python 08Pandas
1.基础概念



2.基本操作
(1)加载数据集
import pandas as pd #引入pandas包打开csv文件
df = pd.read_csv('./data/gapminder.tsv',sep='\t') #\t制表符,即tab,缩进四个字符 \n表示回车换行
print(type(df))
print(df.head()) #显示前5行 默认将列表的第一列设置为列标签,即取完之后的数据其实是从原始列表的第二列开始的<class 'pandas.core.frame.DataFrame'>
country continent year lifeExp pop gdpPercap
0 Afghanistan Asia 1952 28.801 8425333 779.445314
1 Afghanistan Asia 1957 30.332 9240934 820.853030
2 Afghanistan Asia 1962 31.997 10267083 853.100710
3 Afghanistan Asia 1967 34.020 11537966 836.197138
4 Afghanistan Asia 1972 36.088 13079460 739.981106
print(df.tail()) #显示最后5行print(type(df)) #df为DataFrame类型print(df.shape) #shape是DataFrame的属性,而不是方法,注意没有()print(df.columns) #查看数据的列名,相当于数据库的字段名print(type(df.columns))print(list(df.columns)) #可以转换为list
(2)获取列子集
country_df = df['country'] #获取一列
print(country_df.head())
print(type(country_df)) #contry_df为Series类型,pandas的列为series类型country_df = df[['country','year']] #获取制定多列,注意 里面是list 两层[],可以理解为df获取列的参数是某一列,或者是多列组成的一个Listprint(country_df.head())
print(type(country_df))
(3)获取行子集
通过索引标签获取行(注意与iloc的区别)
print(df.head())
