Python数据分析实验四:数据分析综合应用开发
目录
- 一、实验目的与要求
- 二、主要实验过程
- 1、加载数据集
- 2、数据预处理
- 3、划分数据集
- 4、创建模型估计器
- 5、模型拟合
- 6、模型性能评估
- 三、主要程序清单和运行结果
- 四、实验体会
一、实验目的与要求
1、目的:
综合运用所学知识,选取有实际背景的应用问题进行数据分析方案的设计与实现。要求明确目标和应用需求,涵盖数据预处理、建模分析、模型评价和结果展示等处理阶段,完成整个分析流程。
2、要求:
(1)应用Scikit-Learn库中的逻辑回归、SVM和kNN算法对Scikit-Learn自带的乳腺癌(from sklearn.datasets import load_breast_cancer)数据集进行分类,并分别评估每种算法的分类性能。
(2)为了进一步提升算法的分类性能,能否尝试使用网格搜索和交叉验证找出每种算法较优的超参数。
二、主要实验过程
1、加载数据集
from sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()
cancer.keys()
dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names'])
将数据集转换为DataFram:
import pandas as pd
cancer_data=pd.DataFrame(cancer.data,columns=cancer.feature_names)
cancer_data['target']=cancer.target_names[cancer.target]
cancer_data.head(3).append(cancer_data.tail(3))
| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | ... | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.30010 | 0.14710 | 0.2419 | 0.07871 | ... | 17.33 | 184.60 | 2019.0 | 0.16220 | 0.66560 | 0.7119 | 0.2654 | 0.4601 | 0.11890 | malignant |
| 1 | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.08690 | 0.07017 | 0.1812 | 0.05667 | ... | 23.41 | 158.80 | 1956.0 | 0.12380 | 0.18660 | 0.2416 | 0.1860 | 0.2750 | 0.08902 | malignant |
| 2 | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.19740 | 0.12790 | 0.2069 | 0.05999 | ... | 25.53 | 152.50 | 1709.0 | 0.14440 | 0.42450 | 0.4504 | 0.2430 | 0.3613 | 0.08758 | malignant |
| 566 | 16.60 | 28.08 | 108.30 | 858.1 | 0.08455 | 0.10230 | 0.09251 | 0.05302 | 0.1590 | 0.05648 | ... | 34.12 | 126.70 | 1124.0 | 0.11390 | 0.30940 | 0.3403 | 0.1418 | 0.2218 | 0.07820 | malignant |
| 567 | 20.60 | 29.33 | 140.10 | 1265.0 | 0.11780 | 0.27700 | 0.35140 | 0.15200 | 0.2397 | 0.07016 | ... | 39.42 | 184.60 | 1821.0 | 0.16500 | 0.86810 | 0.9387 | 0.2650 | 0.4087 | 0.12400 | malignant |
| 568 | 7.76 | 24.54 | 47.92 | 181.0 | 0.05263 | 0.04362 | 0.00000 | 0.00000 | 0.1587 | 0.05884 | ... | 30.37 | 59.16 | 268.6 | 0.08996 | 0.06444 | 0.0000 | 0.0000 | 0.2871 | 0.07039 | benign |
6 rows × 31 columns
2、数据预处理
进行数据标准化:
from sklearn.preprocessing import StandardScaler
X=StandardScaler().fit_transform(cancer.data)
y=cancer.target
3、划分数据集
将数据集划分为训练集和测试集:
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,random_state=33)
4、创建模型估计器
(1)创建逻辑回归模型估计器:
#创建逻辑回归模型估计器
from sklearn.linear_model import LogisticRegression
lgr=LogisticRegression()
(2)创建SVM算法模型估计器:
#创建SVM算法模型估计器
from sklearn.svm import SVC
svc=SVC()
(3)创建kNN算法模型估计器:
#创建kNN算法模型估计器
