Llama 3 CPU推理优化指南
备受期待的 Meta 第三代 Llama 现已发布,我想确保你知道如何以最佳方式部署这种最先进的 (SoTA) LLM。在本教程中,我们将重点介绍如何执行仅权重量化 (WOQ) 来压缩 8B 参数模型并改善推理延迟,但首先,让我们讨论一下 Meta Llama 3。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、Llama 3
到目前为止,Llama 3 系列包括从 8B 到 70B 参数的模型,未来还会有更多版本。这些模型附带宽松的 Meta Llama 3 许可证,建议你在接受使用它们所需的条款之前先查看一下。这标志着 Llama 模型系列和开源 AI 的一个激动人心的篇章。
1.1 架构
Llama 3 是一个基于仅解码器transformer的自回归 LLM。与 Llama 2 相比,Meta 团队做出了以下显著改进:
- 采用分组查询注意 (GQA),提高了推理效率。
- 优化的标记器,词汇量为 128K 个标记,旨在更有效地编码语言。
- 在 15 万亿个标记数据集上进行训练,这比 Llama 2 的训练数据集大 7 倍,代码量多 4 倍。
下图(图 1)是 print(model) 的结果,其中 model 是 meta-llama/Meta-Llama-3–8B-Instruct。在此图中,我们可以看到该模型包含 32 个由 Llama Attention 自注意力组件组成的 LlamaDecoderLayers。此外,它还有 LlamaMLP、LlamaRMSNorm 和 Linear head。我们希望在 Llama 3 研究论文发布后了解更多信息。
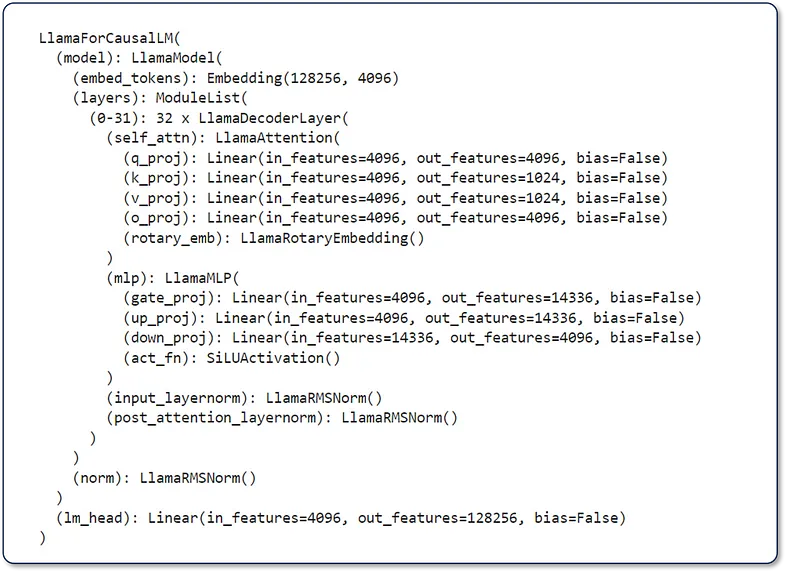
图 1. `print(model)` 的输出展示了 llama-3-8B-instruct 架构中各层的分布
1.2 语言建模性能
该模型在各种行业标准语言建模基准上进行了评估,例如 MMLU、GPQA、HumanEval、GSM-8K、MATH 等。为了本教程的目的,我们将回顾“指令调整模型”的性能(图 2)。这些数字中最引人注目的是,Llama 3 8B 参数模型在报告的基准测试中比 Llama 2 70B 的性能高出 62% 到 143%,同时模型体积小 88%!