print(df.loc[0]) #通过索引值取得行print(type(df.loc[0])) #注意,取得一行的时候,结果是Seriesprint(df.loc[2:5]) #同list和numpy的切片操作可以使用tail()返回最后一行
print(df.tail(n=5)) #n为选取的数量,修改为2试试选取多行
print(df.loc[[0,1,3]]) #里面是list,两层[],同上df取多列print(df.tail())
print(df.iloc[[-2,-1]])
(4)混合获取
使用loc获取列子集
subset = df.loc[:,['year','pop']] #同numpy的二维操作,行通过:取全部,列通过一个list取得特定的列 修改行的值试试,去特定几行
print(subset.head())subset = df.iloc[:,[2,3,-2,-1]] #负值索引,同list,忘记的回去复习巩固
print(subset.head())通过范围选择列子集
m=list(range(0,2)) #想先之前学过的,范围包含第一个值,不包含第二个值
print(m)
print(df.iloc[:,m].head())通过切片选择列子集
subset = df.iloc[:,0:6:2] #带步长,跟list一样
print(subset)获取行和列的子集
print(df.loc[2,'year']) #loc注意是索引值获取多行和多列的子集
print(df.loc[[0,99,999],['country','year']]) #这里与numpy的二维数组取多行多列区别开
(5)分组和聚合计算
print(df.groupby('year')['lifeExp'].mean()) #按年份分组计算平均值3.Pandas数据结构
(1)创建series
Series
Series是 一维 容器,类似于python 的list。
DataFrame可以看作由Series对象组成的字典,其中每个键是列名,值是Series
import pandas as pd
s = pd.Series(['banana',42]) #默认索引
print(type(s))
print(s)s = pd.Series(['banana',42],index=['食物','数量']) #指定索引
print(s)
(2)创建DataFrame
scientists = pd.DataFrame({'name':['Franklin','William Gosset'],'Age':[37,61]})