from sklearn.neighbors import KNeighborsClassifier
knn=KNeighborsClassifier()
5、模型拟合
用训练集训练模型估计器estimator:
#训练逻辑回归模型估计器
lgr.fit(X_train,y_train)
#训练SVM算法模型估计器
svc.fit(X_train,y_train)
#训练kNN算法模型估计器
knn.fit(X_train,y_train)
6、模型性能评估
(1)逻辑回归模型性能评估:
#用模型估计器对测试集数据做预测
y_pred=lgr.predict(X_test)#对模型估计器的学习效果进行评价
print("测试集的分类准确率为:",lgr.score(X_test,y_test))
(2)SVM算法模型性能评估:
#用模型估计器对测试集数据做预测
y_pred=svc.predict(X_test)#对模型估计器的学习效果进行评价
print("测试集的分类准确率为:",svc.score(X_test,y_test))
(3)kNN算法模型性能评估:
#用模型估计器对测试集数据做预测
y_pred=knn.predict(X_test)#对模型估计器的学习效果进行评价
print("测试集的分类准确率为:",knn.score(X_test,y_test))
三、主要程序清单和运行结果
1、逻辑回归用于分类
#加载数据集
from sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()#对数据集进行预处理,实现数据标准化
from sklearn.preprocessing import StandardScaler
X=StandardScaler().fit_transform(cancer.data)
y=cancer.target#将数据集划分为训练集和测试集(要求测试集占25%,随机状态random state设置为33)
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,random_state=33) #创建模型估计器estimator
from sklearn.linear_model import LogisticRegression
lgr=LogisticRegression()#用训练集训练模型估计器estimator
lgr.fit(X_train,y_train)#用模型估计器对测试集数据做预测
y_pred=lgr.predict(X_test)#对模型估计器的学习效果进行评价
#最简单的评估方法:就是调用估计器的score(),该方法的两个参数要求是测试集的特征矩阵和标签向量
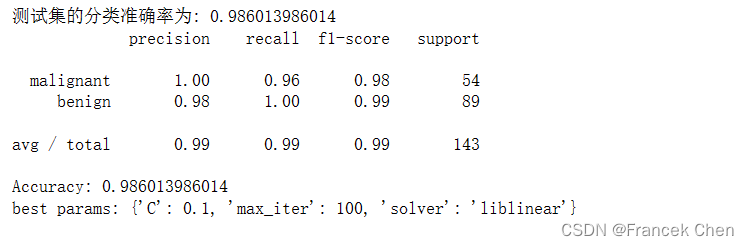
print("测试集的分类准确率为:",lgr.score(X_test,y_test))
from sklearn import metrics
#对于多分类问题,还可以使用metrics子包中的classification_report
print(metrics.classification_report(y_test,y_pred,target_names=cancer.target_names)) #网格搜索与交叉验证相结合的逻辑回归算法分类:
from sklearn.model_selection import GridSearchCV,KFold
params_lgr={'C':[0.01,0.1,1,10,100],'max_iter':[100,200,300],'solver':['liblinear','lbfgs']}
kf=KFold(n_splits=5,shuffle=False)grid_search_lgr=GridSearchCV(lgr,params_lgr,cv=kf)
grid_search_lgr.fit(X_train,y_train)
grid_search_y_pred=grid_search_lgr.predict(X_test)
print("Accuracy:",grid_search_lgr.score(X_test,y_test))
print("best params:",grid_search_lgr.best_params_)
2、支持向量用于分类
#加载数据集
from sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()#对数据集进行预处理,实现数据标准化
from sklearn.preprocessing import StandardScaler
X=StandardScaler().fit_transform(cancer.data)
y=cancer.target#将数据集划分为训练集和测试集(要求测试集占25%,随机状态random state设置为33)
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,random_state=33) #创建模型估计器estimator
from sklearn.svm import SVC
svc=SVC()#用训练集训练模型估计器estimator
svc.fit(X_train,y_train)#用模型估计器对测试集数据做预测
y_pred=svc.predict(X_test)#对模型估计器的学习效果进行评价
#最简单的评估方法:就是调用估计器的score(),该方法的两个参数要求是测试集的特征矩阵和标签向量
print("测试集的分类准确率为:",svc.score(X_test,y_test))
from sklearn import metrics
