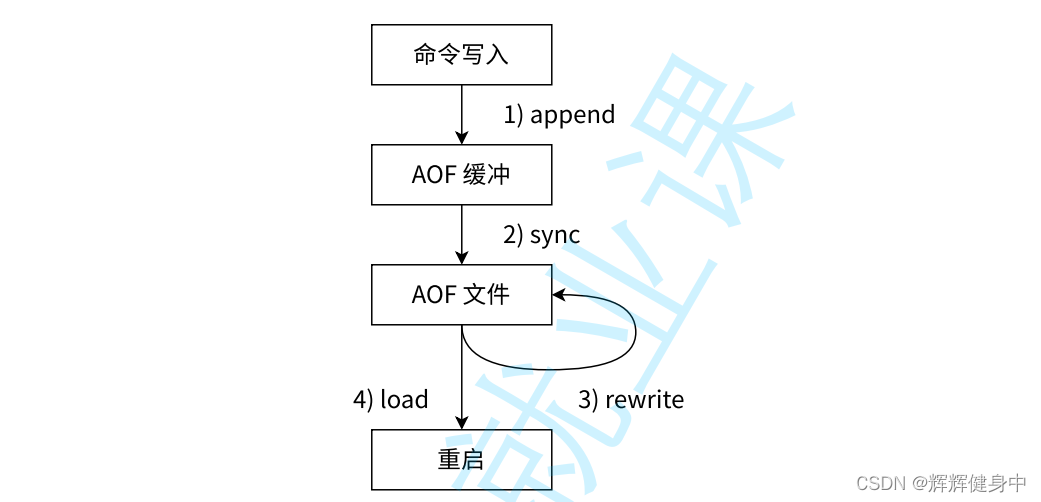
随着时间的推移aof文件会越来越大,但是其中会有很多冗余,会影响到redis的启动时间。如图说是,右侧的一些操作在运行中都会被记录在aof文件中,但其最终的数据结果和左侧一样,所以我们对aof进行重写,对其进行瘦身,保证瘦身后得到的数据不变即可。

 AOF 重写过程可以⼿动触发和⾃动触发:
AOF 重写过程可以⼿动触发和⾃动触发:
- 手动触发:调用 bgrewriteaof 命令。
- 自动动触发:根据 auto-aof-rewrite-min-size 和 auto-aof-rewrite-percentage 参数确定自动触发时机。
- auto-aof-rewrite-min-size:表示触发重写时 AOF 的最小文件大小,默认为 64MB。
- auto-aof-rewrite-percentage:代表当前 AOF 占用大小相比较上次重写时增加的比例。
重写流程:
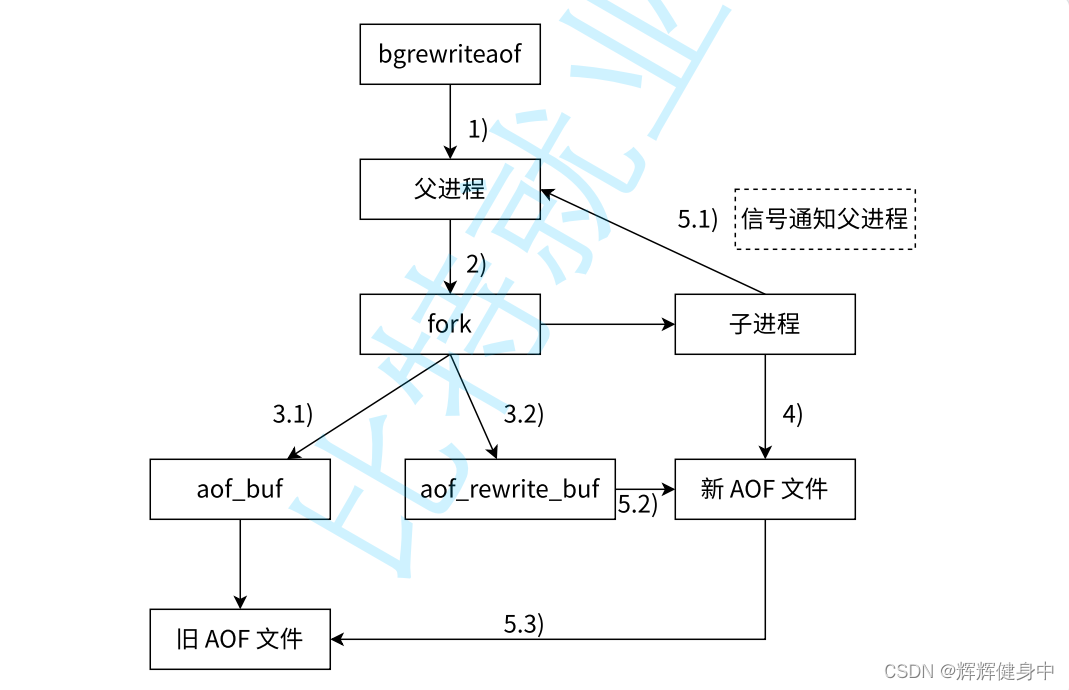
由图可知,在子进程重写aof的过程中,父进程依然在处理其他命令,并把操作记录在aof_buff和aof_rewrite_buf两个缓冲区中,当子进程新的aof文件,会将aof_rewrite_buf的内容合并到新aof文件中,然后删除旧aof,重命名新aof文件。如果没有合并这一步,那么实时备份和定期备份几乎就没有差别了。aof_buf和aof_rewrite_buf两个缓冲有什么区别,存的东西不都是操作记录吗,为什么还要有aof_rewrite_buf:
