大模型实践:如何选择适合自己场景的Prompt框架?
1. 选择适合自己场景的Prompt框架需要考虑哪些因素?
以下是一些关键的步骤和考虑点:
- 理解任务需求:首先,明确你的任务类型(如文本生成、问答、文本分类、机器翻译等)和具体需求。不同的任务可能需要不同类型的Prompt。
- 评估模型能力:了解你正在使用的模型的能力和局限性。对于强大的预训练模型,简单的指令可能就足够指导生成高质量的输出;而对于能力较弱的模型,可能需要更详细的Prompt。
- 考虑数据可用性:根据你手头的数据量来选择Prompt框架。如果有大量的标记数据,可以使用Few-Shot Prompt;如果数据有限,可能需要设计更精细的Prompt来利用模型的无监督学习能力。
- 实验和迭代:尝试不同的Prompt框架和策略,通过实验来评估它们在特定任务上的表现。根据实验结果调整Prompt设计,优化模型性能。
- 考虑计算资源:某些Prompt框架可能需要更多的计算资源。在实际应用中,需要在模型性能和计算成本之间找到平衡点。
- 参考社区和文献:研究相关的学术文献和社区实践,了解其他研究者和开发者是如何为类似任务设计Prompt的。
- 用户反馈:如果任务涉及到用户交互,考虑用户的反馈来调整Prompt,确保生成的输出符合用户的期望。
- 可解释性和透明度:对于需要高度可解释性的任务,选择能够提供清晰推理过程的Prompt框架,如Chain of Thought。
- 灵活性和通用性:考虑Prompt框架的灵活性和通用性,以便在未来的任务或场景变化时能够快速适应。
以下是一个更具体的模板,用于设计AI模型的Prompt框架:
2. 具体的设计Prompt框架模版
- 任务理解:
-
- 任务类型:___(如文本生成、问答、文本分类等)
- 任务目标:_______
- 关键要素:___(如关键词、主题、实体等)
- 模型能力评估:
-
- 模型名称:_______
- 模型大小:_______
- 预训练任务:_______
- 已有能力:___(如理解、生成、推理等)
- 数据可用性:
-
- 标记数据量:_______
- 数据质量:_______
- 数据分布:_______
- Prompt框架设计:
-
- 指令:___(如“请回答问题”、“请生成文本”等)
- 上下文:___(如相关背景信息、示例等)
- 输入:___(如问题、文本等)
- 输出:___(如答案、生成文本等)
- 实验和迭代:
-
- 实验设计:___(如不同Prompt框架的比较、超参数调整等)
- 评估指标:___(如准确率、F1分数、生成质量等)
- 结果分析:___(如哪些Prompt框架表现更好、为什么等)
- 用户反馈:
-
- 用户满意度:_______
- 用户建议:_______
- 调整Prompt框架:___
请注意,这只是一个模板,您可以根据具体任务和需求进行调整和补充。
3. 当手头数据不多时,怎么设计Prompt框架?
充分利用有限的样本有效地指导模型。以下是一些建议:
- 利用先验知识:将你对任务的先验知识编码到Prompt中。例如,如果你知道某些关键词或概念与任务高度相关,确保这些信息被包含在Prompt中。
- 模板化Prompt:创建一个模板化的Prompt,它可以为模型提供明确的指导,同时允许一定的灵活性。模板可以帮助模型理解期望的输出格式。
- 指令明确:在Prompt中提供清晰的指令,告诉模型应该执行什么任务。明确的指令可以帮助模型更好地定位问题的核心。
- 上下文丰富:尽管数据有限,但仍然可以在Prompt中提供尽可能丰富的上下文信息,帮助模型更好地理解任务背景。
- 示例驱动:如果可能,提供几个高质量的示例作为Prompt的一部分。这些示例可以展示模型如何处理类似的输入并生成期望的输出。
- Zero-Shot和Few-Shot Prompt:考虑使用Zero-Shot或Few-Shot Prompt,这些方法不需要大量的标记数据。Zero-Shot Prompt依赖于模型的预训练能力,而Few-Shot Prompt则利用少量的示例来指导模型。
- 迭代优化:初始的Prompt设计可能不是最佳的。通过实验和评估结果,不断迭代和优化Prompt。
- 利用伪标签:如果标记数据有限,可以考虑使用伪标签技术,即让模型在未标记的数据上生成预测,并使用这些预测作为额外的训练样本。
- 外部知识:如果允许,尝试将外部知识源(如百科全书、专业知识库等)整合到Prompt中,以增强模型的表现。
- 用户交互:如果任务涉及到用户交互,可以利用用户的反馈来改进Prompt设计。
4. 如何利用先验知识设计Prompt框架?