#对于多分类问题,还可以使用metrics子包中的classification_report
print(metrics.classification_report(y_test,y_pred,target_names=cancer.target_names))#网格搜索与交叉验证相结合的SVM算法分类:
from sklearn.model_selection import GridSearchCV,KFold
params_svc={'C':[0.1,1,10],'gamma':[0.1,1,10],'kernel':['linear','rbf']}
kf=KFold(n_splits=5,shuffle=False)
grid_search_svc=GridSearchCV(svc,params_svc,cv=kf)
grid_search_svc.fit(X_train,y_train)
grid_search_y_pred=grid_search_svc.predict(X_test)
print("Accuracy:",grid_search_svc.score(X_test,y_test))
print("best params:",grid_search_svc.best_params_)

3、kNN用于分类
#加载数据集
from sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()#对数据集进行预处理,实现数据标准化
from sklearn.preprocessing import StandardScaler
X=StandardScaler().fit_transform(cancer.data)
y=cancer.target#将数据集划分为训练集和测试集(要求测试集占25%,随机状态random state设置为33)
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,random_state=33) #创建模型估计器estimator
from sklearn.neighbors import KNeighborsClassifier
knn=KNeighborsClassifier()#用训练集训练模型估计器estimator
knn.fit(X_train,y_train)#用模型估计器对测试集数据做预测
y_pred=knn.predict(X_test)#对模型估计器的学习效果进行评价
#最简单的评估方法:就是调用估计器的score(),该方法的两个参数要求是测试集的特征矩阵和标签向量
print("测试集的分类准确率为:",knn.score(X_test,y_test))
from sklearn import metrics
#对于多分类问题,还可以使用metrics子包中的classification_report
print(metrics.classification_report(y_test,y_pred,target_names=cancer.target_names))#网格搜索与交叉验证相结合的kNN算法分类:
from sklearn.model_selection import GridSearchCV,KFold
params_knn={'algorithm':['auto','ball_tree','kd_tree','brute'],'n_neighbors':range(3,10,1),'weights':['uniform','distance']}
kf=KFold(n_splits=5,shuffle=False)
grid_search_knn=GridSearchCV(knn,params_knn,cv=kf)
grid_search_knn.fit(X_train,y_train)
grid_search_y_pred=grid_search_knn.predict(X_test)
print("Accuracy:",grid_search_knn.score(X_test,y_test))
print("best params:",grid_search_knn.best_params_)

四、实验体会
在本次实验中,我使用了Scikit-Learn库中的逻辑回归、支持向量机(SVM)和k最近邻(kNN)算法对乳腺癌数据集进行分类,并对每种算法的分类性能进行了评估。随后,我尝试使用网格搜索和交叉验证来找出每种算法的较优超参数,以进一步提升其分类性能。
首先,我加载了乳腺癌数据集,并将其划分为训练集和测试集。然后,我分别使用逻辑回归、SVM和kNN算法进行训练,并在测试集上进行评估。评估指标包括准确率、精确率、召回率和F1-score等。通过这些指标,我能够了解每种算法在乳腺癌数据集上的分类性能。
接着,我尝试使用网格搜索(Grid Search)和交叉验证(Cross Validation)来找出每种算法的较优超参数。网格搜索是一种通过在指定的超参数空间中搜索最佳参数组合来优化模型的方法。而交叉验证则是一种评估模型性能和泛化能力的方法,它将数据集分成多个子集,在每个子集上轮流进行训练和测试,从而得到更稳健的性能评估结果。
在进行网格搜索和交叉验证时,我根据每种算法的参数范围设置了不同的参数组合,并使用交叉验证来评估每种参数组合的性能。最终,我选择了在交叉验证中性能最优的参数组合作为最终的超参数,并将其用于重新训练模型。
通过这次实验,我学到了如何使用Scikit-Learn库中的机器学习算法进行分类任务,并了解了如何通过网格搜索和交叉验证来优化算法的超参数,提升其分类性能。同时,我也意识到了在实际应用中,选择合适的算法和调优超参数对于获得良好的分类效果至关重要。这次实验为我提供了宝贵的实践经验,对我的机器学习学习之旅有着重要的意义。