【class18】人工智能初步----语音识别(4)
【class17】
上节课,我们学习了: 语音端点检测的相关概念,并通过代码切分和保存了音频。
本节课,我们将学习这些知识点:
1. 序列到序列模型
2. 循环神经网络
3. 调用短语音识别接口

知其然,知其所以然
在调用语音识别接口前,我们先来学习语音识别系统最核心的部分:强大的黑盒子——语音识别模型。
通过学习黑盒子的内部,帮助我们进一步了解语音识别的前因后果。
强大的黑盒子
在一个典型的深度学习语音识别系统中,其模型由两部分组成:
1.编码器 2.解码器

编码和译码的目的
1.为了对输入数据进行分析并编写成机器能够处理的信息,就需要编码。
2.为了将编码器编写的信息翻译成人类理解的信息,就需要译码。
通俗的说,编码器就是让机器读得懂,解码器就是让人读的懂。
编码器解码器模型又叫做seq2seq模型——序列到序列模型。序列到序列也就是说,输入和输出都是序列。
序列到序列模型
定义
序列到序列模型(seq2seq )包括编码器 (Encoder) 和解码器 (Decoder) 两部分。
seq2seq 是自然语言处理中的一种重要模型,可以用于语音识别、机器翻译、对话系统以及自动文摘等。
隐喻
把这个过程想象成谍战片里的情报截获和翻译,编码器为敌方,解码器为我方。我方情报员截获了敌方编码好的情报,为了读懂情报,就需要进行解码。
语音识别的输入和输出都是不定长序列,换句话说,就是每次输入的语音和输出的文字长度不定。比如,时长不一样的语音,采样后所得的数字序列是不一样长的。
像语音识别这种输入输出都是不定长序列时,我们就使用seq2seq模型。
seq2seq模型由编码器和解码器组成,而编码器和解码器都是利用了循环神经网络 — RNN来实现的。基本思想就是利用两个RNN,一个RNN作为编码器,另一个RNN作为解码器。
循环神经网络
定义
循环神经网络 (Recurrent Neural Network,RNN) 是一类用于处理序列数据的神经网络。在近些年,人们利用RNN解决了各种各样的问题:语音识别、语言模型、机器翻译和图像描述等。
对于序列数据来说,顺序排列非常重要! 比如,这样一句话「我要给手( )充电」。 我们就可以根据前后文字猜测,( )可能是机、表等单字。

当话变成「电充( )手要我」时,( )里该填什么?是不是满脸问号???显然,针对有关于序列的问题,我们需要一个神经网络来进行专门的处理。于是RNN出来了。

在学习RNN结构之前,我们看其他网络(如CNN)是如何处理数据的:每个网络处理数据是单独进行的。
每个数据通过隐含层(A)处理,都会得到一个对应的结果。
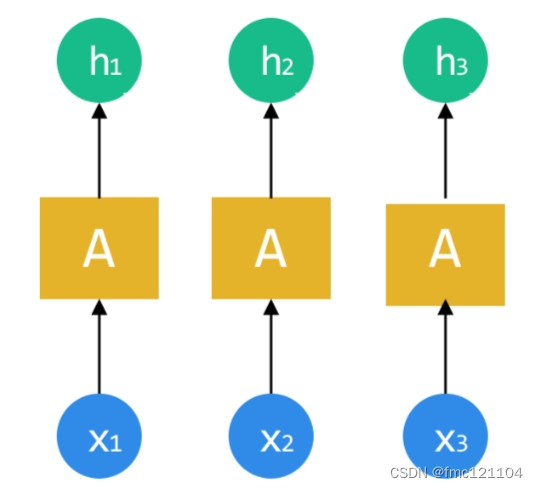
如果待处理的数据之间(x1、x2、x3)有关联顺序,也就是为序列数据时:对于神经网络来说,并没有办法知道数据之间的关联。怎么让网络知道这些数据顺序关联,比如图中的护肤顺序,并能进一步分析呢?
科学家们脑袋一转,不怕不怕,我们把前一个网络的中间状态作为后一个的输入就好啦!这样就能形成一个所有记忆循环分析的网络,处理序列数据刚刚好!
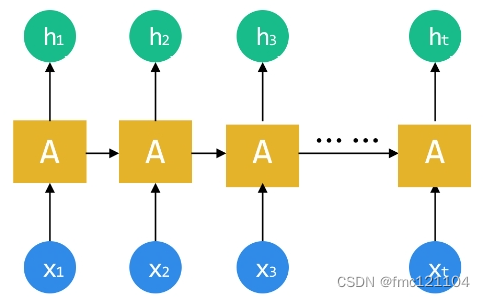
RNN结构
循环神经网络和卷积神经网络一样,它包含三个结构:
1. 输入层 2. 隐含层 3. 输出层