具体例子可以多种多样,具体取决于任务的性质和领域。以下是一些不同场景下的例子:
- 文本分类:假设你正在处理一个情绪分析任务,你的数据集很小,但你了解到某些词汇(如“快乐”、“悲伤”)和表情符号(如“:)”、“:(”)通常与特定的情绪相关联。你可以在Prompt中包含这些词汇和符号,以及简短的上下文,来引导模型识别情绪。
Prompt示例:
根据下面的文本判断情绪:
文本:我感到非常 [快乐],因为我刚刚通过了考试。😊
情绪:- 问答系统:如果你正在构建一个问答系统,并且知道某些事实信息对于回答问题至关重要,你可以在Prompt中提供这些事实作为上下文。
Prompt示例:
根据以下信息回答问题:
信息:水的化学式是H2O。
问题:水是由哪些元素组成的?
答案:- 机器翻译:在设计用于机器翻译的Prompt时,如果你知道某些短语或习语在源语言和目标语言中有特定的对应关系,你可以在Prompt中包含这些信息。
Prompt示例:
将以下英文短语翻译成中文:
英文:Once in a blue moon
中文:- 文本生成:如果你正在使用模型生成故事或文章,并且想要引导模型产生特定风格或内容的输出,你可以在Prompt中包含相关的风格指南或主题。
Prompt示例:
请根据以下主题和风格写一个简短的故事:
主题:太空探险
风格:科幻小说
故事:- 命名实体识别:在命名实体识别任务中,如果你知道某些词汇(如人名、地点、组织名)通常代表特定的实体类型,你可以在Prompt中突出这些词汇。
Prompt示例:
识别以下文本中的命名实体:
文本:马云是阿里巴巴的创始人。
实体:5. 如何测试和验证Prompt框架的效果?
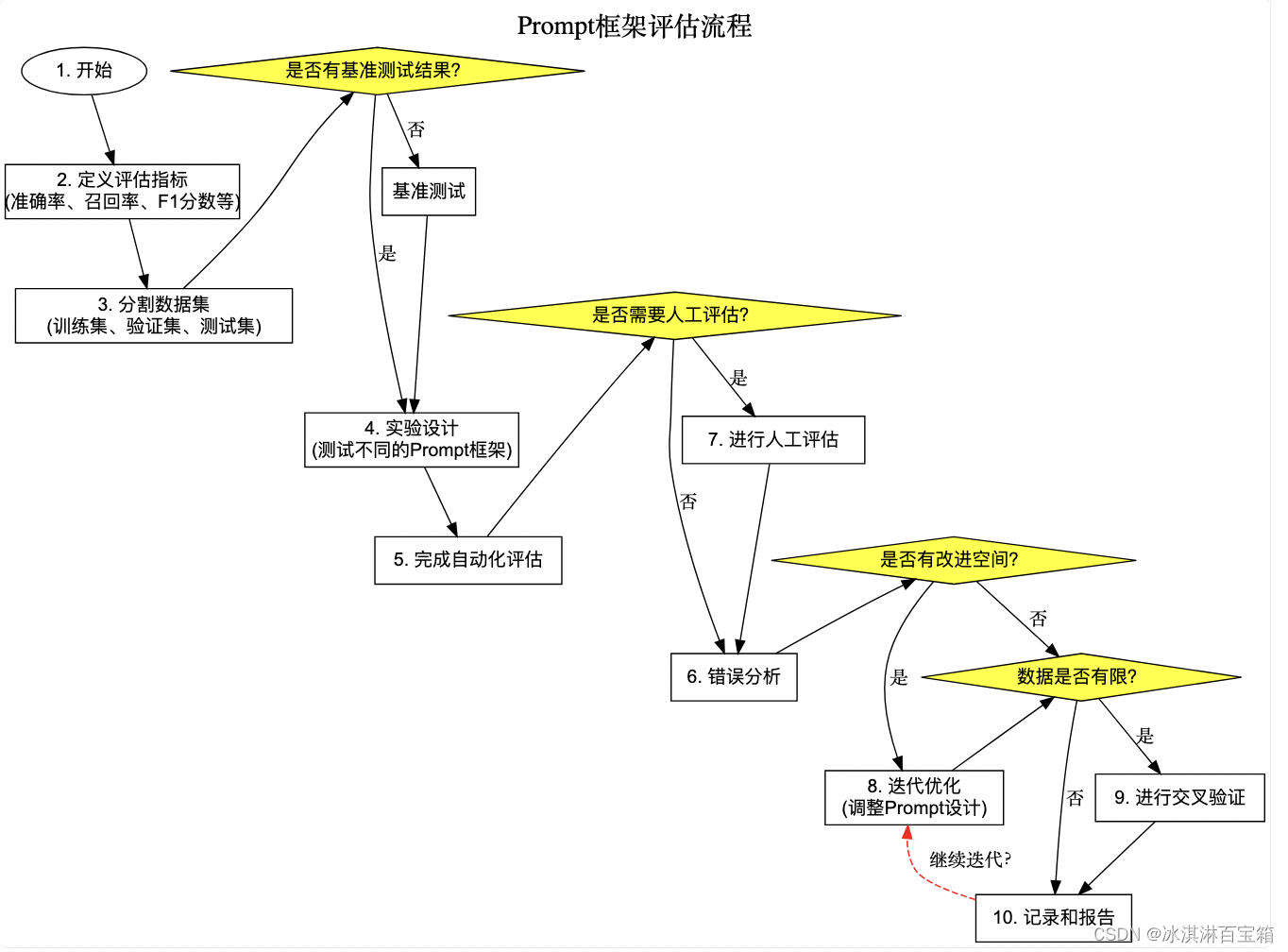
- 定义评估指标:首先,你需要确定如何衡量Prompt框架的效果。这可能包括准确率、召回率、F1分数、BLEU分数、ROUGE分数、人工评估等,具体取决于你的任务类型。
- 分割数据集:将你的数据集分割为训练集、验证集和测试集。训练集用于训练模型,验证集用于调整超参数和评估Prompt框架的设计,而测试集用于最终评估模型性能。
- 基准测试:在没有Prompt的情况下运行模型,获取基准性能。这有助于你了解Prompt框架对模型性能的具体影响。
- 实验设计:设计一系列实验来测试不同的Prompt框架。这可能包括不同的Prompt模板、指令、上下文信息等。确保每次只改变一个变量,以便准确地评估每个变化的效果。
- 自动化评估:使用自动化工具和脚本来自动化评估过程,这有助于你快速比较不同Prompt框架的性能。