首先要明确是,父进程会不断向aof_buf写入操作记录,但并不会一直向aof_rewrite_buf写入操作记录,当子进程通知父进程新aof已经写好后,父进程就会停止向aof_rewrite_buf写入操作记录,然后由子进程完成合并操作,最后替换旧aof,这个过程中父进程可能随时会对aof_buf进行写入,如果没有aof_rewrite_buf的存在,那么在合并的过程中子进程也需要去操作aof_rewrite_buf,这就很容易混乱。
父进程不断向aof_buf中写入操作记录还有一个好处,如果发生意外导致子进程被杀死,但父进程还在,虽然新aof没有了,但是因为父进程不断向aof_buf写入,所以不会在造成从fork开始到子进程意外死亡这段时间内的数据丢失,这个是时间的操作被保存在aof_buf,就还可以进行下一次重写。
混合持久化:
混合持久化中redis:在对aof进行瘦身时会将文本形式的数据优化成RDB形式的二进制数据,后续备份aof_buf的数据还是会采用文本个数写入aof:(提一嘴,从缓冲区写入aof的过程中是自动的,redis给我们提供了三种频率可以选怎,无需手动刷缓冲区)

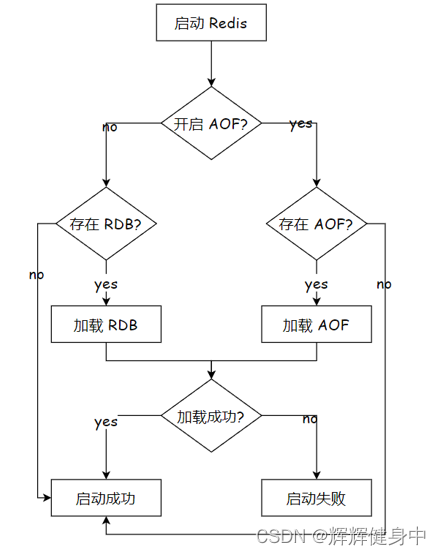
当redis上同时存在rdb快照和aof文件时,会使用哪一个来加载数据呢?答案是会加载aof的数据,因为aof的数据会更全一些。