为了更好理解,将RNN按照序列顺序将其展开:
RNN 的顺序链式结构让它看起来就像是为序列数据而生!(图中的输入x1-xt就可以是我们采样所得的序列数据)

输入层、输出层比较容易理解。
在语音识别中,输入层输入的是语音,输出层输出的是识别结果。
那么,隐含层呢?
循环神经网络的隐含层前后顺序相连,前后相互依赖,前一个的输出为后一个的输入。 这与语音的前一个字依赖后一个字或者前一句话依赖后一句话非常契合。
RNN VS CNN
RNN 与CNN相比,RNN的特别之处在于:
1. 处理序列数据效果好
2. 允许控制输入或输出向量序列的长度
第1点我们已经学习了,接下来,我们通过两个结构模型来理解第2点。
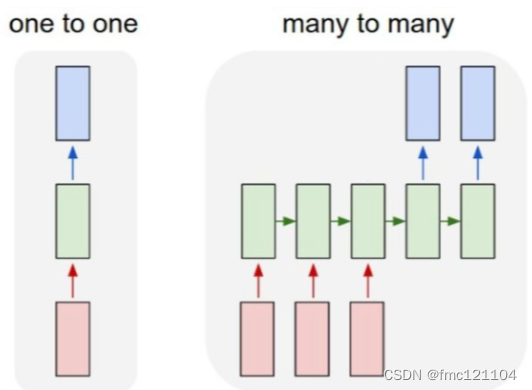
CNN:
1->1 结构,固定长的输入和输出 (应用:比如图像分类)
RNN
N->M 结构,不定长的序列输入和序列输出 (应用:比如语音识别)
seq2seq模型输入输出序列的长度是不固定的,对应的就是N->M结构。
学习完seq2seq模型与RNN的原理和概念之后,该如何实现语音识别呢?接下来,我们完成“调用接口实现语音识别”的第一步——单段音频的语音识别。
通过代码调用短语音识别接口,实现对单段音频文件的语音识别。
让我们一起尝试一下吧~
1. 首先,我们开始打开并读取音频。
使用 with...as 配合open()函数以rb 方式,打开路径为filePath的音频,并赋值给 fp;
使用read()函数读取音频,输出结果为二进制的编码数据。
代码示例:
调用短语音识别接口
代码的作用
利用短语音识别接口,对一段音频文件识别,返回值为字典类型。
第20行,通过asr接口识别输入的音频wavsample,并将结果存储在rejson变量中。

分析代码:
语音识别客户端
使用变量client,即创建好的语音识别客户端,可对其调用。
短语音识别接口
对创建的AipSpeech客户端,使用asr()函数调用短语音识别接口。
注意:该接口只能将60秒以下的音频识别为文字,若音频时长超过限制,可切分为多段音频进行识别。
待识别语音
必选参数wavsample,语音内容的Buffer对象,文件格式支持pcm 或者 wav 或者 amr。
文件格式
必选参数,传入字符串"wav"设置音频文件格式为wav文件。
采样率
必选参数,传入参数16000声明音频文件的采样率为16000Hz。常用的音频采样率有:8000Hz、16000Hz和32000Hz等。
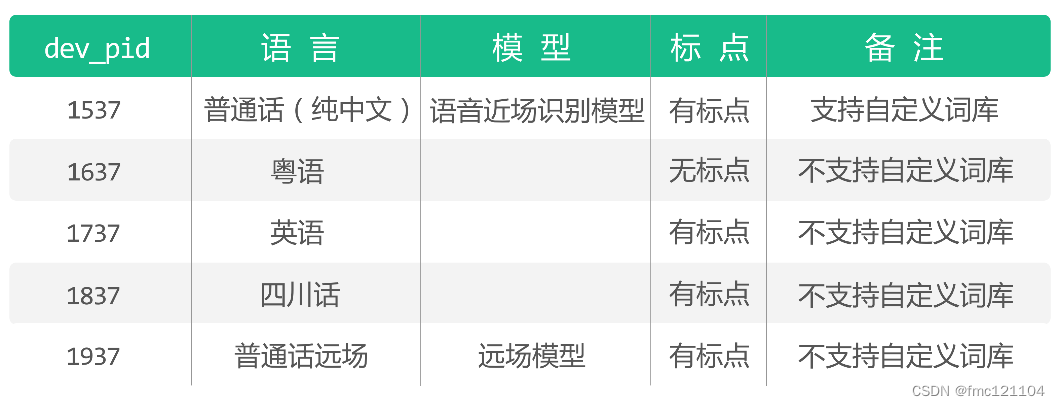
可选参数
asr()函数中传入可选参数{"dev_pid": 参数}设置待识别音频的语音类型。
参数为1537表示可识别的语言:普通话(纯中文识别)。
其余参数和解释如下:
总结:
调用接口----使用asr()函数调用短语音识别接口。将待识别的音频必选参数wavsample,"wav",16000传入到该函数中。输出调用接口返回的结果rejson。