print(scientists)scientists = pd.DataFrame(data={'Occupation':['chemist','statistician'],'Born':['1920','1876'],'Died':['1958','1937'],'Age':[37,61]},index=['Rosaline Franklin','William Gosset'], #把此行注销掉试试看columns=['Occupation','Born','Died','Age']
) #必须与data里的一致print(scientists)
(3)series操作
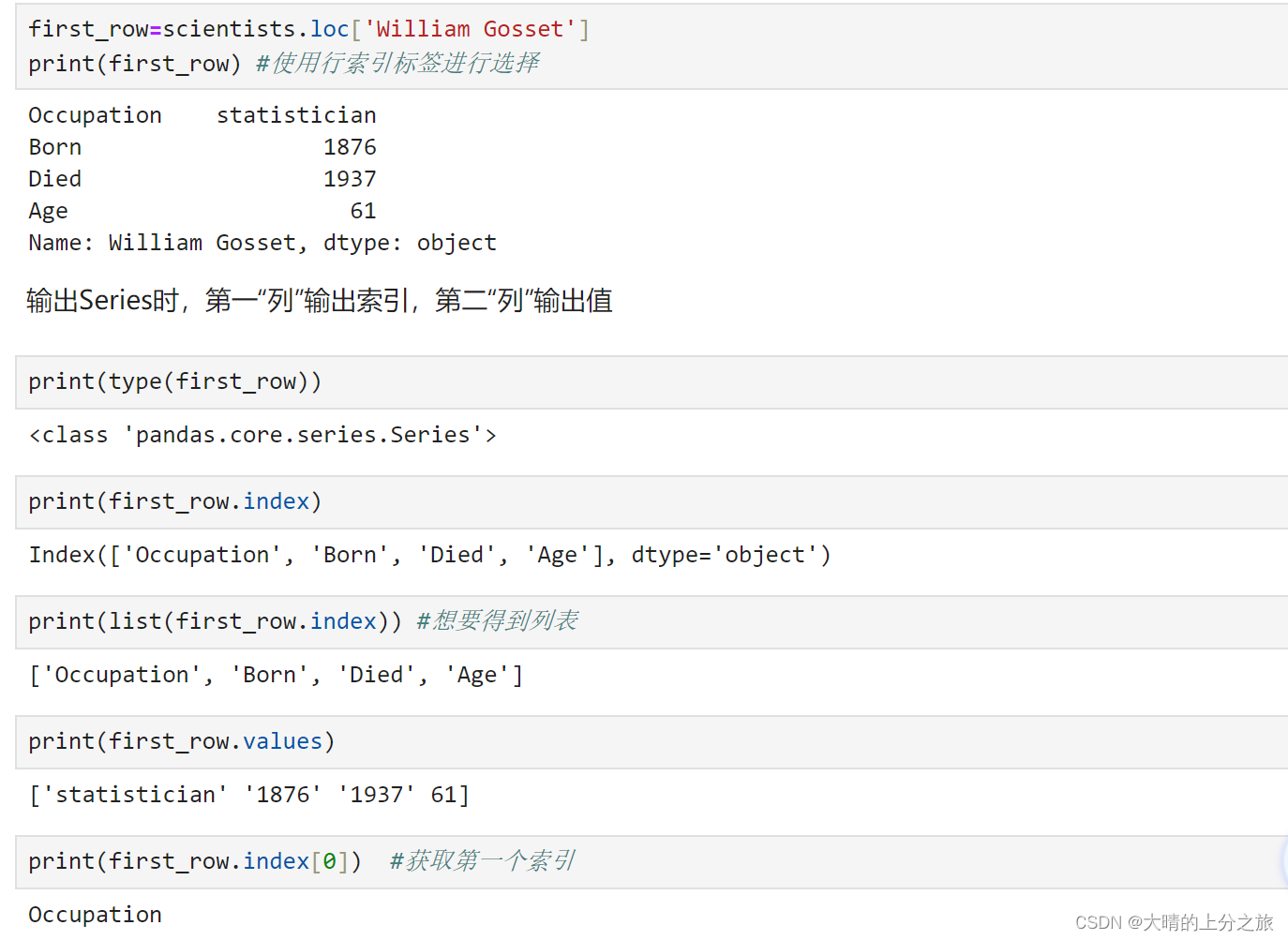
(4)series数据操作
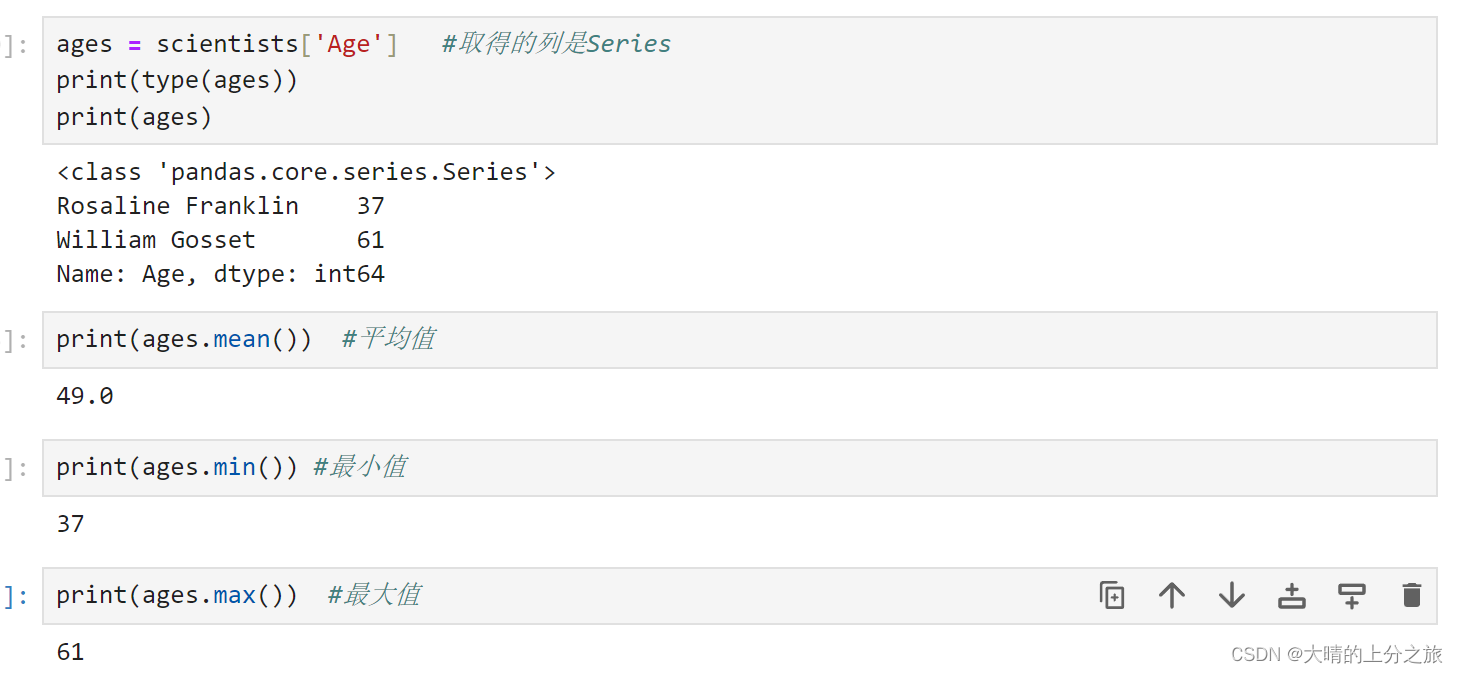
布尔子集:Series
用于取数据子集的行索引或列索引往往不确定,通常需要寻求满足(或不满足)特定计算或观测值的值
scientists = pd.read_csv('./data/scientists.csv')
print(scientists)
print(scientists.shape)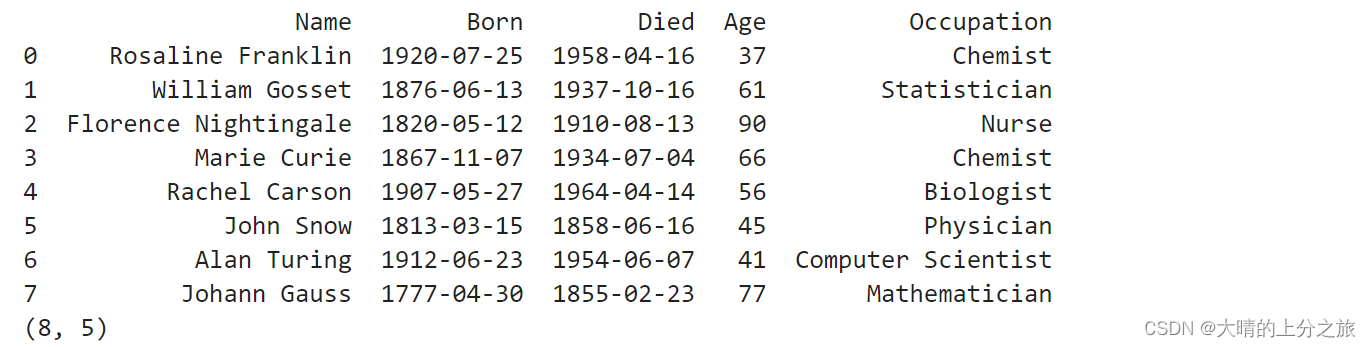
ages = scientists['Age']
print(ages)使用describe()方法获取基本统计量
ages.describe()操作自动对齐和向量化
许多Series方法都是 向量化 的,这些方法会 同时 处理整个向量,而不用使用for循环
对向量的操作会根据索引进行,缺失值用NaN表示
带有常见索引标签的向量(自动对齐)
DataFrame操作
导出和导入数据
保存数据
names=scientists['Name']print(names)names.to_pickle('./data/scientist_names_)series.pikle') #保存成pickle文件,用二进制格式保存数据,节省磁盘空间 .p .pkl也可scientist_from=pd.read_pickle('./data/scientist_names_)series.pikle')
print(scientist_from)scientist.to_csv('./data/scientist_no_index.csv',index=False)对于CSV文件,有时需要删除行号