- 人工评估:对于一些主观的任务,如文本生成或对话系统,自动化评估可能不够全面。在这种情况下,可以考虑进行人工评估,让人类评估者对模型的输出进行评分。
- 错误分析:分析模型在验证集和测试集中的错误,了解模型在哪些类型的输入上表现不佳,这可以帮助你进一步优化Prompt框架。
- 迭代优化:根据评估结果,对Prompt框架进行迭代优化。这可能包括调整Prompt的设计、添加更多的上下文信息、改进指令等。
- 交叉验证:如果数据量有限,可以考虑使用交叉验证来提高评估的可靠性。
- 记录和报告:详细记录所有实验的设置、结果和观察到的模式。这不仅可以用于当前的模型开发,还可以为未来的研究提供宝贵的参考。
6. 实战:问答系统-测试Prompt框架的例子
以下是一个测试Prompt框架的例子,假设我们正在开发一个问答系统,用于回答有关历史事件的问题。
- 定义评估指标:我们选择准确率作为评估指标,因为对于问答系统来说,能够提供正确答案的比例非常重要。
- 分割数据集:我们将数据集分为训练集、验证集和测试集。训练集用于训练模型,验证集用于调整Prompt框架和超参数,测试集用于最终评估模型性能。
- 基准测试:我们先在没有Prompt的情况下运行模型,得到基准准确率为60%。
- 实验设计:我们设计以下实验来测试不同的Prompt框架:
-
- 实验1:使用简单的指令Prompt,例如:“回答问题:[问题]”
- 实验2:在Prompt中添加相关背景信息,例如:“根据历史背景,回答问题:[问题]”
- 实验3:在Prompt中使用Few-Shot示例,例如:“根据以下示例回答问题:[示例1] [示例2] [问题]”
- 自动化评估:我们使用自动化脚本在验证集上运行这些实验,并计算每个实验的准确率。
- 人工评估:由于自动化评估可能无法完全捕捉到答案的准确性和相关性,我们进行人工评估,让人类评估者对模型的输出进行评分。
- 错误分析:我们分析模型在验证集上的错误,发现实验1中模型经常无法理解问题的上下文,而实验2和实验3中的错误较少。
- 迭代优化:根据评估结果,我们决定采用实验2的Prompt框架,并进一步优化背景信息的呈现方式。
- 交叉验证:由于数据量有限,我们使用交叉验证来评估模型的稳定性。
- 记录和报告:我们记录所有实验的设置、结果和观察到的模式,并编写报告,总结Prompt框架对模型性能的影响。
通过这个例子,我们可以看到如何系统地测试和验证Prompt框架的效果,并根据评估结果进行优化,以提高模型在特定任务上的性能。