从输出结果可以看到,调用接口返回的是一个字典。 该字典包含多个参数:
corpus_no:语料库码 err_msg:错误码描述 err_no:错误码
result:识别结果 sn:语音数据唯一标识
成功返回
成功返回时rejson字典中的参数err_msg和err_no内容为:
1. err_msg:错误码描述,rejson["err_msg"]为"success."
2. err_no:错误码,rejson["err_no"]为0
成功返回时rejson字典中的参数result为列表结构:rejson["result"]中保存了单段音频语音识别的文字信息。
获取识别结果
查看输出结果,我们从rejson字典中的键result就能得到识别结果。
调用接口返回的是一个复杂的字典结构,我们将它赋值给了变量rejson。
从字典rejson中取出参数"result"的值,可以用rejson["result"];
再从rejson["result"]中取出列表内的元素,可以用rejson["result"][0]。
代码示例:
# 获取语音识别结果
# 从返回结果中提取出参数result中的唯一值并赋值给变量msg
msg = rejson["result"][0]
完善代码:
-
- if-else语句判定
使用if-else语句,若错误码为0,则得到语音识别结果;否则给出"语音识别错误!"提示。
以防出现语音识别无结果或者出现其他错误情况,而导致代码报错不能正常运行!
- if-else语句判定
代码:
# if—else语句判定
# 若错误码为0,则得到语音识别结果
if rejson["err_no"] == 0:
# 获取语音识别结果
# 从返回结果中提取出参数result中的唯一值并赋值给变量msg
msg = rejson["result"][0]
# 否则给出"语音识别错误!"提示
else:
msg = "语音识别错误!"
-
- 语音识别函数
将调用接口实现语音识别封装为函数,方便后面的调用。
最后通过参数wavsample调用函数,并输出结果。
修改后的代码:
# 定义语音识别函数audio2text()
def audio2text(wav):
# 调用短语音识别接口把结果赋值给rejson变量
rejson = client.asr(wav,"wav",16000,{"dev_pid": 1537})
# if—else语句判定
# 若错误码为0,则得到语音识别结果
if rejson["err_no"] == 0:
# 获取语音识别结果
# 从返回结果中提取出参数result中的唯一值并赋值给变量msg
msg = rejson["result"][0]
# 否则给出"语音识别错误!"提示
else:
msg = "语音识别错误!"
# 返回语音识别结果msg
return msg
调用短语音识别接口实现了单个音频的语音识别。接下来我们对上节课获得的音频片段做批量处理,批量读取音频文件,实现多段音频文件的批量识别。
我们先完成第一步——批量读取音频。
代码复习
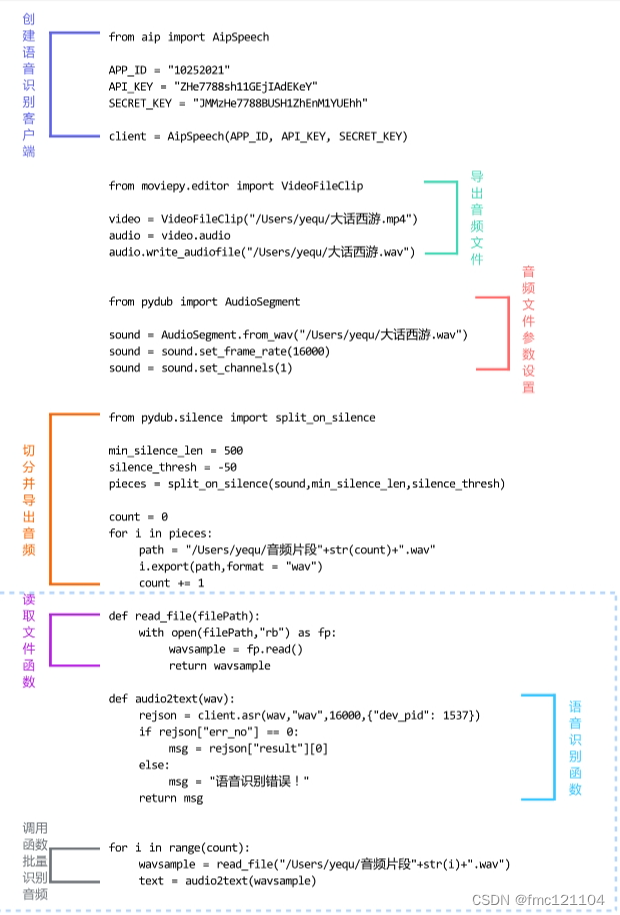
批量处理之前,复习一下前面课程从视频中获取音频文件,并切分和保存为wav文件的完整代码。
"""获取音频文件"""
from moviepy.editor import VideoFileClip
video = VideoFileClip("/Users/yequ/大话西游.mp4")
audio = video.audio