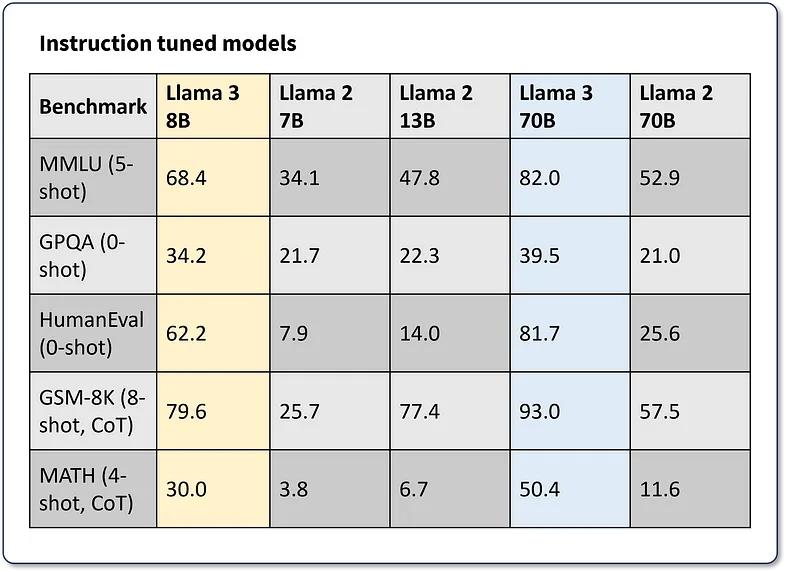
图 2. Llama 3 指令模型在 MMLU、GPQA、HumanEval、GSM-8K 和 MATH LLM 基准测试中的性能指标摘要
最新一代 Llama 所包含的语言建模性能提升、许可宽松和架构效率标志着生成式 AI 领域一个激动人心的篇章的开始。让我们来探索如何优化 CPU 上的推理,以实现可扩展、低延迟的 Llama 3 部署。
2、使用 PyTorch 优化 Llama 3 推理
在上一篇文章中,我介绍了模型压缩和整体推理优化在开发基于 LLM 的应用程序中的重要性。在本教程中,我们将重点介绍将仅权重量化 (WOQ) 应用于 meta-llama/Meta-Llama-3–8B-Instruct。WOQ 在性能、延迟和准确性之间实现了平衡,并可选择量化为 int4 或 int8。WOQ 的一个关键组成部分是反量化步骤,它在计算之前将 int4/in8 权重转换回 bf16。

图 3. 仅权重量化的简单说明,橙色表示预量化权重,绿色表示量化权重。请注意,这描述了计算步骤中初始量化为 int4/int8 和反量化为 fp16/bf16
2.1 环境设置
你需要大约 60GB 的 RAM 才能在 Llama-3-8B-Instruct 上执行 WOQ。其中包括约 30GB 用于加载完整模型和约 30GB 用于量化期间的峰值内存。WOQ Llama 3 仅消耗约 10GB 的 RAM,这意味着我们可以通过从内存中释放完整模型来释放约 50GB 的 RAM。
你可以在 Intel® Tiber® 开发人员云免费 JupyterLab* 环境上运行本教程。该环境提供具有 224 个线程和 504 GB 内存的第四代 Intel® Xeon® CPU,足以运行此代码。
如果在自己的 IDE 中运行此程序,你可能需要解决其他依赖项,例如安装 Jupyter 和/或配置 conda/python 环境。在开始之前,请确保你已安装以下依赖项。
intel-extension-for-pytorch==2.2
transformers==4.35.2
torch==2.2.0
huggingface_hub2.2 访问和配置 Llama 3
你需要一个 Hugging Face* 帐户才能访问 Llama 3 的模型和标记器。
为此,请从设置菜单中选择“访问令牌”(图 4)并创建一个令牌。
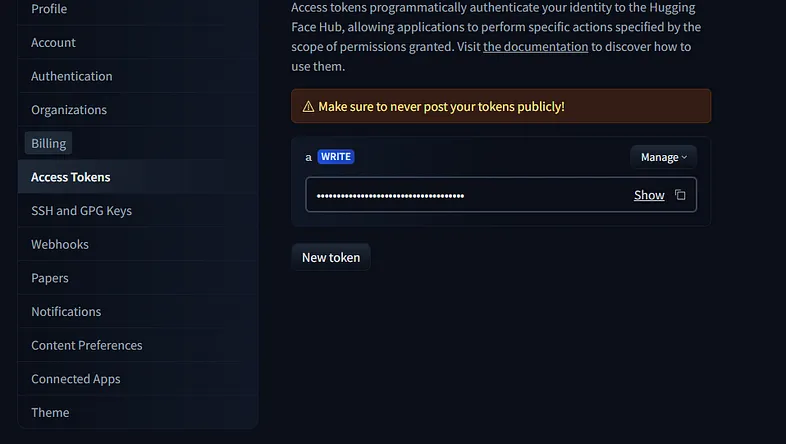
图 4. Hugging Face 令牌配置控制台的快照
复制你的访问令牌并将其粘贴到运行以下代码后在 Jupyter 单元内生成的“令牌”字段中。
from huggingface_hub import notebook_login, Repository# Login to Hugging Face
notebook_login()请访问 meta-llama/Meta-Llama-3–8B-Instruct,在提供你的信息并提交 Llama 3 访问请求之前,仔细评估条款和许可。接受模型的条款并提供你的信息完全由你自己决定。
2.3 使用 WOQ 量化 Llama-3–8B-Instruct
我们将利用英特尔® PyTorch* 扩展将 WOQ 应用于 Llama 3。此扩展包含针对英特尔硬件的最新 PyTorch 优化。按照以下步骤使用优化的 Llama 3 模型进行量化和推理:
- Llama 3 模型和标记器
导入所需的软件包并使用AutoModelForCausalLM.from_pretrained() 和 AutoTokenizer.from_pretrained() 方法加载 Llama-3–8B-Instruct 特定的权重和标记器。
import torch
import intel_extension_for_pytorch as ipex
from transformers import AutoTokenizer, AutoModelForCausalLM, TextStreamerModel = 'meta-llama/Meta-Llama-3-8B-Instruct'model = AutoModelForCausalLM.from_pretrained(Model)
tokenizer = AutoTokenizer.from_pretrained(Model)- 量化配方配置
配置 WOQ 量化配方。我们可以将 weight_dtype 变量设置为所需的内存数据类型,分别为 int4 和 in8 选择 torch.quint4x2 或 torch.qint8。此外,我们可以使用 lowp_model 来定义反量化精度。
目前,我们将其保留为 ipex.quantization.WoqLowpMode.None,以保持默认的 bf16 计算精度。
qconfig = ipex.quantization.get_weight_only_quant_qconfig_mapping(weight_dtype=torch.quint4x2, # or torch.qint8lowp_mode=ipex.quantization.WoqLowpMode.NONE, # or FP16, BF16, INT8
)
checkpoint = None # optionally load int4 or int8 checkpoint# PART 3: Model optimization and quantization
model_ipex = ipex.llm.optimize(model, quantization_config=qconfig, low_precision_checkpoint=checkpoint)del model 我们使用 ipex.llm.optimize() 应用 WOQ,然后使用 del model 从内存中删除完整模型并释放约 30GB 的 RAM。
- 提示 Llama 3
与 LLama 2 一样,Llama 3 为其指令调整模型提供了预定义的提示模板。使用此模板,开发人员可以定义特定的模型行为指令并提供用户提示和对话历史记录。
system= """\n\n You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. If you don't know the answer to a question, please don't share false information."""
user= "\n\n You are an expert in astronomy. Can you tell me 5 fun facts about the universe?"
model_answer_1 = 'None'llama_prompt_tempate = f"""
<|begin_of_text|>\n<|start_header_id|>system<|end_header_id|>{system}
<|eot_id|>\n<|start_header_id|>user<|end_header_id|>{user}
<|eot_id|>\n<|start_header_id|>assistant<|end_header_id|>{model_answer_1}<|eot_id|>
"""inputs = tokenizer(llama_prompt_tempate, return_tensors="pt").input_ids我们提供所需的字段,然后使用 tokenizer 将整个模板转换为模型的 token。
- Llama 3 推理
对于文本生成,我们利用 TextStreamer 生成实时推理流,而不是一次打印整个输出。这为读者带来了更自然的文本生成体验。我们为 model_ipex.generate() 和其他文本生成参数提供了配置的流式处理程序。
streamer = TextStreamer(tokenizer,skip_prompt=True)with torch.inference_mode():tokens = model_ipex.generate(inputs,streamer=streamer,pad_token_id=128001,eos_token_id=128001,max_new_tokens=300,repetition_penalty=1.5,
)运行此代码后,模型将开始生成输出。请记住,这些是未经过滤且不受保护的输出。对于实际用例,你需要进行额外的后处理考虑。
图 5. 在英特尔 Tiber 开发者云的 JupyterLab 环境上运行的 Llama-3–8B-Instruct 在 int4 上使用 WOQ 模式压缩进行流式推理
3、部署注意事项
根据你的推理服务部署策略,需要考虑以下几点:
- 如果在容器中部署 Llama 3 实例,WOQ 将提供较小的内存占用,并允许你在单个硬件节点上提供模型的多个推理服务。
- 部署多个推理服务时,你应该优化为每个服务实例保留的线程和内存。留出足够的额外内存(~4 GB)和线程(~4 个线程)来处理后台进程。
- 考虑保存模型的 WOQ 版本并将其存储在模型注册表中,从而无需在每个实例部署时重新量化模型。
4、结束语
Meta 的 Llama 3 LLM 系列与前几代产品相比有了显著的改进,具有多种配置(更多配置即将推出)。在本教程中,我们探索了使用仅权重量化 (WOQ) 增强 CPU 推理,这是一种减少延迟且对准确性影响最小的技术。
通过将新一代面向性能的 Llama 3 LLM 与 WOQ 等优化技术相结合,开发人员可以为 GenAI 应用程序解锁新的可能性。这种组合简化了硬件要求,以实现集成到新系统和现有系统中的 LLM 的高保真度、低延迟结果。
接下来要尝试的一些令人兴奋的事情是:
- 尝试量化级别:你应该测试 int4 和 int8 量化,以确定特定应用程序的性能和准确性之间的最佳折衷。
- 性能监控:在不同的现实场景中持续评估 Llama 3 模型的性能和准确性至关重要,以确保量化保持所需的有效性。
- 测试更多 Llamas:探索整个 Llama 3 系列并评估 WOQ 和其他 PyTorch 量化配方的影响。
原文链接:Llama 3 CPU推理指南 - BimAnt