audio.write_audiofile("/Users/yequ/大话西游.wav")
"""音频文件参数设置"""
from pydub import AudioSegment
sound = AudioSegment.from_wav("/Users/yequ/大话西游.wav")
sound = sound.set_frame_rate(16000)
sound = sound.set_channels(1)
"""切分音频"""
from pydub.silence import split_on_silence
min_silence_len = 500
silence_thresh = -50
pieces = split_on_silence(sound,min_silence_len,silence_thresh)
"""导出音频片段"""
count = 0
for i in pieces:
path = "/Users/yequ/音频片段"+str(count)+".wav"
i.export(path,format = "wav")
count += 1
step1.批量读取音频
将文件读取部分代码封装为函数:定义文件读取函数read_file(),传入参数文件地址filePath,返回音频对象wavsample。
再通过for循环批量读取切分完的音频文件,共12个音频文件,循环范围为0-11,即range(count)。
代码:
# 定义文件读取函数read_file(),传入参数文件地址filePath
def read_file(filePath):
# 使用 with...as 配合open函数以rb 方式,打开路径为filePath的音频
with open(filePath,"rb") as fp:
# 使用read()函数读取音频赋值给wavsample
wavsample = fp.read()
# 返回音频对象
return wavsample
# 通过for循环批量读取切分完的音频文件
for i in range(count):##
wavsample = read_file("/Users/yequ/音频片段"+str(i)+".wav")
# 输出查看wavsample结果
print(wavsample)
step2批量读取完音频之后:
我们将实现“多段音频文件的批量识别”的第二步——批量调用接口识别音频。
批量调用接口识别音频:在for循环结果的循环体内,调用语音识别函数audio2text(),获取语音识别结果,并输出识别结果,实现批量调用接口识别音频。
代码:
# 通过for循环调用批量读取切分完的音频文件
for i in range(count):
# 调用文件读取函数read_file(),读取所有音频片段文件
wavsample = read_file("/Users/yequ/音频片段"+str(i)+".wav")
# 调用语音识别函数audio2text(),获取语音识别结果
text = audio2text(wavsample)
# 输出查看text
print(text)
代码整理
将今日学习的代码分为三个部分:
part1. 读取文件函数
part2. 语音识别函数
part3. 调用函数批量识别音频
本节课,我们学习了语音识别模型的结构和原理,同时调用创建好的AipSpeech客户端实现了语音转文字功能。
下节课,我们将学习视频文件字幕格式,并通过代码生成标准格式字幕文件。